
۱. مرور کلی
در این آزمایشگاه، شما:
- ایجاد یک مجموعه داده مدیریتشده
- وارد کردن دادهها از یک مخزن ذخیرهسازی ابری گوگل
- بهروزرسانی متادیتای ستون برای استفاده مناسب با AutoML
- آموزش یک مدل با استفاده از گزینههایی مانند بودجه و هدف بهینهسازی
- پیشبینیهای دستهای آنلاین انجام دهید
۲. بررسی دادهها
این آزمایشگاه از دادههای مجموعه دادههای فروش مشروبات الکلی آیووا از مجموعه دادههای عمومی BigQuery استفاده میکند. این مجموعه دادهها شامل خرید عمده مشروبات الکلی در ایالت آیووای ایالات متحده از سال ۲۰۱۲ است.
میتوانید با انتخاب «مشاهده مجموعه دادهها» (View Dataset) ، دادههای خام اصلی را مشاهده کنید. برای دسترسی به جدول، در نوار پیمایش سمت چپ به پروژه bigquery-public-datasets ، سپس مجموعه داده iowa_liquor_sales و در نهایت جدول فروش بروید. میتوانید برای مشاهده مجموعهای از ردیفهای مجموعه دادهها، «پیشنمایش» (Preview) را انتخاب کنید.

برای اهداف این آزمایش، ما قبلاً برخی پیشپردازشهای اولیه دادهها را برای گروهبندی خریدها بر اساس روز انجام دادهایم. ما از یک فایل CSV استخراجشده از جدول BigQuery استفاده خواهیم کرد. ستونهای فایل CSV عبارتند از:
- ds : تاریخ
- y : مجموع کل خریدهای آن روز به دلار
- holiday : یک متغیر بولی که مشخص میکند آیا تاریخ مورد نظر جزو تعطیلات رسمی ایالات متحده است یا خیر.
- id : یک شناسه سری زمانی (برای پشتیبانی از چندین سری زمانی، مثلاً بر اساس فروشگاه یا محصول). در این حالت، ما صرفاً قصد داریم خریدهای کلی را در یک سری زمانی پیشبینی کنیم، بنابراین id برای هر ردیف روی 0 تنظیم میشود.
۳. وارد کردن دادهها
مرحله 1: به مجموعه دادههای هوش مصنوعی Vertex بروید
از طریق نوار ناوبری سمت چپ کنسول ابری ، در منوی Vertex AI به مجموعه دادهها دسترسی پیدا کنید.

مرحله ۲: ایجاد مجموعه داده
یک مجموعه داده جدید ایجاد کنید، Tabular Data و سپس نوع مسئله پیشبینی را انتخاب کنید. نام iowa_daily یا هر چیز دیگری را که ترجیح میدهید انتخاب کنید.

مرحله ۳: وارد کردن دادهها
مرحله بعدی وارد کردن دادهها به مجموعه دادهها است. گزینه Select a CSV from Cloud Storage را انتخاب کنید. سپس، به فایل CSV موجود در AutoML Demo Alpha بروید و automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv را وارد کنید.
۴. مدل قطار
مرحله ۱: پیکربندی ویژگیهای مدل
بعد از چند دقیقه، AutoML به شما اطلاع میدهد که وارد کردن اطلاعات تکمیل شده است. در آن مرحله، میتوانید ویژگیهای مدل را پیکربندی کنید.
- ستون شناسه سری زمانی را برای id انتخاب کنید. ما فقط یک سری زمانی در مجموعه داده خود داریم، بنابراین این یک امر تشریفاتی است.
- ستون Time را برای ds انتخاب کنید.
سپس، گزینهی «ایجاد آمار» (Generate Statistics) را انتخاب کنید. پس از اتمام فرآیند، آمار مربوط به « درصد گمشده» (Missing% ) و «مقادیر متمایز» (Distinct values) را مشاهده خواهید کرد. این فرآیند ممکن است چند دقیقه طول بکشد، بنابراین در صورت تمایل میتوانید به مرحلهی بعدی بروید.
مرحله ۲: آموزش مدل
برای شروع فرآیند آموزش، گزینه Train the Model را انتخاب کنید. مطمئن شوید که AutoML انتخاب شده است و سپس Continue را بزنید .

مرحله ۳: تعریف مدل
- ستون Target را y انتخاب کنید. این مقداری است که ما پیشبینی میکنیم.
- اگر قبلاً تنظیم نشده است، ستون شناسه سری را روی id و ستون Timestamp را روی ds تنظیم کنید.
- بخش « جزئیات دادهها» (Data Granularity) را روی «روزها» (Days) و «افق پیشبینی» (Frequency) را روی ۷ تنظیم کنید. این فیلد تعداد دورههایی را که مدل میتواند برای آینده پیشبینی کند، مشخص میکند.
- پنجره Context را روی ۷ روز تنظیم کنید. مدل از دادههای ۳۰ روز گذشته برای پیشبینی استفاده خواهد کرد. بین پنجرههای کوتاهتر و بلندتر، بدهبستانهایی وجود دارد و بهطورکلی انتخاب مقداری بین ۱ تا ۱۰ برابر افق پیشبینی توصیه میشود.
- کادر «صادر کردن مجموعه دادههای آزمایشی به BigQuery» را علامت بزنید. میتوانید آن را خالی بگذارید تا بهطور خودکار یک مجموعه داده و جدول در پروژه شما ایجاد شود (یا مکان مورد نظر خود را مشخص کنید).
- ادامه را انتخاب کنید.

مرحله ۴: تنظیم گزینههای آموزشی
در این مرحله، میتوانید جزئیات بیشتری در مورد نحوه آموزش مدل مشخص کنید.
- ستون تعطیلات را روی «در زمان پیشبینی موجود است» تنظیم کنید، زیرا از قبل میدانیم که آیا یک تاریخ معین، تعطیل است یا خیر.
- هدف بهینهسازی را به MAE تغییر دهید. MAE یا میانگین خطای میانگین، نسبت به میانگین مربعات خطا، در برابر دادههای پرت مقاومتر است. از آنجا که ما با دادههای خرید روزانه کار میکنیم که میتوانند نوسانات شدیدی داشته باشند، MAE معیار مناسبی برای استفاده است.
- ادامه را انتخاب کنید.

مرحله ۵: شروع آموزش
بودجهای به دلخواه خود تعیین کنید. در این حالت، ۱ ساعت گره برای آموزش مدل کافی است. سپس، فرآیند آموزش را آغاز کنید.
مرحله ۶: ارزیابی مدل
فرآیند آموزش ممکن است ۱ تا ۲ ساعت طول بکشد (شامل هرگونه زمان اضافی برای راهاندازی). پس از اتمام آموزش، ایمیلی دریافت خواهید کرد. وقتی آماده شد، میتوانید دقت مدلی که ایجاد کردهاید را مشاهده کنید.
۵. پیشبینی کنید
مرحله ۱: بررسی پیشبینیها روی دادههای آزمایشی
برای مشاهده پیشبینیها روی دادههای آزمایشی، به کنسول BigQuery بروید. در داخل پروژه شما، یک مجموعه داده جدید به طور خودکار با طرح نامگذاری زیر ایجاد میشود: export_evaluated_data_items + <model name> + <timestamp> . در داخل آن مجموعه داده، جدول evaluated_data_items را برای بررسی پیشبینیها خواهید یافت.
این جدول چند ستون جدید دارد:
- prediction_on_[date column]: تاریخی که پیشبینی انجام شده است. برای مثال، اگر prediction_on_ds برابر با 11/4 و ds برابر با 11/8 باشد، ما 4 روز جلوتر را پیشبینی میکنیم.
- prediction_[target column].tables.value: مقدار پیشبینیشده

مرحله ۲: انجام پیشبینیهای دستهای
در نهایت، شما میخواهید از مدل خود برای پیشبینی استفاده کنید.
فایل ورودی شامل مقادیر خالی برای تاریخهای پیشبینیشده، همراه با دادههای تاریخی است:
دی اس | تعطیلات | شناسه | ی |
۱۵/۵/۲۰۲۰ | 0 | 0 | ۱۷۵۱۳۱۵.۴۳ |
۱۶/۵/۲۰۲۰ | 0 | 0 | 0 |
۱۷/۵/۲۰۲۰ | 0 | 0 | 0 |
۱۸/۵/۲۰۲۰ | 0 | 0 | ۱۶۱۲۰۶۶.۴۳ |
۱۹/۵/۲۰۲۰ | 0 | 0 | ۱۷۷۳۸۸۵.۱۷ |
۲۰/۵/۲۰ | 0 | 0 | ۱۴۸۷۲۷۰.۹۲ |
۲۱/۵/۲۰۲۰ | 0 | 0 | ۱۰۲۴۰۵۱.۷۶ |
۲۲/۵/۲۰۲۰ | 0 | 0 | ۱۴۷۱۷۳۶.۳۱ |
۲۳/۵/۲۰۲۰ | 0 | 0 | <خالی> |
۲۰/۵/۲۴ | 0 | 0 | <خالی> |
2020/5/25 | ۱ | 0 | <خالی> |
۵/۲۶/۲۰ | 0 | 0 | <خالی> |
2020/5/27 | 0 | 0 | <خالی> |
۲۸/۵/۲۰ | 0 | 0 | <خالی> |
۲۹/۵/۲۰ | 0 | 0 | <خالی> |
از آیتم پیشبینیهای دستهای در نوار ناوبری سمت چپ پلتفرم هوش مصنوعی (یکپارچه)، میتوانید یک پیشبینی دستهای جدید ایجاد کنید.
یک فایل ورودی نمونه در اینجا در یک مخزن ذخیرهسازی برای شما ایجاد میشود: automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv
میتوانید محل فایل منبع را مشخص کنید. سپس میتوانید پیشبینیهای خود را به صورت CSV به یک محل ذخیرهسازی ابری یا به BigQuery صادر کنید. برای اهداف این آزمایش، BigQuery را انتخاب کرده و شناسه پروژه Google Cloud خود را انتخاب کنید.
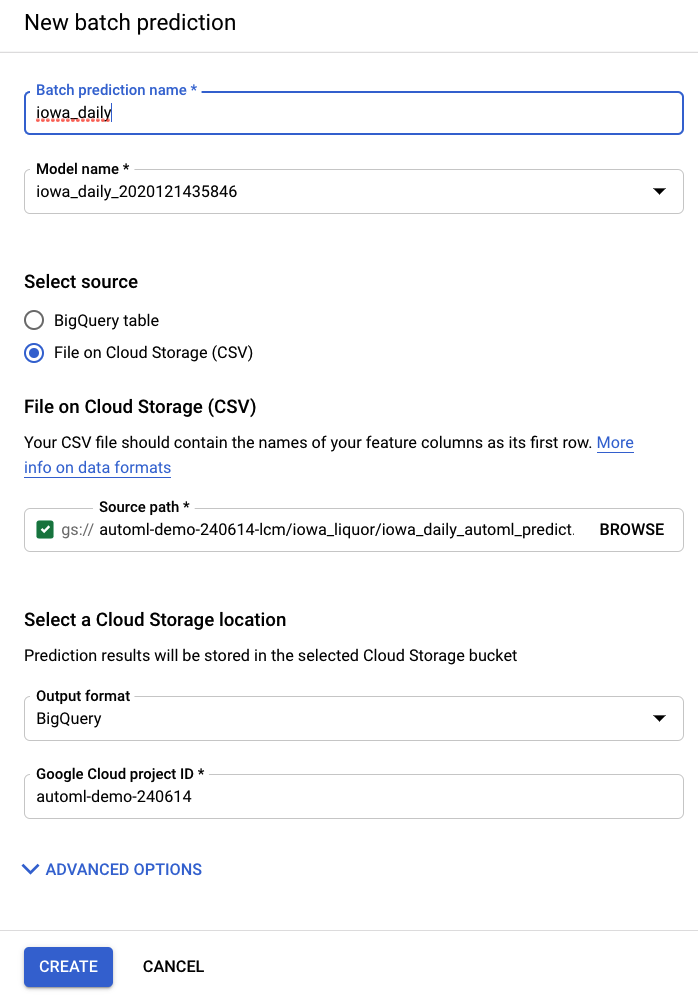
فرآیند پیشبینی دستهای چند دقیقه طول میکشد. پس از اتمام آن، میتوانید روی کار پیشبینی دستهای کلیک کنید تا جزئیات، از جمله محل خروجی ، را مشاهده کنید. در BigQuery، برای دسترسی به پیشبینیها باید به project / dataset / table در نوار ناوبری سمت چپ بروید.
این کار دو جدول مختلف در BigQuery ایجاد میکند. یکی شامل هر ردیفی که خطا دارد و دیگری شامل پیشبینیها خواهد بود. در اینجا مثالی از خروجی جدول پیشبینیها آورده شده است:

مرحله ۳: نتیجهگیری
تبریک میگویم، شما با موفقیت یک مدل پیشبینی را با AutoML ساختید و آموزش دادید. در این آزمایش، ما وارد کردن دادهها، ساخت مدل و انجام پیشبینیها را پوشش دادیم.
شما آمادهاید تا مدل پیشبینی خودتان را بسازید!