
1. Обзор

Что такое Document AI?
Document AI — это платформа, позволяющая извлекать полезную информацию из ваших документов. По сути, она предлагает постоянно расширяющийся список обработчиков документов (также называемых парсерами или разделителями, в зависимости от их функциональности).
Существует два способа управления процессорами Document AI:
- вручную, через веб-консоль;
- Программным способом, используя API Document AI.
Вот пример скриншота, показывающий список ваших процессоров как из веб-консоли, так и из кода Python:
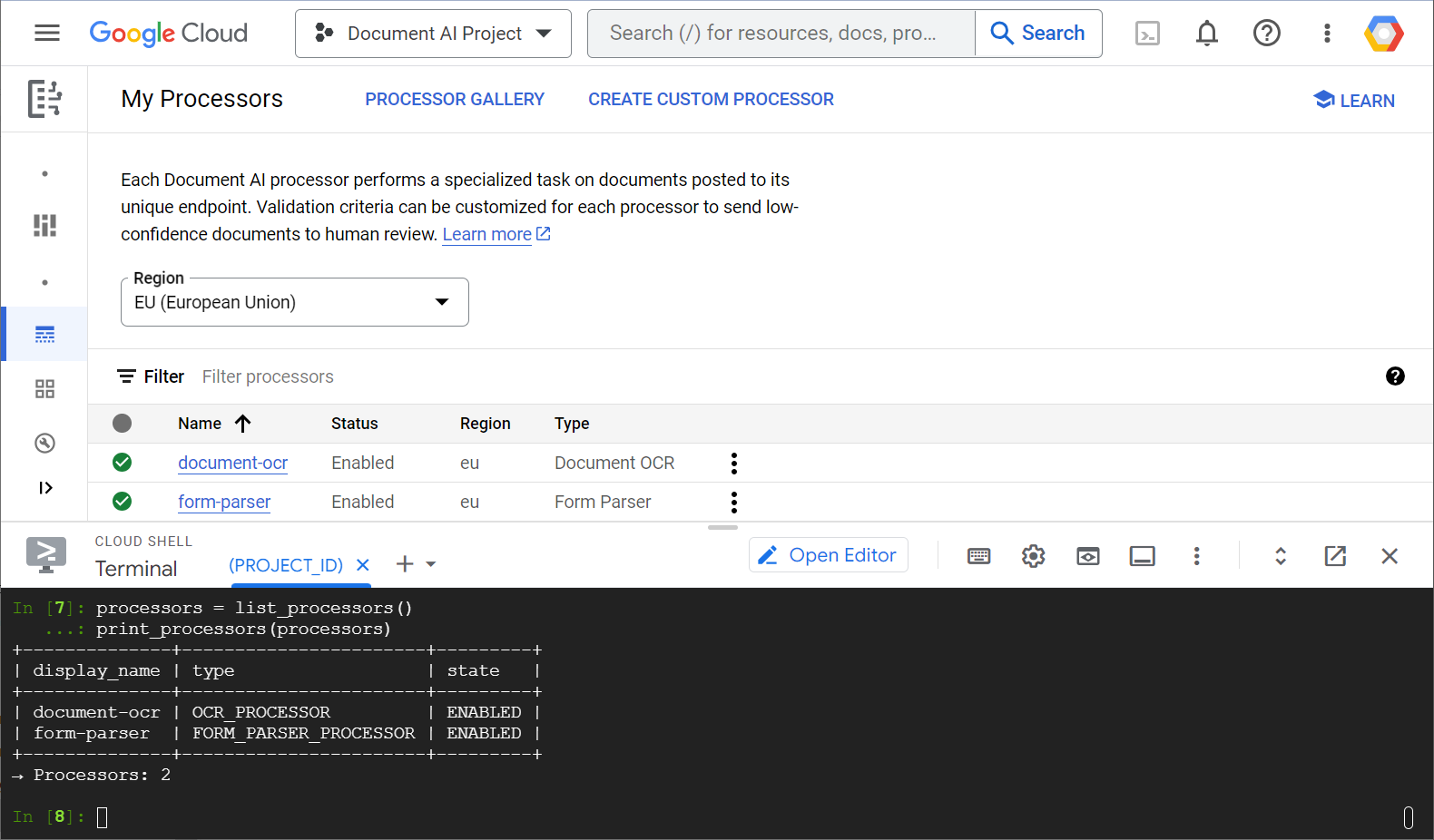
В этой лабораторной работе вы сосредоточитесь на программном управлении обработчиками Document AI с помощью клиентской библиотеки Python.
Что вы увидите
- Как настроить свою среду
- Как получить информацию о типах процессоров
- Как создавать процессоры
- Как составить список обработчиков проектов
- Как использовать процессоры
- Как включить/отключить процессоры
- Как управлять версиями процессора
- Как удалить процессоры
Что вам понадобится
Опрос
Как вы будете использовать этот учебный материал?
Как бы вы оценили свой опыт работы с Python?
Как бы вы оценили свой опыт использования сервисов Google Cloud?
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этой лабораторной работе вы будете использовать Cloud Shell — среду командной строки, работающую в облаке.
Активировать Cloud Shell
- В консоли Cloud нажмите «Активировать Cloud Shell» .
 .
.

Если вы запускаете Cloud Shell впервые, вам будет показан промежуточный экран с описанием его возможностей. Если вам был показан промежуточный экран, нажмите «Продолжить» .
Подготовка и подключение к Cloud Shell займут всего несколько минут.

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Большая часть, если не вся, ваша работа в этом практическом задании может быть выполнена с помощью браузера.
После подключения к Cloud Shell вы увидите, что прошли аутентификацию и что проект настроен на ваш идентификатор проекта.
- Выполните следующую команду в Cloud Shell, чтобы подтвердить свою аутентификацию:
gcloud auth list
вывод команды
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте:
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить это с помощью следующей команды:
gcloud config set project <PROJECT_ID>
вывод команды
Updated property [core/project].
3. Настройка среды
Прежде чем начать использовать Document AI, выполните следующую команду в Cloud Shell, чтобы включить API Document AI:
gcloud services enable documentai.googleapis.com
Вы должны увидеть что-то подобное:
Operation "operations/..." finished successfully.
Теперь вы можете использовать Document AI!
Перейдите в свою домашнюю директорию:
cd ~
Создайте виртуальное окружение Python для изоляции зависимостей:
virtualenv venv-docai
Активируйте виртуальную среду:
source venv-docai/bin/activate
Установите IPython, клиентскую библиотеку Document AI и python-tabulate (который вы будете использовать для форматированного вывода результатов запроса):
pip install ipython google-cloud-documentai tabulate
Вы должны увидеть что-то подобное:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Теперь вы готовы использовать клиентскую библиотеку Document AI!
Установите следующие переменные среды:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
С этого момента все этапы следует выполнять в рамках одной сессии.
Убедитесь, что ваши переменные окружения определены правильно:
echo $PROJECT_ID
echo $API_LOCATION
На следующих шагах вы будете использовать интерактивный интерпретатор Python под названием IPython , который вы только что установили. Начните сессию, запустив ipython в Cloud Shell:
ipython
Вы должны увидеть что-то подобное:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Скопируйте следующий код в свою сессию IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Вы готовы отправить свой первый запрос и получить типы процессоров.
4. Получение типов процессоров
Перед созданием процессора на следующем шаге получите список доступных типов процессоров. Этот список можно получить с помощью fetch_processor_types .
Добавьте следующие функции в сессию IPython:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Перечислите типы процессоров:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
В результате у вас должно получиться что-то подобное:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Теперь у вас есть вся необходимая информация для создания процессоров на следующем этапе.
5. Создание процессоров
Для создания процессора вызовите функцию create_processor , указав отображаемое имя и тип процессора.
Добавьте следующую функцию:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Создайте обработчики тестов:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
В результате вы должны получить следующее:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Вы создали новые процессоры!
Далее рассмотрим, как составить список процессоров.
6. Перечень обработчиков проектов
list_processors возвращает список всех процессоров, принадлежащих вашему проекту.
Добавьте следующие функции:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Вызовите функции:
processors = list_processors()
print_processors(processors)
В результате вы должны получить следующее:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Для получения информации о процессоре по его отображаемому имени добавьте следующую функцию:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Проверьте работу функции:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Вы должны увидеть что-то подобное:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Теперь вы знаете, как составить список обработчиков вашего проекта и получить к ним доступ по отображаемым именам. Далее рассмотрим, как использовать обработчик.
7. Использование процессоров
Обработка документов может осуществляться двумя способами:
- Синхронно : Вызовите
process_documentдля анализа отдельного документа и непосредственного использования результатов. - Асинхронно : вызовите функцию
batch_process_documentsдля запуска пакетной обработки нескольких или больших документов.
Ваш тестовый документ ( PDF ) представляет собой отсканированную анкету, заполненную от руки. Загрузите её в свою рабочую директорию непосредственно из сессии IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Проверьте содержимое вашей рабочей директории:
!ls
У вас должно быть следующее:
... form.pdf ... venv-docai ...
Для анализа локального файла можно использовать синхронный метод process_document . Добавьте следующую функцию:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Поскольку ваш документ представляет собой анкету, выберите парсер форм. Помимо извлечения текста (печатного и рукописного), что делают все процессоры, этот универсальный процессор распознает поля формы.
Проанализируйте документ:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Все процессоры выполняют первый этап оптического распознавания символов (OCR) документа. Просмотрите текст, распознанный в ходе OCR:
document.text.split("\n")
Вы должны увидеть что-то подобное:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Добавьте следующие функции для вывода обнаруженных полей формы:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Также добавьте следующие вспомогательные функции:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Вывести на экран обнаруженные поля формы:
print_form_fields(document)
В результате вы должны получить распечатку примерно следующего вида:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Просмотрите обнаруженные названия полей и значения ( PDF ). Вот верхняя часть анкеты:

Вы проанализировали форму, содержащую как печатный, так и рукописный текст. Вы также с высокой степенью достоверности определили ее поля. В результате ваши пиксели были преобразованы в структурированные данные!
8. Включение и отключение процессоров
С помощью disable_processor и enable_processor вы можете управлять возможностью использования процессора.
Добавьте следующие функции:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Отключите обработчик парсинга форм и проверьте состояние ваших обработчиков:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
В результате вы должны получить следующее:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Повторно включите обработчик парсера форм:
enable_processor(processor)
print_processors()
В результате вы должны получить следующее:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Далее рассмотрим, как управлять версиями процессора.
9. Управление версиями процессора
Процессоры могут быть доступны в нескольких версиях. Узнайте, как использовать методы list_processor_versions и set_default_processor_version .
Добавьте следующие функции:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Перечислите доступные версии процессора OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Вы получаете версии процессоров:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Теперь добавим функцию для изменения версии процессора по умолчанию:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Переключитесь на последнюю версию процессора:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Вы получаете конфигурацию новой версии:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
И далее, самый совершенный метод управления процессором (удаление).
10. Удаление процессоров
Наконец, ознакомьтесь с тем, как использовать метод delete_processor .
Добавьте следующую функцию:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Удалите ваши обработчики тестов:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
В результате вы должны получить следующее:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Вы рассмотрели все методы управления процессором! Вы почти закончили...
11. Поздравляем!
Вы научились управлять обработчиками Document AI с помощью Python!
Уборка
Для очистки среды разработки используйте Cloud Shell:
- Если вы всё ещё находитесь в сессии IPython, вернитесь в командную оболочку:
exit - Прекратите использование виртуальной среды Python:
deactivate - Удалите папку виртуального окружения:
cd ~ ; rm -rf ./venv-docai
Чтобы удалить свой проект Google Cloud, используйте Cloud Shell:
- Получите текущий идентификатор проекта:
PROJECT_ID=$(gcloud config get-value core/project) - Убедитесь, что это именно тот проект, который вы хотите удалить:
echo $PROJECT_ID - Удалите проект:
gcloud projects delete $PROJECT_ID
Узнать больше
- Попробуйте Document AI в своем браузере: https://cloud.google.com/document-ai/docs/drag-and-drop
- Подробная информация об обработчике Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python в Google Cloud: https://cloud.google.com/python
- Клиентские библиотеки для облачных сервисов на Python: https://github.com/googleapis/google-cloud-python
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.