1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ sử dụng Vertex AI để chạy một quy trình huấn luyện nhiều worker cho mô hình TensorFlow.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Sửa đổi mã xử lý ứng dụng huấn luyện để huấn luyện nhiều worker
- Định cấu hình và chạy một quy trình huấn luyện nhiều worker từ giao diện người dùng Vertex AI
- Định cấu hình và chạy một quy trình huấn luyện nhiều worker bằng Vertex SDK
Tổng chi phí để chạy bài tập này trên Google Cloud là khoảng 5 USD.
2. Giới thiệu về Vertex AI
Phòng thí nghiệm này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm ML trên Google Cloud thành một trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI. Nếu bạn có ý kiến phản hồi, vui lòng truy cập trang hỗ trợ.
Vertex AI có nhiều sản phẩm để hỗ trợ quy trình làm việc ML toàn diện. Phòng thí nghiệm này sẽ tập trung vào các sản phẩm được làm nổi bật bên dưới: Training và Workbench

3. Tổng quan về trường hợp sử dụng
Trong phòng thí nghiệm này, bạn sẽ sử dụng phương pháp học chuyển giao để huấn luyện một mô hình phân loại hình ảnh trên tập dữ liệu sắn từ Tập dữ liệu TensorFlow. Cấu trúc mà bạn sẽ sử dụng là mô hình ResNet50 từ thư viện tf.keras.applications được huấn luyện trước trên tập dữ liệu Imagenet.
Tại sao nên sử dụng tính năng Huấn luyện theo kiểu phân tán?
Nếu bạn có một GPU, TensorFlow sẽ sử dụng trình tăng tốc này để tăng tốc quá trình huấn luyện mô hình mà bạn không cần phải làm gì thêm. Tuy nhiên, nếu muốn tăng hiệu suất bằng cách sử dụng nhiều GPU trên một máy hoặc nhiều máy (mỗi máy có thể có nhiều GPU), thì bạn cần sử dụng tf.distribute. Đây là thư viện của TensorFlow để chạy một phép tính trên nhiều thiết bị. Thiết bị là một CPU hoặc bộ tăng tốc, chẳng hạn như GPU hoặc TPU, trên một số máy mà TensorFlow có thể chạy các hoạt động.
Cách đơn giản nhất để bắt đầu với quy trình huấn luyện phân tán là sử dụng một máy duy nhất có nhiều thiết bị GPU. Một chiến lược phân phối TensorFlow từ mô-đun tf.distribute sẽ quản lý việc điều phối hoạt động phân phối dữ liệu và cập nhật độ dốc trên tất cả các GPU. Nếu bạn đã nắm vững quy trình huấn luyện trên một máy chủ và muốn mở rộng quy mô hơn nữa, thì việc thêm nhiều máy vào cụm có thể giúp bạn tăng hiệu suất hơn nữa. Bạn có thể sử dụng một cụm máy chỉ có CPU hoặc mỗi máy có một hoặc nhiều GPU. Phòng thí nghiệm này đề cập đến trường hợp thứ hai và minh hoạ cách sử dụng MultiWorkerMirroredStrategy để phân phối quá trình huấn luyện một mô hình TensorFlow trên nhiều máy trên Vertex AI.
MultiWorkerMirroredStrategy là một chiến lược song song hoá dữ liệu đồng bộ mà bạn có thể sử dụng chỉ với một vài thay đổi về mã. Một bản sao của mô hình sẽ được tạo trên mỗi thiết bị trong cụm của bạn. Các bản cập nhật độ dốc tiếp theo sẽ diễn ra theo cách đồng bộ. Điều này có nghĩa là mỗi thiết bị worker sẽ tính toán các lượt truyền xuôi và truyền ngược thông qua mô hình trên một phần dữ liệu đầu vào khác. Sau đó, các độ dốc được tính toán từ mỗi lát cắt này sẽ được tổng hợp trên tất cả các thiết bị trên một máy và tất cả các máy trong cụm, đồng thời được giảm (thường là giá trị trung bình) trong một quy trình được gọi là giảm tất cả. Sau đó, trình tối ưu hoá sẽ thực hiện các bản cập nhật tham số với các độ dốc giảm này, nhờ đó giữ cho các thiết bị được đồng bộ hoá. Để tìm hiểu thêm về hoạt động huấn luyện phân tán bằng TensorFlow, hãy xem video bên dưới:
4. Thiết lập môi trường
Bạn cần có một dự án trên Google Cloud Platform đã bật tính năng thanh toán để chạy lớp học lập trình này. Để tạo một dự án, hãy làm theo hướng dẫn tại đây.
Bước 1: Bật Compute Engine API
Chuyển đến Compute Engine rồi chọn Bật nếu bạn chưa bật. Bạn sẽ cần thông tin này để tạo thực thể sổ tay.
Bước 2: Bật Container Registry API
Chuyển đến Container Registry rồi chọn Bật nếu bạn chưa bật. Bạn sẽ dùng thông tin này để tạo một vùng chứa cho công việc huấn luyện tuỳ chỉnh.
Bước 3: Bật Vertex AI API
Chuyển đến mục Vertex AI trong Bảng điều khiển Cloud rồi nhấp vào Bật Vertex AI API.

Bước 4: Tạo một phiên bản Vertex AI Workbench
Trong phần Vertex AI của Cloud Console, hãy nhấp vào Workbench:

Bật Notebooks API nếu bạn chưa bật.

Sau khi bật, hãy nhấp vào MANAGED NOTEBOOKS (SỔ TAY ĐƯỢC QUẢN LÝ):

Sau đó, chọn SỔ TAY MỚI.

Đặt tên cho sổ tay của bạn, sau đó nhấp vào Cài đặt nâng cao.

Trong phần Cài đặt nâng cao, hãy bật chế độ tắt khi không hoạt động và đặt số phút thành 60. Điều này có nghĩa là sổ tay của bạn sẽ tự động tắt khi không sử dụng để bạn không phải chịu các chi phí không cần thiết.

Trong phần Bảo mật, hãy chọn "Bật thiết bị đầu cuối" nếu bạn chưa bật.

Bạn có thể giữ nguyên tất cả các chế độ cài đặt nâng cao khác.
Tiếp theo, hãy nhấp vào Tạo. Thực thể sẽ mất vài phút để được cấp phép.
Sau khi tạo phiên bản, hãy chọn Mở JupyterLab.

Vào lần đầu tiên sử dụng một phiên bản mới, bạn sẽ được yêu cầu xác thực. Làm theo các bước trong giao diện người dùng để thực hiện việc này.
5. Đóng gói mã xử lý ứng dụng huấn luyện vào vùng chứa
Bạn sẽ gửi công việc huấn luyện này đến Vertex bằng cách đặt mã xử lý ứng dụng huấn luyện vào một vùng chứa Docker và đẩy vùng chứa này đến Google Container Registry. Bằng cách sử dụng phương pháp này, bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào.
Để bắt đầu, từ trình đơn Trình chạy, hãy mở cửa sổ dòng lệnh trong phiên bản sổ tay của bạn:

Tạo một thư mục mới có tên là cassava rồi chuyển đến thư mục đó:
mkdir cassava
cd cassava
Bước 1: Tạo một Dockerfile
Bước đầu tiên trong việc chứa mã của bạn là tạo một Dockerfile. Trong Dockerfile, bạn sẽ đưa tất cả các lệnh cần thiết để chạy hình ảnh. Thao tác này sẽ cài đặt tất cả các thư viện cần thiết và thiết lập điểm truy cập cho mã huấn luyện.
Trên thiết bị đầu cuối, hãy tạo một Dockerfile trống:
touch Dockerfile
Mở Dockerfile rồi sao chép nội dung sau vào đó:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-7
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Dockerfile này sử dụng Hình ảnh Docker GPU TensorFlow Enterprise 2.7 của Deep Learning Container. Deep Learning Containers trên Google Cloud được cài đặt sẵn nhiều khung học máy và khoa học dữ liệu phổ biến. Sau khi tải hình ảnh đó xuống, Dockerfile này sẽ thiết lập điểm truy cập cho mã huấn luyện. Bạn chưa tạo các tệp này. Ở bước tiếp theo, bạn sẽ thêm mã để huấn luyện và điều chỉnh mô hình.
Bước 2: Tạo một bộ chứa Cloud Storage
Trong quy trình huấn luyện này, bạn sẽ xuất mô hình TensorFlow đã huấn luyện sang một bộ chứa Cloud Storage. Trong Terminal, hãy chạy lệnh sau để xác định một biến môi trường cho dự án của bạn, nhớ thay thế your-cloud-project bằng mã dự án:
PROJECT_ID='your-cloud-project'
Tiếp theo, hãy chạy lệnh sau trong Terminal để tạo một nhóm mới trong dự án của bạn.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Bước 3: Thêm mã huấn luyện mô hình
Trong Terminal, hãy chạy lệnh sau để tạo một thư mục cho mã huấn luyện và một tệp Python nơi bạn sẽ thêm mã:
mkdir trainer
touch trainer/task.py
Bây giờ, bạn sẽ có những nội dung sau trong thư mục cassava/:
+ Dockerfile
+ trainer/
+ task.py
Tiếp theo, hãy mở tệp task.py bạn vừa tạo rồi sao chép mã bên dưới. Bạn cần thay thế {your-gcs-bucket} bằng tên của bộ chứa Cloud Storage mà bạn vừa tạo.
import tensorflow as tf
import tensorflow_datasets as tfds
import os
PER_REPLICA_BATCH_SIZE = 64
EPOCHS = 2
# TODO: replace {your-gcs-bucket} with the name of the Storage bucket you created earlier
BUCKET = 'gs://{your-gcs-bucket}/mwms'
def preprocess_data(image, label):
'''Resizes and scales images.'''
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
def create_dataset(batch_size):
'''Loads Cassava dataset and preprocesses data.'''
data, info = tfds.load(name='cassava', as_supervised=True, with_info=True)
number_of_classes = info.features['label'].num_classes
train_data = data['train'].map(preprocess_data,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_data = train_data.shuffle(1000)
train_data = train_data.batch(batch_size)
train_data = train_data.prefetch(tf.data.experimental.AUTOTUNE)
# Set AutoShardPolicy
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_data = train_data.with_options(options)
return train_data, number_of_classes
def create_model(number_of_classes):
'''Creates and compiles pretrained ResNet50 model.'''
base_model = tf.keras.applications.ResNet50(weights='imagenet', include_top=False)
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(1016, activation='relu')(x)
predictions = tf.keras.layers.Dense(number_of_classes, activation='softmax')(x)
model = tf.keras.Model(inputs=base_model.input, outputs=predictions)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.0001),
metrics=['accuracy'])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
global_batch_size = PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync
train_data, number_of_classes = create_dataset(global_batch_size)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model(number_of_classes)
model.fit(train_data, epochs=EPOCHS)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(BUCKET, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
Trước khi bạn tạo vùng chứa, hãy xem xét kỹ hơn mã này. Mã này sử dụng MultiWorkerMirroredStrategy từ API tf.distribute.Strategy.
Có một vài thành phần trong mã cần thiết để mã của bạn hoạt động với MultiWorkerMirroredStrategy.
- Dữ liệu cần được phân đoạn, tức là mỗi worker được chỉ định một tập hợp con của toàn bộ tập dữ liệu. Do đó, ở mỗi bước, mỗi worker sẽ xử lý một kích thước lô chung gồm các phần tử tập dữ liệu không chồng chéo. Quá trình phân đoạn này diễn ra tự động với
tf.data.experimental.AutoShardPolicy, có thể được đặt thànhFILEhoặcDATA. Trong ví dụ này, hàmcreate_dataset()đặtAutoShardPolicythànhDATAvì tập dữ liệu sắn không được tải xuống dưới dạng nhiều tệp. Tuy nhiên, nếu bạn không đặt chính sách thànhDATA, thì chính sáchAUTOmặc định sẽ có hiệu lực và kết quả cuối cùng sẽ giống nhau. Bạn có thể tìm hiểu thêm về phân đoạn tập dữ liệu bằngMultiWorkerMirroredStrategytại đây. - Trong hàm
main(), đối tượngMultiWorkerMirroredStrategyđược tạo. Tiếp theo, bạn sẽ bao bọc quá trình tạo các biến mô hình trong phạm vi của chiến lược. Bước quan trọng này cho TensorFlow biết những biến nào cần được phản chiếu trên các bản sao. - Kích thước lô được tăng lên theo
num_replicas_in_sync. Điều này đảm bảo rằng mỗi bản sao xử lý cùng một số lượng ví dụ ở mỗi bước. Chuyển tỉ lệ kích thước lô là một phương pháp hay nhất khi sử dụng các chiến lược song song hoá dữ liệu đồng bộ trong TensorFlow. - Việc lưu mô hình sẽ phức tạp hơn một chút trong trường hợp có nhiều worker vì đích đến cần phải khác nhau đối với mỗi worker. Worker chính sẽ lưu vào thư mục mô hình mong muốn, trong khi các worker khác sẽ lưu mô hình vào thư mục tạm thời. Điều quan trọng là các thư mục tạm thời này phải là duy nhất để ngăn nhiều worker ghi vào cùng một vị trí. Việc lưu có thể bao gồm các thao tác tập thể, nghĩa là tất cả các worker đều phải lưu chứ không chỉ worker chính. Các hàm
_is_chief(),_get_temp_dir(),write_filepath()cũng như hàmmain()đều có mã nguyên mẫu giúp lưu mô hình.
Xin lưu ý rằng nếu đã sử dụng MultiWorkerMirroredStrategy trong một môi trường khác, thì có thể bạn đã thiết lập biến môi trường TF_CONFIG. Vertex AI tự động đặt TF_CONFIG cho bạn, vì vậy bạn không cần xác định biến này trên mỗi máy trong cụm.
Bước 4: Tạo vùng chứa
Trong Terminal, hãy chạy lệnh sau để xác định một biến môi trường cho dự án của bạn, nhớ thay thế your-cloud-project bằng mã dự án:
PROJECT_ID='your-cloud-project'
Xác định một biến bằng URI của hình ảnh vùng chứa trong Google Container Registry:
IMAGE_URI="gcr.io/$PROJECT_ID/multiworker:cassava"
Định cấu hình docker
gcloud auth configure-docker
Sau đó, hãy tạo vùng chứa bằng cách chạy lệnh sau từ gốc của thư mục cassava:
docker build ./ -t $IMAGE_URI
Cuối cùng, hãy đẩy nó vào Google Container Registry:
docker push $IMAGE_URI
Sau khi đẩy vùng chứa lên Container Registry, bạn đã sẵn sàng bắt đầu một quy trình huấn luyện.
6. Chạy một quy trình huấn luyện nhiều worker trên Vertex AI
Phòng thí nghiệm này sử dụng hoạt động huấn luyện tuỳ chỉnh thông qua một vùng chứa tuỳ chỉnh trên Google Container Registry, nhưng bạn cũng có thể chạy một công việc huấn luyện bằng các vùng chứa được tạo sẵn.
Để bắt đầu, hãy chuyển đến phần Huấn luyện trong phần Vertex của bảng điều khiển Cloud:

Bước 1: Định cấu hình quy trình huấn luyện
Nhấp vào Tạo để nhập các tham số cho công việc huấn luyện của bạn.
- Trong mục Tập dữ liệu, hãy chọn Không có tập dữ liệu được quản lý
- Sau đó, hãy chọn Khoá huấn luyện tuỳ chỉnh (nâng cao) làm phương pháp huấn luyện rồi nhấp vào Tiếp tục.
- Nhập
multiworker-cassava(hoặc tên bất kỳ mà bạn muốn đặt cho mô hình) cho Tên mô hình - Nhấp vào Tiếp tục
Trong bước Cài đặt vùng chứa, hãy chọn Vùng chứa tuỳ chỉnh:

Trong hộp đầu tiên (Hình ảnh vùng chứa), hãy nhập giá trị của biến IMAGE_URI trong phần trước. Đó phải là: gcr.io/your-cloud-project/multiworker:cassava, với mã dự án của riêng bạn. Để trống các trường còn lại rồi nhấp vào Tiếp tục.
Bỏ qua bước Siêu tham số bằng cách nhấp vào Tiếp tục một lần nữa.
Bước 2: Định cấu hình cụm tính toán
Vertex AI cung cấp 4 nhóm worker để xử lý các loại tác vụ máy khác nhau.
Nhóm nhân viên 0 định cấu hình Primary, chief, scheduler hoặc "master". Trong MultiWorkerMirroredStrategy, tất cả các máy đều được chỉ định là worker, tức là các máy vật lý mà trên đó quá trình tính toán được sao chép sẽ được thực thi. Ngoài mỗi máy là một worker, cần có một worker đảm nhận thêm một số công việc như lưu điểm kiểm tra và ghi tệp tóm tắt vào TensorBoard. Máy này được gọi là máy chủ. Chỉ có một nhân viên chính, vì vậy số lượng nhân viên cho nhóm nhân viên 0 sẽ luôn là 1.
Trong phần Compute and pricing (Điện toán và giá), hãy giữ nguyên khu vực đã chọn và định cấu hình Worker pool 0 (Nhóm worker 0) như sau:

Nhóm worker 1 là nơi bạn định cấu hình các worker cho cụm.
Định cấu hình Nhóm worker 1 như sau:
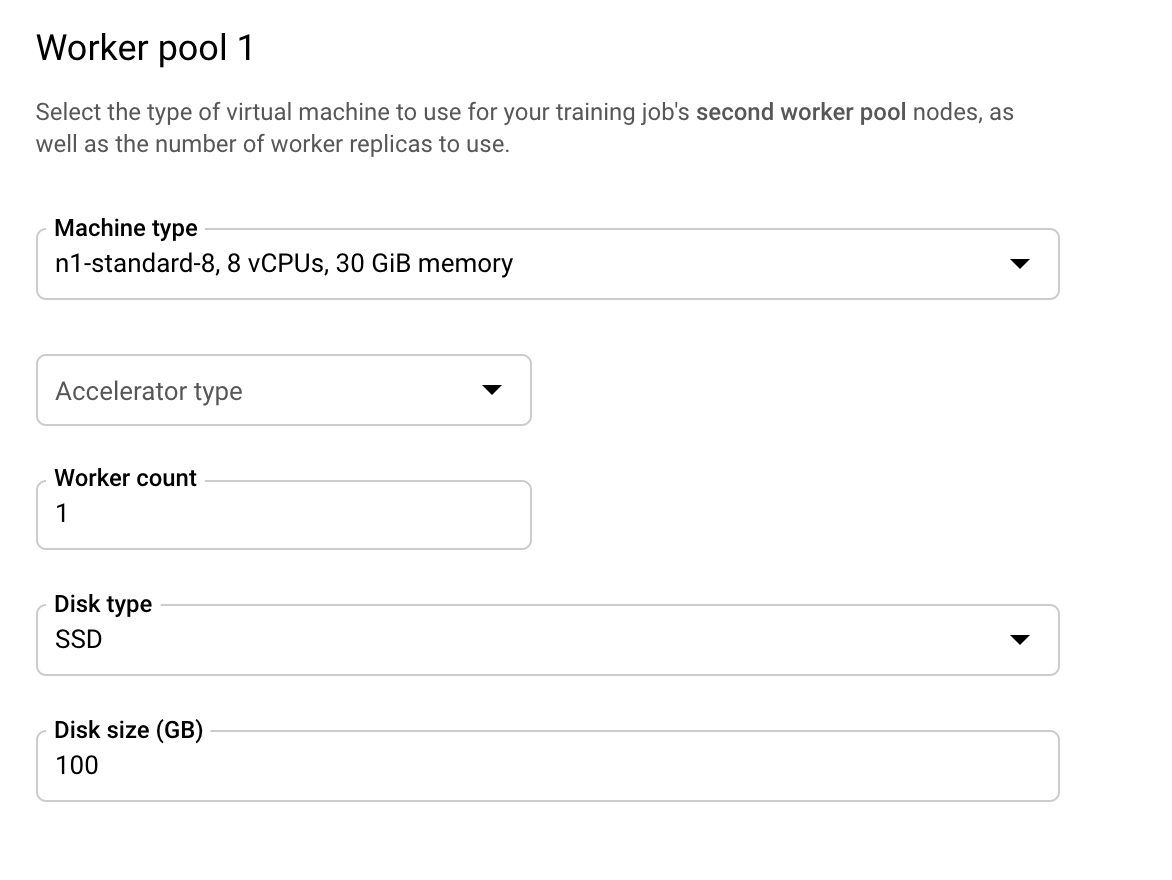
Cụm hiện được định cấu hình để chỉ có 2 máy CPU. Khi mã xử lý ứng dụng huấn luyện được chạy, MultiWorkerMirroredStrategy sẽ phân phối quá trình huấn luyện trên cả hai máy.
MultiWorkerMirroredStrategy chỉ có các loại tác vụ chính và tác vụ của nhân viên, nên bạn không cần định cấu hình Nhóm nhân viên bổ sung. Tuy nhiên, nếu sử dụng ParameterServerStrategy của TensorFlow, bạn sẽ định cấu hình các máy chủ tham số trong nhóm worker 2. Và nếu muốn thêm một trình đánh giá vào cụm, bạn sẽ định cấu hình máy đó trong nhóm worker 3.
Nhấp vào Start training (Bắt đầu huấn luyện) để bắt đầu công việc điều chỉnh siêu tham số. Trong phần Đào tạo của bảng điều khiển, bạn sẽ thấy công việc mới khởi chạy trong thẻ TRAINING PIPELINES (PIPELINE ĐÀO TẠO):

🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI để:
- Chạy một công việc huấn luyện nhiều worker cho mã huấn luyện được cung cấp trong một vùng chứa tuỳ chỉnh. Bạn đã sử dụng một mô hình TensorFlow trong ví dụ này, nhưng bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào bằng cách sử dụng các vùng chứa tuỳ chỉnh hoặc vùng chứa tích hợp.
Để tìm hiểu thêm về các phần khác nhau của Vertex, hãy xem tài liệu.
7. [Không bắt buộc] Sử dụng Vertex SDK
Phần trước đã hướng dẫn cách chạy quy trình huấn luyện thông qua giao diện người dùng. Trong phần này, bạn sẽ thấy một cách khác để gửi công việc huấn luyện bằng cách sử dụng Vertex Python API.
Quay lại thực thể sổ tay của bạn và tạo một sổ tay TensorFlow 2 từ Trình chạy:

Nhập Vertex AI SDK.
from google.cloud import aiplatform
Để chạy quy trình huấn luyện nhiều worker, trước tiên, bạn cần xác định thông số kỹ thuật của nhóm worker. Xin lưu ý rằng việc sử dụng GPU trong thông số kỹ thuật là hoàn toàn không bắt buộc và bạn có thể xoá accelerator_type và accelerator_count nếu muốn có một cụm chỉ dùng CPU như trong phần trước.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace {YOUR-PROJECT-ID} with your project ID.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-8", "accelerator_type": "NVIDIA_TESLA_V100", "accelerator_count": 1
},
"container_spec": {"image_uri": "gcr.io/{YOUR-PROJECT-ID}/multiworker:cassava"}
}
]
Tiếp theo, hãy tạo và chạy một CustomJob. Bạn cần thay thế {YOUR_BUCKET} bằng một vùng chứa trong dự án của mình để dàn dựng. Bạn có thể sử dụng chính nhóm mà bạn đã tạo trước đó.
# Replace YOUR_BUCKET
my_multiworker_job = aiplatform.CustomJob(display_name='multiworker-cassava-sdk',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_multiworker_job.run()
Trong phần Huấn luyện của bảng điều khiển, bạn sẽ thấy công việc huấn luyện của mình trong thẻ CÔNG VIỆC TUỲ CHỈNH:
8. Dọn dẹp
Vì chúng ta đã định cấu hình sổ tay để hết thời gian chờ sau 60 phút không hoạt động, nên chúng ta không cần lo lắng về việc tắt phiên bản. Nếu bạn muốn tắt thực thể theo cách thủ công, hãy nhấp vào nút Dừng trong phần Vertex AI Workbench của bảng điều khiển. Nếu bạn muốn xoá hoàn toàn sổ tay, hãy nhấp vào nút Xoá.

Để xoá Thùng lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt tìm Bộ nhớ, chọn thùng của bạn rồi nhấp vào Xoá: