
1. खास जानकारी
सर्वरलेस माइग्रेशन स्टेशन की कोडलैब सीरीज़ (अपने हिसाब से सीखने और प्रैक्टिकल करने वाले ट्यूटोरियल) और इससे जुड़े वीडियो का मकसद, Google Cloud सर्वरलेस डेवलपर की मदद करना है. इससे वे एक या उससे ज़्यादा माइग्रेशन करके, अपने ऐप्लिकेशन को बेहतर बना सकते हैं. इनमें मुख्य रूप से लेगसी सेवाओं से माइग्रेट करना शामिल है. ऐसा करने से, आपके ऐप्लिकेशन को एक जगह से दूसरी जगह ले जाना आसान हो जाता है. साथ ही, आपको ज़्यादा विकल्प और सुविधा मिलती है. इससे आपको Cloud प्रॉडक्ट की ज़्यादा रेंज के साथ इंटिग्रेट करने और उन्हें ऐक्सेस करने में मदद मिलती है. साथ ही, भाषा के नए वर्शन पर आसानी से अपग्रेड किया जा सकता है. शुरुआत में, इस सीरीज़ में मुख्य तौर पर App Engine (स्टैंडर्ड एनवायरमेंट) डेवलपर के लिए कॉन्टेंट शामिल किया गया था. हालांकि, अब इसमें अन्य सर्वरलेस प्लैटफ़ॉर्म के लिए भी कॉन्टेंट शामिल किया गया है. जैसे, Cloud Functions और Cloud Run. इसके अलावा, इसमें अन्य प्लैटफ़ॉर्म के लिए भी कॉन्टेंट शामिल किया गया है.
इस कोडलैब का मकसद, Python 2 App Engine डेवलपर को यह बताना है कि App Engine Task Queue के पुल टास्क से Cloud Pub/Sub पर कैसे माइग्रेट किया जाए. Datastore को ऐक्सेस करने के लिए, App Engine NDB से Cloud NDB में इंप्लिसिट माइग्रेशन भी होता है. इसके बारे में मुख्य रूप से मॉड्यूल 2 में बताया गया है. साथ ही, Python 3 में अपग्रेड भी होता है.
मॉड्यूल 18 में, आपको अपने ऐप्लिकेशन में पुल टास्क जोड़ने का तरीका बताया गया है. इस मॉड्यूल में, आपको मॉड्यूल 18 में बनाए गए ऐप्लिकेशन का इस्तेमाल करना है. साथ ही, आपको उस ऐप्लिकेशन को Cloud Pub/Sub पर माइग्रेट करना है. पुश टास्क के लिए Task Queues का इस्तेमाल करने वाले लोग, Cloud Tasks पर माइग्रेट करेंगे. उन्हें मॉड्यूल 7 से 9 देखने चाहिए.
आपको इनके बारे में जानकारी मिलेगी
- App Engine Task Queue (पुल टास्क) की जगह Cloud Pub/Sub का इस्तेमाल करना
- App Engine NDB की जगह Cloud NDB का इस्तेमाल करें. इसके बारे में जानने के लिए, दूसरा मॉड्यूल भी देखें
- ऐप्लिकेशन को Python 3 में पोर्ट करना
आपको किन चीज़ों की ज़रूरत होगी
- चालू GCP बिलिंग खाते वाला Google Cloud Platform प्रोजेक्ट
- Python की बुनियादी जानकारी
- Linux की सामान्य कमांड के बारे में जानकारी होना
- App Engine ऐप्लिकेशन डेवलप और डिप्लॉय करने की बुनियादी जानकारी
- App Engine का सैंपल ऐप्लिकेशन, जो मॉड्यूल 18 पर काम करता हो
सर्वे
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Python के साथ अपने अनुभव को आप क्या रेटिंग देंगे?
Google Cloud की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
2. बैकग्राउंड
App Engine Task Queue, पुश और पुल, दोनों तरह के टास्क के साथ काम करती है. ऐप्लिकेशन को आसानी से पोर्ट करने के लिए, Google Cloud का सुझाव है कि Task Queue जैसी लेगसी बंडल की गई सेवाओं से, Cloud की स्टैंडअलोन सेवाओं या तीसरे पक्ष की मिलती-जुलती सेवाओं पर माइग्रेट करें.
- Task Queue push task का इस्तेमाल करने वाले लोगों को Cloud Tasks पर माइग्रेट करना चाहिए.
- Task Queue के पुल टास्क का इस्तेमाल करने वाले लोगों को Cloud Pub/Sub पर माइग्रेट करना चाहिए.
माइग्रेशन के मॉड्यूल 7 से 9 में, पुश टास्क माइग्रेशन के बारे में बताया गया है. वहीं, मॉड्यूल 18 और 19 में पुल टास्क माइग्रेशन के बारे में बताया गया है. Cloud Tasks, Task Queue के पुश टास्क से ज़्यादा मेल खाता है. हालांकि, Pub/Sub, Task Queue के पुल टास्क से उतना मेल नहीं खाता.
Pub/Sub में, Task Queue की पुल सुविधा के मुकाबले ज़्यादा सुविधाएँ हैं. उदाहरण के लिए, Pub/Sub में पुश करने की सुविधा भी होती है. हालांकि, Cloud Tasks, टास्क क्यू में पुश किए जाने वाले टास्क की तरह होता है. इसलिए, Pub/Sub पुश को किसी भी माइग्रेशन मॉड्यूल में शामिल नहीं किया गया है. इस 19वें मॉड्यूल के कोडलैब में, टास्क क्यू की पुल क्यू से Pub/Sub पर क्यूइंग मेकेनिज़्म को स्विच करने के साथ-साथ, Datastore को ऐक्सेस करने के लिए App Engine NDB से Cloud NDB पर माइग्रेट करने का तरीका बताया गया है. इसमें दूसरे मॉड्यूल के माइग्रेशन को दोहराया गया है.
Module 18 के कोड को Python 2 के सैंपल ऐप्लिकेशन के तौर पर "प्रमोट" किया गया है. हालांकि, इसका सोर्स Python 2 और 3 के साथ काम करता है. साथ ही, Module 19 में Cloud Pub/Sub (और Cloud NDB) पर माइग्रेट करने के बाद भी यह इसी तरह काम करता है.
इस ट्यूटोरियल में ये चरण शामिल हैं:
- सेटअप/प्रीवर्क
- कॉन्फ़िगरेशन अपडेट करना
- ऐप्लिकेशन कोड में बदलाव करना
3. सेटअप/प्रीवर्क
इस सेक्शन में, यह बताया गया है कि:
- अपना Cloud प्रोजेक्ट सेट अप करना
- बेसलाइन सैंपल ऐप्लिकेशन पाना
- बेसलाइन ऐप्लिकेशन को (फिर से) डिप्लॉय करें और उसकी पुष्टि करें
- Google Cloud की नई सेवाओं/एपीआई को चालू करना
इन चरणों से यह पक्का किया जाता है कि आप काम करने वाले कोड से शुरुआत कर रहे हैं और यह क्लाउड सेवाओं पर माइग्रेट करने के लिए तैयार है.
1. प्रोजेक्ट सेट अप करना
अगर आपने मॉड्यूल 18 का कोडलैब पूरा कर लिया है, तो उसी प्रोजेक्ट और कोड का फिर से इस्तेमाल करें. इसके अलावा, एक नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. पक्का करें कि प्रोजेक्ट में चालू बिलिंग खाता हो और App Engine ऐप्लिकेशन चालू हो. अपना प्रोजेक्ट आईडी ढूंढें, क्योंकि इस कोडलैब के दौरान आपको इसकी ज़रूरत होगी. जब भी आपको PROJECT_ID वैरिएबल दिखे, तब इसका इस्तेमाल करें.
2. बेसलाइन सैंपल ऐप्लिकेशन पाना
इसके लिए, Module 18 App Engine ऐप्लिकेशन का काम करना ज़रूरी है. इसलिए, या तो इसका कोडलैब पूरा करें (सुझाया गया; ऊपर दिया गया लिंक) या repo से Module 18 कोड कॉपी करें. चाहे आपने अपना प्रॉम्प्ट इस्तेमाल किया हो या हमारा, हम यहीं से शुरू करेंगे ("START"). इस कोडलैब में, माइग्रेट करने का तरीका बताया गया है. इसमें आखिर में ऐसा कोड दिया गया है जो Module 19 repo फ़ोल्डर ("FINISH") में मौजूद कोड जैसा है.
- शुरू करें: Module 18 folder (Python 2)
- FINISH: Module 19 folder (Python 2 और 3)
- पूरी रिपो (क्लोन करने या ZIP फ़ाइल डाउनलोड करने के लिए)
Module 18 के किसी भी ऐप्लिकेशन का इस्तेमाल करने पर, फ़ोल्डर ऐसा दिखना चाहिए. इसमें lib फ़ोल्डर भी हो सकता है:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
3. बेसलाइन ऐप्लिकेशन को (फिर से) डिप्लॉय करें और उसकी पुष्टि करें
Module 18 ऐप्लिकेशन को डिप्लॉय करने के लिए, यह तरीका अपनाएं:
- अगर
libफ़ोल्डर मौजूद है, तो उसे मिटाएं. इसके बाद,pip install -t lib -r requirements.txtचलाकरlibको फिर से भरें. अगर आपने डेवलपमेंट मशीन पर Python 2 और 3, दोनों इंस्टॉल किए हैं, तो आपकोpip2का इस्तेमाल करना पड़ सकता है. - पक्का करें कि आपने
gcloudकमांड-लाइन टूल को इंस्टॉल और शुरू कर लिया हो. साथ ही, इसके इस्तेमाल की समीक्षा कर ली हो. - (ज़रूरी नहीं) अगर आपको हर
gcloudकमांड के साथPROJECT_IDनहीं डालना है, तोgcloud config set projectPROJECT_IDका इस्तेमाल करके अपना Cloud प्रोजेक्ट सेट करें. gcloud app deployकी मदद से, सैंपल ऐप्लिकेशन को डिप्लॉय करना- पुष्टि करें कि ऐप्लिकेशन बिना किसी समस्या के उम्मीद के मुताबिक काम कर रहा है. अगर आपने 18वें मॉड्यूल का कोडलैब पूरा कर लिया है, तो ऐप्लिकेशन में सबसे ज़्यादा बार आने वाले लोगों के साथ-साथ हाल ही की विज़िट भी दिखेंगी. इसकी जानकारी यहां दी गई है. अगर ऐसा नहीं है, तो हो सकता है कि दिखाने के लिए कोई विज़िटर काउंट न हो.
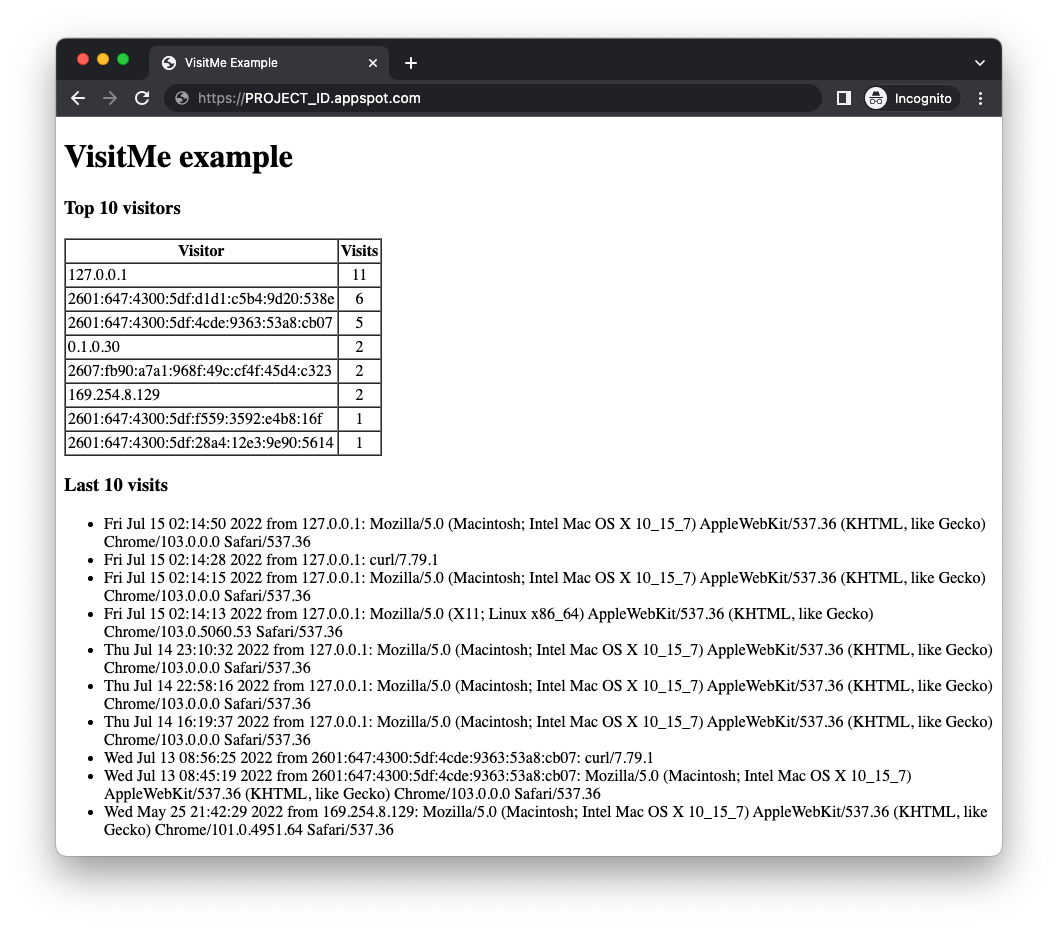
Module 18 के सैंपल ऐप्लिकेशन को माइग्रेट करने से पहले, आपको उन क्लाउड सेवाओं को चालू करना होगा जिनका इस्तेमाल, बदला गया ऐप्लिकेशन करेगा.
4. Google Cloud की नई सेवाओं/एपीआई को चालू करना
पुराने ऐप्लिकेशन में App Engine की बंडल की गई सेवाओं का इस्तेमाल किया जाता था. इनके लिए, किसी अतिरिक्त सेटअप की ज़रूरत नहीं होती. हालांकि, स्टैंडअलोन Cloud सेवाओं के लिए ऐसा करना ज़रूरी होता है. अपडेट किए गए ऐप्लिकेशन में Cloud Pub/Sub और Cloud Datastore, दोनों का इस्तेमाल किया जाएगा. ऐसा Cloud NDB क्लाइंट लाइब्रेरी के ज़रिए किया जाएगा. App Engine और दोनों Cloud API के लिए, "हमेशा मुफ़्त" टियर के कोटे उपलब्ध हैं. जब तक आप इन सीमाओं के अंदर रहते हैं, तब तक इस ट्यूटोरियल को पूरा करने के लिए आपसे कोई शुल्क नहीं लिया जाएगा. Cloud API को Cloud Console या कमांड-लाइन से चालू किया जा सकता है. यह आपकी पसंद पर निर्भर करता है.
Cloud Console से
Cloud Console में, सही प्रोजेक्ट के लिए एपीआई मैनेजर के लाइब्रेरी पेज पर जाएं. इसके बाद, पेज के बीच में मौजूद खोज बार का इस्तेमाल करके, Cloud Datastore और Cloud Pub/Sub API खोजें:
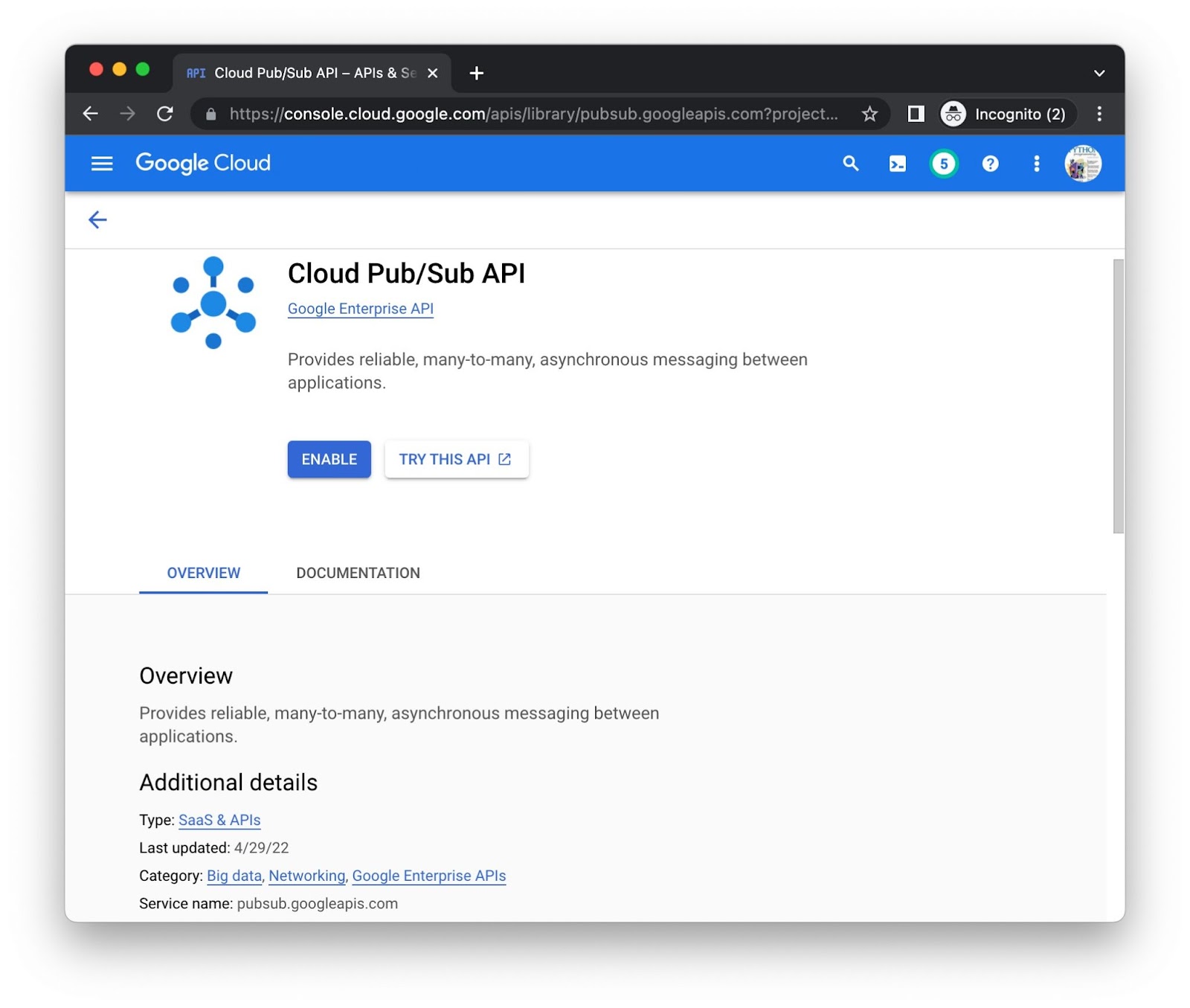
हर एपीआई के लिए, चालू करें बटन पर क्लिक करें. आपसे बिलिंग की जानकारी मांगी जा सकती है. उदाहरण के लिए, यह Cloud Pub/Sub API लाइब्रेरी का पेज है:
कमांड-लाइन से
कंसोल से एपीआई चालू करने पर, विज़ुअल तौर पर जानकारी मिलती है. हालांकि, कुछ लोग कमांड-लाइन का इस्तेमाल करना पसंद करते हैं. दोनों एपीआई को एक साथ चालू करने के लिए, gcloud services enable pubsub.googleapis.com datastore.googleapis.com कमांड जारी करें:
$ gcloud services enable pubsub.googleapis.com datastore.googleapis.com Operation "operations/acat.p2-aaa-bbb-ccc-ddd-eee-ffffff" finished successfully.
आपसे बिलिंग की जानकारी मांगी जा सकती है. अगर आपको अन्य Cloud API चालू करने हैं और उनके यूआरआई के बारे में जानना है, तो उन्हें हर एपीआई के लाइब्रेरी पेज पर सबसे नीचे देखा जा सकता है. उदाहरण के लिए, Pub/Sub पेज पर सबसे नीचे मौजूद, pubsub.googleapis.com को "सेवा का नाम" के तौर पर देखें.
इन चरणों को पूरा करने के बाद, आपका प्रोजेक्ट एपीआई को ऐक्सेस कर पाएगा. अब समय है कि ऐप्लिकेशन को अपडेट करके, उन एपीआई का इस्तेमाल किया जाए.
4. Pub/Sub संसाधन बनाना
मॉड्यूल 18 में टास्क क्यू वर्कफ़्लो के क्रम को फिर से बताया गया है:
- मॉड्यूल 18 में,
queue.yamlफ़ाइल का इस्तेमाल करकेpullqनाम की पुल क्यू बनाई गई थी. - यह ऐप्लिकेशन, वेबसाइट पर आने वाले लोगों को ट्रैक करने के लिए, पुल क्यू में टास्क जोड़ता है.
- टास्क को आखिर में एक वर्कर प्रोसेस करता है. इसे एक घंटे के लिए लीज़ किया जाता है.
- हाल ही के विज़िटर की संख्या का मिलान करने के लिए, टास्क पूरे किए जाते हैं.
- टास्क पूरा होने पर, उन्हें सूची से हटा दिया जाता है.
आपको Pub/Sub की मदद से, इसी तरह का वर्कफ़्लो दोहराना है. अगले सेक्शन में, Pub/Sub की बुनियादी शब्दावली के बारे में बताया गया है. साथ ही, Pub/Sub के ज़रूरी संसाधन बनाने के तीन अलग-अलग तरीके बताए गए हैं.
App Engine की टास्क क्यू (पुल) और Cloud Pub/Sub की शब्दावली
Pub/Sub पर स्विच करने के लिए, आपको अपने शब्दकोश में थोड़ा बदलाव करना होगा. यहां दोनों प्रॉडक्ट की मुख्य कैटगरी और उनसे जुड़े शब्द दिए गए हैं. इसके अलावा, माइग्रेशन गाइड भी देखें. इसमें भी इसी तरह की तुलनाएं दी गई हैं.
- डेटा स्ट्रक्चर को क्रम में लगाना: टास्क क्यू की मदद से, डेटा को पुल क्यू में भेजा जाता है. वहीं, Pub/Sub की मदद से, डेटा को विषयों में भेजा जाता है.
- कतार में लगे डेटा की इकाइयां: Task Queue में मौजूद पुल टास्क को Pub/Sub में मैसेज कहा जाता है.
- डेटा प्रोसेसर: Task Queue की मदद से, वर्कर पुल टास्क ऐक्सेस करते हैं. वहीं, Pub/Sub की मदद से मैसेज पाने के लिए, आपको सदस्यताएं/सदस्य चाहिए
- डेटा निकालना: पुल टास्क को लीज़ करना, किसी विषय से (सदस्यता के ज़रिए) मैसेज पुल करने जैसा ही होता है.
- क्लीन-अप/पूरा करना: जब आपका काम पूरा हो जाता है, तब पुल क्यू से Task Queue टास्क को मिटाना, Pub/Sub मैसेज को स्वीकार करने जैसा होता है
प्रॉडक्ट में बदलावों को क्रम से लगाने की सुविधा में बदलाव हुआ है, लेकिन वर्कफ़्लो में ज़्यादा बदलाव नहीं हुआ है:
- ऐप्लिकेशन, पुल क्यू के बजाय
pullqनाम के विषय का इस्तेमाल करता है. - ऐप्लिकेशन, टास्क को पुल क्यू में जोड़ने के बजाय, किसी विषय (
pullq) को मैसेज भेजता है. - पुल क्यू से टास्क लीज़ करने वाले वर्कर के बजाय,
workerनाम का सदस्य,pullqविषय से मैसेज पुल करता है. - यह ऐप्लिकेशन, मैसेज पेलोड को प्रोसेस करता है. साथ ही, Datastore में वेबसाइट पर आने वाले लोगों की संख्या बढ़ाता है.
- ऐप्लिकेशन, पुल क्यू से टास्क मिटाने के बजाय, प्रोसेस किए गए मैसेज की पुष्टि करता है.
टास्क क्यू की मदद से, पुल क्यू बनाया जाता है. Pub/Sub का इस्तेमाल करने के लिए, आपको एक विषय और एक सदस्यता बनानी होगी. मॉड्यूल 18 में, हमने queue.yaml को ऐप्लिकेशन के बाहर प्रोसेस किया था. अब इसे Pub/Sub के साथ भी करना होगा.
विषय और सदस्यताएं बनाने के लिए, आपके पास तीन विकल्प हैं:
- Cloud Console से
- कमांड-लाइन से या
- कोड (छोटी Python स्क्रिप्ट) से
Pub/Sub संसाधन बनाने के लिए, यहां दिए गए विकल्पों में से कोई एक चुनें और उससे जुड़े निर्देशों का पालन करें.
Cloud Console से
Cloud Console से कोई विषय बनाने के लिए, यह तरीका अपनाएं:
- Cloud Console में Pub/Sub के विषय वाले पेज पर जाएं.
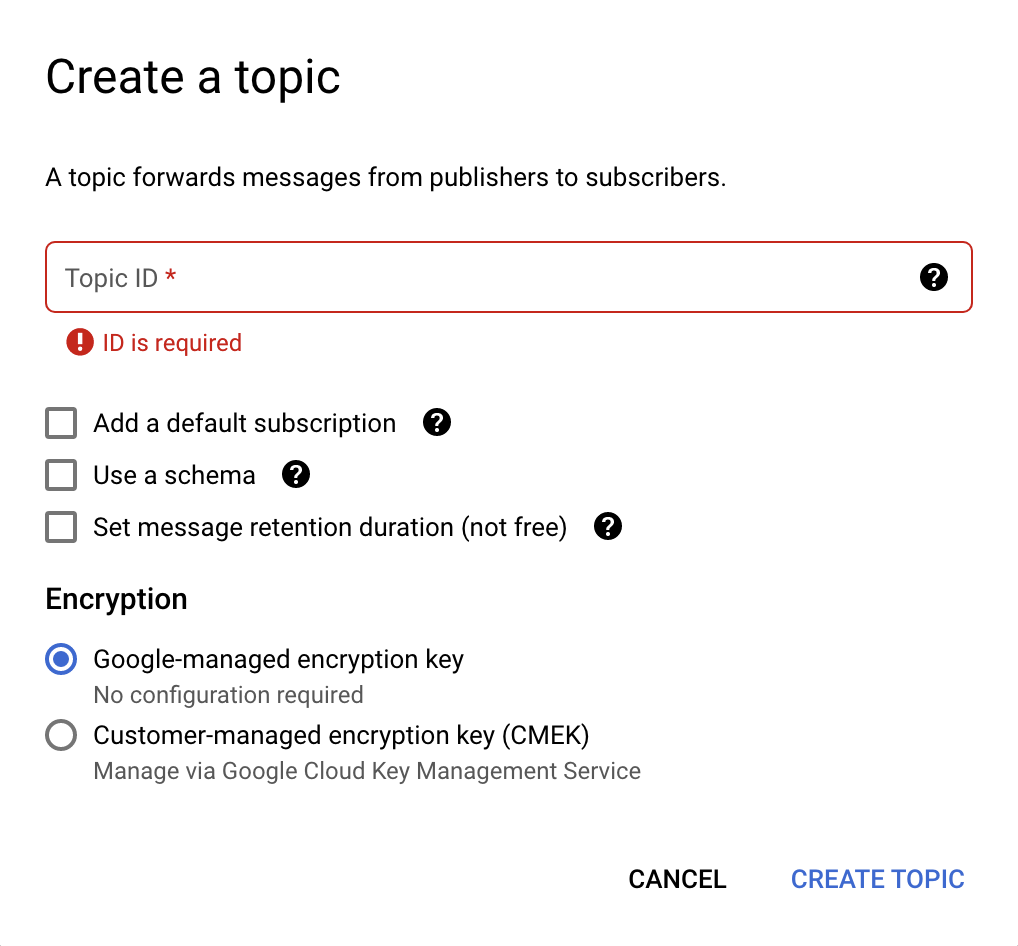
- सबसे ऊपर मौजूद, विषय बनाएं पर क्लिक करें. इसके बाद, एक नई डायलॉग विंडो खुलेगी (नीचे दी गई इमेज देखें)
- विषय का आईडी फ़ील्ड में,
pullqडालें. - सही का निशान लगे सभी विकल्पों से चुने हुए का निशान हटाएं. इसके बाद, Google की ओर से मैनेज की जाने वाली एन्क्रिप्शन कुंजी को चुनें.
- बनाएं विषय बटन पर क्लिक करें.
विषय बनाने का डायलॉग बॉक्स ऐसा दिखता है:
अब आपके पास एक विषय है. इसलिए, उस विषय के लिए सदस्यता बनानी होगी:
- Cloud Console में Pub/Sub सदस्यता पेज पर जाएं.
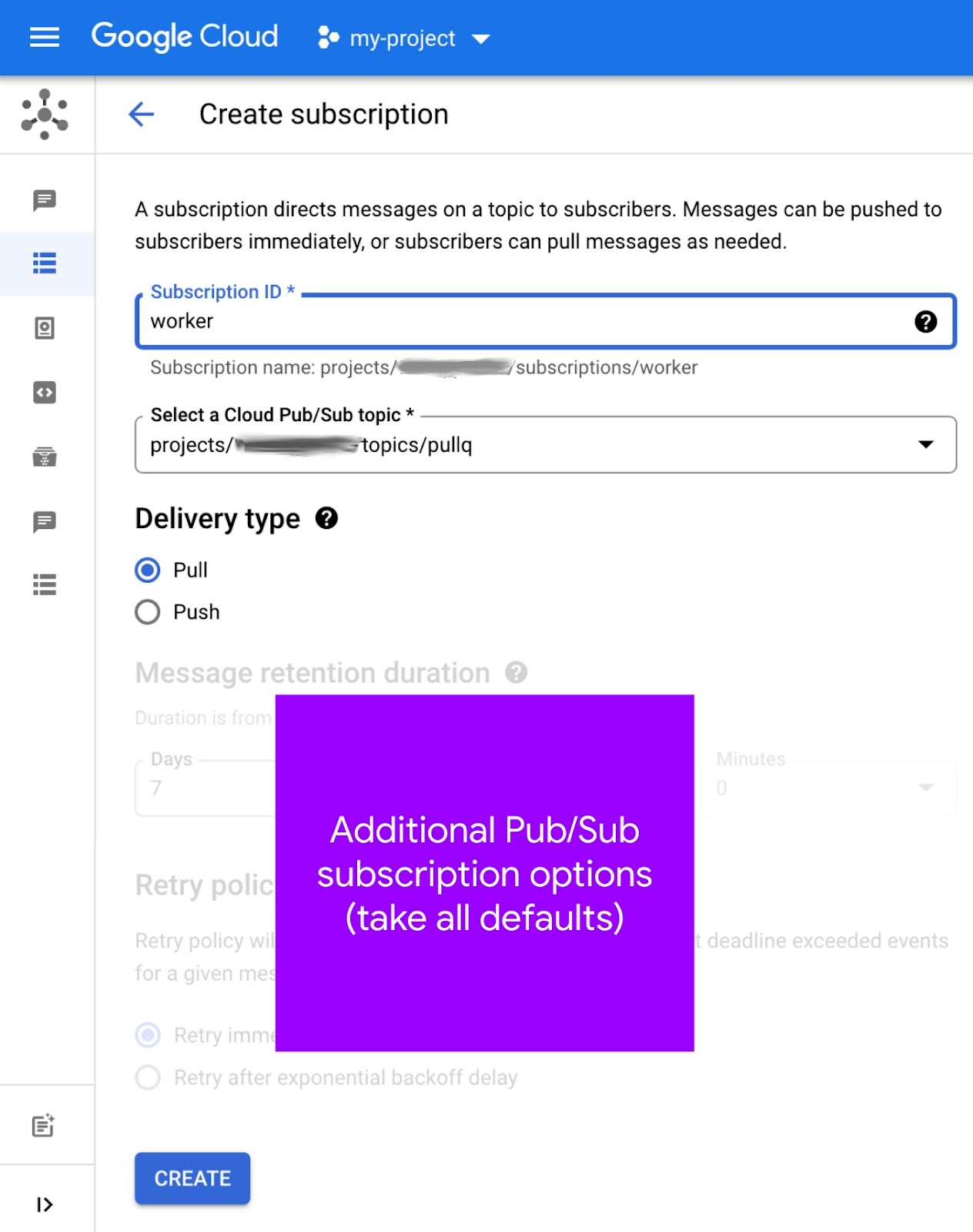
- सबसे ऊपर मौजूद, सदस्यता बनाएं पर क्लिक करें. नीचे दी गई इमेज देखें.
- सदस्यता आईडी फ़ील्ड में
workerडालें. - Cloud Pub/Sub टॉपिक चुनें पुलडाउन से
pullqचुनें. साथ ही, इसके "पूरी तरह से क्वालिफ़ाइड पाथनेम" को नोट करें. उदाहरण के लिए,projects/PROJECT_ID/topics/pullq - डिलीवरी टाइप के लिए, पुल चुनें.
- अन्य सभी विकल्पों को डिफ़ॉल्ट रूप से सेट रहने दें और बनाएं बटन पर क्लिक करें.
सदस्यता बनाने की स्क्रीन ऐसी दिखती है:
विषय पेज पर जाकर भी सदस्यता बनाई जा सकती है. यह "शॉर्टकट" आपके लिए तब काम का हो सकता है, जब आपको विषयों को सदस्यताओं से जोड़ना हो. सदस्यताएं बनाने के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
कमांड-लाइन से
Pub/Sub के उपयोगकर्ता, gcloud pubsub topics create TOPIC_ID और gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic=TOPIC_ID कमांड का इस्तेमाल करके, विषय और सदस्यताएं बना सकते हैं. pullq के TOPIC_ID और worker के SUBSCRIPTION_ID के साथ इन निर्देशों को लागू करने पर, प्रोजेक्ट PROJECT_ID के लिए यह आउटपुट मिलता है:
$ gcloud pubsub topics create pullq Created topic [projects/PROJECT_ID/topics/pullq]. $ gcloud pubsub subscriptions create worker --topic=pullq Created subscription [projects/PROJECT_ID/subscriptions/worker].
क्विकस्टार्ट दस्तावेज़ में, यह पेज भी देखें. कमांड-लाइन का इस्तेमाल करने से, उन वर्कफ़्लो को आसान बनाया जा सकता है जहां विषयों और सदस्यताओं को नियमित तौर पर बनाया जाता है. साथ ही, इस काम के लिए शेल स्क्रिप्ट में ऐसी कमांड का इस्तेमाल किया जा सकता है.
कोड (छोटी Python स्क्रिप्ट) से
विषय और सदस्यताएं अपने-आप बनाने का एक और तरीका है. इसके लिए, सोर्स कोड में Pub/Sub API का इस्तेमाल करें. मॉड्यूल 19 के रेपो फ़ोल्डर में, maker.py स्क्रिप्ट का कोड यहां दिया गया है.
from __future__ import print_function
import google.auth
from google.api_core import exceptions
from google.cloud import pubsub
_, PROJECT_ID = google.auth.default()
TOPIC = 'pullq'
SBSCR = 'worker'
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
def make_top():
try:
top = ppc_client.create_topic(name=TOP_PATH)
print('Created topic %r (%s)' % (TOPIC, top.name))
except exceptions.AlreadyExists:
print('Topic %r already exists at %r' % (TOPIC, TOP_PATH))
def make_sub():
try:
sub = psc_client.create_subscription(name=SUB_PATH, topic=TOP_PATH)
print('Subscription created %r (%s)' % (SBSCR, sub.name))
except exceptions.AlreadyExists:
print('Subscription %r already exists at %r' % (SBSCR, SUB_PATH))
try:
psc_client.close()
except AttributeError: # special Py2 handler for grpcio<1.12.0
pass
make_top()
make_sub()
इस स्क्रिप्ट को एक्ज़ीक्यूट करने पर, उम्मीद के मुताबिक आउटपुट मिलता है. हालांकि, ऐसा तब होता है, जब कोई गड़बड़ी न हो:
$ python3 maker.py Created topic 'pullq' (projects/PROJECT_ID/topics/pullq) Subscription created 'worker' (projects/PROJECT_ID/subscriptions/worker)
पहले से मौजूद संसाधनों को बनाने के लिए एपीआई को कॉल करने पर, क्लाइंट लाइब्रेरी से google.api_core.exceptions.AlreadyExists अपवाद मिलता है. इसे स्क्रिप्ट मैनेज करती है:
$ python3 maker.py Topic 'pullq' already exists at 'projects/PROJECT_ID/topics/pullq' Subscription 'worker' already exists at 'projects/PROJECT_ID/subscriptions/worker'
अगर आपने Pub/Sub का इस्तेमाल पहले कभी नहीं किया है, तो ज़्यादा जानकारी के लिए Pub/Sub आर्किटेक्चर का वाइट पेपर देखें.
5. कॉन्फ़िगरेशन अपडेट करना
कॉन्फ़िगरेशन में किए गए अपडेट में, अलग-अलग कॉन्फ़िगरेशन फ़ाइलों में बदलाव करना और App Engine की पुल कतारों के बराबर की कतारें बनाना शामिल है. हालांकि, ये कतारें Cloud Pub/Sub के इकोसिस्टम में बनाई जाती हैं.
queue.yaml फ़ाइल मिटाएं
हम पूरी तरह से Task Queue का इस्तेमाल बंद कर रहे हैं. इसलिए, queue.yaml को मिटा दें, क्योंकि Pub/Sub इस फ़ाइल का इस्तेमाल नहीं करता. पुल क्यू बनाने के बजाय, आपको Pub/Sub विषय और सदस्यता बनानी होगी.
requirements.txt
मॉड्यूल 18 से flask में शामिल होने के लिए, google-cloud-ndb और google-cloud-pubsub, दोनों को requirements.txt में जोड़ें. अपडेट किया गया आपका मॉड्यूल 19 requirements.txt अब ऐसा दिखना चाहिए:
flask
google-cloud-ndb
google-cloud-pubsub
इस requirements.txt फ़ाइल में कोई वर्शन नंबर नहीं है. इसका मतलब है कि सबसे नए वर्शन चुने गए हैं. अगर कोई समस्या आती है, तो ऐप्लिकेशन के काम करने वाले वर्शन को लॉक-इन करने के लिए, वर्शन नंबर इस्तेमाल करने का स्टैंडर्ड तरीका अपनाएं.
app.yaml
app.yaml में किए जाने वाले बदलाव, इस बात पर निर्भर करते हैं कि आपको Python 2 का इस्तेमाल जारी रखना है या Python 3 पर अपग्रेड करना है.
Python 2
requirements.txt के ऊपर दिए गए अपडेट में, Google Cloud की क्लाइंट लाइब्रेरी का इस्तेमाल किया गया है. इनके लिए App Engine से अतिरिक्त सहायता की ज़रूरत होती है. जैसे, कुछ बिल्ट-इन लाइब्रेरी, setuptools, और grpcio. पहले से मौजूद लाइब्रेरी का इस्तेमाल करने के लिए, app.yaml में libraries सेक्शन और लाइब्रेरी के वर्शन नंबर या App Engine सर्वर पर उपलब्ध सबसे नए वर्शन के लिए "latest" का इस्तेमाल करना ज़रूरी है. मॉड्यूल 18 app.yaml में, इनमें से कोई एक सेक्शन अभी तक नहीं है:
BEFORE:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
app.yaml में libraries सेक्शन जोड़ें. साथ ही, setuptools और grpcio, दोनों के लिए एंट्री जोड़ें. इसके लिए, उनके नए वर्शन चुनें. साथ ही, Python 3 के लिए एक प्लेसहोल्डर runtime एंट्री जोड़ें. इसे मौजूदा 3.x रिलीज़ के साथ टिप्पणी के तौर पर जोड़ा गया है. उदाहरण के लिए, इस लेख को लिखते समय 3.10. इन बदलावों के बाद, app.yaml अब ऐसा दिखता है:
AFTER:
#runtime: python310
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
libraries:
- name: setuptools
version: latest
- name: grpcio
version: latest
Python 3
Python 3 और app.yaml का इस्तेमाल करने वाले लोगों के लिए, यह सब कुछ हटाने के बारे में है. इस सेक्शन में, आपको handlers सेक्शन, threadsafe और api_version डायरेक्टिव मिटाने होंगे. साथ ही, आपको libraries सेक्शन नहीं बनाना होगा.
दूसरी जनरेशन के रनटाइम में, तीसरे पक्ष की लाइब्रेरी पहले से मौजूद नहीं होती हैं. इसलिए, app.yaml में libraries सेक्शन की ज़रूरत नहीं होती. इसके अलावा, कॉपी करने (इसे कभी-कभी वेंडरिंग या सेल्फ़-बंडलिंग भी कहा जाता है) नॉन-बिल्ट-इन तीसरे पक्ष के पैकेज की अब ज़रूरत नहीं है. आपको सिर्फ़ उन तीसरे पक्ष की लाइब्रेरी को requirements.txt में शामिल करना होगा जिनका इस्तेमाल आपका ऐप्लिकेशन करता है.
app.yaml में मौजूद handlers सेक्शन का इस्तेमाल, ऐप्लिकेशन (स्क्रिप्ट) और स्टैटिक फ़ाइल हैंडलर के बारे में बताने के लिए किया जाता है. Python 3 रनटाइम को वेब फ़्रेमवर्क की ज़रूरत होती है, ताकि वे अपनी राउटिंग कर सकें. इसलिए, सभी स्क्रिप्ट हैंडलर को auto में बदलना होगा. अगर आपका ऐप्लिकेशन (जैसे कि Module 18) स्टैटिक फ़ाइलें नहीं दिखाता है, तो सभी रूट auto हो जाएंगे. इससे वे काम के नहीं रहेंगे. इसलिए, handlers सेक्शन की भी ज़रूरत नहीं है. इसे मिटा दें.
आखिर में, Python 3 में न तो threadsafe और न ही api_version निर्देशों का इस्तेमाल किया जाता है. इसलिए, इन्हें भी मिटा दें. इसका मतलब यह है कि आपको app.yaml के सभी सेक्शन मिटा देने चाहिए, ताकि सिर्फ़ runtime डायरेक्टिव बचा रहे. इसमें Python 3 का नया वर्शन, जैसे कि 3.10 के बारे में बताया गया हो. इन अपडेट से पहले और बाद में, app.yaml इस तरह दिखता है:
BEFORE:
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
AFTER:
runtime: python310
जिन लोगों को Python 3 के लिए app.yaml से सब कुछ नहीं मिटाना है उनके लिए, हमने Module 19 repo फ़ोल्डर में app3.yaml की वैकल्पिक फ़ाइल उपलब्ध कराई है. अगर आपको डिप्लॉयमेंट के लिए इसका इस्तेमाल करना है, तो पक्का करें कि आपने इस फ़ाइल के नाम को अपने निर्देश के आखिर में जोड़ दिया हो: gcloud app deploy app3.yaml. ऐसा न करने पर, यह डिफ़ॉल्ट रूप से Python 2 app.yaml फ़ाइल का इस्तेमाल करेगा और आपके ऐप्लिकेशन को डिप्लॉय करेगा.
appengine_config.py
अगर Python 3 पर अपग्रेड किया जा रहा है, तो appengine_config.py की ज़रूरत नहीं है. इसलिए, इसे मिटा दें. तीसरे पक्ष की लाइब्रेरी के साथ काम करने के लिए, सिर्फ़ requirements.txt में उन्हें तय करना ज़रूरी होता है. इसलिए, उन्हें अलग से तय करने की ज़रूरत नहीं होती. Python 2 का इस्तेमाल करने वाले लोग, आगे पढ़ें.
मॉड्यूल 18 appengine_config.py में, तीसरे पक्ष की लाइब्रेरी के साथ काम करने वाला सही कोड मौजूद है. उदाहरण के लिए, Flask और Cloud की क्लाइंट लाइब्रेरी को अभी-अभी requirements.txt में जोड़ा गया है:
BEFORE:
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
हालांकि, सिर्फ़ इस कोड से, अभी-अभी जोड़ी गई बिल्ट-इन लाइब्रेरी (setuptools, grpcio) काम नहीं करेंगी. इसके लिए, कुछ और लाइनें जोड़नी होंगी. इसलिए, appengine_config.py को अपडेट करें, ताकि यह इस तरह दिखे:
AFTER:
import pkg_resources
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
# Add libraries to pkg_resources working set to find the distribution.
pkg_resources.working_set.add_entry(PATH)
Cloud क्लाइंट लाइब्रेरी के साथ काम करने के लिए, ज़रूरी बदलावों के बारे में ज़्यादा जानकारी बंडल की गई सेवाओं को माइग्रेट करने से जुड़े दस्तावेज़ में मिल सकती है.
कॉन्फ़िगरेशन से जुड़े अन्य अपडेट
अगर आपके पास lib फ़ोल्डर है, तो उसे मिटाएं. अगर Python 2 का इस्तेमाल किया जा रहा है, तो lib फ़ोल्डर को फिर से भरने के लिए, यह निर्देश दें:
pip install -t lib -r requirements.txt # or pip2
अगर आपके डेवलपमेंट सिस्टम पर Python 2 और 3, दोनों इंस्टॉल हैं, तो आपको pip के बजाय pip2 का इस्तेमाल करना पड़ सकता है.
6. ऐप्लिकेशन कोड में बदलाव करना
इस सेक्शन में, मुख्य ऐप्लिकेशन फ़ाइल main.py के अपडेट के बारे में बताया गया है. इसमें App Engine Task Queue की पुल कतारों की जगह Cloud Pub/Sub का इस्तेमाल किया गया है. वेब टेंप्लेट, templates/index.html में कोई बदलाव नहीं किया गया है. दोनों ऐप्लिकेशन एक जैसे होने चाहिए और उनमें एक जैसा डेटा दिखना चाहिए.
इंपोर्ट और इनिशियलाइज़ेशन को अपडेट करना
इंपोर्ट और इनिशियलाइज़ेशन से जुड़े कई अपडेट किए गए हैं:
- इंपोर्ट के लिए, App Engine NDB और Task Queue को Cloud NDB और Pub/Sub से बदलें.
pullqका नाम बदलकरQUEUEसेTOPICकर दिया गया है.- पुल टास्क में, वर्कर ने उन्हें एक घंटे के लिए लीज़ पर लिया था. हालांकि, Pub/Sub में टाइमआउट को हर मैसेज के हिसाब से मापा जाता है. इसलिए,
HOURकॉन्स्टेंट को मिटा दें. - Cloud API के लिए, एपीआई क्लाइंट का इस्तेमाल करना ज़रूरी है. इसलिए, Cloud NDB और Cloud Pub/Sub के लिए इन्हें शुरू करें. Cloud Pub/Sub, विषयों और सदस्यताओं, दोनों के लिए क्लाइंट उपलब्ध कराता है.
- Pub/Sub के लिए Cloud प्रोजेक्ट आईडी की ज़रूरत होती है. इसलिए, इसे
google.auth.default()से इंपोर्ट करें और पाएं. - Pub/Sub को विषयों और सदस्यताओं के लिए "पूरी तरह से क्वालिफ़ाइड पाथनेम" की ज़रूरत होती है. इसलिए,
*_path()सुविधा फ़ंक्शन का इस्तेमाल करके उन्हें बनाएं.
यहां मॉड्यूल 18 से इंपोर्ट और इनिशियलाइज़ेशन के बारे में बताया गया है. इसके बाद, ऊपर दिए गए बदलावों को लागू करने के बाद सेक्शन कैसे दिखने चाहिए, इसके बारे में बताया गया है. इसमें ज़्यादातर नया कोड, अलग-अलग Pub/Sub संसाधन हैं:
BEFORE:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
AFTER:
from flask import Flask, render_template, request
import google.auth
from google.cloud import ndb, pubsub
LIMIT = 10
TASKS = 1000
TOPIC = 'pullq'
SBSCR = 'worker'
app = Flask(__name__)
ds_client = ndb.Client()
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
_, PROJECT_ID = google.auth.default()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
डेटा मॉडल के अपडेट के बारे में जानकारी देने वाले पेज पर जाएं
Visit डेटा मॉडल में कोई बदलाव नहीं होता. Datastore को ऐक्सेस करने के लिए, Cloud NDB API क्लाइंट कॉन्टेक्स्ट मैनेजर, ds_client.context() का इस्तेमाल करना ज़रूरी है. कोड में इसका मतलब है कि आपको Python with ब्लॉक में, Datastore कॉल को store_visit() और fetch_visits(), दोनों में रैप करना होगा. यह अपडेट, मॉड्यूल 2 में शामिल जानकारी के जैसा ही है.
Pub/Sub के लिए सबसे ज़रूरी बदलाव यह है कि Task Queue के पुल टास्क को कतार में लगाने के बजाय, Pub/Sub मैसेज को pullq विषय पर पब्लिश किया जाए. यहां इन अपडेट से पहले और बाद का कोड दिया गया है:
BEFORE:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
AFTER:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
with ds_client.context():
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
ppc_client.publish(TOP_PATH, remote_addr.encode('utf-8'))
def fetch_visits(limit):
'get most recent visits'
with ds_client.context():
return Visit.query().order(-Visit.timestamp).fetch(limit)
VisitorCount डेटा मॉडल से जुड़े अपडेट
VisitorCount डेटा मॉडल में कोई बदलाव नहीं होता है. साथ ही, इसमें fetch_counts() होता है. हालांकि, इसकी Datastore क्वेरी को with ब्लॉक में रैप किया जाता है. इसके बारे में यहां बताया गया है:
BEFORE:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
AFTER:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
with ds_client.context():
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
वर्कर कोड अपडेट करना
वर्कर कोड को अपडेट किया गया है. इसमें NDB की जगह Cloud NDB और Task Queue की जगह Pub/Sub का इस्तेमाल किया गया है. हालांकि, इसके काम करने का तरीका पहले जैसा ही है.
- Datastore कॉल को Cloud NDB कॉन्टेक्स्ट मैनेजर
withब्लॉक में रैप करें. - टास्क क्यू को क्लीन अप करने का मतलब है कि पुल क्यू से सभी टास्क मिटा दिए गए हैं. Pub/Sub की मदद से, "पुष्टि करने वाले आईडी" को
acksमें इकट्ठा किया जाता है. इसके बाद, इन्हें मिटा दिया जाता है या इनकी पुष्टि कर दी जाती है. - Task Queue के पुल टास्क को उसी तरह से लीज़ किया जाता है जिस तरह Pub/Sub के मैसेज को पुल किया जाता है. पुल टास्क को टास्क ऑब्जेक्ट की मदद से मिटाया जाता है. वहीं, Pub/Sub मैसेज को उनके एकनॉलेजमेंट आईडी की मदद से मिटाया जाता है.
- Pub/Sub मैसेज पेलोड के लिए बाइट (Python स्ट्रिंग नहीं) की ज़रूरत होती है. इसलिए, किसी विषय पर मैसेज पब्लिश करते समय और उससे मैसेज खींचते समय, UTF-8 एन्कोडिंग और डिकोडिंग होती है.
log_visitors() की जगह, नीचे दिया गया अपडेट किया गया कोड डालें. इसमें ऊपर बताए गए बदलाव लागू किए गए हैं:
BEFORE:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
AFTER:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
acks = set()
rsp = psc_client.pull(subscription=SUB_PATH, max_messages=TASKS)
msgs = rsp.received_messages
for rcvd_msg in msgs:
acks.add(rcvd_msg.ack_id)
visitor = rcvd_msg.message.data.decode('utf-8')
tallies[visitor] = tallies.get(visitor, 0) + 1
if acks:
psc_client.acknowledge(subscription=SUB_PATH, ack_ids=acks)
try:
psc_client.close()
except AttributeError: # special handler for grpcio<1.12.0
pass
# increment those counts in Datastore and return
if tallies:
with ds_client.context():
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(msgs), len(tallies))
मुख्य ऐप्लिकेशन हैंडलर root() में कोई बदलाव नहीं किया गया है. एचटीएमएल टेंप्लेट फ़ाइल, templates/index.html में भी कोई बदलाव करने की ज़रूरत नहीं है. इसलिए, इसमें सभी ज़रूरी अपडेट शामिल हैं. Cloud Pub/Sub का इस्तेमाल करके, Module 19 के नए ऐप्लिकेशन पर पहुंचने के लिए बधाई!
7. खास जानकारी/सफ़ाई
अपने ऐप्लिकेशन को डिप्लॉय करें, ताकि यह पुष्टि की जा सके कि वह ठीक से काम कर रहा है और उससे मिलने वाला आउटपुट सही है. साथ ही, विज़िटर की संख्या को प्रोसेस करने के लिए वर्कर को चलाएं. ऐप्लिकेशन की पुष्टि होने के बाद, क्लीन-अप से जुड़े सभी चरण पूरे करें और आगे की कार्रवाई करें.
ऐप्लिकेशन डिप्लॉय करना और उसकी पुष्टि करना
पक्का करें कि आपने pullq विषय और worker सदस्यता पहले ही बना ली हो. अगर आपने यह प्रोसेस पूरी कर ली है और आपका सैंपल ऐप्लिकेशन इस्तेमाल के लिए तैयार है, तो gcloud app deploy की मदद से अपना ऐप्लिकेशन डिप्लॉय करें. आउटपुट, Module 18 ऐप्लिकेशन के आउटपुट जैसा ही होना चाहिए. हालांकि, इसमें आपने क्यूइंग के पूरे तरीके को बदल दिया है:
ऐप्लिकेशन का वेब फ़्रंटएंड अब पुष्टि करता है कि ऐप्लिकेशन का यह हिस्सा काम करता है. ऐप्लिकेशन का यह हिस्सा, सबसे ज़्यादा बार आने वाले लोगों और हाल ही में आने वाले लोगों के बारे में क्वेरी करता है और उन्हें दिखाता है. हालांकि, ऐप्लिकेशन इस विज़िट को रजिस्टर करता है. साथ ही, इस विज़िटर को कुल संख्या में जोड़ने के लिए, पुल टास्क बनाता है. यह टास्क अब प्रोसेस होने के लिए इंतज़ार कर रहा है.
इसे App Engine की बैकएंड सेवा, cron जॉब, /log पर जाकर या कमांड-लाइन एचटीटीपी अनुरोध जारी करके लागू किया जा सकता है. यहां curl का इस्तेमाल करके वर्कर कोड को कॉल करने का एक सैंपल एक्ज़ीक्यूशन और आउट दिया गया है (अपनी PROJECT_ID डालें):
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
इसके बाद, अपडेट की गई संख्या वेबसाइट पर अगली बार आने पर दिखेगी. हो गया!
व्यवस्थित करें
सामान्य
अगर आपको अभी और काम नहीं करना है, तो हमारा सुझाव है कि आप अपने App Engine ऐप्लिकेशन को बंद कर दें, ताकि आपसे शुल्क न लिया जाए. हालांकि, अगर आपको कुछ और टेस्ट या एक्सपेरिमेंट करने हैं, तो App Engine प्लैटफ़ॉर्म पर मुफ़्त कोटा उपलब्ध है. इसलिए, जब तक आप इस्तेमाल की उस सीमा से ज़्यादा नहीं होते हैं, तब तक आपसे कोई शुल्क नहीं लिया जाएगा. यह शुल्क कंप्यूट के लिए है. हालांकि, App Engine की सेवाओं के लिए भी शुल्क लिया जा सकता है. इसलिए, ज़्यादा जानकारी के लिए कीमत वाला पेज देखें. अगर इस माइग्रेशन में अन्य क्लाउड सेवाएं शामिल हैं, तो उनके लिए अलग से बिल भेजा जाता है. अगर लागू हो, तो दोनों ही मामलों में, नीचे दिया गया "इस कोडलैब के लिए खास जानकारी" सेक्शन देखें.
पूरी जानकारी के लिए बता दें कि App Engine जैसे Google Cloud के सर्वरलेस कंप्यूट प्लैटफ़ॉर्म पर डिप्लॉय करने से, बिल्ड और स्टोरेज के लिए मामूली शुल्क लगता है. Cloud Build का अपना मुफ़्त कोटा होता है. साथ ही, Cloud Storage का भी अपना मुफ़्त कोटा होता है. उस इमेज को सेव करने के लिए, स्टोरेज कोटा का कुछ हिस्सा इस्तेमाल किया जाता है. हालांकि, ऐसा हो सकता है कि आपके देश/इलाके में बिना किसी शुल्क के स्टोरेज इस्तेमाल करने की सुविधा उपलब्ध न हो. इसलिए, स्टोरेज के इस्तेमाल पर नज़र रखें, ताकि संभावित लागत को कम किया जा सके. Cloud Storage के कुछ "फ़ोल्डर" की समीक्षा करनी चाहिए. इनमें ये शामिल हैं:
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- ऊपर दिए गए स्टोरेज लिंक, आपके
PROJECT_IDऔर *LOC*ation पर निर्भर करते हैं. उदाहरण के लिए, अगर आपका ऐप्लिकेशन अमेरिका में होस्ट किया गया है, तो "us" दिखेगा.
दूसरी ओर, अगर आपको इस ऐप्लिकेशन या माइग्रेशन से जुड़े अन्य कोडलैब का इस्तेमाल नहीं करना है और आपको सब कुछ पूरी तरह से मिटाना है, तो अपना प्रोजेक्ट बंद करें.
इस कोडलैब के लिए खास तौर पर
यहां दी गई सेवाएं, इस कोड सीखने की लैब के लिए खास तौर पर बनाई गई हैं. ज़्यादा जानकारी के लिए, हर प्रॉडक्ट का दस्तावेज़ देखें:
- Cloud Pub/Sub के अलग-अलग कॉम्पोनेंट के लिए, बिना किसी शुल्क के इस्तेमाल किया जा सकने वाला टियर उपलब्ध है. इसके इस्तेमाल से जुड़े शुल्क के बारे में बेहतर तरीके से जानने के लिए, इसके इस्तेमाल की कुल लागत का पता लगाएं. ज़्यादा जानकारी के लिए, इसका कीमत वाला पेज देखें.
- App Engine Datastore सेवा, Cloud Datastore (Cloud Firestore in Datastore mode) से मिलती है. इसमें भी बिना शुल्क वाली सेवा उपलब्ध है. ज़्यादा जानकारी के लिए, इसका कीमत वाला पेज देखें.
अगले चरण
इस ट्यूटोरियल के अलावा, माइग्रेशन के अन्य मॉड्यूल भी उपलब्ध हैं. इनमें लेगसी बंडल की गई सेवाओं से माइग्रेट करने पर फ़ोकस किया गया है. इनमें ये शामिल हैं:
- मॉड्यूल 2: App Engine
ndbसे Cloud NDB पर माइग्रेट करना - मॉड्यूल 7-9: App Engine Task Queue (पुश टास्क) से Cloud Tasks पर माइग्रेट करना
- मॉड्यूल 12-13: App Engine Memcache से Cloud Memorystore पर माइग्रेट करना
- मॉड्यूल 15-16: App Engine Blobstore से Cloud Storage पर माइग्रेट करना
App Engine अब Google Cloud में सर्वरलेस प्लैटफ़ॉर्म नहीं है. अगर आपके पास कोई छोटा App Engine ऐप्लिकेशन है या ऐसा ऐप्लिकेशन है जिसमें सीमित सुविधाएं हैं और आपको उसे स्टैंडअलोन माइक्रोसेवा में बदलना है या आपको किसी मोनोलिथिक ऐप्लिकेशन को फिर से इस्तेमाल किए जा सकने वाले कई कॉम्पोनेंट में बांटना है, तो Cloud Functions पर माइग्रेट करने के लिए ये अच्छी वजहें हैं. अगर कंटेनर बनाने की प्रोसेस, ऐप्लिकेशन डेवलपमेंट वर्कफ़्लो का हिस्सा बन गई है, तो Cloud Run पर माइग्रेट करें. खास तौर पर, अगर इसमें सीआई/सीडी (लगातार इंटिग्रेशन/लगातार डिलीवरी या डिप्लॉयमेंट) पाइपलाइन शामिल है. इन स्थितियों के बारे में यहां दिए गए मॉड्यूल में बताया गया है:
- App Engine से Cloud Functions पर माइग्रेट करना: मॉड्यूल 11 देखें
- App Engine से Cloud Run पर माइग्रेट करना: Docker की मदद से अपने ऐप्लिकेशन को कंटेनर में बदलने के लिए, मॉड्यूल 4 देखें. इसके अलावा, कंटेनर, Docker की जानकारी या
Dockerfileके बिना ऐसा करने के लिए, मॉड्यूल 5 देखें
किसी दूसरे सर्वरलेस प्लैटफ़ॉर्म पर स्विच करना ज़रूरी नहीं है. हमारा सुझाव है कि कोई भी बदलाव करने से पहले, अपने ऐप्लिकेशन और इस्तेमाल के उदाहरणों के लिए सबसे सही विकल्पों पर विचार करें.
अगले माइग्रेशन मॉड्यूल के तौर पर किसी भी मॉड्यूल को चुना जा सकता है. हालांकि, Serverless Migration Station का पूरा कॉन्टेंट (कोड लैब, वीडियो, सोर्स कोड [अगर उपलब्ध हो]) इसके ओपन सोर्स रेपो में ऐक्सेस किया जा सकता है. रेपो के README में यह भी बताया गया है कि किन माइग्रेशन पर विचार करना चाहिए. साथ ही, माइग्रेशन मॉड्यूल के "क्रम" के बारे में भी बताया गया है.
8. अन्य संसाधन
यहां डेवलपर के लिए कुछ और संसाधन दिए गए हैं. इनकी मदद से, डेवलपर इस या इससे मिलते-जुलते माइग्रेशन मॉड्यूल के साथ-साथ इससे जुड़े प्रॉडक्ट के बारे में ज़्यादा जान सकते हैं. इसमें इस कॉन्टेंट पर सुझाव/राय देने या शिकायत करने की जगह, कोड के लिंक, और कई तरह के दस्तावेज़ शामिल हैं, जो आपके काम आ सकते हैं.
कोडलैब से जुड़ी समस्याएं/सुझाव/राय
अगर आपको इस कोडलैब में कोई समस्या मिलती है, तो कृपया शिकायत दर्ज करने से पहले अपनी समस्या खोजें. नई समस्याएं खोजने और बनाने के लिए लिंक:
माइग्रेशन के लिए उपलब्ध संसाधन
मॉड्यूल 18 (START) और मॉड्यूल 19 (FINISH) के लिए, repo फ़ोल्डर के लिंक यहां दी गई टेबल में मिलेंगे.
कोडलैब | Python 2 | Python 3 |
(लागू नहीं) | ||
मॉड्यूल 19 (यह कोडलैब) | (Python 2 की तरह ही, app3.yaml का इस्तेमाल करें. हालांकि, अगर आपने ऊपर बताए गए तरीके से app.yaml को अपडेट किया है, तो इसका इस्तेमाल न करें) |
ऑनलाइन रेफ़रंस
इस ट्यूटोरियल के लिए काम के संसाधन यहां दिए गए हैं:
App Engine टास्क क्यू
- App Engine की टास्क क्यू सेवा के बारे में खास जानकारी
- App Engine की टास्क क्यू में मौजूद पुल क्यू के बारे में खास जानकारी
- App Engine टास्क क्यू की पुल क्यू का पूरा सैंपल ऐप्लिकेशन
- Task Queue की पुल कतारें बनाना
- Google I/O 2011 में लॉन्च किए गए पुल क्यू का वीडियो ( Votelator का सैंपल ऐप्लिकेशन)
queue.yamlरेफ़रंसqueue.yamlबनाम Cloud Tasks- पुल क्यू से Pub/Sub पर माइग्रेट करने से जुड़ी गाइड
Cloud Pub/Sub
- Cloud Pub/Sub का प्रॉडक्ट पेज
- Pub/Sub क्लाइंट लाइब्रेरी का इस्तेमाल करना
- Pub/Sub की Python क्लाइंट लाइब्रेरी के सैंपल
- Pub/Sub Python क्लाइंट लाइब्रेरी के बारे में दस्तावेज़
- Pub/Sub विषयों को बनाना और मैनेज करना
- Pub/Sub विषय का नाम रखने से जुड़े दिशा-निर्देश
- Pub/Sub की सदस्यताएं बनाना और उन्हें मैनेज करना
- App Engine (फ़्लेक्सिबल) का सैंपल ऐप्लिकेशन (इसे स्टैंडर्ड एनवायरमेंट में भी डिप्लॉय किया जा सकता है; Python 3)
- ऊपर दिए गए सैंपल ऐप्लिकेशन के लिए रेपो
- Pub/Sub पुल सदस्यताएं
- Pub/Sub पुश सदस्यताएं
- App Engine Pub/Sub पुश सैंपल ऐप्लिकेशन (Python 3)
- App Engine Pub/Sub पुश सैंपल ऐप्लिकेशन रिपो
- Pub/Sub की कीमत के बारे में जानकारी
- Cloud Tasks या Cloud Pub/Sub? (पुश बनाम पुल)
App Engine NDB और Cloud NDB (Datastore)
- App Engine NDB के दस्तावेज़
- App Engine NDB repo
- Google Cloud NDB के दस्तावेज़
- Google Cloud NDB repo
- Cloud Datastore की कीमत के बारे में जानकारी
App Engine प्लैटफ़ॉर्म
- App Engine के दस्तावेज़
- Python 2 App Engine (स्टैंडर्ड एनवायरमेंट) रनटाइम
- Python 2 App Engine पर App Engine की पहले से मौजूद लाइब्रेरी का इस्तेमाल करना
- Python 3 App Engine (स्टैंडर्ड एनवायरमेंट) रनटाइम
- App Engine के स्टैंडर्ड एनवायरमेंट के Python 2 और Python 3 रनटाइम के बीच अंतर
- Python 2 से 3 App Engine (स्टैंडर्ड एनवायरमेंट) में माइग्रेट करने से जुड़ी गाइड
- App Engine की कीमत और कोटे की जानकारी
- App Engine प्लैटफ़ॉर्म की दूसरी जनरेशन लॉन्च की गई (2018)
- पहली और दूसरी जनरेशन के प्लैटफ़ॉर्म की तुलना करना
- लेगसी रनटाइम के लिए लंबे समय तक सहायता
- दस्तावेज़ माइग्रेट करने के उदाहरण
- कम्यूनिटी के योगदान से तैयार किए गए माइग्रेशन के सैंपल
क्लाउड से जुड़ी अन्य जानकारी
- Google Cloud Platform पर Python
- Google Cloud की Python क्लाइंट लाइब्रेरी
- Google Cloud का "हमेशा के लिए बिना शुल्क" वाला टियर
- Google Cloud SDK (
gcloudकमांड-लाइन टूल) - Google Cloud के सभी दस्तावेज़
वीडियो
- Serverless Migration Station
- Serverless Expeditions
- Google Cloud Tech की सदस्यता लें
- Google Developers की सदस्यता लें
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.