
1. Présentation
Dans différents secteurs, la recherche de brevets est un outil essentiel pour comprendre le paysage concurrentiel, identifier les opportunités potentielles de licence ou d'acquisition, et éviter d'enfreindre les brevets existants.
La recherche de brevets est vaste et complexe. Passer au crible d'innombrables résumés techniques pour trouver des innovations pertinentes est une tâche ardue. Les recherches traditionnelles basées sur des mots clés sont souvent inexactes et prennent beaucoup de temps. Les résumés sont longs et techniques, ce qui rend difficile la compréhension rapide de l'idée principale. Les chercheurs peuvent ainsi passer à côté de brevets clés ou perdre du temps sur des résultats non pertinents.
Le secret de cette révolution réside dans la recherche vectorielle. Au lieu de s'appuyer sur une simple correspondance de mots clés, la recherche vectorielle transforme le texte en représentations numériques (embeddings). Cela nous permet d'effectuer des recherches en fonction du sens de la requête, et pas seulement des mots spécifiques utilisés. Dans le monde de la recherche documentaire, cela change la donne. Imaginez trouver un brevet pour un "moniteur de fréquence cardiaque portable", même si l'expression exacte n'est pas utilisée dans le document.
Objectif
Dans cet atelier de programmation, nous allons rendre le processus de recherche de brevets plus rapide, plus intuitif et incroyablement précis en exploitant AlloyDB, l'extension pgvector, Gemini 1.5 Pro, Embeddings et la recherche vectorielle.
Objectifs de l'atelier
Dans cet atelier, vous allez :
- créer une instance AlloyDB et charger les données de l'ensemble de données public sur les brevets ;
- activer les extensions pgvector et de modèle d'IA générative dans AlloyDB ;
- générer des embeddings à partir des insights ;
- effectuer une recherche de similarité cosinus en temps réel pour le texte de recherche de l'utilisateur ;
- déployer la solution dans Cloud Functions sans serveur.
Le schéma suivant représente le flux de données et les étapes impliquées dans l'implémentation.

High level diagram representing the flow of the Patent Search Application with AlloyDB
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée pour un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec bq. Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud reconnaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises. Vous pouvez utiliser une commande gcloud dans le terminal Cloud Shell :
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Vous pouvez également accéder à la commande gcloud via la console en recherchant chaque produit ou en utilisant ce lien.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Préparer votre base de données AlloyDB
Créons un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données sur les brevets sera chargé.
Créer des objets AlloyDB
Créez un cluster et une instance avec l'ID de cluster "patent-cluster", le mot de passe "alloydb", compatible avec PostgreSQL 15 et la région "us-central1", le réseau défini sur "default". Définissez l'ID d'instance sur "patent-instance". Cliquez sur CRÉER UN CLUSTER. Pour en savoir plus sur la création d'un cluster, consultez le lien suivant : https://cloud.google.com/alloydb/docs/cluster-create.
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
Activer les extensions
Pour créer l'application de recherche de brevets, nous allons utiliser les extensions pgvector et google_ml_integration. L' extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra à votre numéro de projet.
Vous pouvez également accorder l'accès à l'aide de la commande gcloud :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Modifier la table pour ajouter une colonne Vector afin de stocker les embeddings
Exécutez le LDD ci-dessous pour ajouter le champ abstract_embeddings à la table que nous venons de créer. Cette colonne permettra de stocker les valeurs vectorielles du texte :
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. Charger les données de brevets dans la base de données
Nous allons utiliser les ensembles de données publics Google Patents sur BigQuery comme ensemble de données. Nous allons utiliser AlloyDB Studio pour exécuter nos requêtes. Le dépôt alloydb-pgvector inclut le script insert_into_patents_data.sql que nous allons exécuter pour charger les données de brevets.
- Dans la console Google Cloud, ouvrez la AlloyDB.
- Sélectionnez le cluster que vous venez de créer, puis cliquez sur l'instance.
- Dans le menu de navigation AlloyDB, cliquez sur AlloyDB Studio. Connectez-vous avec vos identifiants.
- Ouvrez un nouvel onglet en cliquant sur l'icône Nouvel onglet à droite.
- Copiez l'instruction de requête
insertdu scriptinsert_into_patents_data.sqlmentionné ci-dessus dans l'éditeur. Vous pouvez copier entre 50 et 100 instructions d'insertion pour une démonstration rapide de ce cas d'utilisation. - Cliquez sur Exécuter. Les résultats de votre requête s'affichent dans la table Résultats.
5. Créer des embeddings pour les données de brevets
Commençons par tester la fonction d'embedding en exécutant l'exemple de requête suivant :
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Cela devrait renvoyer le vecteur d'embeddings, qui ressemble à un tableau de valeurs flottantes, pour l'exemple de texte de la requête. Voici les résultats :

Mettre à jour le champ Vector abstract_embeddings
Exécutez le LMD ci-dessous pour mettre à jour les résumés de brevets dans la table avec les embeddings correspondants :
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. Effectuer une recherche vectorielle
Maintenant que la table, les données et les embeddings sont prêts, effectuons la recherche vectorielle en temps réel pour le texte de recherche de l'utilisateur. Vous pouvez tester cela en exécutant la requête ci-dessous :
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
Dans cette requête :
- Le texte de recherche de l'utilisateur est le suivant : "A new Natural Language Processing related Machine Learning Model".
- Nous le convertissons en embeddings dans la méthode embedding() à l'aide du modèle : gemini-embedding-001.
- "<=>" représente l'utilisation de la méthode de distance COSINE SIMILARITY.
- Nous convertissons le résultat de la méthode d'embedding en type vectoriel pour le rendre compatible avec les vecteurs stockés dans la base de données.
- LIMIT 10 indique que nous sélectionnons les 10 correspondances les plus proches du texte de recherche.
Le résultat est le suivant :

Comme vous pouvez le voir dans vos résultats, les correspondances sont assez proches du texte de recherche.
7. Transférer l'application sur le Web
Prêt à transférer cette application sur le Web ? Procédez comme suit :
- Accédez à l'éditeur Cloud Shell, puis cliquez sur l'icône "Cloud Code – Se connecter" en bas à gauche (barre d'état) de l'éditeur. Sélectionnez votre projet Google Cloud actuel pour lequel la facturation est activée et assurez-vous d'être connecté au même projet depuis Gemini (dans l'angle droit de la barre d'état).
- Cliquez sur l'icône Cloud Code et attendez que la boîte de dialogue Cloud Code s'affiche. Sélectionnez Nouvelle application, puis, dans la fenêtre pop-up Créer une application, sélectionnez Application Cloud Functions :

Sur la page 2/2 de la fenêtre pop-up Créer une application, sélectionnez Java : Hello World, saisissez le nom de votre projet "alloydb-pgvector" à l'emplacement de votre choix, puis cliquez sur OK :

- Dans la structure de projet obtenue, recherchez pom.xml et remplacez-le par le contenu du fichier de dépôt. Il doit comporter ces dépendances en plus de quelques autres :

- Remplacez le fichier HelloWorld.java par le contenu du fichier de dépôt.
Notez que vous devez remplacer les valeurs ci-dessous par vos valeurs réelles :
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
Notez que la fonction attend le texte de recherche comme paramètre d'entrée avec la clé "search" et que, dans cette implémentation, nous ne renvoyons qu'une seule correspondance la plus proche de la base de données :
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- Pour déployer la fonction Cloud Functions que vous venez de créer, exécutez la commande suivante à partir du terminal Cloud Shell. N'oubliez pas d'accéder d'abord au dossier de projet correspondant à l'aide de la commande :
cd alloydb-pgvector
Exécutez ensuite la commande :
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
ÉTAPE IMPORTANTE :
Une fois le déploiement lancé, vous devriez pouvoir voir les fonctions dans la console Google Cloud Run Functions. Recherchez la fonction que vous venez de créer, ouvrez-la, modifiez les configurations et apportez les modifications suivantes :
- Accédez à Paramètres d'exécution, de compilation, de connexion et de sécurité.
- Augmentez le délai d'inactivité à 180 secondes.
- Accédez à l'onglet CONNEXIONS :

- Sous les paramètres d'entrée, assurez-vous que l'option "Autoriser tout le trafic" est sélectionnée.
- Sous les paramètres de sortie, cliquez sur le menu déroulant Réseau, sélectionnez l'option "Ajouter un connecteur VPC", puis suivez les instructions qui s'affichent dans la boîte de dialogue :

- Indiquez un nom pour le connecteur VPC et assurez-vous que la région est la même que celle de votre instance. Laissez la valeur Réseau par défaut et définissez le sous-réseau sur Plage d'adresses IP personnalisée avec la plage d'adresses IP 10.8.0.0 ou une plage similaire disponible.
- Développez AFFICHER LES PARAMÈTRES DE SCALING et assurez-vous que la configuration est exactement la suivante :
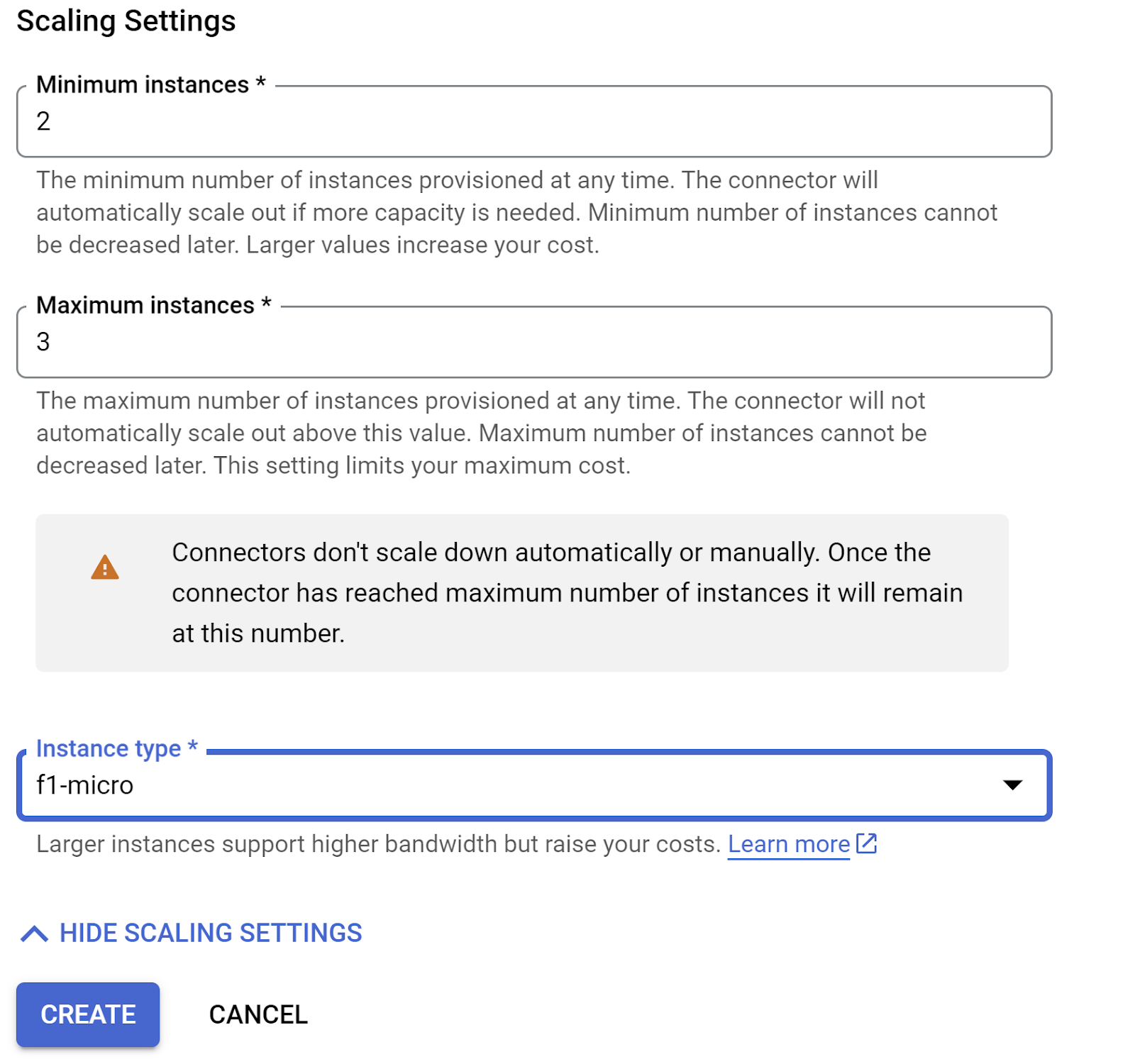
- Cliquez sur CRÉER. Ce connecteur devrait maintenant être listé dans les paramètres de sortie.
- Sélectionnez le connecteur que vous venez de créer.
- Choisissez d'acheminer tout le trafic via ce connecteur VPC.
8. Tester l'application
Une fois déployé, le point de terminaison doit s'afficher au format suivant :
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
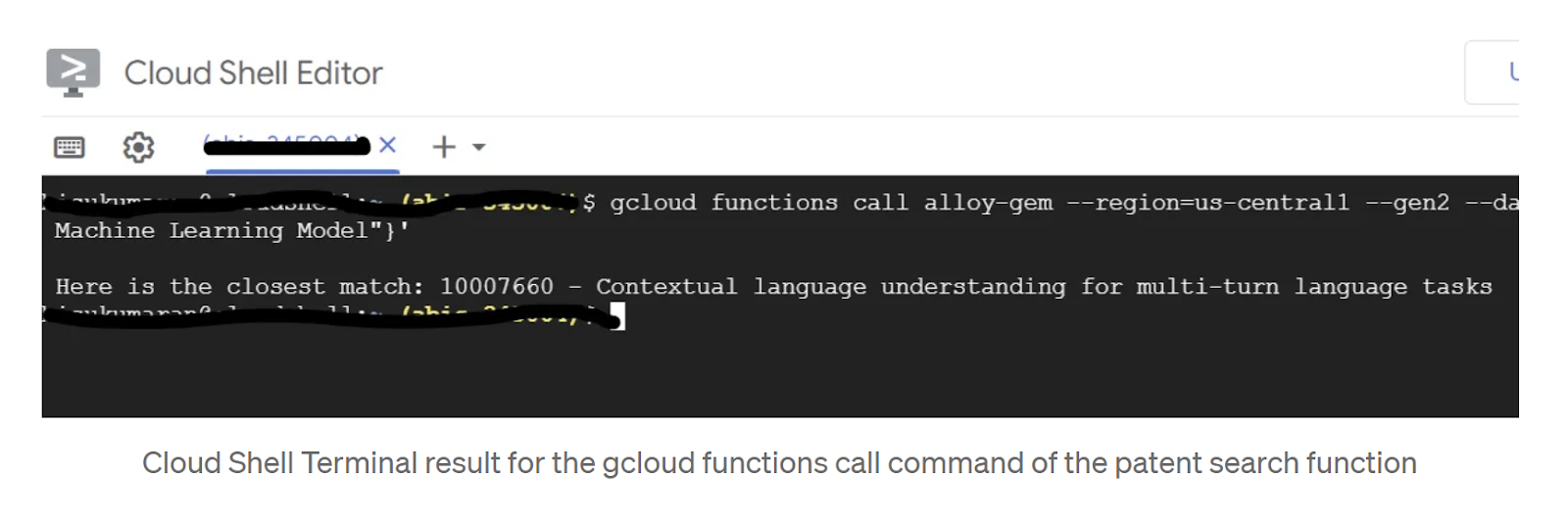
Vous pouvez le tester à partir du terminal Cloud Shell en exécutant la commande suivante :
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
Résultat :
Vous pouvez également le tester à partir de la liste Cloud Functions. Sélectionnez la fonction déployée et accédez à l'onglet "TEST". Dans la zone de texte de la section "Configurer l'événement déclencheur" pour la requête JSON, saisissez ce qui suit :
{"search": "A new Natural Language Processing related Machine Learning Model"}
Cliquez sur le bouton TESTER LA FONCTION. Le résultat s'affiche à droite de la page :

Et voilà ! Il est très simple d'effectuer une recherche vectorielle de similarité à l'aide du modèle Embeddings sur les données AlloyDB.
9. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les
- ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
10. Félicitations
Félicitations ! Vous avez effectué une recherche de similarité à l'aide d'AlloyDB, de pgvector et de la recherche vectorielle. En combinant les fonctionnalités de AlloyDB, Vertex AI et de la recherche vectorielle, nous avons fait un grand pas en avant pour rendre les recherches documentaires accessibles, efficaces et réellement axées sur le sens.