
1. סקירה כללית
בשיעור ה-Lab הזה תשתמשו ב-Vertex AI כדי לקבל חיזויים ממודל סיווג תמונות שאומן מראש.
מה לומדים
במאמר הזה נסביר איך:
- ייבוא מודל TensorFlow למרשם המודלים של Vertex AI
- קבלת חיזויים אונליין
- עדכון פונקציית TensorFlow Serving
העלות הכוללת להרצת שיעור ה-Lab הזה ב-Google Cloud היא בערך 1$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. בשיעור ה-Lab הזה נתמקד במוצרים שמודגשים בהמשך: תחזיות וסביבת עבודה

3. סקירה כללית של תרחישי שימוש
בשיעור ה-Lab הזה תלמדו איך לקחת מודל שאומן מראש מ-TensorFlow Hub ולפרוס אותו ב-Vertex AI. TensorFlow Hub הוא מאגר של מודלים מאומנים למגוון תחומים, כמו הטמעה, יצירת טקסט, המרת דיבור לטקסט, חלוקת תמונות למקטעים ועוד.
הדוגמה שבה נעשה שימוש בשיעור ה-Lab הזה היא מודל לסיווג תמונות MobileNet V1 שאומן מראש על מערך הנתונים ImageNet. בעזרת מודלים מוכנים מראש מ-TensorFlow Hub או ממאגרי מידע דומים אחרים של למידה עמוקה, אתם יכולים לפרוס מודלים איכותיים של למידה חישובית למגוון משימות חיזוי בלי לדאוג לאימון המודל.
4. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל.
שלב 2: הפעלת Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על הפעלת Vertex AI API.

שלב 3: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:

מפעילים את Notebooks API אם הוא עדיין לא מופעל.

אחרי ההפעלה, לוחצים על מחברות מנוהלות:

לאחר מכן בוחרים באפשרות מחברת חדשה.

נותנים שם למחברת, ובקטע הרשאה בוחרים באפשרות חשבון שירות.

לוחצים על הגדרות מתקדמות.
בקטע אבטחה, בוחרים באפשרות 'הפעלת מסוף' אם היא עדיין לא מופעלת.

אפשר להשאיר את כל ההגדרות המתקדמות האחרות כמו שהן.
אחרי כן, לוחצים על יצירה. ייקח כמה דקות עד שהמופע יוקצה.
אחרי שיוצרים את המופע, בוחרים באפשרות OPEN JUPYTERLAB (פתיחת JupyterLab).

5. רישום המודל
שלב 1: מעלים את המודל ל-Cloud Storage
לוחצים על הקישור הזה כדי לעבור לדף TensorFlow Hub של מודל MobileNet V1 שאומן על מערך הנתונים של ImageNet.
לוחצים על הורדה כדי להוריד את הארטיפקטים של המודל השמור.

בקטע Cloud Storage במסוף Google Cloud, לוחצים על CREATE.

נותנים שם ל-bucket ובוחרים באזור us-central1. ואז לוחצים על יצירה.

מעלים לקטגוריה את המודל מ-TensorFlow Hub שהורדתם. חשוב לוודא שביצעתם פתיחה של קובץ ה-tar.

הקטגוריה אמורה להיראות כך:
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
שלב 2: ייבוא המודל למאגר
עוברים לקטע Model registry של Vertex AI במסוף Cloud.

בוחרים באפשרות IMPORT.
בוחרים באפשרות ייבוא כמודל חדש ומזינים שם למודל.

בקטע Model settings (הגדרות המודל), מציינים את מאגר TensorFlow העדכני ביותר שנבנה מראש. לאחר מכן בוחרים את הנתיב ב-Cloud Storage שבו שמרתם את ארטיפקטים של המודל.
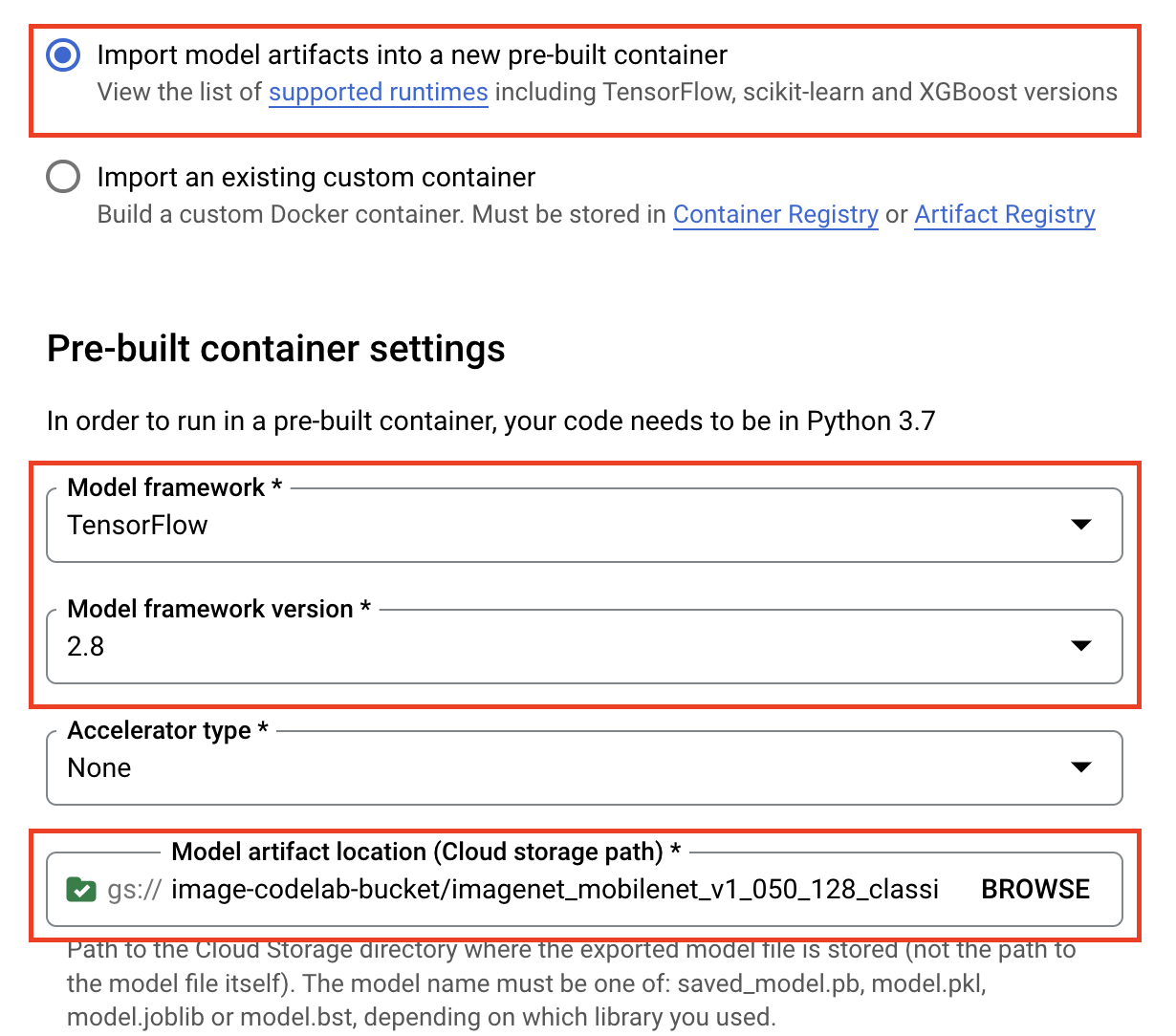
אפשר לדלג על הקטע הסבר.
אחר כך לוחצים על IMPORT.
אחרי הייבוא, המודל יופיע במאגר המודלים

6. פריסת מודל
במאגר המודלים, לוחצים על סמל האפשרויות הנוספות (3 נקודות) בצד שמאל של המודל ואז על פריסה לנקודת קצה.

בקטע הגדרת נקודת הקצה, בוחרים באפשרות יצירת נקודת קצה חדשה ומזינים שם לנקודת הקצה.
בקטע Model settings, מגדירים את Maximum number of compute nodes ל-1, ואת סוג המכונה ל-n1-standard-2. משאירים את כל ההגדרות האחרות כמו שהן ולוחצים על DEPLOY.

אחרי הפריסה, סטטוס הפריסה ישתנה לDeployed on Vertex AI.

7. קבלת תחזיות
פותחים את מחברת Workbench שיצרתם בשלבי ההגדרה. ממרכז האפליקציות, יוצרים מחברת חדשה של TensorFlow 2.

מריצים את התא הבא כדי לייבא את הספריות הנדרשות
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
מודל MobileNet שהורדתם מ-TensorFlow Hub אומן על מערך הנתונים ImageNet. הפלט של מודל MobileNet הוא מספר שמתאים לתווית של מחלקה במערך הנתונים ImageNet. כדי לתרגם את המספר הזה לתווית מחרוזת, צריך להוריד את תוויות התמונות.
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
כדי להגיע לנקודת הקצה, צריך להגדיר את משאב נקודת הקצה. חשוב להחליף את {PROJECT_NUMBER} ואת {ENDPOINT_ID}.
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
מספר הפרויקט מופיע בדף הבית של המסוף.

המזהה של נקודת הקצה מוצג בקטע Endpoints ב-Vertex AI.

בשלב הבא, תבדקו את נקודת הקצה.
קודם מורידים את התמונה הבאה ומעלים אותה למופע.

פותחים את התמונה באמצעות PIL. לאחר מכן משנים את הגודל ומכפילים ב-255. שימו לב: גודל התמונה שהמודל מצפה לו מופיע בדף של המודל ב-TensorFlow Hub.
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
לאחר מכן, ממירים את נתוני NumPy לרשימה כדי שאפשר יהיה לשלוח אותם בגוף של בקשת ה-HTTP.
x_test = im.astype(np.float32).tolist()
לבסוף, מפעילים קריאה לחיזוי בנקודת הקצה ומחפשים את תווית המחרוזת המתאימה.
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [אופציונלי] שימוש ב-TF Serving כדי לבצע אופטימיזציה של התחזיות
כדי לקבל דוגמאות מציאותיות יותר, כדאי לשלוח את התמונה ישירות לנקודת הקצה, במקום לטעון אותה קודם ב-NumPy. השיטה הזו יעילה יותר, אבל תצטרכו לשנות את פונקציית ההצגה של מודל TensorFlow. השינוי הזה נדרש כדי להמיר את נתוני הקלט לפורמט שהמודל מצפה לו.
שלב 1: שינוי פונקציית ההצגה
פותחים מחברת TensorFlow חדשה ומייבאים את הספריות הנדרשות.
from google.cloud import aiplatform
import tensorflow as tf
במקום להוריד את הארטיפקטים של המודל השמור, הפעם תטענו את המודל ל-TensorFlow באמצעות hub.KerasLayer, שעוטף TensorFlow SavedModel כשכבת Keras. כדי ליצור את המודל, אפשר להשתמש ב-Keras Sequential API עם מודל TF Hub שהורד כשכבה, ולציין את צורת הקלט של המודל.
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
מגדירים את ה-URI לקטגוריה שיצרתם קודם.
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
כששולחים בקשה לשרת חיזוי אונליין, שרת HTTP מקבל את הבקשה. שרת ה-HTTP מחלץ את בקשת החיזוי מתוכן גוף בקשת ה-HTTP. בקשת החיזוי שחולצה מועברת לפונקציית ההצגה. במאגרי התחזיות המוכנים מראש של Vertex AI, תוכן הבקשה מועבר לפונקציית ההגשה כ-tf.string.
כדי להעביר תמונות לשירות החיזוי, צריך לקודד את בייטים של התמונה הדחוסה ל-Base64, וכך התוכן מוגן מפני שינויים בזמן העברת נתונים בינאריים ברשת.
מכיוון שהמודל שנפרס מצפה לקבל נתוני קלט כבייטים גולמיים (לא דחוסים), צריך לוודא שהנתונים בקידוד Base64 יומרו בחזרה לבייטים גולמיים (למשל JPEG), ואז יעברו עיבוד מקדים כדי להתאים לדרישות הקלט של המודל, לפני שהם מועברים כקלט למודל שנפרס.
כדי לפתור את הבעיה, מגדירים פונקציית מילוי בקשות (serving_fn) ומצרפים אותה למודל כשלב של עיבוד מקדים. מוסיפים את העיטור @tf.function כדי שהפונקציה להכניס לשימוש בסביבת הייצור תמוזג עם המודל הבסיסי (במקום upstream במעבד (CPU)).
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
כששולחים נתונים לחיזוי כחבילת בקשת HTTP, נתוני התמונה מקודדים ב-Base64, אבל מודל TensorFlow מקבל קלט numpy. פונקציית ההצגה תבצע את ההמרה מ-base64 למערך numpy.
כששולחים בקשת חיזוי, צריך להפנות את הבקשה לפונקציית ההצגה במקום למודל, ולכן צריך לדעת את השם של שכבת הקלט של פונקציית ההצגה. אנחנו יכולים לקבל את השם הזה מחתימת פונקציית ההצגה.
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
שלב 2: ייבוא למאגר ופריסה
בקטעים הקודמים ראיתם איך לייבא מודל למרשם המודלים של Vertex AI דרך ממשק המשתמש. בקטע הזה מוצגת דרך חלופית לשימוש ב-SDK. שימו לב: אם אתם מעדיפים, אתם יכולים להשתמש בממשק המשתמש במקום זאת.
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
אפשר גם לפרוס את המודל באמצעות ה-SDK, במקום ממשק המשתמש.
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
שלב 3: בדיקת המודל
עכשיו אפשר לבדוק את נקודת הקצה. בגלל ששינינו את פונקציית ההצגה, הפעם אפשר לשלוח את התמונה ישירות (בקידוד base64) בבקשה, במקום לטעון את התמונה ל-NumPy קודם. בנוסף, תוכלו לשלוח תמונות גדולות יותר בלי לחרוג ממגבלת הגודל של Vertex AI Predictions.
הורדה חוזרת של תוויות התמונה
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
מקודדים את התמונה ב-Base64.
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
מבצעים קריאה לחיזוי ומציינים את שם שכבת הקלט של פונקציית ההצגה שהגדרנו במשתנה serving_input קודם לכן.
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI כדי:
- אירוח ופריסה של מודל שעבר אימון מראש
מידע נוסף על החלקים השונים של Vertex זמין בתיעוד.
9. הסרת המשאבים
ב-notebooks מנוהלים של Vertex AI Workbench יש תכונה של כיבוי במצב לא פעיל, ולכן לא צריך לדאוג לכיבוי המופע. כדי לכבות את המופע באופן ידני, לוחצים על הלחצן Stop (עצירה) בקטע Vertex AI Workbench במסוף. כדי למחוק את ה-Notebook לגמרי, לוחצים על לחצן המחיקה.

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete:
