
1. Обзор
В этом практическом занятии мы рассмотрим, как создать конвейер обработки данных с использованием Apache Spark и Dataproc на платформе Google Cloud Platform . В науке о данных и инженерии данных часто встречается ситуация, когда данные считываются из одного хранилища, преобразуются и записываются в другое. Типичные преобразования включают изменение содержимого данных, удаление ненужной информации и изменение типов файлов.
В этом практическом занятии вы узнаете об Apache Spark, запустите пример конвейера обработки данных с использованием Dataproc, PySpark (API Apache Spark для Python), BigQuery , Google Cloud Storage и данных с Reddit.
2. Введение в Apache Spark (необязательно)
Согласно веб-сайту, « Apache Spark — это унифицированный аналитический движок для обработки больших объемов данных». Он позволяет анализировать и обрабатывать данные параллельно и в оперативной памяти, что обеспечивает масштабные параллельные вычисления на множестве различных машин и узлов. Первоначально он был выпущен в 2014 году как обновление традиционного MapReduce и до сих пор остается одним из самых популярных фреймворков для выполнения крупномасштабных вычислений. Apache Spark написан на Scala и, соответственно, имеет API на Scala, Java, Python и R. Он содержит множество библиотек, таких как Spark SQL для выполнения SQL-запросов к данным, Spark Streaming для потоковой обработки данных, MLlib для машинного обучения и GraphX для обработки графов, все из которых работают на движке Apache Spark.

Spark может работать автономно или использовать сервисы управления ресурсами, такие как Yarn , Mesos или Kubernetes, для масштабирования. В этом практическом задании вы будете использовать Dataproc, который работает на основе Yarn.
Первоначально данные в Spark загружались в память в так называемые RDD, или отказоустойчивые распределенные наборы данных. В дальнейшем в разработку Spark были добавлены два новых столбцовых типа данных: Dataset, типизированный тип, и Dataframe, нетипизированный тип. В общих чертах, RDD отлично подходят для любых типов данных, тогда как Dataset и Dataframe оптимизированы для табличных данных. Поскольку Dataset доступны только в API Java и Scala, в этом практическом занятии мы будем использовать API PySpark Dataframe. Для получения дополнительной информации обратитесь к документации Apache Spark.
3. Вариант использования
Инженерам по обработке данных часто требуется, чтобы данные были легко доступны специалистам по анализу данных. Однако данные зачастую изначально загрязнены (их сложно использовать для аналитики в текущем состоянии) и нуждаются в очистке, прежде чем они смогут быть полезны. Примером этого являются данные, полученные путем парсинга веб-сайтов, которые могут содержать странные кодировки или лишние HTML-теги.
В этой лабораторной работе вы загрузите набор данных из BigQuery в виде сообщений Reddit в кластер Spark, размещенный на Dataproc, извлечете полезную информацию и сохраните обработанные данные в виде заархивированных CSV-файлов в Google Cloud Storage.
Главный специалист по анализу данных в вашей компании заинтересован в том, чтобы его команды работали над различными задачами обработки естественного языка. В частности, его интересует анализ данных в сабреддите "r/food". Вам предстоит создать конвейер для выгрузки данных, начиная с заполнения данных за период с января 2017 года по август 2019 года.
4. Доступ к BigQuery через API хранилища BigQuery
Извлечение данных из BigQuery с помощью метода API tabledata.list может оказаться трудоемким и неэффективным процессом по мере увеличения объема данных. Этот метод возвращает список объектов JSON и требует последовательного чтения одной страницы за раз для чтения всего набора данных.
API хранилища BigQuery значительно улучшает доступ к данным в BigQuery, используя протокол на основе RPC. Он поддерживает параллельное чтение и запись данных, а также различные форматы сериализации, такие как Apache Avro и Apache Arrow . В целом, это приводит к значительному повышению производительности, особенно при работе с большими наборами данных.
В этом практическом занятии вы будете использовать spark-bigquery-connector для чтения и записи данных между BigQuery и Spark.
5. Создание проекта
Войдите в консоль Google Cloud Platform по адресу console.cloud.google.com и создайте новый проект:



Далее вам потребуется включить оплату в консоли Cloud, чтобы использовать ресурсы Google Cloud.
Выполнение этого практического задания не должно обойтись вам дороже нескольких долларов, но может стоить больше, если вы решите использовать дополнительные ресурсы или оставите их запущенными. В последнем разделе этого практического задания мы расскажем вам, как привести ваш проект в порядок.
Новые пользователи Google Cloud Platform могут получить бесплатную пробную версию стоимостью 300 долларов .
6. Настройка среды
Теперь вы перейдете к настройке вашей среды, выполнив следующие действия:
- Включение API-интерфейсов Compute Engine, Dataproc и BigQuery Storage.
- Настройка параметров проекта
- Создание кластера Dataproc
- Создание корзины Google Cloud Storage
Включение API и настройка среды
Откройте Cloud Shell, нажав кнопку в правом верхнем углу консоли Cloud Console.

После загрузки Cloud Shell выполните следующие команды, чтобы включить API-интерфейсы Compute Engine, Dataproc и BigQuery Storage:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
Укажите идентификатор вашего проекта. Вы можете найти его, перейдя на страницу выбора проектов и выполнив поиск по названию вашего проекта. Он может не совпадать с названием вашего проекта.


Выполните следующую команду, чтобы установить идентификатор вашего проекта :
gcloud config set project <project_id>
Укажите регион вашего проекта, выбрав один из списка здесь . Например, это может быть us-central1 .
gcloud config set dataproc/region <region>
Выберите имя для вашего кластера Dataproc и создайте для него переменную среды.
CLUSTER_NAME=<cluster_name>
Создание кластера Dataproc
Создайте кластер Dataproc, выполнив следующую команду:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
Выполнение этой команды займет несколько минут. Разберем команду по частям:
Это запустит создание кластера Dataproc с именем, которое вы указали ранее. Использование beta API позволит активировать бета-функции Dataproc, такие как Component Gateway .
gcloud beta dataproc clusters create ${CLUSTER_NAME}
Это позволит задать тип оборудования, которое будет использоваться для ваших работников.
--worker-machine-type n1-standard-8
Это определит количество рабочих процессов, которые будут задействованы в вашем кластере.
--num-workers 8
Это позволит установить версию образа Dataproc.
--image-version 1.5-debian
Это позволит настроить действия инициализации , которые будут использоваться в кластере. Здесь вы указываете действие инициализации pip .
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
Это метаданные, которые необходимо включить в кластер. Здесь вы предоставляете метаданные для действия инициализации pip .
--metadata 'PIP_PACKAGES=google-cloud-storage'
Это позволит задать список дополнительных компонентов, которые будут установлены в кластере.
--optional-components=ANACONDA
Это позволит активировать компонентный шлюз, который даст вам возможность использовать компонентный шлюз Dataproc для просмотра распространенных пользовательских интерфейсов, таких как Zeppelin, Jupyter или история Spark.
--enable-component-gateway
Для более подробного ознакомления с Dataproc, пожалуйста, ознакомьтесь с этим практическим заданием .
Создание корзины Google Cloud Storage
Для вывода результатов вашей задачи вам потребуется хранилище Google Cloud Storage. Придумайте уникальное имя для вашего хранилища и выполните следующую команду, чтобы создать новое хранилище. Имена хранилищ уникальны для всех проектов Google Cloud и всех пользователей, поэтому вам может потребоваться повторить эту операцию несколько раз с разными именами. Хранилище считается успешно созданным, если вы не получили исключение ServiceException .
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. Исследовательский анализ данных
Прежде чем приступать к предварительной обработке данных, вам следует подробнее узнать о природе данных, с которыми вы работаете. Для этого вы изучите два метода исследования данных. Сначала вы просмотрите некоторые необработанные данные с помощью веб-интерфейса BigQuery, а затем рассчитаете количество сообщений в каждом сабреддите с помощью PySpark и Dataproc.
Использование веб-интерфейса BigQuery
Для начала воспользуйтесь веб-интерфейсом BigQuery, чтобы просмотреть свои данные. В консоли Cloud Console прокрутите вниз и нажмите «BigQuery», чтобы открыть веб-интерфейс BigQuery.

Далее выполните следующую команду в редакторе запросов веб-интерфейса BigQuery. Она вернет 10 полных строк данных за январь 2017 года:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;

Вы можете прокрутить страницу, чтобы увидеть все доступные столбцы, а также несколько примеров. В частности, вы увидите два столбца, представляющих текстовое содержимое каждого поста: «title» и «selftext», последний представляет собой текст поста. Также обратите внимание на другие столбцы, такие как «created_utc», который показывает время создания поста по UTC, и «subreddit», который указывает сабреддит, в котором находится пост.
Выполнение задания PySpark
Выполните следующие команды в Cloud Shell, чтобы клонировать репозиторий с примером кода и перейти в нужную директорию:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
Вы можете использовать PySpark для определения количества постов в каждом сабреддите. Для этого откройте Cloud Editor и прочитайте скрипт cloud-dataproc/codelabs/spark-bigquery прежде чем выполнять его на следующем шаге:


Нажмите кнопку «Открыть терминал» в Cloud Editor, чтобы вернуться в Cloud Shell, и выполните следующую команду для запуска вашего первого задания PySpark:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
Эта команда позволяет отправлять задания в Dataproc через API заданий. Здесь вы указываете тип задания как pyspark . Вы можете указать имя кластера, необязательные параметры и имя файла, содержащего задание. Здесь вы указываете параметр --jars , который позволяет включить spark-bigquery-connector в ваше задание. Вы также можете установить уровни вывода логов с помощью --driver-log-levels root=FATAL , который подавит весь вывод логов, кроме ошибок. Логи Spark, как правило, довольно зашумлены.
Выполнение этой команды займет несколько минут, и в итоге вы получите примерно такой результат:
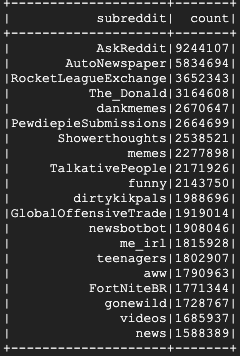
8. Изучение пользовательских интерфейсов Dataproc и Spark.
При запуске заданий Spark в Dataproc у вас есть доступ к двум пользовательским интерфейсам для проверки состояния заданий/кластеров. Первый — это интерфейс Dataproc, который можно найти, щелкнув значок меню и прокрутив вниз до пункта Dataproc. Здесь вы можете увидеть текущий доступный объем памяти, а также ожидающую память и количество рабочих процессов.

Вы также можете перейти на вкладку «Задания», чтобы просмотреть завершенные задания. Подробную информацию о заданиях, такую как журналы и результаты их выполнения, можно посмотреть, щелкнув по идентификатору конкретного задания. 
Вы также можете просмотреть пользовательский интерфейс Spark. На странице задания нажмите стрелку «Назад», а затем выберите «Веб-интерфейсы». В разделе «Шлюз компонентов» вы увидите несколько параметров. Многие из них можно включить с помощью дополнительных компонентов при настройке кластера. Для этой лабораторной работы выберите «Сервер истории Spark».


Должно открыться следующее окно:

Здесь отобразятся все завершенные задания, и вы можете щелкнуть по любому application_id, чтобы узнать больше информации о задании. Аналогично, вы можете щелкнуть по кнопке «Показать незавершенные задания» в самом низу главной страницы, чтобы просмотреть все задания, выполняемые в данный момент.
9. Запуск операции по заполнению вакансий.
Теперь вам нужно запустить задачу, которая загрузит данные в память, извлечет необходимую информацию и выгрузит результат в хранилище Google Cloud Storage. Вы извлечете "заголовок", "тело" (исходный текст) и "временную метку создания" для каждого комментария на Reddit. Затем вы возьмете эти данные, преобразуете их в CSV-файл, заархивируете и загрузите в хранилище с URI gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz.
Вы можете снова обратиться к редактору облачных ресурсов, чтобы прочитать код файла cloud-dataproc/codelabs/spark-bigquery/backfill.sh который представляет собой скрипт-обертку для выполнения кода из cloud-dataproc/codelabs/spark-bigquery/backfill.py .
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
Вскоре вы увидите множество сообщений о завершении задания. Выполнение задания может занять до 15 минут. Вы также можете проверить свой сегмент хранилища, чтобы убедиться в успешном выводе данных, используя gsutil. После завершения всех заданий выполните следующую команду:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
Вы должны увидеть следующий результат:
Поздравляем, вы успешно завершили заполнение данных о комментариях на Reddit! Если вас интересует, как можно создавать модели на основе этих данных, перейдите к практическому заданию по Spark-NLP .
10. Уборка
Чтобы избежать ненужных расходов на ваш счет GCP после завершения этого краткого руководства:
- Удалите созданный вами сегмент облачного хранилища для данной среды.
- Удалите среду Dataproc .
Если вы создали проект специально для этого практического занятия, вы также можете при желании удалить этот проект:
- В консоли GCP перейдите на страницу «Проекты» .
- В списке проектов выберите проект, который хотите удалить, и нажмите «Удалить».
- В поле введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 3.0 Generic License и лицензией Apache 2.0.