
1. Обзор
Серия обучающих материалов Serverless Migration Station (самостоятельные практические уроки) и сопутствующих видеороликов призвана помочь разработчикам бессерверных приложений Google Cloud модернизировать свои приложения, проведя их через одну или несколько миграций, в первую очередь, через отказ от устаревших сервисов. Это делает ваши приложения более портативными, предоставляет больше возможностей и гибкости, позволяя интегрироваться с более широким спектром облачных продуктов и получать к ним доступ, а также упрощает обновление до более новых версий языков программирования. Хотя изначально серия ориентирована на самых первых пользователей облачных сервисов, в первую очередь разработчиков App Engine (стандартная среда), она достаточно широка, чтобы охватить и другие бессерверные платформы, такие как Cloud Functions и Cloud Run , или другие, если это применимо.
Цель этого практического занятия — показать разработчикам приложений на Python 2, как перейти от задач App Engine Task Queue с механизмом pull к Cloud Pub/Sub . Также будет рассмотрена неявная миграция с App Engine NDB на Cloud NDB для доступа к хранилищу данных (в основном это рассматривается в модуле 2), а также обновление до Python 3.
В модуле 18 вы узнаете, как добавить использование задач с механизмом «вытягивания» (pull tasks) в ваше приложение. В этом модуле вы возьмете готовое приложение из модуля 18 и перенесете его использование в Cloud Pub/Sub. Тем, кто использует очереди задач для задач с механизмом «вытягивания» , следует перейти на Cloud Tasks и обратиться к модулям 7-9.
Вы узнаете, как
- Замените использование очереди задач App Engine (запросы на получение) на Cloud Pub/Sub.
- Замените использование App Engine NDB на Cloud NDB (см. также Модуль 2).
- Перевести приложение на Python 3
Что вам понадобится
- Проект на платформе Google Cloud Platform с активным платежным аккаунтом GCP.
- Базовые навыки работы с Python.
- Практические навыки работы с распространенными командами Linux.
- Базовые знания разработки и развертывания приложений на платформе App Engine.
- Рабочий пример приложения, созданного с помощью App Engine (модуль 18).
Опрос
Как вы будете использовать этот учебный материал?
Как бы вы оценили свой опыт работы с Python?
Как бы вы оценили свой опыт использования сервисов Google Cloud?
2. Предыстория
App Engine Task Queue supports both push and pull tasks. To improve application portability, Google Cloud recommends migrating from legacy bundled services like Task Queue to other Cloud standalone or 3rd-party equivalent services.
- Пользователям, использующим функцию отправки задач в очередь, следует перейти на Cloud Tasks .
- Пользователям, использующим функцию извлечения задач из очереди, следует перейти на Cloud Pub/Sub .
Модули миграции 7-9 посвящены миграции задач с помощью механизма "push", а модули 18-19 — миграции задач с помощью механизма "pull". Хотя Cloud Tasks больше похож на задачи с механизмом "push" в Task Queue, Pub/Sub не является таким близким аналогом задач с механизмом "pull" в Task Queue.
Pub/Sub обладает большим количеством функций, чем функция pull, предоставляемая Task Queue. Например, Pub/Sub также имеет функцию push , однако Cloud Tasks больше похож на задачи push из Task Queue, поэтому функция push из Pub/Sub не рассматривается ни одним из модулей миграции. В этом практическом занятии по модулю 19 демонстрируется переключение механизма очереди с очередей pull Task Queue на Pub/Sub, а также миграция с App Engine NDB на Cloud NDB для доступа к хранилищу данных, повторяя миграцию из модуля 2 .
Хотя код Модуля 18 "рекламируется" как пример приложения на Python 2, сам исходный код совместим с Python 2 и 3, и это сохраняется даже после миграции на Cloud Pub/Sub (и Cloud NDB) в Модуле 19.
В этом руководстве описаны следующие шаги:
- Подготовка/Настройка
- Обновить конфигурацию
- Измените код приложения
3. Подготовка/Предварительные работы
В этом разделе объясняется, как:
- Настройте свой облачный проект
- Получите базовый образец приложения
- (Повторное) развертывание и проверка базового приложения.
- Включите новые сервисы/API Google Cloud.
Эти шаги гарантируют, что вы начинаете с работающего кода и что он готов к миграции в облачные сервисы.
1. Настройка проекта
Если вы выполнили практическое задание по модулю 18 , используйте тот же проект (и код). В качестве альтернативы создайте совершенно новый проект или используйте существующий. Убедитесь, что у проекта есть активный платежный аккаунт и включенное приложение App Engine. Найдите идентификатор своего проекта, так как он понадобится вам во время выполнения этого практического задания, используя его всякий раз, когда вы встретите переменную PROJECT_ID .
2. Получите базовый образец приложения.
Одно из необходимых условий — наличие работающего приложения App Engine модуля 18, поэтому либо пройдите его практическое занятие (рекомендуется; ссылка выше), либо скопируйте код модуля 18 из репозитория. Независимо от того, используете ли вы свой или наш код, мы начнем с этого («НАЧАЛО»). Это практическое занятие проведет вас через процесс миграции и завершится кодом, похожим на тот, что находится в папке репозитория модуля 19 («ЗАВЕРШЕНИЕ»).
- НАЧАЛО: Папка модуля 18 (Python 2)
- ЗАВЕРШЕНИЕ: Папка модуля 19 (Python 2 и 3)
- Весь репозиторий (для клонирования или загрузки ZIP-файла )
Независимо от того, какое приложение из Модуля 18 вы используете, папка должна выглядеть примерно так, как показано ниже, возможно, с дополнительной папкой lib :
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
3. (Повторное) развертывание и проверка базового приложения.
Для развертывания приложения «Модуль 18» выполните следующие действия:
- Удалите папку
lib, если она есть, и выполните командуpip install -t lib -r requirements.txt, чтобы заново заполнитьlib. Возможно, вам потребуется использоватьpip2если на вашей машине для разработки установлены Python 2 и 3. - Убедитесь, что вы установили и инициализировали инструмент командной строки
gcloudи ознакомились с его использованием . - (необязательно) Укажите свой облачный проект с помощью
gcloud config set projectPROJECT_IDесли вы не хотите вводитьPROJECT_IDпри каждой командеgcloud. - Разверните демонстрационное приложение с помощью
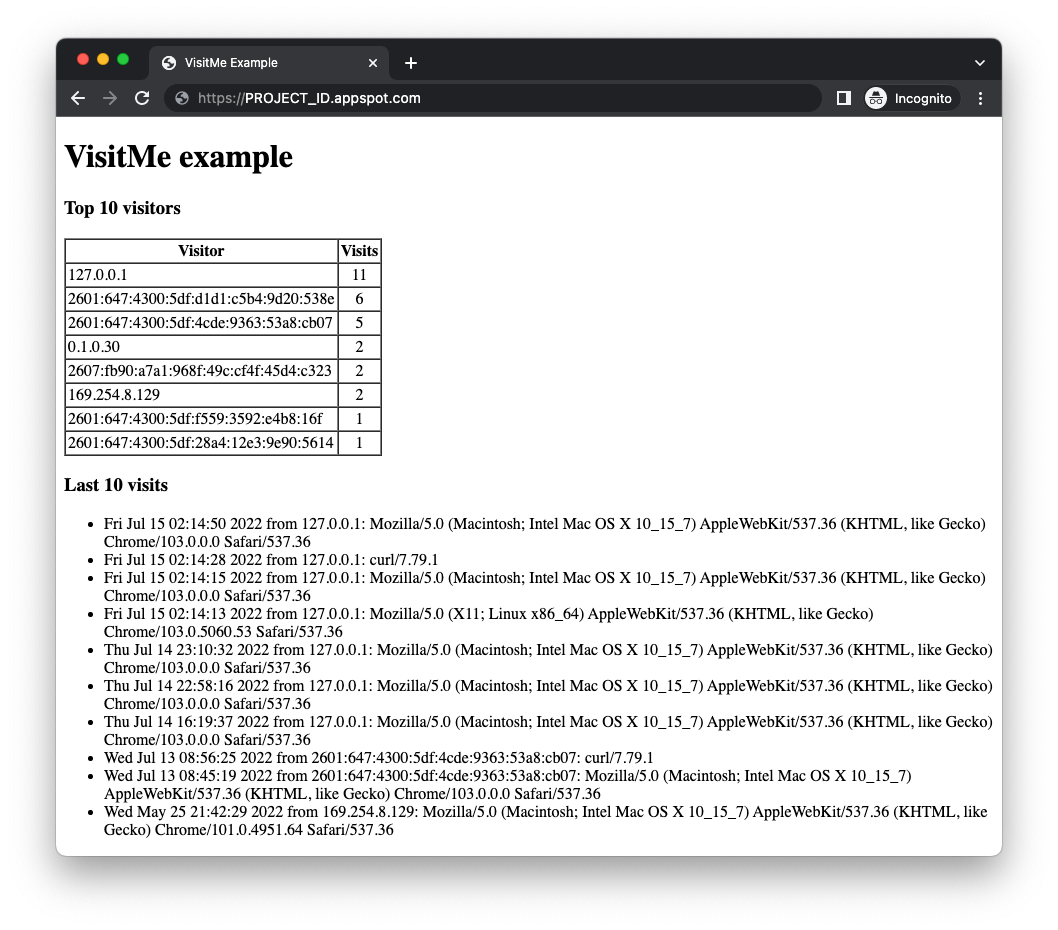
gcloud app deploy - Убедитесь, что приложение работает должным образом и без проблем. Если вы выполнили практическое задание модуля 18, приложение отображает самых активных посетителей, а также самые последние посещения (см. пример ниже). В противном случае, возможно, нет данных о количестве посетителей для отображения.
Перед переносом демонстрационного приложения Модуля 18 необходимо сначала включить облачные сервисы, которые будет использовать модифицированное приложение.
4. Включите новые сервисы/API Google Cloud.
В старой версии приложения использовались встроенные сервисы App Engine, не требующие дополнительной настройки, тогда как автономные облачные сервисы требуют её, а в обновлённой версии приложения будут использоваться как Cloud Pub/Sub, так и Cloud Datastore (через клиентскую библиотеку Cloud NDB). App Engine и оба облачных API имеют лимиты на использование сервисов по тарифу «Всегда бесплатно» , и пока вы не превышаете эти лимиты, вам не придётся платить за выполнение этого руководства. В зависимости от ваших предпочтений, облачные API можно включить либо из консоли Cloud, либо из командной строки.
Из облачной консоли
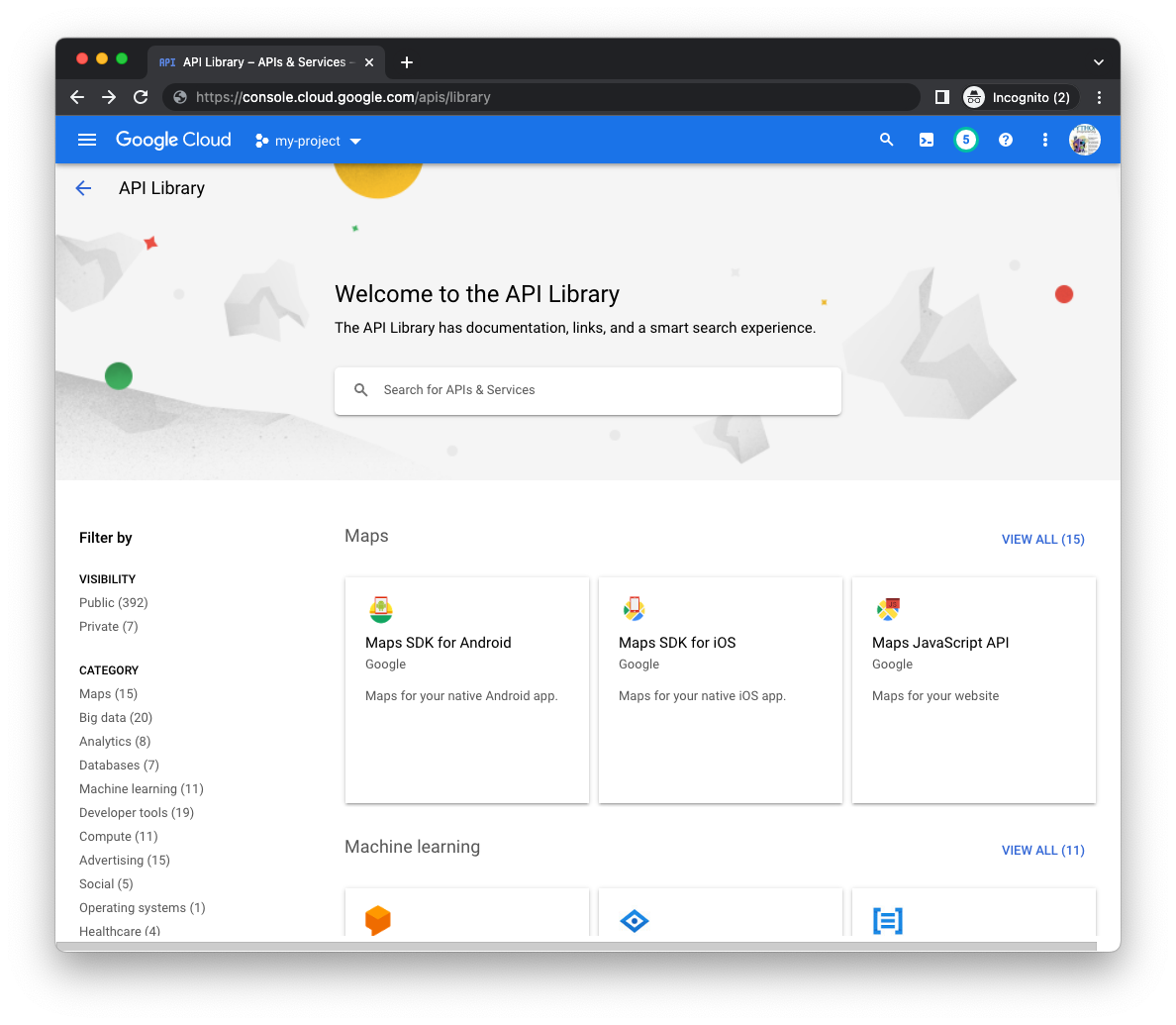
Перейдите на страницу библиотеки API Manager (для соответствующего проекта) в консоли Cloud и найдите API Cloud Datastore и Cloud Pub/Sub, используя строку поиска в центре страницы:
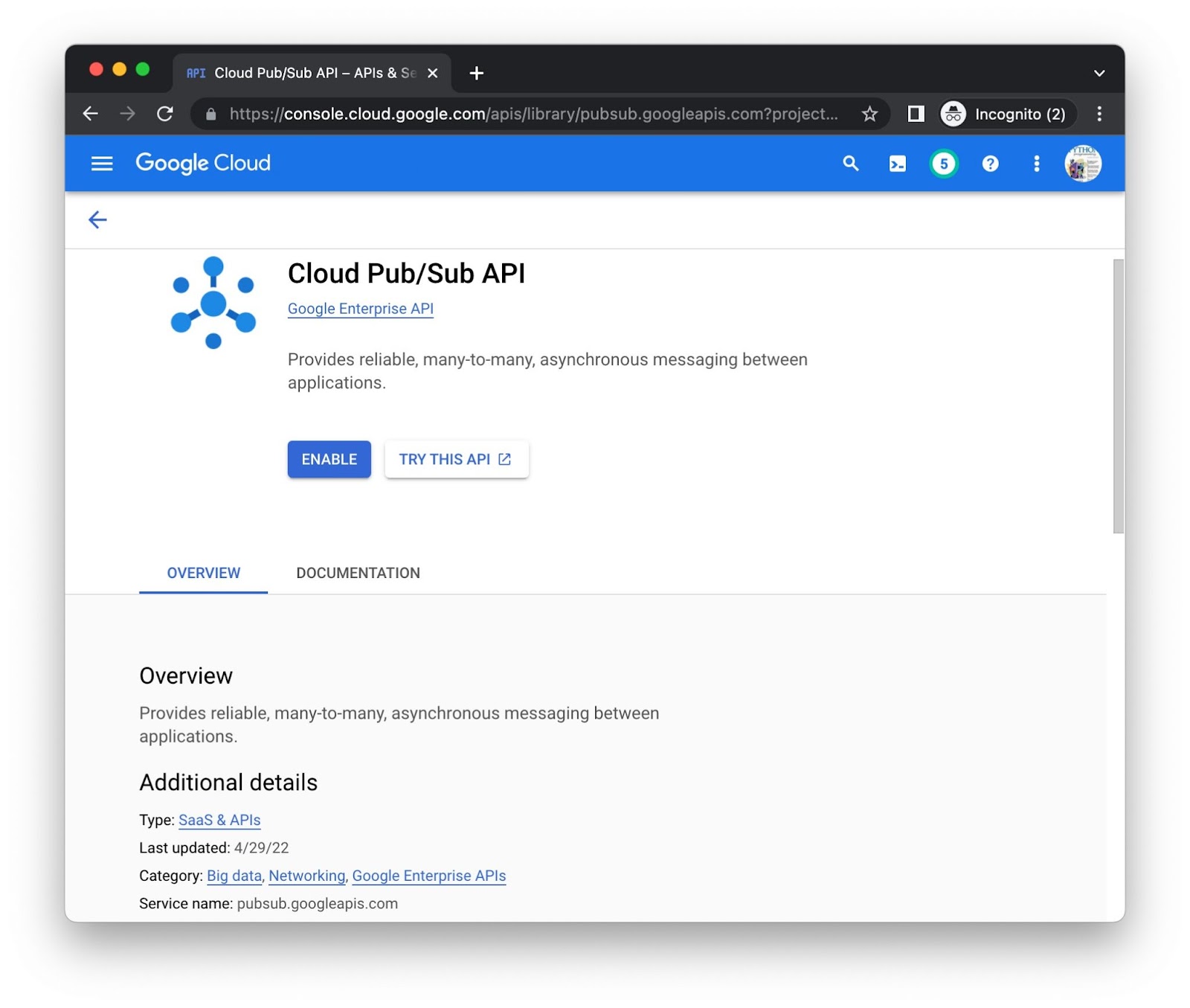
Нажмите кнопку «Включить» для каждого API отдельно — возможно, вам потребуется ввести платежную информацию. Например, это страница библиотеки API Cloud Pub/Sub:
Из командной строки
Хотя включение API из консоли визуально информативно, некоторые предпочитают командную строку. Для одновременного включения обоих API выполните команду ` gcloud services enable pubsub.googleapis.com datastore.googleapis.com :
$ gcloud services enable pubsub.googleapis.com datastore.googleapis.com Operation "operations/acat.p2-aaa-bbb-ccc-ddd-eee-ffffff" finished successfully.
Возможно, вам потребуется ввести платежную информацию. Если вы хотите включить другие облачные API и узнать их URI, их можно найти внизу страницы библиотеки каждого API. Например, обратите внимание на pubsub.googleapis.com в качестве «имени сервиса» внизу страницы Pub/Sub, расположенной чуть выше.
После выполнения этих шагов ваш проект сможет получить доступ к API. Теперь пришло время обновить приложение, чтобы оно использовало эти API.
4. Создайте ресурсы Pub/Sub.
Подведем итоги последовательности действий в очереди задач из модуля 18:
- В модуле 18 использовался файл
queue.yamlдля создания очереди запросов с именемpullq. - Приложение добавляет задачи в очередь запросов для отслеживания посетителей.
- В конечном итоге задачи обрабатываются работником, арендованным на ограниченный период времени (один час).
- Выполняются задачи по подсчету количества посетителей за последнее время.
- Задачи удаляются из очереди по завершении.
Вам предстоит воспроизвести аналогичный рабочий процесс с использованием Pub/Sub. В следующем разделе будет представлена основная терминология Pub/Sub, а также три различных способа создания необходимых ресурсов Pub/Sub.
Терминология App Engine Task Queue (pull) против Cloud Pub/Sub
Переход на систему публикации/подписки потребует небольшой корректировки вашего словарного запаса. Ниже перечислены основные категории, а также соответствующие термины из обоих продуктов. Также ознакомьтесь с руководством по миграции , в котором представлены аналогичные сравнения.
- Структура данных для очередей: при использовании очереди задач данные поступают в очереди с запросом данных (pull queues ); при использовании модели публикации/подписки (Pub/Sub) данные поступают в темы (topics) .
- Единицы данных в очереди: задачи, выполняемые с помощью очереди задач (Task Queue), называются сообщениями при использовании модели публикации/подписки (Pub/Sub).
- Data processors: With Task Queue, workers access pull tasks; with Pub/Sub, you need subscriptions/subscribers to receive messages
- Извлечение данных: Аренда задачи получения данных аналогична извлечению сообщения из темы (посредством подписки).
- Очистка/завершение: Удаление задачи из очереди задач после завершения аналогично подтверждению сообщения в системе публикации/подписки.
Несмотря на изменение типа обрабатываемого продукта, рабочий процесс остается относительно похожим:
- Вместо очереди запросов приложение использует тему с именем
pullq. - Вместо добавления задач в очередь запросов, приложение отправляет сообщения в тему (
pullq). - Вместо того чтобы рабочий процесс арендовал задачи из очереди запросов, подписчик с именем
workerполучает сообщения из топикаpullq. - Приложение обрабатывает содержимое сообщений, увеличивая счетчики посетителей в хранилище данных.
- Вместо удаления задач из очереди обработки, приложение подтверждает получение обработанных сообщений.
При использовании очереди задач настройка включает создание очереди запросов. При использовании Pub/Sub настройка требует создания как темы, так и подписки. В модуле 18 мы обрабатывали queue.yaml вне выполнения приложения; теперь то же самое необходимо сделать с Pub/Sub.
Существует три варианта создания тем и подписок:
- Из облачной консоли
- Из командной строки или
- Из кода (короткий скрипт на Python)
Выберите один из вариантов ниже и следуйте соответствующим инструкциям для создания ресурсов Pub/Sub.
Из облачной консоли
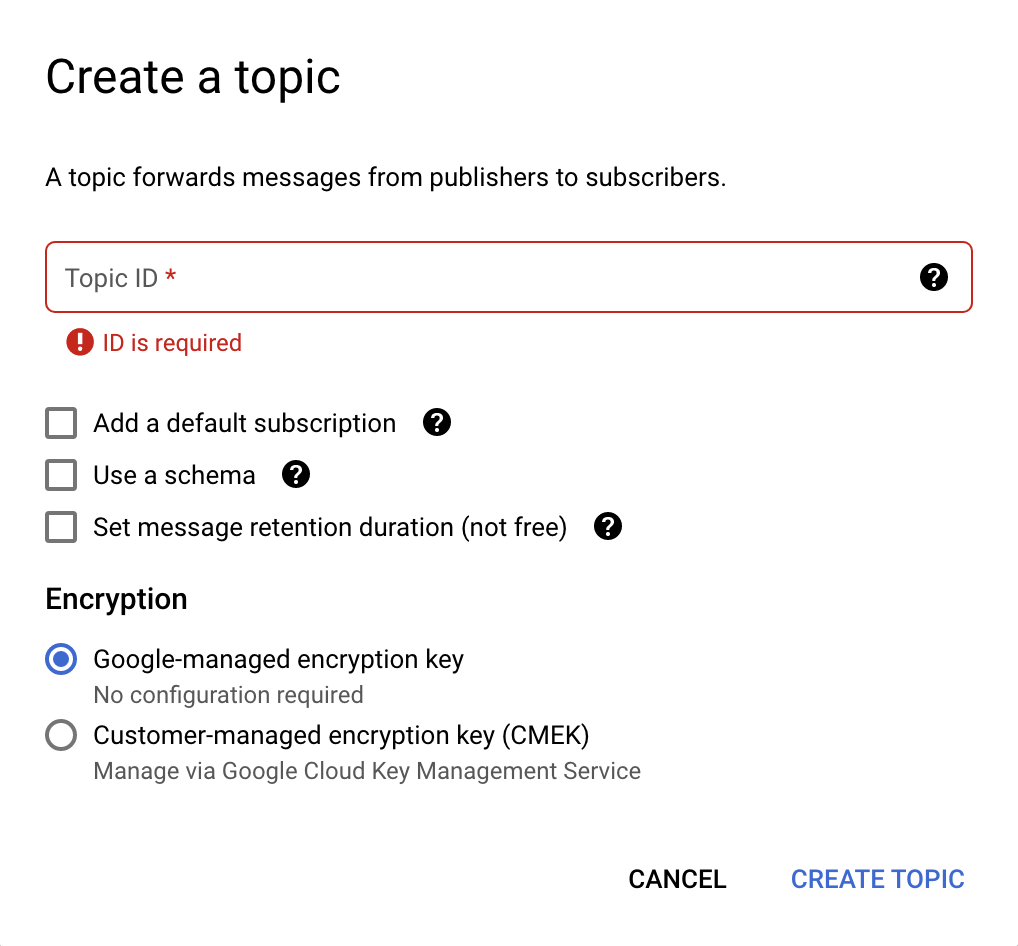
Чтобы создать тему из консоли Cloud Console, выполните следующие действия:
- Перейдите на страницу «Темы публикации/подписки» в консоли Cloud.
- Вверху нажмите кнопку «Создать тему» ; откроется новое диалоговое окно (см. изображение ниже).
- В поле «Идентификатор темы» введите
pullq. - Снимите флажки со всех отмеченных параметров и выберите ключ шифрования, управляемый Google .
- Нажмите кнопку «Создать тему» .
Вот как выглядит диалоговое окно создания темы:
Теперь, когда у вас есть тема, необходимо создать подписку на эту тему:
- Перейдите на страницу «Подписки Pub/Sub» в консоли Cloud.
- Вверху нажмите кнопку «Создать подписку» (см. изображение ниже).
- Введите имя
workerв поле «Идентификатор подписки» . - Выберите
pullqиз раскрывающегося списка «Выберите тему Cloud Pub/Sub », обратив внимание на его «полный путь», например,projects/PROJECT_ID/topics/pullq - В поле «Тип доставки» выберите «Сборка» .
- Оставьте все остальные параметры без изменений и нажмите кнопку «Создать» .
Вот как выглядит экран создания подписки:
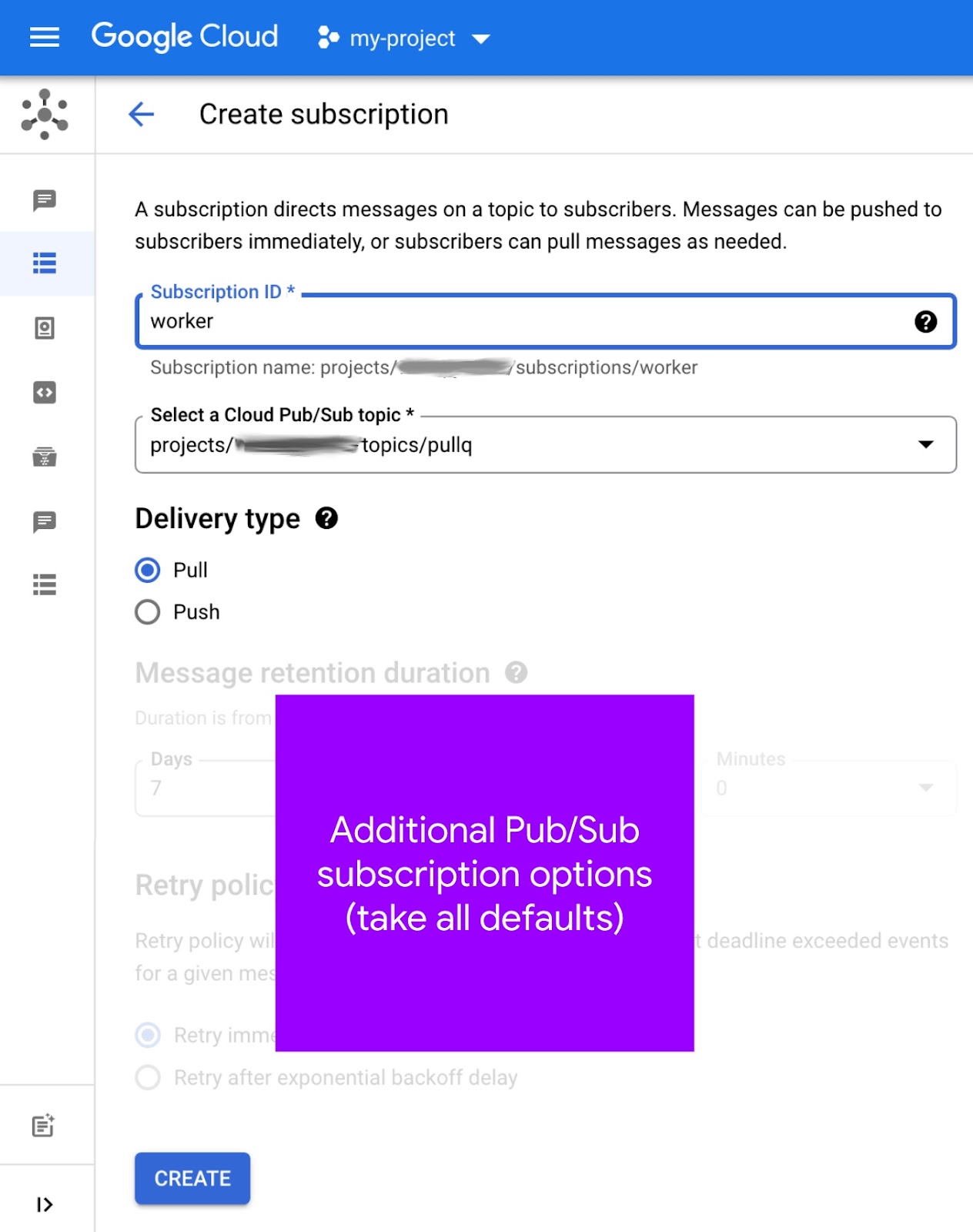
You can also create a subscription from the Topics page—this "shortcut" might be useful for you in helping associate topics with subscriptions. To learn more about creating subscriptions, see the documentation .
Из командной строки
Пользователи Pub/Sub могут создавать темы и подписки с помощью команд gcloud pubsub topics create TOPIC_ID и gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic= TOPIC_ID соответственно. Выполнение этих команд с TOPIC_ID равным pullq и SUBSCRIPTION_ID равным worker приводит к следующему результату для проекта PROJECT_ID :
$ gcloud pubsub topics create pullq Created topic [projects/PROJECT_ID/topics/pullq]. $ gcloud pubsub subscriptions create worker --topic=pullq Created subscription [projects/PROJECT_ID/subscriptions/worker].
См. также эту страницу в документации по быстрому запуску. Использование командной строки может упростить рабочие процессы, в которых темы и подписки создаются на регулярной основе, и такие команды можно использовать в сценариях оболочки для этой цели.
Из кода (короткий скрипт на Python)
Another way to automate creating topics and subscriptions is by using the Pub/Sub API in source code. Below is the code for the maker.py script in the Module 19 repo folder.
from __future__ import print_function
import google.auth
from google.api_core import exceptions
from google.cloud import pubsub
_, PROJECT_ID = google.auth.default()
TOPIC = 'pullq'
SBSCR = 'worker'
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
def make_top():
try:
top = ppc_client.create_topic(name=TOP_PATH)
print('Created topic %r (%s)' % (TOPIC, top.name))
except exceptions.AlreadyExists:
print('Topic %r already exists at %r' % (TOPIC, TOP_PATH))
def make_sub():
try:
sub = psc_client.create_subscription(name=SUB_PATH, topic=TOP_PATH)
print('Subscription created %r (%s)' % (SBSCR, sub.name))
except exceptions.AlreadyExists:
print('Subscription %r already exists at %r' % (SBSCR, SUB_PATH))
try:
psc_client.close()
except AttributeError: # special Py2 handler for grpcio<1.12.0
pass
make_top()
make_sub()
Выполнение этого скрипта приводит к ожидаемому результату (при условии отсутствия ошибок):
$ python3 maker.py Created topic 'pullq' (projects/PROJECT_ID/topics/pullq) Subscription created 'worker' (projects/PROJECT_ID/subscriptions/worker)
При вызове API для создания уже существующих ресурсов клиентская библиотека генерирует исключение google.api_core.exceptions.AlreadyExists , которое корректно обрабатывается скриптом:
$ python3 maker.py Topic 'pullq' already exists at 'projects/PROJECT_ID/topics/pullq' Subscription 'worker' already exists at 'projects/PROJECT_ID/subscriptions/worker'
Если вы новичок в Pub/Sub, ознакомьтесь с документом по архитектуре Pub/Sub для получения дополнительной информации.
5. Обновите конфигурацию
Обновления конфигурации включают в себя как изменение различных конфигурационных файлов, так и создание аналогов очередей запросов App Engine, но в рамках экосистемы Cloud Pub/Sub.
Удалите файл queue.yaml
Мы полностью отказываемся от очереди задач, поэтому удалите файл queue.yaml поскольку Pub/Sub его не использует. Вместо создания очереди запросов вы создадите тему Pub/Sub (и подписку ).
requirements.txt
Добавьте в requirements.txt строки google-cloud-ndb и google-cloud-pubsub , чтобы подключить flask из модуля 18. Обновленный файл requirements.txt модуля 19 теперь должен выглядеть так:
flask
google-cloud-ndb
google-cloud-pubsub
В файле requirements.txt отсутствуют номера версий, что означает выбор последних версий. В случае возникновения несовместимостей следует использовать стандартную процедуру фиксации рабочих версий приложения с помощью номеров версий.
app.yaml
Изменения в app.yaml различаются в зависимости от того, остаетесь ли вы с Python 2 или переходите на Python 3.
Python 2
В указанное выше обновление файла requirements.txt добавляется использование клиентских библиотек Google Cloud. Для их работы требуется дополнительная поддержка со стороны App Engine, а именно пара встроенных библиотек : setuptools и grpcio . Использование встроенных библиотек требует наличия раздела libraries в app.yaml и указания номеров версий библиотек или параметра "latest" для получения самой последней доступной версии на серверах App Engine. В файле app.yaml модуля 18 такого раздела пока нет:
ДО:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
Добавьте в app.yaml раздел libraries а также записи для setuptools и grpcio , указав их последние версии. Также добавьте закомментированную запись runtime для Python 3, указав текущую версию 3.x, например, 3.10 на момент написания этого текста. После этих изменений app.yaml теперь выглядит так:
ПОСЛЕ:
#runtime: python310
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
libraries:
- name: setuptools
version: latest
- name: grpcio
version: latest
Python 3
Для пользователей Python 3 и app.yaml все сводится к удалению ненужных элементов. В этом разделе вы удалите раздел handlers , директивы threadsafe и api_version , и не будете создавать раздел libraries .
В средах выполнения второго поколения отсутствуют встроенные сторонние библиотеки , поэтому раздел libraries в app.yaml не требуется. Кроме того, копирование (иногда называемое vendoring или self-bundling) невстроенных сторонних пакетов больше не требуется. Вам нужно лишь перечислить сторонние библиотеки, используемые вашим приложением, в requirements.txt .
Раздел handlers в app.yaml предназначен для указания обработчиков для приложения (скриптов) и статических файлов. Поскольку среда выполнения Python 3 требует от веб-фреймворков выполнения собственной маршрутизации, все обработчики скриптов должны быть изменены на auto . Если ваше приложение (например, как в модуле 18) не обслуживает статические файлы, все маршруты будут иметь значение auto , что сделает их неактуальными. В результате раздел handlers также не нужен, поэтому удалите его.
Наконец, директивы threadsafe и api_version не используются в Python 3, поэтому удалите и их. В итоге, вам следует удалить все разделы файла app.yaml , чтобы осталась только директива runtime , указывающая современную версию Python 3, например, 3.10. Вот как выглядит app.yaml до и после этих обновлений:
ДО:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
ПОСЛЕ:
runtime: python310
Для тех, кто не готов полностью удалять файл app.yaml для Python 3, мы предоставили альтернативный файл app3.yaml в папке репозитория модуля 19. Если вы хотите использовать его для развертывания, обязательно добавьте это имя файла в конец вашей команды: gcloud app deploy app3.yaml (в противном случае по умолчанию будет развернут ваш приложение с файлом app.yaml для Python 2, который вы оставили без изменений).
appengine_config.py
Если вы переходите на Python 3, файл appengine_config.py вам не нужен, поэтому удалите его. Причина в том, что для поддержки сторонних библиотек достаточно указать их в requirements.txt . Пользователям Python 2 — читайте дальше.
В модуле 18 appengine_config.py содержится соответствующий код для поддержки сторонних библиотек , например, Flask и облачных клиентских библиотек, недавно добавленных в requirements.txt :
ДО:
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
Однако одного этого кода недостаточно для поддержки только что добавленных встроенных библиотек ( setuptools , grpcio ). Необходимо добавить ещё несколько строк, поэтому обновите appengine_config.py так, чтобы он выглядел следующим образом:
ПОСЛЕ:
import pkg_resources
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
# Add libraries to pkg_resources working set to find the distribution.
pkg_resources.working_set.add_entry(PATH)
Более подробная информация об изменениях, необходимых для поддержки клиентских библиотек облачных сервисов, содержится в документации по миграции встроенных сервисов .
Другие обновления конфигурации
Если у вас есть папка lib , удалите её. Если вы используете Python 2, заполните папку lib , выполнив следующую команду:
pip install -t lib -r requirements.txt # or pip2
Если на вашей системе разработки установлены Python 2 и 3, вам может потребоваться использовать pip2 вместо pip .
6. Измените код приложения.
В этом разделе внесены изменения в основной файл приложения, main.py , заменяющие использование очередей задач App Engine на Cloud Pub/Sub. Веб-шаблон, templates/index.html , остался без изменений. Оба приложения должны работать идентично, отображая одни и те же данные.
Обновление импорта и инициализации
Внесены некоторые изменения в процессы импорта и инициализации:
- При импорте замените App Engine NDB и Task Queue на Cloud NDB и Pub/Sub.
- Переименовать
pullqиз имениQUEUEв имяTOPIC. - При использовании задач с запросом данных (pull tasks) работник арендовал их на час, но при использовании метода публикации/подписки (Pub/Sub) тайм-ауты измеряются для каждого сообщения отдельно, поэтому удалите константу
HOUR. - Для работы с облачными API требуется клиент API, поэтому инициализируйте их для Cloud NDB и Cloud Pub/Sub, причем последний предоставляет клиенты как для тем, так и для подписок.
- Для работы Pub/Sub требуется идентификатор проекта Cloud, поэтому импортируйте его и получите с помощью
google.auth.default(). - Для работы Pub/Sub требуются "полные пути к файлам" для тем и подписок, поэтому создавайте их с помощью удобных функций
*_path().
Ниже приведены импорт и инициализация из модуля 18, а затем показано, как должны выглядеть разделы после внесения вышеуказанных изменений, при этом большая часть нового кода представляет собой различные ресурсы Pub/Sub:
ДО:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
ПОСЛЕ:
from flask import Flask, render_template, request
import google.auth
from google.cloud import ndb, pubsub
LIMIT = 10
TASKS = 1000
TOPIC = 'pullq'
SBSCR = 'worker'
app = Flask(__name__)
ds_client = ndb.Client()
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
_, PROJECT_ID = google.auth.default()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
Обновления модели данных посещений
Модель данных Visit остается неизменной. Для доступа к Datastore требуется явное использование менеджера контекста клиента Cloud NDB API, ds_client.context() . В коде это означает, что вызовы Datastore в функциях store_visit() и fetch_visits() внутри Python оборачиваются with . Это обновление идентично тому, что рассматривалось в Модуле 2.
Наиболее существенное изменение для Pub/Sub заключается в замене добавления задачи pull из очереди задач на публикацию сообщения Pub/Sub в топик pullq . Ниже приведен код до и после внесения этих изменений:
ДО:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
ПОСЛЕ:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
with ds_client.context():
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
ppc_client.publish(TOP_PATH, remote_addr.encode('utf-8'))
def fetch_visits(limit):
'get most recent visits'
with ds_client.context():
return Visit.query().order(-Visit.timestamp).fetch(limit)
Обновления модели данных VisitorCount
Модель данных VisitorCount не меняется и использует fetch_counts() за исключением того, что запрос к Datastore оборачивается в блок with , как показано ниже:
ДО:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
ПОСЛЕ:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
with ds_client.context():
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
Обновить код рабочего процесса
В коде обработчика произошли изменения: NDB заменен на Cloud NDB, а очередь задач — на Pub/Sub, но сам рабочий процесс остался прежним.
- Оберните вызовы Datastore в менеджере контекста Cloud NDB
withблок. - Очистка очереди задач включает удаление всех задач из очереди запросов. В системе Pub/Sub идентификаторы подтверждений собираются в
acks, а затем удаляются/подтверждаются в конце. - Задачи очереди задач (Task Queue) обрабатываются аналогично сообщениям, извлекаемым из очередей публикаций (Pub/Sub). В то время как удаление задач, обрабатываемых из очередей, осуществляется с помощью самих объектов задач, сообщения Pub/Sub удаляются по их идентификаторам подтверждения.
- Для передачи данных в рамках модели Pub/Sub требуются байты (а не строки Python), поэтому при публикации и извлечении сообщений из топика используется кодировка и декодирование в UTF-8 соответственно.
Замените log_visitors() на обновленный код ниже, реализующий описанные выше изменения:
ДО:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
ПОСЛЕ:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
acks = set()
rsp = psc_client.pull(subscription=SUB_PATH, max_messages=TASKS)
msgs = rsp.received_messages
for rcvd_msg in msgs:
acks.add(rcvd_msg.ack_id)
visitor = rcvd_msg.message.data.decode('utf-8')
tallies[visitor] = tallies.get(visitor, 0) + 1
if acks:
psc_client.acknowledge(subscription=SUB_PATH, ack_ids=acks)
try:
psc_client.close()
except AttributeError: # special handler for grpcio<1.12.0
pass
# increment those counts in Datastore and return
if tallies:
with ds_client.context():
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(msgs), len(tallies))
В основном обработчике приложения root() изменений нет. Также не требуется никаких изменений в HTML-шаблоне templates/index.html , поэтому все необходимые обновления включены в этот код. Поздравляем с созданием нового приложения Модуля 19 с использованием Cloud Pub/Sub!
7. Подведение итогов/Завершение
Разверните приложение, чтобы убедиться в его корректной работе и корректности выходных данных. Также запустите обработчик для подсчета посетителей. После проверки приложения выполните необходимые действия по очистке и определите дальнейшие шаги.
Разверните и проверьте приложение.
Убедитесь, что вы уже создали тему pullq и подписку worker . Если это сделано и ваше тестовое приложение готово к работе, разверните его с помощью gcloud app deploy . Результат должен быть идентичен приложению из модуля 18, за исключением того, что вы успешно заменили весь базовый механизм очередей:
Теперь веб-интерфейс приложения проверяет работоспособность этой части. Хотя эта часть приложения успешно запрашивает и отображает самых популярных и последних посетителей, напомним, что приложение регистрирует это посещение и создает задачу добавления этого посетителя к общему числу. Эта задача теперь находится в очереди на обработку.
Вы можете выполнить это с помощью бэкэнд-сервиса App Engine, задания cron , перейдя по адресу /log или отправив HTTP-запрос из командной строки. Вот один пример выполнения и вывода кода обработчика с помощью curl (замените ваш PROJECT_ID ):
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
Обновленные данные будут отображены при следующем посещении сайта. Вот и все!
Уборка
Общий
Если на этом пока всё, мы рекомендуем отключить ваше приложение App Engine, чтобы избежать дополнительных расходов. Однако, если вы хотите продолжить тестирование или эксперименты, платформа App Engine предоставляет бесплатную квоту , поэтому, пока вы не превысите этот лимит, с вас не должны взиматься дополнительные платежи. Это касается вычислительных ресурсов, но за соответствующие услуги App Engine также может взиматься плата, поэтому проверьте страницу с ценами для получения более подробной информации. Если эта миграция включает другие облачные сервисы, они оплачиваются отдельно. В любом случае, если применимо, см. раздел «Информация, относящаяся к этому практическому занятию» ниже.
Для полной ясности, развертывание на бессерверной вычислительной платформе Google Cloud, такой как App Engine, влечет за собой незначительные затраты на сборку и хранение . Cloud Build и Cloud Storage имеют собственную бесплатную квоту. Хранение образа использует часть этой квоты. Однако вы можете проживать в регионе, где нет такого бесплатного уровня, поэтому следите за использованием хранилища, чтобы минимизировать потенциальные затраты. К числу конкретных «папок» Cloud Storage, которые следует проверить, относятся:
-
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/images -
console.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com - Приведенные выше ссылки на хранилища зависят от вашего
PROJECT_IDи *LOC*, например, "us", если ваше приложение размещено в США.
С другой стороны, если вы не собираетесь продолжать работу над этим приложением или другими связанными с миграцией кодовыми руководствами и хотите полностью удалить все, закройте свой проект .
Это относится именно к данному практическому занятию.
Перечисленные ниже услуги являются уникальными для данной учебной лаборатории. Для получения более подробной информации обратитесь к документации по каждому продукту:
- Для различных компонентов Cloud Pub/Sub предусмотрен бесплатный тариф; определите свой общий объем использования, чтобы лучше понять финансовые последствия, и ознакомьтесь с информацией на странице с ценами для получения более подробных сведений.
- Сервис App Engine Datastore предоставляется компанией Cloud Datastore (Cloud Firestore в режиме Datastore), которая также предлагает бесплатный тариф; подробную информацию можно найти на странице с ценами .
Следующие шаги
Помимо этого руководства, следует рассмотреть и другие модули миграции, ориентированные на отказ от устаревших встроенных сервисов:
- Модуль 2 : миграция с App Engine
ndbна Cloud NDB - Модули 7-9 : миграция с очереди задач App Engine (принудительная отправка задач) на облачные задачи.
- Модули 12-13 : миграция с App Engine Memcache на Cloud Memorystore
- Модули 15-16 : миграция с App Engine Blobstore на Cloud Storage.
App Engine больше не является единственной бессерверной платформой в Google Cloud. Если у вас небольшое приложение App Engine или приложение с ограниченной функциональностью, которое вы хотите превратить в автономный микросервис, или вы хотите разбить монолитное приложение на несколько многократно используемых компонентов, это веские причины для перехода на Cloud Functions . Если контейнеризация стала частью вашего рабочего процесса разработки приложений, особенно если он включает в себя конвейер CI/CD (непрерывная интеграция/непрерывная доставка или развертывание), рассмотрите возможность миграции на Cloud Run . Эти сценарии рассматриваются в следующих модулях:
- Переход с App Engine на Cloud Functions: см. Модуль 11
- Переход с App Engine на Cloud Run: см. Модуль 4 , чтобы контейнеризировать ваше приложение с помощью Docker, или Модуль 5 , чтобы сделать это без контейнеров, знаний Docker или файлов
Dockerfile.
Переход на другую бессерверную платформу необязателен, и мы рекомендуем рассмотреть оптимальные варианты для ваших приложений и сценариев использования, прежде чем вносить какие-либо изменения.
Независимо от того, какой модуль миграции вы выберете следующим, весь контент Serverless Migration Station (практические занятия, видео, исходный код [при наличии]) доступен в его репозитории с открытым исходным кодом . README репозитория также содержится информация о том, какие миграции следует рассмотреть и в каком порядке следует выбирать модули миграции.
8. Дополнительные ресурсы
Ниже перечислены дополнительные ресурсы для разработчиков, желающих подробнее изучить этот или связанный с ним модуль миграции, а также сопутствующие продукты. Сюда входят места для оставления отзывов о данном контенте, ссылки на код и различные документы, которые могут оказаться полезными.
Вопросы/отзывы о Codelabs
Если вы обнаружите какие-либо проблемы в этом практическом задании, пожалуйста, сначала найдите свою проблему, прежде чем сообщать о ней. Ссылки для поиска и создания новых проблем:
Миграционные ресурсы
Ссылки на папки репозитория для Модуля 18 (НАЧАЛО) и Модуля 19 (ЗАВЕРШЕНИЕ) можно найти в таблице ниже.
Кодлаб | Python 2 | Python 3 |
(н/д) | ||
Module 19 (this codelab) | (То же самое, что и в Python 2, за исключением использования файла app3.yaml, если вы не обновили app.yaml, как описано выше) |
Онлайн-ссылки
Ниже приведены ресурсы, имеющие отношение к данному уроку:
Очередь задач App Engine
- Обзор очереди задач App Engine
- Обзор очередей задач App Engine и очередей запросов.
- Пример приложения App Engine Task Queue pull queue.
- Создание очереди задач с возможностью выбора очередей
- Видео с презентации системы «pull queue» на Google I/O 2011 ( пример приложения Votelator )
- ссылка на файл
queue.yaml -
queue.yamlпротив облачных задач - Руководство по миграции очередей с использованием метода Pub/Sub
Облачная публикация/подписка
- Страница продукта Cloud Pub/Sub
- Использование клиентских библиотек Pub/Sub
- Примеры клиентской библиотеки Python для работы с протоколом Pub/Sub
- Документация клиентской библиотеки Pub/Sub для Python
- Создание и управление темами Pub/Sub
- Рекомендации по именованию тем в Pub/Sub
- Создание и управление подписками Pub/Sub
- Пример приложения App Engine (гибкий интерфейс) (возможно развертывание и на Standard; Python 3)
- Репозиторий с примером приложения, указанным выше.
- Подписки Pub/Sub с возможностью отправки по запросу
- Подписки Pub/Sub push
- Пример приложения App Engine Pub/Sub с функцией push-уведомлений (Python 3)
- Пример репозитория приложения App Engine Pub/Sub push
- Информация о ценах на пабы/сабы
- Облачные задачи или облачная публикация/подписка ? (push против pull)
App Engine NDB и Cloud NDB (хранилище данных)
- Документация App Engine NDB
- Репозиторий App Engine NDB
- Документация Google Cloud NDB
- Репозиторий Google Cloud NDB
- Информация о ценах на облачное хранилище данных
платформа App Engine
- Документация App Engine
- Среда выполнения Python 2 App Engine (стандартная среда)
- Использование встроенных библиотек App Engine в Python 2 App Engine
- Среда выполнения Python 3 App Engine (стандартная среда)
- Различия между средами выполнения Python 2 и 3 App Engine (стандартная среда)
- Руководство по миграции с Python 2 на Python 3 App Engine (стандартная среда)
- Информация о ценах и квотах App Engine
- Запуск платформы App Engine второго поколения (2018)
- Сравнение платформ первого и второго поколений
- Долгосрочная поддержка устаревших сред выполнения.
- Образцы миграции документации
- Образцы миграции, предоставленные сообществом
Прочая информация об облачных сервисах
- Python на платформе Google Cloud
- Клиентские библиотеки Python от Google Cloud
- Уровень Google Cloud «Всегда бесплатно»
- Google Cloud SDK (инструмент командной строки
gcloud) - Вся документация Google Cloud
Видео
- Станция миграции бессерверных приложений
- Бессерверные экспедиции
- Подпишитесь на Google Cloud Tech
- Подпишитесь на Google Developers
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.