
1. 简介
本 Codelab 重点介绍托管在 Google Cloud 上的 Gemini 大语言模型 (LLM)。Vertex AI 是一个平台,涵盖了 Google Cloud 上的所有机器学习产品、服务和模型。
您将使用 Java 通过 LangChain4j 框架与 Gemini API 进行交互。您将通过具体示例了解如何利用 LLM 进行问答、创意生成、实体和结构化内容提取、检索增强生成和函数调用。
什么是生成式 AI?
生成式 AI 是指使用人工智能来创作新内容,例如文本、图片、音乐、音频和视频。
生成式 AI 基于可以执行多任务处理和执行开箱即用任务(包括摘要、问答、分类等)的大型语言模型 (LLM)。只需少量训练,即可针对特定应用场景调整基础模型,所需示例数据极少。
生成式 AI 如何运作?
生成式 AI 的工作原理是利用机器学习 (ML) 模型,学习人工创建的内容数据集中的模式和关系。然后,它会利用学到的模式生成新内容。
如需训练生成式 AI 模型,最常见的方式是使用监督学习。系统会为该模型提供一组人工创建的内容和相应的标签。然后,它会学习如何生成类似于人工创建的内容。
生成式 AI 的常见应用有哪些?
生成式 AI 可用于:
- 通过改善聊天和搜索体验来提高客户互动度。
- 通过对话界面和摘要探索大量非结构化数据。
- 协助处理重复性任务,例如回复提案请求、将营销内容本地化为不同语言,以及检查客户合同是否合规等。
Google Cloud 提供哪些生成式 AI 产品?
借助 Vertex AI,您可以自定义基础模型、与其交互、将其嵌入到应用中,而无需具备机器学习方面的专业知识。您可以在 Model Garden 上访问基础模型,通过 Vertex AI Studio 上的简单界面微调模型,或者在数据科学笔记本中使用模型。
Vertex AI Search and Conversation 为开发者提供了构建由生成式 AI 提供支持的搜索引擎和聊天机器人的最快方式。
Gemini for Google Cloud 由 Gemini 提供支持,是一款 AI 赋能的协作工具,可在 Google Cloud 和 IDE 中使用,帮助您更快地完成更多工作。Gemini Code Assist 提供代码补全、代码生成、代码解释功能,还支持聊天,以便您提出技术问题。
什么是 Gemini?
Gemini 是 Google DeepMind 开发的一系列生成式 AI 模型,专为多模态应用场景而设计。多模态是指它可以处理和生成不同类型的内容,例如文本、代码、图片和音频。

Gemini 有多种变体和规格:
- Gemini 2.0 Flash:我们最新的下一代功能和改进的功能。
- Gemini 2.0 Flash-Lite:一款经过优化的 Gemini 2.0 Flash 模型,可提高成本效益并缩短延迟时间。
- Gemini 2.5 Pro:我们迄今为止最先进的高级推理模型。
- Gemini 2.5 Flash:一款具备思考能力且功能全面的模型。旨在在价格和性能之间取得平衡。
主要特性:
- 多模态:Gemini 能够理解和处理多种信息格式,这比传统的纯文本语言模型有了显著进步。
- 性能:Gemini 2.5 Pro 在许多基准测试中都优于当前最先进的模型,并且是首个在极具挑战性的 MMLU(大规模多任务语言理解)基准测试中超越人类专家的模型。
- 灵活性:Gemini 有多种尺寸,可适应各种应用场景,从大规模研究到在移动设备上部署。
如何通过 Java 与 Vertex AI 上的 Gemini 进行交互?
您有两种选择:
- 官方 Vertex AI Java API for Gemini 库。
- LangChain4j 框架。
在此 Codelab 中,您将使用 LangChain4j 框架。
什么是 LangChain4j 框架?
LangChain4j 框架是一个开源库,用于通过编排各种组件(例如 LLM 本身,以及其他工具,如矢量数据库 [用于语义搜索]、文档加载器和拆分器 [用于分析文档并从中学习]、输出解析器等)在 Java 应用中集成 LLM。
该项目的灵感来自 LangChain Python 项目,但旨在为 Java 开发者提供服务。

学习内容
- 如何设置 Java 项目以使用 Gemini 和 LangChain4j
- 如何以程序化方式向 Gemini 发送第一个提示
- 如何让 Gemini 逐字逐句给出回答
- 如何创建用户与 Gemini 之间的对话
- 如何在多模态情境中使用 Gemini,即同时发送文本和图片
- 如何从非结构化内容中提取有用的结构化信息
- 如何操作提示模板
- 如何进行文本分类(例如情感分析)
- 如何与自己的文档对话(检索增强生成)
- 如何通过函数调用扩展聊天机器人
- 如何通过 Ollama 和 TestContainers 在本地使用 Gemma
所需条件
- 了解 Java 编程语言
- Google Cloud 项目
- 浏览器,例如 Chrome 或 Firefox
2. 设置和要求
自定进度的环境设置
- 登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。



- 项目名称是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
- 接下来,您需要在 Cloud 控制台中启用结算功能,以便使用 Cloud 资源/API。运行此 Codelab 应该不会产生太多的费用(如果有的话)。若要关闭资源以避免产生超出本教程范围的结算费用,您可以删除自己创建的资源或删除项目。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Cloud Shell,这是一个在云端运行的命令行环境。
激活 Cloud Shell
- 在 Cloud Console 中,点击激活 Cloud Shell
 。
。

如果您是第一次启动 Cloud Shell,系统会显示一个介绍其功能的过渡页面。如果您看到了过渡页面,请点击继续。

预配和连接到 Cloud Shell 只需花几分钟时间。

这个虚拟机已加载了所需的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。只需使用一个浏览器即可完成本 Codelab 中的大部分工作。
连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的项目 ID。
- 在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目:
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
3. 准备开发环境
在此 Codelab 中,您将使用 Cloud Shell 终端和 Cloud Shell 编辑器来开发 Java 程序。
启用 Vertex AI API
在 Google Cloud 控制台中,确保您的项目名称显示在 Google Cloud 控制台的顶部。如果未显示,请点击选择项目以打开项目选择器,然后选择您的预期项目。
您可以从 Google Cloud 控制台的 Vertex AI 部分或 Cloud Shell 终端启用 Vertex AI API。
如需从 Google Cloud 控制台启用,请先前往 Google Cloud 控制台菜单的 Vertex AI 部分:

在 Vertex AI 信息中心内,点击启用所有推荐的 API。
这将启用多个 API,但对于此 Codelab 而言,最重要的 API 是 aiplatform.googleapis.com。
或者,您也可以在 Cloud Shell 终端中使用以下命令启用此 API:
gcloud services enable aiplatform.googleapis.com
克隆 GitHub 代码库
在 Cloud Shell 终端中,克隆此 Codelab 的代码库:
git clone https://github.com/glaforge/gemini-workshop-for-java-developers.git
如需检查项目是否已准备就绪,您可以尝试运行“Hello World”程序。
确保您位于顶级文件夹中:
cd gemini-workshop-for-java-developers/
创建 Gradle 封装容器:
gradle wrapper
使用 gradlew 运行:
./gradlew run
您应该会看到以下输出内容:
.. > Task :app:run Hello World!
打开并设置 Cloud 编辑器
通过 Cloud Shell 使用 Cloud Code 编辑器打开代码:

在 Cloud Code 编辑器中,依次选择 File -> Open Folder,然后指向 Codelab 源代码文件夹(例如 /home/username/gemini-workshop-for-java-developers/)。
设置环境变量
在 Cloud Code 编辑器中,依次选择 Terminal -> New Terminal,打开新终端。设置运行代码示例所需的两个环境变量:
- PROJECT_ID - 您的 Google Cloud 项目 ID
- LOCATION - 部署 Gemini 模型的区域
按如下方式导出变量:
export PROJECT_ID=$(gcloud config get-value project) export LOCATION=us-central1
4. 首次调用 Gemini 模型
项目设置妥当后,就可以调用 Gemini API 了。
查看 app/src/main/java/gemini/workshop 目录中的 QA.java:
package gemini.workshop;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class QA {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
System.out.println(model.generate("Why is the sky blue?"));
}
}
在第一个示例中,您需要导入实现 ChatModel 接口的 VertexAiGeminiChatModel 类。
在 main 方法中,您可以使用 VertexAiGeminiChatModel 的构建器配置聊天语言模型,并指定:
- 项目
- 位置
- 模型名称 (
gemini-2.0-flash)。
现在语言模型已就绪,您可以调用 generate() 方法并传递提示、问题或指令,以发送到 LLM。在这里,您可以问一个简单的问题,即是什么让天空呈现蓝色。
您可以随意更改此提示,尝试提出不同的问题或执行不同的任务。
在源代码根文件夹中运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.QA
您应该会看到如下所示的输出:
The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight enters the atmosphere, it is made up of a mixture of different wavelengths of light, each with a different color. The different wavelengths of light interact with the molecules and particles in the atmosphere in different ways. The shorter wavelengths of light, such as those corresponding to blue and violet light, are more likely to be scattered in all directions by these particles than the longer wavelengths of light, such as those corresponding to red and orange light. This is because the shorter wavelengths of light have a smaller wavelength and are able to bend around the particles more easily. As a result of Rayleigh scattering, the blue light from the sun is scattered in all directions, and it is this scattered blue light that we see when we look up at the sky. The blue light from the sun is not actually scattered in a single direction, so the color of the sky can vary depending on the position of the sun in the sky and the amount of dust and water droplets in the atmosphere.
恭喜,您已首次调用 Gemini!
流式响应
您是否注意到,在几秒钟后,系统一次性给出了回答?借助流式响应变体,您还可以逐步获得响应。流式传输回答:模型会分段返回回答,并在生成一段回答后立即返回。
在此 Codelab 中,我们将继续使用非流式响应,但我们先来看看流式响应,了解如何实现。
在 app/src/main/java/gemini/workshop 目录中的 StreamQA.java 中,您可以看到流式响应的实际效果:
package gemini.workshop;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiStreamingChatModel;
import static dev.langchain4j.model.LambdaStreamingResponseHandler.onNext;
public class StreamQA {
public static void main(String[] args) {
StreamingChatLanguageModel model = VertexAiGeminiStreamingChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(4000)
.build();
model.generate("Why is the sky blue?", onNext(System.out::println));
}
}
这次,我们导入了实现 StreamingChatLanguageModel 接口的流式类变体 VertexAiGeminiStreamingChatModel。您还需要静态导入 LambdaStreamingResponseHandler.onNext,这是一个便捷方法,可提供 StreamingResponseHandler 来使用 Java lambda 表达式创建流式处理程序。
这次,generate() 方法的签名略有不同。返回值类型为 void,而不是返回字符串。除了提示之外,您还必须传递流式响应处理程序。在这里,得益于我们上面提到的静态导入,我们可以定义一个传递给 onNext() 方法的 lambda 表达式。每次有新的响应片段可用时,都会调用 lambda 表达式,而后者仅在发生错误时调用。
运行以下命令:
./gradlew run -q -DjavaMainClass=gemini.workshop.StreamQA
您会获得与上一个类类似的答案,但这次,您会注意到答案会逐步显示在 shell 中,而不是等待显示完整答案。
额外配置
对于配置,我们仅定义了项目、位置和模型名称,但您还可以为模型指定其他参数:
temperature(Float temp)- 用于定义您希望回答的创意程度(0 表示创意程度较低,通常更符合事实;2 表示创意程度较高)topP(Float topP)- 选择总概率之和达到该浮点数(介于 0 和 1 之间)的可能字词topK(Integer topK)- 从文本补全的最多数量的可能字词中随机选择一个字词(从 1 到 40)maxOutputTokens(Integer max)- 用于指定模型给出的答案的最大长度(一般来说,4 个 token 大约相当于 3 个字)maxRetries(Integer retries)- 如果您运行的请求超出了每次请求的配额,或者平台遇到了一些技术问题,您可以让模型重试调用 3 次
到目前为止,您只向 Gemini 提出了一个问题,但您也可以进行多轮对话。您将在下一部分中探讨相关内容。
5. 与 Gemini 对话
在上一步中,您提出了一个问题。现在,我们来模拟用户与 LLM 之间的真实对话。每个问题和答案都可以建立在前一个问题和答案的基础上,从而形成真实的讨论。
查看 app/src/main/java/gemini/workshop 文件夹中的 Conversation.java:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.service.AiServices;
import java.util.List;
public class Conversation {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
interface ConversationService {
String chat(String message);
}
ConversationService conversation =
AiServices.builder(ConversationService.class)
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
List.of(
"Hello!",
"What is the country where the Eiffel tower is situated?",
"How many inhabitants are there in that country?"
).forEach( message -> {
System.out.println("\nUser: " + message);
System.out.println("Gemini: " + conversation.chat(message));
});
}
}
此类中新增了几个有趣的导入:
MessageWindowChatMemory- 一个类,可帮助处理对话的多轮方面,并在本地内存中保留之前的问题和答案AiServices- 一种更高级别的抽象类,用于将聊天模型和聊天内存联系起来
在 main 方法中,您将设置模型、聊天记忆和 AI 服务。该模型会照常配置项目、位置和模型名称信息。
对于聊天记忆,我们使用 MessageWindowChatMemory 的构建器来创建一个记忆,该记忆会保留最近 20 条交换的消息。它是对话的滑动窗口,其上下文会保留在 Java 类客户端中。
然后,创建将聊天模型与聊天记忆绑定的 AI service。
请注意,AI 服务如何使用我们定义的自定义 ConversationService 接口(由 LangChain4j 实现),该接口接受 String 查询并返回 String 响应。
现在,您可以与 Gemini 对话了。首先,系统会发送一条简单的问候语,然后提出第一个问题,询问埃菲尔铁塔位于哪个国家/地区。请注意,最后一句话与第一个问题的答案相关,因为您想知道埃菲尔铁塔所在国家/地区有多少居民,但没有明确提及之前答案中给出的国家/地区。这表明,系统会在每次提示中发送过往的问题和答案。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.Conversation
您应该会看到三个类似于以下内容的答案:
User: Hello! Gemini: Hi there! How can I assist you today? User: What is the country where the Eiffel tower is situated? Gemini: France User: How many inhabitants are there in that country? Gemini: As of 2023, the population of France is estimated to be around 67.8 million.
您可以向 Gemini 提出单轮问题,也可以与 Gemini 进行多轮对话,但到目前为止,输入内容仅限于文本。图片呢?让我们在下一步中探索图片。
6. Gemini 的多模态
Gemini 是一种多模态模型。它不仅接受文本作为输入,还接受图片甚至视频作为输入。在本部分中,您将了解一个混合使用文本和图片的用例。
你认为 Gemini 会识别出这只猫吗?

雪地里猫咪的照片,来自维基百科
查看 app/src/main/java/gemini/workshop 目录中的 Multimodal.java:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.data.message.ImageContent;
import dev.langchain4j.data.message.TextContent;
public class Multimodal {
static final String CAT_IMAGE_URL =
"https://upload.wikimedia.org/wikipedia/" +
"commons/b/b6/Felis_catus-cat_on_snow.jpg";
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
UserMessage userMessage = UserMessage.from(
ImageContent.from(CAT_IMAGE_URL),
TextContent.from("Describe the picture")
);
Response<AiMessage> response = model.generate(userMessage);
System.out.println(response.content().text());
}
}
在导入中,请注意我们区分了不同类型的消息和内容。UserMessage 可以同时包含 TextContent 和 ImageContent 对象。这就是多模态的运用:混合文本和图片。我们不仅发送简单的字符串提示,还会发送一个更结构化的对象来表示用户消息,该对象由图片内容片段和文本内容片段组成。模型会发回一个包含 AiMessage 的 Response。
然后,您可以通过 content() 从响应中检索 AiMessage,并通过 text() 检索消息文本。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.Multimodal
图片名称确实提示了图片内容,但 Gemini 输出类似于以下内容:
A cat with brown fur is walking in the snow. The cat has a white patch of fur on its chest and white paws. The cat is looking at the camera.
混合使用图片和文字提示可实现有趣的应用场景。您可以创建能够执行以下操作的应用:
- 识别图片中的文字。
- 检查图片是否可以安全显示。
- 创建图片说明。
- 通过纯文本说明搜索图片数据库。
除了从图片中提取信息外,您还可以从非结构化文本中提取信息。这正是您将在下一部分中学习的内容。
7. 从非结构化文本中提取结构化信息
在许多情况下,报告文档、电子邮件或其他长篇文本中会以非结构化方式提供重要信息。理想情况下,您希望能够以结构化对象的形式提取非结构化文本中包含的关键细节。我们来看看如何实现这一点。
假设您想根据某人的个人简介、简历或描述来提取该人的姓名和年龄。您可以指示 LLM 通过巧妙调整的提示从非结构化文本中提取 JSON(这通常称为“提示工程”)。
但在以下示例中,我们不会精心设计描述 JSON 输出的提示,而是使用 Gemini 的一项强大的功能,即结构化输出(有时也称为受限生成),强制模型仅输出有效的 JSON 内容,并遵循指定的 JSON 架构。
不妨看看 app/src/main/java/gemini/workshop 中的 ExtractData.java:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import static dev.langchain4j.model.vertexai.SchemaHelper.fromClass;
public class ExtractData {
record Person(String name, int age) { }
interface PersonExtractor {
@SystemMessage("""
Your role is to extract the name and age
of the person described in the biography.
""")
Person extractPerson(String biography);
}
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.responseMimeType("application/json")
.responseSchema(fromClass(Person.class))
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
String bio = """
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
""";
Person person = extractor.extractPerson(bio);
System.out.println(person.name()); // Anna
System.out.println(person.age()); // 23
}
}
我们来看看此文件中的各个步骤:
- 定义了一个
Person记录来表示描述人员(姓名和年龄)的详细信息。 PersonExtractor接口定义了一个方法,该方法在给定非结构化文本字符串的情况下返回Person实例。extractPerson()带有@SystemMessage注释,该注释将指令提示与extractPerson()相关联。这是模型将用于指导信息提取的提示,并以 JSON 文档的形式返回详细信息,该文档将为您解析并解封到Person实例中。
现在,我们来看看 main() 方法的内容:
- 聊天模型已配置并实例化。我们使用了模型构建器类的 2 个新方法:
responseMimeType()和responseSchema()。第一个指令告诉 Gemini 在输出中生成有效的 JSON。第二种方法定义了应返回的 JSON 对象的架构。此外,后者会委托给一个便捷方法,该方法能够将 Java 类或记录转换为合适的 JSON 架构。 - 借助 LangChain4j 的
AiServices类,可以创建PersonExtractor对象。 - 然后,您只需调用
Person person = extractor.extractPerson(...)即可从非结构化文本中提取人员的详细信息,并返回包含姓名和年龄的Person实例。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.ExtractData
您应该会看到以下输出内容:
Anna 23
是的,我是 Anna,今年 23 岁!
使用这种 AiServices 方法时,您需要使用强类型对象。您不是直接与 LLM 互动。相反,您使用的是具体类,例如用于表示提取的个人信息的 Person 记录,并且您有一个包含 extractPerson() 方法的 PersonExtractor 对象,该方法会返回一个 Person 实例。LLM 的概念被抽象出来,作为 Java 开发者,您在使用此 PersonExtractor 接口时,只需操作常规类和对象。
8. 使用提示模板设计提示结构
当您使用一组通用指令或问题与 LLM 进行互动时,提示中有一部分内容始终不变,而其他部分则包含数据。例如,如果您想创建食谱,可以使用“你是一位才华横溢的厨师,请使用以下食材制作一份食谱:...”之类的提示,然后将食材附加到该文本的末尾。这就是提示模板的用途,它类似于编程语言中的插值字符串。提示模板包含占位符,您可以将这些占位符替换为针对特定 LLM 调用的正确数据。
更具体地说,我们来研究 app/src/main/java/gemini/workshop 目录中的 TemplatePrompt.java:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.output.Response;
import java.util.HashMap;
import java.util.Map;
public class TemplatePrompt {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(500)
.temperature(1.0f)
.topK(40)
.topP(0.95f)
.maxRetries(3)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
You're a friendly chef with a lot of cooking experience.
Create a recipe for a {{dish}} with the following ingredients: \
{{ingredients}}, and give it a name.
"""
);
Map<String, Object> variables = new HashMap<>();
variables.put("dish", "dessert");
variables.put("ingredients", "strawberries, chocolate, and whipped cream");
Prompt prompt = promptTemplate.apply(variables);
Response<AiMessage> response = model.generate(prompt.toUserMessage());
System.out.println(response.content().text());
}
}
与往常一样,您需要配置 VertexAiGeminiChatModel 模型,并使用较高的温度以及较高的 topP 和 topK 值来提高创意水平。然后,您可以使用 PromptTemplate 的 from() 静态方法创建一个 PromptTemplate,方法是传递提示字符串,并使用双大括号占位变量:{{dish}} 和 {{ingredients}}。
您可以通过调用 apply() 来创建最终提示,该函数接受一个键值对映射,其中包含占位符的名称以及要替换为的字符串值。
最后,您可以通过根据该提示创建包含 prompt.toUserMessage() 指令的用户消息,来调用 Gemini 模型的 generate() 方法。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.TemplatePrompt
您应该会看到类似于以下内容的生成输出:
**Strawberry Shortcake** Ingredients: * 1 pint strawberries, hulled and sliced * 1/2 cup sugar * 1/4 cup cornstarch * 1/4 cup water * 1 tablespoon lemon juice * 1/2 cup heavy cream, whipped * 1/4 cup confectioners' sugar * 1/4 teaspoon vanilla extract * 6 graham cracker squares, crushed Instructions: 1. In a medium saucepan, combine the strawberries, sugar, cornstarch, water, and lemon juice. Bring to a boil over medium heat, stirring constantly. Reduce heat and simmer for 5 minutes, or until the sauce has thickened. 2. Remove from heat and let cool slightly. 3. In a large bowl, combine the whipped cream, confectioners' sugar, and vanilla extract. Beat until soft peaks form. 4. To assemble the shortcakes, place a graham cracker square on each of 6 dessert plates. Top with a scoop of whipped cream, then a spoonful of strawberry sauce. Repeat layers, ending with a graham cracker square. 5. Serve immediately. **Tips:** * For a more elegant presentation, you can use fresh strawberries instead of sliced strawberries. * If you don't have time to make your own whipped cream, you can use store-bought whipped cream.
您可以随意更改地图中的 dish 和 ingredients 值,调整温度 topK 和 tokP,然后重新运行代码。这样,您就可以观察更改这些参数对 LLM 的影响。
提示模板是一种很好的方式,可为 LLM 调用提供可重复使用且可参数化的指令。您可以传递数据并针对用户提供的不同值自定义提示。
9. 使用少样本提示进行文本分类
LLM 非常擅长将文本分类到不同类别。您可以提供一些文本及其关联类别的示例,帮助 LLM 完成这项任务。这种方法通常称为少样本提示。
我们来打开 app/src/main/java/gemini/workshop 目录中的 TextClassification.java,以执行特定类型的文本分类:情感分析。
package gemini.workshop;
import com.google.cloud.vertexai.api.Schema;
import com.google.cloud.vertexai.api.Type;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import java.util.List;
public class TextClassification {
enum Sentiment { POSITIVE, NEUTRAL, NEGATIVE }
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(10)
.maxRetries(3)
.responseSchema(Schema.newBuilder()
.setType(Type.STRING)
.addAllEnum(List.of("POSITIVE", "NEUTRAL", "NEGATIVE"))
.build())
.build();
interface SentimentAnalysis {
@SystemMessage("""
Analyze the sentiment of the text below.
Respond only with one word to describe the sentiment.
""")
Sentiment analyze(String text);
}
MessageWindowChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);
memory.add(UserMessage.from("This is fantastic news!"));
memory.add(AiMessage.from(Sentiment.POSITIVE.name()));
memory.add(UserMessage.from("Pi is roughly equal to 3.14"));
memory.add(AiMessage.from(Sentiment.NEUTRAL.name()));
memory.add(UserMessage.from("I really disliked the pizza. Who would use pineapples as a pizza topping?"));
memory.add(AiMessage.from(Sentiment.NEGATIVE.name()));
SentimentAnalysis sentimentAnalysis =
AiServices.builder(SentimentAnalysis.class)
.chatLanguageModel(model)
.chatMemory(memory)
.build();
System.out.println(sentimentAnalysis.analyze("I love strawberries!"));
}
}
Sentiment 枚举列出了情感的不同值:负面、中性或正面。
在 main() 方法中,您像往常一样创建 Gemini 对话模型,但设置了较小的最大输出令牌数,因为您只需要简短的回答:文本为 POSITIVE、NEGATIVE 或 NEUTRAL。为了限制模型仅返回这些值,您可以利用在数据提取部分中发现的结构化输出支持。这就是使用 responseSchema() 方法的原因。这次,您不会使用 SchemaHelper 中的便捷方法来推断架构定义,而是使用 Schema 构建器来了解架构定义是什么样的。
配置模型后,您需要创建一个 SentimentAnalysis 接口,LangChain4j 的 AiServices 将使用 LLM 为您实现该接口。此接口包含一个方法:analyze()。它会接受要分析的文本作为输入,并返回 Sentiment 枚举值。因此,您只需操作表示已识别情感类别的强类型对象。
然后,为了提供“少样本示例”来促使模型执行分类工作,您需要创建一个聊天记忆,以传递用户消息和 AI 回答对,这些消息和回答对代表文本及其相关联的情感。
我们来使用 AiServices.builder() 方法将所有内容绑定在一起,方法是传递 SentimentAnalysis 接口、要使用的模型以及包含小样本示例的聊天记忆。最后,使用要分析的文本调用 analyze() 方法。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.TextClassification
您应该会看到一个字词:
POSITIVE
看来喜爱草莓是一种积极的情感!
10. 检索增强生成
LLM 基于大量文本进行训练。不过,它们的知识仅限于训练时所用的信息。如果模型训练截止日期之后发布了新信息,模型将无法获取这些详细信息。因此,模型将无法回答有关其未见过的信息的问题。
因此,本部分将介绍检索增强生成 (RAG) 等方法,这些方法有助于提供 LLM 可能需要了解的额外信息,以便满足用户请求,并提供可能更及时或在训练时无法访问的私密信息。
让我们回到对话。这次,您可以就文档内容提问。您将构建一个聊天机器人,该机器人能够从包含拆分为更小块(“块”)的文档的数据库中检索相关信息,并且模型将使用这些信息来为回答提供依据,而不是仅仅依赖于训练中包含的知识。
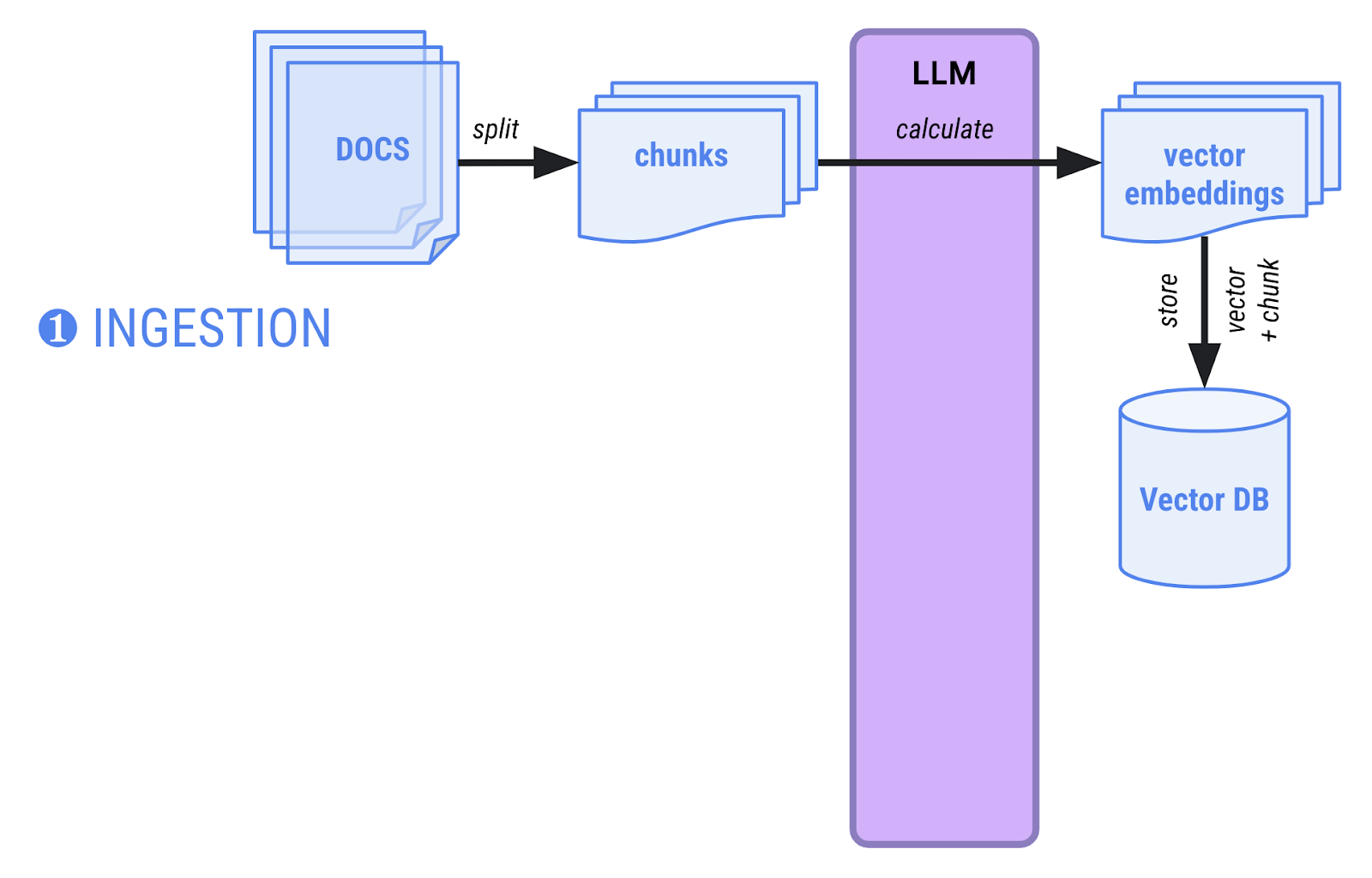
在 RAG 中,有两个阶段:
- 提取阶段 - 文档会加载到内存中,拆分为更小的块,并计算向量嵌入(块的高多维向量表示形式),然后存储在能够进行语义搜索的向量数据库中。此提取阶段通常在需要向文档语料库添加新文档时执行一次。
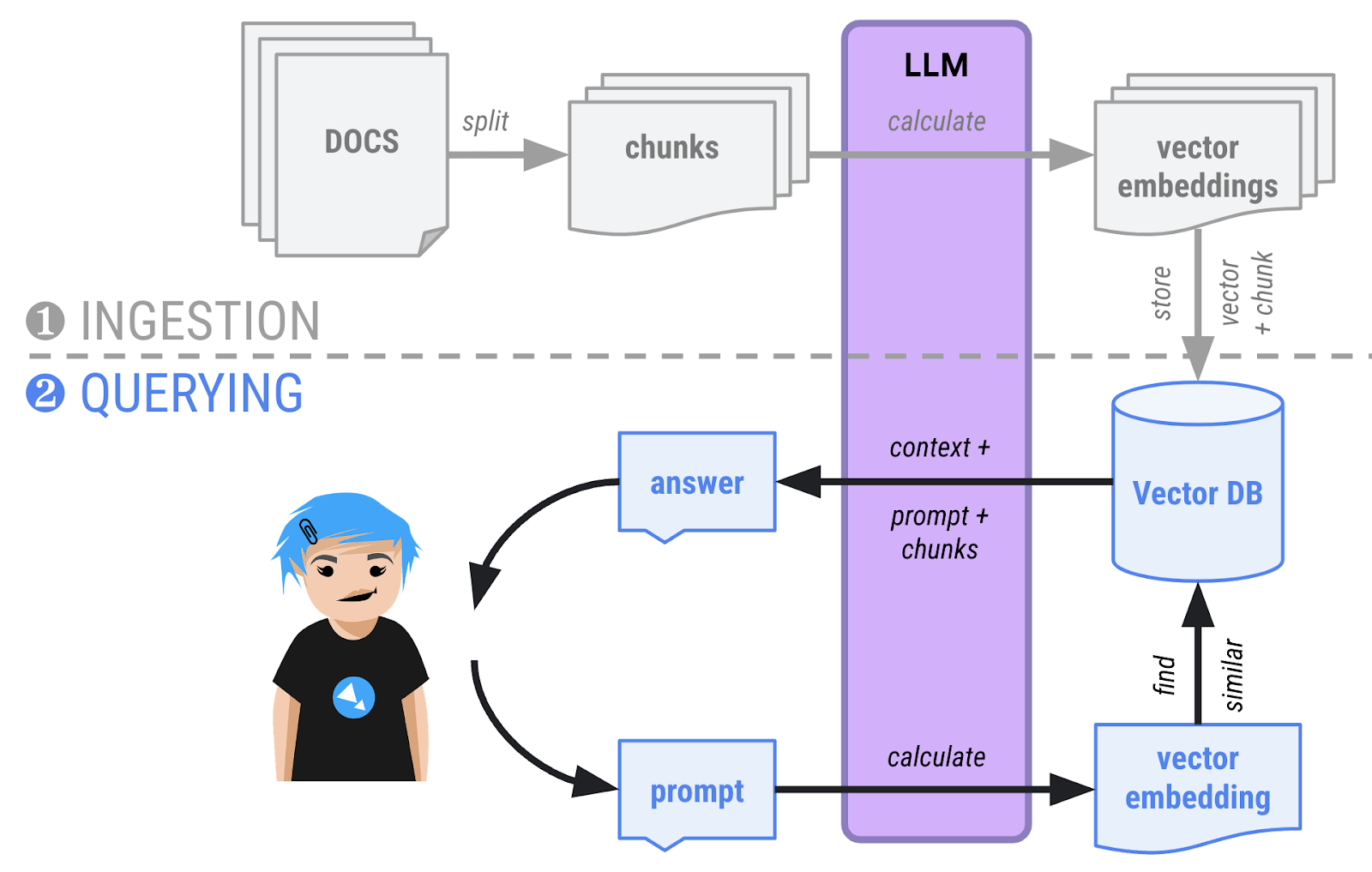
- 查询阶段 - 用户现在可以就文档提出问题。问题也会转换为向量,并与数据库中的所有其他向量进行比较。最相似的向量通常在语义上相关,并且由向量数据库返回。然后,系统会向 LLM 提供对话的上下文、与数据库返回的向量对应的文本块,并要求 LLM 通过查看这些文本块来确定回答。
准备好证件
在这个新示例中,您将询问有关虚构汽车制造商生产的虚构汽车型号“Cymbal Starlight”的问题!也就是说,有关虚构汽车的文档不应成为模型知识的一部分。因此,如果 Gemini 能够正确回答有关此汽车的问题,则意味着 RAG 方法有效:它能够搜索您的文档。
实现聊天机器人
接下来,我们来探讨如何构建两阶段方法:首先是文档提取,然后是查询时间(也称为“检索阶段”),即用户询问有关文档的问题时。
在此示例中,两个阶段都在同一类中实现。通常,您会有一个应用负责数据提取,另一个应用为用户提供聊天机器人界面。
此外,在此示例中,我们将使用内存中的向量数据库。在实际的生产场景中,注入阶段和查询阶段会分别在两个不同的应用中进行,并且向量会持久保存在独立的数据库中。
文档注入
文档注入阶段的第一步是找到有关虚构汽车的 PDF 文件,并准备一个 PdfParser 来读取该文件:
URL url = new URI("https://raw.githubusercontent.com/meteatamel/genai-beyond-basics/main/samples/grounding/vertexai-search/cymbal-starlight-2024.pdf").toURL();
ApachePdfBoxDocumentParser pdfParser = new ApachePdfBoxDocumentParser();
Document document = pdfParser.parse(url.openStream());
您不是先创建常规聊天语言模型,而是创建嵌入模型的实例。这是一种特殊模型,其作用是创建文本片段(字词、句子甚至段落)的向量表示。它返回的是浮点数向量,而不是文本响应。
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint(System.getenv("LOCATION") + "-aiplatform.googleapis.com:443")
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.publisher("google")
.modelName("text-embedding-005")
.maxRetries(3)
.build();
接下来,您需要一些类来协同完成以下任务:
- 加载 PDF 文档并将其拆分为块。
- 为所有这些分块创建向量嵌入。
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
系统会创建一个 InMemoryEmbeddingStore 实例(内存中的向量数据库)来存储向量嵌入。
借助 DocumentSplitters 类,文档可以拆分为多个块。它会将 PDF 文件的文本拆分为 500 个字符的片段,重叠 100 个字符(与后续块重叠,以避免将字词或句子拆分为零碎的片段)。
存储区提取器将文档拆分器、用于计算向量的嵌入模型和内存中向量数据库关联起来。然后,ingest() 方法将负责执行提取操作。
至此,第一阶段已结束,文档已转换为文本块及其关联的向量嵌入,并存储在向量数据库中。
提问
现在,准备好提问吧!创建聊天模型以开始对话:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(1000)
.build();
您还需要一个检索器类,用于将向量数据库(位于 embeddingStore 变量中)与嵌入模型相关联。其任务是通过计算用户查询的向量嵌入来查询向量数据库,以查找数据库中的相似向量:
EmbeddingStoreContentRetriever retriever =
new EmbeddingStoreContentRetriever(embeddingStore, embeddingModel);
创建一个表示汽车专家助理的接口,该接口是 AiServices 类将实现的接口,以便您与模型互动:
interface CarExpert {
Result<String> ask(String question);
}
CarExpert 接口会返回封装在 LangChain4j 的 Result 类中的字符串响应。为什么要使用此封装容器?因为不仅会给出答案,还会让您检查内容检索器从数据库中返回的块。这样,您就可以向用户显示用于为最终回答提供依据的文档的来源。
此时,您可以配置新的 AI 服务:
CarExpert expert = AiServices.builder(CarExpert.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(retriever)
.build();
此服务将以下内容绑定在一起:
- 您之前配置的聊天语言模型。
- 对话记忆,用于记录对话内容。
- 检索器会将向量嵌入查询与数据库中的向量进行比较。
.retrievalAugmentor(DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("""
You are an expert in car automotive, and you answer concisely.
Here is the question: {{userMessage}}
Answer using the following information:
{{contents}}
"""))
.build())
.contentRetriever(retriever)
.build())
您终于可以开始提问了!
List.of(
"What is the cargo capacity of Cymbal Starlight?",
"What's the emergency roadside assistance phone number?",
"Are there some special kits available on that car?"
).forEach(query -> {
Result<String> response = expert.ask(query);
System.out.printf("%n=== %s === %n%n %s %n%n", query, response.content());
System.out.println("SOURCE: " + response.sources().getFirst().textSegment().text());
});
完整源代码位于 app/src/main/java/gemini/workshop 目录中的 RAG.java 中。
运行示例:
./gradlew -q run -DjavaMainClass=gemini.workshop.RAG
在输出中,您应该会看到问题的答案:
=== What is the cargo capacity of Cymbal Starlight? === The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. SOURCE: Cargo The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of the vehicle. To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell. When loading cargo into the trunk, be sure to distribute the weight evenly. Do not overload the trunk, as this could affect the vehicle's handling and stability. Luggage === What's the emergency roadside assistance phone number? === The emergency roadside assistance phone number is 1-800-555-1212. SOURCE: Chapter 18: Emergencies Roadside Assistance If you experience a roadside emergency, such as a flat tire or a dead battery, you can call roadside assistance for help. Roadside assistance is available 24 hours a day, 7 days a week. To call roadside assistance, dial the following number: 1-800-555-1212 When you call roadside assistance, be prepared to provide the following information: Your name and contact information Your vehicle's make, model, and year Your vehicle's location === Are there some special kits available on that car? === Yes, the Cymbal Starlight comes with a tire repair kit. SOURCE: Lane keeping assist: This feature helps to keep you in your lane by gently steering the vehicle back into the lane if you start to drift. Adaptive cruise control: This feature automatically adjusts your speed to maintain a safe following distance from the vehicle in front of you. Forward collision warning: This feature warns you if you are approaching another vehicle too quickly. Automatic emergency braking: This feature can automatically apply the brakes to avoid a collision.
11. 函数调用
在某些情况下,您可能希望 LLM 能够访问外部系统,例如检索信息或执行操作的远程 Web API,或者执行某种计算的服务。例如:
远程 Web API:
- 跟踪和更新客户订单。
- 在问题跟踪器中查找或创建工单。
- 提取实时数据,例如股票报价或物联网传感器测量结果。
- 发送电子邮件。
计算工具:
- 适用于更高级数学问题的计算器。
- 当 LLM 需要推理逻辑时,用于运行代码的代码解释。
- 将自然语言请求转换为 SQL 查询,以便 LLM 可以查询数据库。
函数调用(有时称为工具或工具使用)是指模型能够代表用户请求进行一次或多次函数调用,以便使用更新鲜的数据正确回答用户的提示。
如果用户给出了特定提示,并且 LLM 知道哪些现有函数可能与该上下文相关,那么它可以回复函数调用请求。集成 LLM 的应用随后可以代表用户调用该函数,然后向 LLM 返回回答,而 LLM 随后会通过文本回答进行解释。
函数调用的四个步骤
我们来看一个函数调用示例:获取天气预报信息。
如果您向 Gemini 或任何其他 LLM 询问巴黎的天气,它们会回答说没有关于当前天气预报的信息。如果您希望 LLM 实时访问天气数据,则需要定义一些它可以请求使用的函数。
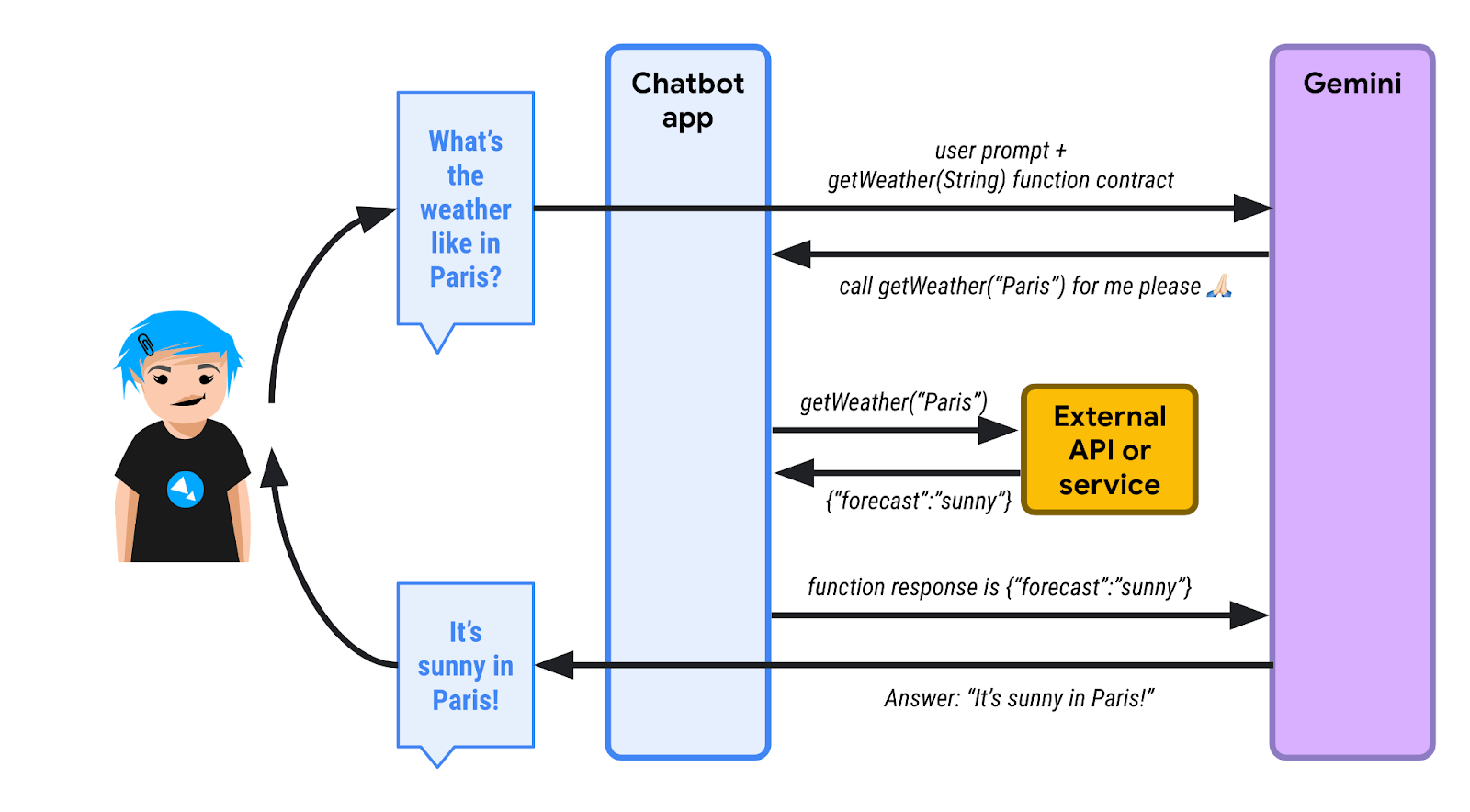
请看下图:

1️⃣ 首先,用户询问巴黎的天气。聊天机器人应用(使用 LangChain4j)知道它可以使用一个或多个函数来帮助 LLM 满足查询。聊天机器人会发送初始提示以及可调用的函数列表。在此示例中,有一个名为 getWeather() 的函数,该函数接受位置的字符串形参。

由于 LLM 不了解天气预报,因此它不会通过文本回复,而是会发送函数执行请求。聊天机器人必须使用 "Paris" 作为位置参数来调用 getWeather() 函数。
2️⃣ 聊天机器人代表 LLM 调用该函数,并检索函数响应。在此,我们假设响应为 {"forecast": "sunny"}。

3️⃣ 聊天机器人应用将 JSON 响应发送回 LLM。

4️⃣ LLM 查看 JSON 响应,解读该信息,最终回复“巴黎天气晴朗”。
以代码形式呈现的每个步骤
首先,您将像往常一样配置 Gemini 模型:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
您可以定义一个工具规范,用于描述可调用的函数:
ToolSpecification weatherToolSpec = ToolSpecification.builder()
.name("getWeather")
.description("Get the weather forecast for a given location or city")
.parameters(JsonObjectSchema.builder()
.addStringProperty(
"location",
"the location or city to get the weather forecast for")
.build())
.build();
定义了函数的名称以及参数的名称和类型,但请注意,函数和参数都给出了说明。说明非常重要,有助于 LLM 真正了解函数的功能,从而判断是否需要在对话上下文中调用该函数。
我们先从第 1 步开始,发送有关巴黎天气的初始问题:
List<ChatMessage> allMessages = new ArrayList<>();
// 1) Ask the question about the weather
UserMessage weatherQuestion = UserMessage.from("What is the weather in Paris?");
allMessages.add(weatherQuestion);
在第 2 步中,我们传递了希望模型使用的工具,模型回复了一个工具执行请求:
// 2) The model replies with a function call request
Response<AiMessage> messageResponse = model.generate(allMessages, weatherToolSpec);
ToolExecutionRequest toolExecutionRequest = messageResponse.content().toolExecutionRequests().getFirst();
System.out.println("Tool execution request: " + toolExecutionRequest);
allMessages.add(messageResponse.content());
第 3 步。此时,我们知道 LLM 希望我们调用哪个函数。在代码中,我们没有真正调用外部 API,而是直接返回假设的天气预报:
// 3) We send back the result of the function call
ToolExecutionResultMessage toolExecResMsg = ToolExecutionResultMessage.from(toolExecutionRequest,
"{\"location\":\"Paris\",\"forecast\":\"sunny\", \"temperature\": 20}");
allMessages.add(toolExecResMsg);
在第 4 步中,LLM 会了解函数执行结果,然后合成文本响应:
// 4) The model answers with a sentence describing the weather
Response<AiMessage> weatherResponse = model.generate(allMessages);
System.out.println("Answer: " + weatherResponse.content().text());
完整源代码位于 app/src/main/java/gemini/workshop 目录中的 FunctionCalling.java 中。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCalling
您应该会看到类似于如下内容的输出:
Tool execution request: ToolExecutionRequest { id = null, name = "getWeatherForecast", arguments = "{"location":"Paris"}" }
Answer: The weather in Paris is sunny with a temperature of 20 degrees Celsius.
在上面的输出中,您可以看到工具执行请求以及答案。
12. LangChain4j 处理函数调用
在上一步中,您了解了常规文本问题/回答和函数请求/响应互动是如何交织在一起的,并且在两者之间,您直接提供了所请求的函数响应,而无需调用实际函数。
不过,LangChain4j 还提供了一种更高级别的抽象,可以透明地处理函数调用,同时像往常一样处理对话。
单次函数调用
让我们来逐一了解 FunctionCallingAssistant.java。
首先,您需要创建一个记录来表示函数的响应数据结构:
record WeatherForecast(String location, String forecast, int temperature) {}
响应包含有关位置、天气预报和温度的信息。
然后,您创建一个包含要提供给模型的实际函数的类:
static class WeatherForecastService {
@Tool("Get the weather forecast for a location")
WeatherForecast getForecast(@P("Location to get the forecast for") String location) {
if (location.equals("Paris")) {
return new WeatherForecast("Paris", "Sunny", 20);
} else if (location.equals("London")) {
return new WeatherForecast("London", "Rainy", 15);
} else {
return new WeatherForecast("Unknown", "Unknown", 0);
}
}
}
请注意,此类包含单个函数,但使用 @Tool 注释进行了注释,该注释对应于模型可以请求调用的函数的说明。
函数的形参(此处为单个形参)也带有注释,但使用的是简短的 @P 注释,该注释还提供了形参的说明。您可以根据需要添加任意数量的函数,以便模型在更复杂的场景中使用这些函数。
在此类中,您会返回一些预设的响应,但如果您想调用真正的外部天气预报服务,则需要在该方法的正文中调用该服务。
正如我们在之前的方法中创建 ToolSpecification 时所见,记录函数的作用并描述参数的对应关系非常重要。这有助于模型了解如何以及何时使用此函数。
接下来,LangChain4j 可让您提供与您想要用于与模型交互的合约对应的接口。在此示例中,这是一个简单的接口,可接收表示用户消息的字符串,并返回与模型回答对应的字符串:
interface WeatherAssistant {
String chat(String userMessage);
}
如果您想处理更复杂的情况,也可以使用涉及 LangChain4j 的 UserMessage(针对用户消息)或 AiMessage(针对模型响应)甚至 TokenStream 的更复杂的签名,因为这些更复杂的对象还包含额外的信息,例如消耗的令牌数量等。不过,为简单起见,我们只接受字符串输入,并输出字符串。
最后,我们来实现将所有部分串联起来的 main() 方法:
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
WeatherForecastService weatherForecastService = new WeatherForecastService();
WeatherAssistant assistant = AiServices.builder(WeatherAssistant.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.tools(weatherForecastService)
.build();
System.out.println(assistant.chat("What is the weather in Paris?"));
System.out.println(assistant.chat("Is it warmer in London or in Paris?"));
}
与往常一样,您需要配置 Gemini 对话模型。然后,您将实例化天气预报服务,其中包含模型将请求我们调用的“函数”。
现在,您再次使用 AiServices 类来绑定聊天模型、聊天记忆和工具(即天气预报服务及其函数)。AiServices 会返回一个实现您定义的 WeatherAssistant 接口的对象。剩下的唯一任务就是调用该助理的 chat() 方法。调用该模型时,您只会看到文本回答,但开发者不会看到函数调用请求和函数调用回答,这些请求将自动透明地处理。如果 Gemini 认为应该调用某个函数,它会回复函数调用请求,而 LangChain4j 会负责代表您调用本地函数。
运行示例:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCallingAssistant
您应该会看到类似于如下内容的输出:
OK. The weather in Paris is sunny with a temperature of 20 degrees.
It is warmer in Paris (20 degrees) than in London (15 degrees).
以上是单个函数的示例。
多次函数调用
您还可以使用多个函数,并让 LangChain4j 代表您处理多个函数调用。如需查看多函数示例,请参阅 MultiFunctionCallingAssistant.java。
它具有用于兑换币种的函数:
@Tool("Convert amounts between two currencies")
double convertCurrency(
@P("Currency to convert from") String fromCurrency,
@P("Currency to convert to") String toCurrency,
@P("Amount to convert") double amount) {
double result = amount;
if (fromCurrency.equals("USD") && toCurrency.equals("EUR")) {
result = amount * 0.93;
} else if (fromCurrency.equals("USD") && toCurrency.equals("GBP")) {
result = amount * 0.79;
}
System.out.println(
"convertCurrency(fromCurrency = " + fromCurrency +
", toCurrency = " + toCurrency +
", amount = " + amount + ") == " + result);
return result;
}
用于获取股票价值的另一个函数:
@Tool("Get the current value of a stock in US dollars")
double getStockPrice(@P("Stock symbol") String symbol) {
double result = 170.0 + 10 * new Random().nextDouble();
System.out.println("getStockPrice(symbol = " + symbol + ") == " + result);
return result;
}
另一个用于将百分比应用于给定金额的函数:
@Tool("Apply a percentage to a given amount")
double applyPercentage(@P("Initial amount") double amount, @P("Percentage between 0-100 to apply") double percentage) {
double result = amount * (percentage / 100);
System.out.println("applyPercentage(amount = " + amount + ", percentage = " + percentage + ") == " + result);
return result;
}
然后,您可以将所有这些函数与 MultiTools 类相结合,并提出诸如“AAPL 股价的 10%(从美元兑换为欧元)是多少?”之类的问题。
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
MultiTools multiTools = new MultiTools();
MultiToolsAssistant assistant = AiServices.builder(MultiToolsAssistant.class)
.chatLanguageModel(model)
.chatMemory(withMaxMessages(10))
.tools(multiTools)
.build();
System.out.println(assistant.chat(
"What is 10% of the AAPL stock price converted from USD to EUR?"));
}
按如下方式运行:
./gradlew run -q -DjavaMainClass=gemini.workshop.MultiFunctionCallingAssistant
您应该会看到多个被调用的函数:
getStockPrice(symbol = AAPL) == 172.8022224055534 convertCurrency(fromCurrency = USD, toCurrency = EUR, amount = 172.8022224055534) == 160.70606683716468 applyPercentage(amount = 160.70606683716468, percentage = 10.0) == 16.07060668371647 10% of the AAPL stock price converted from USD to EUR is 16.07060668371647 EUR.
面向代理
函数调用是 Gemini 等大语言模型的一项出色的扩展机制。这使我们能够构建更复杂的系统,通常称为“代理”或“AI 助理”。这些智能体可以通过外部 API 与外部世界互动,还可以与可能对外部环境产生副作用的服务(例如发送电子邮件、创建工单等)互动。
在创建如此强大的代理时,您应负责任地进行。在执行自动化操作之前,您应考虑采用人机协同模式。在设计与外部世界互动的 LLM 赋能的代理时,请务必考虑安全性。
13. 使用 Ollama 和 TestContainers 运行 Gemma
到目前为止,我们一直在使用 Gemini,但还有 Gemma,它是 Gemini 的小妹模型。
Gemma 是一系列先进的轻量级开放式模型,其开发采用了与 Gemini 模型相同的研究成果和技术。最新的 Gemma 模型是 Gemma3,提供 1B(纯文本)、4B、12B 和 27B 四个规格。这些模型的权重可免费获取,而且体积小巧,因此您可以自行运行,即使在笔记本电脑上或 Cloud Shell 中也可以运行。
如何运行 Gemma?
您可以通过多种方式运行 Gemma:在云端运行,通过 Vertex AI 一键运行,或通过 GKE 搭配一些 GPU 运行,但您也可以在本地运行。
在本地运行 Gemma 的一个不错的选择是使用 Ollama,借助该工具,您可以在本地机器上运行 Llama、Mistral 等小型模型。它类似于 Docker,但适用于 LLM。
按照适用于您操作系统的说明安装 Ollama。
如果您使用的是 Linux 环境,则需要在安装 Ollama 后先启用它。
ollama serve > /dev/null 2>&1 &
在本地安装后,您可以运行命令来拉取模型:
ollama pull gemma3:1b
等待拉取模型。此过程可能需要一段时间。
运行模型:
ollama run gemma3:1b
现在,您可以与模型互动:
>>> Hello! Hello! It's nice to hear from you. What can I do for you today?
如需退出提示,请按 Ctrl+D
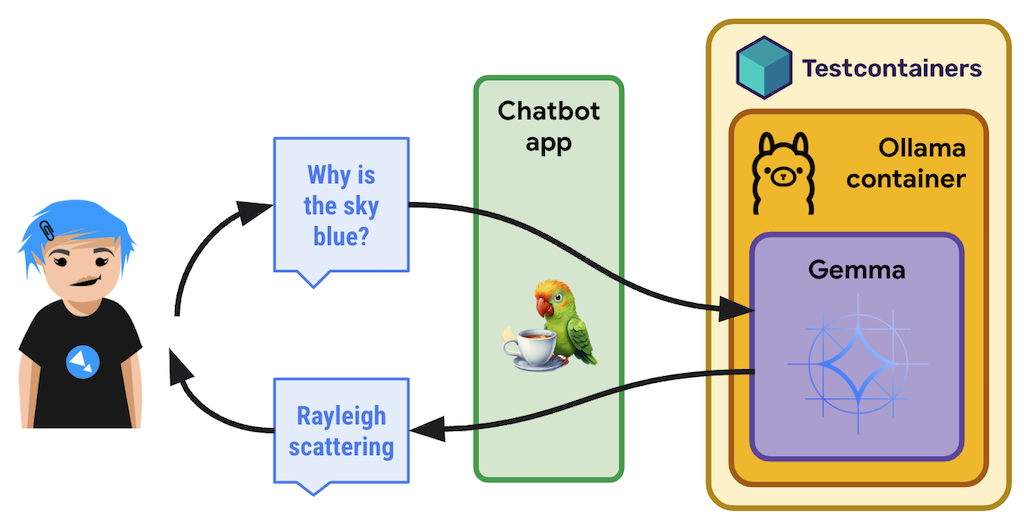
在 TestContainers 上使用 Ollama 运行 Gemma
您可以在由 TestContainers 处理的容器中使用 Ollama,而无需在本地安装和运行 Ollama。
TestContainers 不仅适用于测试,还可用于执行容器。您甚至还可以利用特定的 OllamaContainer!
以下是完整的情况:
实现
让我们来逐一了解 GemmaWithOllamaContainer.java。
首先,您需要创建一个派生的 Ollama 容器,用于拉取 Gemma 模型。此映像要么已存在(来自之前的运行),要么将被创建。如果映像已存在,您只需告知 TestContainers 您要将默认 Ollama 映像替换为基于 Gemma 的变体:
private static final String TC_OLLAMA_GEMMA3 = "tc-ollama-gemma3-1b";
public static final String GEMMA_3 = "gemma3:1b";
// Creating an Ollama container with Gemma 3 if it doesn't exist.
private static OllamaContainer createGemmaOllamaContainer() throws IOException, InterruptedException {
// Check if the custom Gemma Ollama image exists already
List<Image> listImagesCmd = DockerClientFactory.lazyClient()
.listImagesCmd()
.withImageNameFilter(TC_OLLAMA_GEMMA3)
.exec();
if (listImagesCmd.isEmpty()) {
System.out.println("Creating a new Ollama container with Gemma 3 image...");
OllamaContainer ollama = new OllamaContainer("ollama/ollama:0.7.1");
System.out.println("Starting Ollama...");
ollama.start();
System.out.println("Pulling model...");
ollama.execInContainer("ollama", "pull", GEMMA_3);
System.out.println("Committing to image...");
ollama.commitToImage(TC_OLLAMA_GEMMA3);
return ollama;
}
System.out.println("Ollama image substitution...");
// Substitute the default Ollama image with our Gemma variant
return new OllamaContainer(
DockerImageName.parse(TC_OLLAMA_GEMMA3)
.asCompatibleSubstituteFor("ollama/ollama"));
}
接下来,您需要创建并启动 Ollama 测试容器,然后创建一个 Ollama 聊天模型,方法是指定包含要使用的模型的容器的地址和端口。最后,只需像往常一样调用 model.generate(yourPrompt):
public static void main(String[] args) throws IOException, InterruptedException {
OllamaContainer ollama = createGemmaOllamaContainer();
ollama.start();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(String.format("http://%s:%d", ollama.getHost(), ollama.getFirstMappedPort()))
.modelName(GEMMA_3)
.build();
String response = model.generate("Why is the sky blue?");
System.out.println(response);
}
按如下方式运行:
./gradlew run -q -DjavaMainClass=gemini.workshop.GemmaWithOllamaContainer
首次运行时,系统需要一段时间来创建和运行容器,但完成后,您应该会看到 Gemma 做出响应:
INFO: Container ollama/ollama:0.7.1 started in PT7.228339916S
The sky appears blue due to Rayleigh scattering. Rayleigh scattering is a phenomenon that occurs when sunlight interacts with molecules in the Earth's atmosphere.
* **Scattering particles:** The main scattering particles in the atmosphere are molecules of nitrogen (N2) and oxygen (O2).
* **Wavelength of light:** Blue light has a shorter wavelength than other colors of light, such as red and yellow.
* **Scattering process:** When blue light interacts with these molecules, it is scattered in all directions.
* **Human eyes:** Our eyes are more sensitive to blue light than other colors, so we perceive the sky as blue.
This scattering process results in a blue appearance for the sky, even though the sun is actually emitting light of all colors.
In addition to Rayleigh scattering, other atmospheric factors can also influence the color of the sky, such as dust particles, aerosols, and clouds.
您已在 Cloud Shell 中运行 Gemma!
14. 恭喜
恭喜,您已使用 LangChain4j 和 Gemini API 成功构建了您的第一个 Java 生成式 AI 聊天应用!您在学习过程中发现,多模态大语言模型非常强大,能够处理各种任务,例如问答(即使是针对您自己的文档)、数据提取、与外部 API 互动等。
后续操作
现在,轮到您通过强大的 LLM 集成来增强应用了!