
1. Przegląd
Seria codelabów Serverless Migration Station (samodzielne, praktyczne samouczki) i powiązane z nimi filmy mają na celu pomóc deweloperom usług bezserwerowych Google Cloud w modernizacji aplikacji poprzez przeprowadzenie ich przez co najmniej jedną migrację, głównie z usług starszego typu. Dzięki temu Twoje aplikacje będą bardziej przenośne, a Ty zyskasz więcej opcji i elastyczności, co umożliwi Ci integrację z szerszą gamą usług w chmurze i łatwiejsze przechodzenie na nowsze wersje języka. Chociaż początkowo skupialiśmy się na pierwszych użytkownikach usług w chmurze, głównie na deweloperach App Engine (środowisko standardowe), ta seria jest wystarczająco szeroka, aby obejmować inne platformy bezserwerowe, takie jak Cloud Functions i Cloud Run, lub inne, jeśli ma to zastosowanie.
Celem tego laboratorium jest pokazanie deweloperom aplikacji App Engine w Pythonie 2, jak przeprowadzić migrację z zadań pull w kolejce zadań App Engine do Cloud Pub/Sub. W przypadku dostępu do Datastore (głównie w module 2) następuje też niejawna migracja z App Engine NDB do Cloud NDB, a także przejście na Pythona 3.
W module 18 dowiesz się, jak dodać do aplikacji zadania typu pull. W tym module weźmiesz gotową aplikację z modułu 18 i przeniesiesz jej funkcje do Cloud Pub/Sub. Użytkownicy, którzy korzystają z kolejek zadań do zadań push, powinni zamiast tego przejść na Cloud Tasks i zapoznać się z modułami 7–9.
Dowiesz się, jak:
- Zastąpienie kolejki zadań App Engine (zadań pull) Cloud Pub/Sub
- Zastąp App Engine NDB Cloud NDB (patrz też moduł 2).
- Przenoszenie aplikacji do Pythona 3
Czego potrzebujesz
- projekt Google Cloud Platform z aktywnym kontem rozliczeniowym GCP;
- podstawowe umiejętności w zakresie Pythona,
- Praktyczna znajomość typowych poleceń systemu Linux
- Podstawowa wiedza na temat tworzenia i wdrażania aplikacji App Engine.
- działająca przykładowa aplikacja App Engine z modułu 18;
Ankieta
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie z Pythonem?
Jak oceniasz korzystanie z usług Google Cloud?
2. Tło
Kolejka zadań App Engine obsługuje zadania push i pull. Aby zwiększyć przenośność aplikacji, Google Cloud zaleca migrację z starszych usług pakietowych, takich jak kolejka zadań, do innych samodzielnych usług w chmurze lub usług równoważnych innych firm.
- Użytkownicy zadań push w kolejce zadań powinni przejść na Cloud Tasks.
- Użytkownicy zadań pull w kolejce zadań powinni przejść na Cloud Pub/Sub.
Moduły 7–9 dotyczą migracji zadań typu push, a moduły 18–19 – migracji zadań typu pull. Cloud Tasks jest bardziej podobny do kolejek push w kolejkach zadań, ale Pub/Sub nie jest tak podobny do kolejek pull w kolejkach zadań.
Pub/Sub ma więcej funkcji niż funkcja pull udostępniana przez kolejkę zadań. Na przykład Pub/Sub ma też funkcję push, ale Cloud Tasks bardziej przypomina zadania push w kolejce zadań, więc funkcja push w Pub/Sub nie jest objęta żadnym z modułów migracji. W tym module 19 znajdziesz ćwiczenia z programowania, które pokazują, jak zmienić mechanizm kolejkowania z kolejek pull w Task Queue na Pub/Sub, a także jak przenieść dostęp do Datastore z App Engine NDB do Cloud NDB, powtarzając migrację z modułu 2.
Chociaż kod modułu 18 jest „reklamowany” jako przykładowa aplikacja w języku Python 2, sam kod jest zgodny z językami Python 2 i 3 i pozostaje taki nawet po migracji do Cloud Pub/Sub (i Cloud NDB) w tym module 19.
Ten samouczek obejmuje te kroki:
- Konfiguracja/przygotowanie
- Aktualizacja konfiguracji
- Modyfikowanie kodu aplikacji
3. Konfiguracja/przygotowanie
Z tej sekcji dowiesz się, jak:
- Konfigurowanie projektu w chmurze
- Pobieranie przykładowej aplikacji podstawowej
- (Ponowne) wdrażanie i weryfikowanie aplikacji podstawowej
- Włączanie nowych usług i interfejsów API Google Cloud
Dzięki tym czynnościom masz pewność, że zaczynasz od działającego kodu, który jest gotowy do migracji do usług w chmurze.
1. Konfigurowanie projektu
Jeśli masz za sobą laboratorium programowania w module 18, użyj tego samego projektu (i kodu). Możesz też utworzyć zupełnie nowy projekt lub użyć innego istniejącego projektu. Upewnij się, że projekt ma aktywne konto rozliczeniowe i włączoną aplikację App Engine. Znajdź identyfikator projektu, ponieważ będzie Ci potrzebny podczas tego szkolenia. Używaj go zawsze, gdy napotkasz zmienną PROJECT_ID.
2. Pobieranie przykładowej aplikacji podstawowej
Jednym z wymagań wstępnych jest działająca aplikacja App Engine z modułu 18, więc wykonaj ćwiczenia z programowania (zalecane; link powyżej) lub skopiuj kod modułu 18 z repozytorium. Niezależnie od tego, czy używasz własnego, czy naszego, od tego miejsca zaczniemy („START”). Ten codelab przeprowadzi Cię przez proces migracji, a na końcu znajdziesz kod podobny do tego w folderze repozytorium modułu 19 („FINISH”).
- START: Folder modułu 18 (Python 2)
- FINISH: Folder Module 19 (Python 2 i 3)
- Całe repozytorium (do sklonowania lub pobrania pliku ZIP)
Niezależnie od tego, której aplikacji z modułu 18 używasz, folder powinien wyglądać jak poniżej. Może też zawierać folder lib:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
3. (Ponowne) wdrażanie i weryfikowanie aplikacji podstawowej
Aby wdrożyć aplikację z modułu 18, wykonaj te czynności:
- Usuń folder
lib, jeśli istnieje, i uruchom poleceniepip install -t lib -r requirements.txt, aby ponownie wypełnić folderlib. Jeśli na komputerze używanym do programowania masz zainstalowane zarówno Pythona 2, jak i 3, może być konieczne użycie poleceniapip2. - Sprawdź, czy narzędzie wiersza poleceń
gcloudzostało zainstalowane i zainicjowane oraz czy zapoznano się z jego użyciem. - (opcjonalnie) Ustaw projekt w chmurze za pomocą polecenia
gcloud config set projectPROJECT_ID, jeśli nie chcesz wpisywaćPROJECT_IDprzy każdym poleceniugcloud. - Wdrażanie przykładowej aplikacji za pomocą
gcloud app deploy - Sprawdź, czy aplikacja działa zgodnie z oczekiwaniami i nie sprawia problemów. Jeśli udało Ci się ukończyć ćwiczenie z programowania w module 18, aplikacja wyświetli najważniejszych użytkowników wraz z najnowszymi wizytami (jak na ilustracji poniżej). W przeciwnym razie może nie być dostępnych żadnych danych o liczbie odwiedzających do wyświetlenia.
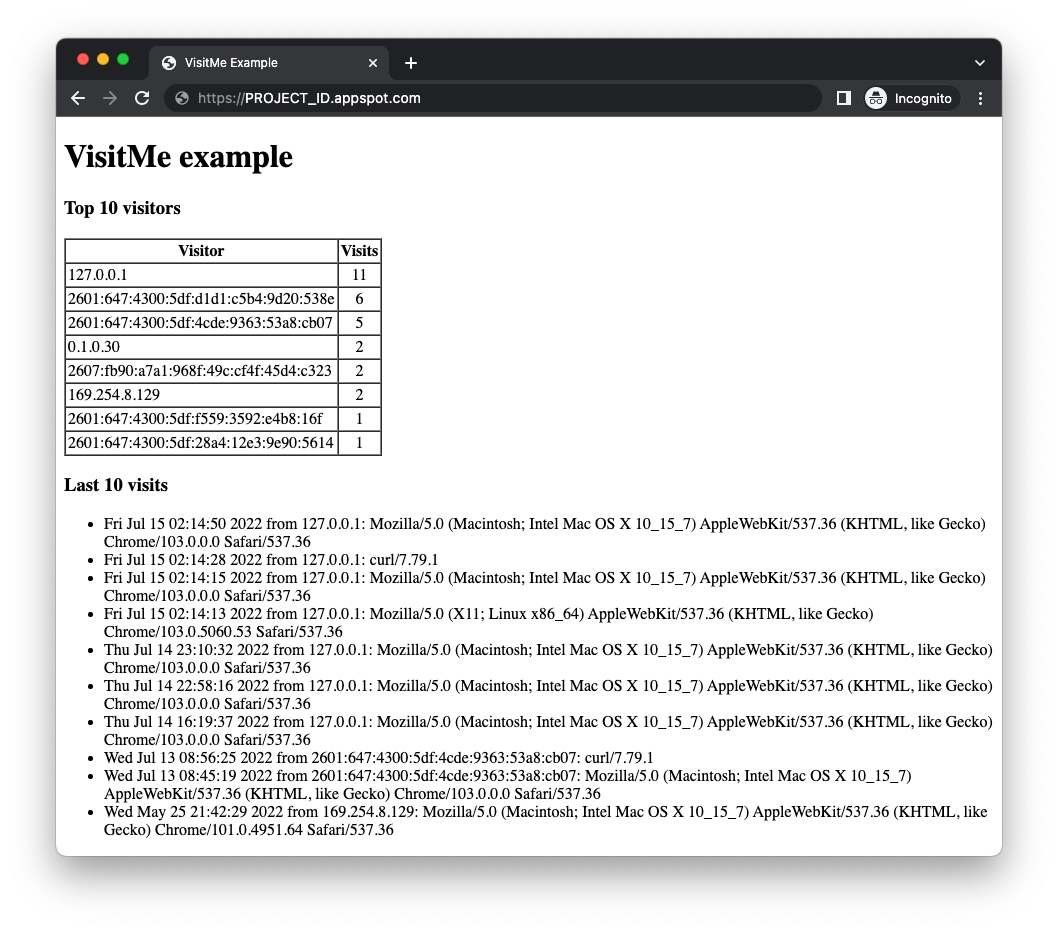
Zanim przeprowadzisz migrację przykładowej aplikacji z modułu 18, musisz najpierw włączyć usługi w chmurze, z których będzie korzystać zmodyfikowana aplikacja.
4. Włączanie nowych usług i interfejsów API Google Cloud
Stara aplikacja korzystała z usług pakietowych App Engine, które nie wymagają dodatkowej konfiguracji. Jednak samodzielne usługi Cloud wymagają konfiguracji, a zaktualizowana aplikacja będzie korzystać zarówno z Cloud Pub/Sub, jak i z Cloud Datastore (za pomocą biblioteki klienta Cloud NDB). App Engine i oba interfejsy Cloud API mają limity poziomu „Zawsze bezpłatnie”, więc jeśli nie przekroczysz tych limitów, ukończenie tego samouczka nie powinno wiązać się z żadnymi opłatami. Interfejsy API Cloud możesz włączyć w konsoli Cloud lub w wierszu poleceń, w zależności od preferencji.
W konsoli Cloud
Otwórz stronę Biblioteka Menedżera interfejsów API (w odpowiednim projekcie) w konsoli Cloud i wyszukaj interfejsy Cloud Datastore i Cloud Pub/Sub API za pomocą paska wyszukiwania na środku strony:
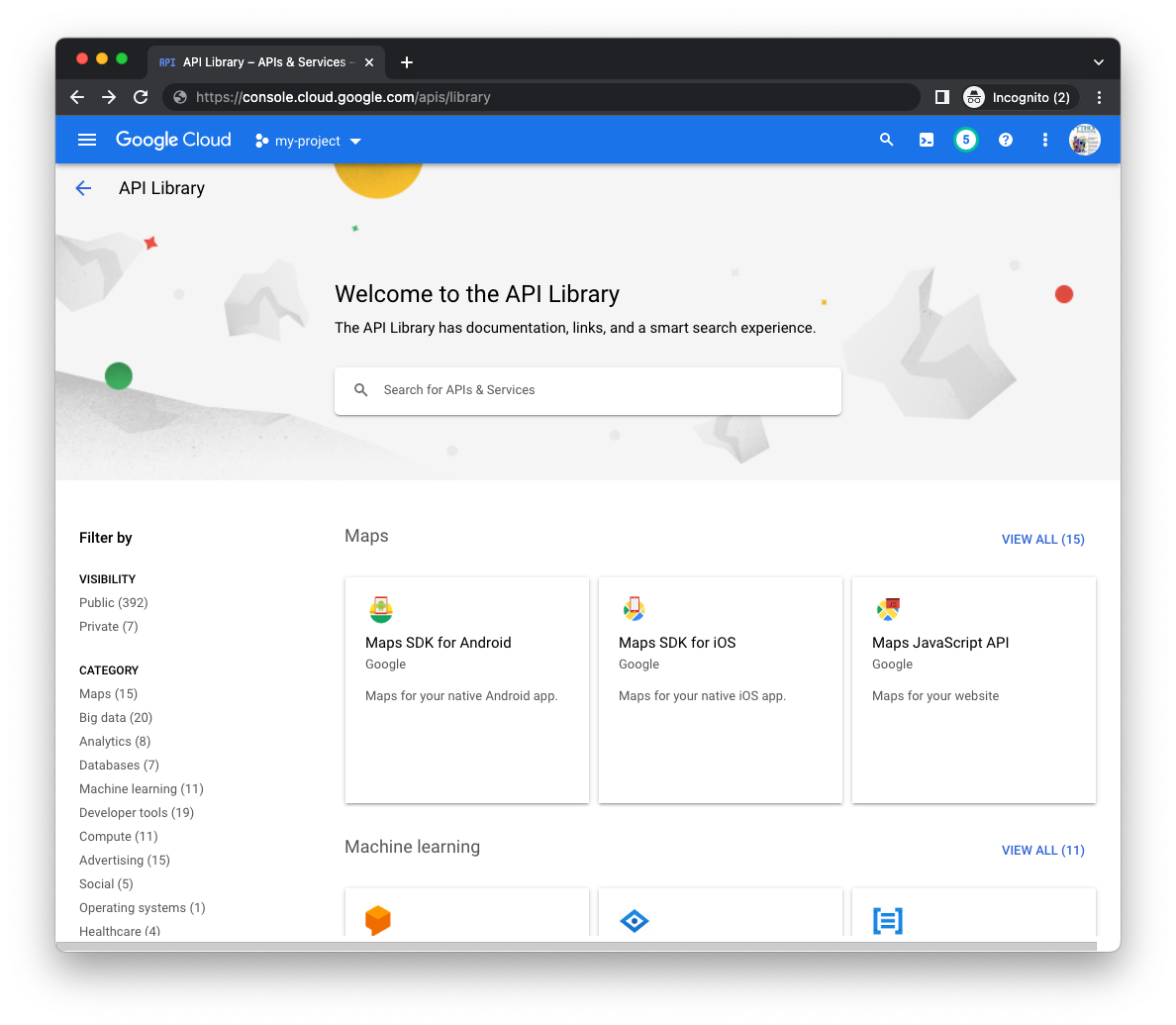
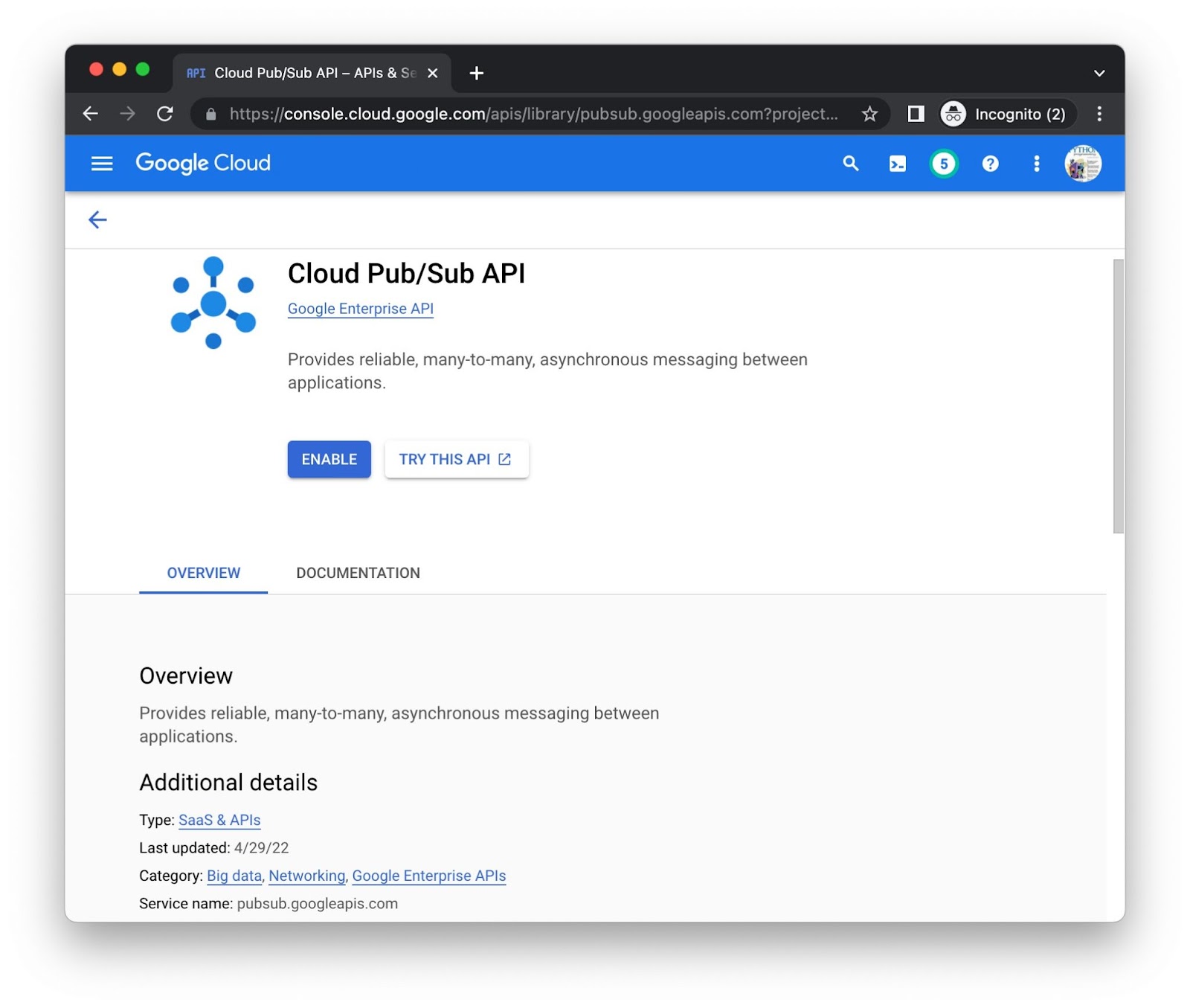
Kliknij przycisk Włącz przy każdym interfejsie API z osobna. Możesz zostać poproszony(-a) o podanie informacji rozliczeniowych. Na przykład tak wygląda strona biblioteki Cloud Pub/Sub API:
W wierszu poleceń
Włączanie interfejsów API w konsoli jest bardzo wygodne, ale niektórzy wolą wiersz poleceń. Wydaj polecenie gcloud services enable pubsub.googleapis.com datastore.googleapis.com, aby włączyć oba interfejsy API jednocześnie:
$ gcloud services enable pubsub.googleapis.com datastore.googleapis.com Operation "operations/acat.p2-aaa-bbb-ccc-ddd-eee-ffffff" finished successfully.
Może pojawić się prośba o podanie informacji rozliczeniowych. Jeśli chcesz włączyć inne interfejsy Cloud API i poznać ich identyfikatory URI, znajdziesz je u dołu strony biblioteki każdego interfejsu API. Na przykład na dole strony Pub/Sub powyżej widać pubsub.googleapis.com jako „Nazwę usługi”.
Po wykonaniu tych czynności projekt będzie miał dostęp do interfejsów API. Teraz możesz zaktualizować aplikację, aby korzystała z tych interfejsów API.
4. Tworzenie zasobów Pub/Sub
Podsumowanie kolejności przepływu pracy kolejki zadań z modułu 18:
- W module 18 użyto pliku
queue.yamldo utworzenia kolejki typu pull o nazwiepullq. - Aplikacja dodaje zadania do kolejki pull, aby śledzić odwiedzających.
- Zadania są ostatecznie przetwarzane przez instancję roboczą, która jest dzierżawiona na określony czas (godzinę).
- Zadania są wykonywane w celu zliczenia ostatnich wizyt.
- Zadania są usuwane z kolejki po zakończeniu.
Podobny przepływ pracy odtworzysz za pomocą Pub/Sub. W następnej sekcji znajdziesz podstawowe terminy związane z Pub/Sub oraz 3 sposoby tworzenia niezbędnych zasobów Pub/Sub.
Terminologia kolejek zadań App Engine (pull) a Cloud Pub/Sub
Przejście na Pub/Sub wymaga niewielkiej zmiany słownictwa. Poniżej znajdziesz główne kategorie wraz z odpowiednimi terminami z obu usług. Zapoznaj się też z przewodnikiem po migracji, w którym znajdziesz podobne porównania.
- Struktura danych kolejki: w przypadku kolejki zadań dane trafiają do kolejek pull, a w przypadku Pub/Sub – do tematów.
- Jednostki danych w kolejce: zadania pull w kolejce zadań są nazywane wiadomościami w Pub/Sub.
- Procesory danych: w przypadku kolejki zadań procesy robocze uzyskują dostęp do zadań pull, a w przypadku Pub/Sub do odbierania wiadomości potrzebne są subskrypcje/subskrybenci.
- Wyodrębnianie danych: Dzierżawa zadania typu pull jest taka sama jak pobranie wiadomości z tematu (za pomocą subskrypcji).
- Czyszczenie/ukończenie: usuwanie zadania z kolejki zadań typu pull po jego wykonaniu jest analogiczne do potwierdzania wiadomości Pub/Sub.
Chociaż produkt do kolejkowania ulega zmianie, przepływ pracy pozostaje stosunkowo podobny:
- Zamiast kolejki pull aplikacja używa tematu o nazwie
pullq. - Zamiast dodawać zadania do kolejki typu pull, aplikacja wysyła wiadomości do tematu (
pullq). - Zamiast pracownika dzierżawiącego zadania z kolejki pull, subskrybent o nazwie
workerpobiera wiadomości z tematupullq. - Aplikacja przetwarza ładunki wiadomości, zwiększając liczbę odwiedzających w Datastore.
- Zamiast usuwać zadania z kolejki pull, aplikacja potwierdza przetworzone wiadomości.
W przypadku kolejki zadań konfiguracja obejmuje utworzenie kolejki pull. W przypadku Pub/Sub konfiguracja wymaga utworzenia zarówno tematu, jak i subskrypcji. W module 18 przetworzyliśmy queue.yaml poza wykonaniem aplikacji. Teraz to samo musimy zrobić w przypadku Pub/Sub.
Tematy i subskrypcje możesz utworzyć na 3 sposoby:
- W konsoli Cloud
- z wiersza poleceń lub
- Z kodu (krótki skrypt w Pythonie)
Wybierz jedną z opcji poniżej i postępuj zgodnie z odpowiednimi instrukcjami, aby utworzyć zasoby Pub/Sub.
W konsoli Cloud
Aby utworzyć temat w konsoli Google Cloud, wykonaj te czynności:
- Otwórz stronę Tematy Pub/Sub w konsoli Cloud.
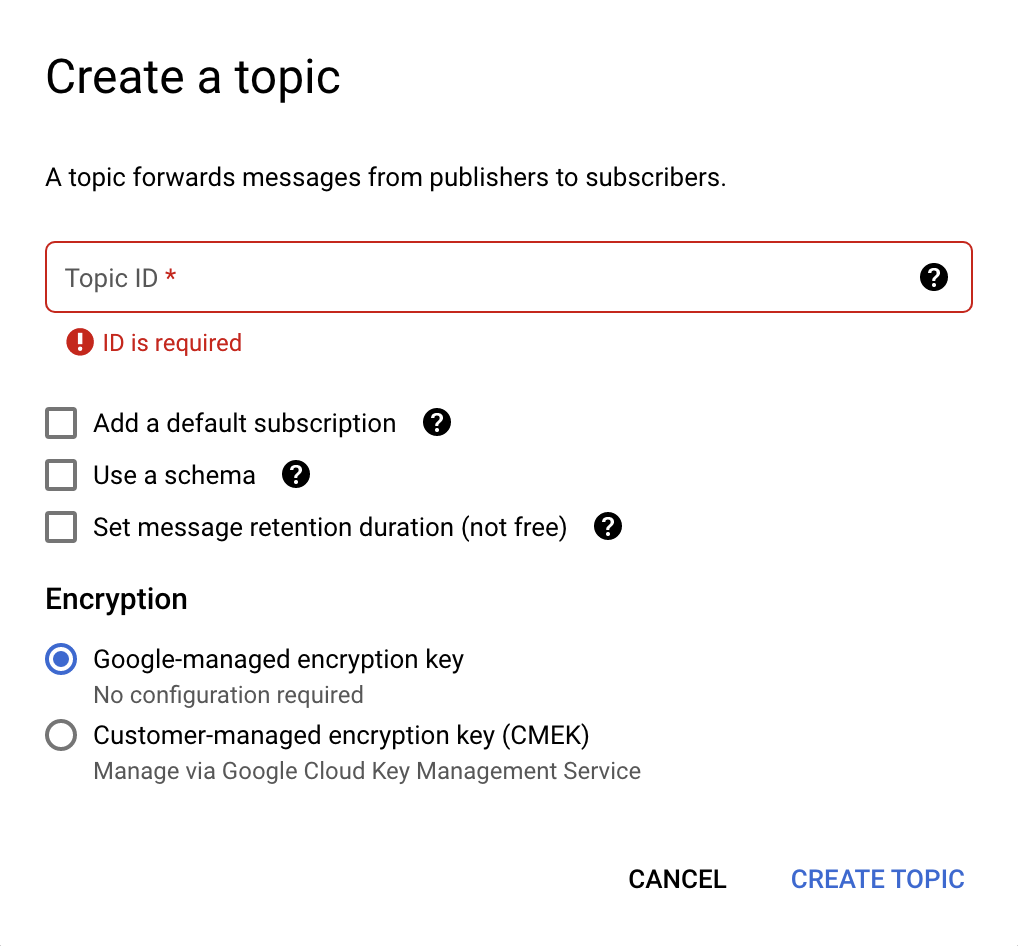
- U góry kliknij Utwórz temat. Otworzy się nowe okno dialogowe (patrz obraz poniżej).
- W polu Identyfikator tematu wpisz
pullq. - Odznacz wszystkie zaznaczone opcje i wybierz Klucz szyfrowania zarządzany przez Google.
- Kliknij przycisk Utwórz temat.
Okno tworzenia tematu wygląda tak:
Teraz, gdy masz już temat, musisz utworzyć subskrypcję tego tematu:
- Otwórz stronę Subskrypcje Pub/Sub w konsoli Cloud.
- U góry kliknij Utwórz subskrypcję (patrz obraz poniżej).
- W polu Identyfikator subskrypcji wpisz
worker. - Wybierz
pullqz menu Wybierz temat Cloud Pub/Sub, zwracając uwagę na jego „pełną i jednoznaczną ścieżkę”, np.projects/PROJECT_ID/topics/pullq. - Jako Sposób dostarczania wybierz Pull.
- Pozostaw inne opcje bez zmian i kliknij przycisk Utwórz.
Tak wygląda ekran tworzenia subskrypcji:
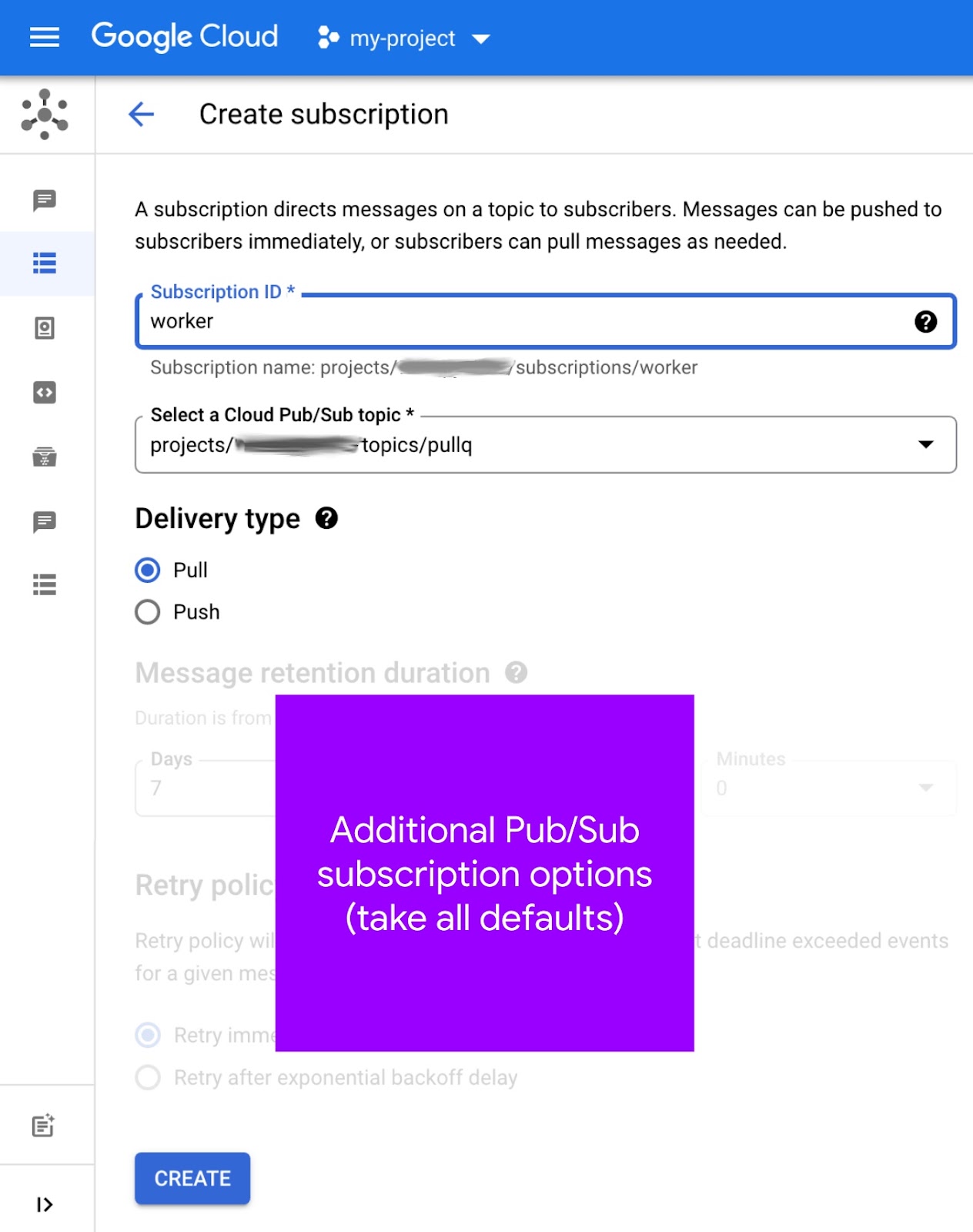
Subskrypcję możesz też utworzyć na stronie Tematy. Ten „skrót” może Ci pomóc w powiązaniu tematów z subskrypcjami. Więcej informacji o tworzeniu subskrypcji znajdziesz w dokumentacji.
W wierszu poleceń
Użytkownicy Pub/Sub mogą tworzyć tematy i subskrypcje za pomocą poleceń gcloud pubsub topics create TOPIC_ID i gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic=TOPIC_ID. Wykonanie tych działań z wartością TOPIC_ID równą pullq i wartością SUBSCRIPTION_ID równą worker spowoduje wygenerowanie następujących danych wyjściowych dla projektu PROJECT_ID:
$ gcloud pubsub topics create pullq Created topic [projects/PROJECT_ID/topics/pullq]. $ gcloud pubsub subscriptions create worker --topic=pullq Created subscription [projects/PROJECT_ID/subscriptions/worker].
Zapoznaj się też z tą stroną w dokumentacji krótkiego wprowadzenia. Korzystanie z wiersza poleceń może uprościć procesy, w których tematy i subskrypcje są tworzone regularnie. W tym celu można używać takich poleceń w skryptach powłoki.
Z kodu (krótki skrypt w Pythonie)
Innym sposobem na zautomatyzowanie tworzenia tematów i subskrypcji jest użycie interfejsu Pub/Sub API w kodzie źródłowym. Poniżej znajduje się kod maker.pyskryptu w folderze repozytorium Moduł 19.
from __future__ import print_function
import google.auth
from google.api_core import exceptions
from google.cloud import pubsub
_, PROJECT_ID = google.auth.default()
TOPIC = 'pullq'
SBSCR = 'worker'
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
def make_top():
try:
top = ppc_client.create_topic(name=TOP_PATH)
print('Created topic %r (%s)' % (TOPIC, top.name))
except exceptions.AlreadyExists:
print('Topic %r already exists at %r' % (TOPIC, TOP_PATH))
def make_sub():
try:
sub = psc_client.create_subscription(name=SUB_PATH, topic=TOP_PATH)
print('Subscription created %r (%s)' % (SBSCR, sub.name))
except exceptions.AlreadyExists:
print('Subscription %r already exists at %r' % (SBSCR, SUB_PATH))
try:
psc_client.close()
except AttributeError: # special Py2 handler for grpcio<1.12.0
pass
make_top()
make_sub()
Wykonanie tego skryptu daje oczekiwane dane wyjściowe (pod warunkiem, że nie ma błędów):
$ python3 maker.py Created topic 'pullq' (projects/PROJECT_ID/topics/pullq) Subscription created 'worker' (projects/PROJECT_ID/subscriptions/worker)
Wywołanie interfejsu API w celu utworzenia zasobów, które już istnieją, powoduje zgłoszenie przez bibliotekę klienta wyjątku google.api_core.exceptions.AlreadyExists, który jest obsługiwany przez skrypt w odpowiedni sposób:
$ python3 maker.py Topic 'pullq' already exists at 'projects/PROJECT_ID/topics/pullq' Subscription 'worker' already exists at 'projects/PROJECT_ID/subscriptions/worker'
Jeśli dopiero zaczynasz korzystać z Pub/Sub, więcej informacji znajdziesz w raporcie o architekturze Pub/Sub.
5. Aktualizacja konfiguracji
Aktualizacje konfiguracji obejmują zarówno zmianę różnych plików konfiguracyjnych, jak i utworzenie odpowiednika kolejek pobierania App Engine, ale w ekosystemie Cloud Pub/Sub.
Usuń plik queue.yaml
Całkowicie wycofujemy kolejki zadań, więc usuń plik queue.yaml, ponieważ Pub/Sub go nie używa. Zamiast tworzyć kolejkę pull, utworzysz temat Pub/Sub (i subskrypcję).
requirements.txt
Dołącz do flask z modułu 18, dodając do requirements.txt zarówno google-cloud-ndb, jak i google-cloud-pubsub. Zaktualizowany moduł 19 requirements.txt powinien wyglądać tak:
flask
google-cloud-ndb
google-cloud-pubsub
Ten plik requirements.txt nie zawiera numerów wersji, co oznacza, że wybrane są najnowsze wersje. Jeśli wystąpią jakiekolwiek niezgodności, postępuj zgodnie ze standardową procedurą używania numerów wersji, aby zablokować działające wersje aplikacji.
app.yaml
Zmiany w app.yaml różnią się w zależności od tego, czy pozostajesz przy Pythonie 2, czy przechodzisz na Pythona 3.
Python 2
Powyższa aktualizacja requirements.txt dodaje korzystanie z bibliotek klienta Google Cloud. Wymagają one dodatkowej obsługi ze strony App Engine, a mianowicie kilku wbudowanych bibliotek, setuptools i grpcio. Korzystanie z wbudowanych bibliotek wymaga sekcji libraries w pliku app.yaml oraz numerów wersji bibliotek lub słowa „latest” (najnowsza) w przypadku najnowszej wersji dostępnej na serwerach App Engine. Moduł 18 app.yaml nie ma jeszcze jednej z tych sekcji:
PRZED:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
Dodaj sekcję libraries do app.yaml wraz z wpisami dla setuptools i grpcio, wybierając ich najnowsze wersje. Dodaj też wpis zastępczy runtime dla Pythona 3, zakomentowany wraz z aktualną wersją 3.x, np. 3.10 (w momencie pisania tego artykułu). Po wprowadzeniu tych zmian app.yaml wygląda tak:
PO:
#runtime: python310
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
libraries:
- name: setuptools
version: latest
- name: grpcio
version: latest
Python 3
W przypadku użytkowników Pythona 3 i app.yaml chodzi o usuwanie elementów. W tej sekcji usuniesz sekcję handlers oraz dyrektywy threadsafe i api_version. Nie utworzysz też sekcji libraries.
Środowiska wykonawcze 2 generacji nie udostępniają wbudowanych bibliotek innych firm, więc w sekcji app.yaml nie jest potrzebna sekcja libraries. Ponadto kopiowanie (czasami nazywane udostępnianiem lub samodzielnym łączeniem w pakiety) niewbudowanych pakietów innych firm nie jest już wymagane. W requirements.txt musisz podać tylko biblioteki innych firm, których używa Twoja aplikacja.
Sekcja handlers w app.yaml służy do określania modułów obsługi aplikacji (skryptów) i plików statycznych. Środowisko wykonawcze Pythona 3 wymaga, aby platformy internetowe wykonywały własne routingi, więc wszystkie moduły obsługi skryptów muszą zostać zmienione na auto. Jeśli Twoja aplikacja (np. z modułu 18) nie obsługuje plików statycznych, wszystkie ścieżki będą miały wartość auto, co sprawi, że będą nieistotne. W związku z tym sekcja handlers też nie jest potrzebna, więc ją usuń.
Na koniec w Pythonie 3 nie używa się dyrektyw threadsafe ani api_version, więc je też usuń. Najważniejsze jest to, aby usunąć wszystkie sekcje app.yaml, tak aby pozostała tylko dyrektywa runtime określająca nowoczesną wersję Pythona 3, np. 3.10. Tak wygląda app.yaml przed i po tych zmianach:
PRZED:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
PO:
runtime: python310
Dla osób, które nie są gotowe na usunięcie wszystkiego z app.yaml dla Pythona 3, udostępniliśmy app3.yaml alternatywny plik w folderze repozytorium modułu 19. Jeśli chcesz użyć tego pliku do wdrożeń, dodaj jego nazwę na końcu polecenia: gcloud app deploy app3.yaml (w przeciwnym razie domyślnie zostanie użyty plik app.yaml w języku Python 2, który pozostawisz bez zmian).
appengine_config.py
Jeśli przechodzisz na Pythona 3, nie potrzebujesz już appengine_config.py, więc usuń ten plik. Nie jest to konieczne, ponieważ obsługa bibliotek innych firm wymaga tylko określenia ich w requirements.txt. Użytkownicy języka Python 2, czytajcie dalej.
Moduł 18 appengine_config.py zawiera odpowiedni kod do obsługi bibliotek innych firm, np. Flask i bibliotek klienta Cloud, które właśnie zostały dodane do requirements.txt:
PRZED:
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
Ten kod nie wystarczy jednak do obsługi nowo dodanych bibliotek wbudowanych (setuptools, grpcio). Potrzeba jeszcze kilku wierszy, więc zaktualizuj appengine_config.py, aby wyglądał tak:
PO:
import pkg_resources
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
# Add libraries to pkg_resources working set to find the distribution.
pkg_resources.working_set.add_entry(PATH)
Więcej informacji o zmianach wymaganych do obsługi bibliotek klienta Cloud znajdziesz w dokumentacji dotyczącej migracji usług pakietowych.
Inne aktualizacje konfiguracji
Jeśli masz folder lib, usuń go. Jeśli używasz Pythona 2, uzupełnij folder lib, wydając to polecenie:
pip install -t lib -r requirements.txt # or pip2
Jeśli na komputerze deweloperskim masz zainstalowane zarówno Pythona 2, jak i 3, zamiast pip może być konieczne użycie pip2.
6. Modyfikowanie kodu aplikacji
Ta sekcja zawiera aktualizacje głównego pliku aplikacji, main.py, które zastępują kolejki pull w App Engine Task Queue usługą Cloud Pub/Sub. W szablonie internetowym nie ma żadnych zmian templates/index.html. Obie aplikacje powinny działać identycznie i wyświetlać te same dane.
Aktualizowanie importów i inicjowanie
Wprowadziliśmy kilka zmian w importach i inicjowaniu:
- W przypadku importów zastąp App Engine NDB i Task Queue usługami Cloud NDB i Pub/Sub.
- Zmień nazwę
pullqzQUEUEnaTOPIC. - W przypadku zadań typu pull instancja robocza wypożyczała je na godzinę, ale w przypadku Pub/Sub limity czasu są mierzone dla każdej wiadomości, więc usuń stałą
HOUR. - Interfejsy Cloud API wymagają użycia klienta API, więc zainicjuj je dla Cloud NDB i Cloud Pub/Sub. Ten ostatni udostępnia klientów zarówno dla tematów, jak i subskrypcji.
- Pub/Sub wymaga identyfikatora projektu w chmurze, więc zaimportuj go i pobierz z
google.auth.default(). - Pub/Sub wymaga „w pełni kwalifikowanych nazw ścieżek” w przypadku tematów i subskrypcji, więc utwórz je za pomocą funkcji pomocniczych
*_path().
Poniżej znajdziesz importy i inicjalizację z modułu 18, a także wygląd sekcji po wprowadzeniu powyższych zmian. Większość nowego kodu to różne zasoby Pub/Sub:
PRZED:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
PO:
from flask import Flask, render_template, request
import google.auth
from google.cloud import ndb, pubsub
LIMIT = 10
TASKS = 1000
TOPIC = 'pullq'
SBSCR = 'worker'
app = Flask(__name__)
ds_client = ndb.Client()
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
_, PROJECT_ID = google.auth.default()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
Aktualizacje modelu danych
Model danych Visit nie ulegnie zmianie. Dostęp do Datastore wymaga jawnego użycia menedżera kontekstu klienta Cloud NDB API, ds_client.context(). W kodzie oznacza to, że wywołania Datastore należy umieścić w blokach store_visit() i fetch_visits() w blokach with w Pythonie. Ta aktualizacja jest identyczna z tą, którą omówiliśmy w module 2.
Najważniejsza zmiana w przypadku Pub/Sub polega na zastąpieniu kolejkowania zadania pull w kolejce zadań publikowaniem wiadomości Pub/Sub w temacie pullq. Poniżej znajdziesz kod przed wprowadzeniem tych zmian i po nich:
PRZED:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
PO:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
with ds_client.context():
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
ppc_client.publish(TOP_PATH, remote_addr.encode('utf-8'))
def fetch_visits(limit):
'get most recent visits'
with ds_client.context():
return Visit.query().order(-Visit.timestamp).fetch(limit)
Aktualizacje modelu danych VisitorCount
Model danych VisitorCount nie ulega zmianie i fetch_counts(), z wyjątkiem umieszczenia zapytania Datastore w bloku with, jak pokazano poniżej:
PRZED:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
PO:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
with ds_client.context():
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
Aktualizowanie kodu pracownika
Kod procesu roboczego jest aktualizowany w zakresie zastąpienia NDB przez Cloud NDB i kolejki zadań przez Pub/Sub, ale jego przepływ pracy pozostaje taki sam.
- Umieść wywołania Datastore w bloku menedżera kontekstu Cloud NDB
with. - Czyszczenie kolejki zadań polega na usunięciu wszystkich zadań z kolejki pull. W Pub/Sub „identyfikatory potwierdzeń” są zbierane w
acks, a następnie usuwane lub potwierdzane na końcu. - Zadania pull w kolejce zadań są wypożyczane w podobny sposób jak wiadomości Pub/Sub. Zadania typu pull są usuwane za pomocą samych obiektów zadań, a wiadomości Pub/Sub – za pomocą identyfikatorów potwierdzenia.
- Ładunki wiadomości Pub/Sub wymagają bajtów (nie ciągów znaków w języku Python), więc podczas publikowania wiadomości w temacie i pobierania ich z niego następuje odpowiednio kodowanie i dekodowanie w UTF-8.
Zastąp zmienną log_visitors() zaktualizowanym kodem poniżej, który wprowadza opisane wyżej zmiany:
PRZED:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
PO:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
acks = set()
rsp = psc_client.pull(subscription=SUB_PATH, max_messages=TASKS)
msgs = rsp.received_messages
for rcvd_msg in msgs:
acks.add(rcvd_msg.ack_id)
visitor = rcvd_msg.message.data.decode('utf-8')
tallies[visitor] = tallies.get(visitor, 0) + 1
if acks:
psc_client.acknowledge(subscription=SUB_PATH, ack_ids=acks)
try:
psc_client.close()
except AttributeError: # special handler for grpcio<1.12.0
pass
# increment those counts in Datastore and return
if tallies:
with ds_client.context():
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(msgs), len(tallies))
Główny moduł obsługi aplikacji root() pozostaje bez zmian. Nie musisz też wprowadzać żadnych zmian w pliku szablonu HTML templates/index.html. W ten sposób zakończysz wszystkie niezbędne aktualizacje. Gratulujemy dotarcia do nowej aplikacji modułu 19 korzystającej z Cloud Pub/Sub.
7. Podsumowanie i czyszczenie
Wdróż aplikację, aby sprawdzić, czy działa zgodnie z przeznaczeniem i czy wszystkie dane wyjściowe są prawidłowe. Uruchom też proces roboczy, aby przetworzyć liczbę odwiedzających. Po zweryfikowaniu aplikacji wykonaj czynności związane z czyszczeniem i zastanów się, co dalej zrobić.
Wdrażanie i weryfikowanie aplikacji
Sprawdź, czy masz już utworzony temat pullq i subskrypcję worker. Jeśli to zrobisz i przykładowa aplikacja będzie gotowa, wdróż ją za pomocą polecenia gcloud app deploy. Dane wyjściowe powinny być identyczne z aplikacją z modułu 18, z tym wyjątkiem, że cały mechanizm kolejkowania został zastąpiony:
Interfejs internetowy aplikacji weryfikuje teraz, czy ta część aplikacji działa. Ta część aplikacji prawidłowo wysyła zapytania o najważniejszych użytkowników i najnowsze wizyty oraz wyświetla te informacje. Pamiętaj, że aplikacja rejestruje tę wizytę i tworzy zadanie pobierania, aby dodać tego użytkownika do ogólnej liczby. To zadanie jest teraz w kolejce i czeka na przetworzenie.
Możesz to zrobić za pomocą usługi backendu App Engine, zadania cron, przeglądając /log lub wysyłając żądanie HTTP w wierszu poleceń. Oto przykładowe wykonanie i dane wyjściowe wywołania kodu roboczego za pomocą curl (zastąp PROJECT_ID):
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
Zaktualizowana liczba zostanie uwzględniona podczas następnej wizyty w witrynie. To wszystko.
Czyszczenie danych
Ogólne
Jeśli na razie nie chcesz już korzystać z usługi, zalecamy wyłączenie aplikacji App Engine, aby uniknąć naliczania opłat. Jeśli jednak chcesz przeprowadzić więcej testów lub eksperymentów, platforma App Engine ma bezpłatny limit, więc dopóki nie przekroczysz tego poziomu wykorzystania, nie powinny być naliczane żadne opłaty. Dotyczy to obliczeń, ale mogą też wystąpić opłaty za odpowiednie usługi App Engine, więc więcej informacji znajdziesz na stronie z cennikiem. Jeśli migracja obejmuje inne usługi w chmurze, są one rozliczane oddzielnie. W każdym przypadku, jeśli to konieczne, zapoznaj się z sekcją „Specyficzne dla tego laboratorium” poniżej.
Wdrożenie na bezserwerowej platformie obliczeniowej Google Cloud, takiej jak App Engine, wiąże się z niewielkimi kosztami kompilacji i przechowywania. Cloud Build ma własny bezpłatny limit, podobnie jak Cloud Storage. Przechowywanie tego obrazu wykorzystuje część tego limitu. Możesz jednak mieszkać w regionie, w którym nie ma takiego bezpłatnego pakietu, więc kontroluj wykorzystanie miejsca na dane, aby zminimalizować potencjalne koszty. Sprawdź te „foldery” Cloud Storage:
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- Linki do pamięci masowej powyżej zależą od
PROJECT_IDi *LOC*acji, np. „us”, jeśli Twoja aplikacja jest hostowana w Stanach Zjednoczonych.
Jeśli nie zamierzasz kontynuować pracy z tą aplikacją ani innymi powiązanymi z nią samouczkami dotyczącymi migracji i chcesz wszystko całkowicie usunąć, wyłącz projekt.
Dotyczy tych ćwiczeń z programowania
Usługi wymienione poniżej są dostępne tylko w tym laboratorium. Więcej informacji znajdziesz w dokumentacji poszczególnych usług:
- Poszczególne komponenty Cloud Pub/Sub mają bezpłatny poziom. Określ ogólne wykorzystanie, aby lepiej poznać konsekwencje kosztowe. Więcej informacji znajdziesz na stronie z cenami.
- Usługa App Engine Datastore jest udostępniana przez Cloud Datastore (Cloud Firestore w trybie Datastore), która również ma bezpłatny poziom. Więcej informacji znajdziesz na stronie z cennikiem.
Dalsze kroki
Oprócz tego samouczka możesz też zapoznać się z innymi modułami migracji, które skupiają się na przejściu z starszych usług w pakiecie:
- Moduł 2. Migracja z App Engine
ndbdo Cloud NDB - Moduły 7–9: migracja z kolejki zadań App Engine (zadania push) do Cloud Tasks
- Moduły 12–13: migracja z Memcache App Engine do Cloud Memorystore
- Moduły 15–16: migracja z App Engine Blobstore do Cloud Storage
App Engine nie jest już jedyną platformą bezserwerową w Google Cloud. Jeśli masz małą aplikację App Engine lub aplikację o ograniczonej funkcjonalności i chcesz przekształcić ją w samodzielny mikroserwis albo podzielić aplikację monolityczną na wiele komponentów wielokrotnego użytku, warto rozważyć przejście na Cloud Functions. Jeśli konteneryzacja stała się częścią procesu tworzenia aplikacji, zwłaszcza jeśli obejmuje potok CI/CD (tryb ciągłej integracji/tryb ciągłego dostarczania lub wdrażanie), rozważ migrację do Cloud Run. Te scenariusze są omówione w tych modułach:
- Migracja z App Engine do Cloud Functions: patrz moduł 11
- Migracja z App Engine do Cloud Run: w module 4 dowiesz się, jak skonteneryzować aplikację za pomocą Dockera, a w module 5 – jak to zrobić bez kontenerów, wiedzy o Dockerze ani
Dockerfiles
Przejście na inną platformę bezserwerową jest opcjonalne. Zanim wprowadzisz jakiekolwiek zmiany, zalecamy rozważenie najlepszych opcji dla Twoich aplikacji i przypadków użycia.
Niezależnie od tego, który moduł migracji wybierzesz, wszystkie materiały dotyczące Serverless Migration Station (ćwiczenia z programowania, filmy, kod źródłowy [jeśli jest dostępny]) znajdziesz w repozytorium open source. W repozytorium README znajdziesz też wskazówki dotyczące migracji, które warto rozważyć, oraz odpowiednią „kolejność” modułów migracji.
8. Dodatkowe materiały
Poniżej znajdziesz dodatkowe materiały dla programistów, którzy chcą dowiedzieć się więcej o tym lub powiązanym module migracji, a także o powiązanych produktach. Znajdziesz tu m.in. miejsca, w których możesz przesłać opinię o tych treściach, linki do kodu i różne dokumenty, które mogą Ci się przydać.
Problemy z Codelabs lub opinie na ich temat
Jeśli zauważysz jakieś problemy z tym kursem, najpierw poszukaj rozwiązania, a dopiero potem zgłoś problem. Linki do wyszukiwania i tworzenia nowych problemów:
Materiały dotyczące migracji
Linki do folderów repozytorium dla modułu 18 (START) i modułu 19 (FINISH) znajdziesz w tabeli poniżej.
Ćwiczenia z programowania | Python 2 | Python 3 |
(n/a) | ||
Moduł 19 (te ćwiczenia z programowania) | (tak samo jak w przypadku Pythona 2, z tym że zamiast app.yaml użyj app3.yaml, chyba że plik app.yaml został zaktualizowany zgodnie z powyższymi instrukcjami) |
Odsyłacze online
Poniżej znajdziesz zasoby przydatne w tym samouczku:
Kolejka zadań App Engine
- Omówienie kolejki zadań App Engine
- Omówienie kolejek pull w kolejce zadań App Engine
- Pełna przykładowa aplikacja kolejki pull w App Engine Task Queue
- Tworzenie kolejek pull w Task Queue
- Film z wprowadzenia kolejki pull na Google I/O 2011 ( przykładowa aplikacja Votelator)
queue.yamlźródło informacjiqueue.yamla Cloud Tasks- Przewodnik po migracji kolejek pull do Pub/Sub
Cloud Pub/Sub
- Strona produktu Cloud Pub/Sub
- Korzystanie z bibliotek klienta Pub/Sub
- Przykłady biblioteki klienta Pub/Sub w języku Python
- Dokumentacja biblioteki klienta Pub/Sub w Pythonie
- Tworzenie tematów Pub/Sub i zarządzanie nimi
- Wytyczne dotyczące nazewnictwa tematów Pub/Sub
- Tworzenie subskrypcji Pub/Sub i zarządzanie nimi
- Przykładowa aplikacja App Engine (elastyczna) (można ją też wdrożyć w środowisku standardowym; Python 3)
- Repozytorium przykładowej aplikacji powyżej
- Subskrypcje pull Pub/Sub
- Subskrypcje push Pub/Sub
- Przykładowa aplikacja App Engine Pub/Sub push (Python 3)
- Repozytorium przykładowej aplikacji App Engine Pub/Sub push
- Informacje o cenach Pub/Sub
- Cloud Tasks czy Cloud Pub/Sub? (push vs. pull)
App Engine NDB i Cloud NDB (Datastore)
- Dokumentacja App Engine NDB
- Repozytorium App Engine NDB
- Dokumentacja Google Cloud NDB
- repozytorium Google Cloud NDB,
- Informacje o cenach Cloud Datastore
Platforma App Engine
- Dokumentacja App Engine
- Środowisko wykonawcze App Engine (środowisko standardowe) w Pythonie 2
- Korzystanie z wbudowanych bibliotek App Engine w App Engine w Pythonie 2
- Środowisko wykonawcze Pythona 3 w App Engine (środowisko standardowe)
- Różnice między środowiskami wykonawczymi App Engine (środowisko standardowe) w Pythonie 2 i 3
- Przewodnik po migracji z App Engine (środowisko standardowe) z Pythona 2 na Pythona 3
- Informacje o cenach i limitach App Engine
- Uruchomienie platformy App Engine drugiej generacji (2018)
- Porównanie platform pierwszej i drugiej generacji
- Wsparcie długoterminowe dla starszych środowisk wykonawczych
- Przykłady migracji dokumentacji
- Przykłady migracji stworzone przez społeczność
Inne informacje o chmurze
- Python w Google Cloud Platform
- Biblioteki klienta Google Cloud Python
- Poziom „Zawsze bezpłatny” w Google Cloud
- Google Cloud SDK (narzędzie wiersza poleceń
gcloud) - Cała dokumentacja Google Cloud
Filmy
- Serverless Migration Station
- Ekspedycje bezserwerowe
- Subskrybuj Google Cloud Tech
- Subskrybuj Google Developers
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.