
此 Codelab 设想了一个可能的企业工作流程:图片存档、分析和报告生成。想象一下,您的组织有一系列图片占用了有限资源上的空间。您想要存档该数据,分析那些图片,最重要的是生成一份报告以汇总存档位置和分析结果,供管理人员整理并准备使用。为此,Google Cloud 提供了 G Suite 和 Google Cloud Platform (GCP) 两个产品线 API,可帮助您实现这一目标。
在我们的场景中,企业用户将在 Google 云端硬盘上存储图片。最好将这些备份到“更冷”的便宜存储中,例如 Google Cloud Storage 提供的存储类别。Google Cloud Vision 可让开发者轻松在应用内集成视觉检测功能,包括物体和地标检测、光学字符识别 (OCR) 等。最后,还有(Google 表格)电子表格是一种实用的可视化工具,可为您的老板总结所有这些信息。
完成本 Codelab 以构建利用 Google Cloud 的所有解决方案之后,我们希望您会受到启发,为您的组织或客户构建更具影响力的内容。
您将学习的内容
- 如何使用 Cloud Shell
- 如何对 API 请求进行身份验证
- 如何安装 Python 版 Google API 客户端库
- 如何启用 Google API
- 如何从 Google 云端硬盘下载文件
- 如何将对象/blob 上传到 Cloud Storage
- 如何使用 Cloud Vision 分析数据
- 如何将行写入 Google 表格
所需条件
- Google 帐号(G Suite 帐号可能需要管理员批准)
- 具有有效 GCP 结算帐号的 Google Cloud Platform 项目
- 熟悉操作系统终端/shell 命令
- 基本掌握 Python(2 或 3)课程,您可以使用任何支持的语言
熟悉上述四种 Google Cloud 产品很有帮助,但不是必需的。如果时间允许您首先分别熟悉它们,则欢迎在进行此练习之前为每个对象编写 Codelab:
- Google 云端硬盘(使用 G Suite API)简介 (Python)
- 将 Cloud Vision 与 Python 搭配使用 (Python)
- 使用 Sheets API 构建自定义报告工具 (JS/Node)
- 将对象上传到 Google Cloud Storage(无需编码)
调查问卷
您打算如何使用本教程?
您如何评价使用 Python 的体验?
您如何评价使用 Google Cloud Platform 服务的体验?
您如何评价使用 G Suite 开发者服务的体验?
与产品功能介绍的 Codelab 相比,您想看到更多的“面向企业”的 Codelab 吗?
自定进度的环境设置
- 登录 Cloud Console,然后创建一个新项目或重复使用现有项目。(如果您还没有 Gmail 或 G Suite 帐号,则必须创建一个。)



请记好项目 ID,这是所有 Google Cloud 项目中的唯一名称(上面的名称已被使用,对您不起作用,对不起!)。此 Codelab 稍后将在 PROJECT_ID 中引用它。
- 接下来,您需要在 Cloud Console 中启用结算功能才能使用 Google Cloud 资源。
运行此 Codelab 不会产生任何费用(如果有)。请务必按照“清理”部分中的说明操作,其中介绍了如何关停资源,这样您就不会在本教程之外产生费用。Google Cloud 的新用户均有资格申请 $300 美元免费试用计划。
启动 Cloud Shell
摘要
虽然您可以在笔记本电脑上本地开发代码,但此 Codelab 的第二个目标是教您如何使用 Google Cloud Shell,这是一种通过现代网络浏览器在云中运行的命令行环境。
激活 Cloud Shell
- 在 Cloud Console 中,点击激活 Cloud Shell
。

如果您以前从未启动过 Cloud Shell,将看到一个中间屏幕(在折叠下面),描述它是什么。如果是这种情况,请点击继续(您将永远不会再看到它)。一次性屏幕如下所示:

预配和连接到 Cloud Shell 只需花几分钟时间。

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。只需使用一个浏览器或 Google Chromebook 即可完成本 Codelab 中的大部分(甚至全部)工作。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的项目 ID:
- 在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
此 Codelab 要求您使用 Python 语言(虽然 Google API 客户端库支持许多语言,但您可以随意使用自己喜欢的开发工具构建等效内容,并使用 Python 作为伪代码)。具体地讲,此 Codelab 支持 Python 2 和 3,但建议尽快迁移到 3.x。
Cloud Shell 为用户可从 Cloud Console 直接提供,不需要本地开发环境,因此本教程需要使用网络浏览器。如果您正在开发或打算使用 GCP 产品和 API 进行开发,则 Cloud Shell 特别有用。对于此 Codelab,更具体地说,Cloud Shell 已经预安装了两个版本的 Python。
Cloud Shell 还安装了 IPython...它是更高级别的交互式 Python 解释器,建议在您参与数据科学或机器学习社区时。如果您启用 IPython,则 Jupyter 是 Jupyter Notebooks 的默认解析器,以及由 Google Research 托管的 Jupyter 笔记本 Colab。
IPython 更喜欢 Python 3 解释器,但如果 3.x 不可用,则回退到 Python 2。可以从 Cloud Shell 访问 IPython,也可以安装在本地开发环境中。退出 ^D (Ctrl-d) 并接受要退出的提议。启动 ipython 的输出示例如下所示:
$ ipython Python 3.7.3 (default, Mar 4 2020, 23:11:43) Type 'copyright', 'credits' or 'license' for more information IPython 7.13.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
如果不喜欢 IPython,则使用标准 Python 交互式解释器(Cloud Shell 或您的本地开发环境)是完全可以接受的(同时使用 ^D 退出):
$ python Python 2.7.13 (default, Sep 26 2018, 18:42:22) [GCC 6.3.0 20170516] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> $ python3 Python 3.7.3 (default, Mar 10 2020, 02:33:39) [GCC 6.3.0 20170516] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
Codelab 还假定您拥有 pip 安装工具(Python 软件包管理器和依赖项解析器)。它捆绑了 2.7.9 及更高版本或 3.4 及更高版本。如果您安装的是旧版 Python,请参阅此指南,了解安装说明。根据您的权限,您可能需要拥有 sudo 或超级用户访问权限,但通常并非如此。您还可以明确使用 pip2 或 pip3 针对特定 Python 版本执行 pip。
此 Codelab 的其余内容假定您使用的是 Python 3。如果 Python 2 的说明与 3.x 之间的差异很大,则会为 Python 2 提供具体说明。
*创建和使用虚拟环境
本部分是可选部分,仅当为本 Codelab 使用虚拟环境的用户才需要使用(根据上述警告边栏)。如果您的计算机上只有 Python 3,则只需发出此命令即可创建一个名为 my_env 的 virtualenv(您可以根据需要选择其他名称):
virtualenv my_env
不过,如果您的计算机上同时安装了 Python 2 和 Python 3,我们建议您安装 Python 3 virtualenv,借助 -p flag 来执行此操作:
virtualenv -p python3 my_env
通过“激活”新创建的 virtualenv,如下所示:
source my_env/bin/activate
通过观察 shell 提示符在环境名称前面加上
(my_env) $
现在,您应该能够 pip install 任何必需软件包,执行此实施中的代码等。另一个好处是,如果完全搞砸了,请进入 Python 安装中断的情况,然后您可以移除整个环境而不影响系统的其余部分。
此 Codelab 需要使用 Python 版 Google API 客户端库,因此这是一个简单的安装过程,或者您可能什么都不做。
较早之前,我们建议您考虑使用 Cloud Shell 以便于使用。您可以通过云端网络浏览器完成整个教程。使用 Cloud Shell 的另一个原因是,已预安装的许多热门开发工具和必要库。
*安装客户端库
(可选)如果您使用的是 Cloud Shell 或已安装客户端库的本地环境,则可以跳过这一步。只有在本地开发并且尚未安装(或不确定)已经开发的情况下,才需要执行此操作。最简单的方法是使用 pip(或 pip3)进行安装(包括根据需要更新 pip):
pip install -U pip google-api-python-client oauth2client
确认安装
此命令会安装客户端库及其依赖的任何软件包。无论是使用 Cloud Shell 还是您自己的环境,都通过导入必要的软件包来验证客户端库是否已安装,并确保不存在导入错误(或输出):
python3 -c "import googleapiclient, httplib2, oauth2client"
如果您改为使用 Python 2(来自 Cloud Shell),则会收到一条警告,表明其支持已被弃用:
******************************************************************************* Python 2 is deprecated. Upgrade to Python 3 as soon as possible. See https://cloud.google.com/python/docs/python2-sunset To suppress this warning, create an empty ~/.cloudshell/no-python-warning file. The command will automatically proceed in seconds or on any key. *******************************************************************************
成功运行该导入“test”命令(无错误/输出)后,您就可以开始与 Google API 通信了!
摘要
由于这是一个中间 Codelab,因此假设您已经拥有在控制台中创建和使用项目的经验。如果您刚接触 Google API 和 G Suite API,请先试用 G Suite API 入门 Codelab。此外,如果您知道如何创建(或重用现有)用户帐号(而非服务帐号)凭据,请将 client_secret.json 文件拖放到工作目录中,跳过下一个模块,然后跳至“启用 Google API”。
如果您已创建用户帐号授权凭据并熟悉此过程,可以跳过此部分。它与服务帐号授权不同,后者的技术有所不同,请在下方继续操作。
授权简介(以及部分身份验证)
为了向 API 发出请求,您的应用需要具有适当的授权。身份验证是一个类似的词,它描述了登录凭据,即您在使用登录名和密码登录 Google 帐号时进行身份验证。一旦通过身份验证,下一步就是授权您(或者更确切地说是您的代码)访问数据,例如 Cloud Storage 上的 Blob 文件或 Google 云端硬盘上的用户个人文件。
Google API 支持多种类型的授权,但 G Suite API 用户最常见的一种是用户授权,因为此 Codelab 中的示例应用会访问属于最终用户的数据。这些最终用户必须允许访问您的应用才能访问其数据。这意味着您的代码必须获取用户帐号 OAuth2 凭据。
如需获取用户授权的 OAuth2 凭据,请返回 API 管理器,然后选择左侧导航栏上的“凭据”标签页:
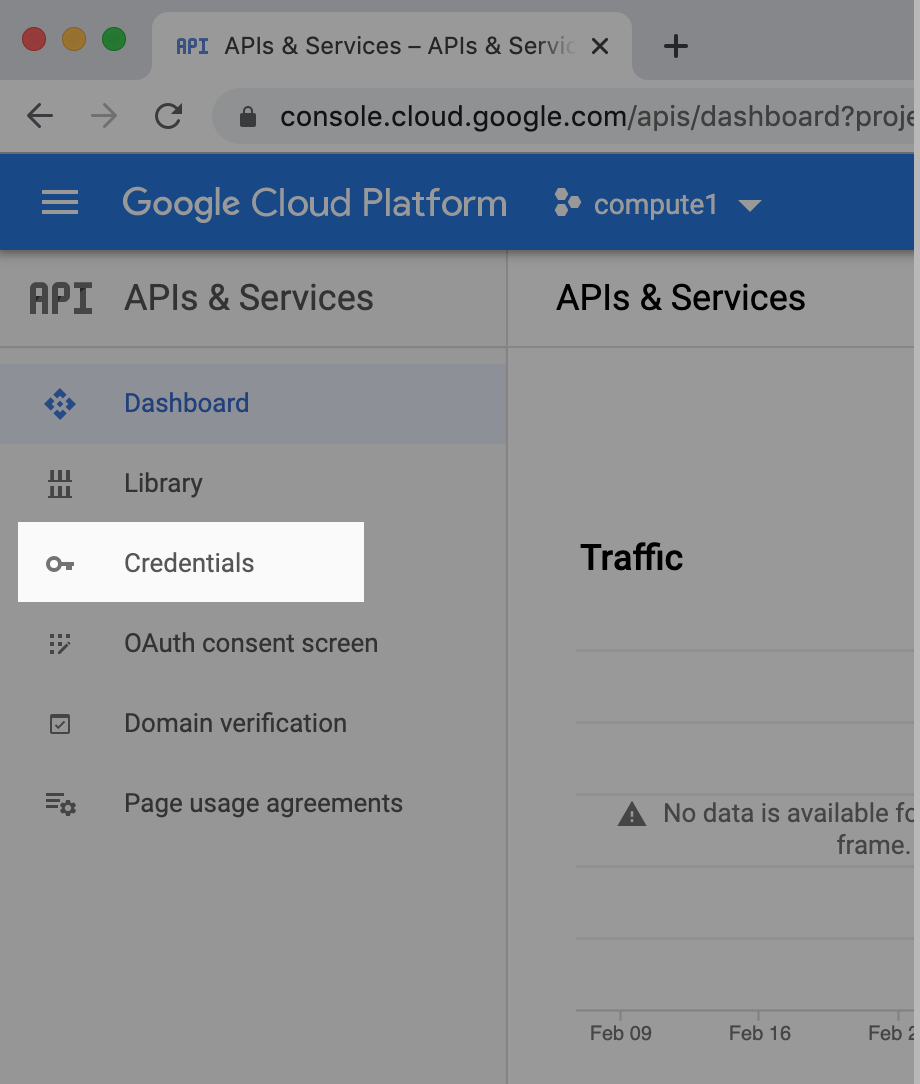
访问该页面后,您会在以下三个部分看到您的所有凭据:
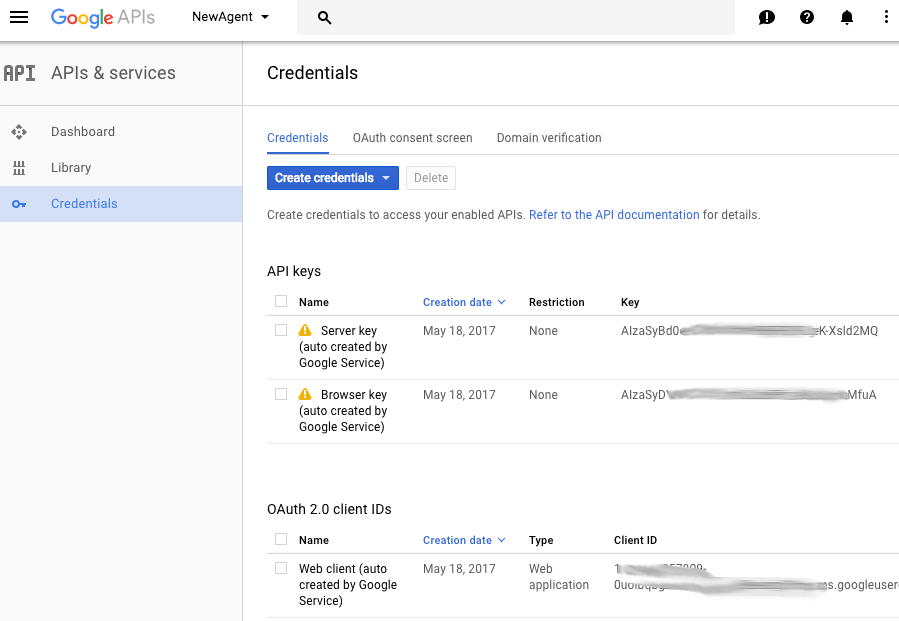
第一个用于 API 密钥,第二个是 OAuth 2.0 客户端 ID,最后一个是 OAuth2 服务帐号:我们使用的是第二个。
创建凭据
在“凭据”页面中,点击顶部的 + 创建凭据按钮,然后您会看到一个对话框,您可以在其中选择“OAuth 客户端 ID”:

在下一个屏幕上,您可以执行以下两项操作:配置应用的授权“同意屏幕”并选择应用类型:

如果您尚未设置同意屏幕,会在控制台中看到警告,但需要立即进行设置。(如果您的同意屏幕已设置完毕,请跳过以下后续步骤)。
OAuth 同意屏幕
点击“配置同意屏幕”,选择“外部”应用(如果您是 G Suite 客户,请点击“内部”):
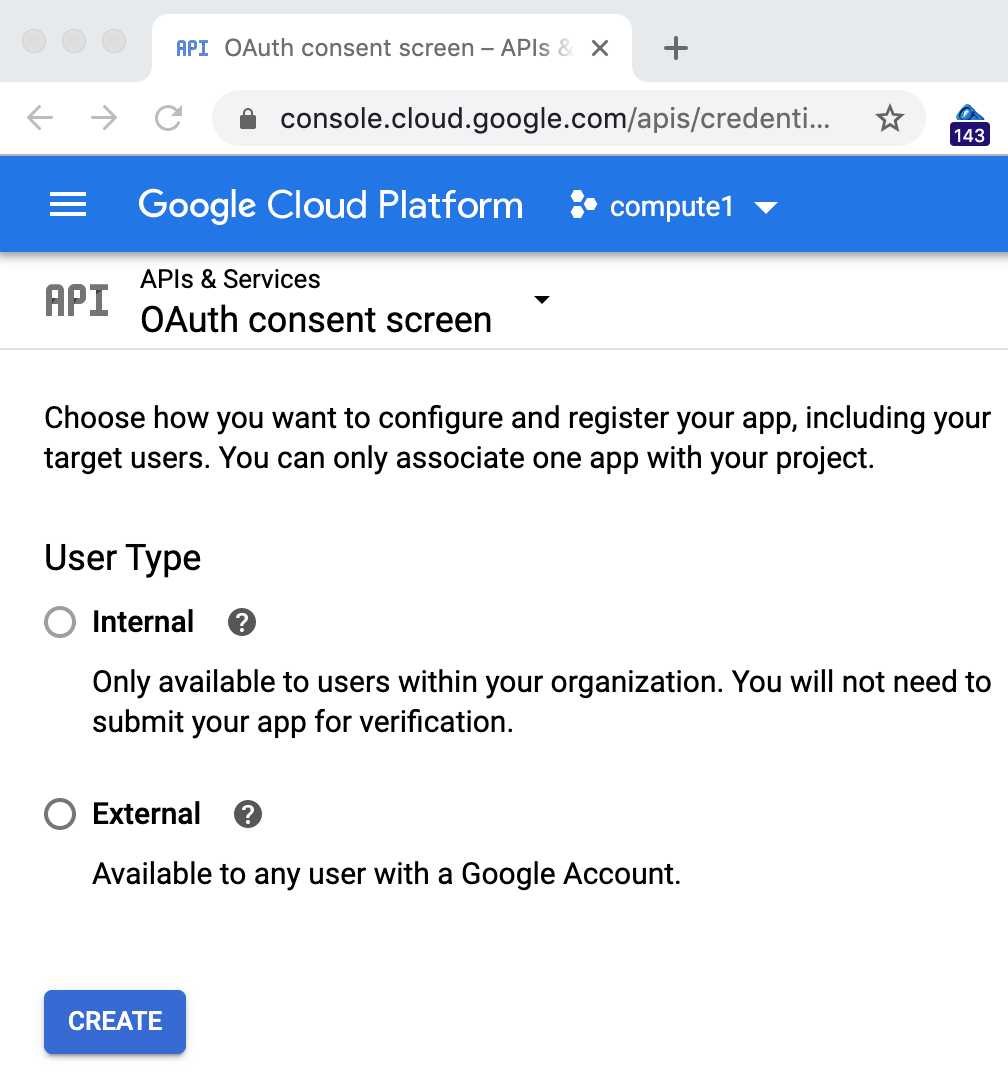
请注意,在本练习中,无论您选择不发布 Codelab 示例,哪个选择都无关紧要。大多数人会选择“外部”转到较复杂的屏幕,但是您只需填写顶部的“应用名称”字段:
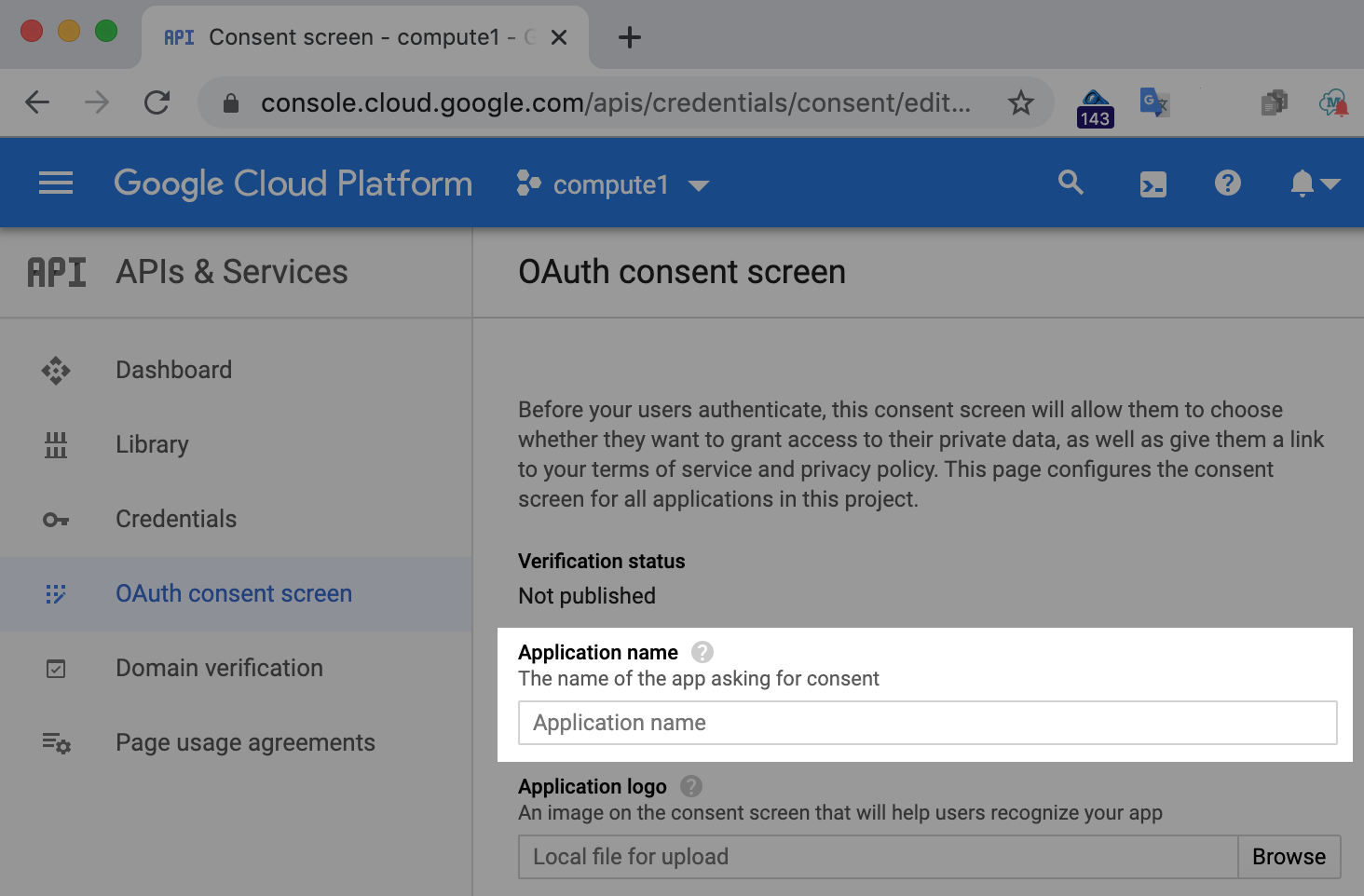
目前,您需要执行的唯一操作只是一个应用名称,因此,请选择能反映您正在执行的 Codelab 的人,然后点击保存。
创建 OAuth 客户端 ID(用户帐号身份验证)
现在,返回到“凭据”标签页以创建 OAuth2 客户端 ID。下面显示了您可以创建的各种 OAuth 客户端 ID:
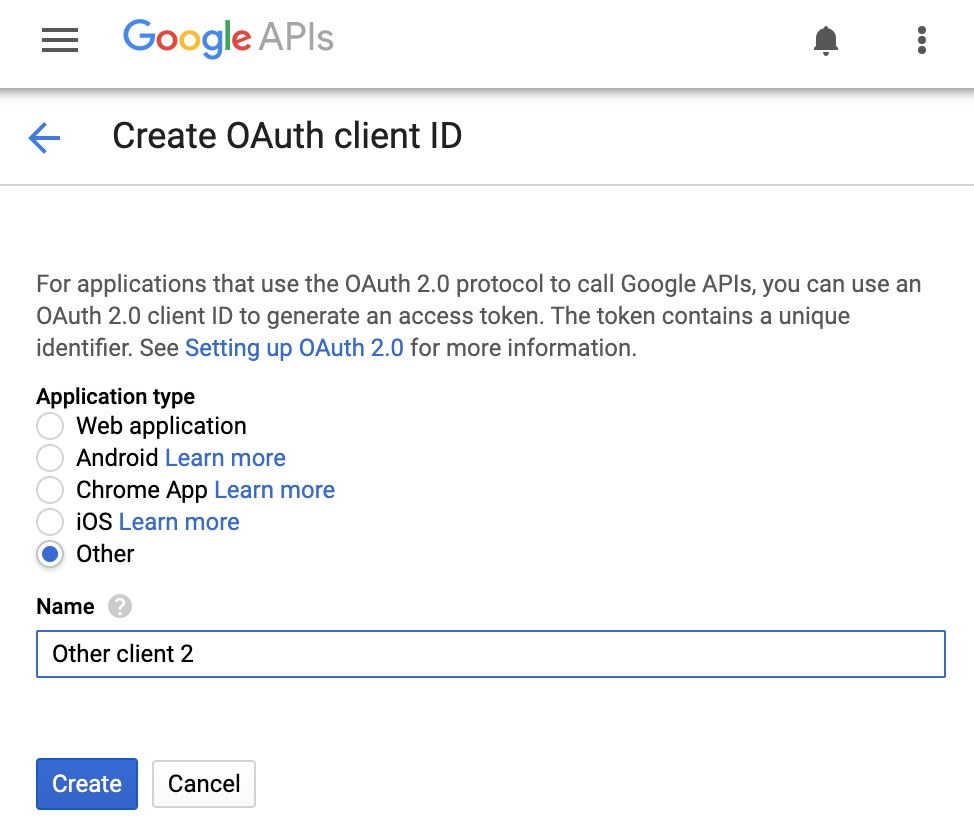
我们正在开发命令行工具(即其他),因此请选择该版本,然后点击创建按钮。选择一个客户端 ID,该 ID 用于反映您正在创建的应用,或者直接使用默认名称(通常为“其他客户端 N”)。
保存您的凭据
- 此时会显示一个包含新凭据的对话框;点击确定以关闭

- 返回“凭据”页面,向下滚动到“OAuth2 客户端 ID”部分,然后点击新创建的客户端 ID 最右侧的下载图标
。
- 此操作将打开一个对话框,让您保存名为
client_secret-LONG-HASH-STRING.apps.googleusercontent.com.json的文件,这个文件夹很可能保存在您的下载文件夹中。我们建议将其简化为一个更简单的名称,例如client_secret.json(示例应用使用的名称),然后将其保存到您将在此 Codelab 中创建示例应用的目录/文件夹。

摘要
现在,您准备启用此 Codelab 中使用的 Google API。另外,对于 OAuth 同意屏幕中的应用名称,我们选择了“Vision API 演示”,因此在某些即将推出的屏幕截图中,您会看到这一点。
简介
此 Codelab 使用四 (4) 个 Google Cloud API,一对来自 GCP(Cloud Storage 和 Cloud Vision),另一对来自 G Suite(Google 云端硬盘和 Google 表格)。以下是如何仅启用 Vision API 的说明。知道如何启用一个 API 后,您必须自行启用其他 3 个 API。
您必须先启用它们,然后才能开始使用 Google API。以下示例显示了如何启用 Cloud Vision API。在此 Codelab 中,您可能正在使用一个或多个 API,并且应该按照类似的步骤来启用它们。
通过 Cloud Shell
使用 Cloud Shell,您可以使用以下命令启用 API:
gcloud services enable vision.googleapis.com
通过 Cloud Console
您还可以在 API 管理器中启用 Vision API。在 Cloud Console 中,转到 API 管理器,然后选择“库”。

在搜索栏中,开始输入“视觉”,然后在显示 Vision API 时选择它。您在输入时内容可能如下所示:

选择 Cloud Vision API 获取下方显示的对话框,然后点击“启用”按钮:

费用
虽然许多 Google API 可免费使用,但 GCP(产品和 API)不是免费的。启用 Vision API(如上所述)时,系统可能会要求您提供有效的结算帐号。在启用之前,用户应引用 Vision API 的价格信息。请注意,某些 Google Cloud Platform (GCP) 产品有一个“始终免费”层级,您需要超出该层级来产生费用。在 Codelab 中,对 Vision API 的每次调用都会计入该免费层级,并且只要您不超出其聚合次数(每个月),就不会产生费用。
某些 Google API,即 G Suite 的月度订阅方案可能适用,因此,您使用 Gmail、Google 云端硬盘、Google 日历、Google 文档、表格和幻灯片时并没有直接结算。Google 产品的计费方式不同,因此请务必参阅 API 的文档以了解相关信息。
摘要
现在,Cloud Vision 已启用,您可以通过同样的方式在 Cloud Shell、使用 gcloud services enable 或 Cloud Console 中启用另外三个 API(Google 云端硬盘、Cloud Storage、Google 表格):
- 返回 API 库
- 输入几个字母即可搜索所需内容
- 选择所需的 API,然后
- 启用
泡沫、冲洗并重复。Cloud Storage 有多种选择:选择“Google Cloud Storage JSON API”。Cloud Storage API 也预计会有一个活跃的结算帐号。
这是中型代码的开始,我们希望采取一些敏捷的做法,并确保配备通用、稳定且稳定的基础架构,然后再处理主应用。请仔细检查 client_secret.json 在当前目录中是否可用,然后启动 ipython 并输入以下代码段,或将其保存到 analyze_gsimg.py 并从 shell 运行它(首选,因为我们会继续处理添加到代码示例):
from __future__ import print_function
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
# process credentials for OAuth2 tokens
SCOPES = 'https://www.googleapis.com/auth/drive.readonly'
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
此核心组件包括模块/软件包导入、处理用户身份验证凭据和创建 API 服务端点的代码块。您应该查看的代码的关键部分:
- 导入
print()函数可使此示例 Python 2-3 兼容,并且 Google 库导入功能引入了与 Google API 通信所需的所有工具。 SCOPES变量表示向用户请求的权限 - 目前只有一项权限:拥有从其 Google 云端硬盘读取数据的权限- 其余的凭据处理代码会在缓存的 OAuth2 令牌中读取,在原始访问令牌过期时可能会更新为具有刷新令牌的新访问令牌。
- 如果未出于任何原因而创建令牌或检索有效的访问令牌失败,用户必须完成 OAuth2 三足式流程 (3LO):使用所请求的权限创建对话框并提示用户接受。一旦超出此范围,应用将继续运行,否则
tools.run_flow()会抛出异常,并在执行时停止。 - 用户授予权限后,将创建一个 HTTP 客户端以与服务器通信,而所有请求均会使用用户的凭据进行签名。然后,系统会使用该 HTTP 客户端创建 Google Drive API(版本 3)的服务端点,然后将其分配给
DRIVE。
运行应用
在您第一次执行脚本时,该脚本无权访问云端硬盘中的文件(您自己的文件)。输出看起来像这样,执行已暂停:
$ python3 ./analyze_gsimg.py
/usr/local/lib/python3.6/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Your browser has been opened to visit:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=http%3A%2F%2Flocalhost%3A8080%2F&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
If your browser is on a different machine then exit and re-run this
application with the command-line parameter
--noauth_local_webserver
如果您是从 Cloud Shell 运行,请跳至“通过 Cloud Shell”部分,然后根据需要向下滚动查看“通过本地开发环境”中的相关屏幕。
通过本地开发环境
命令行脚本会在浏览器窗口打开时暂停。您可能会看到类似下面所示的恐怖警告页面:

这是一个合理的问题,因为您正在尝试运行访问用户数据的应用。由于这只是演示版应用,如果您是开发者,因此希望您对自己足够信任,可以继续进行下去。为了更清楚地理解此问题,请设身处地为用户着想:比如,系统要求他人代码访问您的数据。如果您打算发布此类应用,则需要完成验证流程,这样您的用户就不会看到此屏幕。
点击“转到‘不安全’应用”链接后,您将获得如下所示的 OAuth2 权限对话框 - 我们始终改进了界面,因此,如果它不完全匹配,请不要担心:

OAuth2 流程对话框反映了开发者请求的权限(通过 SCOPES 变量)。在这种情况下,用户能够通过 Google 云端硬盘进行查看和下载。在应用代码中,这些权限范围显示为 URI,但它们被转换为用户语言区域指定的语言。在这种情况下,用户必须为请求的权限提供显式授权,否则将抛出异常,以使脚本不再继续。
您甚至可以获取另外一个对话框要求您确认:

注意:有些使用多个网络浏览器登录到不同的帐号,因此此授权请求可能会转到错误的浏览器标签页/窗口,并且您可能必须将此请求的链接剪切并粘贴到使用正确登录名的浏览器中帐号。
通过 Cloud Shell
Cloud Shell 不会弹出浏览器窗口,让您停下。确认底部的诊断消息是为您准备的...这一个:
If your browser is on a different machine then exit and re-run this application with the command-line parameter --noauth_local_webserver
您必须按 ^C(Ctrl-C 或其他按键)来停止脚本执行,然后通过带有额外标志的 shell 运行该命令。以这种方式运行此命令时,您将获得以下输出:
$ python3 analyze_gsimg.py --noauth_local_webserver
/usr/local/lib/python3.7/site-packages/oauth2client/_helpers.py:255: UserWarning: Cannot access storage.json: No such file or directory
warnings.warn(_MISSING_FILE_MESSAGE.format(filename))
Go to the following link in your browser:
https://accounts.google.com/o/oauth2/auth?client_id=LONG-STRING.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.readonly&access_type=offline&response_type=code
Enter verification code:
(忽略该警告,因为我们知道 storage.json 还没有创建警告,并且)按照该网址在另一个浏览器标签页中的说明进行操作,您将获得与上述本地开发环境几乎相同的体验(请参阅上面的屏幕截图)。最后是一个最终屏幕,其中包含要在 Cloud Shell 中输入的验证码:

将此代码复制并粘贴到终端窗口中。
摘要
除“Authentication successful”外,预计不会有任何其他输出。回想一下,这只是设置部分,您尚未进行任何设置。您的操作已经成功着手,因而更有可能首次成功执行。(最出色的部分是,系统仅提示一次授权;所有连续的执行步骤都会跳过,因为您的权限已缓存。)现在,让代码做一些实际的工作,以产生实际的输出。
问题排查
如果您收到错误而不是没有输出,则可能是由于一个或多个原因造成的,原因可能如下:
在上一步中,我们建议将代码创建为 analyze_gsimg.py 并从中进行修改。也可以简单地将所有内容直接粘贴到 iPython 或标准 Python shell 中,但随着我们继续构建一个应用片段,这会有些麻烦。
假设您的应用已获得授权且已创建 API 服务端点。在您的代码中,以 DRIVE 变量表示。现在,在 Google 云端硬盘中找到一个图片文件,
将其设置为名为 NAME 的变量。在第 0 步的代码下方输入以下 drive_get_img() 函数:
FILE = 'YOUR_IMG_ON_DRIVE' # fill-in with name of your Drive file
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
云端硬盘 files() 集合具有 list() 方法,用于为指定的文件执行查询(q 参数)。fields 参数用来指定您感兴趣的值。如果您不关心其他值,为什么还要花钱找回一切并放慢速度呢?如果您刚开始接触过滤 API 返回值的字段掩码,请参阅这篇博文和视频。否则,执行查询并提取返回的 files 属性,如果没有匹配项,则默认为空列表数组。
如果没有结果,则跳过其余函数,并返回 None(隐式)。否则,获取第一个匹配的响应 (rsp[0]),返回文件名、其 MIME 类型、最后的修改时间戳记,最后返回其二进制有效载荷,该载荷也由 get_media() 函数(通过其文件 ID)在 files() 集合中检索到。(与其他语言客户端库相比,方法名称可能会略有不同。)
最后一部分是驱动整个应用的“主体”:
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
else:
print('ERROR: Cannot download %r from Drive' % fname)
在云端硬盘中,系统会将名为 section-work-card-img_2x.jpg 的图片设置为 FILE,并将其成功执行,您应该会看到输出,确认该图片能够从云端硬盘中读取文件(但不保存到您的计算机):
$ python3 analyze_gsimg.py Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
问题排查
如果没有获得上述成功的输出,则可能是由于一种或多种原因造成的,原因可能如下:
摘要
在本部分中,您了解了(在两次不同的 API 调用中)如何连接特定文件的 Drive API 查询,然后下载该文件。业务用例:归档您的云端硬盘数据并可能对其进行分析(例如使用 GCP 工具)。此阶段的应用代码应与代码库中的 step1-drive/analyze_gsimg.py 中的代码一致。
要详细了解如何下载 Google 云端硬盘上的文件,请点击此处或参阅这篇博文和视频。该 Codelab 的这一部分与 G Suite API Codelab 的整个简介几乎相同,它无需下载文件,而是在用户的 Google 云端硬盘上显示前 100 个文件/文件夹,并使用了更严格的范围。
下一步是添加对 Google Cloud Storage 的支持。为此,我们需要导入另一个 Python 软件包 io。确保导入部分的顶部与下面这样类似:
from __future__ import print_function
import io
除了云端硬盘文件名之外,我们还需要关于在 Cloud Storage 上存储此文件的位置的一些信息,具体包括您将该文件放在的“存储分区”的名称以及任何“父文件夹”前缀。我们下面会对此进行详细介绍:
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
存储分区一瞥...Cloud Storage 提供变形的 Blob 存储。在上传文件时,文件无法理解文件类型、扩展名等概念,这与 Google 云端硬盘的作用相同。它们只是 Cloud Storage 中的“blob”。此外,Cloud Storage 中不存在文件夹或子目录的概念。
可以,文件名中可以包含斜杠 (/) 来表示多个子文件夹的抽象,但当天,所有 blob 都进入一个存储分区,“/”只是字符的文件名。如需了解详情,请参阅存储分区和对象命名页面。
上文中的第 1 步请求云端硬盘的只读范围。到目前为止,这就是您所需要的。现在,需要具有 Cloud Storage 的上传(读写)权限。将 SCOPES 从单个字符串变量更改为权限范围的数组(Python 元组 [或列表]),如下所示:
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
)
现在,在云端硬盘的服务存储下方创建一个到 Cloud Storage 的服务端点。请注意,我们稍微更改了调用以重复使用相同的 HTTP 客户端对象,因为当它可以成为共享资源时,不需要创建新的 HTTP 客户端对象。
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
现在请添加此函数(在 drive_get_img() 之后),再上传到 Cloud Storage:
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
objects.().insert() 调用需要存储分区名称、文件元数据和二进制 blob 本身。要过滤返回值,fields 变量仅请求从 API 返回的存储分区和对象名称。如需详细了解用于 API 读取请求的字段掩码,请参阅这篇博文和视频。
现在,将 gcs_blob_upload() 的使用集成到主应用中:
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
gcsname 变量会合并附加到文件名本身的所有“父子目录”名称,并在加上存储分区名称时加上“/bucket/parent.../filename”来归档您要归档的文件。在 else 子句上方的第一个 print() 函数之后立即滑动此块,以便使整个“main”看起来像这样:
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
假设我们创建了一个名为“vision-demo”的存储分区,并以“analyzed_imgs”作为父级子目录。设置这些变量并重新运行脚本后,系统会从云端硬盘下载 section-work-card-img_2x.jpg,然后再上传到 Cloud Storage。 不是!
$ python3 analyze_gsimg.py
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Traceback (most recent call last):
File "analyze_gsimg.py", line 85, in <module>
io.BytesIO(data), mimetype=mtype), mtype)
File "analyze_gsimg.py", line 72, in gcs_blob_upload
media_body=media, fields='bucket,name').execute()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/_helpers.py", line 134, in positional_wrapper
return wrapped(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/googleapiclient/http.py", line 898, in execute
raise HttpError(resp, content, uri=self.uri)
googleapiclient.errors.HttpError: <HttpError 403 when requesting https://storage.googleapis.com/upload/storage/v1/b/PROJECT_ID/o?fields=bucket%2Cname&alt=json&uploadType=multipart returned "Insufficient Permission">
仔细查看,虽然驱动器下载成功,但是上传到 Cloud Storage 失败。为什么?
这是因为当我们最初为步骤 1 授权此应用时,我们仅授权了对 Google 云端硬盘的只读访问权限。在添加 Cloud Storage 的读写范围时,我们从未提示用户授权该访问。为了使其正常工作,我们需要删除缺少此范围的 storage.json 文件,然后重新运行。
重新授权后(通过在 storage.json 内部查看并在其中看到两个范围进行确认),输出将如预期的那样:
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
摘要
这很重要,用相对较少的代码行向您展示了如何在两个基于云的存储系统之间传输文件。这里的业务用例是将可能受约束的资源备份到“更冷”的存储中,如前所述。Cloud Storage 提供不同的存储类别,具体取决于您是定期、每月、每季度还是每年访问数据。
当然,开发者常常会问我们 Google 云端硬盘和 Cloud Storage 的存在... 毕竟,它们不是都存储在云中吗?这就是我们制作此视频的原因。此阶段的代码应与 step2-gcs/analyze_gsimg.py 存储库中的代码匹配。
虽然我们知道您已经可以在 GCP 和 G Suite 之间移动数据,但尚未完成任何分析,因此请将图片发送到 Cloud Vision 以进行标签注释(也称为对象检测)。为此,我们需要对数据进行 Base64 编码,即另一个 Python 模块 base64。确保您的热门导入部分现在如下所示:
from __future__ import print_function
import base64
import io
默认情况下,Vision API 会返回找到的所有标签。为了保持一致性,我们仅请求前 5 位(当然这可以由用户调整)。为此,我们将使用常量变量 TOP;将其添加到所有其他常量下:
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
TOP = 5 # TOP # of VISION LABELS TO SAVE
与前面的步骤一样,我们需要另一个权限范围,这次是 Vision API。使用其字符串更新 SCOPES:
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
)
现在,创建到 Cloud Vision 的服务端点,使其与如下所示的其他服务对齐:
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
现在,添加此函数以将图片载荷发送到 Cloud Vision:
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
images().annotate() 调用需要数据以及所需的 API 功能。前 5 个标签上限也是载荷的一部分(但完全可选)。如果调用成功,载荷将返回对象的前 5 个标签以及对象在图片中的置信度分数。(如果未返回任何响应,请分配一个空 Python 字典,以免以下 if 语句失败。) 此函数简单地将这些数据整理为 CSV 字符串,以供最终在报告中使用。
在成功上传到 Cloud Storage 后,应立即调用以下 5 行调用 vision_label_img() 的行:
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
添加后,整个主驱动程序应如下所示:
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), TOP)
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
删除 storage.json 以刷新范围并重新运行更新的应用应该产生类似于以下内容的输出,并添加了 Cloud Vision 分析:
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
摘要
并非每个人都具备机器学习专业知识,能够构建并训练自己的机器学习模型来分析数据。Google Cloud 团队已经将 Google 的一些预训练模型用于一般用途,并将其放在 API 后面,从而帮助所有人普及 AI 和机器学习。
如果您是开发者并可以调用 API,则可以使用机器学习。Cloud Vision 只是可用于分析数据的一项 API 服务之一。点击此处了解其他选项。您的代码现在应与位于 step3-vision/analyze_gsimg.py 的代码库中的代码进行匹配。
您现在能够归档公司数据并进行分析,但缺少该资料的摘要。让我们将所有结果整理到一个报告中,然后交给老板。与电子表格相比,管理方面不够用?
无需对 Google Sheets API 进行其他导入,并且唯一需要的新信息是现有电子表格的文件 ID,正在等待新的数据行,因此为 SHEET 常量。我们建议您创建与下图类似的新电子表格:

该电子表格的网址将如下所示:https://docs.google.com/spreadsheets/d/FILE_ID/edit。获取 FILE_ID 并将其作为字符串分配给 SHEET。
我们还在一个名为 k_ize() 的小型函数中进行写入操作,该函数将字节转换为千字节,将其定义为 Python lambda,因为它是简单的单行线。这两项功能与其他常量集成均如下所示:
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
和前面的步骤一样,我们需要另一个权限范围,这次是 Sheets API 的读写权限。SCOPES 现在包含所有 4 种需求:
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
现在,在其他位置创建 Google 表格的服务端点,如下所示:
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
sheet_append_row() 的功能非常简单:获取一行数据和一个工作表 ID,然后将该行添加到该工作表中:
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
spreadsheets().values().append() 调用需要 Google 表格的文件 ID、一系列单元格、数据输入方式以及数据本身。文件 ID 非常简单,单元格范围以 A1 表示法表示。“Sheet1”的范围表示整个工作表 - 向 API 发出信号,以附加工作表中所有数据之后。我们有一对数据应如何添加到 Google 表格中、“RAW”(输入字符串数据动词)或“USER_ENTERED”(写入数据就好像用户使用 Google 表格应用在键盘中输入数据一样,但请保留所有单元格格式设置功能)。
如果调用成功,则返回值实际上没有任何超级有用的功能,因此我们选择通过 API 请求获取更新的单元格数量。下面是调用该函数的代码:
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
Google 表格具有代表数据的列,例如任何父级“子目录”,已归档文件在 Cloud Storage 上的位置(存储区+文件名)、文件的 MIME 类型、文件大小(最初以字节为单位,但已通过 k_ize() 转换为千字节),以及 Cloud Vision 标签字符串。另请注意,存档位置是一个超链接,因此您的经理可以点击以确认它已安全备份。
在显示 Cloud Vision 的结果之后,在代码上方添加代码块,驱动应用的主要部分现已完成,尽管结构上有些复杂:
if __name__ == '__main__':
# download img file & info from Drive
rsp = drive_get_img(FILE)
if rsp:
fname, mtype, ftime, data = rsp
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (PARENT, fname)
rsp = gcs_blob_upload(gcsname, BUCKET, data, mtype)
if rsp:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if rsp:
print('Top %d labels from Vision API: %s' % (TOP, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [PARENT,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
BUCKET, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(SHEET, row)
if rsp:
print('Updated %d cells in Google Sheet' % rsp)
else:
print('ERROR: Cannot write row to Google Sheets')
else:
print('ERROR: Vision API cannot analyze %r' % fname)
else:
print('ERROR: Cannot upload %r to Cloud Storage' % gcsname)
else:
print('ERROR: Cannot download %r from Drive' % fname)
最后删除 storage.json 一个并重新运行更新的应用应该会导致输出类似于以下内容,并注意添加了 Cloud Vision 分析:
$ python3 analyze_gsimg.py
. . .
Authentication successful.
Downloaded 'section-work-card-img_2x.jpg' (image/jpeg, 2020-02-27T09:27:22.095Z, size: 27781)
Uploaded 'analyzed_imgs/section-work-card-img_2x.jpg' to GCS bucket 'vision-demo'
Top 5 labels from Vision API: (89.94%) Sitting, (86.09%) Interior design, (82.08%) Furniture, (81.52%) Table, (80.85%) Room
Updated 6 cells in Google Sheet
额外看一看的输出行虽然有用,但可以通过窥探一下经过修改的 Google 表格来更好地看到,最后一行(以下示例中的第 7 行)添加到了先前添加的现有数据集中:

摘要
在本教程的前 3 个步骤中,您关联了 G Suite 和 GCP API 以移动数据并进行分析,这相当于全部工作的 80%。但归根结底,这些事都无法替代任何您需要的管理层。为了更清楚地呈现结果,在生成的报告中汇总所有结果都会反映流量。
为了进一步增强分析的有效性,除了将结果写入电子表格外,一种可能的增强功能是为每个图像索引这前 5 个标签,以便建立一个内部数据库,允许授权员工通过搜索查询图像团队,但我们将其留给读者练习。
目前,我们的结果在表格中,可供管理人员使用。此阶段的应用代码应与代码库中的 step4-sheets/analyze_gsimg.py 中的代码一致。最后一步是清理代码并将其转换为可用的脚本。
(可选)应用效果良好。需要改进吗?是,主应用似乎杂乱无章。我们将其放入它自己的函数中,并使其支持用户输入,而不是固定常量。我们会在 argparse 模块中完成这一步。此外,在写入数据行后,我们将启动一个网络浏览器标签页以显示工作表。可以通过 webbrowser 模块执行此操作。我们将这些导入文件与其他导入文件一起导入,因此顶部导入如下:
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
为了能够在其他应用中使用此代码,我们需要能够抑制输出,所以我们来添加一个 DEBUG 标记来完成此操作,让我们在顶部附近的常量部分末尾添加这行代码:
DEBUG = False
现在介绍正文内容 在构建此示例时,您应该会开始觉得“不舒服”,因为我们的代码会为添加了每项服务添加另一层嵌套。如果您觉得自己完全不愿意这样做,那就不必这么做,因为正如这篇 Google 测试博文中所述,这样做会增加代码复杂性。
按照此最佳做法,我们将应用的主要部分重新整理到一个函数中,然后在每个“断点”时重新映射 return 而非嵌套(如果任何步骤失败,则返回 None,如果所有成功均返回 True):
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'))
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
它是一个简洁而明晰的后台 if-else 链,并降低了代码复杂性(如上所述)。最后,我们要创建一个“实际”主驱动程序,允许用户自定义,并最大程度减少输出(除非需要):
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
如果所有步骤都成功,则脚本将启动Web浏览器到指定添加新数据行的电子表格。
摘要
没有发生范围更改,因此无需删除 storage.json。重新运行更新的应用后,系统会显示在修改后的工作表中打开新的浏览器窗口,输出的行数更少,并发出 -h 选项以向用户显示其选项,包括 -v(以恢复当前检测到的输出行)之前:
$ python3 analyze_gsimg.py Processing file 'section-work-card-img_2x.jpg'... please wait DONE: opening web browser to it, or see https://docs.google.com/spreadsheets/d/SHEET_ID/edit $ python3 analyze_gsimg.py -h usage: analyze_gsimg.py [-h] [-i] [-t] [-f] [-b] [-s] [-v] optional arguments: -h, --help show this help message and exit -i, --imgfile image file filename -t, --viz_top return top N (default 5) Vision API labels -f, --folder Google Cloud Storage image folder -b, --bucket_id Google Cloud Storage bucket name -s, --sheet_id Google Sheet Drive file ID (44-char str) -v, --verbose verbose display output
其他选项可让用户选择不同的云端硬盘文件名、Cloud Storage“子目录”和存储分区名称、Cloud Vision 中的“N”结果以及电子表格表格 ID。借助这些最新更新,最终版代码现在应与 final/analyze_gsimg.py 处的代码库以及此处的完整版本保持一致:
## Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
'''
analyze_gsimg.py - analyze G Suite image processing workflow
Download image from Google Drive, archive to Google Cloud Storage, send
to Google Cloud Vision for processing, add results row to Google Sheet.
'''
from __future__ import print_function
import argparse
import base64
import io
import webbrowser
from googleapiclient import discovery, http
from httplib2 import Http
from oauth2client import file, client, tools
k_ize = lambda b: '%6.2fK' % (b/1000.) # bytes to kBs
FILE = 'YOUR_IMG_ON_DRIVE'
BUCKET = 'YOUR_BUCKET_NAME'
PARENT = '' # YOUR IMG FILE PREFIX
SHEET = 'YOUR_SHEET_ID'
TOP = 5 # TOP # of VISION LABELS TO SAVE
DEBUG = False
# process credentials for OAuth2 tokens
SCOPES = (
'https://www.googleapis.com/auth/drive.readonly',
'https://www.googleapis.com/auth/devstorage.full_control',
'https://www.googleapis.com/auth/cloud-vision',
'https://www.googleapis.com/auth/spreadsheets',
)
store = file.Storage('storage.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
creds = tools.run_flow(flow, store)
# create API service endpoints
HTTP = creds.authorize(Http())
DRIVE = discovery.build('drive', 'v3', http=HTTP)
GCS = discovery.build('storage', 'v1', http=HTTP)
VISION = discovery.build('vision', 'v1', http=HTTP)
SHEETS = discovery.build('sheets', 'v4', http=HTTP)
def drive_get_img(fname):
'download file from Drive and return file info & binary if found'
# search for file on Google Drive
rsp = DRIVE.files().list(q="name='%s'" % fname,
fields='files(id,name,mimeType,modifiedTime)'
).execute().get('files', [])
# download binary & return file info if found, else return None
if rsp:
target = rsp[0] # use first matching file
fileId = target['id']
fname = target['name']
mtype = target['mimeType']
binary = DRIVE.files().get_media(fileId=fileId).execute()
return fname, mtype, target['modifiedTime'], binary
def gcs_blob_upload(fname, bucket, media, mimetype):
'upload an object to a Google Cloud Storage bucket'
# build blob metadata and upload via GCS API
body = {'name': fname, 'uploadType': 'multipart', 'contentType': mimetype}
return GCS.objects().insert(bucket=bucket, body=body,
media_body=http.MediaIoBaseUpload(io.BytesIO(media), mimetype),
fields='bucket,name').execute()
def vision_label_img(img, top):
'send image to Vision API for label annotation'
# build image metadata and call Vision API to process
body = {'requests': [{
'image': {'content': img},
'features': [{'type': 'LABEL_DETECTION', 'maxResults': top}],
}]}
rsp = VISION.images().annotate(body=body).execute().get('responses', [{}])[0]
# return top labels for image as CSV for Sheet (row)
if 'labelAnnotations' in rsp:
return ', '.join('(%.2f%%) %s' % (
label['score']*100., label['description']) \
for label in rsp['labelAnnotations'])
def sheet_append_row(sheet, row):
'append row to a Google Sheet, return #cells added'
# call Sheets API to write row to Sheet (via its ID)
rsp = SHEETS.spreadsheets().values().append(
spreadsheetId=sheet, range='Sheet1',
valueInputOption='USER_ENTERED', body={'values': [row]}
).execute()
if rsp:
return rsp.get('updates').get('updatedCells')
def main(fname, bucket, sheet_id, folder, top, debug):
'"main()" drives process from image download through report generation'
# download img file & info from Drive
rsp = drive_get_img(fname)
if not rsp:
return
fname, mtype, ftime, data = rsp
if debug:
print('Downloaded %r (%s, %s, size: %d)' % (fname, mtype, ftime, len(data)))
# upload file to GCS
gcsname = '%s/%s'% (folder, fname)
rsp = gcs_blob_upload(gcsname, bucket, data, mtype)
if not rsp:
return
if debug:
print('Uploaded %r to GCS bucket %r' % (rsp['name'], rsp['bucket']))
# process w/Vision
rsp = vision_label_img(base64.b64encode(data).decode('utf-8'), top)
if not rsp:
return
if debug:
print('Top %d labels from Vision API: %s' % (top, rsp))
# push results to Sheet, get cells-saved count
fsize = k_ize(len(data))
row = [folder,
'=HYPERLINK("storage.cloud.google.com/%s/%s", "%s")' % (
bucket, gcsname, fname), mtype, ftime, fsize, rsp
]
rsp = sheet_append_row(sheet_id, row)
if not rsp:
return
if debug:
print('Added %d cells to Google Sheet' % rsp)
return True
if __name__ == '__main__':
# args: [-hv] [-i imgfile] [-b bucket] [-f folder] [-s Sheet ID] [-t top labels]
parser = argparse.ArgumentParser()
parser.add_argument("-i", "--imgfile", action="store_true",
default=FILE, help="image file filename")
parser.add_argument("-b", "--bucket_id", action="store_true",
default=BUCKET, help="Google Cloud Storage bucket name")
parser.add_argument("-f", "--folder", action="store_true",
default=PARENT, help="Google Cloud Storage image folder")
parser.add_argument("-s", "--sheet_id", action="store_true",
default=SHEET, help="Google Sheet Drive file ID (44-char str)")
parser.add_argument("-t", "--viz_top", action="store_true",
default=TOP, help="return top N (default %d) Vision API labels" % TOP)
parser.add_argument("-v", "--verbose", action="store_true",
default=DEBUG, help="verbose display output")
args = parser.parse_args()
print('Processing file %r... please wait' % args.imgfile)
rsp = main(args.imgfile, args.bucket_id,
args.sheet_id, args.folder, args.viz_top, args.verbose)
if rsp:
sheet_url = 'https://docs.google.com/spreadsheets/d/%s/edit' % args.sheet_id
print('DONE: opening web browser to it, or see %s' % sheet_url)
webbrowser.open(sheet_url, new=1, autoraise=True)
else:
print('ERROR: could not process %r' % args.imgfile)
我们会努力使本教程的内容保持最新,但在某些情况下,代码库会有最新的代码。
在此 Codelab 中肯定有很多学习的知识,而您在较长的 Codelab 中幸存下来就实现了这一点。基于此,您可能以大约 130 行 Python 的方式利用了可能发生的企业场景,利用所有 Google Cloud (GCP + G Suite) 数据,在数据间迁移数据,构建有效的解决方案。您可以尽情探索此应用所有版本的开放源代码代码库(详情请见下文)。
清理
- 使用 GCP API 不是免费的,而 G Suite API 则由您的每月 G Suite 订阅费或您作为 Gmail 消费者用户的零月费用来支付,因此 G Suite 用户无需进行 API 清理/调低费用。对于 GCP,您可以转到 Cloud Console 信息中心并查看结算“卡片”中的估算费用。
- 对于 Cloud Vision,您每月可以免费使用固定数量的 API 调用。因此,只要您不超出这些限制,就无需关闭项目,也无需停用/删除项目。如需了解有关 Vision API 结算和免费配额的更多信息,请参阅其价格页面。
- 部分 Cloud Storage 用户每月可获得额外的存储空间。如果您使用此 Codelab 归档的图片不会超出该配额,则不会产生任何费用。如需了解有关 GCS 结算和免费配额的更多信息,请参阅其价格页面。您可以在 Cloud Storage 浏览器中轻松查看和删除 blob。
- 您对 Google 云端硬盘的使用也可能有存储配额,如果超出(或接近)配额,您实际上可以考虑使用在此 Codelab 中构建的工具将这些图像归档到 Cloud Storage 中,以在 Google 云端硬盘上留出更多空间 。如需详细了解 Google 云端硬盘存储空间,请参阅相应的 G Suite 基本版用户或 Gmail/消费者用户的相应价格页面。
尽管大多数 G Suite 商务版和企业计划都具有无限的存储空间,但这可能会导致您的云端硬盘文件夹混乱和/或不堪重负,并且您在本教程中构建的应用是归档多余文件和清理 Google 云端硬盘的绝佳方式。
备用版本
final/analyze_gsimg.py 是您在本教程中处理的“最后一个”官方版本,但不是该故事的结束。最终版应用存在一个问题,即该版本使用的是已弃用的身份验证库。我们之所以选择此路径,是因为在本文编写时,较新的身份验证库不支持多个关键元素:OAuth 令牌存储管理和线程安全。
当前(新)身份验证库
但是,在某些时候,将不再支持较旧的身份验证库,因此我们建议您查看使用存储库 alt 文件夹中的较新(当前)身份验证库的版本,即使它们不是线程安全的也可以(但是您可以构建自己的解决方案)。查找名称中包含 *newauth* 的文件。
GCP 产品客户端库
Google Cloud 建议所有开发者在使用 GCP API 时都使用产品客户端库。遗憾的是,非 GCP API 没有这样的库。使用较低级别的平台库可以使 API 的使用实现一致性和提高可读性。与上述建议类似,存储库的 alt 文件夹中提供了使用 GCP 产品客户端库的替代版本供您查看。查找名称中包含 *-gcp* 的文件。
服务帐号授权
仅在云端工作时,通常没有人类或(用户)拥有的数据,因此服务帐号和服务帐号授权主要用于 GCP。不过,G Suite 文档通常由(用户)用户拥有,因此本教程使用用户帐号授权。这并不意味着无法通过 G Suite API 使用服务帐号。只要这些帐号拥有相应的访问权限级别,它们就可在应用中使用。与上述版本类似,代码库的 alt 文件夹中还提供了使用服务帐号授权的备用版本供您查看。查找名称中包含 *-svc* 的文件。
备用版本目录
在下文中,您可以找到 final/analyze_gsimg.py 的所有备用版本,每个版本都有上述一个或多个属性。在各个版本的文件名中,查找...
- 对于使用旧版身份验证库(
final/analyze_gsimg.py之外)的版本,此列的值为“oldauth” - “
newauth”(针对使用当前/新身份验证库的用户) - “
gcp”(表示使用 GCP 产品客户端库,即 google-cloud-storage 等)的人员 - 使用服务帐号(“svc 帐号”)身份验证而不是用户帐号的用户为“
svc”
以下是所有版本:
文件名 | 说明 |
| 主要示例;使用旧版身份验证库 |
| 与 |
| 与 |
| 与 |
| 与 |
| 与 |
| 与 |
| 与 |
结合原始的 final/analyze_gsimg.py ,您可以结合使用最终解决方案的所有组合(无论您的 Google API 开发环境为何),可选择最适合您需求的解决方案。有关类似说明,另请参阅 alt/README.md。
其他研究
以下这些提示可用于进一步或完成第 2 步操作。您可以扩展当前解决方案可处理的问题集,从而做出以下增强功能:
- (文件夹中包含多个图片)假设 Google 云端硬盘文件夹中有图片,而不是处理一张图片。
- (ZIP 文件中的多个图片)不是包含图片文件夹的 ZIP 归档文件,如果使用 Python,请考虑使用
zipfile模块。 - (分析 Vision 标签)将相似的图片聚在一起,可能首先是查找最常见的标签,然后是第二最常见的标签,依此类推。
- (创建图表)跟进第 3 项,根据 Vision API 分析和分类功能使用 Sheets API 生成图表
- (分类文档)与使用 Cloud Vision API 分析图片相比,假设您有使用 Cloud Natural Language API 分类的 PDF 文件。使用上述解决方案,这些 PDF 文件可以位于云端硬盘中的云端硬盘文件夹或 ZIP 归档文件中。
- (创建演示文稿)使用 Slides API 根据 Google 表格报告的内容生成幻灯片组。如需灵感,请参阅此博文和视频,借助电子表格数据生成幻灯片。
- (导出为 PDF)以 PDF 格式导出电子表格和/或幻灯片,但这不是 Google 表格或 Slides API 的一项功能。提示:Google Drive API。额外赠送金额:将 Google 表格和幻灯片 PDF 文件合并到一个主 PDF 中,并使用 Ghostscript(Linux、Windows)或
Combine PDF Pages.action(Mac OS X) 等工具。
了解详情
Codelab
- G Suite API 简介 (Google Drive API) (Python)
- 将 Cloud Vision 与 Python 搭配使用 (Python)
- 构建自定义报告工具 (Google Sheets API) (JS/Node)
- 将对象上传到 Google Cloud Storage(无需编码)
常规
G Suite
Google Cloud Platform (GCP)
- Google Cloud Storage 首页
- Google Cloud Vision 首页和现场演示
- Cloud Vision API 文档
- Vision API 图片标签文档
- Google Cloud Platform 上的 Python
- GCP 产品客户端库
- GCP 文档
许可
此作品已获得知识共享署名 2.0 通用许可证授权。