
1. Visão geral
Neste laboratório, você vai usar a Vertex AI para receber previsões de um modelo de classificação de imagens pré-treinado.
Conteúdo do laboratório
Você vai aprender a:
- Importar um modelo do TensorFlow para o Vertex AI Model Registry
- Receber previsões on-line
- Atualizar uma função de disponibilização do TensorFlow
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$1.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos para a Vertex AI.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Os produtos destacados abaixo são o foco deste laboratório: Previsões e Workbench

3. Visão geral do caso de uso
Neste laboratório, você vai aprender a usar um modelo pré-treinado do TensorFlow Hub e implantá-lo na Vertex AI. O TensorFlow Hub é um repositório de modelos treinados para vários domínios de problemas, como incorporações, geração de texto, fala para texto, segmentação de imagens e muito mais.
O exemplo usado neste laboratório é um modelo de classificação de imagens MobileNet V1 pré-treinado no conjunto de dados do ImageNet. Ao aproveitar modelos prontos do TensorFlow Hub ou de outros repositórios de aprendizado profundo semelhantes, você pode implantar modelos de ML de alta qualidade para várias tarefas de previsão sem precisar se preocupar com o treinamento de modelo.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada.
Etapa 2: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.

Etapa 3: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":

Ative a API Notebooks, se ela ainda não tiver sido ativada.

Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.

Dê um nome ao notebook. Em Permissão selecione Conta de serviço.

Selecione Configurações avançadas.
Em Segurança, selecione "Ativar terminal", se essa opção ainda não estiver ativada.

Você pode manter as outras configurações avançadas como estão.
Em seguida, clique em Criar. O provisionamento da instância vai levar alguns minutos.
Quando a instância tiver sido criada, selecione ABRIR O JUPYTERLAB.

5. Registrar modelo
Etapa 1: fazer upload do modelo para o Cloud Storage
Clique neste link para acessar a página do TensorFlow Hub do modelo MobileNet V1 treinado no conjunto de dados do ImageNet.
Selecione Download para baixar os artefatos do modelo salvo.

Na seção Cloud Storage do console do Google Cloud, selecione CRIAR.

Dê um nome ao bucket e selecione us-central1 como a região. Em seguida, clique em CRIAR.

Faça o upload do modelo do TensorFlow Hub que você baixou para o bucket. Descompacte o arquivo primeiro.

O bucket vai ficar assim:
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
Etapa 2: importar o modelo para o registro
Navegue até a seção Registro de modelos da Vertex AI no console do Cloud.

Selecione IMPORT.
Selecione Importar como novo modelo e dê um nome para o modelo.

Em Configurações do modelo , especifique o contêiner pré-criado mais recente do TensorFlow. Em seguida, selecione o caminho no Cloud Storage em que você armazenou os artefatos do modelo.

Você pode pular a seção Explicabilidade.
Depois clique em IMPORT.
Após a importação, o modelo vai aparecer no registro de modelos.

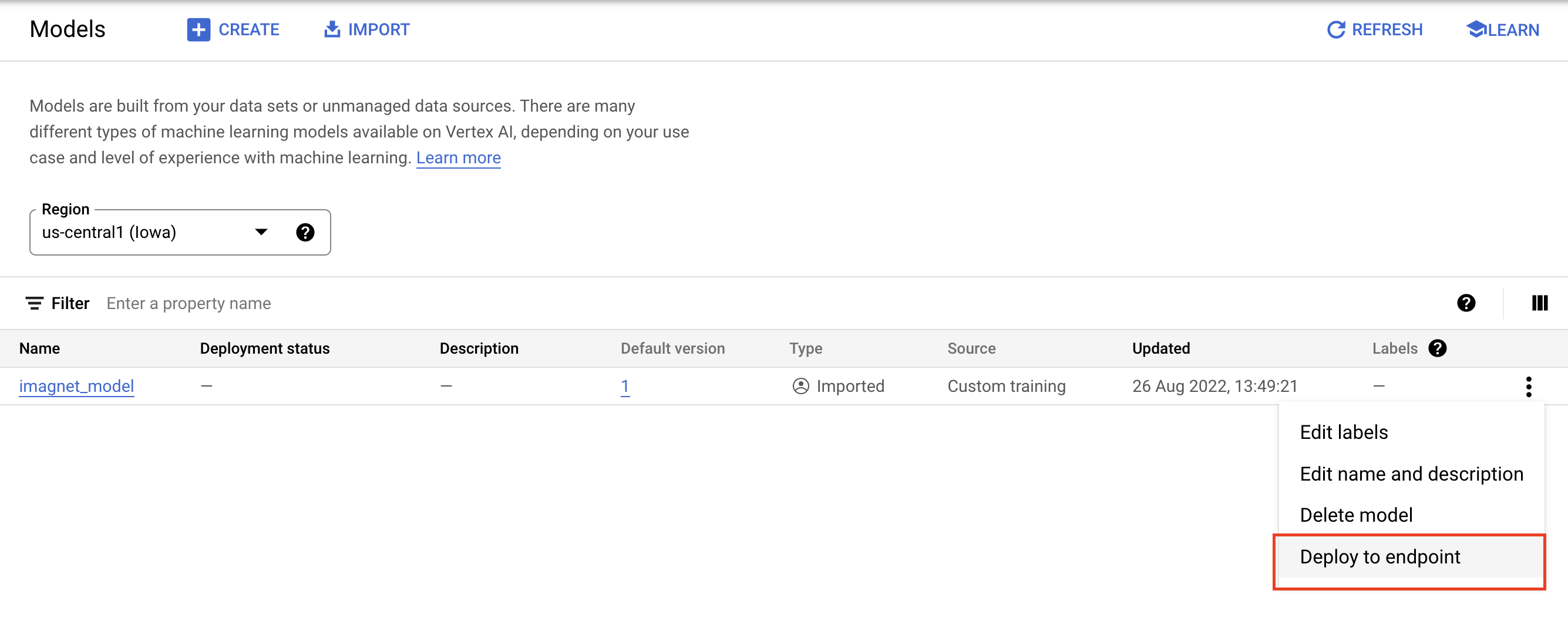
6. Implantar o modelo
No registro de modelos, selecione os três pontos no lado direito do modelo e clique em Implantar no endpoint.
Em Definir seu endpoint , selecione Criar novo endpoint e dê um nome a ele.
Em Configurações do modelo, defina o Número máximo de nós de computação como 1, o tipo de máquina como n1-standard-2 e deixe todas as outras configurações no estado em que se encontram. Em seguida, clique em IMPLANTAR.

Quando implantado, o status da implantação muda para Implantado na Vertex AI.

7. Receber previsões
Abra o notebook do Workbench que você criou nas etapas de configuração. Na tela de início, crie outro notebook do TensorFlow 2.

Execute a célula a seguir para importar as bibliotecas necessárias.
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
O modelo MobileNet que você baixou do TensorFlow Hub foi treinado no conjunto de dados do ImageNet. A saída do modelo MobileNet é um número que corresponde a um rótulo de classe no conjunto de dados do ImageNet. Para traduzir esse número em um rótulo de string, é necessário baixar os rótulos de imagem.
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
Para acessar o endpoint, é necessário definir o recurso de endpoint. Substitua {PROJECT_NUMBER} e {ENDPOINT_ID}.
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
O número do projeto aparece na página inicial do console.

E a ID do endpoint na seção Endpoints da Vertex AI.

Em seguida, você vai testar o endpoint.
Primeiro, faça o download da imagem a seguir e faça o upload dela para a instância.

Abra a imagem com PIL. Em seguida, redimensione e dimensione por 255. Observe que o tamanho da imagem esperado pelo modelo pode ser encontrado na página do modelo no TensorFlow Hub.
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
Em seguida, converta os dados do NumPy em uma lista para que possam ser enviados no corpo da solicitação HTTP.
x_test = im.astype(np.float32).tolist()
Por fim, faça uma chamada de previsão para o endpoint e procure o rótulo de string correspondente.
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [Opcional] Usar o TF Serving para otimizar previsões
Para exemplos mais realistas, é recomendável enviar a imagem diretamente para o endpoint, em vez de carregá-la no NumPy primeiro. Isso é mais eficiente, mas você precisa modificar a função de disponibilização do modelo do TensorFlow. Essa modificação é necessária para converter os dados de entrada no formato esperado pelo modelo.
Etapa 1: modificar a função de disponibilização
Abra um novo notebook do TensorFlow e importe as bibliotecas necessárias.
from google.cloud import aiplatform
import tensorflow as tf
Em vez de baixar os artefatos do modelo salvo, desta vez você vai carregar o modelo no TensorFlow usando hub.KerasLayer, que envolve um SavedModel do TensorFlow como uma camada do Keras. Para criar o modelo, use a API Sequential do Keras com o modelo do TF Hub baixado como uma camada e especifique o formato de entrada do modelo.
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
Defina o URI para o bucket que você criou anteriormente.
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
Quando você envia uma solicitação para um servidor de previsão on-line, ela é recebida por um servidor HTTP. O servidor HTTP extrai a solicitação de previsão do corpo do conteúdo da solicitação HTTP. A solicitação de previsão extraída é encaminhada para a função de disponibilização. Para os contêineres de previsão pré-criados da Vertex AI, o conteúdo da solicitação é transmitido para a função de disponibilização como um tf.string.
Para transmitir imagens ao serviço de previsão, é necessário codificar os bytes de imagem compactados em base64, o que torna o conteúdo seguro contra modificações ao transmitir dados binários pela rede.
Como o modelo implantado espera dados de entrada como bytes brutos (não compactados), é necessário garantir que os dados codificados em base64 sejam convertidos de volta em bytes brutos (por exemplo, JPEG) e pré-processados para corresponder aos requisitos de entrada do modelo, antes de serem transmitidos como entrada para o modelo implantado.
Para resolver isso, defina uma função de disponibilização (serving_fn) e anexe-a ao modelo como uma etapa de pré-processamento. Adicione um decorador @tf.function para que a função de disponibilização seja mesclada ao modelo subjacente (em vez de upstream em uma CPU).
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
Quando você envia dados para previsão como um pacote de solicitação HTTP, os dados da imagem são codificados em base64, mas o modelo do TensorFlow usa a entrada numpy. A função de disponibilização fará a conversão de base64 para uma matriz numpy.
Ao fazer uma solicitação de previsão, é necessário encaminhar a solicitação para a função de disponibilização em vez do modelo. Portanto, é necessário saber o nome da camada de entrada da função de disponibilização. Podemos receber esse nome da assinatura da função de disponibilização.
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
Etapa 2: importar para o registro e implantar
Nas seções anteriores, você aprendeu a importar um modelo para o Vertex AI Model Registry pela interface. Nesta seção, você vai aprender uma maneira alternativa de usar o SDK. Você ainda pode usar a interface aqui, se preferir.
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
Também é possível implantar o modelo usando o SDK, em vez da interface.
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
Etapa 3: testar o modelo
Agora você pode testar o endpoint. Como modificamos a função de disponibilização, desta vez você pode enviar a imagem diretamente (codificada em base64) na solicitação em vez de carregar a imagem no NumPy primeiro. Isso também permite enviar imagens maiores sem atingir o limite de tamanho das previsões da Vertex AI.
Faça o download dos rótulos de imagem novamente.
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
Codifique a imagem em base64.
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
Faça uma chamada de previsão, especificando o nome da camada de entrada da função de disponibilização que definimos na variável serving_input anteriormente.
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Hospedar e implantar um modelo pré-treinado
Para saber mais sobre as diferentes partes da Vertex, consulte a documentação.
9. Revisão dos dados
Como os notebooks gerenciados do Vertex AI Workbench têm um recurso de encerramento inativo, não precisamos nos preocupar em parar a instância. Para encerrar a instância manualmente, clique no botão "Parar" na seção "Vertex AI Workbench" do console. Se quiser excluir o notebook completamente, clique no botão "Excluir".

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":
