
1. ภาพรวม
ในแล็บนี้ คุณจะได้ใช้ Vertex AI เพื่อเรียกใช้งานการฝึกแบบหลายผู้ปฏิบัติงานสำหรับโมเดล TensorFlow
สิ่งที่คุณจะได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- แก้ไขโค้ดของแอปพลิเคชันการฝึกสำหรับการฝึกแบบหลายผู้ปฏิบัติงาน
- กำหนดค่าและเปิดใช้งานงานการฝึกแบบหลายผู้ปฏิบัติงานจาก UI ของ Vertex AI
- กำหนดค่าและเปิดใช้งานงานการฝึกแบบหลายเวิร์กเกอร์ด้วย Vertex SDK
ต้นทุนทั้งหมดในการเรียกใช้ Lab นี้ใน Google Cloud อยู่ที่ประมาณ $5
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
แล็บนี้ใช้ผลิตภัณฑ์ AI ใหม่ล่าสุดที่พร้อมให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้ากับประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้ โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่นี้จะรวมทั้ง 2 อย่างไว้ใน API เดียว พร้อมกับผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย หากมีข้อเสนอแนะ โปรดดูหน้าการสนับสนุน
Vertex AI มีผลิตภัณฑ์มากมายที่แตกต่างกันเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร Lab นี้จะมุ่งเน้นที่ผลิตภัณฑ์ที่ไฮไลต์ไว้ด้านล่าง ได้แก่ Training และ Workbench

3. ภาพรวมกรณีการใช้งาน
ในแล็บนี้ คุณจะได้ใช้การเรียนรู้แบบถ่ายโอนเพื่อฝึกโมเดลการแยกประเภทรูปภาพในชุดข้อมูลมันสำปะหลังจาก TensorFlow Datasets สถาปัตยกรรมที่คุณจะใช้คือโมเดล ResNet50 จากไลบรารี tf.keras.applications ที่ได้รับการฝึกมาก่อนในชุดข้อมูล Imagenet
เหตุใดจึงต้องใช้การฝึกแบบกระจาย
หากมี GPU เดียว TensorFlow จะใช้ตัวเร่งนี้เพื่อเพิ่มความเร็วในการฝึกโมเดลโดยที่คุณไม่ต้องดำเนินการใดๆ เพิ่มเติม อย่างไรก็ตาม หากต้องการเพิ่มประสิทธิภาพจากการใช้ GPU หลายตัวในเครื่องเดียวหรือหลายเครื่อง (แต่ละเครื่องอาจมี GPU หลายตัว) คุณจะต้องใช้ tf.distribute ซึ่งเป็นไลบรารีของ TensorFlow สำหรับการเรียกใช้การคำนวณในอุปกรณ์หลายเครื่อง อุปกรณ์หมายถึง CPU หรือตัวเร่ง เช่น GPU หรือ TPU ในเครื่องบางเครื่องที่ TensorFlow สามารถเรียกใช้การดำเนินการได้
วิธีที่ง่ายที่สุดในการเริ่มต้นการฝึกแบบกระจายคือการใช้เครื่องเดียวที่มีอุปกรณ์ GPU หลายเครื่อง กลยุทธ์การกระจาย TensorFlow จากโมดูล tf.distribute จะจัดการการประสานงานของการกระจายข้อมูลและการอัปเดตการไล่ระดับสีใน GPU ทั้งหมด หากคุณเชี่ยวชาญการฝึกแบบโฮสต์เดียวและต้องการขยายขนาดให้มากยิ่งขึ้น การเพิ่มเครื่องหลายเครื่องลงในคลัสเตอร์จะช่วยเพิ่มประสิทธิภาพได้มากยิ่งขึ้น คุณใช้คลัสเตอร์ของเครื่องที่ใช้ CPU เท่านั้น หรือเครื่องที่มี GPU อย่างน้อย 1 ตัวก็ได้ แล็บนี้จะครอบคลุมกรณีหลังและแสดงวิธีใช้ MultiWorkerMirroredStrategy เพื่อกระจายการฝึกโมเดล TensorFlow ในหลายๆ เครื่องบน Vertex AI
MultiWorkerMirroredStrategy เป็นกลยุทธ์การขนานข้อมูลแบบซิงโครนัสที่คุณใช้ได้โดยมีการเปลี่ยนแปลงโค้ดเพียงเล็กน้อย ระบบจะสร้างสำเนาของโมเดลในแต่ละอุปกรณ์ในคลัสเตอร์ การอัปเดตกราเดียนต์ครั้งต่อๆ ไปจะเกิดขึ้นแบบซิงโครนัส ซึ่งหมายความว่าอุปกรณ์ของผู้ปฏิบัติงานแต่ละเครื่องจะคำนวณการส่งต่อและการส่งย้อนผ่านโมเดลในอินพุตข้อมูลที่แตกต่างกัน จากนั้นระบบจะรวบรวมการไล่ระดับสีที่คำนวณแล้วจากแต่ละส่วนเหล่านี้ในอุปกรณ์ทั้งหมดบนเครื่องและเครื่องทั้งหมดในคลัสเตอร์ แล้วลด (โดยปกติคือค่าเฉลี่ย) ในกระบวนการที่เรียกว่าการลดทั้งหมด จากนั้นเครื่องมือเพิ่มประสิทธิภาพจะอัปเดตพารามิเตอร์ด้วยการไล่ระดับที่ลดลงเหล่านี้ ซึ่งจะช่วยให้อุปกรณ์ซิงค์กันอยู่เสมอ ดูข้อมูลเพิ่มเติมเกี่ยวกับการฝึกแบบกระจายด้วย TensorFlow ได้ในวิดีโอด้านล่าง
4. ตั้งค่าสภาพแวดล้อม
คุณจะต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้ Codelab นี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตามวิธีการที่นี่
ขั้นตอนที่ 1: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ คุณจะต้องใช้ข้อมูลนี้เพื่อสร้างอินสแตนซ์ Notebook
ขั้นตอนที่ 2: เปิดใช้ Container Registry API
ไปที่ Container Registry แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ คุณจะใช้สิ่งนี้เพื่อสร้างคอนเทนเนอร์สำหรับงานการฝึกที่กำหนดเอง
ขั้นตอนที่ 3: เปิดใช้ Vertex AI API
ไปที่ส่วน Vertex AI ของ Cloud Console แล้วคลิกเปิดใช้ Vertex AI API

ขั้นตอนที่ 4: สร้างอินสแตนซ์ Vertex AI Workbench
จากส่วน Vertex AI ของ Cloud Console ให้คลิก Workbench
เปิดใช้ Notebooks API หากยังไม่ได้เปิด

เมื่อเปิดใช้แล้ว ให้คลิก MANAGED NOTEBOOKS

จากนั้นเลือก NOTEBOOK ใหม่

ตั้งชื่อ Notebook แล้วคลิกการตั้งค่าขั้นสูง

ในการตั้งค่าขั้นสูง ให้เปิดใช้การปิดเครื่องเมื่อไม่มีการใช้งานและตั้งค่าจำนวนนาทีเป็น 60 ซึ่งหมายความว่า Notebook จะปิดโดยอัตโนมัติเมื่อไม่มีการใช้งาน เพื่อให้คุณไม่ต้องเสียค่าใช้จ่ายที่ไม่จำเป็น

ในส่วนความปลอดภัย ให้เลือก "เปิดใช้เทอร์มินัล" หากยังไม่ได้เปิดใช้

คุณปล่อยให้การตั้งค่าขั้นสูงอื่นๆ ทั้งหมดเป็นไปตามเดิมได้
จากนั้นคลิกสร้าง ระบบจะใช้เวลา 2-3 นาทีในการจัดสรรอินสแตนซ์
เมื่อสร้างอินสแตนซ์แล้ว ให้เลือกเปิด JupyterLab

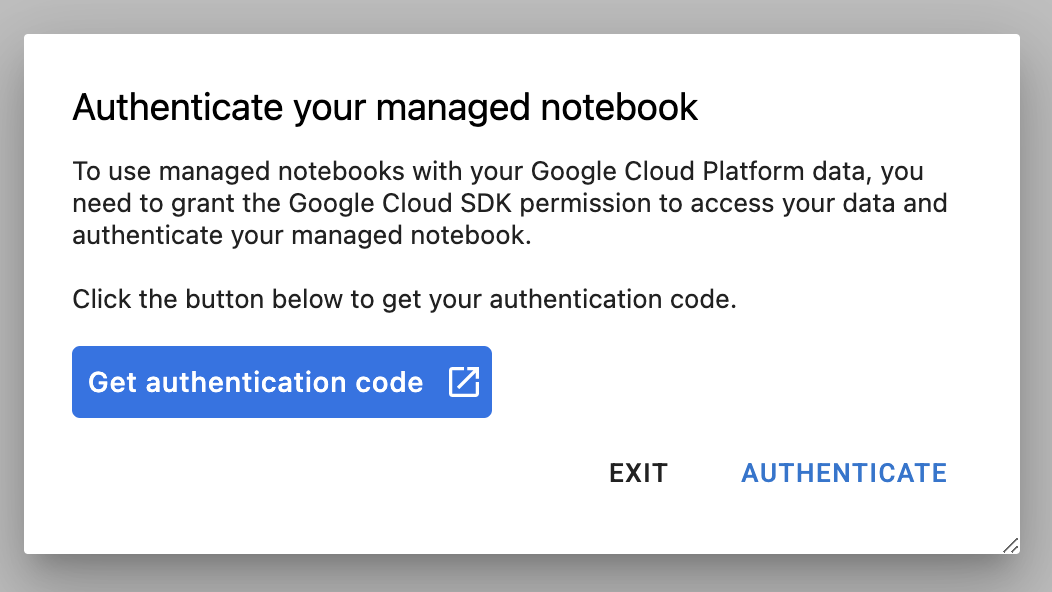
ครั้งแรกที่ใช้อินสแตนซ์ใหม่ ระบบจะขอให้คุณตรวจสอบสิทธิ์ ทำตามขั้นตอนใน UI เพื่อดำเนินการดังกล่าว
5. สร้างคอนเทนเนอร์โค้ดของแอปพลิเคชันการฝึก
คุณจะส่งงานการฝึกนี้ไปยัง Vertex โดยใส่โค้ดของแอปพลิเคชันการฝึกในคอนเทนเนอร์ Docker แล้วพุชคอนเทนเนอร์นี้ไปยัง Google Container Registry เมื่อใช้วิธีนี้ คุณจะฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้
หากต้องการเริ่มต้น ให้เปิดหน้าต่างเทอร์มินัลในอินสแตนซ์ Notebook จากเมนู Launcher โดยทำดังนี้

สร้างไดเรกทอรีใหม่ชื่อ cassava แล้วใช้คำสั่ง cd เพื่อเข้าไปในไดเรกทอรีดังกล่าว
mkdir cassava
cd cassava
ขั้นตอนที่ 1: สร้าง Dockerfile
ขั้นตอนแรกในการทำโค้ดให้เป็นคอนเทนเนอร์คือการสร้าง Dockerfile ใน Dockerfile คุณจะต้องใส่คำสั่งทั้งหมดที่จำเป็นในการเรียกใช้อิมเมจ โดยจะติดตั้งไลบรารีที่จำเป็นทั้งหมดและตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก
สร้าง Dockerfile ที่ว่างเปล่าจากเทอร์มินัลโดยทำดังนี้
touch Dockerfile
เปิด Dockerfile แล้วคัดลอกข้อมูลต่อไปนี้ลงในไฟล์
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile นี้ใช้อิมเมจ Docker ของ GPU สำหรับ TensorFlow Enterprise 2.7 ใน Deep Learning Container คอนเทนเนอร์การเรียนรู้เชิงลึกใน Google Cloud มาพร้อมกับเฟรมเวิร์ก ML และวิทยาศาสตร์ข้อมูลทั่วไปหลายรายการที่ติดตั้งไว้ล่วงหน้า หลังจากดาวน์โหลดอิมเมจนั้นแล้ว Dockerfile นี้จะตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก คุณยังไม่ได้สร้างไฟล์เหล่านี้ ในขั้นตอนถัดไป คุณจะเพิ่มโค้ดสำหรับการฝึกและปรับแต่งโมเดล
ขั้นตอนที่ 2: สร้าง Bucket ของ Cloud Storage
ในงานการฝึกนี้ คุณจะส่งออกโมเดล TensorFlow ที่ผ่านการฝึกไปยัง Bucket ของ Cloud Storage จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ของคุณ โดยอย่าลืมแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์ของคุณ
PROJECT_ID='your-cloud-project'
จากนั้นเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างที่เก็บข้อมูลใหม่ในโปรเจ็กต์
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
ขั้นตอนที่ 3: เพิ่มโค้ดการฝึกโมเดล
จากเทอร์มินัล ให้รันคำสั่งต่อไปนี้เพื่อสร้างไดเรกทอรีสำหรับโค้ดการฝึกและไฟล์ Python ที่คุณจะเพิ่มโค้ด
mkdir trainer
touch trainer/task.py
ตอนนี้คุณควรมีรายการต่อไปนี้ในไดเรกทอรี cassava/
+ Dockerfile
+ trainer/
+ task.py
จากนั้นเปิดไฟล์ task.py ที่เพิ่งสร้างและคัดลอกโค้ดด้านล่าง คุณจะต้องแทนที่ {your-gcs-bucket} ด้วยชื่อของ Bucket ของ Cloud Storage ที่คุณเพิ่งสร้าง
import tensorflow as tf
import tensorflow_datasets as tfds
import os
PER_REPLICA_BATCH_SIZE = 64
EPOCHS = 2
# TODO: replace {your-gcs-bucket} with the name of the Storage bucket you created earlier
BUCKET = 'gs://{your-gcs-bucket}/mwms'
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
def create_dataset(batch_size):
'''Loads Cassava dataset and preprocesses data.'''
data, info = tfds.load(name='cassava', as_supervised=True, with_info=True)
number_of_classes = info.features['label'].num_classes
train_data = data['train'].map(preprocess_data,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(batch_size)
train_data = train_data.prefetch(tf.data.experimental.AUTOTUNE)
# Set AutoShardPolicy
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
return train_data, number_of_classes
def create_model(number_of_classes):
'''Creates and compiles pretrained ResNet50 model.'''
base_model = tf.keras.applications.ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(1016, activation='relu')(x)
predictions = tf.keras.layers.Dense(number_of_classes, activation='softmax')(x)
model = tf.keras.Model(inputs=base_model.input, outputs=predictions)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
global_batch_size = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
train_data, number_of_classes = create_dataset(global_batch_size)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model(number_of_classes)
model.fit(train_data, epochs=EPOCHS)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(BUCKET, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
ก่อนสร้างคอนเทนเนอร์ เรามาดูโค้ดอย่างละเอียดกัน ซึ่งใช้ MultiWorkerMirroredStrategy จาก tf.distribute.Strategy API
โค้ดมีคอมโพเนนต์บางอย่างที่จำเป็นเพื่อให้โค้ดทำงานร่วมกับ MultiWorkerMirroredStrategy ได้
- ต้องมีการแบ่งข้อมูล ซึ่งหมายความว่าผู้ปฏิบัติงานแต่ละคนจะได้รับมอบหมายชุดข้อมูลย่อยของชุดข้อมูลทั้งหมด ดังนั้นในแต่ละขั้นตอน Worker แต่ละตัวจะประมวลผลขนาดกลุ่มทั่วโลกขององค์ประกอบชุดข้อมูลที่ไม่ทับซ้อนกัน การแบ่งข้อมูลนี้จะเกิดขึ้นโดยอัตโนมัติด้วย
tf.data.experimental.AutoShardPolicyซึ่งตั้งค่าเป็นFILEหรือDATAได้ ในตัวอย่างนี้ ฟังก์ชันcreate_dataset()จะตั้งค่าAutoShardPolicyเป็นDATAเนื่องจากไม่ได้ดาวน์โหลดชุดข้อมูลมันสำปะหลังเป็นหลายไฟล์ อย่างไรก็ตาม หากคุณไม่ได้ตั้งค่านโยบายเป็นDATAนโยบายAUTOเริ่มต้นจะทำงานและผลลัพธ์สุดท้ายจะเหมือนกัน ดูข้อมูลเพิ่มเติมเกี่ยวกับการแบ่งข้อมูลชุดข้อมูลด้วยMultiWorkerMirroredStrategyได้ที่นี่ - ในฟังก์ชัน
main()ระบบจะสร้างออบเจ็กต์MultiWorkerMirroredStrategyจากนั้น คุณจะรวมการสร้างตัวแปรโมเดลไว้ภายในขอบเขตของกลยุทธ์ ขั้นตอนนี้มีความสำคัญอย่างยิ่งเนื่องจากจะบอก TensorFlow ว่าควรทำสำเนาตัวแปรใดในรีพลิกา num_replicas_in_syncจะเพิ่มขนาดกลุ่ม ซึ่งจะช่วยให้มั่นใจได้ว่าแต่ละสำเนาจะประมวลผลตัวอย่างจำนวนเท่ากันในแต่ละขั้นตอน การปรับขนาดกลุ่มเป็นแนวทางปฏิบัติแนะนำเมื่อใช้กลยุทธ์การขนานข้อมูลแบบซิงโครนัสใน TensorFlow- การบันทึกโมเดลในกรณีที่มี Worker หลายรายจะซับซ้อนกว่าเล็กน้อย เนื่องจากปลายทางต้องแตกต่างกันสำหรับ Worker แต่ละราย โดยหัวหน้าคนงานจะบันทึกลงในไดเรกทอรีโมเดลที่ต้องการ ส่วนคนงานอื่นๆ จะบันทึกโมเดลลงในไดเรกทอรีชั่วคราว ไดเรกทอรีชั่วคราวเหล่านี้ต้องไม่ซ้ำกันเพื่อป้องกันไม่ให้ Worker หลายคนเขียนไปยังตำแหน่งเดียวกัน การบันทึกอาจมีการดำเนินการร่วมกัน ซึ่งหมายความว่าคนงานทุกคนต้องบันทึก ไม่ใช่แค่หัวหน้า ฟังก์ชัน
_is_chief(),_get_temp_dir(),write_filepath()รวมถึงฟังก์ชันmain()มีโค้ด Boilerplate ที่ช่วยบันทึกโมเดล
โปรดทราบว่าหากคุณเคยใช้ MultiWorkerMirroredStrategy ในสภาพแวดล้อมอื่น คุณอาจได้ตั้งค่าตัวแปรสภาพแวดล้อม TF_CONFIG ไว้แล้ว Vertex AI จะตั้งค่า TF_CONFIG ให้คุณโดยอัตโนมัติ คุณจึงไม่จำเป็นต้องกำหนดตัวแปรนี้ในแต่ละเครื่องในคลัสเตอร์
ขั้นตอนที่ 4: สร้างคอนเทนเนอร์
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ของคุณ โดยอย่าลืมแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์ของคุณ
PROJECT_ID='your-cloud-project'
กำหนดตัวแปรด้วย URI ของอิมเมจคอนเทนเนอร์ใน Google Container Registry ดังนี้
IMAGE_URI="gcr.io/$PROJECT_ID/multiworker:cassava"
กำหนดค่า Docker
gcloud auth configure-docker
จากนั้นสร้างคอนเทนเนอร์โดยเรียกใช้คำสั่งต่อไปนี้จากรูทของไดเรกทอรี cassava
docker build ./ -t $IMAGE_URI
สุดท้าย ให้พุชไปยัง Google Container Registry โดยใช้คำสั่งต่อไปนี้
docker push $IMAGE_URI
เมื่อพุชคอนเทนเนอร์ไปยัง Container Registry แล้ว คุณก็พร้อมที่จะเริ่มงานการฝึกแล้ว
6. เรียกใช้งานการฝึกแบบหลายผู้ปฏิบัติงานใน Vertex AI
แล็บนี้ใช้การฝึกที่กำหนดเองผ่านคอนเทนเนอร์ที่กำหนดเองใน Google Container Registry แต่คุณยังเรียกใช้การฝึกด้วยคอนเทนเนอร์ที่สร้างไว้ล่วงหน้าได้ด้วย
หากต้องการเริ่มต้นใช้งาน ให้ไปที่ส่วนการฝึกในส่วน Vertex ของคอนโซล Cloud

ขั้นตอนที่ 1: กำหนดค่างานการฝึก
คลิกสร้างเพื่อป้อนพารามิเตอร์สำหรับงานการฝึก
- ในส่วนชุดข้อมูล ให้เลือกไม่มีชุดข้อมูลที่มีการจัดการ
- จากนั้นเลือกการฝึกแบบกำหนดเอง (ขั้นสูง) เป็นวิธีการฝึก แล้วคลิกต่อไป
- ป้อน
multiworker-cassava(หรือชื่อโมเดลที่คุณต้องการ) สำหรับชื่อโมเดล - คลิกต่อไป
ในขั้นตอนการตั้งค่าคอนเทนเนอร์ ให้เลือกคอนเทนเนอร์ที่กำหนดเอง

ในช่องแรก (อิมเมจคอนเทนเนอร์) ให้ป้อนค่าของตัวแปร IMAGE_URI จากส่วนก่อนหน้า โดยควรมีลักษณะดังนี้ gcr.io/your-cloud-project/multiworker:cassava โดยใช้รหัสโปรเจ็กต์ของคุณเอง เว้นช่องที่เหลือว่างไว้ แล้วคลิกดำเนินการต่อ
ข้ามขั้นตอนไฮเปอร์พารามิเตอร์โดยคลิกต่อไปอีกครั้ง
ขั้นตอนที่ 2: กำหนดค่าคลัสเตอร์การประมวลผล
Vertex AI มีพูลผู้ปฏิบัติงาน 4 รายการเพื่อครอบคลุมงานประเภทต่างๆ ของเครื่อง
Worker pool 0 กำหนดค่า Primary, chief, scheduler หรือ "master" ใน MultiWorkerMirroredStrategy เครื่องทั้งหมดจะได้รับการกำหนดให้เป็นเครื่องปฏิบัติงาน ซึ่งเป็นเครื่องจริงที่ใช้ดำเนินการคำนวณที่จำลอง นอกจากเครื่องแต่ละเครื่องจะเป็น Worker แล้ว ยังต้องมี Worker หนึ่งเครื่องที่รับงานเพิ่มเติม เช่น การบันทึกจุดตรวจสอบและการเขียนไฟล์สรุปไปยัง TensorBoard เครื่องนี้เรียกว่า "หัวหน้า" มีผู้ปฏิบัติงานหลักเพียงคนเดียวเสมอ ดังนั้นจำนวนผู้ปฏิบัติงานสำหรับพูลผู้ปฏิบัติงาน 0 จะเป็น 1 เสมอ
ในการประมวลผลและราคา ให้ปล่อยภูมิภาคที่เลือกไว้ตามเดิม แล้วกำหนดค่าพูลผู้ปฏิบัติงาน 0 ดังนี้

พูลผู้ปฏิบัติงาน 1 คือที่ที่คุณกำหนดค่าผู้ปฏิบัติงานสำหรับคลัสเตอร์
กำหนดค่าพูลผู้ปฏิบัติงาน 1 ดังนี้

ตอนนี้คลัสเตอร์ได้รับการกำหนดค่าให้มีเครื่องที่ใช้ CPU เพียง 2 เครื่อง เมื่อเรียกใช้โค้ดของแอปพลิเคชันการฝึก MultiWorkerMirroredStrategy จะกระจายการฝึกในเครื่องทั้ง 2 เครื่อง
MultiWorkerMirroredStrategy มีเฉพาะประเภทงานหัวหน้าและงานผู้ปฏิบัติงาน จึงไม่จำเป็นต้องกำหนดค่า Worker Pool เพิ่มเติม แต่หากคุณใช้ ParameterServerStrategy ของ TensorFlow คุณจะต้องกำหนดค่าเซิร์ฟเวอร์พารามิเตอร์ในกลุ่มผู้ปฏิบัติงาน 2 และหากต้องการเพิ่มผู้ประเมินลงในคลัสเตอร์ คุณจะต้องกำหนดค่าเครื่องนั้นในพูลผู้ปฏิบัติงาน 3
คลิกเริ่มการฝึกเพื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์ ในส่วนการฝึกของคอนโซลภายใต้แท็บ TRAINING PIPELINES คุณจะเห็นงานที่เพิ่งเปิดตัวใหม่

🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้
- เปิดใช้งานงานการฝึกแบบหลายเวิร์กเกอร์สำหรับโค้ดการฝึกที่ระบุไว้ในคอนเทนเนอร์ที่กำหนดเอง คุณใช้โมเดล TensorFlow ในตัวอย่างนี้ แต่สามารถฝึกโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้โดยใช้คอนเทนเนอร์ที่กำหนดเองหรือคอนเทนเนอร์ในตัว
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex ได้ที่เอกสารประกอบ
7. [ไม่บังคับ] ใช้ Vertex SDK
ส่วนก่อนหน้าแสดงวิธีเปิดใช้งานงานการฝึกผ่าน UI ในส่วนนี้ คุณจะเห็นวิธีอื่นในการส่งงานการฝึกโดยใช้ Vertex Python API
กลับไปที่อินสแตนซ์ Notebook แล้วสร้าง Notebook TensorFlow 2 จาก Launcher โดยทำดังนี้

นำเข้า Vertex AI SDK
from google.cloud import aiplatform
หากต้องการเปิดใช้งานงานการฝึกแบบหลาย Worker คุณต้องกำหนดข้อกำหนดของ Worker Pool ก่อน โปรดทราบว่าการใช้ GPU ในข้อกำหนดนั้นเป็นทางเลือกโดยสมบูรณ์ และคุณสามารถนำ accelerator_type และ accelerator_count ออกได้หากต้องการคลัสเตอร์ CPU เท่านั้นตามที่แสดงในส่วนก่อนหน้า
# The spec of the worker pools including machine type and Docker image
# Be sure to replace {YOUR-PROJECT-ID} with your project ID.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
}
]
จากนั้นสร้างและเรียกใช้ CustomJob คุณจะต้องแทนที่ {YOUR_BUCKET} ด้วย Bucket ในโปรเจ็กต์สำหรับการจัดเตรียม คุณสามารถใช้ Bucket เดียวกันกับที่สร้างไว้ก่อนหน้านี้ได้
# Replace YOUR_BUCKET
my_multiworker_job = aiplatform.CustomJob(display_name='multiworker-cassava-sdk',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_multiworker_job.run()
ในส่วนการฝึกของคอนโซลใต้แท็บงานที่กำหนดเอง คุณจะเห็นงานการฝึก

8. ล้างข้อมูล
เนื่องจากเรากำหนดค่า Notebook ให้หมดเวลาหลังจากไม่มีการใช้งาน 60 นาที จึงไม่ต้องกังวลเรื่องการปิดอินสแตนซ์ หากต้องการปิดอินสแตนซ์ด้วยตนเอง ให้คลิกปุ่มหยุดในส่วน Vertex AI Workbench ของคอนโซล หากต้องการลบ Notebook ทั้งหมด ให้คลิกปุ่มลบ

หากต้องการลบ Storage Bucket ให้ใช้เมนูการนำทางใน Cloud Console ไปที่ Storage เลือก Bucket แล้วคลิกลบ
