
۱. مرور کلی
مجموعه آزمایشگاههای کد Serverless Migration Station (آموزشهای عملی و خودآموز) و ویدیوهای مرتبط با آن ، با هدف کمک به توسعهدهندگان Google Cloud serverless برای مدرنسازی برنامههایشان، با راهنمایی آنها در طول یک یا چند مهاجرت، و در درجه اول دور شدن از سرویسهای قدیمی، ارائه میشوند. انجام این کار، برنامههای شما را قابل حملتر میکند و گزینهها و انعطافپذیری بیشتری به شما میدهد و شما را قادر میسازد تا با طیف وسیعتری از محصولات Cloud ادغام شده و به آنها دسترسی داشته باشید و به راحتی به نسخههای جدیدتر زبان ارتقا دهید. در حالی که در ابتدا بر روی اولین کاربران Cloud، در درجه اول توسعهدهندگان App Engine (محیط استاندارد)، تمرکز دارد، این مجموعه به اندازه کافی گسترده است که شامل سایر پلتفرمهای serverless مانند Cloud Functions و Cloud Run یا در صورت لزوم، هر جای دیگری نیز میشود.
هدف از این آزمایشگاه کد، نشان دادن نحوه مهاجرت توسعهدهندگان App Engine با پایتون ۲ از وظایف صفبندی App Engine به Cloud Pub/Sub است. همچنین یک مهاجرت ضمنی از App Engine NDB به Cloud NDB برای دسترسی به Datastore (که عمدتاً در ماژول ۲ پوشش داده شده است) و همچنین ارتقاء به پایتون ۳ نیز وجود دارد.
در ماژول ۱۸، یاد میگیرید که چگونه استفاده از وظایف pull را در برنامه خود اضافه کنید. در این ماژول، برنامه نهایی ماژول ۱۸ را برداشته و استفاده از آن را به Cloud Pub/Sub منتقل خواهید کرد. کسانی که از Task Queues برای وظایف push استفاده میکنند، به Cloud Tasks مهاجرت میکنند و باید به ماژولهای ۷ تا ۹ مراجعه کنند.
یاد خواهید گرفت که چگونه
- جایگزینی صف وظایف موتور برنامه (وظایف pull) با Cloud Pub/Sub
- جایگزینی استفاده از App Engine NDB با Cloud NDB (همچنین به ماژول ۲ مراجعه کنید)
- انتقال برنامه به پایتون ۳
آنچه نیاز دارید
- یک پروژه پلتفرم ابری گوگل با یک حساب پرداخت فعال GCP
- مهارتهای پایه پایتون
- آشنایی کامل با دستورات رایج لینوکس
- دانش پایه در توسعه و استقرار برنامههای App Engine
- یک نمونه برنامه کاربردی ماژول ۱۸ موتور برنامه
نظرسنجی
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را با پایتون چگونه ارزیابی میکنید؟
تجربه خود را در استفاده از خدمات ابری گوگل چگونه ارزیابی میکنید؟
۲. پیشینه
صف وظایف موتور برنامه از هر دو وظیفه push و pull پشتیبانی میکند. برای بهبود قابلیت حمل برنامه، گوگل کلود توصیه میکند از سرویسهای قدیمی مانند Task Queue به سایر سرویسهای مستقل ابری یا معادلهای شخص ثالث مهاجرت کنید.
- کاربرانی که میخواهند وظایف را در صف وظایف (Task Queue) ارسال کنند، باید به Cloud Tasks مهاجرت کنند.
- کاربران Task Pull Queue باید به Cloud Pub/Sub مهاجرت کنند.
ماژولهای مهاجرت ۷-۹، مهاجرت وظایف ارسالی (push task) را پوشش میدهند، در حالی که ماژولهای ۱۸-۱۹ بر مهاجرت وظایف دریافت (pull task) تمرکز دارند. در حالی که Cloud Tasks بیشتر با وظایف ارسالی Task Queue مطابقت دارد، Pub/Sub به اندازه Taskهای دریافت (pull task) در صف وظایف (Task Queue) قابل مقایسه نیست.
Pub/Sub ویژگیهای بیشتری نسبت به قابلیت pull ارائه شده توسط Task Queue دارد. به عنوان مثال، Pub/Sub قابلیت push نیز دارد، با این حال Cloud Tasks بیشتر شبیه Task Queue push tasks است، بنابراین Pub/Sub push توسط هیچ یک از ماژولهای مهاجرت پوشش داده نمیشود . این codelab ماژول ۱۹، تغییر مکانیسم صفبندی از صفهای pull Task Queue به Pub/Sub و همچنین مهاجرت از App Engine NDB به Cloud NDB برای دسترسی به Datastore را نشان میدهد و مهاجرت ماژول ۲ را تکرار میکند.
در حالی که کد ماژول ۱۸ به عنوان یک برنامه نمونه پایتون ۲ «تبلیغ» میشود، خود منبع با پایتون ۲ و ۳ سازگار است و حتی پس از مهاجرت به Cloud Pub/Sub (و Cloud NDB) در ماژول ۱۹، همچنان به همین شکل باقی میماند.
این آموزش شامل مراحل زیر است:
- راهاندازی/پیشپردازش
- پیکربندی را بهروزرسانی کنید
- اصلاح کد برنامه
۳. تنظیمات/پیشپردازش
این بخش توضیح میدهد که چگونه:
- پروژه ابری خود را راهاندازی کنید
- دریافت برنامه نمونه پایه
- (دوباره)استقرار و اعتبارسنجی برنامه پایه
- فعال کردن سرویسها/APIهای جدید Google Cloud
این مراحل تضمین میکنند که شما با کدی کار میکنید که به درستی کار میکند و برای انتقال به سرویسهای ابری آماده است.
۱. پروژه راهاندازی
اگر آزمایشگاه کد ماژول ۱۸ را تکمیل کردهاید، از همان پروژه (و کد) دوباره استفاده کنید. روش دیگر، ایجاد یک پروژه کاملاً جدید یا استفاده مجدد از یک پروژه موجود دیگر است. مطمئن شوید که پروژه دارای یک حساب صورتحساب فعال و یک برنامه App Engine فعال است. شناسه پروژه خود را پیدا کنید زیرا در طول این آزمایشگاه کد به آن نیاز دارید و هر زمان که با متغیر PROJECT_ID مواجه شدید، از آن استفاده کنید.
۲. نمونه برنامه پایه را دریافت کنید
یکی از پیشنیازها، یک برنامهی ماژول ۱۸ App Engine است که کار کند، بنابراین یا codelab آن را تکمیل کنید (توصیه میشود؛ لینک بالا) یا کد ماژول ۱۸ را از مخزن کپی کنید. چه از کد خودتان استفاده کنید و چه از کد ما، اینجا جایی است که ما شروع میکنیم ("شروع"). این codelab شما را در طول مهاجرت راهنمایی میکند و با کدی که شبیه کد موجود در پوشهی مخزن ماژول ۱۹ است ("پایان") به پایان میرسد.
- شروع: پوشه ماژول ۱۸ (پایتون ۲)
- پایان: پوشه ماژول ۱۹ (پایتون ۲ و ۳)
- کل مخزن (برای کلون کردن یا دانلود فایل زیپ )
صرف نظر از اینکه از کدام برنامه ماژول ۱۸ استفاده میکنید، پوشه باید شبیه شکل زیر باشد، احتمالاً شامل یک پوشه lib نیز خواهد بود:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
۳. (دوباره) استقرار و اعتبارسنجی برنامه پایه
برای نصب برنامه ماژول ۱۸ مراحل زیر را انجام دهید:
- اگر پوشه
libوجود دارد، آن را حذف کنید وpip install -t lib -r requirements.txtرا برای پر کردن مجددlibاجرا کنید. اگر پایتون ۲ و ۳ را روی دستگاه توسعه خود نصب دارید، ممکن است لازم باشد ازpip2استفاده کنید. - مطمئن شوید که ابزار خط فرمان
gcloudرا نصب و راهاندازی اولیه کردهاید و نحوهی استفاده از آن را بررسی کردهاید. - (اختیاری) اگر نمیخواهید
PROJECT_IDبا هر دستورgcloudوارد کنید، پروژه Cloud خود را باgcloud config set projectPROJECT_IDتنظیم کنید. - برنامه نمونه را با
gcloud app deployمستقر کنید - تأیید کنید که برنامه طبق انتظار و بدون مشکل اجرا میشود. اگر ماژول کدلب ۱۸ را تکمیل کرده باشید، برنامه بازدیدکنندگان برتر را به همراه آخرین بازدیدها (مطابق تصویر زیر) نمایش میدهد. در غیر این صورت، ممکن است هیچ تعداد بازدیدکنندهای برای نمایش وجود نداشته باشد.
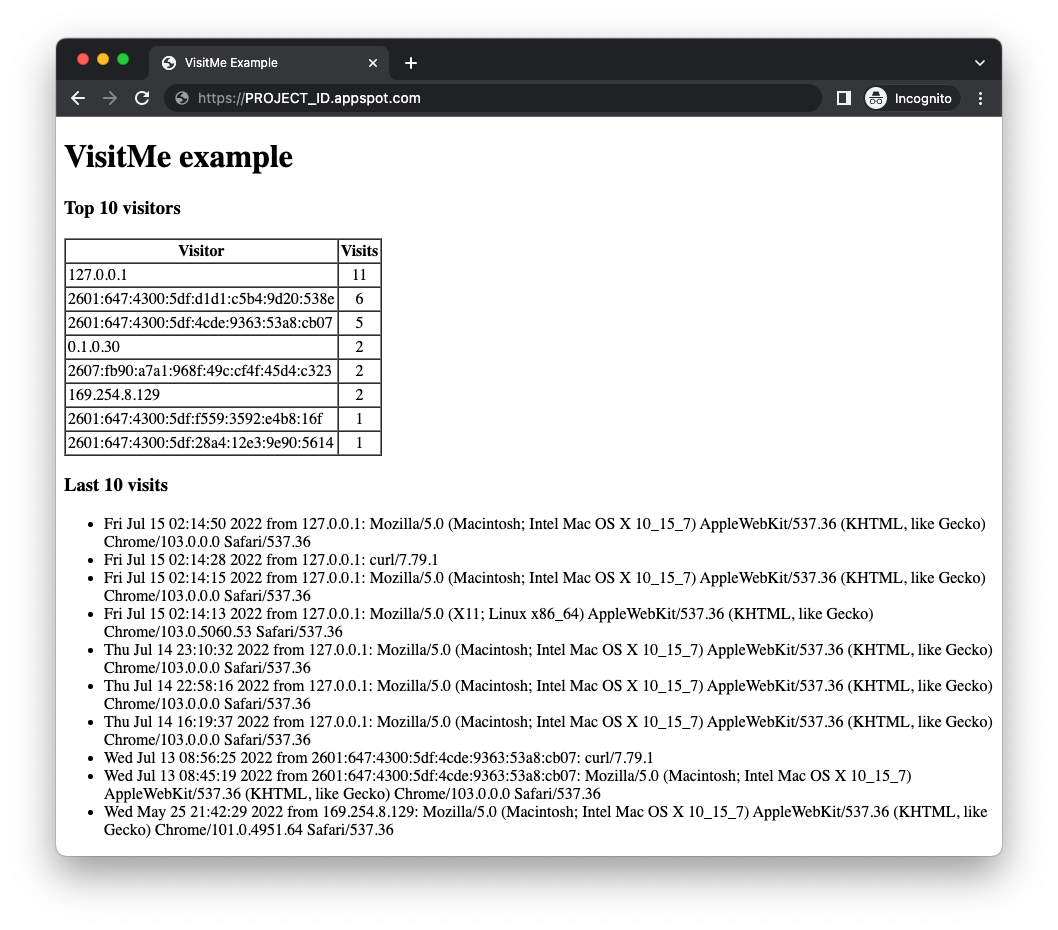
قبل از انتقال برنامه نمونه ماژول ۱۸، ابتدا باید سرویسهای ابری که برنامه اصلاحشده از آنها استفاده خواهد کرد را فعال کنید.
۴. فعال کردن سرویسها/APIهای جدید گوگل کلود
برنامه قدیمی از سرویسهای همراه App Engine استفاده میکرد که نیازی به تنظیمات اضافی ندارند، اما سرویسهای Cloud مستقل این کار را انجام میدهند و برنامه بهروزرسانیشده از Cloud Pub/Sub و Cloud Datastore (از طریق کتابخانه کلاینت Cloud NDB) استفاده خواهد کرد. App Engine و هر دو API Cloud دارای سهمیههای سطح «همیشه رایگان» هستند و تا زمانی که زیر این محدودیتها بمانید، برای تکمیل این آموزش نباید هزینهای متحمل شوید. APIهای Cloud را میتوان بسته به ترجیح شما از طریق Cloud Console یا از طریق خط فرمان فعال کرد.
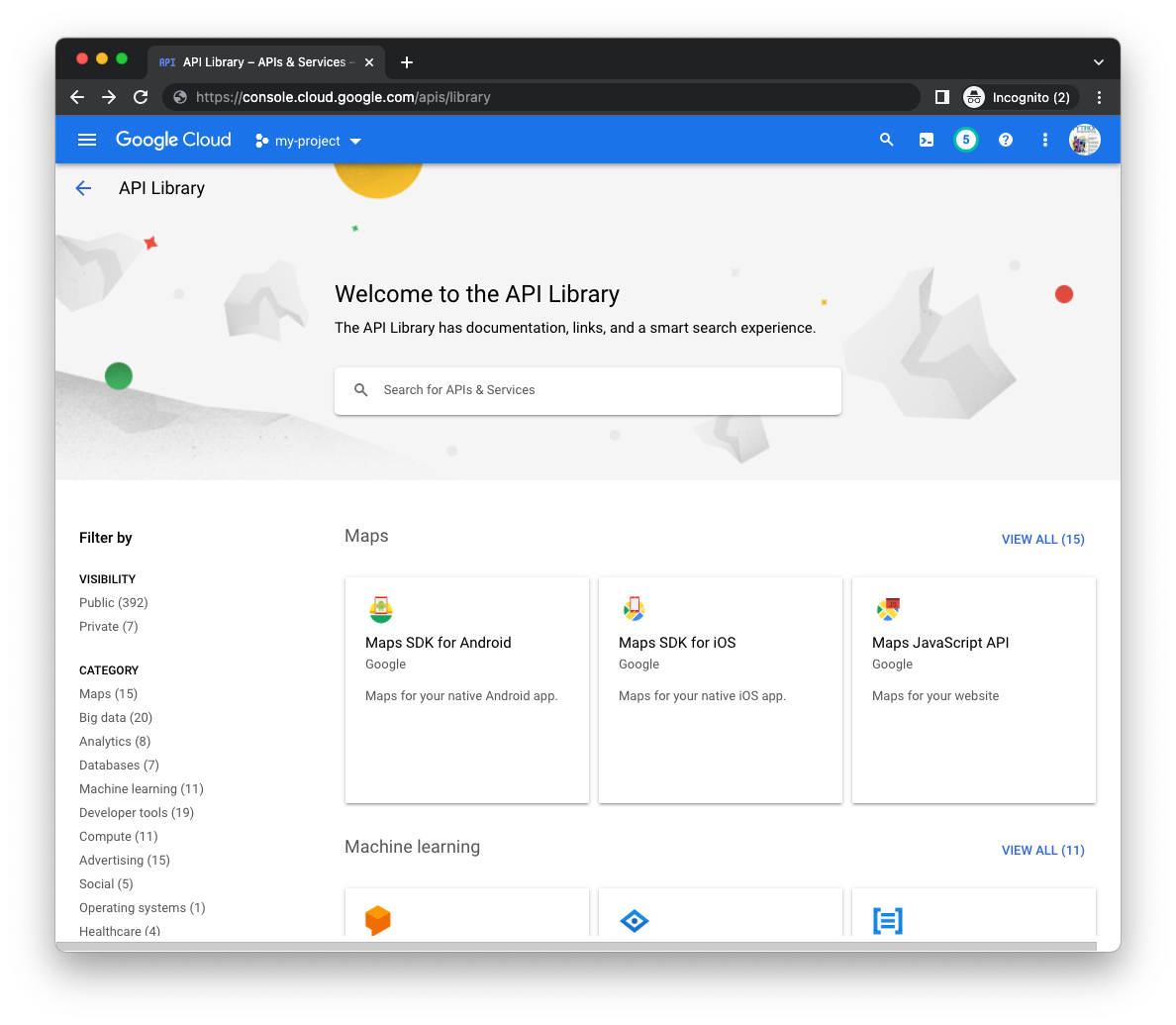
از کنسول ابری
به صفحه کتابخانه مدیر API (برای پروژه صحیح) در کنسول ابری بروید و با استفاده از نوار جستجو در وسط صفحه، APIهای Cloud Datastore و Cloud Pub/Sub را جستجو کنید:
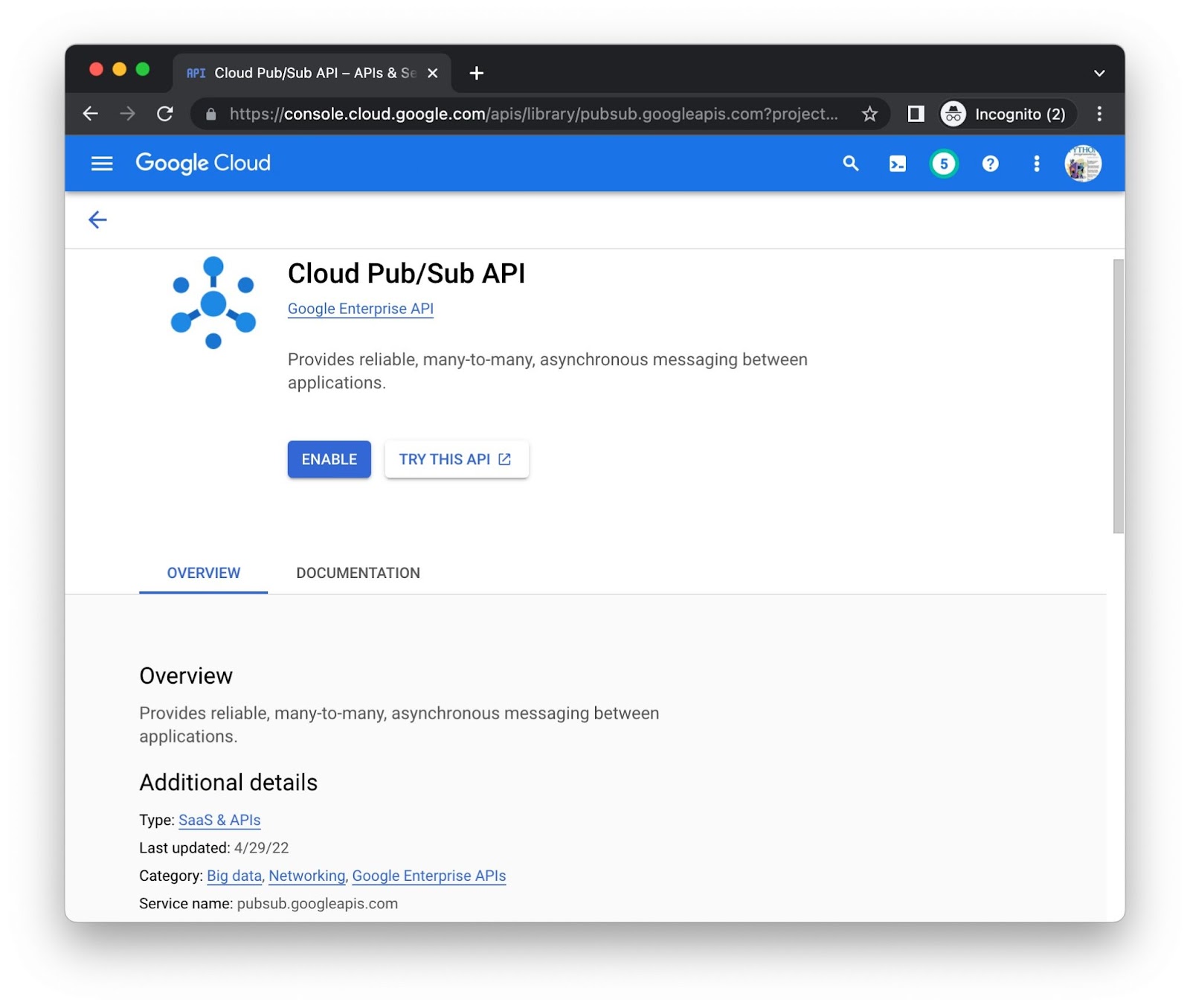
برای هر API به طور جداگانه روی دکمه فعالسازی کلیک کنید—ممکن است از شما اطلاعات صورتحساب خواسته شود. برای مثال، این صفحه کتابخانه Cloud Pub/Sub API است:
از خط فرمان
اگرچه فعال کردن APIها از طریق کنسول از نظر بصری آموزنده است، اما برخی خط فرمان را ترجیح میدهند. دستور gcloud services enable pubsub.googleapis.com datastore.googleapis.com را برای فعال کردن همزمان هر دو API اجرا کنید:
$ gcloud services enable pubsub.googleapis.com datastore.googleapis.com Operation "operations/acat.p2-aaa-bbb-ccc-ddd-eee-ffffff" finished successfully.
ممکن است از شما اطلاعات صورتحساب خواسته شود. اگر میخواهید سایر APIهای ابری را فعال کنید و آدرسهای اینترنتی (URI) آنها را بدانید، میتوانید آنها را در پایین صفحه کتابخانه هر API پیدا کنید. به عنوان مثال، pubsub.googleapis.com به عنوان "نام سرویس" در پایین صفحه Pub/Sub درست در بالا مشاهده کنید.
پس از اتمام مراحل، پروژه شما قادر به دسترسی به APIها خواهد بود. اکنون زمان آن رسیده است که برنامه را برای استفاده از آن APIها بهروزرسانی کنید.
۴. ایجاد منابع Pub/Sub
خلاصهای از ترتیب توالی گردش کار صف وظایف از ماژول ۱۸:
- ماژول ۱۸ از فایل
queue.yamlبرای ایجاد یک صف pull به نامpullqاستفاده کرد. - این برنامه وظایف را به صف انتظار اضافه میکند تا بازدیدکنندگان را ردیابی کند.
- وظایف در نهایت توسط یک کارگر پردازش میشوند که برای مدت زمان محدودی (یک ساعت) اجاره داده شده است.
- وظایفی برای شمارش تعداد بازدیدکنندگان اخیر اجرا میشوند.
- وظایف پس از اتمام از صف حذف میشوند.
شما قرار است یک گردش کار مشابه را با Pub/Sub تکرار کنید. بخش بعدی اصطلاحات اولیه Pub/Sub را معرفی میکند و سه روش مختلف برای ایجاد منابع Pub/Sub لازم ارائه میدهد.
صف وظایف موتور برنامه (pull) در مقابل اصطلاحات Cloud Pub/Sub
تغییر به Pub/Sub نیاز به کمی تغییر در واژگان شما دارد. در زیر دسته بندی های اصلی به همراه اصطلاحات مرتبط از هر دو محصول فهرست شده است. همچنین راهنمای مهاجرت را که شامل مقایسه های مشابهی است، مرور کنید.
- ساختار داده صفبندی: با صف وظیفه، دادهها به صفهای کشش (pull queue) میروند؛ با Pub/Sub، دادهها به تاپیکها (topics) میروند.
- واحدهای داده صفبندیشده: وظایف Pull با Task Queue، پیامهایی با Pub/Sub نامیده میشوند.
- پردازندههای داده: با صف وظایف، کارگران به وظایف pull دسترسی دارند؛ با Pub/Sub، برای دریافت پیامها به اشتراک/مشترک نیاز دارید.
- استخراج دادهها: اجاره یک وظیفه pull مشابه دریافت پیام از یک تاپیک (از طریق اشتراک) است.
- پاکسازی/تکمیل: حذف یک وظیفه از صف وظایف (Task Queue) پس از اتمام کار، مشابه تأیید یک پیام Pub/Sub است.
اگرچه محصول صفبندی تغییر میکند، اما گردش کار نسبتاً مشابه باقی میماند:
- به جای صف دریافت، این برنامه از موضوعی به نام
pullqاستفاده میکند. - به جای اضافه کردن وظایف به صف pull، برنامه پیامها را به یک تاپیک (
pullq) ارسال میکند. - به جای اینکه یک worker وظایف را از صف pull اجاره کند، یک مشترک به نام
workerپیامها را از تاپیکpullqدریافت میکند . - این برنامه، پیامهای مخرب را پردازش میکند و تعداد بازدیدکنندگان را در Datastore افزایش میدهد.
- به جای حذف وظایف از صف انتظار، برنامه پیامهای پردازششده را تأیید میکند .
با Task Queue، راهاندازی شامل ایجاد صف pull میشود. با Pub/Sub، راهاندازی نیاز به ایجاد یک موضوع و یک اشتراک دارد. در ماژول ۱۸، queue.yaml خارج از اجرای برنامه پردازش کردیم؛ اکنون همین کار باید با Pub/Sub انجام شود.
سه گزینه برای ایجاد موضوعات و اشتراکها وجود دارد:
- از کنسول ابری
- از خط فرمان، یا
- از کد (اسکریپت کوتاه پایتون)
یکی از گزینههای زیر را انتخاب کنید و دستورالعملهای مربوطه را برای ایجاد منابع Pub/Sub خود دنبال کنید.
از کنسول ابری
برای ایجاد یک موضوع از کنسول ابری، مراحل زیر را دنبال کنید:
- به صفحه «موضوعات فرعی/میخانهها» در کنسول ابری بروید.
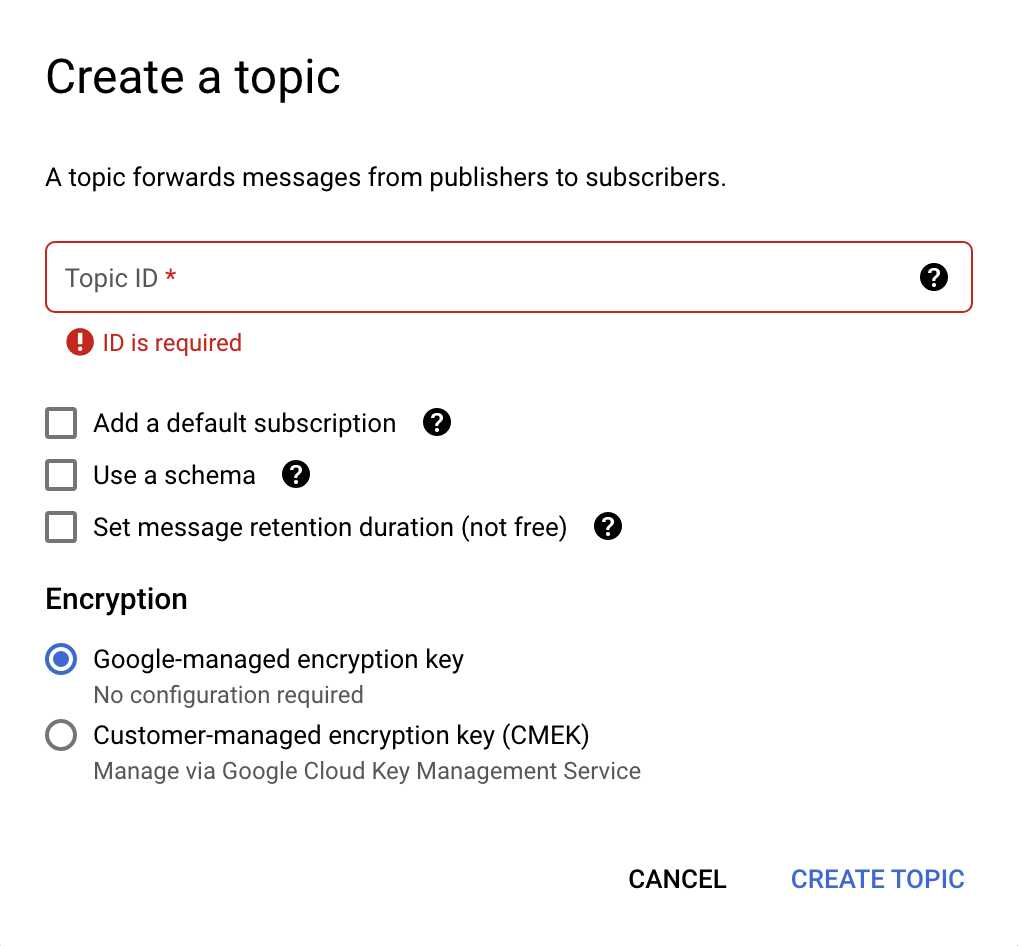
- روی ایجاد موضوع در بالا کلیک کنید؛ یک پنجره محاورهای جدید باز میشود (تصویر زیر را ببینید)
- در فیلد شناسه موضوع ،
pullqوارد کنید. - همه گزینههای تیکدار را از حالت انتخاب خارج کنید و کلید رمزگذاری مدیریتشده توسط گوگل را انتخاب کنید.
- Click the Create topic button.
این همان چیزی است که کادر گفتگوی ایجاد موضوع به نظر میرسد:
حالا که یک موضوع دارید، باید برای آن موضوع یک اشتراک ایجاد کنید:
- به صفحه اشتراکهای انتشار/عضویت در کنسول ابری بروید.
- روی ایجاد اشتراک در بالا کلیک کنید (تصویر زیر را ببینید).
- در قسمت شناسه اشتراک،
workerرا وارد کنید. - از منوی کشویی Select a Cloud Pub/Sub topic ، گزینه
pullqانتخاب کنید و به «نام مسیر کاملاً واجد شرایط» آن توجه کنید، مثلاًprojects/PROJECT_ID/topics/pullq - برای نوع تحویل ، گزینه «دریافت» را انتخاب کنید.
- سایر گزینهها را به حال خود رها کنید و روی دکمهی «ایجاد» کلیک کنید.
صفحه ایجاد اشتراک به این شکل است:
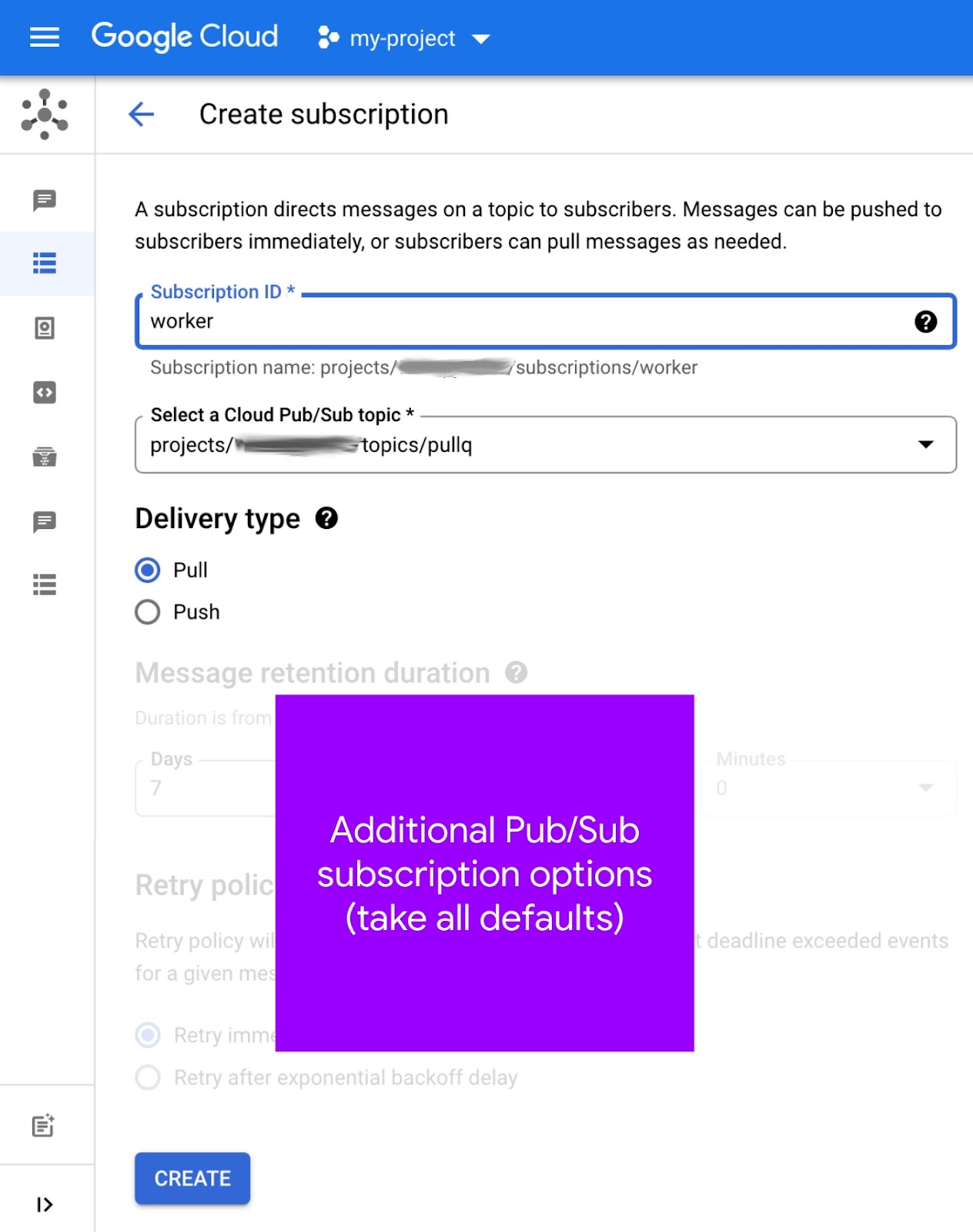
همچنین میتوانید از صفحه موضوعات، اشتراک ایجاد کنید - این «میانبر» ممکن است برای کمک به مرتبط کردن موضوعات با اشتراکها مفید باشد. برای کسب اطلاعات بیشتر در مورد ایجاد اشتراک، به مستندات مراجعه کنید.
از خط فرمان
کاربران Pub/Sub میتوانند با استفاده از دستورات gcloud pubsub topics create TOPIC_ID و gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic= TOPIC_ID به ترتیب موضوعات و اشتراکها را ایجاد کنند. اجرای این دستورات با TOPIC_ID از pullq و SUBSCRIPTION_ID از worker منجر به خروجی زیر برای پروژه PROJECT_ID میشود:
$ gcloud pubsub topics create pullq Created topic [projects/PROJECT_ID/topics/pullq]. $ gcloud pubsub subscriptions create worker --topic=pullq Created subscription [projects/PROJECT_ID/subscriptions/worker].
همچنین به این صفحه در مستندات شروع سریع مراجعه کنید. استفاده از خط فرمان میتواند گردش کار را در مواردی که موضوعات و اشتراکها به طور منظم ایجاد میشوند، ساده کند و چنین دستوراتی را میتوان برای این منظور در اسکریپتهای پوسته استفاده کرد.
از کد (اسکریپت کوتاه پایتون)
راه دیگر برای خودکارسازی ایجاد موضوعات و اشتراکها، استفاده از API Pub/Sub در کد منبع است. در زیر کد مربوط به اسکریپت maker.py در پوشه مخزن ماژول ۱۹ آمده است.
from __future__ import print_function
import google.auth
from google.api_core import exceptions
from google.cloud import pubsub
_, PROJECT_ID = google.auth.default()
TOPIC = 'pullq'
SBSCR = 'worker'
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
def make_top():
try:
top = ppc_client.create_topic(name=TOP_PATH)
print('Created topic %r (%s)' % (TOPIC, top.name))
except exceptions.AlreadyExists:
print('Topic %r already exists at %r' % (TOPIC, TOP_PATH))
def make_sub():
try:
sub = psc_client.create_subscription(name=SUB_PATH, topic=TOP_PATH)
print('Subscription created %r (%s)' % (SBSCR, sub.name))
except exceptions.AlreadyExists:
print('Subscription %r already exists at %r' % (SBSCR, SUB_PATH))
try:
psc_client.close()
except AttributeError: # special Py2 handler for grpcio<1.12.0
pass
make_top()
make_sub()
اجرای این اسکریپت منجر به خروجی مورد انتظار میشود (مشروط بر اینکه هیچ خطایی وجود نداشته باشد):
$ python3 maker.py Created topic 'pullq' (projects/PROJECT_ID/topics/pullq) Subscription created 'worker' (projects/PROJECT_ID/subscriptions/worker)
فراخوانی API برای ایجاد منابع از قبل موجود، منجر به خطای google.api_core.exceptions.AlreadyExists میشود که توسط کتابخانه کلاینت ایجاد شده و توسط اسکریپت به خوبی مدیریت میشود:
$ python3 maker.py Topic 'pullq' already exists at 'projects/PROJECT_ID/topics/pullq' Subscription 'worker' already exists at 'projects/PROJECT_ID/subscriptions/worker'
اگر در زمینه Pub/Sub تازهکار هستید، برای اطلاعات بیشتر به مقاله رسمی معماری Pub/Sub مراجعه کنید.
۵. بهروزرسانی پیکربندی
بهروزرسانیها در پیکربندی شامل تغییر فایلهای پیکربندی مختلف و همچنین ایجاد معادل صفهای کشش App Engine اما در اکوسیستم Cloud Pub/Sub میشود.
حذف queue.yaml
ما کاملاً از صف وظایف (Task Queue) فاصله میگیریم، بنابراین queue.yaml حذف کنید زیرا Pub/Sub از این فایل استفاده نمیکند. به جای ایجاد یک صف کشش (pull queue )، یک موضوع Pub/Sub (و اشتراک ) ایجاد خواهید کرد.
الزامات.txt
هر دو فایل google-cloud-ndb و google-cloud-pubsub به requirements.txt اضافه کنید تا به flask از ماژول ۱۸ متصل شود. requirements.txt ماژول ۱۹ بهروزرسانیشدهی شما اکنون باید به شکل زیر باشد:
flask
google-cloud-ndb
google-cloud-pubsub
این فایل requirements.txt هیچ شماره نسخهای ندارد، به این معنی که آخرین نسخهها انتخاب شدهاند. در صورت بروز هرگونه ناسازگاری، از روش استاندارد استفاده از شماره نسخهها برای قفل کردن نسخههای کاری یک برنامه پیروی کنید.
برنامه.yaml
تغییرات در app.yaml بسته به اینکه آیا از پایتون ۲ استفاده میکنید یا به پایتون ۳ ارتقا میدهید، متفاوت است.
پایتون ۲
بهروزرسانی فوق در requirements.txt ، استفاده از کتابخانههای کلاینت Google Cloud را اضافه میکند. این کتابخانهها نیاز به پشتیبانی اضافی از App Engine، یعنی چند کتابخانه داخلی ، setuptools و grpcio . استفاده از کتابخانههای داخلی نیاز به یک بخش libraries در app.yaml و شماره نسخه کتابخانه یا "آخرین" برای جدیدترین نسخههای موجود در سرورهای App Engine دارد. ماژول 18 app.yaml هنوز یکی از این بخشها را ندارد:
قبل از:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
یک بخش libraries به app.yaml به همراه ورودیهایی برای setuptools و grpcio اضافه کنید و آخرین نسخههای آنها را انتخاب کنید. همچنین یک ورودی runtime برای پایتون ۳ اضافه کنید که به همراه نسخه ۳.x فعلی، مثلاً ۳.۱۰، در زمان نوشتن این مطلب، کامنتگذاری شده است. با این تغییرات، app.yaml اکنون به این شکل است:
بعد از:
#runtime: python310
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
libraries:
- name: setuptools
version: latest
- name: grpcio
version: latest
پایتون ۳
برای کاربران پایتون ۳ و app.yaml ، همه چیز در مورد حذف موارد است. در این بخش، بخش handlers ، دستورالعملهای threadsafe و api_version را حذف خواهید کرد و بخش libraries را ایجاد نخواهید کرد.
نسل دوم سیستمعاملها ، کتابخانههای شخص ثالث داخلی را ارائه نمیدهند، بنابراین نیازی به بخش libraries در app.yaml نیست . علاوه بر این، کپی کردن (که گاهی اوقات به عنوان vendor یا self-bundling شناخته میشود) بستههای شخص ثالث غیر داخلی دیگر لازم نیست. شما فقط باید کتابخانههای شخص ثالثی را که برنامه شما از آنها استفاده میکند، در requirements.txt فهرست کنید.
بخش handlers در app.yaml برای مشخص کردن handlers برنامه (اسکریپت) و فایلهای استاتیک است. از آنجایی که زمان اجرای پایتون ۳ به چارچوبهای وب نیاز دارد تا مسیریابی خود را انجام دهند، همه handlers اسکریپت باید به auto تغییر داده شوند. اگر برنامه شما (مانند ماژول ۱۸) فایلهای استاتیک را پشتیبانی نمیکند، همه مسیرها auto خواهند بود و آنها را بیاهمیت میکند. در نتیجه، بخش handlers نیز مورد نیاز نیست، بنابراین آن را حذف کنید.
در نهایت، نه دستورالعملهای threadsafe و نه api_version در پایتون ۳ استفاده نمیشوند، بنابراین آنها را نیز حذف کنید. نکته اصلی این است که شما باید تمام بخشهای app.yaml را حذف کنید تا فقط دستورالعمل runtime باقی بماند و نسخه مدرن پایتون ۳، مثلاً ۳.۱۰ را مشخص کند. در اینجا نحوه نمایش app.yaml قبل و بعد از این بهروزرسانیها آمده است:
قبل از:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
بعد از:
runtime: python310
برای کسانی که آماده نیستند همه چیز را از app.yaml خود برای پایتون ۳ حذف کنند، ما یک فایل جایگزین app3.yaml در پوشه مخزن ماژول ۱۹ ارائه دادهایم. اگر میخواهید از آن برای استقرارها استفاده کنید، حتماً این نام فایل را به انتهای دستور خود اضافه کنید: gcloud app deploy app3.yaml (در غیر این صورت، به طور پیشفرض برنامه شما را با فایل app.yaml پایتون ۲ که بدون تغییر باقی گذاشتهاید، مستقر میکند و مستقر میکند).
appengine_config.py
اگر در حال ارتقا به پایتون ۳ هستید، نیازی به appengine_config.py نیست، بنابراین آن را حذف کنید. دلیل عدم نیاز به آن این است که پشتیبانی از کتابخانههای شخص ثالث فقط نیاز به مشخص کردن آنها در requirements.txt دارد. کاربران پایتون ۲، ادامه مطلب را بخوانید.
ماژول ۱۸ appengine_config.py کد مناسبی برای پشتیبانی از کتابخانههای شخص ثالث دارد، برای مثال، Flask و کتابخانههای کلاینت Cloud که به requirements.txt اضافه شدهاند:
قبل از:
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
با این حال، این کد به تنهایی برای پشتیبانی از کتابخانههای داخلی تازه اضافه شده ( setuptools ، grpcio ) کافی نیست. چند خط دیگر مورد نیاز است، بنابراین appengine_config.py را بهروزرسانی کنید تا به شکل زیر باشد:
بعد از:
import pkg_resources
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
# Add libraries to pkg_resources working set to find the distribution.
pkg_resources.working_set.add_entry(PATH)
جزئیات بیشتر در مورد تغییرات مورد نیاز برای پشتیبانی از کتابخانههای کلاینت ابری را میتوانید در مستندات سرویسهای همراه در حال انتقال بیابید.
سایر بهروزرسانیهای پیکربندی
اگر پوشه lib دارید، آن را حذف کنید. اگر کاربر پایتون ۲ هستید، با اجرای دستور زیر، پوشه lib را دوباره پر کنید:
pip install -t lib -r requirements.txt # or pip2
اگر پایتون ۲ و ۳ را روی سیستم توسعه خود نصب کردهاید، ممکن است لازم باشد به جای pip از pip2 استفاده کنید.
۶. کد برنامه را تغییر دهید
این بخش شامل بهروزرسانیهایی برای فایل اصلی برنامه، main.py ، است که استفاده از صفهای دریافت وظیفه App Engine را با Cloud Pub/Sub جایگزین میکند. هیچ تغییری در الگوی وب، templates/index.html ، ایجاد نمیشود. هر دو برنامه باید به طور یکسان عمل کنند و دادههای یکسانی را نمایش دهند.
بهروزرسانی واردات و مقداردهی اولیه
چندین بهروزرسانی در مورد واردات و مقداردهی اولیه وجود دارد:
- برای ایمپورتها، App Engine NDB و Task Queue را با Cloud NDB و Pub/Sub جایگزین کنید.
- نام
pullqازQUEUEبهTOPICتغییر دهید. - در وظایف pull، کارگر آنها را به مدت یک ساعت اجاره میداد، اما در Pub/Sub، زمانهای انقضا بر اساس هر پیام اندازهگیری میشوند، بنابراین ثابت
HOURرا حذف کنید. - APIهای ابری نیاز به استفاده از یک کلاینت API دارند، بنابراین آنها را برای Cloud NDB و Cloud Pub/Sub راهاندازی کنید، که دومی کلاینتهایی را برای موضوعات و اشتراکها فراهم میکند.
- Pub/Sub به شناسه پروژه ابری نیاز دارد، بنابراین آن را از
google.auth.default()وارد و دریافت کنید. - Pub/Sub برای موضوعات و اشتراکها به «نامهای مسیر کاملاً واجد شرایط» نیاز دارد، بنابراین آنها را با استفاده از توابع
*_path()ایجاد کنید.
در زیر، ایمپورتها و مقداردهی اولیه از ماژول ۱۸ و به دنبال آن نحوهی عملکرد بخشها پس از پیادهسازی تغییرات فوق آمده است، که بیشتر کد جدید، منابع مختلف Pub/Sub هستند:
قبل از:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
بعد از:
from flask import Flask, render_template, request
import google.auth
from google.cloud import ndb, pubsub
LIMIT = 10
TASKS = 1000
TOPIC = 'pullq'
SBSCR = 'worker'
app = Flask(__name__)
ds_client = ndb.Client()
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
_, PROJECT_ID = google.auth.default()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
از بهروزرسانیهای مدل داده بازدید کنید
مدل داده Visit تغییر نمیکند. دسترسی به Datastore مستلزم استفاده صریح از مدیریت زمینه کلاینت Cloud NDB API، یعنی ds_client.context() است. در کد، این بدان معناست که شما فراخوانیهای Datastore را در هر دو store_visit() و fetch_visits() درون پایتون with بلوکها قرار میدهید. این بهروزرسانی مشابه مواردی است که در ماژول ۲ پوشش داده شده است.
مهمترین تغییر برای Pub/Sub، جایگزینی enqueuing یک Task Queue pull task با انتشار یک پیام Pub/Sub در تاپیک pullq است. در زیر کد قبل و بعد از انجام این بهروزرسانیها آمده است:
قبل از:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
بعد از:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
with ds_client.context():
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
ppc_client.publish(TOP_PATH, remote_addr.encode('utf-8'))
def fetch_visits(limit):
'get most recent visits'
with ds_client.context():
return Visit.query().order(-Visit.timestamp).fetch(limit)
بهروزرسانیهای مدل داده VisitorCount
مدل داده VisitorCount تغییر نمیکند و از fetch_counts() استفاده میکند، به جز اینکه کوئری Datastore خود را درون یک بلوک with قرار میدهد، همانطور که در زیر نشان داده شده است:
قبل از:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
بعد از:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
with ds_client.context():
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
کد کارگر را بهروزرسانی کنید
کد worker تا جایی بهروزرسانی میشود که NDB را با Cloud NDB و Task Queue را با Pub/Sub جایگزین میکند، اما گردش کار آن ثابت میماند.
- فراخوانیهای Datastore را در مدیریت زمینه Cloud NDB
withبلوک، پوشش دهید. - پاکسازی صف وظایف شامل حذف تمام وظایف از صف دریافت است. با Pub/Sub، "شناسههای تأیید" در
acksجمعآوری شده و سپس در انتها حذف/تأیید میشوند. - وظایف pull صف وظایف به روشی مشابه با پیامهای Pub/Sub که pull میشوند، اجاره داده میشوند. در حالی که حذف وظایف pull با خود اشیاء وظیفه انجام میشود، پیامهای Pub/Sub از طریق شناسههای تأیید آنها حذف میشوند.
- بارهای داده پیامهای Pub/Sub به بایت نیاز دارند (نه رشتههای پایتون)، بنابراین هنگام انتشار و دریافت پیامها از یک تاپیک، به ترتیب مقداری رمزگذاری و رمزگشایی UTF-8 وجود دارد.
log_visitors() با کد بهروزرسانیشدهی زیر که تغییرات شرح داده شده را پیادهسازی میکند، جایگزین کنید:
قبل از:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
بعد از:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
acks = set()
rsp = psc_client.pull(subscription=SUB_PATH, max_messages=TASKS)
msgs = rsp.received_messages
for rcvd_msg in msgs:
acks.add(rcvd_msg.ack_id)
visitor = rcvd_msg.message.data.decode('utf-8')
tallies[visitor] = tallies.get(visitor, 0) + 1
if acks:
psc_client.acknowledge(subscription=SUB_PATH, ack_ids=acks)
try:
psc_client.close()
except AttributeError: # special handler for grpcio<1.12.0
pass
# increment those counts in Datastore and return
if tallies:
with ds_client.context():
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(msgs), len(tallies))
هیچ تغییری در root() کنترلکننده اصلی برنامه ایجاد نشده است. هیچ تغییری در فایل قالب HTML، templates/index.html ، نیز لازم نیست، بنابراین این شامل تمام بهروزرسانیهای لازم میشود. تبریک میگوییم که به برنامه ماژول ۱۹ جدید خود با استفاده از Cloud Pub/Sub دسترسی پیدا کردید!
۷. خلاصه/پاکسازی
برنامه خود را مستقر کنید تا تأیید شود که طبق برنامه و در هر خروجی منعکس شده کار میکند. همچنین worker را برای پردازش تعداد بازدیدکنندگان اجرا کنید. پس از اعتبارسنجی برنامه، مراحل پاکسازی را انجام دهید و مراحل بعدی را در نظر بگیرید.
استقرار و تأیید برنامه
مطمئن شوید که قبلاً موضوع pullq و اشتراک worker را ایجاد کردهاید. اگر این کار تکمیل شده و برنامه نمونه شما آماده استفاده است، برنامه خود را با gcloud app deploy مستقر کنید. خروجی باید مشابه برنامه ماژول ۱۸ باشد، با این تفاوت که کل مکانیسم صفبندی زیربنایی را با موفقیت جایگزین کردهاید:
اکنون رابط کاربری وب برنامه، عملکرد این بخش از برنامه را تأیید میکند. در حالی که این بخش از برنامه با موفقیت بازدیدکنندگان برتر و جدیدترین بازدیدها را جستجو و نمایش میدهد، به یاد داشته باشید که برنامه این بازدید را به همراه ایجاد یک وظیفه pull برای اضافه کردن این بازدیدکننده به تعداد کل، ثبت میکند. آن وظیفه اکنون در صف انتظار برای پردازش است.
شما میتوانید این کار را با یک سرویس backend موتور برنامه، یک cron job، مرور در /log یا صدور یک درخواست HTTP خط فرمان اجرا کنید. در اینجا یک نمونه اجرا و فراخوانی کد worker با curl آورده شده است ( PROJECT_ID خود را جایگزین کنید):
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
تعداد بهروزرسانیشده سپس در بازدید بعدی از وبسایت اعمال خواهد شد. همین!
تمیز کردن
عمومی
اگر فعلاً کارتان تمام است، توصیه میکنیم برنامه App Engine خود را غیرفعال کنید تا از پرداخت هزینه جلوگیری شود. با این حال، اگر میخواهید بیشتر آزمایش یا تجربه کنید، پلتفرم App Engine سهمیه رایگان دارد و بنابراین تا زمانی که از آن سطح استفاده تجاوز نکنید، نباید هزینهای از شما دریافت شود. این هزینه برای محاسبات است، اما ممکن است برای سرویسهای مربوطه App Engine نیز هزینههایی وجود داشته باشد، بنابراین برای اطلاعات بیشتر به صفحه قیمتگذاری آن مراجعه کنید. اگر این مهاجرت شامل سایر سرویسهای ابری باشد، هزینه آنها جداگانه محاسبه میشود. در هر صورت، در صورت لزوم، به بخش "ویژه این codelab" در زیر مراجعه کنید.
برای روشن شدن کامل موضوع، استقرار در یک پلتفرم محاسباتی بدون سرور Google Cloud مانند App Engine هزینههای ساخت و ذخیرهسازی کمی را متحمل میشود. Cloud Build نیز مانند Cloud Storage سهمیه رایگان خود را دارد. ذخیرهسازی آن تصویر مقداری از آن سهمیه را مصرف میکند. با این حال، ممکن است در منطقهای زندگی کنید که چنین ردیف رایگانی ندارد، بنابراین برای به حداقل رساندن هزینههای احتمالی، از میزان استفاده از فضای ذخیرهسازی خود آگاه باشید. «پوشههای» خاص Cloud Storage که باید بررسی کنید عبارتند از:
-
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/images -
console.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com - لینکهای ذخیرهسازی بالا به
PROJECT_IDو *LOC*ation شما بستگی دارند، برای مثال، اگر برنامه شما در ایالات متحده میزبانی میشود، "us" خواهد بود.
از طرف دیگر، اگر قصد ندارید با این برنامه یا سایر آزمایشگاههای کد مهاجرت مرتبط ادامه دهید و میخواهید همه چیز را به طور کامل حذف کنید، پروژه خود را ببندید .
مخصوص این آزمایشگاه کد
سرویسهای ذکر شده در زیر مختص این codelab هستند. برای اطلاعات بیشتر به مستندات هر محصول مراجعه کنید:
- اجزای مختلف Cloud Pub/Sub یک سطح رایگان دارند؛ برای درک بهتر از پیامدهای هزینه، میزان استفاده کلی خود را تعیین کنید و برای جزئیات بیشتر به صفحه قیمتگذاری آن مراجعه کنید.
- سرویس App Engine Datastore توسط Cloud Datastore (Cloud Firestore در حالت Datastore) ارائه میشود که یک نسخه رایگان نیز دارد؛ برای اطلاعات بیشتر به صفحه قیمتگذاری آن مراجعه کنید.
مراحل بعدی
فراتر از این آموزش، ماژولهای مهاجرت دیگری که بر دور شدن از سرویسهای همراه قدیمی تمرکز دارند، عبارتند از:
- ماژول 2 : مهاجرت از App Engine
ndbبه Cloud NDB - ماژولهای ۷-۹ : مهاجرت از صف وظایف موتور برنامه (وظایف ارسالی) به وظایف ابری
- ماژولهای ۱۲-۱۳ : مهاجرت از App Engine Memcache به Cloud Memorystore
- ماژولهای ۱۵-۱۶ : مهاجرت از App Engine Blobstore به Cloud Storage
App Engine دیگر تنها پلتفرم بدون سرور در Google Cloud نیست. اگر یک برنامه کوچک App Engine یا برنامهای با قابلیتهای محدود دارید و میخواهید آن را به یک میکروسرویس مستقل تبدیل کنید، یا میخواهید یک برنامه یکپارچه را به چندین مؤلفه قابل استفاده مجدد تقسیم کنید، اینها دلایل خوبی برای در نظر گرفتن انتقال به Cloud Functions هستند. اگر کانتینرسازی به بخشی از گردش کار توسعه برنامه شما تبدیل شده است، به خصوص اگر شامل یک خط لوله CI/CD (ادغام مداوم/تحویل مداوم یا استقرار) باشد، مهاجرت به Cloud Run را در نظر بگیرید. این سناریوها توسط ماژولهای زیر پوشش داده میشوند:
- مهاجرت از موتور برنامه به توابع ابری: به ماژول 11 مراجعه کنید
- مهاجرت از App Engine به Cloud Run: برای کانتینرایز کردن برنامه خود با Docker به ماژول ۴ و برای انجام این کار بدون کانتینرها، دانش Docker یا
Dockerfileها به ماژول ۵ مراجعه کنید.
تغییر به یک پلتفرم بدون سرور دیگر اختیاری است و توصیه میکنیم قبل از ایجاد هرگونه تغییر، بهترین گزینهها را برای برنامهها و موارد استفاده خود در نظر بگیرید.
صرف نظر از اینکه کدام ماژول مهاجرت را در مرحله بعد در نظر بگیرید، تمام محتوای Serverless Migration Station (آزمایشگاههای کد، ویدیوها، کد منبع [در صورت وجود]) در مخزن متنباز آن قابل دسترسی است. README این مخزن همچنین راهنماییهایی در مورد اینکه کدام مهاجرتها را باید در نظر گرفت و هرگونه «ترتیب» مربوط به ماژولهای مهاجرت ارائه میدهد.
۸. منابع اضافی
در زیر منابع بیشتری برای توسعهدهندگان جهت بررسی بیشتر این ماژول مهاجرت یا ماژولهای مرتبط و همچنین محصولات مرتبط فهرست شده است. این منابع شامل مکانهایی برای ارائه بازخورد در مورد این محتوا، لینکهایی به کد و مستندات مختلفی است که ممکن است برای شما مفید باشند.
مشکلات/بازخوردهای Codelabs
اگر در این آزمایشگاه کد مشکلی پیدا کردید، لطفاً قبل از ثبت، ابتدا مشکل خود را جستجو کنید. لینکهای جستجو و ایجاد مشکلات جدید:
منابع مهاجرت
لینکهای پوشههای مخزن ماژول ۱۸ (شروع) و ماژول ۱۹ (پایان) را میتوانید در جدول زیر بیابید.
کدلب | پایتون ۲ | پایتون ۳ |
(نامشخص) | ||
ماژول ۱۹ (این آزمایشگاه کد) | (مشابه پایتون ۲ با این تفاوت که از app3.yaml استفاده میکند، مگر اینکه app.yaml را طبق توضیحات بالا بهروزرسانی کرده باشید) |
مراجع آنلاین
منابع مرتبط با این آموزش در زیر آمده است:
صف وظایف موتور برنامه
- مرور کلی صف وظایف موتور برنامه
- مرور کلی صفهای pull در صف وظیفه موتور برنامه
- موتور برنامه، صف وظایف، صف کشیدن، نمونه برنامه کامل
- ایجاد صفهای pull برای Task Queue
- ویدیوی شروع صف انتظار کنفرانس گوگل آی/او ۲۰۱۱ ( نمونه برنامه Votelator )
- مرجع
queue.yaml -
queue.yamlدر مقابل Cloud Tasks - صفها را به راهنمای مهاجرت Pub/Sub بکشید
میخانه/زیرشبکه ابری
- صفحه ابر میخانه/زیرمحصول
- استفاده از کتابخانههای Pub/Sub client
- نمونههای کتابخانه کلاینت پایتون Pub/Sub
- مستندات کتابخانه کلاینت پایتون Pub/Sub
- ایجاد و مدیریت موضوعات عمومی/فرعی
- دستورالعملهای نامگذاری موضوع میخانه/زیرموضوع
- ایجاد و مدیریت اشتراکهای Pub/Sub
- موتور برنامه (انعطافپذیر) برنامه نمونه (قابل گسترش به استاندارد نیز هست؛ پایتون ۳)
- مخزن برای برنامه نمونه بالا
- اشتراکهای Pub/Sub-pull
- Pub/Sub push subscriptions
- نمونه برنامه Pub/Sub push موتور برنامه (پایتون ۳)
- مخزن برنامه نمونه Pub/Sub-push موتور برنامه
- اطلاعات قیمتگذاری میخانه/زیرقیمت
- وظایف ابری یا انتشار/زیرنویس ابری ؟ (فشار دادن در مقابل کشیدن)
NDB موتور برنامه و NDB ابری (ذخیره داده)
- اسناد NDB موتور برنامه
- مخزن NDB موتور برنامه
- اسناد Google Cloud NDB
- مخزن Google Cloud NDB
- اطلاعات قیمتگذاری فروشگاه داده ابری
پلتفرم موتور برنامه
- مستندات موتور برنامه
- موتور برنامه پایتون ۲ (محیط استاندارد) در زمان اجرا
- استفاده از کتابخانههای داخلی App Engine در Python 2 App Engine
- موتور برنامه پایتون ۳ (محیط استاندارد) در زمان اجرا
- تفاوتهای بین زمانهای اجرای موتور برنامه پایتون ۲ و ۳ (محیط استاندارد)
- راهنمای مهاجرت موتور برنامه پایتون ۲ به ۳ (محیط استاندارد)
- اطلاعات قیمتگذاری و سهمیهبندی موتور برنامه
- راهاندازی پلتفرم نسل دوم App Engine (۲۰۱۸)
- مقایسه پلتفرمهای نسل اول و دوم
- پشتیبانی بلندمدت از رانتایمهای قدیمی
- نمونههای مهاجرت مستندات
- نمونههای مهاجرت با مشارکت جامعه
سایر اطلاعات ابری
- پایتون در پلتفرم ابری گوگل
- کتابخانههای کلاینت پایتون گوگل کلود
- سطح «همیشه رایگان» گوگل کلود
- کیت توسعه نرمافزار گوگل کلود (ابزار خط فرمان
gcloud) - تمام مستندات گوگل کلود
ویدیوها
- ایستگاه مهاجرت بدون سرور
- سفرهای اکتشافی بدون سرور
- مشترک شدن در فناوری ابری گوگل
- مشترک شدن در توسعهدهندگان گوگل
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 2.0 منتشر شده است.