
۱. مرور کلی
این آزمایشگاه، یک آموزش جامع در مورد استقرار یک سرور برنامه LIT بر روی پلتفرم ابری گوگل (GCP) برای تعامل با مدلهای پایه Vertex AI Gemini و مدلهای زبان بزرگ (LLM) شخص ثالث خود-میزبان ارائه میدهد. همچنین شامل راهنمایی در مورد نحوه استفاده از رابط کاربری LIT برای اشکالزدایی سریع و تفسیر مدل است.
با دنبال کردن این آزمایشگاه، کاربران یاد خواهند گرفت که چگونه:
- یک سرور LIT را روی GCP پیکربندی کنید.
- سرور LIT را به مدلهای Vertex AI Gemini یا سایر LLM های خود میزبان متصل کنید.
- از رابط کاربری LIT برای تجزیه و تحلیل، اشکالزدایی و تفسیر اعلانها برای عملکرد و بینش بهتر مدل استفاده کنید.
LIT چیست؟
LIT یک ابزار درک مدل بصری و تعاملی است که از متن، تصویر و دادههای جدولی پشتیبانی میکند. این ابزار میتواند به عنوان یک سرور مستقل یا درون محیطهای نوتبوک مانند Google Colab، Jupyter و Google Cloud Vertex AI اجرا شود. LIT از طریق PyPI و GitHub در دسترس است.
در ابتدا برای درک مدلهای طبقهبندی و رگرسیون ساخته شده بود، اما بهروزرسانیهای اخیر ابزارهایی برای اشکالزدایی از دستورات LLM اضافه کردهاند که به شما امکان میدهد بررسی کنید که چگونه محتوای کاربر، مدل و سیستم بر رفتار تولید تأثیر میگذارد.
هوش مصنوعی ورتکس و مدل گاردن چیست؟
Vertex AI یک پلتفرم یادگیری ماشین (ML) است که به شما امکان میدهد مدلهای ML و برنامههای هوش مصنوعی را آموزش داده و مستقر کنید و LLMها را برای استفاده در برنامههای مبتنی بر هوش مصنوعی خود سفارشی کنید. Vertex AI گردشهای کاری مهندسی داده، علم داده و مهندسی ML را ترکیب میکند و تیمهای شما را قادر میسازد تا با استفاده از یک مجموعه ابزار مشترک همکاری کنند و برنامههای خود را با استفاده از مزایای Google Cloud مقیاسبندی کنند.
Vertex Model Garden یک کتابخانه مدل یادگیری ماشین است که به شما کمک میکند مدلها و داراییهای اختصاصی گوگل و منتخب شخص ثالث را کشف، آزمایش، سفارشیسازی و پیادهسازی کنید.
کاری که انجام خواهید داد
شما از Google Cloud Shell و Cloud Run برای استقرار یک کانتینر Docker از تصویر از پیش ساخته شده LIT استفاده خواهید کرد.
Cloud Run یک پلتفرم محاسباتی مدیریتشده است که به شما امکان میدهد کانتینرها را مستقیماً روی زیرساخت مقیاسپذیر گوگل، از جمله روی پردازندههای گرافیکی ، اجرا کنید.
مجموعه دادهها
این نسخه آزمایشی به طور پیشفرض از مجموعه دادههای نمونه اشکالزدایی اعلان LIT استفاده میکند، یا میتوانید مجموعه دادههای خودتان را از طریق رابط کاربری بارگذاری کنید.
قبل از اینکه شروع کنی
برای این راهنمای مرجع، به یک پروژه Google Cloud نیاز دارید. میتوانید یک پروژه جدید ایجاد کنید یا پروژهای را که قبلاً ایجاد کردهاید انتخاب کنید.
۲. کنسول ابری گوگل و یک پوسته ابری را راهاندازی کنید
در این مرحله، شما یک کنسول ابری گوگل (Google Cloud Console) راهاندازی کرده و از پوسته ابری گوگل (Google Cloud Shell) استفاده خواهید کرد.
۲-الف: کنسول ابری گوگل را راهاندازی کنید
یک مرورگر باز کنید و به کنسول ابری گوگل بروید.
کنسول گوگل کلود یک رابط کاربری تحت وب قدرتمند و امن است که به شما امکان میدهد منابع گوگل کلود خود را به سرعت مدیریت کنید. این یک ابزار DevOps در حال حرکت است.
۲-ب: راهاندازی پوسته ابری گوگل
Cloud Shell یک محیط توسعه و عملیات آنلاین است که از هر مکانی با مرورگر شما قابل دسترسی است. میتوانید منابع خود را با ترمینال آنلاین آن که از قبل با ابزارهایی مانند ابزار خط فرمان gcloud، kubectl و موارد دیگر بارگذاری شده است، مدیریت کنید. همچنین میتوانید برنامههای مبتنی بر ابر خود را با استفاده از ویرایشگر آنلاین Cloud Shell توسعه، ساخت، اشکالزدایی و مستقر کنید. Cloud Shell یک محیط آنلاین آماده برای توسعهدهنده با مجموعهای از ابزارهای مورد علاقه از پیش نصب شده و 5 گیگابایت فضای ذخیرهسازی پایدار فراهم میکند. در مراحل بعدی از خط فرمان استفاده خواهید کرد.
با استفاده از آیکونی که در سمت راست بالای نوار منو قرار دارد و در تصویر زیر با دایره آبی مشخص شده است، یک پوسته ابری گوگل (Google Cloud Shell) راهاندازی کنید.

شما باید یک ترمینال با پوسته Bash در پایین صفحه ببینید.

۲-ج: تنظیم پروژه ابری گوگل
شما باید شناسه پروژه و منطقه پروژه را با استفاده از دستور gcloud تنظیم کنید.
# Set your GCP Project ID.
gcloud config set project your-project-id
# Set your GCP Project Region.
gcloud config set run/region your-project-region
۳. ایمیج داکر سرور برنامه LIT را با Cloud Run مستقر کنید
۳-الف: اپلیکیشن LIT را روی Cloud Run مستقر کنید
ابتدا باید آخرین نسخه LIT-App را به عنوان نسخهای که قرار است مستقر شود، تنظیم کنید.
# Set latest version as your LIT_SERVICE_TAG.
export LIT_SERVICE_TAG=latest
# List all the public LIT GCP App server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app
پس از تنظیم برچسب نسخه، باید سرویس را نامگذاری کنید.
# Set your lit service name. While 'lit-app-service' is provided as a placeholder, you can customize the service name based on your preferences.
export LIT_SERVICE_NAME=lit-app-service
پس از آن، میتوانید دستور زیر را برای استقرار کانتینر در Cloud Run اجرا کنید.
# Use below cmd to deploy the LIT App to Cloud Run.
gcloud run deploy $LIT_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-lit-app:$LIT_SERVICE_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--no-allow-unauthenticated
LIT همچنین به شما امکان میدهد هنگام راهاندازی سرور، مجموعه دادهها را اضافه کنید. برای انجام این کار، متغیر DATASETS را طوری تنظیم کنید که دادههایی را که میخواهید بارگذاری کنید، با استفاده از فرمت name:path ، مثلاً data_foo:/bar/data_2024.jsonl ، شامل کند. فرمت مجموعه دادهها باید .jsonl باشد، که در آن هر رکورد شامل فیلدهای prompt و target و source اختیاری است. برای بارگذاری چندین مجموعه داده، آنها را با کاما از هم جدا کنید. در صورت عدم تنظیم، مجموعه دادههای نمونه اشکالزدایی prompt LIT بارگذاری خواهد شد.
# Set the dataset.
export DATASETS=[DATASETS]
با تنظیم MAX_EXAMPLES، میتوانید حداکثر تعداد مثالها را برای بارگذاری از هر مجموعه ارزیابی تعیین کنید.
# Set the max examples.
export MAX_EXAMPLES=[MAX_EXAMPLES]
سپس، در دستور deploy، میتوانید اضافه کنید
--set-env-vars "DATASETS=$DATASETS" \
--set-env-vars "MAX_EXAMPLES=$MAX_EXAMPLES" \
۳-ب: مشاهده سرویس اپلیکیشن LIT
پس از ایجاد سرور LIT App، میتوانید این سرویس را در بخش Cloud Run از Cloud Console پیدا کنید.
سرویس LIT App که ایجاد کردهاید را انتخاب کنید. مطمئن شوید که نام سرویس با LIT_SERVICE_NAME یکسان باشد.

شما میتوانید با کلیک روی سرویسی که اخیراً مستقر کردهاید، آدرس اینترنتی سرویس را پیدا کنید.

سپس باید بتوانید رابط کاربری LIT را مشاهده کنید. اگر با خطایی مواجه شدید، بخش عیبیابی را بررسی کنید.

شما میتوانید بخش LOGS را برای نظارت بر فعالیت، مشاهده پیامهای خطا و پیگیری پیشرفت استقرار بررسی کنید.

برای مشاهده معیارهای سرویس، میتوانید بخش METRICS را بررسی کنید.

۳-ج: بارگذاری مجموعه دادهها
روی گزینه Configure در رابط کاربری LIT کلیک کنید، Dataset انتخاب کنید. با مشخص کردن یک نام و ارائه URL مجموعه داده، مجموعه داده را بارگذاری کنید. فرمت مجموعه داده باید .jsonl باشد، که در آن هر رکورد شامل فیلدهای prompt و target و source اختیاری است.

۴. مدلهای Gemini را در Vertex AI Model Garden آماده کنید
مدلهای پایه Gemini گوگل از طریق API هوش مصنوعی Vertex در دسترس هستند. LIT بستهبندی مدل VertexAIModelGarden را برای استفاده از این مدلها برای تولید ارائه میدهد. کافیست نسخه مورد نظر (مثلاً "gemini-1.5-pro-001") را از طریق پارامتر نام مدل مشخص کنید. مزیت کلیدی استفاده از این مدلها این است که برای استقرار نیازی به تلاش اضافی ندارند. به طور پیشفرض، شما به مدلهایی مانند Gemini 1.0 Pro و Gemini 1.5 Pro در GCP دسترسی فوری دارید و نیاز به مراحل پیکربندی اضافی را از بین میبرید.
۴-الف: مجوزهای هوش مصنوعی Vertex را اعطا کنید
برای پرسوجو از Gemini در GCP، باید مجوزهای Vertex AI را به حساب سرویس اعطا کنید. مطمئن شوید که نام حساب سرویس Default compute service account باشد. ایمیل حساب سرویس را کپی کنید.
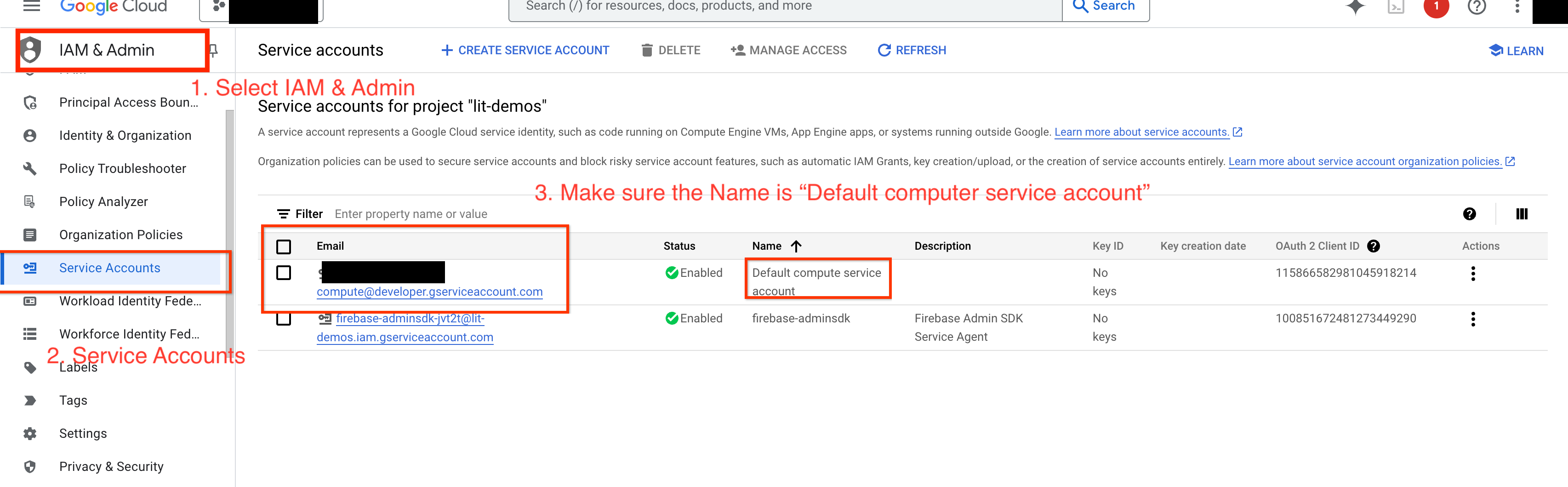
ایمیل حساب سرویس را به عنوان یک مدیر با نقش Vertex AI User در لیست مجاز IAM خود اضافه کنید.

۴-ب: بارگذاری مدلهای جمینی
شما مدلهای Gemini را بارگذاری کرده و پارامترهای آن را طبق مراحل زیر تنظیم خواهید کرد.
- روی گزینه
Configureدر رابط کاربری LIT کلیک کنید.
- روی گزینه
- گزینهی
geminiرا در زیر گزینهیSelect a base modelانتخاب کنید.
- گزینهی
- شما باید مدل را در
new_nameنامگذاری کنید.
- شما باید مدل را در
- مدلهای جمینی انتخابی خود را به عنوان
model_nameوارد کنید.
- مدلهای جمینی انتخابی خود را به عنوان
- روی
Load Modelکلیک کنید.
- روی
-
Submitکلیک کنید.
-

۵. سرور مدل LLM های خود-میزبان را روی GCP مستقر کنید
LLM های خود میزبان با تصویر داکر سرور مدل LIT به شما امکان می دهد از توابع salience و tokenize LIT برای به دست آوردن بینش عمیق تر در مورد رفتار مدل استفاده کنید. تصویر سرور مدل با مدل های KerasNLP یا Hugging Face Transformers ، از جمله وزن های ارائه شده توسط کتابخانه و خود میزبان، به عنوان مثال، در Google Cloud Storage، کار می کند.
۵-الف: پیکربندی مدلها
هر کانتینر یک مدل را بارگذاری میکند که با استفاده از متغیرهای محیطی پیکربندی شده است.
شما باید مدلهایی را که میخواهید بارگذاری کنید با تنظیم MODEL_CONFIG مشخص کنید. فرمت باید name:path باشد، برای مثال model_foo:model_foo_path . مسیر میتواند یک URL، یک مسیر فایل محلی یا نام یک پیشتنظیم برای چارچوب یادگیری عمیق پیکربندی شده باشد (برای اطلاعات بیشتر به جدول زیر مراجعه کنید). این سرور با Gemma، GPT2، Llama و Mistral روی تمام مقادیر DL_FRAMEWORK پشتیبانی شده آزمایش شده است. مدلهای دیگر باید کار کنند، اما ممکن است نیاز به تنظیماتی باشد.
# Set models you want to load. While 'gemma2b is given as a placeholder, you can load your preferred model by following the instructions above.
export MODEL_CONFIG=gemma2b:gemma_2b_en
علاوه بر این، سرور مدل LIT امکان پیکربندی متغیرهای محیطی مختلف را با استفاده از دستور زیر فراهم میکند. لطفاً برای جزئیات بیشتر به جدول مراجعه کنید. توجه داشته باشید که هر متغیر باید به صورت جداگانه تنظیم شود.
# Customize the variable value as needed.
export [VARIABLE]=[VALUE]
متغیر | ارزشها | توضیحات |
چارچوب DL | | کتابخانه مدلسازی مورد استفاده برای بارگذاری وزنهای مدل در زمان اجرای مشخص شده. مقدار پیشفرض |
زمان اجرای DL | | چارچوب بکاند یادگیری عمیق که مدل روی آن اجرا میشود. تمام مدلهای بارگذاری شده توسط این سرور از بکاند یکسانی استفاده میکنند، ناسازگاریها منجر به خطا میشوند. مقدار پیشفرض |
دقت | | دقت اعشاری برای مدلهای LLM. پیشفرض روی |
اندازه دسته | اعداد صحیح مثبت | تعداد مثالهایی که باید در هر دسته پردازش شوند. پیشفرض |
طول توالی | اعداد صحیح مثبت | حداکثر طول توالی اعلان ورودی به علاوه متن تولید شده. مقدار پیشفرض |
۵-ب: استقرار سرور مدل در Cloud Run
ابتدا باید آخرین نسخه Model Server را به عنوان نسخهای که قرار است مستقر شود، تنظیم کنید.
# Set latest as MODEL_VERSION_TAG.
export MODEL_VERSION_TAG=latest
# List all the public LIT GCP model server docker images.
gcloud container images list-tags us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server
پس از تنظیم برچسب نسخه، باید نامی برای مدل-سرور خود تعیین کنید.
# Set your Service name.
export MODEL_SERVICE_NAME='gemma2b-model-server'
پس از آن، میتوانید دستور زیر را برای استقرار کانتینر در Cloud Run اجرا کنید. اگر متغیرهای محیطی را تنظیم نکنید، مقادیر پیشفرض اعمال میشوند. از آنجایی که اکثر LLMها به منابع محاسباتی گرانقیمتی نیاز دارند، اکیداً توصیه میشود از GPU استفاده کنید. اگر ترجیح میدهید فقط روی CPU اجرا شود (که برای مدلهای کوچک مانند GPT2 خوب کار میکند)، میتوانید آرگومانهای مرتبط --gpu 1 --gpu-type nvidia-l4 --max-instances 7 را حذف کنید.
# Deploy the model service container.
gcloud beta run deploy $MODEL_SERVICE_NAME \
--image us-east4-docker.pkg.dev/lit-demos/lit-app/gcp-model-server:$MODEL_VERSION_TAG \
--port 5432 \
--cpu 8 \
--memory 32Gi \
--no-cpu-throttling \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 7 \
--set-env-vars "MODEL_CONFIG=$MODEL_CONFIG" \
--no-allow-unauthenticated
علاوه بر این، میتوانید متغیرهای محیطی را با اضافه کردن دستورات زیر سفارشی کنید. فقط متغیرهای محیطی را که برای نیازهای خاص شما ضروری هستند، اضافه کنید.
--set-env-vars "DL_FRAMEWORK=$DL_FRAMEWORK" \
--set-env-vars "DL_RUNTIME=$DL_RUNTIME" \
--set-env-vars "PRECISION=$PRECISION" \
--set-env-vars "BATCH_SIZE=$BATCH_SIZE" \
--set-env-vars "SEQUENCE_LENGTH=$SEQUENCE_LENGTH" \
ممکن است برای دسترسی به مدلهای خاص، متغیرهای محیطی اضافی لازم باشد. در صورت لزوم، به دستورالعملهای Kaggle Hub (مورد استفاده برای مدلهای KerasNLP) و Hugging Face Hub مراجعه کنید.
۵-ج: سرور مدل دسترسی
پس از ایجاد سرور مدل، سرویس آغاز شده را میتوانید در بخش Cloud Run پروژه GCP خود پیدا کنید.
سرور مدلی که ایجاد کردهاید را انتخاب کنید. مطمئن شوید که نام سرویس با MODEL_SERVICE_NAME یکسان باشد.
شما میتوانید با کلیک روی سرویس مدلی که اخیراً مستقر کردهاید، آدرس اینترنتی سرویس را پیدا کنید.
شما میتوانید بخش LOGS را برای نظارت بر فعالیت، مشاهده پیامهای خطا و پیگیری پیشرفت استقرار بررسی کنید.
برای مشاهده معیارهای سرویس، میتوانید بخش METRICS را بررسی کنید.
۵-د: بارگذاری مدلهای خود-میزبان
اگر در مرحله ۳ (بخش عیبیابی را بررسی کنید) سرور LIT خود را پروکسی کردهاید، باید با اجرای دستور زیر، توکن هویت GCP خود را دریافت کنید.
# Find your GCP identity token.
gcloud auth print-identity-token
شما مدلهای خود-میزبان را بارگذاری کرده و پارامترهای آن را طبق مراحل زیر تنظیم خواهید کرد.
- روی گزینه
Configureدر رابط کاربری LIT کلیک کنید. - گزینه
LLM (self hosted)را در زیر گزینهSelect a base modelانتخاب کنید. - شما باید مدل را در
new_nameنامگذاری کنید. - آدرس سرور مدل خود را به عنوان
base_urlوارد کنید. - اگر سرور برنامه LIT را پروکسی میکنید، توکن هویت بهدستآمده را در
identity_tokenوارد کنید (به مرحله ۳ و مرحله ۷ مراجعه کنید). در غیر این صورت، آن را خالی بگذارید. - روی
Load Modelکلیک کنید. -
Submitکلیک کنید.

۶. تعامل با LIT در GCP
LIT مجموعهای غنی از ویژگیها را برای کمک به شما در اشکالزدایی و درک رفتارهای مدل ارائه میدهد. میتوانید کاری به سادگی پرسوجو از مدل، با تایپ متن در یک کادر و مشاهده پیشبینیهای مدل، انجام دهید یا مدلها را با مجموعه ویژگیهای قدرتمند LIT، از جمله موارد زیر، به طور عمیق بررسی کنید:
۶-الف: از طریق LIT مدل را جستجو کنید
LIT پس از بارگذاری مدل و مجموعه داده، به طور خودکار از مجموعه داده پرس و جو میکند. میتوانید با انتخاب پاسخ در ستونها، پاسخ هر مدل را مشاهده کنید.


۶-ب: از تکنیک برجستگی توالی استفاده کنید
در حال حاضر، تکنیک Sequence Salience در LIT فقط از مدلهای self-hosted پشتیبانی میکند.
Sequence Salience ابزاری بصری است که با برجسته کردن بخشهایی از یک prompt که برای یک خروجی مشخص مهمتر هستند، به اشکالزدایی از LLM promptها کمک میکند. برای اطلاعات بیشتر در مورد Sequence Salience، آموزش کامل را برای نحوه استفاده از این ویژگی بررسی کنید.
برای دسترسی به نتایج برجستگی، روی هر ورودی یا خروجی در اعلان یا پاسخ کلیک کنید تا نتایج برجستگی نمایش داده شود.

۶-ج: دستور و هدف ویرایش مانولای
LIT به شما امکان میدهد هرگونه prompt و target برای نقطه داده موجود به صورت دستی ویرایش کنید. با کلیک روی Add ، ورودی جدید به مجموعه داده اضافه میشود.

۶-د: مقایسه سریع در کنار هم
LIT به شما امکان میدهد تا پاسخ (prompt) را در نمونههای اصلی و ویرایششده، در کنار هم مقایسه کنید. میتوانید یک نمونه را به صورت دستی ویرایش کنید و نتیجه پیشبینی و تحلیل برجستگی توالی (Sequence Salience) را برای هر دو نسخه اصلی و ویرایششده به طور همزمان مشاهده کنید. میتوانید پاسخ (prompt) را برای هر نقطه داده تغییر دهید و LIT با پرسوجو از مدل، پاسخ مربوطه را تولید میکند.

۶-ه: مقایسه چندین مدل در کنار هم
LIT امکان مقایسه پهلو به پهلو مدلها را در نمونههای تولید متن و امتیازدهی منفرد، و همچنین در نمونههای تجمیعشده برای معیارهای خاص فراهم میکند. با پرسوجو از مدلهای بارگذاریشده مختلف، میتوانید به راحتی تفاوتهای موجود در پاسخهای آنها را مقایسه کنید.

۶-ج: مولدهای خودکار خلاف واقع
شما میتوانید از مولدهای خودکار خلاف واقع برای ایجاد ورودیهای جایگزین استفاده کنید و بلافاصله ببینید که مدل شما چگونه روی آنها رفتار میکند.

۶-ز: ارزیابی عملکرد مدل
شما میتوانید عملکرد مدل را با استفاده از معیارها (در حال حاضر از نمرات BLEU و ROUGE برای تولید متن پشتیبانی میشود) در کل مجموعه دادهها یا هر زیرمجموعهای از نمونههای فیلتر شده یا انتخاب شده ارزیابی کنید.

۷. عیبیابی
۷-الف: مشکلات احتمالی دسترسی و راهحلها
از آنجایی که هنگام استقرار در Cloud Run، از --no-allow-unauthenticated استفاده میشود، ممکن است با خطاهای ممنوعه مانند آنچه در زیر نشان داده شده است، مواجه شوید.

دو روش برای دسترسی به سرویس اپلیکیشن LIT وجود دارد.
۱. پروکسی به سرویس محلی
شما میتوانید با استفاده از دستور زیر، سرویس را به میزبان محلی پروکسی کنید.
# Proxy the service to local host.
gcloud run services proxy $LIT_SERVICE_NAME
سپس باید بتوانید با کلیک روی لینک سرویس پروکسی به سرور LIT دسترسی پیدا کنید.
۲. احراز هویت مستقیم کاربران
شما میتوانید برای تأیید اعتبار کاربران و دسترسی مستقیم به سرویس برنامه LIT، از این لینک استفاده کنید. این رویکرد همچنین میتواند گروهی از کاربران را قادر به دسترسی به سرویس کند. برای توسعههایی که شامل همکاری با چندین نفر است، این گزینه مؤثرتری است.
۷-ب: بررسی میکند تا از راهاندازی موفقیتآمیز سرور مدل اطمینان حاصل شود.
برای اطمینان از راهاندازی موفقیتآمیز سرور مدل، میتوانید با ارسال یک درخواست، مستقیماً از سرور مدل پرسوجو کنید. سرور مدل سه نقطه پایانی، predict ، tokenize و salience را ارائه میدهد. مطمئن شوید که هم فیلد prompt و هم فیلد target را در درخواست خود ارائه میدهید.
# Query the model server predict endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/predict -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server tokenize endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/tokenize -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
# Query the model server salience endpoint.
curl -X POST http://YOUR_MODEL_SERVER_URL/salience -H "Content-Type: application/json" -d '{"inputs":[{"prompt":"[YOUR PROMPT]", "target":[YOUR TARGET]}]}'
اگر با مشکل دسترسی مواجه شدید، بخش ۷-الف بالا را بررسی کنید.
۸. تبریک
آفرین که آزمایشگاه کد رو تموم کردی! وقت استراحته!
تمیز کردن
برای پاکسازی آزمایشگاه، تمام سرویسهای ابری گوگل که برای آزمایشگاه ایجاد شدهاند را حذف کنید. از پوسته ابری گوگل برای اجرای دستورات زیر استفاده کنید.
اگر اتصال Google Cloud به دلیل عدم فعالیت قطع شد، متغیرها را طبق مراحل قبلی تنظیم مجدد کنید.
# Delete the LIT App Service.
gcloud run services delete $LIT_SERVICE_NAME
اگر model server را اجرا کردهاید، باید model server را نیز حذف کنید.
# Delete the Model Service.
gcloud run services delete $MODEL_SERVICE_NAME
مطالعه بیشتر
یادگیری ویژگیهای ابزار LIT را با مطالب زیر ادامه دهید:
- جما: لینک
- پایه کد متنباز LIT: مخزن گیت
- مقاله LIT: ArXiv
- مقاله اشکالزدایی سریع LIT: ArXiv
- نسخه نمایشی ویدیوی بلند LIT: یوتیوب
- نسخه آزمایشی اشکالزدایی اعلان LIT: یوتیوب
- جعبه ابزار GenAI مسئول: لینک
تماس
برای هرگونه سوال یا مشکلی در مورد این آزمایشگاه کد، لطفاً از طریق گیتهاب با ما در ارتباط باشید.
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 4.0 منتشر شده است.