
1. 概要
このラボでは、次の作業を行います。
- マネージド データセットを作成する
- Google Cloud Storage バケットからデータをインポートする
- AutoML で適切に使用できるように列のメタデータを更新する
- 予算や最適化目標などのオプションを使用してモデルをトレーニングする
- オンライン バッチ予測を行う
2. データを確認する
このラボでは、BigQuery の一般公開データセットの アイオワ州酒類販売データセットのデータを使用します。このデータセットは、2012 年以降の米国アイオワ州の酒類卸売購入で構成されています。
[データセットを表示] を選択すると、元の生データを確認できます。テーブルにアクセスするには、左側のナビゲーション バーで bigquery-public-datasets プロジェクト、iowa_liquor_sales データセット、sales テーブルの順に移動します。[プレビュー] を選択すると、データセットから選択された行が表示されます。
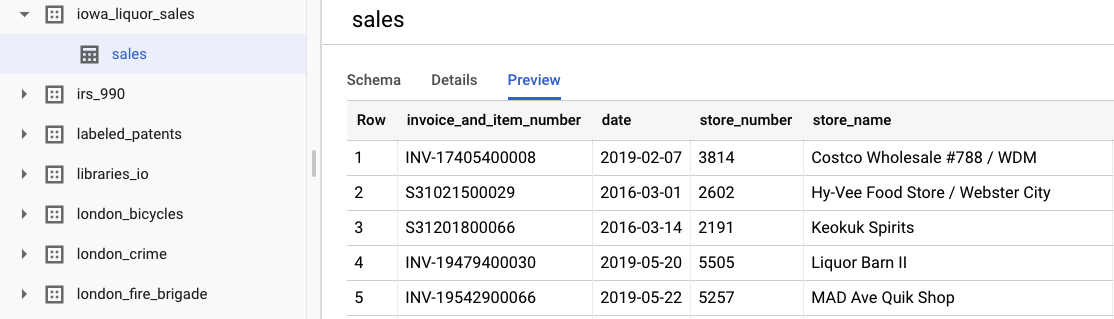
このラボでは、購入を日ごとにグループ化する基本的なデータ前処理がすでに完了しています。BigQuery テーブルから CSV 抽出を使用します。CSV ファイルの列は次のとおりです。
- ds: 日付
- y: その日のすべての購入額の合計(ドル)
- holiday: 日付が米国の祝日かどうかを示すブール値
- id: 時系列識別子(店舗別や商品別など、複数の時系列をサポートするため)。この例では、1 つの時系列で全体的な購入を予測するだけなので、各行の ID は 0 に設定されています。
3. データのインポート
ステップ 1: Vertex AI データセットに移動する
Cloud コンソールの左側のナビゲーション バーから、[Vertex AI] メニューの [データセット] にアクセスします。
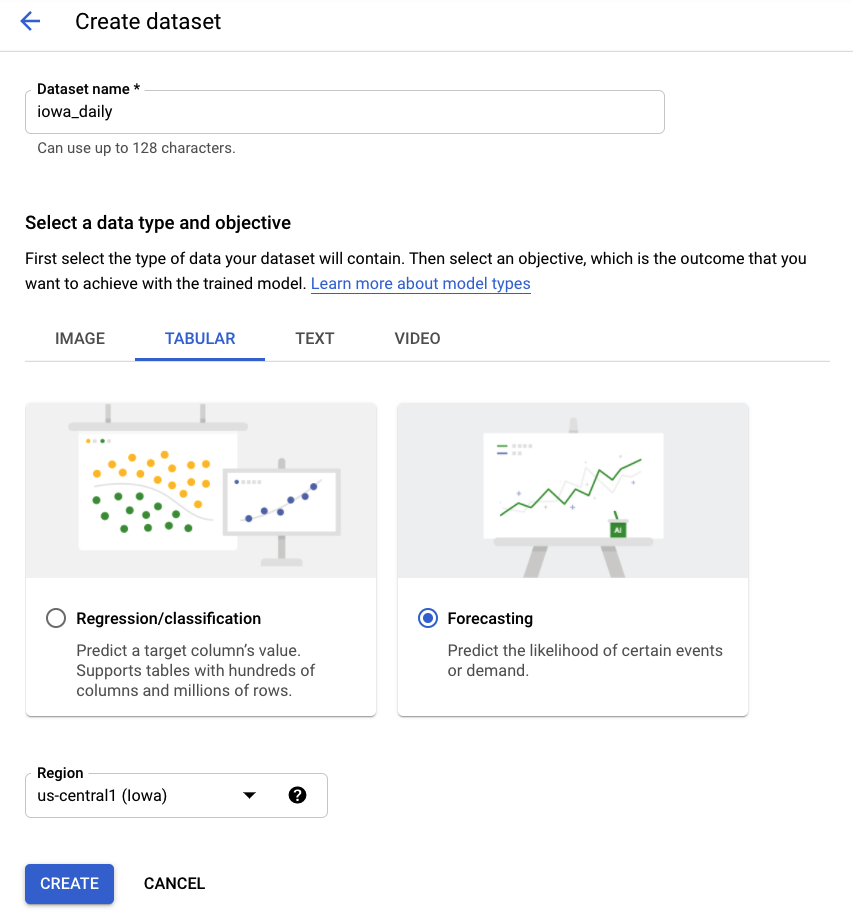
ステップ 2: データセットを作成する
[表形式データ] を選択し、[予測] 問題タイプを選択して、新しいデータセットを作成します。iowa_daily などの名前を選択します。
ステップ 3: データをインポートする
次のステップでは、データセットにデータをインポートします。[Cloud Storage から CSV を選択] オプションを選択します。次に、AutoML Demo Alpha バケット内の CSV ファイルに移動し、automl-demo-240614-lcm/iowa_liquor/iowa_daily.csv を貼り付けます。
4. モデルのトレーニング
ステップ 1: モデルの特徴を構成する
数分後、AutoML からインポートが完了したことが通知されます。その時点で、モデルの機能を構成できます。
- 時系列識別子列を id に選択します。データセットには時系列が 1 つしかないため、これは形式的なものです。
- 時間列を ds に設定します。
[統計情報を生成] を選択します。プロセスが完了すると、[欠損値の割合] と [一意の値] の統計情報が表示されます。この処理には数分かかることがあります。次の手順に進んでください。
ステップ 2: モデルをトレーニングする
[モデルをトレーニングする] を選択して、トレーニング プロセスを開始します。AutoML が選択されていることを確認し、[続行] をクリックします。
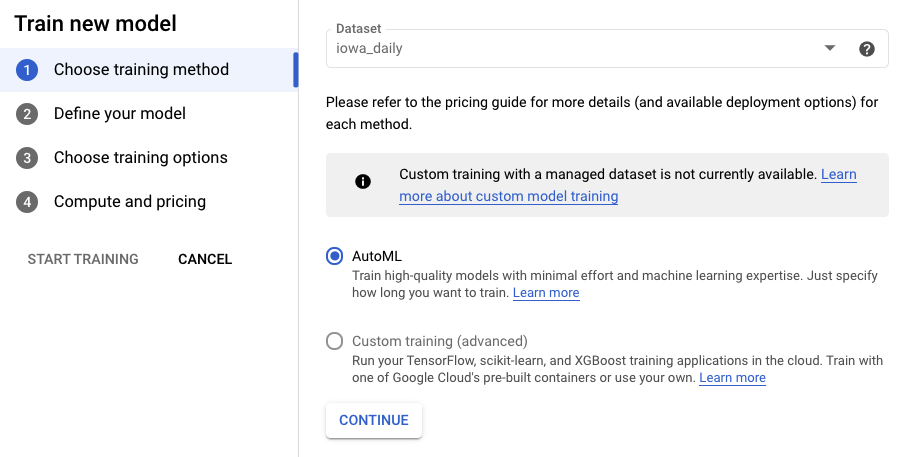
ステップ 3: モデルを定義する
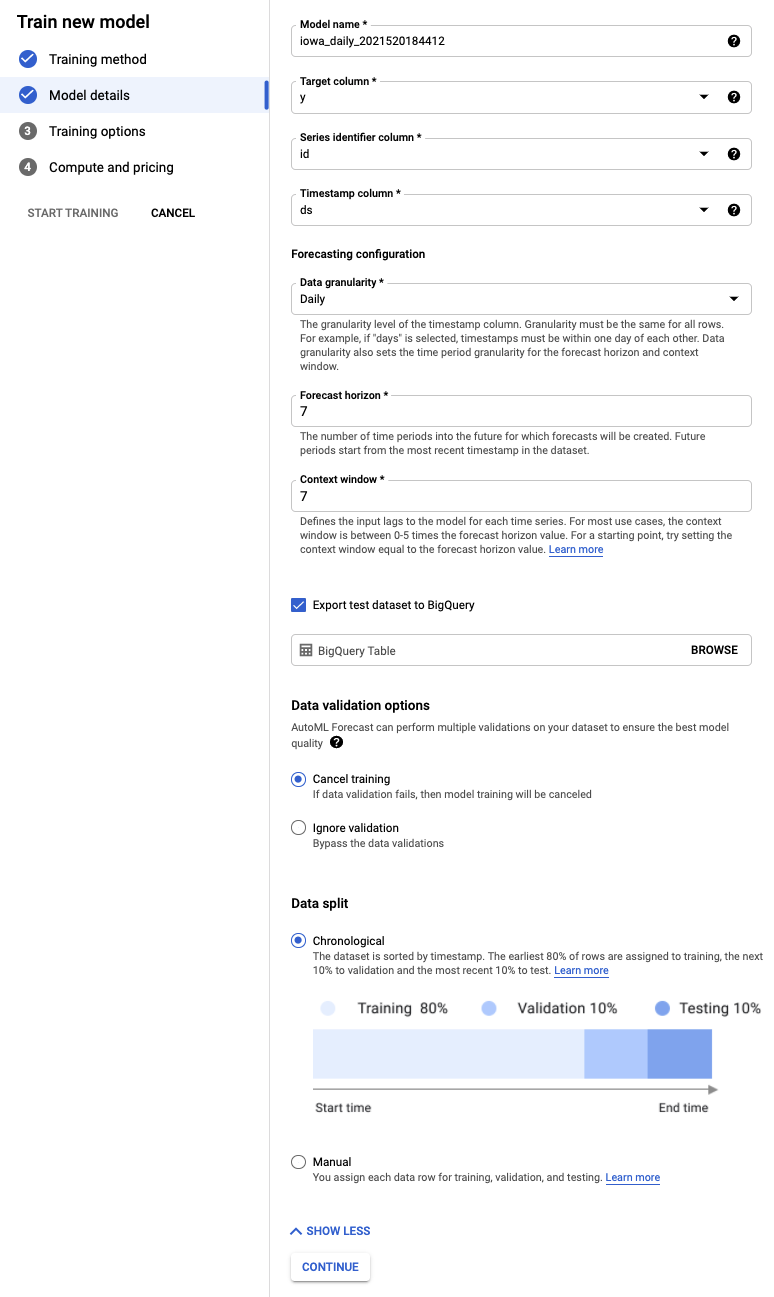
- [ターゲット列] を y に設定します。これが予測する値です。
- まだ設定していない場合は、[時系列の ID] 列を id に、[タイムスタンプ列] を ds に設定します。
- [データ粒度] を [日] に、[予測期間] を [7] に設定します。このフィールドでは、モデルが将来を予測できる期間の数を指定します。
- [コンテキスト ウィンドウ] を 7 日に設定します。モデルは、過去 30 日間のデータを使用して予測を行います。短い期間と長い期間の間にはトレードオフがあり、一般的に予測ホライズンの 1 ~ 10 倍の範囲で値を選択することをおすすめします。
- [テスト データセットを BigQuery にエクスポート] チェックボックスをオンにします。空白のままにすると、プロジェクトにデータセットとテーブルが自動的に作成されます(または、任意のロケーションを指定します)。
- [続行] を選択します。
ステップ 4: トレーニング オプションを設定する
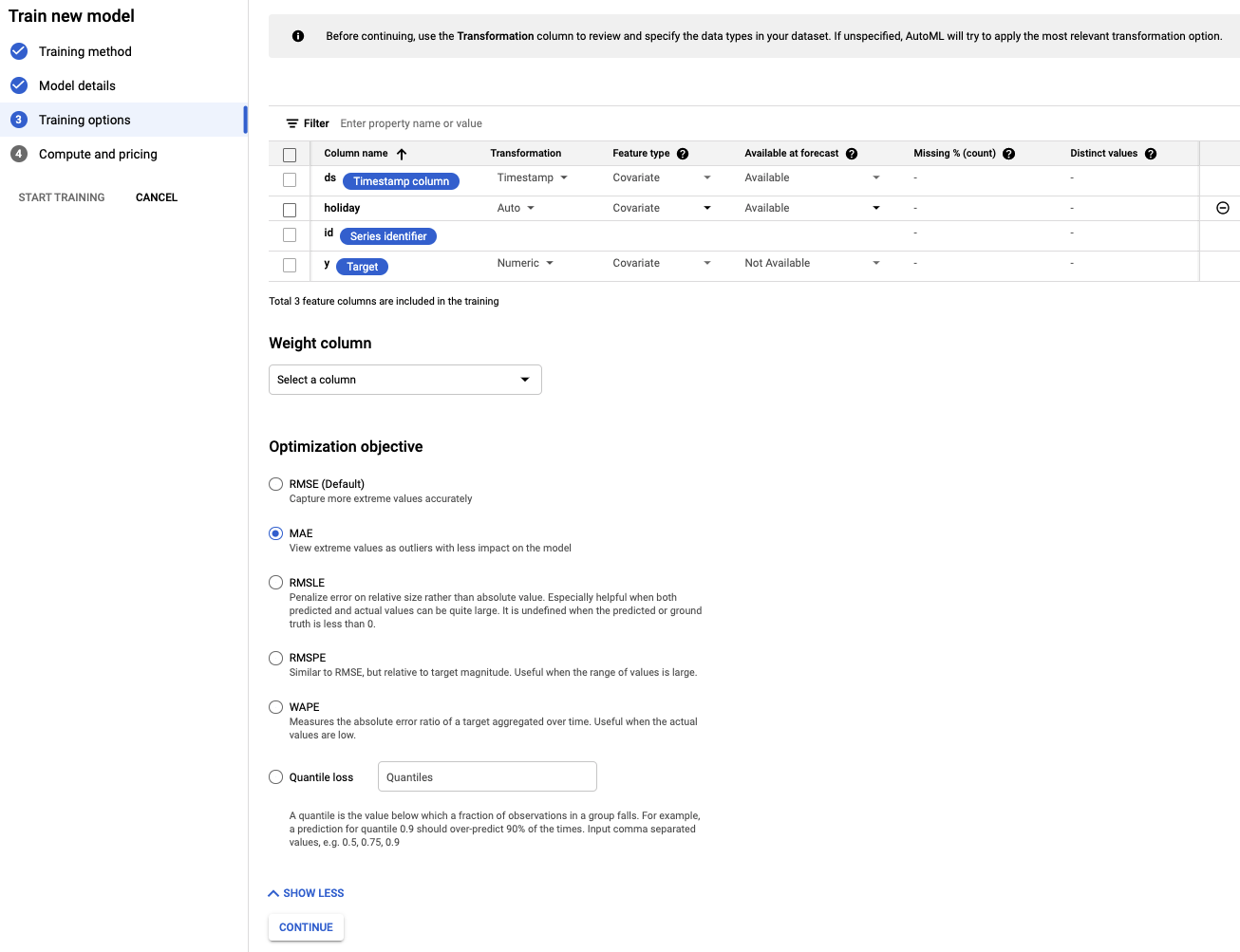
このステップでは、モデルのトレーニング方法の詳細を指定できます。
- 特定の日付が祝日かどうかは事前にわかっているため、holiday 列を予測時に使用可能に設定します。
- [最適化の目標] を [MAE] に変更します。MAE(平均絶対誤差)は、平均二乗誤差に比べて外れ値の影響を受けにくい指標です。日々の購入データは変動が大きいため、MAE は適切な指標です。
- [続行] を選択します。
ステップ 5: トレーニングを開始する
予算を設定します。この場合、モデルのトレーニングには 1 ノード時間で十分です。次に、トレーニング プロセスを開始します。
ステップ 6: モデルを評価する
トレーニング プロセスが完了するまでに 1 ~ 2 時間ほどかかることがあります(追加のセットアップ時間を含む)。トレーニングが完了すると、メールが届きます。準備ができたら、作成したモデルの精度を確認できます。
5. 予測
ステップ 1: テストデータの予測を確認する
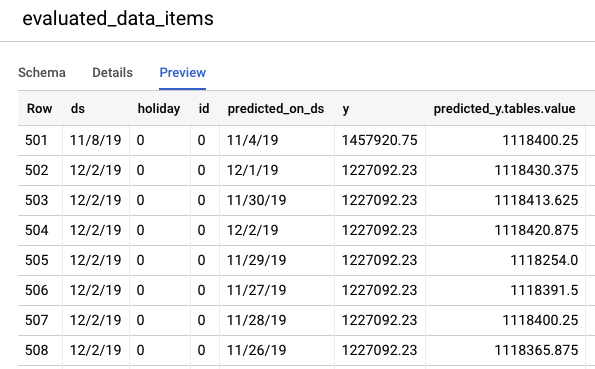
BigQuery コンソールに移動して、テストデータの予測を表示します。プロジェクト内に、export_evaluated_data_items + <モデル名> + <タイムスタンプ> という命名規則で新しいデータセットが自動的に作成されます。このデータセット内には、予測を確認するための evaluated_data_items テーブルがあります。
このテーブルには、次の 2 つの新しい列があります。
- predicted_on_[date column]: 予測が行われた日付。たとえば、predicted_on_ds が 11 月 4 日で ds が 11 月 8 日の場合、4 日先の予測が行われます。
- predicted_[ターゲット列].tables.value: 予測値
ステップ 2: バッチ予測を実行する
最後に、モデルを使用して予測を行います。
入力ファイルには、予測する日付の空の値と過去のデータが含まれています。
ds | holiday | id | y |
2020 年 5 月 15 日 | 0 | 0 | 1751315.43 |
2020 年 5 月 16 日 | 0 | 0 | 0 |
2020 年 5 月 17 日 | 0 | 0 | 0 |
2020 年 5 月 18 日 | 0 | 0 | 1612066.43 |
2020 年 5 月 19 日 | 0 | 0 | 1773885.17 |
2020 年 5 月 20 日 | 0 | 0 | 1487270.92 |
2020 年 5 月 21 日 | 0 | 0 | 1024051.76 |
2020 年 5 月 22 日 | 0 | 0 | 1471736.31 |
2020 年 5 月 23 日 | 0 | 0 | <空> |
2020 年 5 月 24 日 | 0 | 0 | <空> |
2020 年 5 月 25 日 | 1 | 0 | <空> |
2020 年 5 月 26 日 | 0 | 0 | <空> |
2020 年 5 月 27 日 | 0 | 0 | <空> |
2020 年 5 月 28 日 | 0 | 0 | <空> |
2020 年 5 月 29 日 | 0 | 0 | <空> |
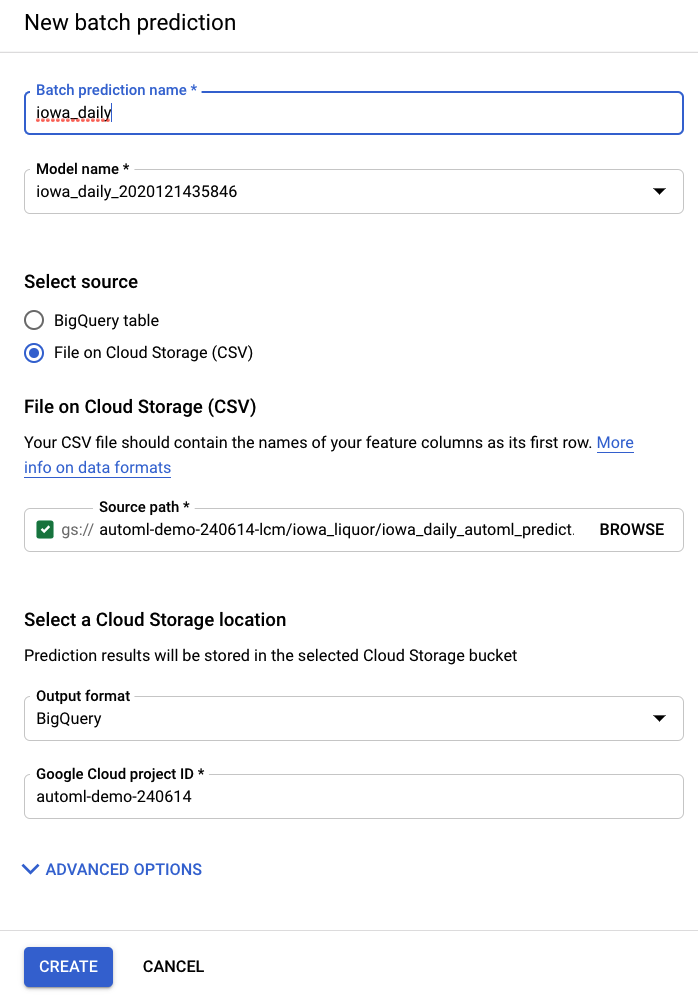
AI Platform(統合型)の左側のナビゲーション バーにある [バッチ予測] 項目から、新しいバッチ予測を作成できます。
入力ファイルの例は、ストレージ バケット automl-demo-240614-lcm/iowa_liquor/iowa_daily_automl_predict.csv に作成されています。
このソースファイルの場所を指定できます。予測を CSV としてクラウド ストレージの場所にエクスポートするか、BigQuery にエクスポートするかを選択できます。このラボでは、[BigQuery] を選択し、Google Cloud プロジェクト ID を選択します。
バッチ予測プロセスには数分かかります。完了したら、バッチ予測ジョブをクリックして、エクスポート ロケーションなどの詳細を表示できます。BigQuery で予測にアクセスするには、左側のナビゲーション バーでプロジェクト、データセット、テーブルに移動する必要があります。
ジョブは BigQuery に 2 つの異なるテーブルを作成します。1 つにはエラーのある行が含まれ、もう 1 つには予測が含まれます。Predictions テーブルの出力例を次に示します。
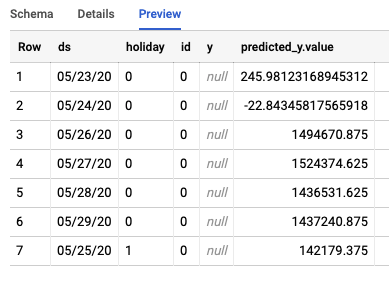
ステップ 3: 結論
お疲れさまでした。AutoML を使用して予測モデルを構築し、トレーニングできました。このラボでは、データのインポート、モデルの構築、予測の作成について説明しました。
これで、独自の予測モデルを構築する準備が整いました。