
1. परिचय
यह कोडलैब, Google Cloud पर Vertex AI पर होस्ट किए गए Gemini लार्ज लैंग्वेज मॉडल (एलएलएम) पर आधारित है. Vertex AI एक ऐसा प्लैटफ़ॉर्म है जिसमें Google Cloud पर मौजूद मशीन लर्निंग के सभी प्रॉडक्ट, सेवाएं, और मॉडल शामिल हैं.
आपको LangChain4j फ़्रेमवर्क का इस्तेमाल करके, Gemini API के साथ इंटरैक्ट करने के लिए Java का इस्तेमाल करना होगा. आपको कुछ उदाहरणों के बारे में बताया जाएगा, ताकि सवालों के जवाब पाने, आइडिया जनरेट करने, इकाई और स्ट्रक्चर्ड कॉन्टेंट निकालने, जानकारी के साथ जवाब जनरेट करने, और फ़ंक्शन कॉल करने के लिए एलएलएम का फ़ायदा उठाया जा सके.
जनरेटिव एआई क्या है?
जनरेटिव एआई का मतलब है, आर्टिफ़िशियल इंटेलिजेंस (एआई) का इस्तेमाल करके नया कॉन्टेंट बनाना. जैसे, टेक्स्ट, इमेज, संगीत, ऑडियो, और वीडियो.
जनरेटिव एआई, लार्ज लैंग्वेज मॉडल (एलएलएम) की मदद से काम करता है. ये मॉडल एक साथ कई टास्क पूरे कर सकते हैं. साथ ही, ये अलग-अलग तरह के काम कर सकते हैं. जैसे, खास जानकारी देना, सवाल-जवाब करना, क्लासिफ़िकेशन करना वगैरह. बुनियादी मॉडल को कम से कम ट्रेनिंग देकर, टारगेट किए गए इस्तेमाल के उदाहरणों के लिए अडॉप्ट किया जा सकता है. इसके लिए, उदाहरण के तौर पर बहुत कम डेटा की ज़रूरत होती है.
जनरेटिव एआई कैसे काम करता है?
जनरेटिव एआई, मशीन लर्निंग (एमएल) मॉडल का इस्तेमाल करके काम करता है. यह मॉडल, इंसानों के बनाए गए कॉन्टेंट के डेटासेट में मौजूद पैटर्न और संबंधों के बारे में जानकारी इकट्ठा करता है. इसके बाद, यह सीखे गए पैटर्न का इस्तेमाल करके नया कॉन्टेंट जनरेट करता है.
जनरेटिव एआई मॉडल को ट्रेनिंग देने का सबसे सामान्य तरीका, सुपरवाइज़्ड लर्निंग का इस्तेमाल करना है. मॉडल को, लोगों के बनाए गए कॉन्टेंट और उससे जुड़े लेबल का सेट दिया जाता है. इसके बाद, यह लोगों के बनाए गए कॉन्टेंट के जैसा कॉन्टेंट जनरेट करना सीखता है.
जनरेटिव एआई के सामान्य इस्तेमाल क्या हैं?
जनरेटिव एआई का इस्तेमाल इन कामों के लिए किया जा सकता है:
- बेहतर चैट और खोज के अनुभव के ज़रिए, ग्राहकों से इंटरैक्शन को बेहतर बनाएं.
- बातचीत वाले इंटरफ़ेस और खास जानकारी की मदद से, स्ट्रक्चर नहीं किए गए डेटा के बड़े हिस्से को एक्सप्लोर करें.
- बार-बार किए जाने वाले कामों में मदद करना. जैसे, प्रस्तावों के अनुरोधों का जवाब देना, मार्केटिंग कॉन्टेंट को अलग-अलग भाषाओं में स्थानीय भाषा के हिसाब से तैयार करना, और ग्राहकों के समझौतों की जांच करना, ताकि यह पता चल सके कि वे नियमों का पालन कर रहे हैं या नहीं.
Google Cloud में जनरेटिव एआई की कौनसी सुविधाएं उपलब्ध हैं?
Vertex AI की मदद से, फ़ाउंडेशन मॉडल के साथ इंटरैक्ट किया जा सकता है. साथ ही, उन्हें अपनी पसंद के मुताबिक बनाया जा सकता है और अपने ऐप्लिकेशन में एम्बेड किया जा सकता है. इसके लिए, आपको मशीन लर्निंग की बहुत कम या बिलकुल भी जानकारी होने की ज़रूरत नहीं है. Model Garden पर जाकर, फ़ाउंडेशन मॉडल ऐक्सेस किए जा सकते हैं. साथ ही, Vertex AI Studio पर मौजूद आसान यूज़र इंटरफ़ेस (यूआई) की मदद से, मॉडल को ट्यून किया जा सकता है. इसके अलावा, डेटा साइंस नोटबुक में मॉडल का इस्तेमाल किया जा सकता है.
Vertex AI Search and Conversation की मदद से, डेवलपर जनरेटिव एआई की मदद से काम करने वाले सर्च इंजन और चैटबॉट तेज़ी से बना सकते हैं.
Gemini की मदद से काम करने वाला Gemini for Google Cloud, एआई की मदद से काम करने वाला एक सहयोगी है. यह Google Cloud और IDEs पर उपलब्ध है. इससे आपको ज़्यादा काम कम समय में करने में मदद मिलती है. Gemini Code Assist की मदद से, कोड पूरा करने, कोड जनरेट करने, और कोड के बारे में जानकारी पाने में मदद मिलती है. साथ ही, इससे चैट करके तकनीकी सवाल पूछे जा सकते हैं.
Gemini क्या है?
Gemini, Google DeepMind के बनाए गए जनरेटिव एआई मॉडल का एक परिवार है. इसे मल्टीमॉडल इस्तेमाल के लिए डिज़ाइन किया गया है. मल्टीमॉडल का मतलब है कि यह अलग-अलग तरह के कॉन्टेंट को प्रोसेस और जनरेट कर सकता है. जैसे, टेक्स्ट, कोड, इमेज, और ऑडियो.

Gemini अलग-अलग वर्शन और साइज़ में उपलब्ध है:
- Gemini 2.0 Flash: इसमें अगली पीढ़ी की नई सुविधाएँ और बेहतर क्षमताएँ हैं.
- Gemini 2.0 Flash-Lite: यह Gemini 2.0 Flash मॉडल है. इसे कम लागत और कम समय में जवाब देने के लिए ऑप्टिमाइज़ किया गया है.
- Gemini 2.5 Pro: यह अब तक का हमारा सबसे ऐडवांस रीज़निंग मॉडल है.
- Gemini 2.5 Flash: यह एक थिंकिंग मॉडल है, जिसमें कई तरह की सुविधाएँ उपलब्ध हैं. इसे कीमत और परफ़ॉर्मेंस के बीच संतुलन बनाए रखने के लिए डिज़ाइन किया गया है.
मुख्य सुविधाएं:
- मल्टीमॉडल: Gemini, जानकारी के कई फ़ॉर्मैट को समझ सकता है और उन्हें हैंडल कर सकता है. यह सिर्फ़ टेक्स्ट वाले पारंपरिक लैंग्वेज मॉडल से काफ़ी बेहतर है.
- परफ़ॉर्मेंस: Gemini 2.5 Pro, कई बेंचमार्क पर मौजूदा समय के सबसे बेहतरीन मॉडल से बेहतर परफ़ॉर्म करता है. यह पहला ऐसा मॉडल है जिसने मुश्किल एमएमएलयू (मैसिव मल्टीटास्क लैंग्वेज अंडरस्टैंडिंग) बेंचमार्क में, विशेषज्ञों से ज़्यादा स्कोर किया है.
- लचीलापन: Gemini के अलग-अलग साइज़ होने की वजह से, इसे कई तरह के कामों के लिए इस्तेमाल किया जा सकता है. जैसे, बड़े पैमाने पर रिसर्च करना और मोबाइल डिवाइसों पर इसे डिप्लॉय करना.
Java से Vertex AI पर Gemini के साथ कैसे इंटरैक्ट किया जा सकता है?
आपके पास दो विकल्प हैं:
- Gemini के लिए Vertex AI Java API की आधिकारिक लाइब्रेरी.
- LangChain4j फ़्रेमवर्क.
इस कोडलैब में, LangChain4j फ़्रेमवर्क का इस्तेमाल किया जाएगा.
LangChain4j फ़्रेमवर्क क्या है?
LangChain4j फ़्रेमवर्क, ओपन सोर्स लाइब्रेरी है. इसका इस्तेमाल, Java ऐप्लिकेशन में एलएलएम को इंटिग्रेट करने के लिए किया जाता है. इसके लिए, यह एलएलएम के साथ-साथ कई अन्य कॉम्पोनेंट को व्यवस्थित करता है. जैसे, वेक्टर डेटाबेस (सिमेंटिक सर्च के लिए), दस्तावेज़ लोड करने वाले और स्प्लिटर (दस्तावेज़ों का विश्लेषण करने और उनसे सीखने के लिए), आउटपुट पार्सर वगैरह.
यह प्रोजेक्ट, LangChain Python प्रोजेक्ट से प्रेरित है. हालांकि, इसका मकसद Java डेवलपर की मदद करना है.

आपको क्या सीखने को मिलेगा
- Gemini और LangChain4j का इस्तेमाल करने के लिए, Java प्रोजेक्ट को कैसे सेट अप करें
- प्रोग्राम के ज़रिए Gemini को पहला प्रॉम्प्ट भेजने का तरीका
- Gemini से मिले जवाबों को स्ट्रीम करने का तरीका
- किसी उपयोगकर्ता और Gemini के बीच बातचीत कैसे शुरू करें
- टेक्स्ट और इमेज, दोनों भेजकर Gemini का इस्तेमाल कैसे करें
- अनस्ट्रक्चर्ड कॉन्टेंट से काम की स्ट्रक्चर्ड जानकारी निकालने का तरीका
- प्रॉम्प्ट टेंप्लेट में बदलाव करने का तरीका
- टेक्स्ट को कैटगरी में बांटने का तरीका, जैसे कि भावना का विश्लेषण करना
- अपने दस्तावेज़ों के साथ चैट करने का तरीका (रीट्रिवल ऑगमेंटेड जनरेशन)
- फ़ंक्शन कॉलिंग की मदद से, अपने चैटबॉट की क्षमताओं को बढ़ाने का तरीका
- Ollama और TestContainers के साथ, स्थानीय तौर पर Gemma का इस्तेमाल करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Java प्रोग्रामिंग लैंग्वेज की जानकारी
- Google Cloud प्रोजेक्ट
- Chrome या Firefox जैसे ब्राउज़र
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.



- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलेगा. वे इसे मुफ़्त में आज़मा सकते हैं.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऑपरेट किया जा सकता है. हालांकि, इस कोडलैब में Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Cloud Shell चालू करें
- Cloud Console में, Cloud Shell चालू करें
 पर क्लिक करें.
पर क्लिक करें.

अगर आपने Cloud Shell को पहली बार शुरू किया है, तो आपको एक इंटरमीडिएट स्क्रीन दिखेगी. इसमें Cloud Shell के बारे में जानकारी दी गई होगी. अगर आपको इंटरमीडिएट स्क्रीन दिखती है, तो जारी रखें पर क्लिक करें.

Cloud Shell से कनेक्ट होने में कुछ ही सेकंड लगेंगे.

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है, जो हमेशा बनी रहती है. साथ ही, यह Google Cloud में काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में ज़्यादातर काम ब्राउज़र से किया जा सकता है.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि हो गई है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट कर दिया गया है.
- पुष्टि करें कि आपने Cloud Shell में पुष्टि कर ली है. इसके लिए, यह कमांड चलाएं:
gcloud auth list
कमांड आउटपुट
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं:
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर ऐसा नहीं है, तो इस कमांड का इस्तेमाल करके इसे सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
कमांड आउटपुट
Updated property [core/project].
3. आपका डेवलपमेंट एनवायरमेंट तैयार किया जा रहा है
इस कोडलैब में, Cloud Shell टर्मिनल और Cloud Shell एडिटर का इस्तेमाल करके, Java प्रोग्राम डेवलप किए जाएँगे.
Vertex AI API चालू करना
Google Cloud Console में, पक्का करें कि आपके प्रोजेक्ट का नाम, Google Cloud Console में सबसे ऊपर दिख रहा हो. अगर ऐसा नहीं है, तो प्रोजेक्ट चुनने वाला टूल खोलने के लिए, कोई प्रोजेक्ट चुनें पर क्लिक करें. इसके बाद, अपना पसंदीदा प्रोजेक्ट चुनें.
Google Cloud Console के Vertex AI सेक्शन से या Cloud Shell टर्मिनल से, Vertex AI API चालू किए जा सकते हैं.
Google Cloud Console से इसे चालू करने के लिए, सबसे पहले Google Cloud Console मेन्यू के Vertex AI सेक्शन पर जाएं:

Vertex AI डैशबोर्ड में, सुझाए गए सभी एपीआई चालू करें पर क्लिक करें.
इससे कई एपीआई चालू हो जाएंगे. हालांकि, इस कोडलैब के लिए सबसे ज़रूरी एपीआई aiplatform.googleapis.com है.
इसके अलावा, इस एपीआई को Cloud Shell टर्मिनल से भी चालू किया जा सकता है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud services enable aiplatform.googleapis.com
GitHub रिपॉज़िटरी को क्लोन करें
Cloud Shell टर्मिनल में, इस कोडलैब के लिए रिपॉज़िटरी को क्लोन करें:
git clone https://github.com/glaforge/gemini-workshop-for-java-developers.git
यह देखने के लिए कि प्रोजेक्ट चलाने के लिए तैयार है या नहीं, "Hello World" प्रोग्राम चलाकर देखें.
पक्का करें कि आप सबसे ऊपर वाले फ़ोल्डर में हों:
cd gemini-workshop-for-java-developers/
Gradle रैपर बनाएं:
gradle wrapper
gradlew के साथ दौड़ें:
./gradlew run
आपको यह आउटपुट दिखेगा:
.. > Task :app:run Hello World!
Cloud Editor खोलना और उसे सेटअप करना
Cloud Shell में Cloud Code Editor की मदद से कोड खोलें:

Cloud Code Editor में, कोडलैब का सोर्स फ़ोल्डर खोलें. इसके लिए, File -> Open Folder को चुनें और कोडलैब के सोर्स फ़ोल्डर (जैसे कि /home/username/gemini-workshop-for-java-developers/).
एनवायरमेंट वैरिएबल सेट अप करना
Terminal -> New Terminal को चुनकर, Cloud Code Editor में नया टर्मिनल खोलें. कोड के उदाहरणों को चलाने के लिए ज़रूरी दो एनवायरमेंट वैरिएबल सेट अप करें:
- PROJECT_ID — आपका Google Cloud प्रोजेक्ट आईडी
- LOCATION — वह इलाका जहां Gemini मॉडल को डिप्लॉय किया गया है
वैरिएबल को इस तरह एक्सपोर्ट करें:
export PROJECT_ID=$(gcloud config get-value project) export LOCATION=us-central1
4. Gemini मॉडल को पहली बार कॉल करना
प्रोजेक्ट को सही तरीके से सेट अप करने के बाद, अब Gemini API को कॉल करने का समय है.
app/src/main/java/gemini/workshop डायरेक्ट्री में मौजूद QA.java को देखें:
package gemini.workshop;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class QA {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
System.out.println(model.generate("Why is the sky blue?"));
}
}
इस पहले उदाहरण में, आपको VertexAiGeminiChatModel क्लास को इंपोर्ट करना होगा. यह VertexAiGeminiChatModel इंटरफ़ेस को लागू करता है.ChatModel
main तरीके में, VertexAiGeminiChatModel के लिए बिल्डर का इस्तेमाल करके, चैट लैंग्वेज मॉडल को कॉन्फ़िगर किया जाता है. साथ ही, यह जानकारी दी जाती है:
- प्रोजेक्ट
- जगह
- मॉडल का नाम (
gemini-2.0-flash).
अब भाषा मॉडल तैयार है. इसलिए, generate() तरीके को कॉल किया जा सकता है. साथ ही, एलएलएम को भेजने के लिए अपना प्रॉम्प्ट, सवाल या निर्देश पास किए जा सकते हैं. यहां, आपने एक आसान सवाल पूछा है कि आसमान नीला क्यों दिखता है.
अलग-अलग सवाल पूछने या टास्क आज़माने के लिए, इस प्रॉम्प्ट को बेझिझक बदलें.
सोर्स कोड के रूट फ़ोल्डर में सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.QA
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight enters the atmosphere, it is made up of a mixture of different wavelengths of light, each with a different color. The different wavelengths of light interact with the molecules and particles in the atmosphere in different ways. The shorter wavelengths of light, such as those corresponding to blue and violet light, are more likely to be scattered in all directions by these particles than the longer wavelengths of light, such as those corresponding to red and orange light. This is because the shorter wavelengths of light have a smaller wavelength and are able to bend around the particles more easily. As a result of Rayleigh scattering, the blue light from the sun is scattered in all directions, and it is this scattered blue light that we see when we look up at the sky. The blue light from the sun is not actually scattered in a single direction, so the color of the sky can vary depending on the position of the sun in the sky and the amount of dust and water droplets in the atmosphere.
बधाई हो, आपने Gemini से पहली बार कॉल किया!
जवाब को स्ट्रीम करना
क्या आपने ध्यान दिया कि जवाब कुछ सेकंड के बाद एक साथ दिया गया था? स्ट्रीमिंग रिस्पॉन्स वैरिएंट की मदद से, जवाब को धीरे-धीरे भी पाया जा सकता है. स्ट्रीमिंग रिस्पॉन्स में, मॉडल जवाब को एक साथ नहीं, बल्कि टुकड़ों में दिखाता है.
इस कोडलैब में, हम स्ट्रीमिंग के बिना जवाब देने की सुविधा का इस्तेमाल करेंगे. हालांकि, स्ट्रीमिंग के साथ जवाब देने की सुविधा को इस्तेमाल करने का तरीका जानने के लिए, आइए इस सुविधा पर एक नज़र डालें.
app/src/main/java/gemini/workshop डायरेक्ट्री में मौजूद StreamQA.java में, स्ट्रीमिंग के जवाब को ऐक्शन में देखा जा सकता है:
package gemini.workshop;
import dev.langchain4j.model.chat.StreamingChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiStreamingChatModel;
import static dev.langchain4j.model.LambdaStreamingResponseHandler.onNext;
public class StreamQA {
public static void main(String[] args) {
StreamingChatLanguageModel model = VertexAiGeminiStreamingChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(4000)
.build();
model.generate("Why is the sky blue?", onNext(System.out::println));
}
}
इस बार, हम स्ट्रीमिंग क्लास के उन वैरिएंट को इंपोर्ट करते हैं VertexAiGeminiStreamingChatModel जो StreamingChatLanguageModel इंटरफ़ेस को लागू करते हैं. आपको LambdaStreamingResponseHandler.onNext को स्टैटिक इंपोर्ट करने की भी ज़रूरत होगी. यह एक सुविधाजनक तरीका है, जो Java lambda एक्सप्रेशन के साथ स्ट्रीमिंग हैंडलर बनाने के लिए StreamingResponseHandler उपलब्ध कराता है.
इस बार, generate() तरीके का सिग्नेचर थोड़ा अलग है. स्ट्रिंग के बजाय, रिटर्न टाइप शून्य है. प्रॉम्प्ट के अलावा, आपको स्ट्रीमिंग रिस्पॉन्स हैंडलर भी पास करना होगा. यहां, ऊपर बताए गए स्टैटिक इंपोर्ट की मदद से, हम एक लैम्डा एक्सप्रेशन तय कर सकते हैं. इसे onNext() तरीके से पास किया जाता है. जब भी जवाब का कोई नया हिस्सा उपलब्ध होता है, तब लैम्ब्डा एक्सप्रेशन को कॉल किया जाता है. वहीं, बाद वाले को सिर्फ़ तब कॉल किया जाता है, जब कोई गड़बड़ी होती है.
रन:
./gradlew run -q -DjavaMainClass=gemini.workshop.StreamQA
आपको पिछली क्लास जैसा ही जवाब मिलेगा. हालांकि, इस बार आपको दिखेगा कि पूरा जवाब दिखने के बजाय, जवाब धीरे-धीरे आपकी शेल में दिखता है.
अतिरिक्त कॉन्फ़िगरेशन
कॉन्फ़िगरेशन के लिए, हमने सिर्फ़ प्रोजेक्ट, जगह, और मॉडल का नाम तय किया है. हालांकि, मॉडल के लिए अन्य पैरामीटर भी तय किए जा सकते हैं:
temperature(Float temp)— इससे यह तय किया जाता है कि आपको जवाब कितना क्रिएटिव चाहिए. 0 का मतलब है कि जवाब में क्रिएटिविटी कम होगी और उसमें ज़्यादातर तथ्य शामिल होंगे. वहीं, 2 का मतलब है कि जवाब ज़्यादा क्रिएटिव होगाtopP(Float topP)— उन संभावित शब्दों को चुनने के लिए जिनकी कुल संभावना, फ़्लोटिंग पॉइंट नंबर (0 से 1 के बीच) के बराबर होती हैtopK(Integer topK)— इसका इस्तेमाल, टेक्स्ट पूरा करने के लिए संभावित शब्दों में से किसी एक शब्द को चुनने के लिए किया जाता है. इसकी वैल्यू 1 से 40 तक हो सकती हैmaxOutputTokens(Integer max)— मॉडल के जवाब की ज़्यादा से ज़्यादा लंबाई तय करने के लिए (आम तौर पर, चार टोकन का मतलब करीब तीन शब्द होता है)maxRetries(Integer retries)— अगर आपने तय समय में अनुरोध करने के कोटे से ज़्यादा अनुरोध किए हैं या प्लैटफ़ॉर्म में कोई तकनीकी समस्या आ रही है, तो मॉडल को कॉल करने के लिए तीन बार फिर से कोशिश करने का विकल्प दिया जा सकता है
अब तक आपने Gemini से सिर्फ़ एक सवाल पूछा है. हालाँकि, आपके पास एक से ज़्यादा बार बातचीत करने का विकल्प भी है. अगले सेक्शन में, आपको इसी के बारे में जानकारी मिलेगी.
5. Gemini के साथ चैट करें
पिछले चरण में, आपने एक सवाल पूछा था. अब समय है कि कोई उपयोगकर्ता और एलएलएम आपस में बातचीत करें. हर सवाल और जवाब, पिछले सवालों और जवाबों के आधार पर तैयार किए जा सकते हैं, ताकि एक असली बातचीत हो सके.
app/src/main/java/gemini/workshop फ़ोल्डर में मौजूद Conversation.java को देखें:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.service.AiServices;
import java.util.List;
public class Conversation {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
interface ConversationService {
String chat(String message);
}
ConversationService conversation =
AiServices.builder(ConversationService.class)
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
List.of(
"Hello!",
"What is the country where the Eiffel tower is situated?",
"How many inhabitants are there in that country?"
).forEach( message -> {
System.out.println("\nUser: " + message);
System.out.println("Gemini: " + conversation.chat(message));
});
}
}
इस क्लास में कुछ नई और दिलचस्प चीज़ें इंपोर्ट की गई हैं:
MessageWindowChatMemory— यह एक ऐसी क्लास है जो बातचीत के कई चरणों को मैनेज करने में मदद करेगी. साथ ही, पिछले सवालों और जवाबों को लोकल मेमोरी में सेव रखेगीAiServices— यह एक हायर-लेवल ऐब्स्ट्रैक्शन क्लास है. यह चैट मॉडल और चैट मेमोरी को एक साथ जोड़ेगी
मुख्य तरीके में, आपको मॉडल, चैट मेमोरी, और एआई सेवा सेट अप करनी होगी. मॉडल को प्रोजेक्ट, जगह, और मॉडल के नाम की जानकारी के साथ हमेशा की तरह कॉन्फ़िगर किया जाता है.
चैट मेमोरी के लिए, हम MessageWindowChatMemory के बिल्डर का इस्तेमाल करते हैं. इससे एक ऐसी मेमोरी बनती है जिसमें पिछले 20 मैसेज सेव रहते हैं. यह बातचीत के दौरान स्लाइडिंग विंडो होती है. इसका कॉन्टेक्स्ट, हमारे Java क्लास क्लाइंट में स्थानीय तौर पर सेव किया जाता है.
इसके बाद, AI service बनाया जाता है. यह चैट मॉडल को चैट मेमोरी से जोड़ता है.
ध्यान दें कि एआई सेवा, हमारे तय किए गए कस्टम ConversationService इंटरफ़ेस का इस्तेमाल करती है. इसे LangChain4j लागू करता है. यह String क्वेरी लेता है और String जवाब देता है.
अब Gemini से बातचीत करने का समय है. सबसे पहले, एक सामान्य बधाई संदेश भेजा जाता है. इसके बाद, आइफ़िल टावर के बारे में पहला सवाल पूछा जाता है, ताकि यह पता चल सके कि यह किस देश में है. ध्यान दें कि आखिरी वाक्य, पहले सवाल के जवाब से जुड़ा है. इसमें पूछा गया है कि आइफ़िल टावर वाले देश में कितने लोग रहते हैं. हालांकि, इसमें उस देश का नाम साफ़ तौर पर नहीं बताया गया है जिसका नाम पिछले जवाब में दिया गया था. इससे पता चलता है कि पिछले सवालों और जवाबों को हर प्रॉम्प्ट के साथ भेजा जाता है.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.Conversation
आपको इन जैसे तीन जवाब दिखेंगे:
User: Hello! Gemini: Hi there! How can I assist you today? User: What is the country where the Eiffel tower is situated? Gemini: France User: How many inhabitants are there in that country? Gemini: As of 2023, the population of France is estimated to be around 67.8 million.
Gemini से एक बार में एक सवाल पूछा जा सकता है या उससे कई बार बातचीत की जा सकती है. हालांकि, अब तक सिर्फ़ टेक्स्ट के ज़रिए इनपुट दिया जा सकता था. इमेज के बारे में क्या जानकारी है? अगले चरण में, इमेज के बारे में जानते हैं.
6. Gemini की मल्टीमोडलिटी सुविधा
Gemini एक मल्टीमॉडल मॉडल है. यह न सिर्फ़ टेक्स्ट को इनपुट के तौर पर स्वीकार करता है, बल्कि इमेज या वीडियो को भी इनपुट के तौर पर स्वीकार करता है. इस सेक्शन में, आपको टेक्स्ट और इमेज को मिलाकर इस्तेमाल करने का एक उदाहरण दिखेगा.
क्या आपको लगता है कि Gemini इस बिल्ली की पहचान कर पाएगा?

बर्फ़ में बिल्ली की तस्वीर, Wikipedia से ली गई है
app/src/main/java/gemini/workshop डायरेक्ट्री में मौजूद Multimodal.java पर एक नज़र डालें:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.data.message.ImageContent;
import dev.langchain4j.data.message.TextContent;
public class Multimodal {
static final String CAT_IMAGE_URL =
"https://upload.wikimedia.org/wikipedia/" +
"commons/b/b6/Felis_catus-cat_on_snow.jpg";
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
UserMessage userMessage = UserMessage.from(
ImageContent.from(CAT_IMAGE_URL),
TextContent.from("Describe the picture")
);
Response<AiMessage> response = model.generate(userMessage);
System.out.println(response.content().text());
}
}
इंपोर्ट किए गए डेटा में, हमने अलग-अलग तरह के मैसेज और कॉन्टेंट के बीच अंतर किया है. UserMessage में TextContent और ImageContent, दोनों ऑब्जेक्ट शामिल हो सकते हैं. यह मल्टीमॉडल सुविधा का इस्तेमाल करके किया गया है. इसमें टेक्स्ट और इमेज को मिक्स किया गया है. हम सिर्फ़ एक सामान्य स्ट्रिंग प्रॉम्प्ट नहीं भेजते, बल्कि हम ज़्यादा स्ट्रक्चर्ड ऑब्जेक्ट भेजते हैं. यह ऑब्जेक्ट, उपयोगकर्ता के मैसेज को दिखाता है. इसमें इमेज और टेक्स्ट, दोनों शामिल होते हैं. मॉडल, Response वापस भेजता है. इसमें AiMessage शामिल होता है.
इसके बाद, content() के ज़रिए जवाब से AiMessage को वापस पाया जाता है. इसके बाद, text() की मदद से मैसेज का टेक्स्ट वापस पाया जाता है.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.Multimodal
इमेज के नाम से आपको यह पता चल गया होगा कि इमेज में क्या है. हालांकि, Gemini का जवाब कुछ इस तरह का है:
A cat with brown fur is walking in the snow. The cat has a white patch of fur on its chest and white paws. The cat is looking at the camera.
इमेज और टेक्स्ट प्रॉम्प्ट को मिलाकर इस्तेमाल करने से, दिलचस्प उदाहरण मिलते हैं. ऐसे ऐप्लिकेशन बनाए जा सकते हैं जो:
- फ़ोटो में मौजूद टेक्स्ट की पहचान करना.
- यह पता लगाना कि इमेज को डिसप्ले करना सुरक्षित है या नहीं.
- इमेज के कैप्शन जनरेट करना.
- इमेज के डेटाबेस में, सामान्य टेक्स्ट के ब्यौरे की मदद से खोजें.
इमेज से जानकारी निकालने के साथ-साथ, बिना किसी स्ट्रक्चर वाले टेक्स्ट से भी जानकारी निकाली जा सकती है. अगले सेक्शन में आपको इसी के बारे में जानकारी मिलेगी.
7. अनस्ट्रक्चर्ड टेक्स्ट से स्ट्रक्चर्ड जानकारी निकालना
कई बार ऐसा होता है, जब रिपोर्ट के दस्तावेज़ों, ईमेल या अन्य लंबे टेक्स्ट में ज़रूरी जानकारी को बिना किसी स्ट्रक्चर के दिया जाता है. आदर्श रूप से, आपको स्ट्रक्चर्ड ऑब्जेक्ट के तौर पर, अनस्ट्रक्चर्ड टेक्स्ट में मौजूद मुख्य जानकारी को एक्सट्रैक्ट करना होगा. आइए, जानते हैं कि ऐसा कैसे किया जा सकता है.
मान लें कि आपको किसी व्यक्ति की जीवनी, सीवी या उसके बारे में दी गई जानकारी से उसका नाम और उम्र निकालनी है. एलएलएम को, बिना किसी स्ट्रक्चर वाले टेक्स्ट से JSON निकालने के लिए कहा जा सकता है. इसके लिए, आपको प्रॉम्प्ट में थोड़ा बदलाव करना होगा. इसे आम तौर पर, "प्रॉम्प्ट इंजीनियरिंग" कहा जाता है.
हालांकि, यहां दिए गए उदाहरण में, JSON आउटपुट के बारे में बताने वाला प्रॉम्प्ट बनाने के बजाय, हम Gemini की एक बेहतरीन सुविधा का इस्तेमाल करेंगे. इसे स्ट्रक्चर्ड आउटपुट कहा जाता है. इसे कभी-कभी कॉन्टेंट जनरेट करने की सुविधा पर पाबंदी लगाना भी कहा जाता है. इससे मॉडल को सिर्फ़ मान्य JSON कॉन्टेंट जनरेट करने के लिए मजबूर किया जाता है. यह कॉन्टेंट, तय किए गए JSON स्कीमा के मुताबिक होता है.
app/src/main/java/gemini/workshop में ExtractData.java को देखें:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import static dev.langchain4j.model.vertexai.SchemaHelper.fromClass;
public class ExtractData {
record Person(String name, int age) { }
interface PersonExtractor {
@SystemMessage("""
Your role is to extract the name and age
of the person described in the biography.
""")
Person extractPerson(String biography);
}
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.responseMimeType("application/json")
.responseSchema(fromClass(Person.class))
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
String bio = """
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
""";
Person person = extractor.extractPerson(bio);
System.out.println(person.name()); // Anna
System.out.println(person.age()); // 23
}
}
आइए, इस फ़ाइल में मौजूद अलग-अलग चरणों पर एक नज़र डालें:
Personरिकॉर्ड को किसी व्यक्ति (नाम और उम्र) के बारे में जानकारी देने के लिए तय किया जाता है.PersonExtractorइंटरफ़ेस को एक ऐसे तरीके से तय किया जाता है जो बिना किसी स्ट्रक्चर वाली टेक्स्ट स्ट्रिंग दिए जाने पर,Personइंस्टेंस दिखाता है.extractPerson()को@SystemMessageएनोटेशन के साथ एनोटेट किया गया है. यह एनोटेशन, निर्देश वाले प्रॉम्प्ट को इससे जोड़ता है. यह वह प्रॉम्प्ट है जिसका इस्तेमाल मॉडल, जानकारी निकालने के लिए करेगा. साथ ही, JSON दस्तावेज़ के तौर पर जानकारी देगा. इस जानकारी को आपके लिए पार्स किया जाएगा औरPersonइंस्टेंस में अनमार्शल किया जाएगा.
अब main() तरीके के कॉन्टेंट पर एक नज़र डालते हैं:
- चैट मॉडल को कॉन्फ़िगर और इंस्टैंटिएट किया जाता है. हम मॉडल बिल्डर क्लास के दो नए तरीकों का इस्तेमाल कर रहे हैं:
responseMimeType()औरresponseSchema(). पहले निर्देश में, Gemini को आउटपुट में मान्य JSON जनरेट करने के लिए कहा गया है. दूसरा तरीका, उस JSON ऑब्जेक्ट के स्कीमा के बारे में बताता है जिसे दिखाया जाना चाहिए. इसके अलावा, बाद वाला तरीका एक सुविधाजनक तरीके को सौंपता है, जो Java क्लास या रिकॉर्ड को सही JSON स्कीमा में बदल सकता है. - LangChain4j की
AiServicesक्लास की मदद से,PersonExtractorऑब्जेक्ट बनाया जाता है. - इसके बाद, बिना किसी स्ट्रक्चर वाले टेक्स्ट से व्यक्ति की जानकारी निकालने के लिए,
Person person = extractor.extractPerson(...)को कॉल करें. इससे आपको नाम और उम्र के साथPersonइंस्टेंस वापस मिल जाएगा.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.ExtractData
आपको यह आउटपुट दिखेगा:
Anna 23
हां, यह ऐना है और इसकी उम्र 23 साल है!
इस AiServices अप्रोच में, स्ट्रॉन्गली टाइप किए गए ऑब्जेक्ट का इस्तेमाल किया जाता है. आप सीधे तौर पर एलएलएम से इंटरैक्ट नहीं कर रहे हैं. इसके बजाय, आपको कॉन्क्रीट क्लास के साथ काम करना होता है. जैसे, निकाली गई निजी जानकारी को दिखाने के लिए Person रिकॉर्ड. साथ ही, आपके पास PersonExtractor ऑब्जेक्ट होता है, जिसमें extractPerson() तरीका होता है. यह Person इंस्टेंस दिखाता है. एलएलएम की अवधारणा को अलग रखा गया है. साथ ही, Java डेवलपर के तौर पर, इस PersonExtractor इंटरफ़ेस का इस्तेमाल करते समय, आपको सिर्फ़ सामान्य क्लास और ऑब्जेक्ट में बदलाव करना होता है.
8. प्रॉम्प्ट टेंप्लेट की मदद से प्रॉम्प्ट को स्ट्रक्चर करना
जब निर्देशों या सवालों के एक सामान्य सेट का इस्तेमाल करके एलएलएम से इंटरैक्ट किया जाता है, तो उस प्रॉम्प्ट का एक हिस्सा कभी नहीं बदलता. वहीं, अन्य हिस्सों में डेटा होता है. उदाहरण के लिए, अगर आपको रेसिपी बनानी हैं, तो "तुम एक प्रतिभाशाली शेफ़ हो, कृपया इन चीज़ों से एक रेसिपी बनाओ: ..." जैसा प्रॉम्प्ट इस्तेमाल किया जा सकता है. इसके बाद, आपको उस टेक्स्ट के आखिर में चीज़ों के नाम जोड़ने होंगे. प्रॉम्प्ट टेंप्लेट इसी काम के लिए होते हैं. ये प्रोग्रामिंग भाषाओं में इंटरपोलेटेड स्ट्रिंग की तरह होते हैं. प्रॉम्प्ट टेंप्लेट में प्लेसहोल्डर होते हैं. एलएलएम को किए गए किसी खास कॉल के लिए, इन प्लेसहोल्डर को सही डेटा से बदला जा सकता है.
ज़्यादा जानकारी के लिए, app/src/main/java/gemini/workshop डायरेक्ट्री में TemplatePrompt.java के बारे में जानें:
package gemini.workshop;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.output.Response;
import java.util.HashMap;
import java.util.Map;
public class TemplatePrompt {
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(500)
.temperature(1.0f)
.topK(40)
.topP(0.95f)
.maxRetries(3)
.build();
PromptTemplate promptTemplate = PromptTemplate.from("""
You're a friendly chef with a lot of cooking experience.
Create a recipe for a {{dish}} with the following ingredients: \
{{ingredients}}, and give it a name.
"""
);
Map<String, Object> variables = new HashMap<>();
variables.put("dish", "dessert");
variables.put("ingredients", "strawberries, chocolate, and whipped cream");
Prompt prompt = promptTemplate.apply(variables);
Response<AiMessage> response = model.generate(prompt.toUserMessage());
System.out.println(response.content().text());
}
}
हमेशा की तरह, आपको VertexAiGeminiChatModel मॉडल को कॉन्फ़िगर करना होगा. इसके लिए, आपको ज़्यादा क्रिएटिविटी के साथ-साथ ज़्यादा तापमान और topP और topK की ज़्यादा वैल्यू का इस्तेमाल करना होगा. इसके बाद, from() स्टैटिक तरीके का इस्तेमाल करके PromptTemplate बनाया जाता है. इसके लिए, हमारे प्रॉम्प्ट की स्ट्रिंग पास की जाती है. साथ ही, दोहरे घुंघराले ब्रैकेट वाले प्लेसहोल्डर वैरिएबल: {{dish}} और {{ingredients}} का इस्तेमाल किया जाता है.
apply() को कॉल करके फ़ाइनल प्रॉम्प्ट बनाया जाता है. यह की/वैल्यू पेयर का मैप लेता है. यह मैप, प्लेसहोल्डर के नाम और उसे बदलने के लिए स्ट्रिंग वैल्यू को दिखाता है.
आखिर में, prompt.toUserMessage() निर्देश के साथ उस प्रॉम्प्ट से उपयोगकर्ता का मैसेज बनाकर, Gemini मॉडल के generate() तरीके को कॉल करें.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.TemplatePrompt
आपको जनरेट किया गया ऐसा आउटपुट दिखेगा:
**Strawberry Shortcake** Ingredients: * 1 pint strawberries, hulled and sliced * 1/2 cup sugar * 1/4 cup cornstarch * 1/4 cup water * 1 tablespoon lemon juice * 1/2 cup heavy cream, whipped * 1/4 cup confectioners' sugar * 1/4 teaspoon vanilla extract * 6 graham cracker squares, crushed Instructions: 1. In a medium saucepan, combine the strawberries, sugar, cornstarch, water, and lemon juice. Bring to a boil over medium heat, stirring constantly. Reduce heat and simmer for 5 minutes, or until the sauce has thickened. 2. Remove from heat and let cool slightly. 3. In a large bowl, combine the whipped cream, confectioners' sugar, and vanilla extract. Beat until soft peaks form. 4. To assemble the shortcakes, place a graham cracker square on each of 6 dessert plates. Top with a scoop of whipped cream, then a spoonful of strawberry sauce. Repeat layers, ending with a graham cracker square. 5. Serve immediately. **Tips:** * For a more elegant presentation, you can use fresh strawberries instead of sliced strawberries. * If you don't have time to make your own whipped cream, you can use store-bought whipped cream.
मैप में dish और ingredients की वैल्यू बदलें. साथ ही, तापमान, topK, और tokP में बदलाव करें और कोड को फिर से चलाएं. इससे आपको एलएलएम पर इन पैरामीटर को बदलने का असर देखने में मदद मिलेगी.
प्रॉम्प्ट टेंप्लेट, एलएलएम कॉल के लिए बार-बार इस्तेमाल किए जा सकने वाले और पैरामीटर वाले निर्देश देने का एक अच्छा तरीका है. आपके पास उपयोगकर्ताओं की ओर से दी गई अलग-अलग वैल्यू के लिए, डेटा पास करने और प्रॉम्प्ट को पसंद के मुताबिक बनाने का विकल्प होता है.
9. उदाहरण के साथ डाले गए प्रॉम्प्ट का इस्तेमाल करके टेक्स्ट को अलग-अलग कैटगरी में बांटना
एलएलएम, टेक्स्ट को अलग-अलग कैटगरी में बांटने में काफ़ी अच्छे होते हैं. टेक्स्ट और उनसे जुड़ी कैटगरी के कुछ उदाहरण देकर, एलएलएम को इस काम में मदद की जा सकती है. इस तरीके को अक्सर फ़्यू शॉट प्रॉम्प्टिंग कहा जाता है.
आइए, app/src/main/java/gemini/workshop डायरेक्ट्री में TextClassification.java खोलते हैं, ताकि हम खास तरह का टेक्स्ट क्लासिफ़िकेशन कर सकें: भावना का विश्लेषण.
package gemini.workshop;
import com.google.cloud.vertexai.api.Schema;
import com.google.cloud.vertexai.api.Type;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.vertexai.VertexAiGeminiChatModel;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import java.util.List;
public class TextClassification {
enum Sentiment { POSITIVE, NEUTRAL, NEGATIVE }
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(10)
.maxRetries(3)
.responseSchema(Schema.newBuilder()
.setType(Type.STRING)
.addAllEnum(List.of("POSITIVE", "NEUTRAL", "NEGATIVE"))
.build())
.build();
interface SentimentAnalysis {
@SystemMessage("""
Analyze the sentiment of the text below.
Respond only with one word to describe the sentiment.
""")
Sentiment analyze(String text);
}
MessageWindowChatMemory memory = MessageWindowChatMemory.withMaxMessages(10);
memory.add(UserMessage.from("This is fantastic news!"));
memory.add(AiMessage.from(Sentiment.POSITIVE.name()));
memory.add(UserMessage.from("Pi is roughly equal to 3.14"));
memory.add(AiMessage.from(Sentiment.NEUTRAL.name()));
memory.add(UserMessage.from("I really disliked the pizza. Who would use pineapples as a pizza topping?"));
memory.add(AiMessage.from(Sentiment.NEGATIVE.name()));
SentimentAnalysis sentimentAnalysis =
AiServices.builder(SentimentAnalysis.class)
.chatLanguageModel(model)
.chatMemory(memory)
.build();
System.out.println(sentimentAnalysis.analyze("I love strawberries!"));
}
}
Sentiment एनम, किसी भावना की अलग-अलग वैल्यू दिखाता है: नकारात्मक, सामान्य या सकारात्मक.
main() तरीके में, Gemini Chat मॉडल को सामान्य तरीके से बनाया जाता है. हालाँकि, इसमें ज़्यादा से ज़्यादा आउटपुट टोकन की संख्या कम होती है, क्योंकि आपको सिर्फ़ छोटा जवाब चाहिए: टेक्स्ट POSITIVE, NEGATIVE या NEUTRAL है. मॉडल को सिर्फ़ उन वैल्यू को दिखाने के लिए, डेटा एक्सट्रैक्शन सेक्शन में बताई गई स्ट्रक्चर्ड आउटपुट की सुविधा का इस्तेमाल किया जा सकता है. इसलिए, responseSchema() तरीके का इस्तेमाल किया जाता है. इस बार, स्कीमा की जानकारी का अनुमान लगाने के लिए, SchemaHelper में मौजूद आसान तरीके का इस्तेमाल नहीं किया जा रहा है. इसके बजाय, Schema बिल्डर का इस्तेमाल किया जाएगा, ताकि यह समझा जा सके कि स्कीमा की जानकारी कैसी दिखती है.
मॉडल को कॉन्फ़िगर करने के बाद, एक SentimentAnalysis इंटरफ़ेस बनाया जाता है. LangChain4j का AiServices, एलएलएम का इस्तेमाल करके इसे लागू करेगा. इस इंटरफ़ेस में एक तरीका शामिल है: analyze(). यह फ़ंक्शन, इनपुट के तौर पर टेक्स्ट लेता है और Sentiment enum वैल्यू दिखाता है. इसलिए, आपको सिर्फ़ उस टाइप किए गए ऑब्जेक्ट में बदलाव करना होता है जो पहचाने गए सेंटीमेंट की क्लास को दिखाता है.
इसके बाद, मॉडल को क्लासिफ़िकेशन का काम करने के लिए "कुछ उदाहरण" देने के लिए, चैट मेमोरी बनाई जाती है. इससे उपयोगकर्ता के मैसेज और एआई के जवाबों के ऐसे जोड़े पास किए जाते हैं जो टेक्स्ट और उससे जुड़ी भावना को दिखाते हैं.
आइए, AiServices.builder() तरीके का इस्तेमाल करके, सभी चीज़ों को एक साथ बाइंड करें. इसके लिए, हमें SentimentAnalysis इंटरफ़ेस, इस्तेमाल किया जाने वाला मॉडल, और कुछ उदाहरणों के साथ चैट मेमोरी पास करनी होगी. आखिर में, विश्लेषण किए जाने वाले टेक्स्ट के साथ analyze() तरीके को कॉल करें.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.TextClassification
आपको एक शब्द दिखेगा:
POSITIVE
ऐसा लगता है कि स्ट्रॉबेरी पसंद करने वाले लोगों की भावनाएं सकारात्मक हैं!
10. रिट्रीवल ऑगमेंटेड जनरेशन
एलएलएम को बहुत ज़्यादा टेक्स्ट की मदद से ट्रेनिंग दी जाती है. हालांकि, एआई के पास सिर्फ़ वही जानकारी होती है जो उसने ट्रेनिंग के दौरान देखी है. अगर मॉडल की ट्रेनिंग के लिए डेटा इकट्ठा करने की आखिरी तारीख के बाद कोई नई जानकारी रिलीज़ की जाती है, तो वह जानकारी मॉडल के लिए उपलब्ध नहीं होगी. इसलिए, मॉडल ऐसी जानकारी के बारे में सवालों के जवाब नहीं दे पाएगा जिसे उसने नहीं देखा है.
इसलिए, Retrieval Augmented Generation (RAG) जैसे तरीके, इस सेक्शन में शामिल किए जाएंगे. ये तरीके, एलएलएम को अतिरिक्त जानकारी देने में मदद करते हैं. इस जानकारी का इस्तेमाल, एलएलएम अपने उपयोगकर्ताओं के अनुरोधों को पूरा करने के लिए कर सकता है. साथ ही, ऐसी जानकारी के साथ जवाब दे सकता है जो ज़्यादा अप-टू-डेट हो या ऐसी निजी जानकारी के बारे में हो जिसे ट्रेनिंग के दौरान ऐक्सेस नहीं किया जा सकता.
आइए, बातचीत पर वापस आते हैं. इस बार, आपको अपने दस्तावेज़ों के बारे में सवाल पूछने का विकल्प मिलेगा. आपको एक ऐसा चैटबॉट बनाना होगा जो आपके दस्तावेज़ों वाले डेटाबेस से काम की जानकारी निकाल सके. आपके दस्तावेज़ों को छोटे-छोटे हिस्सों ("चंक") में बांटा गया है. इस जानकारी का इस्तेमाल मॉडल, अपने जवाबों को सटीक बनाने के लिए करेगा. इसके लिए, वह सिर्फ़ ट्रेनिंग में मिली जानकारी पर भरोसा नहीं करेगा.
आरएजी में दो चरण होते हैं:
- डेटा इकट्ठा करने का चरण — इस चरण में, दस्तावेज़ों को मेमोरी में लोड किया जाता है. इसके बाद, उन्हें छोटे-छोटे हिस्सों में बांटा जाता है. साथ ही, वेक्टर एम्बेडिंग (हिस्सों का हाई मल्टीडाइमेंशनल वेक्टर प्रज़ेंटेशन) का हिसाब लगाया जाता है. इसके बाद, उन्हें वेक्टर डेटाबेस में सेव किया जाता है. यह डेटाबेस, सिमैंटिक सर्च करने में सक्षम होता है. डेटा को शामिल करने की यह प्रोसेस आम तौर पर एक बार की जाती है. ऐसा तब किया जाता है, जब दस्तावेज़ों के कॉर्पस में नए दस्तावेज़ जोड़ने होते हैं.

- क्वेरी फ़ेज़ — अब लोग दस्तावेज़ों के बारे में सवाल पूछ सकते हैं. सवाल को वेक्टर में भी बदला जाएगा. इसके बाद, इसकी तुलना डेटाबेस में मौजूद अन्य सभी वेक्टर से की जाएगी. सबसे मिलते-जुलते वेक्टर, आम तौर पर सिमैंटिक तौर पर एक-दूसरे से जुड़े होते हैं. इन्हें वेक्टर डेटाबेस से वापस लाया जाता है. इसके बाद, एलएलएम को बातचीत का कॉन्टेक्स्ट दिया जाता है. साथ ही, डेटाबेस से मिले वेक्टर से जुड़े टेक्स्ट के हिस्से दिए जाते हैं. साथ ही, उसे उन हिस्सों को देखकर जवाब देने के लिए कहा जाता है.
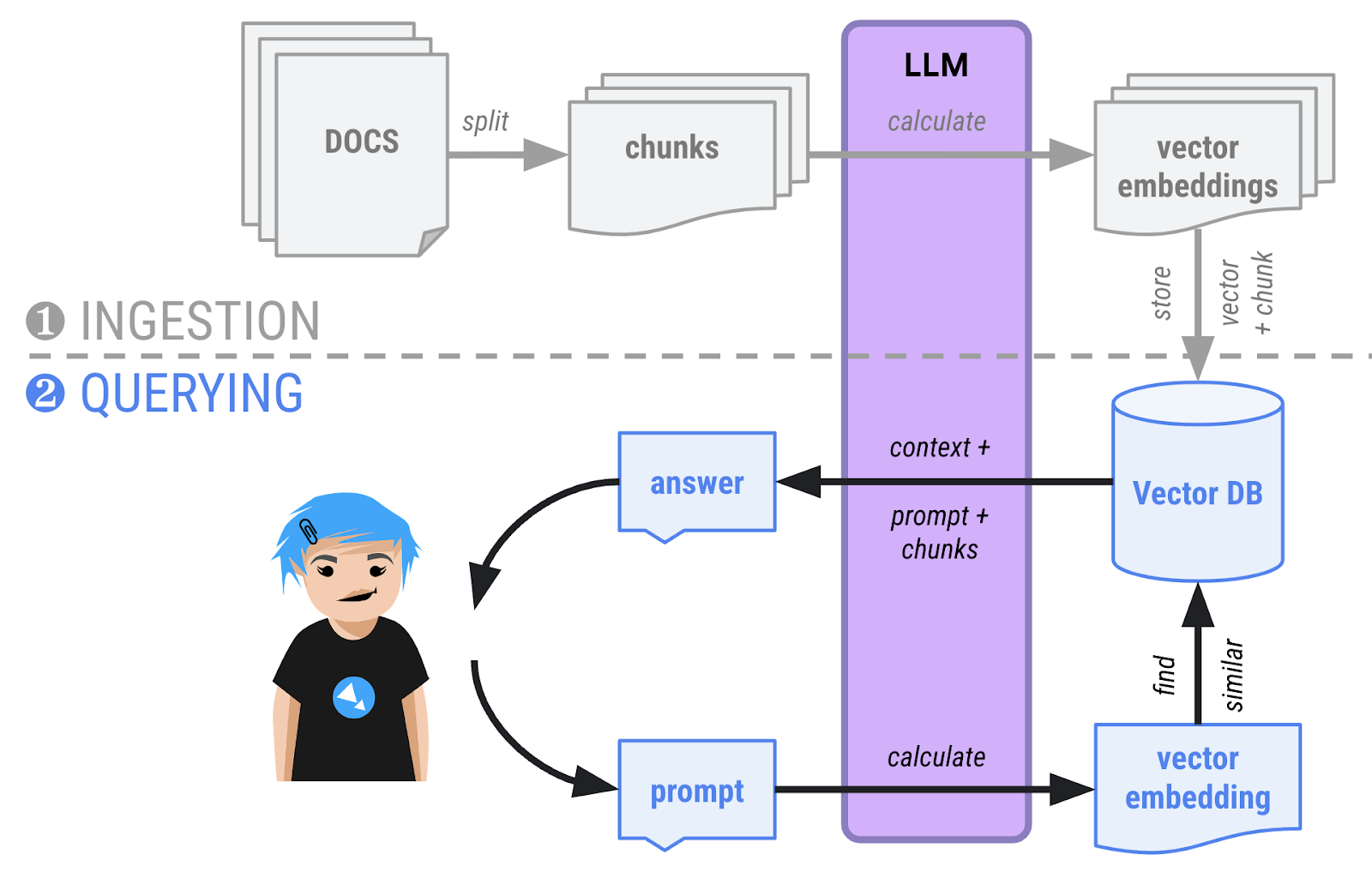
अपने दस्तावेज़ तैयार करना
इस नए उदाहरण में, आपको कार बनाने वाली एक काल्पनिक कंपनी के काल्पनिक मॉडल, Cymbal Starlight कार के बारे में सवाल पूछने हैं! इसका मतलब है कि किसी काल्पनिक कार के बारे में जानकारी देने वाला दस्तावेज़, मॉडल के ज्ञान का हिस्सा नहीं होना चाहिए. अगर Gemini इस कार के बारे में सवालों के सही जवाब दे पाता है, तो इसका मतलब है कि RAG का तरीका काम कर रहा है. इसका मतलब है कि यह आपके दस्तावेज़ में खोज कर सकता है.
चैटबॉट को लागू करना
आइए, दो चरणों वाले इस तरीके के बारे में जानें. पहले चरण में, दस्तावेज़ को शामिल किया जाता है. इसके बाद, दूसरे चरण में क्वेरी का समय (इसे "जानकारी वापस पाने का चरण" भी कहा जाता है) आता है. इस दौरान, लोग दस्तावेज़ के बारे में सवाल पूछते हैं.
इस उदाहरण में, दोनों फ़ेज़ को एक ही क्लास में लागू किया गया है. आम तौर पर, आपके पास एक ऐसा ऐप्लिकेशन होता है जो डेटा को इकट्ठा करता है. वहीं, दूसरा ऐप्लिकेशन उपयोगकर्ताओं को चैटबॉट इंटरफ़ेस उपलब्ध कराता है.
साथ ही, इस उदाहरण में हम इन-मेमोरी वेक्टर डेटाबेस का इस्तेमाल करेंगे. असल प्रोडक्शन के मामले में, डेटा को इकट्ठा करने और क्वेरी करने के चरणों को दो अलग-अलग ऐप्लिकेशन में बांटा जाता है. साथ ही, वेक्टर को एक स्टैंडअलोन डेटाबेस में सेव किया जाता है.
दस्तावेज़ डालना
दस्तावेज़ को शामिल करने के चरण में सबसे पहले, हमारी काल्पनिक कार के बारे में PDF फ़ाइल का पता लगाना होता है. इसके बाद, उसे पढ़ने के लिए PdfParser तैयार करना होता है:
URL url = new URI("https://raw.githubusercontent.com/meteatamel/genai-beyond-basics/main/samples/grounding/vertexai-search/cymbal-starlight-2024.pdf").toURL();
ApachePdfBoxDocumentParser pdfParser = new ApachePdfBoxDocumentParser();
Document document = pdfParser.parse(url.openStream());
इसमें, चैट के लिए सामान्य भाषा मॉडल बनाने के बजाय, सबसे पहले एम्बेडिंग मॉडल का इंस्टेंस बनाया जाता है. यह एक खास मॉडल है. इसका काम, टेक्स्ट के हिस्सों (शब्दों, वाक्यों या पैराग्राफ़) के वेक्टर प्रज़ेंटेशन बनाना है. यह टेक्स्ट के जवाब देने के बजाय, फ़्लोटिंग पॉइंट नंबर के वेक्टर दिखाता है.
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint(System.getenv("LOCATION") + "-aiplatform.googleapis.com:443")
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.publisher("google")
.modelName("text-embedding-005")
.maxRetries(3)
.build();
इसके बाद, आपको साथ मिलकर काम करने के लिए कुछ क्लास की ज़रूरत होगी, ताकि:
- PDF दस्तावेज़ को लोड करें और उसे छोटे-छोटे हिस्सों में बांटें.
- इन सभी चंक के लिए वेक्टर एम्बेडिंग बनाएं.
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
वेक्टर एम्बेडिंग को सेव करने के लिए, मेमोरी में मौजूद वेक्टर डेटाबेस InMemoryEmbeddingStore का एक इंस्टेंस बनाया जाता है.
DocumentSplitters क्लास की मदद से, दस्तावेज़ को अलग-अलग हिस्सों में बांटा गया है. यह PDF फ़ाइल के टेक्स्ट को 500 वर्णों के स्निपेट में बांटेगा. साथ ही, इसमें 100 वर्णों का ओवरलैप होगा, ताकि शब्दों या वाक्यों को छोटे-छोटे हिस्सों में न काटा जाए.
स्टोर इंजेस्टर, दस्तावेज़ को अलग-अलग हिस्सों में बांटने वाले टूल, वेक्टर का हिसाब लगाने वाले एंबेडिंग मॉडल, और मेमोरी में मौजूद वेक्टर डेटाबेस को लिंक करता है. इसके बाद, ingest() तरीके से डेटा को शामिल किया जाएगा.
अब पहला चरण पूरा हो गया है. दस्तावेज़ को टेक्स्ट के छोटे-छोटे हिस्सों में बदल दिया गया है. साथ ही, उनसे जुड़ी वेक्टर एम्बेडिंग को वेक्टर डेटाबेस में सेव कर दिया गया है.
सवाल पूछना
अब सवाल पूछने का समय आ गया है! बातचीत शुरू करने के लिए, चैट मॉडल बनाएं:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(1000)
.build();
आपको वेक्टर डेटाबेस (embeddingStore वैरिएबल में) को एम्बेडिंग मॉडल से लिंक करने के लिए, एक रिट्रीवर क्लास की भी ज़रूरत होती है. इसका काम, उपयोगकर्ता की क्वेरी के लिए वेक्टर एम्बेडिंग का हिसाब लगाकर, वेक्टर डेटाबेस से क्वेरी करना है. इससे डेटाबेस में मिलते-जुलते वेक्टर ढूंढे जा सकते हैं:
EmbeddingStoreContentRetriever retriever =
new EmbeddingStoreContentRetriever(embeddingStore, embeddingModel);
एक ऐसा इंटरफ़ेस बनाएं जो कार के विशेषज्ञ की तरह काम करे. यह एक ऐसा इंटरफ़ेस है जिसे AiServices क्लास लागू करेगी, ताकि आप मॉडल के साथ इंटरैक्ट कर सकें:
interface CarExpert {
Result<String> ask(String question);
}
CarExpert इंटरफ़ेस, LangChain4j की Result क्लास में रैप किया गया स्ट्रिंग रिस्पॉन्स दिखाता है. इस रैपर का इस्तेमाल क्यों करें? ऐसा इसलिए, क्योंकि इससे आपको न सिर्फ़ जवाब मिलेगा, बल्कि डेटाबेस से मिले उन चंक की जांच करने का भी मौका मिलेगा जिन्हें कॉन्टेंट रिट्रीवर ने वापस भेजा है. इस तरह, उपयोगकर्ता को जवाब देने के लिए इस्तेमाल किए गए दस्तावेज़ों के सोर्स दिखाए जा सकते हैं.
इस चरण में, नई एआई सेवा को कॉन्फ़िगर किया जा सकता है:
CarExpert expert = AiServices.builder(CarExpert.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(retriever)
.build();
यह सेवा इन चीज़ों को एक साथ जोड़ती है:
- चैट की भाषा का वह मॉडल जिसे आपने पहले कॉन्फ़िगर किया था.
- चैट मेमोरी, ताकि बातचीत को ट्रैक किया जा सके.
- रीट्रिवर, वेक्टर एम्बेडिंग क्वेरी की तुलना डेटाबेस में मौजूद वेक्टर से करता है.
.retrievalAugmentor(DefaultRetrievalAugmentor.builder()
.contentInjector(DefaultContentInjector.builder()
.promptTemplate(PromptTemplate.from("""
You are an expert in car automotive, and you answer concisely.
Here is the question: {{userMessage}}
Answer using the following information:
{{contents}}
"""))
.build())
.contentRetriever(retriever)
.build())
अब आप अपने सवाल पूछने के लिए तैयार हैं!
List.of(
"What is the cargo capacity of Cymbal Starlight?",
"What's the emergency roadside assistance phone number?",
"Are there some special kits available on that car?"
).forEach(query -> {
Result<String> response = expert.ask(query);
System.out.printf("%n=== %s === %n%n %s %n%n", query, response.content());
System.out.println("SOURCE: " + response.sources().getFirst().textSegment().text());
});
पूरा सोर्स कोड, app/src/main/java/gemini/workshop डायरेक्ट्री में मौजूद RAG.java में है.
सैंपल चलाएं:
./gradlew -q run -DjavaMainClass=gemini.workshop.RAG
आउटपुट में, आपको अपने सवालों के जवाब दिखने चाहिए:
=== What is the cargo capacity of Cymbal Starlight? === The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. SOURCE: Cargo The Cymbal Starlight 2024 has a cargo capacity of 13.5 cubic feet. The cargo area is located in the trunk of the vehicle. To access the cargo area, open the trunk lid using the trunk release lever located in the driver's footwell. When loading cargo into the trunk, be sure to distribute the weight evenly. Do not overload the trunk, as this could affect the vehicle's handling and stability. Luggage === What's the emergency roadside assistance phone number? === The emergency roadside assistance phone number is 1-800-555-1212. SOURCE: Chapter 18: Emergencies Roadside Assistance If you experience a roadside emergency, such as a flat tire or a dead battery, you can call roadside assistance for help. Roadside assistance is available 24 hours a day, 7 days a week. To call roadside assistance, dial the following number: 1-800-555-1212 When you call roadside assistance, be prepared to provide the following information: Your name and contact information Your vehicle's make, model, and year Your vehicle's location === Are there some special kits available on that car? === Yes, the Cymbal Starlight comes with a tire repair kit. SOURCE: Lane keeping assist: This feature helps to keep you in your lane by gently steering the vehicle back into the lane if you start to drift. Adaptive cruise control: This feature automatically adjusts your speed to maintain a safe following distance from the vehicle in front of you. Forward collision warning: This feature warns you if you are approaching another vehicle too quickly. Automatic emergency braking: This feature can automatically apply the brakes to avoid a collision.
11. फ़ंक्शन कॉल करने की सुविधा
कुछ मामलों में, आपको एलएलएम को बाहरी सिस्टम का ऐक्सेस देना पड़ सकता है. जैसे, रिमोट वेब एपीआई जो जानकारी को वापस लाता है या कोई कार्रवाई करता है या ऐसी सेवाएँ जो किसी तरह की कंप्यूटिंग करती हैं. उदाहरण के लिए:
रिमोट वेब एपीआई:
- ग्राहक के ऑर्डर ट्रैक करना और उन्हें अपडेट करना.
- Issue Tracker में कोई टिकट ढूंढें या बनाएं.
- स्टॉक के कोट या आईओटी सेंसर मेज़रमेंट जैसे रीयल टाइम डेटा को फ़ेच करना.
- ईमेल भेजें.
कैलकुलेशन टूल:
- ज़्यादा मुश्किल गणित के सवालों को हल करने के लिए कैलकुलेटर.
- एलएलएम को तर्क देने वाले लॉजिक की ज़रूरत होने पर, कोड चलाने के लिए कोड इंटरप्रेटेशन.
- नैचुरल लैंग्वेज में किए गए अनुरोधों को एसक्यूएल क्वेरी में बदलता है, ताकि एलएलएम किसी डेटाबेस से क्वेरी कर सके.
फ़ंक्शन कॉलिंग (इसे कभी-कभी टूल या टूल का इस्तेमाल भी कहा जाता है) की मदद से मॉडल, अपने लिए एक या उससे ज़्यादा फ़ंक्शन कॉल करने का अनुरोध कर सकता है. इससे वह नए डेटा के साथ, उपयोगकर्ता के प्रॉम्प्ट का सही जवाब दे पाता है.
किसी उपयोगकर्ता के दिए गए प्रॉम्प्ट और उस संदर्भ से जुड़े मौजूदा फ़ंक्शन की जानकारी के आधार पर, एलएलएम फ़ंक्शन कॉल के अनुरोध के साथ जवाब दे सकता है. एलएलएम को इंटिग्रेट करने वाला ऐप्लिकेशन, एलएलएम की ओर से फ़ंक्शन को कॉल कर सकता है. इसके बाद, एलएलएम को जवाब दे सकता है. इसके बाद, एलएलएम टेक्स्ट के तौर पर जवाब देकर, इसकी व्याख्या करता है.
फ़ंक्शन कॉलिंग के चार चरण
फ़ंक्शन कॉलिंग का एक उदाहरण देखते हैं: मौसम के पूर्वानुमान के बारे में जानकारी पाना.
अगर Gemini या किसी अन्य एलएलएम से पेरिस के मौसम के बारे में पूछा जाता है, तो वे जवाब देंगे कि उनके पास मौसम के मौजूदा पूर्वानुमान के बारे में कोई जानकारी नहीं है. अगर आपको एलएलएम को मौसम के डेटा का रीयल टाइम में ऐक्सेस देना है, तो आपको कुछ ऐसे फ़ंक्शन तय करने होंगे जिनके इस्तेमाल का अनुरोध एलएलएम कर सकता है.
इस डायग्राम को देखें:

1️⃣ सबसे पहले, कोई उपयोगकर्ता पेरिस के मौसम के बारे में पूछता है. LangChain4j का इस्तेमाल करने वाले चैटबॉट ऐप्लिकेशन को पता है कि उसके पास एक या उससे ज़्यादा ऐसे फ़ंक्शन हैं जिनकी मदद से एलएलएम, क्वेरी को पूरा कर सकता है. चैटबॉट, शुरुआती प्रॉम्प्ट के साथ-साथ कॉल किए जा सकने वाले फ़ंक्शन की सूची भी भेजता है. यहां, getWeather() नाम का एक फ़ंक्शन है, जो जगह के लिए स्ट्रिंग पैरामीटर लेता है.
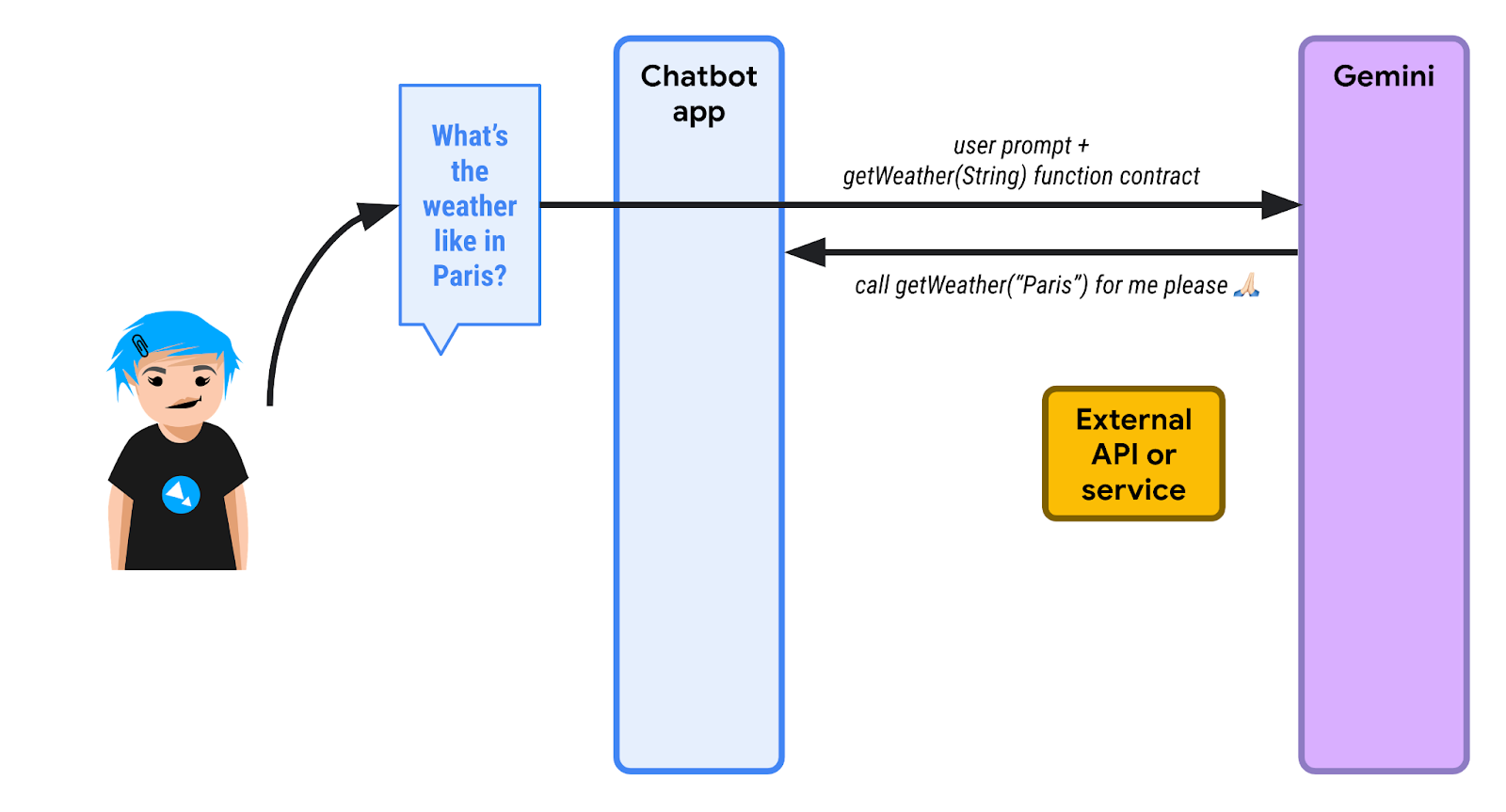
एलएलएम को मौसम के पूर्वानुमान के बारे में जानकारी नहीं होती. इसलिए, वह टेक्स्ट के ज़रिए जवाब देने के बजाय, फ़ंक्शन को लागू करने का अनुरोध भेजता है. चैटबॉट को getWeather() फ़ंक्शन को कॉल करना होगा. इसके लिए, "Paris" को जगह के पैरामीटर के तौर पर इस्तेमाल करना होगा.
2️⃣ चैटबॉट, एलएलएम की ओर से उस फ़ंक्शन को शुरू करता है और फ़ंक्शन का जवाब वापस पाता है. यहां हम मान लेते हैं कि जवाब {"forecast": "sunny"} है.
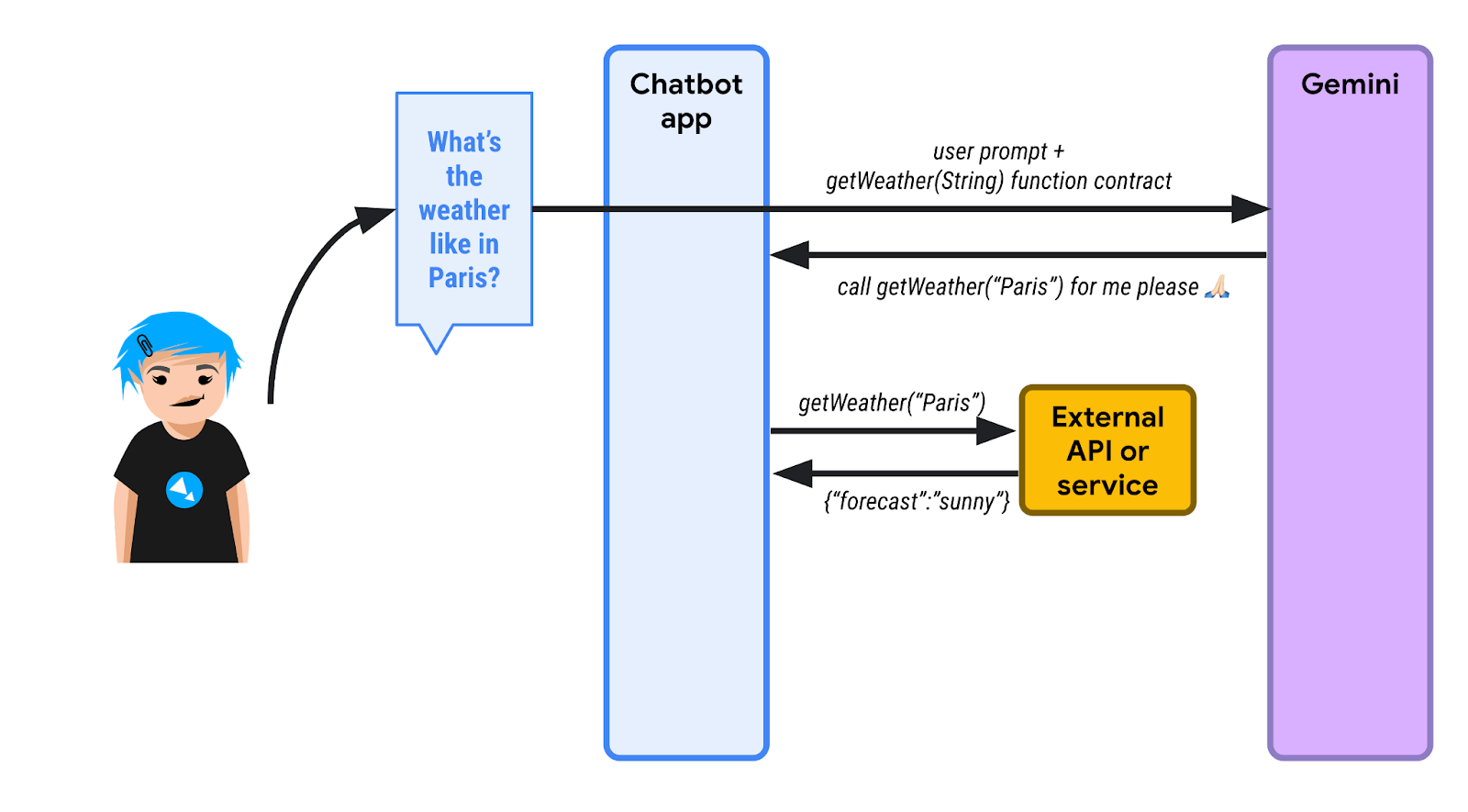
3️⃣ चैटबॉट ऐप्लिकेशन, JSON रिस्पॉन्स को LLM पर वापस भेजता है.
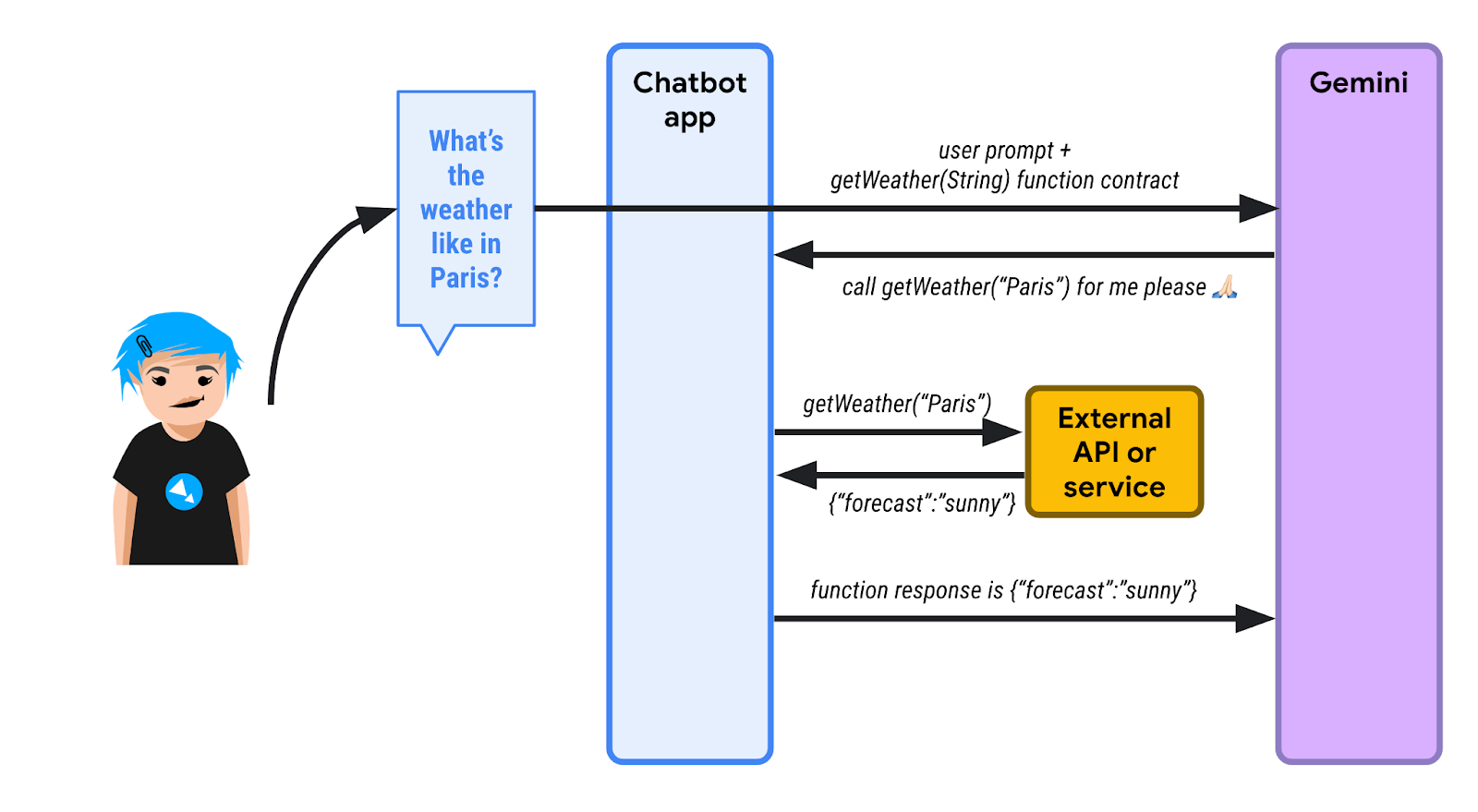
4️⃣ एलएलएम, JSON जवाब को देखता है और उस जानकारी को समझता है. इसके बाद, वह जवाब देता है कि पेरिस में धूप खिली हुई है.

हर चरण को कोड के तौर पर दिखाओ
सबसे पहले, Gemini मॉडल को हमेशा की तरह कॉन्फ़िगर करें:
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
आपको टूल स्पेसिफ़िकेशन तय करना होता है. इसमें उस फ़ंक्शन के बारे में बताया जाता है जिसे कॉल किया जा सकता है:
ToolSpecification weatherToolSpec = ToolSpecification.builder()
.name("getWeather")
.description("Get the weather forecast for a given location or city")
.parameters(JsonObjectSchema.builder()
.addStringProperty(
"location",
"the location or city to get the weather forecast for")
.build())
.build();
इसमें फ़ंक्शन का नाम और पैरामीटर का नाम और टाइप तय किया गया है. हालांकि, ध्यान दें कि फ़ंक्शन और पैरामीटर, दोनों के बारे में जानकारी दी गई है. ब्यौरे बहुत ज़रूरी होते हैं. इनसे एलएलएम को यह समझने में मदद मिलती है कि कोई फ़ंक्शन क्या कर सकता है. इससे एलएलएम यह तय कर पाता है कि बातचीत के संदर्भ में इस फ़ंक्शन को कॉल करने की ज़रूरत है या नहीं.
आइए, पहले चरण से शुरुआत करते हैं. इसके लिए, पेरिस के मौसम के बारे में शुरुआती सवाल भेजें:
List<ChatMessage> allMessages = new ArrayList<>();
// 1) Ask the question about the weather
UserMessage weatherQuestion = UserMessage.from("What is the weather in Paris?");
allMessages.add(weatherQuestion);
दूसरे चरण में, हम उस टूल को पास करते हैं जिसका इस्तेमाल हमें मॉडल से कराना है. इसके बाद, मॉडल टूल को लागू करने के अनुरोध के साथ जवाब देता है:
// 2) The model replies with a function call request
Response<AiMessage> messageResponse = model.generate(allMessages, weatherToolSpec);
ToolExecutionRequest toolExecutionRequest = messageResponse.content().toolExecutionRequests().getFirst();
System.out.println("Tool execution request: " + toolExecutionRequest);
allMessages.add(messageResponse.content());
तीसरा चरण. इस समय, हमें पता है कि एलएलएम को किस फ़ंक्शन को कॉल करना है. कोड में, हम किसी बाहरी एपीआई को असली कॉल नहीं कर रहे हैं. हम सीधे तौर पर मौसम के बारे में एक काल्पनिक अनुमान दिखा रहे हैं:
// 3) We send back the result of the function call
ToolExecutionResultMessage toolExecResMsg = ToolExecutionResultMessage.from(toolExecutionRequest,
"{\"location\":\"Paris\",\"forecast\":\"sunny\", \"temperature\": 20}");
allMessages.add(toolExecResMsg);
चौथे चरण में, एलएलएम को फ़ंक्शन के एक्ज़ीक्यूशन के नतीजे के बारे में पता चलता है. इसके बाद, वह टेक्स्ट के तौर पर जवाब जनरेट कर सकता है:
// 4) The model answers with a sentence describing the weather
Response<AiMessage> weatherResponse = model.generate(allMessages);
System.out.println("Answer: " + weatherResponse.content().text());
पूरा सोर्स कोड, app/src/main/java/gemini/workshop डायरेक्ट्री में मौजूद FunctionCalling.java में है.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCalling
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
Tool execution request: ToolExecutionRequest { id = null, name = "getWeatherForecast", arguments = "{"location":"Paris"}" }
Answer: The weather in Paris is sunny with a temperature of 20 degrees Celsius.
आपको टूल के इस्तेमाल के अनुरोध के साथ-साथ जवाब भी ऊपर दिए गए आउटपुट में दिख सकता है.
12. LangChain4j, फ़ंक्शन कॉल को मैनेज करता है
पिछले चरण में, आपने देखा कि सामान्य टेक्स्ट वाले सवाल/जवाब और फ़ंक्शन के अनुरोध/जवाब के इंटरैक्शन एक-दूसरे से जुड़े होते हैं. साथ ही, आपने अनुरोध किए गए फ़ंक्शन का जवाब सीधे तौर पर दिया, बिना किसी फ़ंक्शन को कॉल किए.
हालांकि, LangChain4j एक बेहतर अबस्ट्रैक्शन भी उपलब्ध कराता है. यह आपके लिए फ़ंक्शन कॉल को पारदर्शी तरीके से हैंडल कर सकता है. साथ ही, बातचीत को सामान्य तरीके से हैंडल कर सकता है.
सिंगल फ़ंक्शन कॉल
आइए, FunctionCallingAssistant.java के हर हिस्से पर एक नज़र डालें.
सबसे पहले, आपको एक ऐसा रिकॉर्ड बनाना होगा जो फ़ंक्शन के रिस्पॉन्स डेटा स्ट्रक्चर को दिखाएगा:
record WeatherForecast(String location, String forecast, int temperature) {}
जवाब में, जगह, मौसम का पूर्वानुमान, और तापमान की जानकारी शामिल होती है.
इसके बाद, एक ऐसी क्लास बनाएं जिसमें वह फ़ंक्शन शामिल हो जिसे आपको मॉडल के लिए उपलब्ध कराना है:
static class WeatherForecastService {
@Tool("Get the weather forecast for a location")
WeatherForecast getForecast(@P("Location to get the forecast for") String location) {
if (location.equals("Paris")) {
return new WeatherForecast("Paris", "Sunny", 20);
} else if (location.equals("London")) {
return new WeatherForecast("London", "Rainy", 15);
} else {
return new WeatherForecast("Unknown", "Unknown", 0);
}
}
}
ध्यान दें कि इस क्लास में सिर्फ़ एक फ़ंक्शन होता है. हालांकि, इसे @Tool एनोटेशन के साथ एनोटेट किया जाता है. यह एनोटेशन, उस फ़ंक्शन के ब्यौरे से मेल खाता है जिसे मॉडल कॉल करने का अनुरोध कर सकता है.
फ़ंक्शन के पैरामीटर (यहां सिर्फ़ एक) को भी एनोटेट किया गया है. हालांकि, इसके लिए @P एनोटेशन का इस्तेमाल किया गया है. इससे पैरामीटर के बारे में भी जानकारी मिलती है. ज़्यादा मुश्किल स्थितियों में मॉडल को उपलब्ध कराने के लिए, जितने चाहें उतने फ़ंक्शन जोड़े जा सकते हैं.
इस क्लास में, कुछ पहले से तैयार जवाब दिखाए जाते हैं. हालांकि, अगर आपको मौसम की जानकारी देने वाली किसी बाहरी सेवा को कॉल करना है, तो आपको इस तरीके के मुख्य हिस्से में उस सेवा को कॉल करना होगा.
हमने देखा कि पिछली प्रोसेस में ToolSpecification बनाते समय, यह ज़रूरी होता है कि फ़ंक्शन के काम करने के तरीके के बारे में बताया जाए. साथ ही, यह भी बताया जाए कि पैरामीटर किस चीज़ से जुड़े हैं. इससे मॉडल को यह समझने में मदद मिलती है कि इस फ़ंक्शन का इस्तेमाल कब और कैसे किया जा सकता है.
इसके बाद, LangChain4j आपको एक ऐसा इंटरफ़ेस उपलब्ध कराता है जो उस अनुबंध से मेल खाता है जिसका इस्तेमाल आपको मॉडल के साथ इंटरैक्ट करने के लिए करना है. यहां एक सामान्य इंटरफ़ेस दिया गया है. यह उपयोगकर्ता के मैसेज को दिखाने वाली स्ट्रिंग लेता है और मॉडल के जवाब से जुड़ी स्ट्रिंग दिखाता है:
interface WeatherAssistant {
String chat(String userMessage);
}
ज़्यादा मुश्किल स्थितियों को हैंडल करने के लिए, ज़्यादा जटिल सिग्नेचर का इस्तेमाल भी किया जा सकता है. इनमें LangChain4j का UserMessage (उपयोगकर्ता के मैसेज के लिए) या AiMessage (मॉडल के जवाब के लिए) या TokenStream शामिल होता है. हालांकि, हम सिर्फ़ इनपुट में स्ट्रिंग और आउटपुट में स्ट्रिंग लेंगे, ताकि इसे आसानी से समझा जा सके.
चलिए, अब main() तरीके के बारे में जानते हैं, जो सभी हिस्सों को एक साथ जोड़ता है:
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.build();
WeatherForecastService weatherForecastService = new WeatherForecastService();
WeatherAssistant assistant = AiServices.builder(WeatherAssistant.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.tools(weatherForecastService)
.build();
System.out.println(assistant.chat("What is the weather in Paris?"));
System.out.println(assistant.chat("Is it warmer in London or in Paris?"));
}
हमेशा की तरह, Gemini Chat मॉडल को कॉन्फ़िगर करें. इसके बाद, मौसम के पूर्वानुमान की सेवा को इंस्टैंटिएट करें. इसमें वह "फ़ंक्शन" शामिल होता है जिसे मॉडल कॉल करने का अनुरोध करेगा.
अब चैट मॉडल, चैट मेमोरी, और टूल (यानी कि मौसम की जानकारी देने वाली सेवा और उसका फ़ंक्शन) को बाइंड करने के लिए, AiServices क्लास का फिर से इस्तेमाल करें. AiServices, एक ऐसा ऑब्जेक्ट दिखाता है जो आपके तय किए गए WeatherAssistant इंटरफ़ेस को लागू करता है. अब सिर्फ़ उस असिस्टेंट के chat() तरीके को कॉल करना बाकी है. इसे चालू करने पर, आपको सिर्फ़ टेक्स्ट वाले जवाब दिखेंगे. हालांकि, फ़ंक्शन कॉल के अनुरोध और फ़ंक्शन कॉल के जवाब, डेवलपर को नहीं दिखेंगे. साथ ही, उन अनुरोधों को अपने-आप और पारदर्शी तरीके से हैंडल किया जाएगा. अगर Gemini को लगता है कि किसी फ़ंक्शन को कॉल किया जाना चाहिए, तो वह फ़ंक्शन कॉल करने के अनुरोध के साथ जवाब देगा. इसके बाद, LangChain4j आपकी ओर से लोकल फ़ंक्शन को कॉल करेगा.
सैंपल चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.FunctionCallingAssistant
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
OK. The weather in Paris is sunny with a temperature of 20 degrees.
It is warmer in Paris (20 degrees) than in London (15 degrees).
यह एक फ़ंक्शन का उदाहरण था.
एक से ज़्यादा फ़ंक्शन कॉल
आपके पास एक से ज़्यादा फ़ंक्शन भी हो सकते हैं. साथ ही, LangChain4j को अपनी ओर से कई फ़ंक्शन कॉल मैनेज करने की अनुमति दी जा सकती है. एक से ज़्यादा फ़ंक्शन के उदाहरण के लिए, MultiFunctionCallingAssistant.java देखें.
इसमें मुद्राओं को बदलने का फ़ंक्शन होता है:
@Tool("Convert amounts between two currencies")
double convertCurrency(
@P("Currency to convert from") String fromCurrency,
@P("Currency to convert to") String toCurrency,
@P("Amount to convert") double amount) {
double result = amount;
if (fromCurrency.equals("USD") && toCurrency.equals("EUR")) {
result = amount * 0.93;
} else if (fromCurrency.equals("USD") && toCurrency.equals("GBP")) {
result = amount * 0.79;
}
System.out.println(
"convertCurrency(fromCurrency = " + fromCurrency +
", toCurrency = " + toCurrency +
", amount = " + amount + ") == " + result);
return result;
}
किसी स्टॉक की वैल्यू पाने के लिए, एक और फ़ंक्शन:
@Tool("Get the current value of a stock in US dollars")
double getStockPrice(@P("Stock symbol") String symbol) {
double result = 170.0 + 10 * new Random().nextDouble();
System.out.println("getStockPrice(symbol = " + symbol + ") == " + result);
return result;
}
किसी दी गई रकम पर प्रतिशत लागू करने के लिए, एक और फ़ंक्शन:
@Tool("Apply a percentage to a given amount")
double applyPercentage(@P("Initial amount") double amount, @P("Percentage between 0-100 to apply") double percentage) {
double result = amount * (percentage / 100);
System.out.println("applyPercentage(amount = " + amount + ", percentage = " + percentage + ") == " + result);
return result;
}
इसके बाद, इन सभी फ़ंक्शन और MultiTools क्लास को एक साथ इस्तेमाल किया जा सकता है. साथ ही, "AAPL के शेयर की कीमत का 10% कितना है? इसे डॉलर से यूरो में बदलें" जैसे सवाल पूछे जा सकते हैं.
public static void main(String[] args) {
ChatLanguageModel model = VertexAiGeminiChatModel.builder()
.project(System.getenv("PROJECT_ID"))
.location(System.getenv("LOCATION"))
.modelName("gemini-2.0-flash")
.maxOutputTokens(100)
.build();
MultiTools multiTools = new MultiTools();
MultiToolsAssistant assistant = AiServices.builder(MultiToolsAssistant.class)
.chatLanguageModel(model)
.chatMemory(withMaxMessages(10))
.tools(multiTools)
.build();
System.out.println(assistant.chat(
"What is 10% of the AAPL stock price converted from USD to EUR?"));
}
इसे इस तरह चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.MultiFunctionCallingAssistant
इसके बाद, आपको कॉल किए गए कई फ़ंक्शन दिखेंगे:
getStockPrice(symbol = AAPL) == 172.8022224055534 convertCurrency(fromCurrency = USD, toCurrency = EUR, amount = 172.8022224055534) == 160.70606683716468 applyPercentage(amount = 160.70606683716468, percentage = 10.0) == 16.07060668371647 10% of the AAPL stock price converted from USD to EUR is 16.07060668371647 EUR.
एजेंट के लिए
फ़ंक्शन कॉलिंग, Gemini जैसे लार्ज लैंग्वेज मॉडल के लिए एक बेहतरीन एक्सटेंशन मैकेनिज़्म है. इससे हमें ज़्यादा जटिल सिस्टम बनाने में मदद मिलती है. इन्हें अक्सर "एजेंट" या "एआई असिस्टेंट" कहा जाता है. ये एजेंट, बाहरी एपीआई के ज़रिए बाहरी दुनिया से इंटरैक्ट कर सकते हैं. साथ ही, ऐसी सेवाओं से भी इंटरैक्ट कर सकते हैं जिनका बाहरी माहौल पर बुरा असर पड़ सकता है. जैसे, ईमेल भेजना, टिकट बनाना वगैरह.
इस तरह के शक्तिशाली एजेंट बनाते समय, आपको ज़िम्मेदारी से काम लेना चाहिए. अपने-आप होने वाली कार्रवाइयां करने से पहले, आपको ह्यूमन-इन-द-लूप के बारे में सोचना चाहिए. बाहरी दुनिया से इंटरैक्ट करने वाले एलएलएम की मदद से काम करने वाले एजेंट को डिज़ाइन करते समय, सुरक्षा का ध्यान रखना ज़रूरी है.
13. Ollama और TestContainers के साथ Gemma को चलाना
अब तक, हम Gemini का इस्तेमाल कर रहे थे. हालांकि, Gemma भी उपलब्ध है, जो Gemini का छोटा वर्शन है.
Gemma एक लाइटवेट और बेहतरीन ओपन मॉडल है. इसे Gemini मॉडल में इस्तेमाल की गई रिसर्च और तकनीक का इस्तेमाल करके बनाया गया है. Gemma का नया मॉडल Gemma3 है. यह चार साइज़ में उपलब्ध है: 1B (सिर्फ़ टेक्स्ट), 4B, 12B, और 27B. इनके वज़न की जानकारी आसानी से उपलब्ध है. साथ ही, इनके छोटे साइज़ की वजह से इन्हें अपने लैपटॉप या Cloud Shell पर भी चलाया जा सकता है.
Gemma को कैसे चलाया जाता है?
Gemma को कई तरीकों से चलाया जा सकता है: क्लाउड में, Vertex AI के ज़रिए एक बटन पर क्लिक करके या कुछ जीपीयू के साथ GKE में. हालांकि, इसे स्थानीय तौर पर भी चलाया जा सकता है.
Gemma को स्थानीय तौर पर चलाने के लिए, Ollama एक अच्छा विकल्प है. यह एक ऐसा टूल है जिसकी मदद से, Llama, Mistral, और अन्य छोटे मॉडल को अपनी लोकल मशीन पर चलाया जा सकता है. यह Docker की तरह है, लेकिन LLM के लिए है.
अपने ऑपरेटिंग सिस्टम के लिए, निर्देश का पालन करके Ollama इंस्टॉल करें.
अगर Linux एनवायरमेंट का इस्तेमाल किया जा रहा है, तो Ollama को इंस्टॉल करने के बाद, आपको इसे चालू करना होगा.
ollama serve > /dev/null 2>&1 &
लोकल तौर पर इंस्टॉल हो जाने के बाद, मॉडल को पुल करने के लिए ये कमांड चलाएं:
ollama pull gemma3:1b
मॉडल के पुल होने का इंतज़ार करें. इसमें कुछ समय लग सकता है.
मॉडल चलाएं:
ollama run gemma3:1b
अब मॉडल के साथ इंटरैक्ट किया जा सकता है:
>>> Hello! Hello! It's nice to hear from you. What can I do for you today?
प्रॉम्प्ट से बाहर निकलने के लिए, Ctrl+D दबाएं
TestContainers पर Ollama में Gemma को चलाना
Ollama को स्थानीय तौर पर इंस्टॉल और चलाने के बजाय, TestContainers की मदद से मैनेज किए जाने वाले कंटेनर में Ollama का इस्तेमाल किया जा सकता है.
TestContainers सिर्फ़ टेस्टिंग के लिए ही नहीं, बल्कि कंटेनर को एक्ज़ीक्यूट करने के लिए भी इस्तेमाल किया जा सकता है. आपके लिए एक खास OllamaContainer भी उपलब्ध है!
यहां पूरी जानकारी दी गई है:

लागू करना
आइए, GemmaWithOllamaContainer.java के हर हिस्से पर एक नज़र डालें.
सबसे पहले, आपको Ollama का एक ऐसा कंटेनर बनाना होगा जो Gemma मॉडल को पुल करता हो. यह इमेज, पिछली बार के रन से पहले से मौजूद है या इसे बनाया जाएगा. अगर इमेज पहले से मौजूद है, तो आपको सिर्फ़ TestContainers को यह बताना होगा कि आपको डिफ़ॉल्ट Ollama इमेज को Gemma की मदद से तैयार की गई इमेज से बदलना है:
private static final String TC_OLLAMA_GEMMA3 = "tc-ollama-gemma3-1b";
public static final String GEMMA_3 = "gemma3:1b";
// Creating an Ollama container with Gemma 3 if it doesn't exist.
private static OllamaContainer createGemmaOllamaContainer() throws IOException, InterruptedException {
// Check if the custom Gemma Ollama image exists already
List<Image> listImagesCmd = DockerClientFactory.lazyClient()
.listImagesCmd()
.withImageNameFilter(TC_OLLAMA_GEMMA3)
.exec();
if (listImagesCmd.isEmpty()) {
System.out.println("Creating a new Ollama container with Gemma 3 image...");
OllamaContainer ollama = new OllamaContainer("ollama/ollama:0.7.1");
System.out.println("Starting Ollama...");
ollama.start();
System.out.println("Pulling model...");
ollama.execInContainer("ollama", "pull", GEMMA_3);
System.out.println("Committing to image...");
ollama.commitToImage(TC_OLLAMA_GEMMA3);
return ollama;
}
System.out.println("Ollama image substitution...");
// Substitute the default Ollama image with our Gemma variant
return new OllamaContainer(
DockerImageName.parse(TC_OLLAMA_GEMMA3)
.asCompatibleSubstituteFor("ollama/ollama"));
}
इसके बाद, Ollama टेस्ट कंटेनर बनाया जाता है और उसे शुरू किया जाता है. इसके बाद, Ollama चैट मॉडल बनाया जाता है. इसके लिए, आपको उस कंटेनर का पता और पोर्ट डालना होता है जिसमें वह मॉडल मौजूद है जिसका आपको इस्तेमाल करना है. आखिर में, हमेशा की तरह model.generate(yourPrompt) को लागू करें:
public static void main(String[] args) throws IOException, InterruptedException {
OllamaContainer ollama = createGemmaOllamaContainer();
ollama.start();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl(String.format("http://%s:%d", ollama.getHost(), ollama.getFirstMappedPort()))
.modelName(GEMMA_3)
.build();
String response = model.generate("Why is the sky blue?");
System.out.println(response);
}
इसे इस तरह चलाएं:
./gradlew run -q -DjavaMainClass=gemini.workshop.GemmaWithOllamaContainer
पहली बार कंटेनर बनाने और उसे चलाने में कुछ समय लगेगा. हालांकि, इसके बाद आपको Gemma का जवाब दिखेगा:
INFO: Container ollama/ollama:0.7.1 started in PT7.228339916S
The sky appears blue due to Rayleigh scattering. Rayleigh scattering is a phenomenon that occurs when sunlight interacts with molecules in the Earth's atmosphere.
* **Scattering particles:** The main scattering particles in the atmosphere are molecules of nitrogen (N2) and oxygen (O2).
* **Wavelength of light:** Blue light has a shorter wavelength than other colors of light, such as red and yellow.
* **Scattering process:** When blue light interacts with these molecules, it is scattered in all directions.
* **Human eyes:** Our eyes are more sensitive to blue light than other colors, so we perceive the sky as blue.
This scattering process results in a blue appearance for the sky, even though the sun is actually emitting light of all colors.
In addition to Rayleigh scattering, other atmospheric factors can also influence the color of the sky, such as dust particles, aerosols, and clouds.
अब आपके पास Cloud Shell में Gemma का इस्तेमाल करने का विकल्प है!
14. बधाई हो
बधाई हो, आपने LangChain4j और Gemini API का इस्तेमाल करके, Java में अपना पहला जनरेटिव एआई चैट ऐप्लिकेशन बना लिया है! आपको यह भी पता चला कि मल्टीमॉडल लार्ज लैंग्वेज मॉडल काफ़ी असरदार होते हैं. साथ ही, ये कई तरह के टास्क कर सकते हैं. जैसे, सवाल/जवाब देना, डेटा निकालना, बाहरी एपीआई के साथ इंटरैक्ट करना वगैरह. ये मॉडल, आपके दस्तावेज़ों के आधार पर भी जवाब दे सकते हैं.
आगे क्या करना है?
अब आपकी बारी है कि आप एलएलएम इंटिग्रेशन की मदद से, अपने ऐप्लिकेशन को बेहतर बनाएं!
इस बारे में और पढ़ें
- जनरेटिव एआई के इस्तेमाल के सामान्य उदाहरण
- जनरेटिव एआई के बारे में ट्रेनिंग के संसाधन
- Generative AI Studio के ज़रिए Gemini से इंटरैक्ट करना
- ज़िम्मेदारी के साथ एआई का इस्तेमाल