
1. نظرة عامة
يقدّم هذا التمرين إرشادات تفصيلية حول نشر خادم تطبيق LIT على Google Cloud Platform (GCP) للتفاعل مع نماذج Gemini الأساسية في Vertex AI والنماذج اللغوية الكبيرة (LLM) التابعة لجهات خارجية والمستضافة ذاتيًا. وتتضمّن أيضًا إرشادات حول كيفية استخدام واجهة مستخدم LIT لتصحيح أخطاء الطلبات وتفسير النماذج.
من خلال اتّباع هذا الدرس التطبيقي، سيتعلّم المستخدمون كيفية:
- إعداد خادم LIT على Google Cloud Platform
- ربط خادم LIT بنماذج Gemini في Vertex AI أو نماذج لغوية كبيرة أخرى مستضافة ذاتيًا
- استخدِم واجهة مستخدم LIT لتحليل الطلبات وتصحيح أخطائها وتفسيرها من أجل تحسين أداء النموذج والحصول على إحصاءات أفضل.
ما هو LIT؟
LIT هي أداة مرئية وتفاعلية لفهم النماذج، وتتيح استخدام النصوص والصور والبيانات الجدولية. يمكن تشغيله كخادم مستقل أو داخل بيئات أوراق ملاحظات مثل Google Colab وJupyter وGoogle Cloud Vertex AI. تتوفّر أداة LIT من PyPI وGitHub.
تم تصميمها في الأصل لفهم نماذج التصنيف والانحدار، وقد أضافت التحديثات الأخيرة أدوات لتصحيح أخطاء طلبات النماذج اللغوية الكبيرة، ما يتيح لك استكشاف كيفية تأثير محتوى المستخدم والنموذج والنظام في سلوك التوليد.
ما هي Vertex AI وModel Garden؟
Vertex AI هي منصة لتعلُّم الآلة (ML) تتيح لك تدريب نماذج تعلُّم الآلة وتطبيقات الذكاء الاصطناعي ونشرها، وتخصيص النماذج اللغوية الكبيرة (LLM) لاستخدامها في تطبيقاتك المستندة إلى الذكاء الاصطناعي. تجمع منصة Vertex AI بين سير عمل هندسة البيانات وعلم البيانات وهندسة تعلُّم الآلة، ما يتيح لفِرقك التعاون باستخدام مجموعة أدوات مشتركة وتوسيع نطاق تطبيقاتك باستخدام مزايا Google Cloud.
Vertex Model Garden هي مكتبة لنماذج تعلُّم الآلة تساعدك في استكشاف نماذج وأصول Google الخاصة ونماذج وأصول محددة تابعة لجهات خارجية واختبارها وتخصيصها وتفعيلها.
الإجراءات التي ستتّخذها
ستستخدم Cloud Shell وCloud Run من Google لنشر حاوية Docker من صورة LIT المُنشأة مسبقًا.
Cloud Run هي منصة حوسبة مُدارة تتيح لك تشغيل الحاويات مباشرةً على بنية Google الأساسية القابلة للتوسّع، بما في ذلك وحدات معالجة الرسومات (GPU).
مجموعة البيانات
يستخدم العرض التوضيحي مجموعة البيانات النموذجية لتصحيح أخطاء طلبات LIT تلقائيًا، أو يمكنك تحميل بياناتك الخاصة من خلال واجهة المستخدم.
قبل البدء
لاستخدام دليل المرجع هذا، يجب أن يكون لديك مشروع على Google Cloud. يمكنك إنشاء مشروع جديد أو اختيار مشروع سبق أن أنشأته.
2. تشغيل Google Cloud Console وCloud Shell
ستشغّل Google Cloud Console وتستخدم Google Cloud Shell في هذه الخطوة.
2-أ: تشغيل Google Cloud Console
افتح متصفّحًا وانتقِل إلى Google Cloud Console.
وحدة تحكّم Google Cloud هي واجهة إدارة ويب آمنة وفعّالة تتيح لك إدارة موارد Google Cloud بسرعة. إنّها أداة DevOps أثناء التنقّل.
2-ب: تشغيل Google Cloud Shell
Cloud Shell هي بيئة تطوير وعمليات على الإنترنت يمكن الوصول إليها من أي مكان باستخدام المتصفح. يمكنك إدارة مواردك باستخدام وحدة التحكّم على الإنترنت المحمَّلة مسبقًا بأدوات مثل أداة سطر الأوامر gcloud وkubectl وغير ذلك. يمكنك أيضًا تطوير تطبيقاتك المستندة إلى السحابة الإلكترونية وإنشاؤها وتصحيح أخطائها ونشرها باستخدام "محرّر Cloud Shell" على الإنترنت. توفّر Cloud Shell بيئة على الإنترنت جاهزة للمطوّرين تتضمّن مجموعة من الأدوات المفضّلة المثبّتة مسبقًا و5 غيغابايت من مساحة التخزين الدائمة. ستستخدم موجّه الأوامر في الخطوات التالية.
شغِّل Google Cloud Shell باستخدام الرمز في أعلى يسار شريط القوائم، والمحاط بدائرة زرقاء في لقطة الشاشة التالية.

من المفترض أن تظهر وحدة طرفية تتضمّن واجهة أوامر Bash في أسفل الصفحة.

2-ج: ضبط مشروع Google Cloud
يجب ضبط معرّف المشروع ومنطقة المشروع باستخدام الأمر gcloud.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
3- نشر صورة Docker لخادم تطبيق LIT باستخدام Cloud Run
3-أ: نشر تطبيق LIT على Cloud Run
عليك أولاً ضبط أحدث إصدار من LIT-App كالإصدار الذي سيتم نشره.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
بعد ضبط علامة الإصدار، عليك تسمية الخدمة.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
بعد ذلك، يمكنك تنفيذ الأمر التالي لنشر الحاوية على Cloud Run.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
تتيح لك أداة LIT أيضًا إضافة مجموعة البيانات عند بدء تشغيل الخادم. لإجراء ذلك، اضبط المتغيّر DATASETS لتضمين البيانات التي تريد تحميلها، باستخدام التنسيق name:path، مثل data_foo:/bar/data_2024.jsonl. يجب أن يكون تنسيق مجموعة البيانات jsonl.، حيث يحتوي كل سجلّ على الحقل prompt والحقلَين الاختياريَين target وsource. لتحميل مجموعات بيانات متعددة، افصل بينها باستخدام فاصلة. في حال عدم ضبطها، سيتم تحميل مجموعة البيانات النموذجية لتصحيح أخطاء طلبات LIT.
# Set the dataset.
export DATASETS=[DATASETS]
من خلال ضبط MAX_EXAMPLES، يمكنك تحديد الحد الأقصى لعدد الأمثلة التي سيتم تحميلها من كل مجموعة تقييم.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
بعد ذلك، يمكنك إضافة ما يلي في أمر النشر:
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
3-ب: عرض خدمة تطبيق LIT
بعد إنشاء خادم تطبيق LIT، يمكنك العثور على الخدمة في قسم Cloud Run في Cloud Console.
اختَر خدمة تطبيق LIT التي أنشأتها للتو. تأكَّد من أنّ اسم الخدمة هو نفسه LIT_SERVICE_NAME.

يمكنك العثور على عنوان URL للخدمة من خلال النقر على الخدمة التي نشرتها للتو.

بعد ذلك، من المفترض أن تتمكّن من عرض واجهة مستخدم LIT. في حال حدوث خطأ، يُرجى الاطّلاع على قسم "تحديد المشاكل وحلّها".

يمكنك الاطّلاع على قسم "السجلات" لمراقبة النشاط وعرض رسائل الخطأ وتتبُّع مستوى تقدّم عملية النشر.

يمكنك الاطّلاع على قسم "المقاييس" لعرض مقاييس الخدمة.

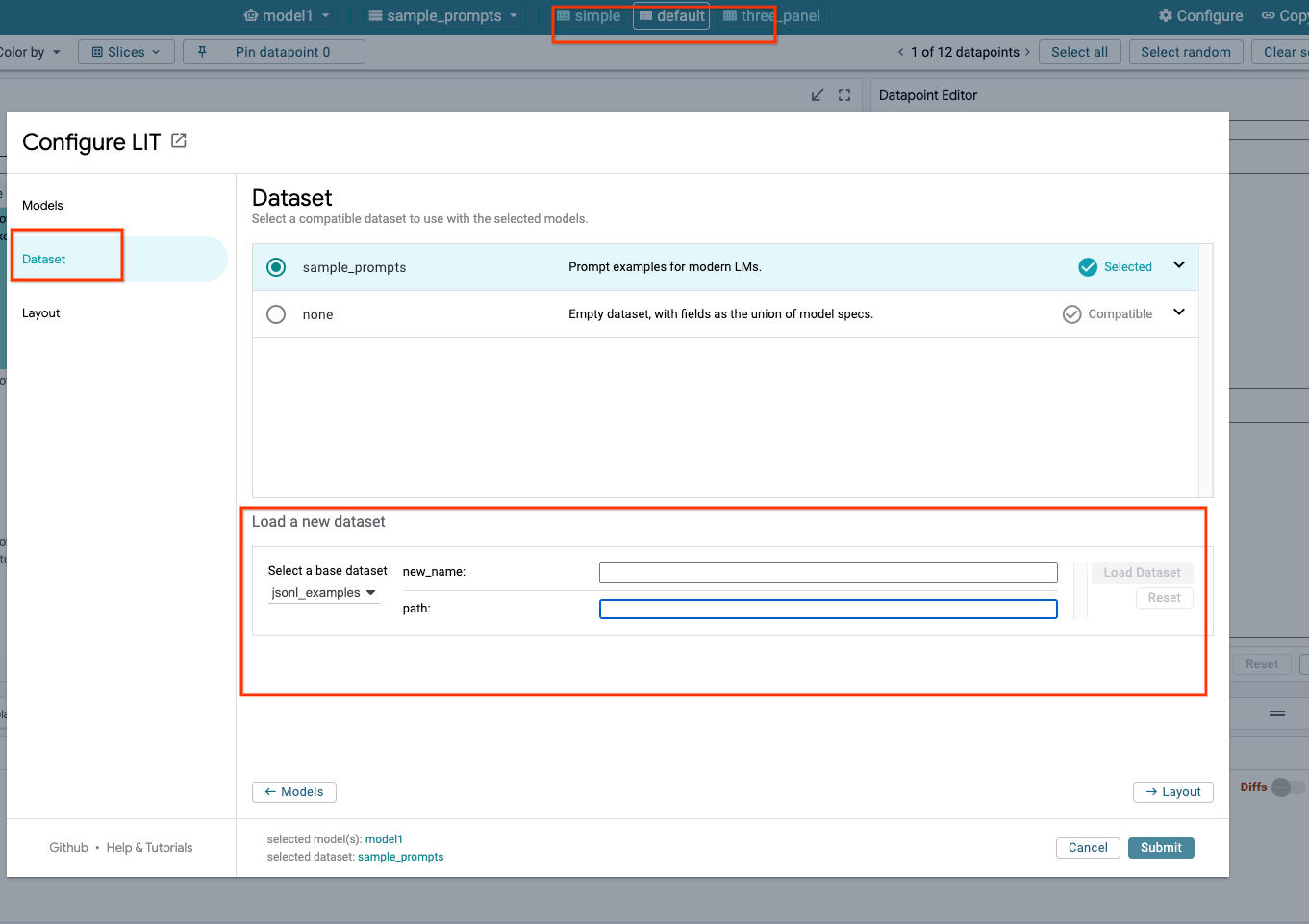
3-ج: تحميل مجموعات البيانات
انقر على الخيار Configure في واجهة مستخدم LIT، ثم انقر على Dataset. حمِّل مجموعة البيانات من خلال تحديد اسم وتقديم عنوان URL لمجموعة البيانات. يجب أن يكون تنسيق مجموعة البيانات jsonl.، حيث يحتوي كل سجلّ على الحقل prompt والحقلَين الاختياريَين target وsource.
4. إعداد "نماذج Gemini" في "مكتبة النماذج" في Vertex AI
تتوفّر نماذج Gemini الأساسية من Google من خلال Vertex AI API. توفّر مكتبة LIT VertexAIModelGarden لتغليف النماذج من أجل استخدامها في إنشاء المحتوى. ما عليك سوى تحديد الإصدار المطلوب (مثل "gemini-1.5-pro-001") من خلال مَعلمة اسم النموذج. من المزايا الرئيسية لاستخدام هذه النماذج أنّها لا تتطلّب أي جهد إضافي لنشرها. بشكلٍ تلقائي، يمكنك الوصول فورًا إلى نماذج مثل Gemini 1.0 Pro وGemini 1.5 Pro على Google Cloud Platform، ما يغنيك عن اتّخاذ خطوات إعداد إضافية.
4-أ: منح أذونات Vertex AI
لإرسال طلبات بحث إلى Gemini في GCP، عليك منح أذونات Vertex AI إلى حساب الخدمة. تأكَّد من أنّ اسم حساب الخدمة هو Default compute service account. انسخ البريد الإلكتروني لحساب الخدمة.

أضِف البريد الإلكتروني لحساب الخدمة ككيان أساسي لديه دور Vertex AI User في قائمة السماح في "إدارة الهوية وإمكانية الوصول".

4-ب: تحميل نماذج Gemini
ستحمّل نماذج Gemini وتعدّل مَعلماتها باتّباع الخطوات التالية.
- انقر على الخيار
Configureفي واجهة مستخدم LIT.
- انقر على الخيار
- انقر على الخيار
geminiضمن الخيارSelect a base model.
- انقر على الخيار
- عليك تسمية النموذج في
new_name.
- عليك تسمية النموذج في
- أدخِل نماذج Gemini التي اخترتها كـ
model_name.
- أدخِل نماذج Gemini التي اخترتها كـ
- انقر على
Load Model.
- انقر على
- انقر على
Submit.
- انقر على

5- نشر خادم نماذج LLM ذاتية الاستضافة على Google Cloud Platform
يتيح لك استضافة نماذج لغوية كبيرة ذاتيًا باستخدام صورة Docker لخادم نماذج LIT استخدام وظيفتَي تحديد الكلمات الرئيسية وتقسيمها إلى رموز في LIT للحصول على إحصاءات أعمق حول سلوك النموذج. تعمل صورة خادم النموذج مع نماذج KerasNLP أو Hugging Face Transformers، بما في ذلك الأوزان التي توفّرها المكتبة والأوزان المستضافة ذاتيًا، مثلاً على Google Cloud Storage.
5-أ: إعداد النماذج
يحمّل كل حاوية نموذجًا واحدًا يتم إعداده باستخدام متغيرات البيئة.
يجب تحديد النماذج التي سيتم تحميلها من خلال ضبط MODEL_CONFIG. يجب أن يكون التنسيق name:path، مثلاً model_foo:model_foo_path. يمكن أن يكون المسار عنوان URL أو مسار ملف محلي أو اسم إعداد مُسبَق لإطار عمل التعلّم العميق الذي تم ضبطه (راجِع الجدول التالي لمزيد من المعلومات). يتم اختبار هذا الخادم باستخدام Gemma وGPT2 وLlama وMistral على جميع قيم DL_FRAMEWORK المتوافقة. من المفترض أن تعمل الطُرز الأخرى، ولكن قد تحتاج إلى إجراء تعديلات.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
بالإضافة إلى ذلك، يتيح خادم نموذج LIT إعداد متغيرات بيئية مختلفة باستخدام الأمر أدناه. يُرجى الرجوع إلى الجدول للحصول على التفاصيل. يُرجى العِلم أنّه يجب ضبط كل متغيّر على حدة.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
متغيّر | القيم | الوصف |
DL_FRAMEWORK | | مكتبة وضع النماذج المستخدَمة لتحميل أوزان النموذج على وقت التشغيل المحدّد القيمة التلقائية هي |
DL_RUNTIME | | إطار العمل الخلفي للتعليم العميق الذي يعمل عليه النموذج ستستخدم جميع النماذج التي يتم تحميلها بواسطة هذا الخادم الخلفية نفسها، وستؤدي حالات عدم التوافق إلى حدوث أخطاء. القيمة التلقائية هي |
PRECISION | | دقة النقطة العائمة لنماذج اللغات الكبيرة القيمة التلقائية هي |
BATCH_SIZE | الأعداد الصحيحة الموجبة | عدد الأمثلة التي ستتم معالجتها لكل دفعة القيمة التلقائية هي |
SEQUENCE_LENGTH | الأعداد الصحيحة الموجبة | الحد الأقصى لطول التسلسل لطلب الإدخال بالإضافة إلى النص الذي تم إنشاؤه القيمة التلقائية هي |
5-ب: نشر خادم النموذج على Cloud Run
عليك أولاً ضبط أحدث إصدار من Model Server كالإصدار الذي سيتم نشره.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
بعد ضبط علامة الإصدار، عليك تسمية خادم النموذج.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
بعد ذلك، يمكنك تنفيذ الأمر التالي لنشر الحاوية على Cloud Run. في حال عدم ضبط متغيرات البيئة، سيتم تطبيق القيم التلقائية. بما أنّ معظم النماذج اللغوية الكبيرة تتطلّب موارد حوسبة باهظة الثمن، يُنصح بشدة باستخدام وحدة معالجة الرسومات. إذا كنت تفضّل التشغيل على وحدة المعالجة المركزية فقط (وهو ما يناسب النماذج الصغيرة مثل GPT2)، يمكنك إزالة الوسيطات ذات الصلة --gpu 1 --gpu-type nvidia-l4 --max-instances 7.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
بالإضافة إلى ذلك، يمكنك تخصيص متغيرات البيئة من خلال إضافة الأوامر التالية. أدرِج فقط متغيرات البيئة الضرورية لتلبية احتياجاتك المحدّدة.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
قد تكون هناك حاجة إلى متغيرات بيئية إضافية للوصول إلى نماذج معيّنة. اطّلِع على التعليمات من Kaggle Hub (المستخدَم لنماذج KerasNLP) وHugging Face Hub حسب الاقتضاء.
5-ج: الوصول إلى خادم النماذج
بعد إنشاء خادم النموذج، يمكن العثور على الخدمة التي تم تشغيلها في قسم Cloud Run ضمن مشروعك على Google Cloud Platform.
اختَر خادم النموذج الذي أنشأته للتو. تأكَّد من أنّ اسم الخدمة هو نفسه MODEL_SERVICE_NAME.
يمكنك العثور على عنوان URL للخدمة من خلال النقر على خدمة النموذج التي نشرتها للتو.
يمكنك الاطّلاع على قسم "السجلات" لمراقبة النشاط وعرض رسائل الخطأ وتتبُّع مستوى تقدّم عملية النشر.
يمكنك الاطّلاع على قسم "المقاييس" لعرض مقاييس الخدمة.
5-د: تحميل النماذج المستضافة ذاتيًا
إذا كنت تستخدم خادم LIT كخادم وكيل في الخطوة 3 (راجِع قسم "تحديد المشاكل وحلّها")، عليك الحصول على رمز تعريف GCP من خلال تنفيذ الأمر التالي.
# Find your GCP identity token.
gcloud auth print-identity-token
ستحمّل النماذج المستضافة ذاتيًا وتعدّل مَعلماتها باتّباع الخطوات أدناه.
- انقر على الخيار
Configureفي واجهة مستخدم LIT. - انقر على الخيار
LLM (self hosted)ضمن الخيارSelect a base model. - عليك تسمية النموذج في
new_name. - أدخِل عنوان URL الخاص بخادم النموذج كـ
base_url. - أدخِل رمز الهوية الذي تم الحصول عليه في
identity_tokenإذا كنت تستخدم خادم تطبيق LIT كخادم وكيل (راجِع الخطوتَين 3 و7). بخلاف ذلك، اتركه فارغًا. - انقر على
Load Model. - انقر على
Submit.

6. التفاعل مع LIT على Google Cloud
تقدّم أداة LIT مجموعة غنية من الميزات لمساعدتك في تصحيح أخطاء سلوك النماذج وفهمها. يمكنك إجراء عمليات بسيطة مثل طلب معلومات من النموذج عن طريق كتابة نص في مربّع وعرض توقّعات النموذج، أو يمكنك فحص النماذج بعمق باستخدام مجموعة ميزات LIT الفعّالة، بما في ذلك:
6-أ: طلب البحث من النموذج من خلال LIT
يستعلم LIT تلقائيًا عن مجموعة البيانات بعد تحميل النموذج ومجموعة البيانات. يمكنك الاطّلاع على ردّ كل نموذج من خلال اختيار الردّ في الأعمدة.


6-ب: استخدام تقنية بروز التسلسل
في الوقت الحالي، لا تتيح تقنية Sequence Salience على LIT سوى استخدام النماذج المستضافة ذاتيًا.
Sequence Salience هي أداة مرئية تساعد في تصحيح أخطاء طلبات LLM من خلال إبراز الأجزاء الأكثر أهمية في الطلب للحصول على ناتج معيّن. لمزيد من المعلومات حول أهمية التسلسل، يُرجى الاطّلاع على البرنامج التعليمي الكامل لمعرفة المزيد حول كيفية استخدام هذه الميزة.
للوصول إلى نتائج تحديد الكلمات الرئيسية، انقر على أي إدخال أو إخراج في الطلب أو الرد، وستظهر نتائج تحديد الكلمات الرئيسية.

6-ج: تعديل الطلب والهدف يدويًا
تتيح لك أداة LIT تعديل أيّ prompt وtarget يدويًا لنقطة بيانات حالية. من خلال النقر على Add، ستتم إضافة الإدخال الجديد إلى مجموعة البيانات.

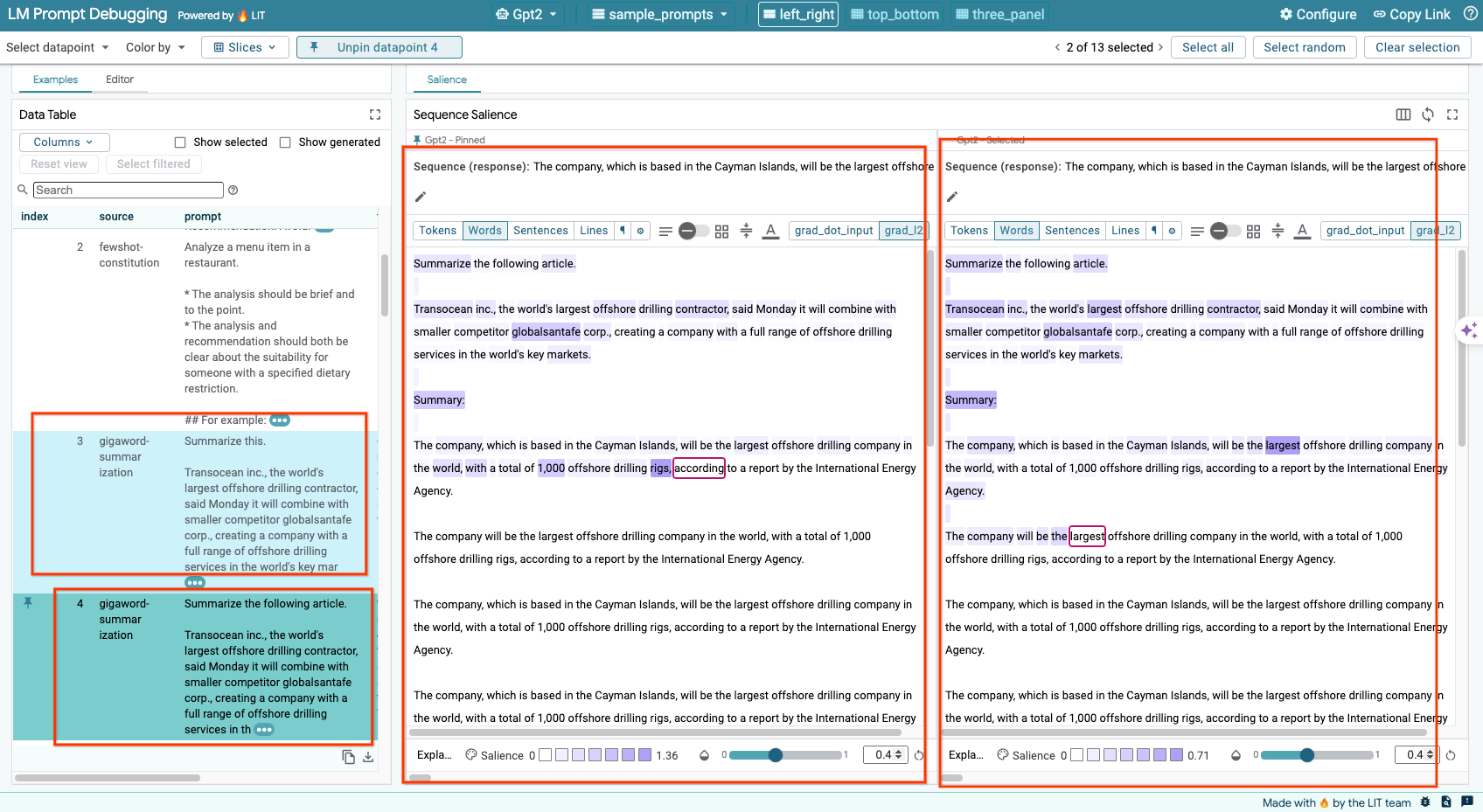
6-د: مقارنة الطلبات جنبًا إلى جنب
تتيح لك أداة LIT مقارنة الطلبات جنبًا إلى جنب في الأمثلة الأصلية والمعدَّلة. يمكنك تعديل مثال يدويًا وعرض نتيجة التوقّع وتحليل "أهمية التسلسل" لكلّ من الإصدار الأصلي والمعدَّل في الوقت نفسه. يمكنك تعديل الطلب لكل نقطة بيانات، وسينشئ LIT الردّ المناسب من خلال الاستعلام من النموذج.
6-هـ: مقارنة نماذج متعدّدة جنبًا إلى جنب
تتيح أداة LIT إجراء مقارنة جنبًا إلى جنب بين النماذج في ما يتعلّق بأمثلة فردية على إنشاء النصوص وتقييمها، بالإضافة إلى أمثلة مجمّعة لمقاييس محدّدة. من خلال طلب البحث من نماذج متعدّدة تم تحميلها، يمكنك بسهولة مقارنة الاختلافات في ردودها.

6-f: مولّدات الحقائق المخالفة للواقع التلقائية
يمكنك استخدام أدوات إنشاء تلقائية لسيناريوهات افتراضية لإنشاء مدخلات بديلة، والاطّلاع على سلوك النموذج معها على الفور.

6-g: تقييم أداء النموذج
يمكنك تقييم أداء النموذج باستخدام المقاييس (نوفّر حاليًا مقياسَي BLEU وROUGE لإنشاء النصوص) على مستوى مجموعة البيانات بأكملها أو أي مجموعات فرعية من الأمثلة التي تمّت فلترتها أو اختيارها.

7. تحديد المشاكل وحلّها
7-أ: مشاكل الوصول المحتملة والحلول
بما أنّ --no-allow-unauthenticated يتم تطبيقه عند النشر على Cloud Run، قد تواجه أخطاء محظورة كما هو موضّح أدناه.

هناك طريقتان للوصول إلى خدمة تطبيق LIT.
1. الخادم الوكيل للخدمة المحلية
يمكنك توجيه الخدمة إلى المضيف المحلي باستخدام الأمر أدناه.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
بعد ذلك، يجب أن تتمكّن من الوصول إلى خادم LIT من خلال النقر على رابط الخدمة الذي تم إعداده كخادم وكيل.
2. مصادقة المستخدمين مباشرةً
يمكنك اتّباع هذا الرابط لمصادقة المستخدمين، ما يتيح الوصول المباشر إلى خدمة تطبيق LIT. يمكن أن يتيح هذا النهج أيضًا لمجموعة من المستخدمين الوصول إلى الخدمة. ويُعدّ هذا الخيار أكثر فعالية في عمليات التطوير التي تتضمّن التعاون مع عدة أشخاص.
7-ب: عمليات التحقّق للتأكّد من أنّ خادم النموذج قد تم تشغيله بنجاح
لضمان إطلاق خادم النموذج بنجاح، يمكنك الاستعلام عن خادم النموذج مباشرةً عن طريق إرسال طلب. يوفّر خادم النماذج ثلاث نقاط نهاية، وهي predict وtokenize وsalience. يُرجى التأكّد من تقديم الحقلين prompt وtarget في طلبك.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
إذا واجهت مشكلة في الوصول إلى حسابك، اطّلِع على القسم 7-أ أعلاه.
8. تهانينا
تهانينا على إكمال الدرس التطبيقي حول الترميز. حان وقت الاسترخاء!
تَنظيم
لتنظيف المختبر، احذف جميع "خدمات Google Cloud" التي تم إنشاؤها للمختبر. استخدِم Google Cloud Shell لتنفيذ الأوامر التالية.
إذا تم فقدان الاتصال بـ Google Cloud بسبب عدم النشاط، أعِد ضبط المتغيرات باتّباع الخطوات السابقة.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
إذا بدأت خادم النموذج، عليك أيضًا حذفه.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
Further reading
يمكنك مواصلة التعرّف على ميزات أداة LIT باستخدام المواد أدناه:
- Gemma: الرابط
- قاعدة رموز المصدر المفتوح في LIT: مستودع Git
- ورقة بحثية حول LIT: ArXiv
- ورقة تصحيح أخطاء طلبات LIT: ArXiv
- عرض توضيحي لفيديو ميزة LIT: Youtube
- عرض توضيحي لتصحيح أخطاء طلبات LIT: Youtube
- مجموعة أدوات الذكاء الاصطناعي التوليدي المسؤول: الرابط
التواصل
إذا كانت لديك أي أسئلة أو مشاكل بشأن هذا الدرس التطبيقي حول الترميز، يُرجى التواصل معنا على GitHub.
الترخيص
يخضع هذا العمل لترخيص المشاع الإبداعي مع نسب العمل إلى مؤلفه 4.0 Generic License.