
1. مقدمة
يركّز هذا الدرس العملي على النموذج اللغوي الكبير Gemini (LLM)، المستضاف على Vertex AI على Google Cloud. Vertex AI هي منصة تشمل جميع منتجات وخدمات ونماذج تعلُّم الآلة على Google Cloud.
ستستخدم Java للتفاعل مع Gemini API باستخدام إطار عمل LangChain4j. ستتعرّف على أمثلة عملية للاستفادة من النموذج اللغوي الكبير في الإجابة عن الأسئلة، وإنشاء الأفكار، واستخراج الكيانات والمحتوى المنظَّم، والتوليد المعزّز بالاسترجاع، واستدعاء الدوال.
ما هو الذكاء الاصطناعي التوليدي؟
يشير الذكاء الاصطناعي التوليدي إلى استخدام الذكاء الاصطناعي لإنشاء محتوى جديد، مثل النصوص والصور والموسيقى والملفات الصوتية والفيديوهات.
يستند الذكاء الاصطناعي التوليدي إلى نماذج لغوية كبيرة (LLM) يمكنها تنفيذ مهام متعددة ومهام جاهزة للاستخدام، مثل التلخيص وطرح الأسئلة والإجابة عنها والتصنيف وغير ذلك. وبأقل قدر من التدريب، يمكن تكييف النماذج الأساسية مع حالات استخدام محدّدة باستخدام قدر ضئيل جدًا من بيانات الأمثلة.
كيف يعمل الذكاء الاصطناعي التوليدي؟
يعمل الذكاء الاصطناعي التوليدي من خلال استخدام نموذج تعلُّم الآلة (ML) للتعرّف على الأنماط والعلاقات في مجموعة بيانات من المحتوى الذي أنشأه الإنسان. ثم يستخدم الأنماط التي تعلّمها لإنشاء محتوى جديد.
الطريقة الأكثر شيوعًا لتدريب نموذج ذكاء اصطناعي توليدي هي استخدام التعلُّم الموجَّه. يتم تزويد النموذج بمجموعة من المحتوى الذي ينشئه المستخدمون والتصنيفات المقابلة. بعد ذلك، يتعلّم كيفية إنشاء محتوى مشابه للمحتوى الذي ينشئه المستخدمون.
ما هي التطبيقات الشائعة للذكاء الاصطناعي التوليدي؟
يمكن استخدام الذكاء الاصطناعي التوليدي في ما يلي:
- تحسين تفاعلات العملاء من خلال تجارب محسّنة في المحادثة والبحث
- استكشاف كميات هائلة من البيانات غير المنظَّمة من خلال واجهات محادثة وملخّصات
- المساعدة في المهام المتكررة، مثل الرد على طلبات عروض الأسعار، وأقلمة المحتوى التسويقي بلغات مختلفة، والتحقّق من امتثال عقود العملاء، وغير ذلك
ما هي عروض الذكاء الاصطناعي التوليدي التي تقدّمها Google Cloud؟
باستخدام Vertex AI، يمكنك التفاعل مع النماذج الأساسية وتخصيصها وتضمينها في تطبيقاتك بدون الحاجة إلى خبرة كبيرة في تعلُّم الآلة. يمكنك الوصول إلى النماذج الأساسية على Model Garden، أو ضبط النماذج من خلال واجهة مستخدم بسيطة على Vertex AI Studio، أو استخدام النماذج في دفتر ملاحظات لعلوم البيانات.
توفّر Vertex AI Search and Conversation للمطوّرين أسرع طريقة لإنشاء محركات بحث وبرامج دردشة تستند إلى الذكاء الاصطناعي التوليدي.
Gemini في Google Cloud هو أداة تعاونية مستندة إلى الذكاء الاصطناعي ومتاحة على Google Cloud وبيئات التطوير المتكاملة لمساعدتك في إنجاز المزيد من المهام بشكل أسرع. يوفّر Gemini Code Assist ميزة إكمال الرموز البرمجية وإنشائها وشرحها، كما يتيح لك الدردشة معه لطرح أسئلة فنية.
ما هو Gemini؟
Gemini هي مجموعة من نماذج الذكاء الاصطناعي التوليدي من تطوير Google DeepMind، وهي مصمَّمة لحالات الاستخدام المتعدّدة الوسائط. تعني عبارة "متعدّد الوسائط" أنّه يمكنه معالجة أنواع مختلفة من المحتوى وإنشائها، مثل النصوص والرموز البرمجية والصور والمقاطع الصوتية.

يتوفّر Gemini بأشكال وأحجام مختلفة:
- Gemini 2.0 Flash: أحدث ميزات الجيل التالي وإمكانات محسّنة
- Gemini 2.0 Flash-Lite: هو نموذج Gemini 2.0 Flash محسَّن لتحقيق فعالية التكلفة وتقليل وقت الاستجابة.
- Gemini 2.5 Pro: نموذج الاستدلال الأكثر تطورًا لدينا حتى الآن.
- Gemini 2.5 Flash: نموذج مفكّر يقدّم إمكانات شاملة. تم تصميمها لتحقيق التوازن بين السعر والأداء.
الميزات الأساسية:
- تعدّد الوسائط: إنّ قدرة Gemini على فهم أنواع متعددة من المعلومات والتعامل معها هي خطوة مهمة تتجاوز نماذج اللغة التقليدية التي تعتمد على النصوص فقط.
- الأداء: يتفوّق Gemini 2.5 Pro على أحدث النماذج الحالية في العديد من مقاييس الأداء، وكان أول نموذج يتفوّق على الخبراء البشريين في مقياس الأداء الصعب MMLU (فهم اللغة للمهام المتعددة الضخمة).
- المرونة: تتيح أحجام Gemini المختلفة إمكانية التكيّف مع حالات الاستخدام المتنوعة، بدءًا من الأبحاث الواسعة النطاق ووصولاً إلى عمليات النشر على الأجهزة الجوّالة.
كيف يمكن التفاعل مع Gemini في Vertex AI من Java؟
أمامك خياران:
- مكتبة Vertex AI Java API for Gemini الرسمية
- إطار عمل LangChain4j
في هذا الدرس التطبيقي حول الترميز، ستستخدم إطار عمل LangChain4j.
ما هو إطار عمل LangChain4j؟
إطار عمل LangChain4j هو مكتبة مفتوحة المصدر لدمج النماذج اللغوية الكبيرة في تطبيقات Java، وذلك من خلال تنسيق المكوّنات المختلفة، مثل النموذج اللغوي الكبير نفسه، بالإضافة إلى أدوات أخرى مثل قواعد بيانات المتّجهات (لعمليات البحث الدلالي) وأدوات تحميل المستندات وتقسيمها (لتحليل المستندات والتعلم منها) وأدوات تحليل النتائج وغير ذلك.
استوحينا فكرة المشروع من مشروع LangChain بلغة Python، ولكن كان هدفنا توفير خدمة لمطوّري Java.

ما ستتعلمه
- كيفية إعداد مشروع Java لاستخدام Gemini وLangChain4j
- كيفية إرسال طلبك الأول إلى Gemini آليًا
- كيفية عرض الردود تدريجيًا من Gemini
- كيفية إنشاء محادثة بين مستخدم وGemini
- كيفية استخدام Gemini في سياق متعدد الوسائط من خلال إرسال نص وصور
- كيفية استخراج معلومات منظَّمة مفيدة من محتوى غير منظَّم
- كيفية تعديل نماذج الطلبات
- كيفية تصنيف النصوص، مثل تحليل المشاعر
- كيفية الدردشة مع مستنداتك (الجيل المعزّز للاسترجاع)
- كيفية توسيع نطاق عمل برامج الدردشة الآلية باستخدام ميزة "استدعاء الدوال"
- كيفية استخدام Gemma محليًا مع Ollama وTestContainers
المتطلبات
- معرفة بلغة البرمجة Java
- مشروع على السحابة الإلكترونية من Google
- متصفّح، مثل Chrome أو Firefox
2. الإعداد والمتطلبات
إعداد البيئة بالسرعة التي تناسبك
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.



- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديلها في أي وقت.
- رقم تعريف المشروع هو معرّف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره بعد ضبطه. تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك (يُشار إليه عادةً باسم
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم مستخدم من اختيارك ومعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير، إن وُجدت أي تكلفة على الإطلاق. لإيقاف الموارد وتجنُّب تحمّل تكاليف تتجاوز هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس العملي Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
تفعيل Cloud Shell
- من Cloud Console، انقر على تفعيل Cloud Shell
 .
.

إذا كانت هذه هي المرة الأولى التي تبدأ فيها Cloud Shell، ستظهر لك شاشة وسيطة توضّح ماهية هذه الخدمة. إذا ظهرت لك شاشة وسيطة، انقر على متابعة.

يستغرق توفير Cloud Shell والاتصال به بضع لحظات فقط.

يتم تحميل هذا الجهاز الافتراضي بجميع أدوات التطوير اللازمة. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إنجاز معظم عملك في هذا الدرس التطبيقي حول الترميز، إن لم يكن كله، باستخدام متصفح.
بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تم إثبات هويتك وأنّه تم ضبط المشروع على رقم تعريف مشروعك.
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من إكمال عملية المصادقة:
gcloud auth list
ناتج الأمر
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك:
gcloud config list project
ناتج الأمر
[core] project = <PROJECT_ID>
إذا لم يكن كذلك، يمكنك تعيينه من خلال هذا الأمر:
gcloud config set project <PROJECT_ID>
ناتج الأمر
Updated property [core/project].
3- إعداد بيئة التطوير
في هذا الدرس التطبيقي حول الترميز، ستستخدم وحدة Cloud Shell الطرفية ومحرّر Cloud Shell لتطوير برامج Java.
تفعيل واجهات برمجة التطبيقات في Vertex AI
في Google Cloud Console، تأكَّد من ظهور اسم مشروعك في أعلى Google Cloud Console. إذا لم يكن كذلك، انقر على اختيار مشروع لفتح أداة اختيار المشاريع، ثم اختَر المشروع المطلوب.
يمكنك تفعيل واجهات برمجة تطبيقات Vertex AI من قسم Vertex AI في Google Cloud Console أو من نافذة Cloud Shell.
للتفعيل من وحدة تحكّم Google Cloud، انتقِل أولاً إلى قسم Vertex AI في قائمة وحدة تحكّم Google Cloud:

انقر على تفعيل جميع واجهات برمجة التطبيقات المقترَحة في لوحة بيانات Vertex AI.
سيؤدي ذلك إلى تفعيل العديد من واجهات برمجة التطبيقات، ولكنّ أهمها في هذا الدرس التطبيقي هي aiplatform.googleapis.com.
يمكنك بدلاً من ذلك تفعيل واجهة برمجة التطبيقات هذه من وحدة Cloud Shell الطرفية باستخدام الأمر التالي:
gcloud services enable aiplatform.googleapis.com
استنساخ مستودع Github
في نافذة Cloud Shell الطرفية، استنسِخ مستودع هذا الدرس التطبيقي حول الترميز:
git clone https://github.com/glaforge/gemini-workshop-for-java-developers.git
للتأكّد من أنّ المشروع جاهز للتنفيذ، يمكنك محاولة تشغيل برنامج "Hello World".
تأكَّد من أنّك في مجلد المستوى الأعلى:
cd gemini-workshop-for-java-developers/
أنشئ برنامج Gradle المغلّف:
gradle wrapper
تشغيل gradlew:
./gradlew run
من المفترض أن يظهر لك الناتج التالي:
.. > Task :app:run Hello World!
فتح "محرّر السحابة الإلكترونية" وإعداده
افتح الرمز باستخدام محرِّر Cloud Code من Cloud Shell:

في "محرّر Cloud Code"، افتح مجلد مصدر الدرس التطبيقي حول الترميز من خلال النقر على File -> Open Folder والإشارة إلى مجلد مصدر الدرس التطبيقي حول الترميز (مثل /home/username/gemini-workshop-for-java-developers/).
إعداد متغيرات البيئة
افتح نافذة طرفية جديدة في "محرّر Cloud Code" من خلال النقر على Terminal -> New Terminal. اضبط متغيّرَي البيئة المطلوبَين لتشغيل أمثلة الرموز البرمجية:
- استبدِل PROJECT_ID برقم تعريف مشروعك على Google Cloud.
- استبدِل LOCATION بالمنطقة التي تم فيها نشر نموذج Gemini.
صدِّر المتغيّرات على النحو التالي:
export PROJECT_ID=$(gcloud config get-value project) export LOCATION=us-central1
4. أول طلب يتم إرساله إلى نموذج Gemini
بعد إعداد المشروع بشكل صحيح، حان الوقت لاستدعاء Gemini API.
ألقِ نظرة على QA.java في الدليل app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class QA {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
System.out.println(model.generate("Why is the sky blue?"));
}
}
في المثال الأول، عليك استيراد الفئة VertexAiGeminiChatModel التي تنفّذ الواجهة ChatModel.
في طريقة main، يمكنك ضبط نموذج اللغة الخاص بالمحادثة باستخدام أداة الإنشاء الخاصة بـ VertexAiGeminiChatModel وتحديد ما يلي:
- المشروع
- الموقع الجغرافي
- اسم الطراز (
gemini-2.0-flash)
بعد أن يصبح نموذج اللغة جاهزًا، يمكنك استدعاء طريقة generate() وتمرير طلبك أو سؤالك أو تعليماتك لإرسالها إلى النموذج اللغوي الكبير. في هذا المشهد، تطرح سؤالاً بسيطًا حول سبب ظهور السماء باللون الأزرق.
يمكنك تغيير هذا الطلب لتجربة أسئلة أو مهام مختلفة.
نفِّذ العيّنة في مجلد الجذر لرمز المصدر:
./gradlew run -q -DjavaMainClass=gemini.workshop.QA
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight enters the atmosphere, it is made up of a mixture of different wavelengths of light, each with a different color. The different wavelengths of light interact with the molecules and particles in the atmosphere in different ways. The shorter wavelengths of light, such as those corresponding to blue and violet light, are more likely to be scattered in all directions by these particles than the longer wavelengths of light, such as those corresponding to red and orange light. This is because the shorter wavelengths of light have a smaller wavelength and are able to bend around the particles more easily. As a result of Rayleigh scattering, the blue light from the sun is scattered in all directions, and it is this scattered blue light that we see when we look up at the sky. The blue light from the sun is not actually scattered in a single direction, so the color of the sky can vary depending on the position of the sun in the sky and the amount of dust and water droplets in the atmosphere.
تهانينا، لقد أجريت أول مكالمة لك مع Gemini.
عرض الرد تدريجيًا
هل لاحظت أنّ الردّ تم تقديمه دفعة واحدة بعد بضع ثوانٍ؟ يمكنك أيضًا الحصول على الردّ بشكل تدريجي، وذلك بفضل خيار الردّ المتدفّق. في الاستجابة المتدفقة، يعرض النموذج الاستجابة جزءًا جزءًا عند توفّرها.
في هذا الدرس التطبيقي، سنلتزم بالردّ غير المتدفّق، ولكن لنلقِ نظرة على الردّ المتدفّق لمعرفة كيفية تنفيذه.
في StreamQA.java في الدليل app/src/main/java/gemini/workshop، يمكنك الاطّلاع على الردود المتدفّقة أثناء عملها:
package gemini.workshop;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiStreamingChatModel;
import static dev.langchain4j.model.LambdaStreamingResponseHandler.onNext;
public class StreamQA {
public static void main(String[] args) {
StreamingChatLanguageModel model = VertexAiGeminiStreamingChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(4000)
.build();
model.generate("Why is the sky blue?", onNext(System.out::println));
}
}
في هذه المرة، نستورد متغيرات فئة البث VertexAiGeminiStreamingChatModel التي تنفّذ الواجهة StreamingChatLanguageModel. عليك أيضًا استيراد LambdaStreamingResponseHandler.onNext بشكل ثابت، وهي طريقة ملائمة توفّر StreamingResponseHandler لإنشاء معالج بث باستخدام تعابير لامدا في Java.
في هذه المرة، يختلف توقيع طريقة generate() قليلاً. بدلاً من عرض سلسلة، يكون نوع القيمة التي تم إرجاعها فارغًا. بالإضافة إلى الطلب، عليك تمرير معالج استجابة البث. هنا، وبفضل عملية الاستيراد الثابت التي ذكرناها أعلاه، يمكننا تحديد تعبير lambda الذي يمكنك تمريره إلى طريقة onNext(). يتم استدعاء تعبير lambda في كل مرة يتوفّر فيها جزء جديد من الرد، بينما لا يتم استدعاء الأخير إلا إذا حدث خطأ.
التشغيل:
./gradlew run -q -DjavaMainClass=gemini.workshop.StreamQA
ستحصل على إجابة مشابهة للصف السابق، ولكن هذه المرة، ستلاحظ أنّ الإجابة تظهر تدريجيًا في الصدفة، بدلاً من انتظار عرض الإجابة الكاملة.
إعدادات إضافية
بالنسبة إلى الإعداد، حدّدنا المشروع والموقع الجغرافي واسم النموذج فقط، ولكن هناك مَعلمات أخرى يمكنك تحديدها للنموذج:
temperature(Float temp): لتحديد مستوى الإبداع المطلوب في الردّ (0 يعني مستوى إبداع منخفضًا وغالبًا ما يكون الردّ أكثر واقعية، بينما 2 يعني مستوى إبداع أعلى)topP(Float topP): لاختيار الكلمات المحتملة التي يصل مجموع احتمالاتها إلى رقم النقطة العائمة هذا (بين 0 و1)topK(Integer topK): لاختيار كلمة عشوائية من بين عدد أقصى من الكلمات المحتملة لإكمال النص (من 1 إلى 40)maxOutputTokens(Integer max): لتحديد الحدّ الأقصى لطول الإجابة التي يقدّمها النموذج (بشكل عام، تمثّل 4 رموز مميزة حوالي 3 كلمات)maxRetries(Integer retries): في حال تجاوزت عدد الطلبات المسموح به في كل مرة أو إذا كانت المنصة تواجه بعض المشاكل الفنية، يمكنك أن تطلب من النموذج إعادة محاولة إجراء المكالمة 3 مرات.
حتى الآن، طرحت سؤالاً واحدًا على Gemini، ولكن يمكنك أيضًا إجراء محادثة متعدّدة الجولات. سنتعرّف على ذلك في القسم التالي.
5- تحدَّث إلى Gemini
في الخطوة السابقة، طرحت سؤالاً واحدًا. حان الوقت الآن لإجراء محادثة حقيقية بين المستخدم والنموذج اللغوي الكبير. يمكن أن يستند كل سؤال وجواب إلى ما سبقهما لتشكيل مناقشة حقيقية.
اطّلِع على Conversation.java في مجلد app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.service.AiServices;
import java.util.List;
public class Conversation {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
interface ConversationService {
String chat(String message);
}
ConversationService conversation =
AiServices.builder(ConversationService.class)
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
List.of(
"Hello!",
"What is the country where the Eiffel tower is situated?",
"How many inhabitants are there in that country?"
).forEach( message -> {
System.out.println("\nUser: " + message);
System.out.println("Gemini: " + conversation.chat(message));
});
}
}
في ما يلي بعض عمليات الاستيراد الجديدة والمثيرة للاهتمام في هذه الفئة:
MessageWindowChatMemory: فئة ستساعد في التعامل مع الجانب المتعدد الأدوار من المحادثة، والاحتفاظ بالأسئلة والأجوبة السابقة في الذاكرة المحلية-
AiServices: فئة تجريدية ذات مستوى أعلى ستربط نموذج الدردشة وذاكرة الدردشة
في الطريقة الرئيسية، ستعمل على إعداد النموذج وذاكرة المحادثة وخدمة الذكاء الاصطناعي. يتم ضبط النموذج كالمعتاد باستخدام معلومات المشروع والموقع الجغرافي واسم النموذج.
بالنسبة إلى ذاكرة المحادثة، نستخدم أداة إنشاء MessageWindowChatMemory لإنشاء ذاكرة تحتفظ بآخر 20 رسالة تم تبادلها. إنّها نافذة منزلقة فوق المحادثة يتم الاحتفاظ بسياقها محليًا في برنامج Java الخاص بالعميل.
بعد ذلك، يمكنك إنشاء AI service الذي يربط نموذج المحادثة بذاكرة المحادثة.
لاحظ كيف تستخدم خدمة الذكاء الاصطناعي واجهة ConversationService مخصّصة حدّدناها، وتنفّذها LangChain4j، وتتلقّى طلب بحث String وتعرض استجابة String.
حان الآن وقت إجراء محادثة مع Gemini. أولاً، يتم إرسال تحية بسيطة، ثم سؤال أول عن برج إيفل لمعرفة البلد الذي يقع فيه. لاحظ أنّ الجملة الأخيرة مرتبطة بإجابة السؤال الأول، إذ تتساءل عن عدد السكان في البلد الذي يقع فيه برج إيفل، بدون الإشارة صراحةً إلى البلد الذي تم ذكره في الإجابة السابقة. ويوضّح أنّ الأسئلة والأجوبة السابقة يتم إرسالها مع كل طلب.
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.Conversation
من المفترض أن تظهر لك ثلاث إجابات مشابهة لما يلي:
User: Hello! Gemini: Hi there! How can I assist you today? User: What is the country where the Eiffel tower is situated? Gemini: France User: How many inhabitants are there in that country? Gemini: As of 2023, the population of France is estimated to be around 67.8 million.
يمكنك طرح أسئلة تتضمّن ردًا واحدًا أو إجراء محادثات متعدّدة الأدوار مع Gemini، ولكن حتى الآن، كان الإدخال نصيًا فقط. ماذا عن الصور؟ لنستكشف الصور في الخطوة التالية.
6. إمكانات Gemini المتعدّدة الوسائط
Gemini هو نموذج متعدد الوسائط. لا يقبل هذا النموذج النصوص كمدخلات فحسب، بل يقبل أيضًا الصور أو حتى الفيديوهات كمدخلات. في هذا القسم، ستتعرّف على حالة استخدام لدمج النصوص والصور.
هل تعتقد أنّ Gemini سيتعرّف على هذه القطة؟

صورة لقطة في الثلج مأخوذة من ويكيبيديا
ألقِ نظرة على Multimodal.java في دليل app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.data.message.ImageContent;
import dev.langchain4j.data.message.TextContent;
public class Multimodal {
static final String CAT_IMAGE_URL =
"https://upload.wikimedia.org/wikipedia/" +
"commons/b/b6/Felis_catus-cat_on_snow.jpg";
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
UserMessage userMessage = UserMessage.from(
ImageContent.from(CAT_IMAGE_URL),
TextContent.from("Describe the picture")
);
Response<AiMessage> response = model.generate(userMessage);
System.out.println(response.content().text());
}
}
في عمليات الاستيراد، لاحظ أنّنا نميّز بين أنواع مختلفة من الرسائل والمحتوى. يمكن أن يحتوي UserMessage على كل من TextContent وImageContent. هذا هو التفاعل المتعدّد الوسائط: مزج النصوص والصور. لا نرسل فقط طلبًا بسيطًا على شكل سلسلة، بل نرسل عنصرًا أكثر تنظيمًا يمثّل رسالة مستخدم، ويتألف من جزء من محتوى الصورة وجزء من محتوى النص. يرسل النموذج Response الذي يحتوي على AiMessage.
بعد ذلك، يمكنك استرداد AiMessage من الردّ باستخدام content()، ثم استرداد نص الرسالة باستخدام text().
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.Multimodal
من المؤكد أنّ اسم الصورة قد أعطاك تلميحًا بشأن محتواها، ولكنّ الناتج الذي قدّمه Gemini يشبه ما يلي:
A cat with brown fur is walking in the snow. The cat has a white patch of fur on its chest and white paws. The cat is looking at the camera.
يؤدي الجمع بين الصور ومطالبات النصوص إلى فتح حالات استخدام مثيرة للاهتمام. يمكنك إنشاء تطبيقات يمكنها إجراء ما يلي:
- التعرّف على النص في الصور
- التحقّق مما إذا كانت الصورة آمنة للعرض
- إنشاء شرح للصور
- البحث في قاعدة بيانات للصور باستخدام أوصاف نصية عادية
بالإضافة إلى استخراج المعلومات من الصور، يمكنك أيضًا استخراج المعلومات من النصوص غير المنظَّمة. هذا ما ستتعرّف عليه في القسم التالي.
7. استخراج معلومات منظَّمة من نص غير منظَّم
هناك العديد من الحالات التي يتم فيها تقديم معلومات مهمة في مستندات التقارير أو الرسائل الإلكترونية أو النصوص الطويلة الأخرى بطريقة غير منظَّمة. من المفترض أن تتمكّن من استخراج التفاصيل الرئيسية الواردة في النص غير المنظَّم على شكل عناصر منظَّمة. لنطّلِع على كيفية إجراء ذلك.
لنفترض أنّك تريد استخراج اسم شخص وعمره من سيرة ذاتية أو وصف لهذا الشخص. يمكنك توجيه النموذج اللغوي الكبير لاستخراج JSON من نص غير منظَّم باستخدام طلب تم تعديله بذكاء (يُعرف هذا عادةً باسم "هندسة الطلبات").
ولكن في المثال أدناه، بدلاً من إنشاء طلب يصف ناتج JSON، سنستخدم ميزة قوية في Gemini تُسمى الناتج المنظَّم، أو الإنشاء المقيد أحيانًا، ما يجبر النموذج على إخراج محتوى JSON صالح فقط، باتّباع مخطط JSON محدّد.
إليك ExtractData.java في app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import static dev.langchain4j.model.vertexai.SchemaHelper.fromClass;
public class ExtractData {
record Person(String name, int age) { }
interface PersonExtractor {
@SystemMessage("""
Your role is to extract the name and age
of the person described in the biography.
""")
Person extractPerson(String biography);
}
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.responseMimeType("application/json")
.responseSchema(fromClass(Person.class))
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
String bio = """
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
""";
Person person = extractor.extractPerson(bio);
System.out.println(person.name()); // Anna
System.out.println(person.age()); // 23
}
}
لنلقِ نظرة على الخطوات المختلفة في هذا الملف:
- يتم تحديد سجلّ
Personلتمثيل التفاصيل التي تصف شخصًا (الاسم والعمر). - يتم تحديد واجهة
PersonExtractorباستخدام طريقة تعرض مثيلاً منPersonعند توفير سلسلة نصية غير منظَّمة. - تمت إضافة تعليق توضيحي
@SystemMessageإلىextractPerson()يربط طلبًا يتضمّن تعليمات به. هذا هو الطلب الذي سيستخدمه النموذج لتوجيه عملية استخراج المعلومات، وسيعرض التفاصيل في شكل مستند JSON سيتم تحليله لك وتحويله إلى مثيلPerson.
لنلقِ الآن نظرة على محتوى الطريقة main():
- تم ضبط نموذج المحادثة وإنشاؤه. نستخدم طريقتَين جديدتَين من فئة أداة إنشاء النماذج:
responseMimeType()وresponseSchema(). يطلب الأمر الأول من Gemini إنشاء JSON صالح في الناتج. تحدّد الطريقة الثانية مخطّط عنصر JSON الذي يجب عرضه. علاوةً على ذلك، يفوّض الأخير إلى طريقة ملائمة يمكنها تحويل فئة Java أو سجلّ إلى مخطّط JSON مناسب. - يتم إنشاء كائن
PersonExtractorبفضل فئةAiServicesفي LangChain4j. - بعد ذلك، يمكنك ببساطة استدعاء
Person person = extractor.extractPerson(...)لاستخراج تفاصيل الشخص من النص غير المنظَّم، والحصول على مثيلPersonيتضمّن الاسم والعمر.
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.ExtractData
من المفترض أن يظهر لك الناتج التالي:
Anna 23
نعم، أنا إيناس وعمري 23 عامًا.
باستخدام أسلوب AiServices هذا، يمكنك التعامل مع عناصر ذات أنواع محددة. أنت لا تتفاعل مباشرةً مع النموذج اللغوي الكبير. بدلاً من ذلك، أنت تعمل مع فئات ملموسة، مثل سجل Person لتمثيل المعلومات الشخصية المستخرجة، ولديك عنصر PersonExtractor مع طريقة extractPerson() تعرض مثيلاً Person. يتم إخفاء مفهوم النموذج اللغوي الكبير، وبصفتك مطوّر Java، ما عليك سوى التعامل مع الفئات والعناصر العادية عند استخدام واجهة PersonExtractor هذه.
8. تنظيم الطلبات باستخدام نماذج الطلبات
عند التفاعل مع نموذج لغوي كبير باستخدام مجموعة شائعة من التعليمات أو الأسئلة، هناك جزء من الطلب لا يتغيّر أبدًا، بينما تحتوي أجزاء أخرى على البيانات. على سبيل المثال، إذا أردت إنشاء وصفات طعام، يمكنك استخدام طلب مثل "أنت طاهٍ موهوب، يُرجى إنشاء وصفة طعام باستخدام المكوّنات التالية: ..."، ثم إضافة المكوّنات إلى نهاية هذا النص. هذا هو الغرض من نماذج الطلبات، وهي تشبه السلاسل المُدرَجة في لغات البرمجة. يحتوي نموذج الطلب على عناصر نائبة يمكنك استبدالها بالبيانات المناسبة لإجراء طلب معيّن إلى النموذج اللغوي الكبير.
بشكل أكثر تحديدًا، لنستعرض TemplatePrompt.java في الدليل app/src/main/java/gemini/workshop:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.output.Response;
import java.util.HashMap;
import java.util.Map;
public class TemplatePrompt {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(500)
.temperature(1.0f)
.topK(40)
.topP(0.95f)
.maxRetries(3)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
You're a friendly chef with a lot of cooking experience.
Create a recipe for a {{dish}} with the following ingredients: \
{{ingredients}}, and give it a name.
"""
);
Map<String, Object> variables = new HashMap<>();
variables.put("dish", "dessert");
variables.put("ingredients", "strawberries, chocolate, and whipped cream");
Prompt prompt = promptTemplate.apply(variables);
Response<AiMessage> response = model.generate(prompt.toUserMessage());
System.out.println(response.content().text());
}
}
كالعادة، يمكنك ضبط نموذج VertexAiGeminiChatModel، مع مستوى عالٍ من الإبداع باستخدام درجة عشوائية عالية، بالإضافة إلى قيم عالية لأعلى احتمال تراكمي وأعلى احتمال. بعد ذلك، يمكنك إنشاء PromptTemplate باستخدام الإجراء الثابت from()، وذلك من خلال تمرير سلسلة الطلب، واستخدام متغيّرات العنصر النائب بين علامتَي اقتباس مزدوجتَين: {{dish}} و{{ingredients}}.
يمكنك إنشاء الطلب النهائي من خلال استدعاء apply() الذي يأخذ خريطة لأزواج المفاتيح/القيم التي تمثّل اسم العنصر النائب وقيمة السلسلة التي سيتم استبدالها بها.
أخيرًا، يمكنك استدعاء طريقة generate() لنموذج Gemini من خلال إنشاء رسالة مستخدم من هذا الطلب، باستخدام التعليمات prompt.toUserMessage().
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.TemplatePrompt
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
**Strawberry Shortcake** Ingredients: * 1 pint strawberries, hulled and sliced * 1/2 cup sugar * 1/4 cup cornstarch * 1/4 cup water * 1 tablespoon lemon juice * 1/2 cup heavy cream, whipped * 1/4 cup confectioners' sugar * 1/4 teaspoon vanilla extract * 6 graham cracker squares, crushed Instructions: 1. In a medium saucepan, combine the strawberries, sugar, cornstarch, water, and lemon juice. Bring to a boil over medium heat, stirring constantly. Reduce heat and simmer for 5 minutes, or until the sauce has thickened. 2. Remove from heat and let cool slightly. 3. In a large bowl, combine the whipped cream, confectioners' sugar, and vanilla extract. Beat until soft peaks form. 4. To assemble the shortcakes, place a graham cracker square on each of 6 dessert plates. Top with a scoop of whipped cream, then a spoonful of strawberry sauce. Repeat layers, ending with a graham cracker square. 5. Serve immediately. **Tips:** * For a more elegant presentation, you can use fresh strawberries instead of sliced strawberries. * If you don't have time to make your own whipped cream, you can use store-bought whipped cream.
يمكنك تغيير قيم dish وingredients في الخريطة وتعديل درجة العشوائية topK وtokP وإعادة تشغيل الرمز. سيسمح لك ذلك بملاحظة تأثير تغيير هذه المَعلمات على النموذج اللغوي الكبير.
تُعدّ قوالب الطلبات طريقة جيدة للحصول على تعليمات قابلة لإعادة الاستخدام ويمكن ضبط مَعلماتها لاستخدامها في طلبات النماذج اللغوية الكبيرة. يمكنك تمرير البيانات وتخصيص الطلبات لقيم مختلفة يقدّمها المستخدمون.
9- تصنيف النصوص باستخدام التلقين ببضعة أمثلة
تُعدّ النماذج اللغوية الكبيرة جيدة جدًا في تصنيف النصوص إلى فئات مختلفة. يمكنك مساعدة نموذج اللغة الكبير في هذه المهمة من خلال تقديم بعض الأمثلة على النصوص والفئات المرتبطة بها. يُطلق على هذا الأسلوب غالبًا اسم التحفيز بعدد قليل من اللقطات.
لنفتح TextClassification.java في دليل app/src/main/java/gemini/workshop، لإجراء نوع معيّن من تصنيف النصوص: تحليل المشاعر.
package gemini.workshop;
import com.google.cloud.vertexai.api.Schema;
import com.google.cloud.vertexai.api.Type;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import java.util.List;
public class TextClassification {
enum Sentiment { POSITIVE, NEUTRAL, NEGATIVE }
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(10)
.maxRetries(3)
.responseSchema(Schema.newBuilder()
.setType(Type.STRING)
.addAllEnum(List.of("POSITIVE", "NEUTRAL", "NEGATIVE"))
.build())
.build();
interface SentimentAnalysis {
@SystemMessage("""
Analyze the sentiment of the text below.
Respond only with one word to describe the sentiment.
""")
Sentiment analyze(String text);
}
MessageWindowChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);
memory.add(UserMessage.from("This is fantastic news!"));
memory.add(AiMessage.from(Sentiment.POSITIVE.name()));
memory.add(UserMessage.from("Pi is roughly equal to 3.14"));
memory.add(AiMessage.from(Sentiment.NEUTRAL.name()));
memory.add(UserMessage.from("I really disliked the pizza. Who would use pineapples as a pizza topping?"));
memory.add(AiMessage.from(Sentiment.NEGATIVE.name()));
SentimentAnalysis sentimentAnalysis =
AiServices.builder(SentimentAnalysis.class)
.chatLanguageModel(model)
.chatMemory(memory)
.build();
System.out.println(sentimentAnalysis.analyze("I love strawberries!"));
}
}
تدرِج السمة Sentiment تعدادًا للقيم المختلفة لآراء العملاء: سلبية أو محايدة أو إيجابية.
في طريقة main()، يمكنك إنشاء نموذج محادثة Gemini كالمعتاد، ولكن مع عدد صغير من الرموز المميزة للناتج الأقصى، لأنّك تريد الحصول على رد قصير فقط: النص هو POSITIVE أو NEGATIVE أو NEUTRAL. ولحصر النموذج في عرض هذه القيم فقط، يمكنك الاستفادة من ميزة الإخراج المنظَّم التي تعرّفت عليها في قسم استخراج البيانات. لهذا السبب يتم استخدام الطريقة responseSchema(). في هذه المرة، لن تستخدم الطريقة السهلة من SchemaHelper لاستنتاج تعريف المخطط، ولكنك ستستخدم أداة إنشاء Schema بدلاً من ذلك، لفهم شكل تعريف المخطط.
بعد إعداد النموذج، يمكنك إنشاء واجهة SentimentAnalysis تنفّذها لك AiServices في LangChain4j باستخدام النموذج اللغوي الكبير. تحتوي هذه الواجهة على طريقة واحدة: analyze(). تتلقّى هذه الدالة النص المطلوب تحليله كمدخل، وتعرض قيمة تعداد Sentiment. وبالتالي، أنت تتعامل فقط مع عنصر مكتوب بشكل صارم يمثّل فئة المشاعر التي يتم التعرّف عليها.
بعد ذلك، لتقديم "أمثلة قليلة" لحثّ النموذج على تنفيذ مهمة التصنيف، يمكنك إنشاء ذاكرة محادثة لتمرير أزواج من رسائل المستخدمين وردود الذكاء الاصطناعي التي تمثّل النص والمشاعر المرتبطة به.
لنربط كل شيء معًا باستخدام طريقة AiServices.builder()، وذلك من خلال تمرير واجهة SentimentAnalysis والنموذج المراد استخدامه وذاكرة المحادثة مع الأمثلة القليلة. أخيرًا، استدعِ الدالة analyze() مع النص المطلوب تحليله.
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.TextClassification
من المفترض أن تظهر لك كلمة واحدة:
POSITIVE
يبدو أنّ حب الفراولة هو شعور إيجابي.
10. التوليد المعزّز بالاسترجاع
يتم تدريب النماذج اللغوية الكبيرة على كمية كبيرة من النصوص. ومع ذلك، لا تغطي معرفتها سوى المعلومات التي اطّلعت عليها أثناء التدريب. إذا تم إصدار معلومات جديدة بعد تاريخ آخر تحديث للبيانات، لن تتوفّر هذه التفاصيل للنموذج. وبالتالي، لن يتمكّن النموذج من الإجابة عن أسئلة حول معلومات لم يسبق له الاطّلاع عليها.
لهذا السبب، تساعد طرق مثل التوليد المعزّز بالاسترجاع (RAG) التي سنتناولها في هذا القسم في توفير المعلومات الإضافية التي قد يحتاج إليها النموذج اللغوي الكبير لتلبية طلبات المستخدمين، والردّ بمعلومات قد تكون أكثر حداثة أو معلومات خاصة لا يمكن الوصول إليها أثناء التدريب.
لنرجع إلى المحادثات. في هذه المرة، ستتمكّن من طرح أسئلة حول مستنداتك. ستنشئ برنامج دردشة آليًا قادرًا على استرداد المعلومات ذات الصلة من قاعدة بيانات تحتوي على مستنداتك مقسّمة إلى أجزاء أصغر ("أجزاء")، وسيستخدم النموذج هذه المعلومات لتحديد مصدر إجاباته، بدلاً من الاعتماد فقط على المعرفة الواردة في تدريبه.
في عملية الاسترجاع والإنشاء، هناك مرحلتان:
- مرحلة الاستيعاب: يتم تحميل المستندات في الذاكرة وتقسيمها إلى أجزاء أصغر، ويتم احتساب تضمينات المتجهات (تمثيل متجه عالي الأبعاد للأجزاء) وتخزينها في قاعدة بيانات متجهات يمكنها إجراء عمليات بحث دلالية. يتم تنفيذ مرحلة الاستيعاب هذه عادةً مرة واحدة، وذلك عند الحاجة إلى إضافة مستندات جديدة إلى مجموعة المستندات.

- مرحلة طلب البحث: يمكن للمستخدمين الآن طرح أسئلة حول المستندات. سيتم تحويل السؤال إلى متّجه أيضًا ومقارنته بجميع المتّجهات الأخرى في قاعدة البيانات. عادةً ما تكون المتجهات الأكثر تشابهًا مرتبطة دلاليًا، وتعرضها قاعدة بيانات المتجهات. بعد ذلك، يتم تزويد النموذج اللغوي الكبير بسياق المحادثة، وبأجزاء النص التي تتوافق مع المتّجهات التي أرجعتها قاعدة البيانات، ويُطلب منه تحديد مصدر إجابته من خلال النظر إلى تلك الأجزاء.

تجهيز مستنداتك
في هذا المثال الجديد، ستطرح أسئلة حول طراز سيارة وهمي من شركة مصنّعة للسيارات وهمية أيضًا، وهي سيارة Cymbal Starlight. الفكرة هي ألّا يكون المستند الذي يتناول سيارة وهمية جزءًا من معرفة النموذج. إذا كان بإمكان Gemini الإجابة عن أسئلة حول هذه السيارة بشكل صحيح، يعني ذلك أنّ طريقة RAG فعّالة، إذ يمكنها البحث في مستندك.
تنفيذ روبوت الدردشة
لنستكشف كيفية إنشاء الأسلوب المكوّن من مرحلتَين: الأولى هي إدخال المستند، والثانية هي وقت طلب البحث (المعروف أيضًا باسم "مرحلة الاسترجاع") عندما يطرح المستخدمون أسئلة حول المستند.
في هذا المثال، يتم تنفيذ كلتا المرحلتَين في الفئة نفسها. في العادة، يكون لديك تطبيق واحد يتولّى عملية الاستيعاب، وتطبيق آخر يوفّر واجهة روبوت الدردشة للمستخدمين.
في هذا المثال، سنستخدم أيضًا قاعدة بيانات متجهات داخل الذاكرة. في سيناريو إنتاج حقيقي، سيتم فصل مرحلتَي الاستيعاب والاستعلام في تطبيقَين مختلفَين، وسيتم الاحتفاظ بالمتجهات في قاعدة بيانات مستقلة.
عرض المستندات
تتمثل الخطوة الأولى في مرحلة نقل المستند في تحديد موقع ملف PDF الخاص بالسيارة الوهمية وإعداد PdfParser لقراءته:
URL url = new URI("https://raw.githubusercontent.com/meteatamel/genai-beyond-basics/main/samples/grounding/vertexai-search/cymbal-starlight-2024.pdf").toURL();
ApachePdfBoxDocumentParser pdfParser = new ApachePdfBoxDocumentParser();
Document document = pdfParser.parse(url.openStream());
بدلاً من إنشاء نموذج لغوي عادي للدردشة أولاً، يمكنك إنشاء مثيل لنموذج تضمين. هذا نموذج معيّن دوره إنشاء تمثيلات متجهة لأجزاء من النص (كلمات أو جمل أو حتى فقرات). تعرض هذه الدالة متجهات من الأرقام النقطية العائمة بدلاً من عرض ردود نصية.
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint(System.getenv("LOCATION") + "-aiplatform.googleapis.com:443")
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.publisher("google")
.modelName("text-embedding-005")
.maxRetries(3)
.build();
بعد ذلك، ستحتاج إلى بعض الصفوف للتعاون معًا من أجل:
- تحميل مستند PDF وتقسيمه إلى أجزاء
- أنشئ تضمينات متجهة لكل هذه الأجزاء.
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
يتم إنشاء مثيل من InMemoryEmbeddingStore، وهي قاعدة بيانات متّجهات في الذاكرة، لتخزين تضمينات المتّجهات.
يتم تقسيم المستند إلى أجزاء بفضل الفئة DocumentSplitters. سيتم تقسيم نص ملف PDF إلى مقتطفات من 500 حرف، مع تداخل 100 حرف (مع الجزء التالي، لتجنُّب قطع الكلمات أو الجمل).
يربط أداة استيعاب المتجر أداة تقسيم المستندات ونموذج التضمين لحساب المتجهات وقاعدة بيانات المتجهات في الذاكرة. بعد ذلك، ستتولّى الطريقة ingest() عملية النقل.
الآن، انتهت المرحلة الأولى، وتم تحويل المستند إلى أجزاء نصية مع تضميناتها المتجهة المرتبطة، وتم تخزينها في قاعدة بيانات المتجهات.
طرح الأسئلة
حان الوقت الآن لطرح الأسئلة. أنشئ نموذج محادثة لبدء المحادثة:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(1000)
.build();
تحتاج أيضًا إلى فئة استرداد لربط قاعدة بيانات المتجهات (في المتغيّر embeddingStore) بنموذج التضمين. مهمة هذا النظام هي البحث في قاعدة بيانات المتّجهات من خلال احتساب تضمين متّجه لطلب المستخدم، وذلك للعثور على متّجهات مشابهة في قاعدة البيانات:
EmbeddingStoreContentRetriever retriever =
new EmbeddingStoreContentRetriever(embeddingStore, embeddingModel);
أنشِئ واجهة تمثّل مساعدًا خبيرًا في مجال السيارات، أي واجهة ستنفّذها الفئة AiServices لتتفاعل مع النموذج:
interface CarExpert {
Result<String> ask(String question);
}
تعرض واجهة CarExpert استجابة سلسلة نصية مضمّنة في فئة Result في LangChain4j. لماذا يجب استخدام هذا الغلاف؟ لأنّها لن تقدّم لك الإجابة فحسب، بل ستتيح لك أيضًا فحص الأجزاء من قاعدة البيانات التي أرجعها برنامج استرجاع المحتوى. بهذه الطريقة، يمكنك عرض مصادر المستندات المستخدَمة لتحديد الإجابة النهائية للمستخدم.
في هذه المرحلة، يمكنك ضبط خدمة ذكاء اصطناعي جديدة باتّباع الخطوات التالية:
CarExpert expert = AiServices.builder(CarExpert.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(retriever)
.build();
تربط هذه الخدمة ما يلي:
- نموذج لغة المحادثة الذي أعددته سابقًا
- ذاكرة محادثة لتتبُّع المحادثة
- يقارن المسترجِع طلب بحث عن تضمين متّجه بالمتّجهات في قاعدة البيانات.
.retrievalAugmentor(DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("""
You are an expert in car automotive, and you answer concisely.
Here is the question: {{userMessage}}
Answer using the following information:
{{contents}}
"""))
.build())
.contentRetriever(retriever)
.build())
أنت الآن مستعد لطرح أسئلتك.
List.of(
"What is the cargo capacity of Cymbal Starlight?",
"What's the emergency roadside assistance phone number?",
"Are there some special kits available on that car?"
).forEach(query -> {
Result<String> response = expert.ask(query);
System.out.printf("%n=== %s === %n%n %s %n%n", query, response.content());
System.out.println("SOURCE: " + response.sources().getFirst().textSegment().text());
});
يتوفّر رمز المصدر الكامل في RAG.java في الدليل app/src/main/java/gemini/workshop.
شغِّل العيّنة:
./gradlew -q run -DjavaMainClass=gemini.workshop.RAG
في الناتج، يجب أن تظهر لك إجابات عن أسئلتك:
=== What is the cargo capacity of Cymbal Starlight? === The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. SOURCE: Cargo The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of the vehicle. To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell. When loading cargo into the trunk, be sure to distribute the weight evenly. Do not overload the trunk, as this could affect the vehicle's handling and stability. Luggage === What's the emergency roadside assistance phone number? === The emergency roadside assistance phone number is 1-800-555-1212. SOURCE: Chapter 18: Emergencies Roadside Assistance If you experience a roadside emergency, such as a flat tire or a dead battery, you can call roadside assistance for help. Roadside assistance is available 24 hours a day, 7 days a week. To call roadside assistance, dial the following number: 1-800-555-1212 When you call roadside assistance, be prepared to provide the following information: Your name and contact information Your vehicle's make, model, and year Your vehicle's location === Are there some special kits available on that car? === Yes, the Cymbal Starlight comes with a tire repair kit. SOURCE: Lane keeping assist: This feature helps to keep you in your lane by gently steering the vehicle back into the lane if you start to drift. Adaptive cruise control: This feature automatically adjusts your speed to maintain a safe following distance from the vehicle in front of you. Forward collision warning: This feature warns you if you are approaching another vehicle too quickly. Automatic emergency braking: This feature can automatically apply the brakes to avoid a collision.
11. استدعاء الدالة
في بعض الحالات، قد تحتاج إلى أن يكون لدى نموذج اللغة الكبير إذن بالوصول إلى أنظمة خارجية، مثل واجهة برمجة تطبيقات ويب بعيدة تسترد المعلومات أو تنفّذ إجراءً، أو خدمات تنفّذ نوعًا من العمليات الحسابية. على سبيل المثال:
واجهات برمجة التطبيقات على الويب عن بُعد:
- تتبُّع طلبات العملاء وتعديلها
- ابحث عن تذكرة أو أنشئها في أداة تتبُّع المشاكل.
- استرداد البيانات في الوقت الفعلي، مثل أسعار الأسهم أو قياسات أجهزة استشعار إنترنت الأشياء
- إرسال رسالة إلكترونية
أدوات الحساب:
- آلة حاسبة للمسائل الحسابية الأكثر تعقيدًا
- تفسير الرموز البرمجية لتشغيلها عندما تحتاج النماذج اللغوية الكبيرة إلى منطق استدلالي
- تحويل الطلبات المُدخلة باللغة العادية إلى طلبات بحث SQL لكي يتمكّن نموذج اللغة الكبير من الاستعلام عن قاعدة بيانات
تتيح ميزة "استدعاء الدوال" (المعروفة أحيانًا باسم "الأدوات" أو "استخدام الأدوات") للنموذج طلب إجراء استدعاء واحد أو أكثر للدوال نيابةً عنه، وذلك ليتمكّن من الردّ بشكل صحيح على طلب المستخدم باستخدام بيانات أحدث.
عندما يقدّم المستخدم طلبًا معيّنًا، وبفضل معرفة الدوال الحالية التي يمكن أن تكون ذات صلة بهذا السياق، يمكن للنموذج اللغوي الكبير الردّ بطلب استدعاء دالة. يمكن للتطبيق الذي يدمج النموذج اللغوي الكبير بعد ذلك استدعاء الدالة نيابةً عنه، ثم الردّ على النموذج اللغوي الكبير، وبعدها يفسّر النموذج اللغوي الكبير الردّ من خلال تقديم إجابة نصية.
أربع خطوات لاستدعاء الدوال
لنلقِ نظرة على مثال على استدعاء دالة: الحصول على معلومات حول توقّعات الطقس.
إذا سألت Gemini أو أي نموذج لغوي كبير آخر عن الطقس في باريس، سيجيبك بأنّه لا يتوفّر لديه معلومات حول توقعات الطقس الحالية. إذا كنت تريد أن يتمكّن النموذج اللغوي الكبير من الوصول إلى بيانات الطقس في الوقت الفعلي، عليك تحديد بعض الدوال التي يمكنه طلب استخدامها.
اطّلِع على الرسم التخطيطي التالي:

1️⃣ أولاً، يسأل المستخدم عن حالة الطقس في باريس. يعرف تطبيق chatbot (باستخدام LangChain4j) أنّ هناك دالة واحدة أو أكثر تحت تصرّفه لمساعدة النموذج اللغوي الكبير في تنفيذ الطلب. يرسل برنامج الدردشة الآلي الطلب الأولي وقائمة الدوال التي يمكن استدعاؤها. في هذا المثال، لدينا دالة باسم getWeather() تأخذ مَعلمة سلسلة للموقع الجغرافي.

بما أنّ النموذج اللغوي الكبير لا يعرف توقّعات الطقس، بدلاً من الردّ عبر رسالة نصية، يرسل طلبًا لتنفيذ دالة. يجب أن يستدعي برنامج الدردشة الآلي الدالة getWeather() مع "Paris" كمعلَمة الموقع الجغرافي.
2️⃣ يستدعي روبوت الدردشة هذه الدالة نيابةً عن النموذج اللغوي الكبير، ويستردّ استجابة الدالة. في هذا المثال، نفترض أنّ الردّ هو {"forecast": "sunny"}.

3️⃣ يرسل تطبيق المحادثة الآلية استجابة JSON إلى النموذج اللغوي الكبير.
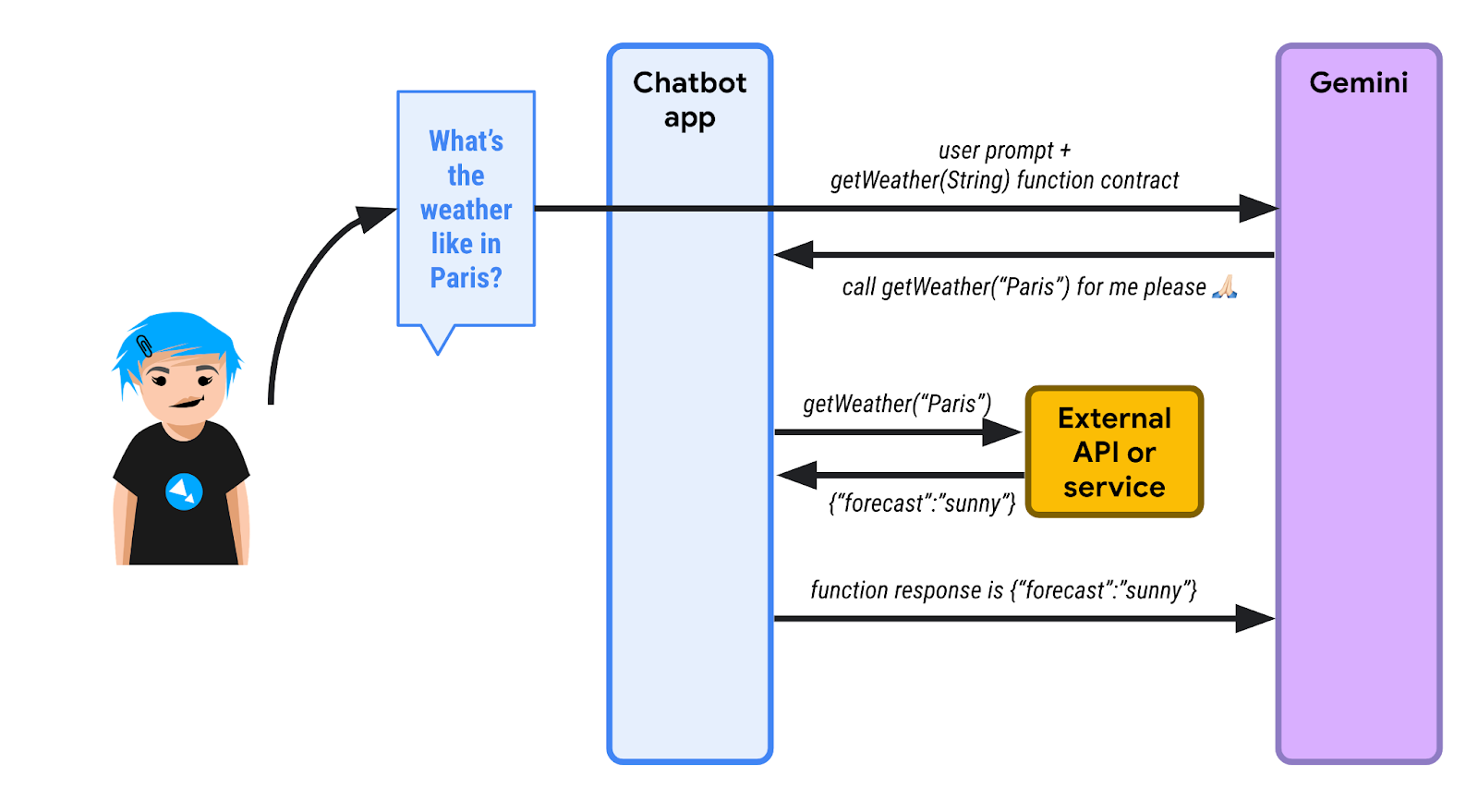
4️⃣ ينظر النموذج اللغوي الكبير إلى استجابة JSON ويفسّر تلك المعلومات، ثم يردّ في النهاية بنص يشير إلى أنّ الطقس مشمس في باريس.

كل خطوة كرمز
أولاً، عليك ضبط نموذج Gemini كالمعتاد:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
تحدّد مواصفات الأداة التي تصف الدالة التي يمكن استدعاؤها:
ToolSpecification weatherToolSpec = ToolSpecification.builder()
.name("getWeather")
.description("Get the weather forecast for a given location or city")
.parameters(JsonObjectSchema.builder()
.addStringProperty(
"location",
"the location or city to get the weather forecast for")
.build())
.build();
يتم تحديد اسم الدالة، بالإضافة إلى اسم المَعلمة ونوعها، ولكن لاحظ أنّه يتم تقديم أوصاف لكل من الدالة والمَعلمات. تُعدّ الأوصاف مهمة جدًا وتساعد النموذج اللغوي الكبير في فهم ما يمكن أن تفعله الدالة، وبالتالي تحديد ما إذا كان يجب استدعاء هذه الدالة في سياق المحادثة.
لنبدأ بالخطوة الأولى من خلال إرسال السؤال الأوّلي حول حالة الطقس في باريس:
List<ChatMessage> allMessages = new ArrayList<>();
// 1) Ask the question about the weather
UserMessage weatherQuestion = UserMessage.from("What is the weather in Paris?");
allMessages.add(weatherQuestion);
في الخطوة رقم 2، نمرّر الأداة التي نريد أن يستخدمها النموذج، ويردّ النموذج بطلب تنفيذ الأداة:
// 2) The model replies with a function call request
Response<AiMessage> messageResponse = model.generate(allMessages, weatherToolSpec);
ToolExecutionRequest toolExecutionRequest = messageResponse.content().toolExecutionRequests().getFirst();
System.out.println("Tool execution request: " + toolExecutionRequest);
allMessages.add(messageResponse.content());
الخطوة 3: في هذه المرحلة، نعرف الدالة التي يريد النموذج اللغوي الكبير أن نستدعيها. في الرمز، لا نُجري طلبًا فعليًا إلى واجهة برمجة تطبيقات خارجية، بل نعرض مباشرةً توقعات افتراضية لحالة الطقس:
// 3) We send back the result of the function call
ToolExecutionResultMessage toolExecResMsg = ToolExecutionResultMessage.from(toolExecutionRequest,
"{\"location\":\"Paris\",\"forecast\":\"sunny\", \"temperature\": 20}");
allMessages.add(toolExecResMsg);
في الخطوة رقم 4، يتعرّف النموذج اللغوي الكبير على نتيجة تنفيذ الدالة، ويمكنه بعد ذلك إنشاء رد نصي:
// 4) The model answers with a sentence describing the weather
Response<AiMessage> weatherResponse = model.generate(allMessages);
System.out.println("Answer: " + weatherResponse.content().text());
يتوفّر رمز المصدر الكامل في FunctionCalling.java في الدليل app/src/main/java/gemini/workshop.
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCalling
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
Tool execution request: ToolExecutionRequest { id = null, name = "getWeatherForecast", arguments = "{"location":"Paris"}" }
Answer: The weather in Paris is sunny with a temperature of 20 degrees Celsius.
يمكنك الاطّلاع في الناتج أعلاه على طلب تنفيذ الأداة، بالإضافة إلى الإجابة.
12. تتعامل LangChain4j مع استدعاء الدالة
في الخطوة السابقة، رأيت كيف تتداخل التفاعلات العادية بين السؤال/الجواب النصي وطلب/رد الدالة، وفي ما بينها، قدّمت رد الدالة المطلوب مباشرةً، بدون استدعاء دالة حقيقية.
ومع ذلك، يوفّر LangChain4j أيضًا تجريدًا أعلى مستوى يمكنه التعامل مع طلبات الدوال بشكل شفاف نيابةً عنك، مع التعامل مع المحادثة كالمعتاد.
استدعاء دالة واحدة
لنلقِ نظرة على FunctionCallingAssistant.java، جزءًا جزءًا.
أولاً، عليك إنشاء سجلّ يمثّل بنية بيانات ردّ الدالة:
record WeatherForecast(String location, String forecast, int temperature) {}
تحتوي الاستجابة على معلومات حول الموقع الجغرافي والتوقعات الجوية ودرجة الحرارة.
بعد ذلك، يمكنك إنشاء فئة تحتوي على الدالة الفعلية التي تريد إتاحتها للنموذج:
static class WeatherForecastService {
@Tool("Get the weather forecast for a location")
WeatherForecast getForecast(@P("Location to get the forecast for") String location) {
if (location.equals("Paris")) {
return new WeatherForecast("Paris", "Sunny", 20);
} else if (location.equals("London")) {
return new WeatherForecast("London", "Rainy", 15);
} else {
return new WeatherForecast("Unknown", "Unknown", 0);
}
}
}
يُرجى العِلم أنّ هذا الصف يحتوي على دالة واحدة، ولكن تم وضع التعليق التوضيحي @Tool عليه، وهو ما يتوافق مع وصف الدالة التي يمكن للنموذج طلب استدعائها.
يتم أيضًا إضافة تعليق توضيحي إلى مَعلمات الدالة (معلَمة واحدة هنا)، ولكن باستخدام التعليق التوضيحي المختصر @P الذي يقدّم أيضًا وصفًا للمعلَمة. يمكنك إضافة أي عدد من الدوال التي تريدها لإتاحتها للنموذج في السيناريوهات الأكثر تعقيدًا.
في هذه الفئة، يمكنك عرض بعض الردود الجاهزة، ولكن إذا أردت طلب خدمة خارجية حقيقية لتوقّعات الطقس، يمكنك إجراء هذا الطلب في نص هذه الطريقة.
كما رأينا عند إنشاء ToolSpecification في الطريقة السابقة، من المهم توثيق ما تفعله الدالة ووصف ما تتوافق معه المَعلمات. يساعد ذلك النموذج في فهم كيفية استخدام هذه الدالة ومتى يمكن استخدامها.
بعد ذلك، تتيح لك LangChain4j توفير واجهة تتوافق مع العقد الذي تريد استخدامه للتفاعل مع النموذج. في ما يلي، واجهة بسيطة تتلقّى سلسلة تمثّل رسالة المستخدم وتعرض سلسلة تتوافق مع ردّ النموذج:
interface WeatherAssistant {
String chat(String userMessage);
}
يمكن أيضًا استخدام توقيعات أكثر تعقيدًا تتضمّن UserMessage في LangChain4j (لرسالة المستخدم) أو AiMessage (لردّ النموذج)، أو حتى TokenStream، إذا أردت التعامل مع حالات أكثر تقدّمًا، لأنّ هذه الكائنات الأكثر تعقيدًا تحتوي أيضًا على معلومات إضافية مثل عدد الرموز المميزة المستخدَمة وما إلى ذلك. ولكن لتبسيط الأمر، سنستخدم السلسلة فقط في الإدخال والإخراج.
لنختم بالدالة main() التي تربط كل الأجزاء معًا:
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
WeatherForecastService weatherForecastService = new WeatherForecastService();
WeatherAssistant assistant = AiServices.builder(WeatherAssistant.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.tools(weatherForecastService)
.build();
System.out.println(assistant.chat("What is the weather in Paris?"));
System.out.println(assistant.chat("Is it warmer in London or in Paris?"));
}
وكالعادة، عليك ضبط نموذج محادثة Gemini. بعد ذلك، يمكنك إنشاء مثيل لخدمة توقّعات الطقس التي تحتوي على "الدالة" التي سيطلب منّا النموذج استدعاءها.
الآن، يمكنك استخدام فئة AiServices مرة أخرى لربط نموذج المحادثة وذاكرة المحادثة والأداة (أي خدمة توقعات الطقس مع وظيفتها). تعرض الدالة AiServices عنصرًا ينفّذ واجهة WeatherAssistant التي حدّدتها. ما عليك سوى استدعاء طريقة chat() الخاصة بهذا المساعد. عند استدعاء هذه الميزة، ستظهر لك الردود النصية فقط، ولكن لن يتمكّن المطوّر من رؤية طلبات استدعاء الوظائف وردودها، وسيتم التعامل مع هذه الطلبات تلقائيًا وبشفافية. إذا رأى Gemini أنّه يجب استدعاء دالة، سيردّ بطلب استدعاء الدالة، وستتولّى LangChain4j استدعاء الدالة المحلية نيابةً عنك.
شغِّل العيّنة:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCallingAssistant
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
OK. The weather in Paris is sunny with a temperature of 20 degrees.
It is warmer in Paris (20 degrees) than in London (15 degrees).
كان هذا مثالاً على دالة واحدة.
استدعاء دوال متعددة
يمكنك أيضًا استخدام دوال متعددة والسماح لمكتبة LangChain4j بالتعامل مع طلبات الدوال المتعددة نيابةً عنك. اطّلِع على MultiFunctionCallingAssistant.java للاطّلاع على مثال لدالة متعددة.
تتضمّن هذه الأداة دالة لتحويل العملات:
@Tool("Convert amounts between two currencies")
double convertCurrency(
@P("Currency to convert from") String fromCurrency,
@P("Currency to convert to") String toCurrency,
@P("Amount to convert") double amount) {
double result = amount;
if (fromCurrency.equals("USD") && toCurrency.equals("EUR")) {
result = amount * 0.93;
} else if (fromCurrency.equals("USD") && toCurrency.equals("GBP")) {
result = amount * 0.79;
}
System.out.println(
"convertCurrency(fromCurrency = " + fromCurrency +
", toCurrency = " + toCurrency +
", amount = " + amount + ") == " + result);
return result;
}
دالة أخرى للحصول على قيمة سهم:
@Tool("Get the current value of a stock in US dollars")
double getStockPrice(@P("Stock symbol") String symbol) {
double result = 170.0 + 10 * new Random().nextDouble();
System.out.println("getStockPrice(symbol = " + symbol + ") == " + result);
return result;
}
دالة أخرى لتطبيق نسبة مئوية على مبلغ معيّن:
@Tool("Apply a percentage to a given amount")
double applyPercentage(@P("Initial amount") double amount, @P("Percentage between 0-100 to apply") double percentage) {
double result = amount * (percentage / 100);
System.out.println("applyPercentage(amount = " + amount + ", percentage = " + percentage + ") == " + result);
return result;
}
يمكنك بعد ذلك الجمع بين كل هذه الدوال وفئة MultiTools وطرح أسئلة مثل "ما هي نسبة% 10 من سعر سهم AAPL محوّلة من الدولار الأمريكي إلى اليورو؟"
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
MultiTools multiTools = new MultiTools();
MultiToolsAssistant assistant = AiServices.builder(MultiToolsAssistant.class)
.chatLanguageModel(model)
.chatMemory(withMaxMessages(10))
.tools(multiTools)
.build();
System.out.println(assistant.chat(
"What is 10% of the AAPL stock price converted from USD to EUR?"));
}
نفِّذها على النحو التالي:
./gradlew run -q -DjavaMainClass=gemini.workshop.MultiFunctionCallingAssistant
من المفترض أن تظهر لك الدوال المتعدّدة التي تم استدعاؤها:
getStockPrice(symbol = AAPL) == 172.8022224055534 convertCurrency(fromCurrency = USD, toCurrency = EUR, amount = 172.8022224055534) == 160.70606683716468 applyPercentage(amount = 160.70606683716468, percentage = 10.0) == 16.07060668371647 10% of the AAPL stock price converted from USD to EUR is 16.07060668371647 EUR.
نحو الوكلاء
تُعدّ ميزة "استدعاء الدوال" آلية رائعة لتوسيع نطاق النماذج اللغوية الكبيرة، مثل Gemini. ويتيح لنا إنشاء أنظمة أكثر تعقيدًا تُعرف غالبًا باسم "برامج آلية" أو "مساعدات مستندة إلى الذكاء الاصطناعي". يمكن لهذه الوكلاء التفاعل مع العالم الخارجي من خلال واجهات برمجة التطبيقات الخارجية ومع الخدمات التي يمكن أن يكون لها آثار جانبية على البيئة الخارجية (مثل إرسال رسائل إلكترونية وإنشاء تذاكر وما إلى ذلك).
عند إنشاء وكلاء بهذه الإمكانات، يجب أن يتم ذلك بمسؤولية. يجب الاستعانة بمراجعين قبل اتّخاذ إجراءات تلقائية. من المهم مراعاة الأمان عند تصميم وكلاء مستندين إلى نماذج لغوية كبيرة تتفاعل مع العالم الخارجي.
13. تشغيل Gemma باستخدام Ollama وTestContainers
حتى الآن، كنا نستخدم Gemini، ولكن يتوفّر أيضًا Gemma، وهو نموذج أصغر حجمًا.
Gemma هي مجموعة من أحدث النماذج المتطوّرة والخفيفة المتاحة للجميع، والتي تم إنشاؤها بناءً على الأبحاث والتكنولوجيا نفسها المستخدمة في إنشاء نماذج Gemini. أحدث نموذج من Gemma هو Gemma3، ويتوفّر بأربعة أحجام: 1B (نص فقط) و4B و12B و27B. تتوفّر أوزانها مجانًا، كما أنّ أحجامها الصغيرة تتيح لك تشغيلها بنفسك، حتى على الكمبيوتر المحمول أو في Cloud Shell.
كيف يمكن تشغيل Gemma؟
تتوفّر طرق عديدة لتشغيل Gemma، مثل تشغيلها على السحابة الإلكترونية أو من خلال Vertex AI بنقرة زر واحدة أو GKE مع بعض وحدات معالجة الرسومات، ولكن يمكنك أيضًا تشغيلها محليًا.
من الخيارات الجيدة لتشغيل Gemma محليًا استخدام Ollama، وهي أداة تتيح لك تشغيل نماذج صغيرة، مثل Llama وMistral وغيرها الكثير على جهازك المحلي. وهي تشبه Docker ولكنها مخصّصة للنماذج اللغوية الكبيرة.
ثبِّت Ollama باتّباع التعليمات الخاصة بنظام التشغيل.
إذا كنت تستخدم بيئة Linux، عليك تفعيل Ollama أولاً بعد تثبيته.
ollama serve > /dev/null 2>&1 &
بعد تثبيت النموذج محليًا، يمكنك تنفيذ أوامر لجلب نموذج:
ollama pull gemma3:1b
انتظِر إلى أن يتم سحب النموذج. يمكن أن تستغرق هذه العملية بعض الوقت.
تشغيل النموذج:
ollama run gemma3:1b
يمكنك الآن التفاعل مع النموذج:
>>> Hello! Hello! It's nice to hear from you. What can I do for you today?
للخروج من الطلب، اضغط على Ctrl+D
تشغيل Gemma في Ollama على TestContainers
بدلاً من تثبيت Ollama وتشغيله محليًا، يمكنك استخدام Ollama داخل حاوية تديرها TestContainers.
لا يفيد إطار عمل TestContainers في الاختبار فحسب، بل يمكنك استخدامه أيضًا لتنفيذ الحاويات. يتوفّر أيضًا OllamaContainer يمكنك الاستفادة منه.
إليك الصورة الكاملة:

التنفيذ
لنلقِ نظرة على GemmaWithOllamaContainer.java، جزءًا جزءًا.
أولاً، عليك إنشاء حاوية Ollama مشتقة تجلب نموذج Gemma. تكون هذه الصورة متوفّرة من عملية تشغيل سابقة أو سيتم إنشاؤها. إذا كانت الصورة متوفّرة، ما عليك سوى إخبار TestContainers بأنّك تريد استبدال صورة Ollama التلقائية بالصورة التي تستخدم Gemma:
private static final String TC_OLLAMA_GEMMA3 = "tc-ollama-gemma3-1b";
public static final String GEMMA_3 = "gemma3:1b";
// Creating an Ollama container with Gemma 3 if it doesn't exist.
private static OllamaContainer createGemmaOllamaContainer() throws IOException, InterruptedException {
// Check if the custom Gemma Ollama image exists already
List<Image> listImagesCmd = DockerClientFactory.lazyClient()
.listImagesCmd()
.withImageNameFilter(TC_OLLAMA_GEMMA3)
.exec();
if (listImagesCmd.isEmpty()) {
System.out.println("Creating a new Ollama container with Gemma 3 image...");
OllamaContainer ollama = new OllamaContainer("ollama/ollama:0.7.1");
System.out.println("Starting Ollama...");
ollama.start();
System.out.println("Pulling model...");
ollama.execInContainer("ollama", "pull", GEMMA_3);
System.out.println("Committing to image...");
ollama.commitToImage(TC_OLLAMA_GEMMA3);
return ollama;
}
System.out.println("Ollama image substitution...");
// Substitute the default Ollama image with our Gemma variant
return new OllamaContainer(
DockerImageName.parse(TC_OLLAMA_GEMMA3)
.asCompatibleSubstituteFor("ollama/ollama"));
}
بعد ذلك، يمكنك إنشاء حاوية اختبار Ollama وبدء تشغيلها، ثم إنشاء نموذج محادثة Ollama، وذلك من خلال الإشارة إلى عنوان الحاوية ومنفذها باستخدام النموذج الذي تريد استخدامه. أخيرًا، ما عليك سوى استدعاء model.generate(yourPrompt) كالمعتاد:
public static void main(String[] args) throws IOException, InterruptedException {
OllamaContainer ollama = createGemmaOllamaContainer();
ollama.start();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(String.format("http://%s:%d", ollama.getHost(), ollama.getFirstMappedPort()))
.modelName(GEMMA_3)
.build();
String response = model.generate("Why is the sky blue?");
System.out.println(response);
}
نفِّذها على النحو التالي:
./gradlew run -q -DjavaMainClass=gemini.workshop.GemmaWithOllamaContainer
سيستغرق التشغيل الأول بعض الوقت لإنشاء الحاوية وتشغيلها، ولكن بعد الانتهاء من ذلك، من المفترض أن ترى Gemma تردّ على النحو التالي:
INFO: Container ollama/ollama:0.7.1 started in PT7.228339916S
The sky appears blue due to Rayleigh scattering. Rayleigh scattering is a phenomenon that occurs when sunlight interacts with molecules in the Earth's atmosphere.
* **Scattering particles:** The main scattering particles in the atmosphere are molecules of nitrogen (N2) and oxygen (O2).
* **Wavelength of light:** Blue light has a shorter wavelength than other colors of light, such as red and yellow.
* **Scattering process:** When blue light interacts with these molecules, it is scattered in all directions.
* **Human eyes:** Our eyes are more sensitive to blue light than other colors, so we perceive the sky as blue.
This scattering process results in a blue appearance for the sky, even though the sun is actually emitting light of all colors.
In addition to Rayleigh scattering, other atmospheric factors can also influence the color of the sky, such as dust particles, aerosols, and clouds.
أصبحت Gemma تعمل في Cloud Shell.
14. تهانينا
تهانينا، لقد أنشأت بنجاح أول تطبيق دردشة يعمل بالذكاء الاصطناعي التوليدي في Java باستخدام LangChain4j وGemini API. لقد تبيّن لك أنّ النماذج اللغوية الكبيرة المتعددة الوسائط فعّالة جدًا وقادرة على التعامل مع مهام مختلفة، مثل طرح الأسئلة والإجابة عنها، حتى في مستنداتك الخاصة، واستخراج البيانات، والتفاعل مع واجهات برمجة التطبيقات الخارجية، وغير ذلك.
ما هي الخطوات التالية؟
حان دورك الآن لتحسين تطبيقاتك من خلال عمليات دمج فعّالة للنماذج اللغوية الكبيرة.
Further reading
- حالات الاستخدام الشائعة للذكاء الاصطناعي التوليدي
- مصادر تدريب حول الذكاء الاصطناعي التوليدي
- التفاعل مع Gemini من خلال Generative AI Studio
- الذكاء الاصطناعي المسؤول