
1. Ringkasan
Dalam lab ini, Anda akan mempelajari cara menyusun lapisan konvolusional ke dalam model jaringan neural yang dapat mengenali bunga. Kali ini, Anda akan membangun model sendiri dari awal dan menggunakan kecanggihan TPU untuk melatihnya dalam hitungan detik dan melakukan iterasi pada desainnya.
Lab ini mencakup penjelasan teoretis yang diperlukan tentang jaringan neural konvolusional dan merupakan titik awal yang baik bagi developer yang mempelajari deep learning.
Lab ini adalah Bagian 3 dari seri "Keras di TPU". Anda dapat melakukannya dalam urutan berikut atau secara terpisah.
- Pipeline data berkecepatan TPU: tf.data.Dataset dan TFRecords
- Model Keras pertama Anda, dengan pemelajaran transfer
- [LAB INI] Jaringan neural konvolusional, dengan Keras dan TPU
- Convnets, squeezenet, dan Xception modern, dengan Keras dan TPU

Yang akan Anda pelajari
- Untuk membuat pengklasifikasi gambar konvolusional menggunakan model Keras Sequential.
- Untuk melatih model Keras Anda di TPU
- Untuk menyesuaikan model Anda dengan pilihan lapisan konvolusional yang baik.
Masukan
Jika Anda melihat sesuatu yang tidak beres dalam codelab ini, beri tahu kami. Masukan dapat diberikan melalui masalah GitHub [ link masukan].
2. Mulai cepat Google Colaboratory
Lab ini menggunakan Google Collaboratory dan tidak memerlukan penyiapan di pihak Anda. Colaboratory adalah platform notebook online untuk tujuan pendidikan. Colab menawarkan pelatihan CPU, GPU, dan TPU gratis.

Anda dapat membuka notebook contoh ini dan menjalankan beberapa sel untuk memahami Colaboratory.
Pilih backend TPU
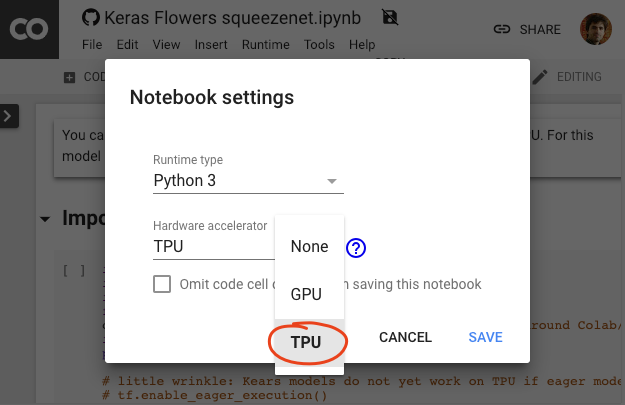
Di menu Colab, pilih Runtime > Ubah jenis runtime, lalu pilih TPU. Dalam codelab ini, Anda akan menggunakan TPU (Tensor Processing Unit) yang andal yang didukung untuk pelatihan yang dipercepat hardware. Koneksi ke runtime akan terjadi secara otomatis pada eksekusi pertama, atau Anda dapat menggunakan tombol "Hubungkan" di sudut kanan atas.
Eksekusi notebook

Jalankan sel satu per satu dengan mengklik sel dan menggunakan Shift-ENTER. Anda juga dapat menjalankan seluruh notebook dengan Runtime > Run all
Daftar isi

Semua notebook memiliki daftar isi. Anda dapat membukanya menggunakan panah hitam di sebelah kiri.
Sel tersembunyi

Beberapa sel hanya akan menampilkan judulnya. Ini adalah fitur notebook khusus Colab. Anda dapat mengklik dua kali untuk melihat kode di dalamnya, tetapi biasanya tidak terlalu menarik. Biasanya mendukung fungsi atau visualisasi. Anda tetap perlu menjalankan sel ini agar fungsi di dalamnya dapat ditentukan.
Autentikasi

Colab dapat mengakses bucket Google Cloud Storage pribadi Anda asalkan Anda melakukan autentikasi dengan akun yang sah. Cuplikan kode di atas akan memicu proses autentikasi.
3. [INFO] Apa itu Tensor Processing Unit (TPU)?
Singkatnya

Kode untuk melatih model di TPU di Keras (dan kembali ke GPU atau CPU jika TPU tidak tersedia):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Hari ini kita akan menggunakan TPU untuk membuat dan mengoptimalkan pengklasifikasi bunga dengan kecepatan interaktif (menit per proses pelatihan).
Mengapa TPU?
GPU modern disusun di sekitar "core" yang dapat diprogram, sebuah arsitektur yang sangat fleksibel yang memungkinkan GPU menangani berbagai tugas seperti rendering 3D, deep learning, simulasi fisik, dll. Di sisi lain, TPU memasangkan prosesor vektor klasik dengan unit perkalian matriks khusus dan unggul dalam tugas apa pun yang didominasi oleh perkalian matriks besar, seperti jaringan neural.

Ilustrasi: lapisan jaringan neural padat sebagai perkalian matriks, dengan batch delapan gambar yang diproses melalui jaringan neural sekaligus. Lakukan perkalian satu baris x kolom untuk memverifikasi bahwa operasi ini memang melakukan jumlah berbobot dari semua nilai piksel gambar. Lapisan konvolusional juga dapat direpresentasikan sebagai perkalian matriks meskipun sedikit lebih rumit ( penjelasan di sini, di bagian 1).
Hardware
MXU dan VPU
Core TPU v2 terdiri dari Matrix Multiply Unit (MXU) yang menjalankan perkalian matriks dan Vector Processing Unit (VPU) untuk semua tugas lainnya seperti aktivasi, softmax, dll. VPU menangani komputasi float32 dan int32. Di sisi lain, MXU beroperasi dalam format floating point 16-32 bit presisi campuran.
Titik mengambang presisi campuran dan bfloat16
MXU menghitung perkalian matriks menggunakan input bfloat16 dan output float32. Akumulasi perantara dilakukan dengan presisi float32.
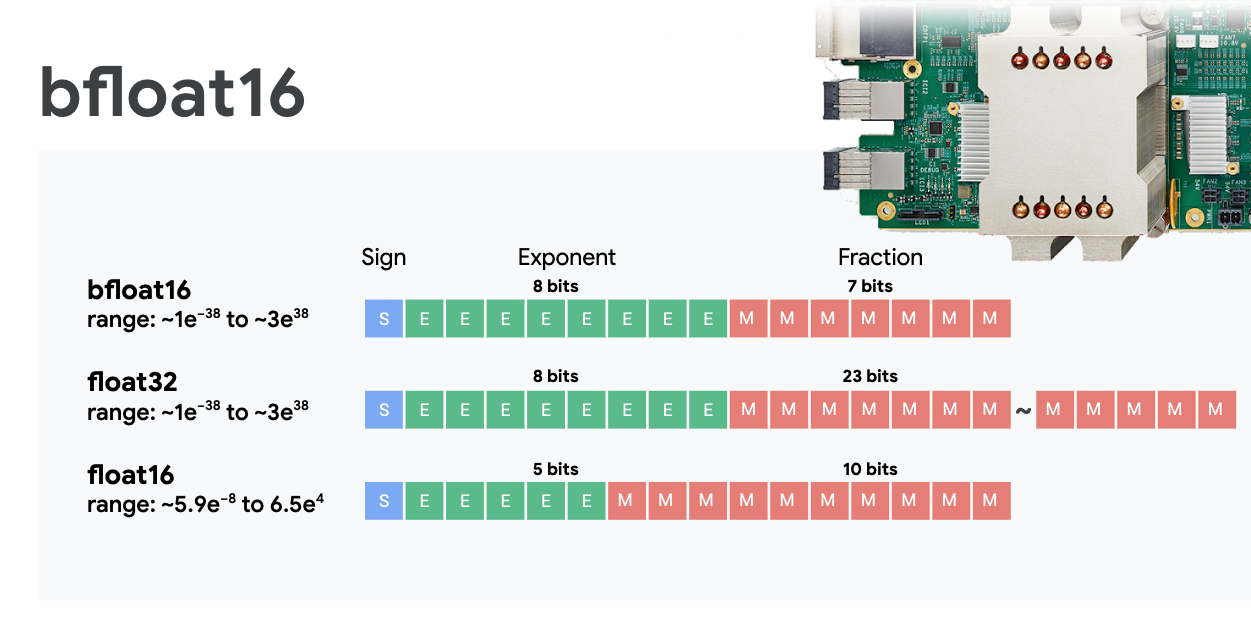
Pelatihan jaringan neural biasanya tahan terhadap derau yang diperkenalkan oleh presisi floating point yang berkurang. Ada kasus ketika derau bahkan membantu pengoptimalan konvergen. Presisi floating point 16-bit secara tradisional digunakan untuk mempercepat komputasi, tetapi format float16 dan float32 memiliki rentang yang sangat berbeda. Mengurangi presisi dari float32 ke float16 biasanya menyebabkan overflow dan underflow. Solusi memang ada, tetapi biasanya diperlukan pekerjaan tambahan agar float16 dapat berfungsi.
Itulah sebabnya Google memperkenalkan format bfloat16 di TPU. bfloat16 adalah float32 yang dipangkas dengan bit eksponen dan rentang yang sama persis dengan float32. Selain itu, TPU menghitung perkalian matriks dalam presisi campuran dengan input bfloat16, tetapi output float32. Artinya, biasanya tidak ada perubahan kode yang diperlukan untuk mendapatkan manfaat dari peningkatan performa presisi yang lebih rendah.
Array sistolik
MXU mengimplementasikan perkalian matriks di hardware menggunakan arsitektur yang disebut "array sistolik" yang elemen datanya mengalir melalui array unit komputasi hardware. (Dalam bidang medis, "sistolik" mengacu pada kontraksi jantung dan aliran darah, di sini mengacu pada aliran data.)
Elemen dasar perkalian matriks adalah produk titik antara baris dari satu matriks dan kolom dari matriks lainnya (lihat ilustrasi di bagian atas bagian ini). Untuk perkalian matriks Y=X*W, salah satu elemen hasilnya adalah:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Di GPU, seseorang akan memprogram produk titik ini ke dalam "core" GPU, lalu mengeksekusinya di sebanyak mungkin "core" secara paralel untuk mencoba menghitung setiap nilai matriks yang dihasilkan sekaligus. Jika matriks yang dihasilkan berukuran 128x128, maka diperlukan 128x128=16 ribu "core" yang tersedia, yang biasanya tidak mungkin. GPU terbesar memiliki sekitar 4.000 core. Sebaliknya, TPU menggunakan hardware minimum untuk unit komputasi di MXU: hanya bfloat16 x bfloat16 => float32 multiply-accumulator, tidak ada yang lain. Unit ini sangat kecil sehingga TPU dapat menerapkan 16 ribu unit dalam MXU 128x128 dan memproses perkalian matriks ini sekaligus.
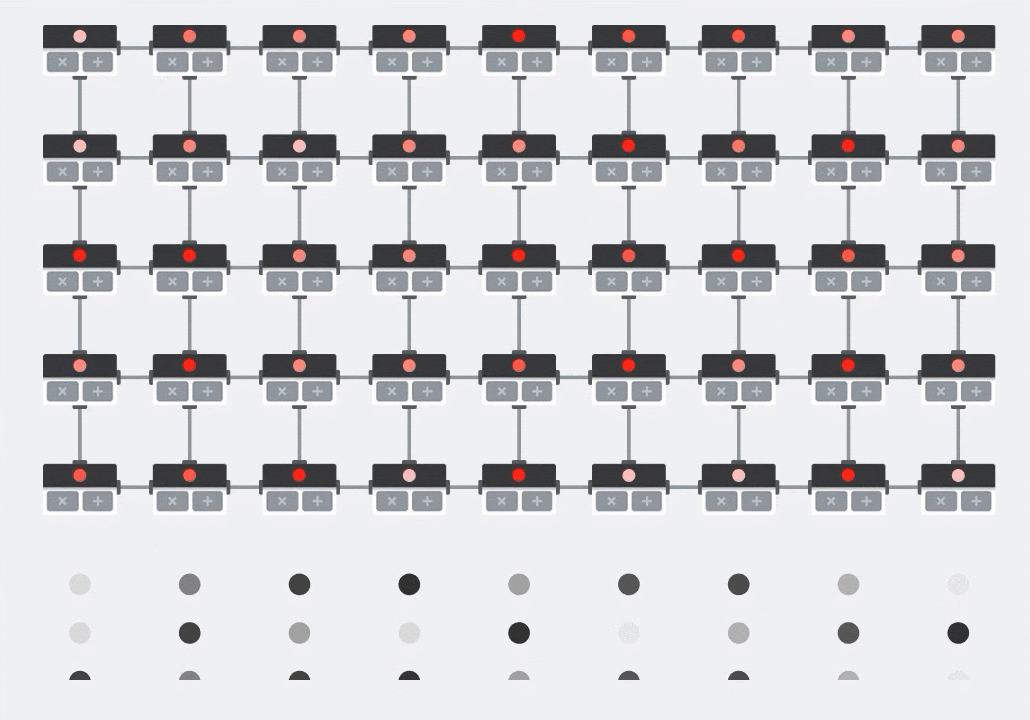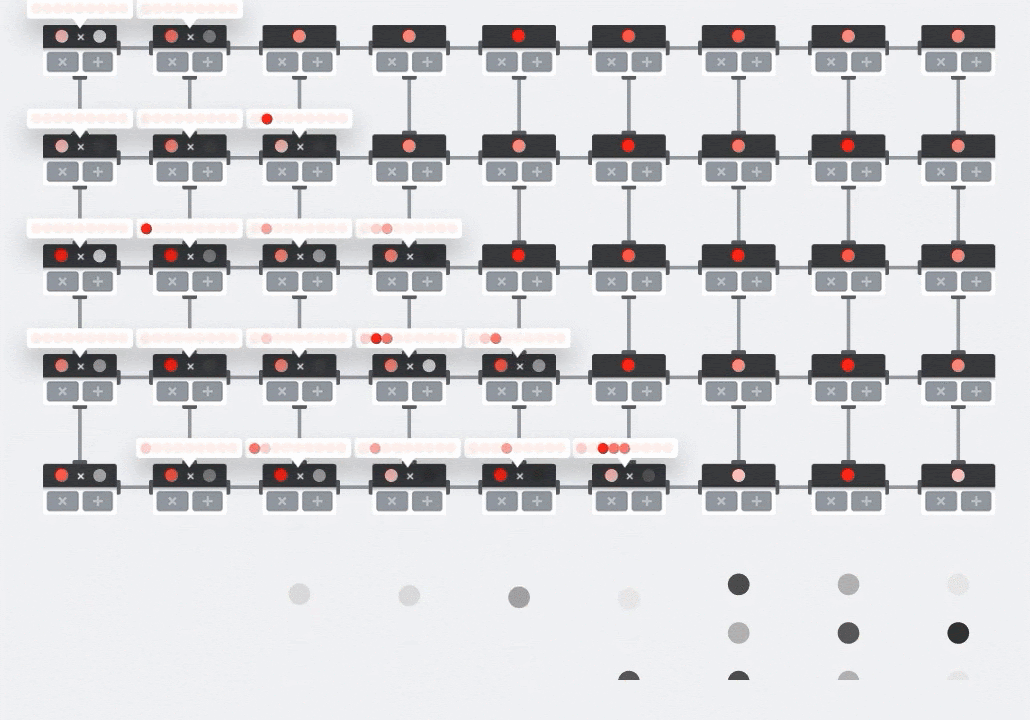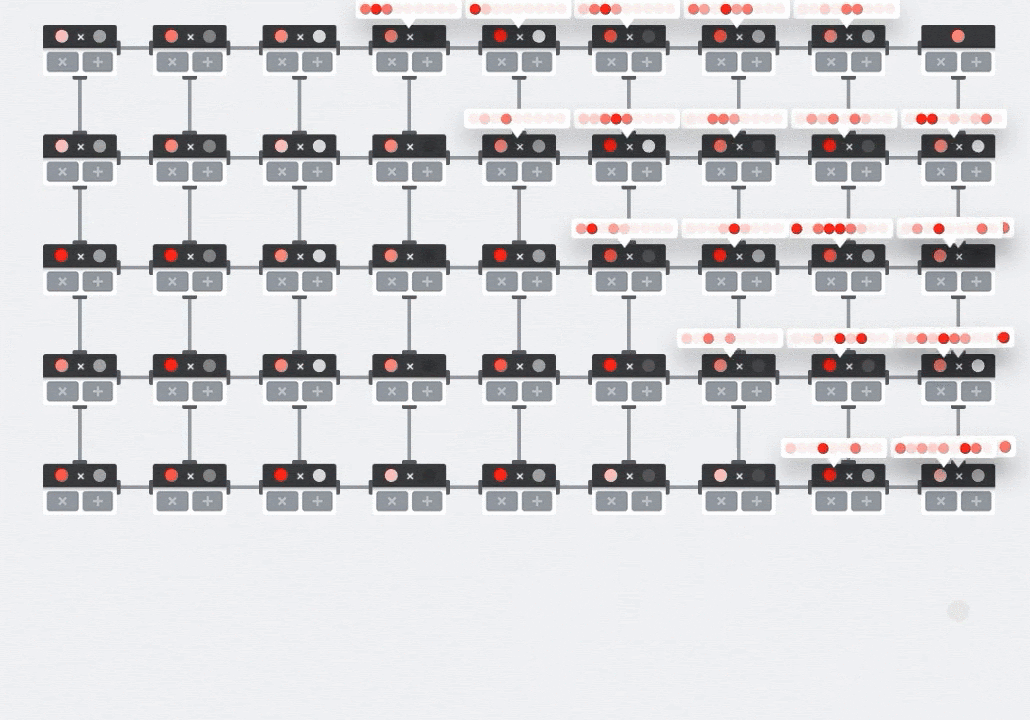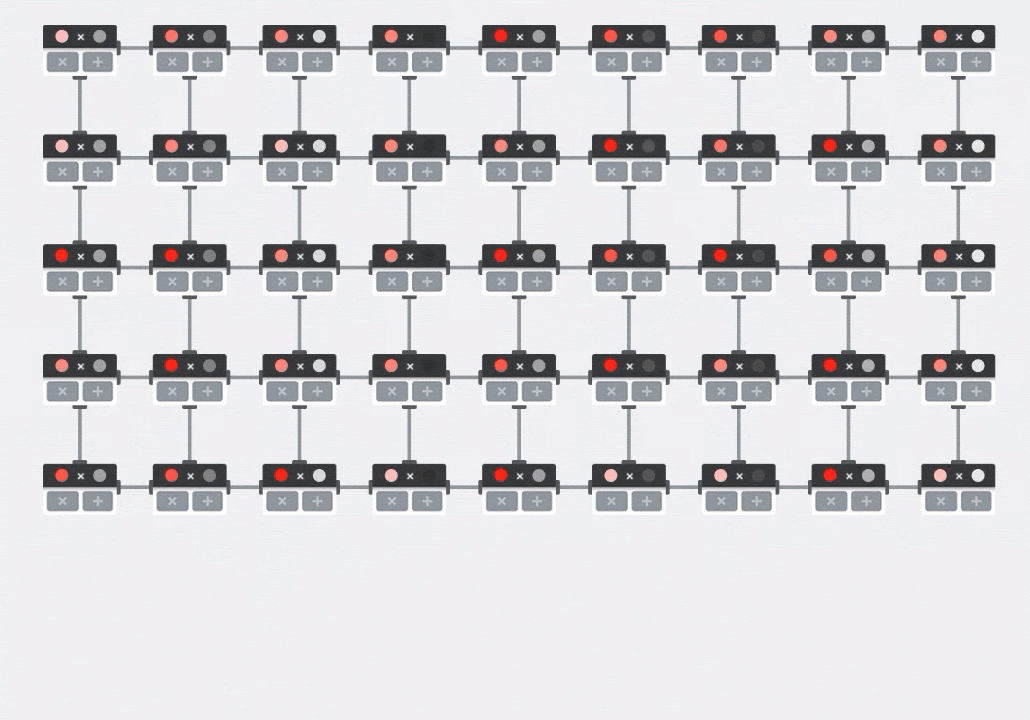
Ilustrasi: array sistolik MXU. Elemen komputasi adalah multiply-accumulator. Nilai satu matriks dimuat ke dalam array (titik merah). Nilai matriks lainnya mengalir melalui array (titik abu-abu). Garis vertikal menyebarkan nilai ke atas. Garis horizontal menyebarkan jumlah parsial. Pengguna harus memverifikasi bahwa saat data mengalir melalui array, Anda akan mendapatkan hasil perkalian matriks yang keluar dari sisi kanan.
Selain itu, saat perkalian titik dihitung dalam MXU, jumlah antara hanya mengalir di antara unit komputasi yang berdekatan. Nilai ini tidak perlu disimpan dan diambil ke/dari memori atau bahkan file register. Hasil akhirnya adalah arsitektur array sistolik TPU memiliki keunggulan kepadatan dan daya yang signifikan, serta keunggulan kecepatan yang tidak dapat diabaikan dibandingkan GPU, saat menghitung perkalian matriks.
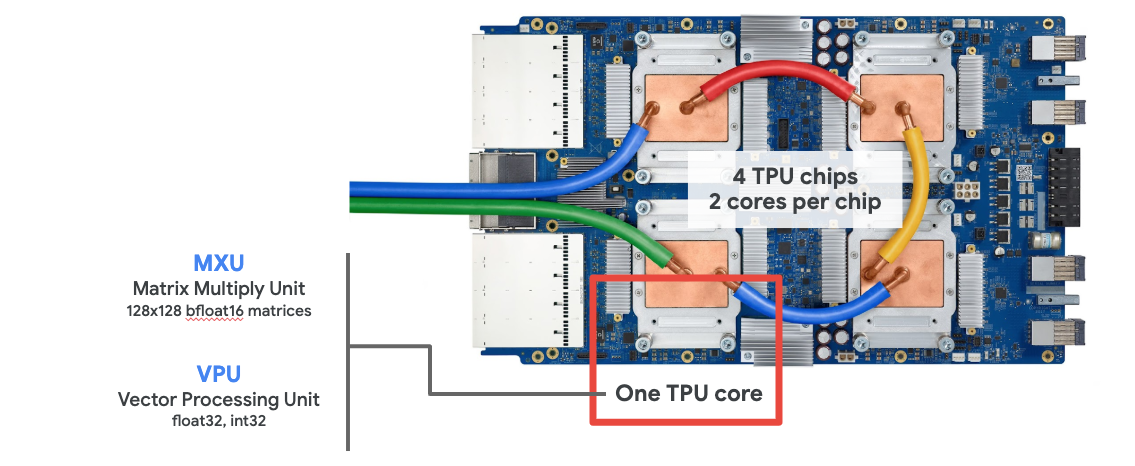
Cloud TPU
Saat Anda meminta satu " Cloud TPU v2" di Google Cloud Platform, Anda akan mendapatkan mesin virtual (VM) yang memiliki board TPU yang terhubung ke PCI. Board TPU memiliki empat chip TPU dual-core. Setiap inti TPU memiliki VPU (Vector Processing Unit) dan MXU (MatriX multiply Unit) 128x128. "Cloud TPU" ini kemudian biasanya terhubung melalui jaringan ke VM yang memintanya. Jadi, gambaran lengkapnya akan terlihat seperti ini:

Ilustrasi: VM Anda dengan akselerator "Cloud TPU" yang terhubung ke jaringan. "Cloud TPU" itu sendiri terdiri dari VM dengan board TPU yang terhubung ke PCI dengan empat chip TPU dual-core di dalamnya.
Pod TPU
Di pusat data Google, TPU terhubung ke interkoneksi komputasi berperforma tinggi (HPC) yang dapat membuatnya muncul sebagai satu akselerator yang sangat besar. Google menyebutnya pod dan pod ini dapat mencakup hingga 512 core TPU v2 atau 2048 core TPU v3.

Ilustrasi: pod TPU v3. Board dan rak TPU yang terhubung melalui interkoneksi HPC.
Selama pelatihan, gradien dipertukarkan antar-core TPU menggunakan algoritma pengurangan penuh ( penjelasan yang baik tentang pengurangan penuh di sini). Model yang dilatih dapat memanfaatkan hardware dengan melatih ukuran batch yang besar.

Ilustrasi: sinkronisasi gradien selama pelatihan menggunakan algoritma all-reduce di jaringan HPC mesh toroida 2-D TPU Google.
Software
Pelatihan ukuran batch besar
Ukuran batch yang ideal untuk TPU adalah 128 item data per core TPU, tetapi hardware sudah dapat menunjukkan pemanfaatan yang baik dari 8 item data per core TPU. Ingat bahwa satu Cloud TPU memiliki 8 core.
Dalam lab kode ini, kita akan menggunakan Keras API. Di Keras, batch yang Anda tentukan adalah ukuran batch global untuk seluruh TPU. Batch Anda akan otomatis dibagi menjadi 8 dan dijalankan di 8 core TPU.

Untuk tips performa tambahan, lihat Panduan Performa TPU. Untuk ukuran batch yang sangat besar, penanganan khusus mungkin diperlukan di beberapa model. Lihat LARSOptimizer untuk mengetahui detail selengkapnya.
Di balik layar: XLA
Program Tensorflow menentukan grafik komputasi. TPU tidak menjalankan kode Python secara langsung, tetapi menjalankan grafik komputasi yang ditentukan oleh program Tensorflow Anda. Di balik layar, compiler yang disebut XLA (compiler Linear Algebra yang dipercepat) mengubah grafik node komputasi Tensorflow menjadi kode mesin TPU. Compiler ini juga melakukan banyak pengoptimalan lanjutan pada kode dan tata letak memori Anda. Kompilasi terjadi secara otomatis saat tugas dikirim ke TPU. Anda tidak harus menyertakan XLA dalam rantai build secara eksplisit.

Ilustrasi: untuk dijalankan di TPU, graf komputasi yang ditentukan oleh program Tensorflow Anda pertama-tama diterjemahkan ke dalam representasi XLA (compiler aljabar linier yang dipercepat), lalu dikompilasi oleh XLA ke dalam kode mesin TPU.
Menggunakan TPU di Keras
TPU didukung melalui Keras API mulai Tensorflow 2.1. Dukungan Keras berfungsi di TPU dan pod TPU. Berikut adalah contoh yang berfungsi di TPU, GPU, dan CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Dalam cuplikan kode ini:
TPUClusterResolver().connect()menemukan TPU di jaringan. Fungsi ini dapat digunakan tanpa parameter di sebagian besar sistem Google Cloud (job AI Platform, Colaboratory, Kubeflow, VM Deep Learning yang dibuat melalui utilitas 'ctpu up'). Sistem ini mengetahui lokasi TPU berkat variabel lingkungan TPU_NAME. Jika Anda membuat TPU secara manual, tetapkan variabel lingkungan TPU_NAME di VM yang Anda gunakan, atau panggilTPUClusterResolverdengan parameter eksplisit:TPUClusterResolver(tp_uname, zone, project)TPUStrategyadalah bagian yang menerapkan algoritma sinkronisasi gradien "all-reduce" dan distribusi.- Strategi diterapkan melalui cakupan. Model harus ditentukan dalam strategy scope().
- Fungsi
tpu_model.fitmengharapkan objek tf.data.Dataset sebagai input untuk pelatihan TPU.
Tugas umum porting TPU
- Meskipun ada banyak cara untuk memuat data dalam model Tensorflow, untuk TPU, penggunaan API
tf.data.Datasetdiperlukan. - TPU sangat cepat dan penyerapan data sering kali menjadi hambatan saat berjalan di TPU. Ada alat yang dapat Anda gunakan untuk mendeteksi hambatan data dan tips performa lainnya di Panduan Performa TPU.
- Angka int8 atau int16 diperlakukan sebagai int32. TPU tidak memiliki hardware bilangan bulat yang beroperasi pada kurang dari 32 bit.
- Beberapa operasi Tensorflow tidak didukung. Daftarnya ada di sini. Kabar baiknya adalah batasan ini hanya berlaku untuk kode pelatihan, yaitu penerusan dan penerusan mundur melalui model Anda. Anda tetap dapat menggunakan semua operasi Tensorflow di pipeline input data karena akan dieksekusi di CPU.
tf.py_functidak didukung di TPU.
4. [INFO] Pengklasifikasi jaringan neural 101
Singkatnya
Jika semua istilah yang dicetak tebal di paragraf berikutnya sudah Anda ketahui, Anda dapat melanjutkan ke latihan berikutnya. Jika Anda baru memulai deep learning, selamat datang, dan silakan baca terus.
Untuk model yang dibuat sebagai urutan lapisan, Keras menawarkan Sequential API. Misalnya, pengklasifikasi gambar yang menggunakan tiga lapisan padat dapat ditulis di Keras sebagai:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Jaringan neural padat
Ini adalah jaringan neural paling sederhana untuk mengklasifikasikan gambar. Jaringan ini terdiri dari "neuron" yang disusun dalam lapisan. Lapisan pertama memproses data input dan memasukkan outputnya ke lapisan lain. Lapisan ini disebut "padat" karena setiap neuron terhubung ke semua neuron di lapisan sebelumnya.

Anda dapat memasukkan gambar ke dalam jaringan seperti itu dengan meratakan nilai RGB semua pikselnya menjadi vektor panjang dan menggunakannya sebagai input. Teknik ini bukan yang terbaik untuk pengenalan gambar, tetapi kami akan meningkatkannya nanti.
Neuron, aktivasi, RELU
"Neuron" menghitung jumlah bobot semua inputnya, menambahkan nilai yang disebut "bias", dan meneruskan hasilnya melalui "fungsi aktivasi". Bobot dan bias tidak diketahui pada awalnya. Bobot ini akan diinisialisasi secara acak dan "dipelajari" dengan melatih jaringan neural pada banyak data yang diketahui.

Fungsi aktivasi yang paling populer disebut RELU untuk Rectified Linear Unit. Ini adalah fungsi yang sangat sederhana seperti yang dapat Anda lihat pada grafik di atas.
Aktivasi softmax
Jaringan di atas diakhiri dengan lapisan 5 neuron karena kita mengklasifikasikan bunga ke dalam 5 kategori (mawar, tulip, dandelion, daisy, bunga matahari). Neuron di lapisan perantara diaktifkan menggunakan fungsi aktivasi RELU klasik. Namun, di lapisan terakhir, kita ingin menghitung angka antara 0 dan 1 yang merepresentasikan probabilitas bunga ini sebagai mawar, tulip, dan sebagainya. Untuk itu, kita akan menggunakan fungsi aktivasi yang disebut "softmax".
Penerapan softmax pada vektor dilakukan dengan mengambil eksponensial setiap elemen, lalu menormalisasi vektor, biasanya menggunakan norma L1 (jumlah nilai absolut) sehingga nilai-nilai tersebut berjumlah 1 dan dapat ditafsirkan sebagai probabilitas.
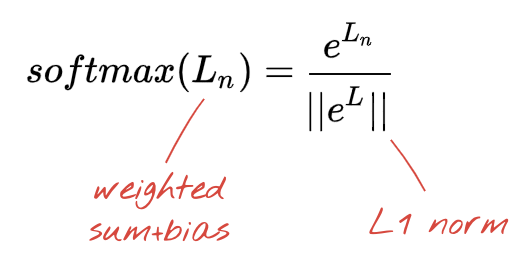

Kerugian entropi silang
Setelah jaringan neural kita menghasilkan prediksi dari gambar input, kita perlu mengukur seberapa baik prediksi tersebut, yaitu jarak antara yang disampaikan jaringan dan jawaban yang benar, yang sering disebut "label". Ingatlah bahwa kita memiliki label yang benar untuk semua gambar dalam set data.
Jarak apa pun akan berfungsi, tetapi untuk masalah klasifikasi, yang disebut "jarak entropi silang" adalah yang paling efektif. Kita akan menyebutnya sebagai fungsi error atau "loss":

Penurunan gradien
"Melatih" jaringan neural sebenarnya berarti menggunakan gambar dan label pelatihan untuk menyesuaikan bobot dan bias sehingga meminimalkan fungsi kerugian entropi silang. Berikut cara kerjanya.
Cross-entropy adalah fungsi bobot, bias, piksel gambar pelatihan, dan kelasnya yang diketahui.
Jika kita menghitung turunan parsial cross-entropy relatif terhadap semua bobot dan semua bias, kita akan mendapatkan "gradien", yang dihitung untuk gambar, label, dan nilai bobot dan bias saat ini. Ingatlah bahwa kita dapat memiliki jutaan bobot dan bias, sehingga menghitung gradien akan membutuhkan banyak pekerjaan. Untungnya, Tensorflow melakukannya untuk kita. Properti matematika gradien adalah bahwa gradien mengarah "ke atas". Karena kita ingin menuju tempat dengan entropi silang yang rendah, kita bergerak ke arah yang berlawanan. Kita memperbarui bobot dan bias dengan sebagian kecil gradien. Kemudian, kita melakukan hal yang sama berulang kali menggunakan batch berikutnya dari gambar dan label pelatihan, dalam loop pelatihan. Semoga, proses ini akan mencapai titik di mana entropi silang minimal, meskipun tidak ada jaminan bahwa minimum ini unik.

Mini-batching dan momentum
Anda dapat menghitung gradien hanya pada satu contoh gambar dan langsung memperbarui bobot dan bias, tetapi melakukannya pada batch, misalnya, 128 gambar akan memberikan gradien yang lebih baik dalam merepresentasikan batasan yang diberlakukan oleh contoh gambar yang berbeda dan oleh karena itu cenderung lebih cepat mencapai solusi. Ukuran tumpukan mini adalah parameter yang dapat disesuaikan.
Teknik ini, yang terkadang disebut "stochastic gradient descent", memiliki manfaat lain yang lebih pragmatis: bekerja dengan batch juga berarti bekerja dengan matriks yang lebih besar dan biasanya lebih mudah dioptimalkan di GPU dan TPU.
Konvergensi masih bisa sedikit kacau dan bahkan dapat berhenti jika vektor gradien semuanya nol. Apakah itu berarti kita telah menemukan nilai minimum? Tidak selalu. Komponen gradien dapat bernilai nol pada minimum atau maksimum. Dengan vektor gradien yang memiliki jutaan elemen, jika semuanya adalah nol, probabilitas bahwa setiap nol sesuai dengan titik minimum dan tidak ada yang sesuai dengan titik maksimum cukup kecil. Dalam ruang dengan banyak dimensi, titik pelana cukup umum dan kita tidak ingin berhenti di titik tersebut.

Ilustrasi: titik pelana. Gradiennya adalah 0, tetapi bukan minimum di semua arah. (Atribusi gambar Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
Solusinya adalah menambahkan beberapa momentum ke algoritma pengoptimalan sehingga dapat melewati titik pelana tanpa berhenti.
Glosarium
batch atau mini-batch: pelatihan selalu dilakukan pada batch data dan label pelatihan. Dengan demikian, algoritma dapat melakukan konvergensi. Dimensi "batch" biasanya merupakan dimensi pertama tensor data. Misalnya, tensor dengan bentuk [100, 192, 192, 3] berisi 100 gambar berukuran 192x192 piksel dengan tiga nilai per piksel (RGB).
Kerugian entropi silang: fungsi kerugian khusus yang sering digunakan dalam pengklasifikasi.
lapisan padat: lapisan neuron di mana setiap neuron terhubung ke semua neuron di lapisan sebelumnya.
fitur: input jaringan saraf terkadang disebut "fitur". Seni mencari tahu bagian mana dari set data (atau kombinasi bagian) yang akan dimasukkan ke jaringan neural untuk mendapatkan prediksi yang baik disebut "rekayasa fitur".
label: nama lain untuk "kelas" atau jawaban yang benar dalam masalah klasifikasi terawasi
kecepatan pembelajaran: fraksi gradien yang digunakan untuk memperbarui bobot dan bias pada setiap iterasi loop pelatihan.
logits: output lapisan neuron sebelum fungsi aktivasi diterapkan disebut "logits". Istilah ini berasal dari "fungsi logistik" alias "fungsi sigmoid" yang dulunya merupakan fungsi aktivasi paling populer. "Neuron outputs before logistic function" disingkat menjadi "logits".
loss: fungsi error yang membandingkan output jaringan neural dengan jawaban yang benar
neuron: menghitung jumlah input yang diberi bobot, menambahkan bias, dan meneruskan hasilnya melalui fungsi aktivasi.
enkode one-hot: kelas 3 dari 5 dienkode sebagai vektor 5 elemen, semua nol kecuali yang ke-3 yaitu 1.
relu: unit linear yang diperbaiki. Fungsi aktivasi yang populer untuk neuron.
sigmoid: fungsi aktivasi lain yang dulu populer dan masih berguna dalam kasus khusus.
softmax: fungsi aktivasi khusus yang bekerja pada vektor, meningkatkan perbedaan antara komponen terbesar dan semua komponen lainnya, serta menormalisasi vektor agar memiliki jumlah 1 sehingga dapat ditafsirkan sebagai vektor probabilitas. Digunakan sebagai langkah terakhir dalam pengklasifikasi.
tensor: "Tensor" seperti matriks, tetapi dengan jumlah dimensi yang berubah-ubah. Tensor 1 dimensi adalah vektor. Tensor 2 dimensi adalah matriks. Kemudian, Anda dapat memiliki tensor dengan 3, 4, 5, atau lebih dimensi.
5. [INFO BARU] Jaringan neural konvolusional
Singkatnya
Jika semua istilah yang dicetak tebal di paragraf berikutnya sudah Anda ketahui, Anda dapat melanjutkan ke latihan berikutnya. Jika Anda baru memulai jaringan neural konvolusional, silakan baca terus.

Ilustrasi: memfilter gambar dengan dua filter berurutan yang masing-masing terdiri dari 48 bobot yang dapat dipelajari (4x4x3=48).
Berikut tampilan jaringan neural konvolusional sederhana di Keras:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
Dasar-dasar jaringan neural konvolusional
Dalam lapisan jaringan konvolusional, satu "neuron" melakukan jumlah berbobot piksel tepat di atasnya, hanya di seluruh area kecil gambar. Lapisan ini menambahkan bias dan memasukkan jumlah melalui fungsi aktivasi, seperti yang dilakukan neuron di lapisan padat biasa. Operasi ini kemudian diulangi di seluruh gambar menggunakan bobot yang sama. Ingatlah bahwa di lapisan padat, setiap neuron memiliki bobotnya sendiri. Di sini, satu "patch" bobot meluncur di seluruh gambar ke kedua arah (sebuah "konvolusi"). Output memiliki nilai sebanyak jumlah piksel dalam gambar (meskipun beberapa padding diperlukan di tepi). Operasi ini adalah operasi pemfilteran, menggunakan filter dengan 4x4x3=48 bobot.
Namun, 48 bobot tidak akan cukup. Untuk menambahkan lebih banyak derajat kebebasan, kita mengulangi operasi yang sama dengan kumpulan bobot baru. Tindakan ini akan menghasilkan serangkaian output filter baru. Mari kita sebutnya sebagai "saluran" output berdasarkan analogi dengan saluran R,G,B dalam gambar input.
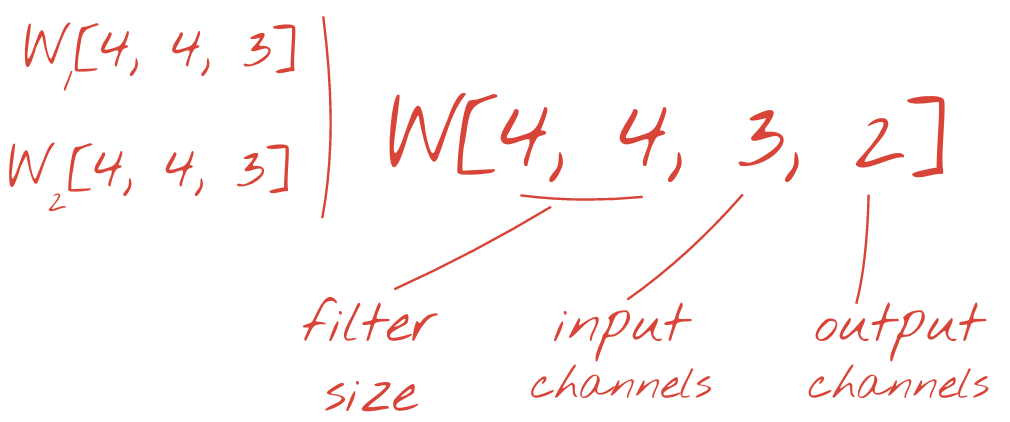
Dua (atau lebih) set bobot dapat dijumlahkan sebagai satu tensor dengan menambahkan dimensi baru. Hal ini memberi kita bentuk umum tensor bobot untuk lapisan konvolusional. Karena jumlah saluran input dan output adalah parameter, kita dapat mulai menumpuk dan merangkai lapisan konvolusional.

Ilustrasi: jaringan neural konvolusional mengubah "kubus" data menjadi "kubus" data lainnya.
Konvolusi berirama, penggabungan maks
Dengan melakukan konvolusi dengan langkah 2 atau 3, kita juga dapat mengecilkan kubus data yang dihasilkan dalam dimensi horizontalnya. Ada dua cara umum untuk melakukannya:
- Konvolusi berirama: filter geser seperti di atas, tetapi dengan irama >1
- Penggabungan maks: jendela geser yang menerapkan operasi MAX (biasanya pada patch 2x2, diulang setiap 2 piksel)

Ilustrasi: menggeser jendela komputasi sebesar 3 piksel akan menghasilkan lebih sedikit nilai output. Konvolusi berirama atau penggabungan maks (maks pada jendela 2x2 yang bergeser dengan irama 2) adalah cara untuk mengecilkan kubus data dalam dimensi horizontal.
Convolutional classifier (Pengklasifikasi konvolusional)
Terakhir, kita melampirkan head klasifikasi dengan meratakan kubus data terakhir dan memasukkannya melalui lapisan padat yang diaktifkan softmax. Pengklasifikasi konvolusional standar dapat terlihat seperti ini:

Ilustrasi: pengklasifikasi gambar menggunakan lapisan konvolusional dan softmax. Menggunakan filter 3x3 dan 1x1. Lapisan maxpool mengambil nilai maksimum dari grup titik data 2x2. Kepala klasifikasi diimplementasikan dengan lapisan padat dengan aktivasi softmax.
Di Keras
Stack konvolusional yang diilustrasikan di atas dapat ditulis di Keras seperti ini:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
6. Convnet kustom Anda
Interaktif
Mari kita bangun dan latih jaringan neural konvolusional dari awal. Dengan menggunakan TPU, kita dapat melakukan iterasi dengan sangat cepat. Buka notebook berikut, jalankan sel (Shift-ENTER), dan ikuti petunjuk di mana pun Anda melihat label "TINDAKAN DIPERLUKAN".

Keras_Flowers_TPU (playground).ipynb
Tujuannya adalah untuk mengalahkan akurasi 75% dari model transfer learning. Model tersebut memiliki keunggulan karena telah dilatih sebelumnya pada set data yang berisi jutaan gambar, sementara kita hanya memiliki 3.670 gambar di sini. Setidaknya, bisakah Anda mencocokkannya?
Informasi tambahan
Berapa banyak lapisan, seberapa besar?
Memilih ukuran lapisan lebih merupakan seni daripada sains. Anda harus menemukan keseimbangan yang tepat antara memiliki terlalu sedikit dan terlalu banyak parameter (bobot dan bias). Dengan bobot yang terlalu sedikit, jaringan saraf tidak dapat merepresentasikan kompleksitas bentuk bunga. Jika terlalu banyak, model dapat rentan terhadap "overfitting", yaitu mengkhususkan diri pada gambar pelatihan dan tidak dapat melakukan generalisasi. Dengan banyak parameter, model juga akan lambat dilatih. Di Keras, fungsi model.summary() menampilkan struktur dan jumlah parameter model Anda:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
Beberapa tips:
- Memiliki beberapa lapisan adalah hal yang membuat jaringan neural "dalam" menjadi efektif. Untuk masalah pengenalan bunga sederhana ini, 5 hingga 10 lapisan sudah cukup.
- Gunakan filter kecil. Biasanya, filter 3x3 bagus di mana saja.
- Filter 1x1 juga dapat digunakan dan harganya murah. Filter ini tidak benar-benar "memfilter" apa pun, tetapi menghitung kombinasi linear saluran. Ganti dengan filter asli. (Selengkapnya tentang "konvolusi 1x1" di bagian berikutnya.)
- Untuk masalah klasifikasi seperti ini, lakukan downsampling secara sering dengan lapisan max-pooling (atau konvolusi dengan langkah >1). Anda tidak peduli di mana bunga itu berada, yang penting bunga itu adalah mawar atau dandelion, sehingga kehilangan informasi x dan y tidak penting dan memfilter area yang lebih kecil lebih murah.
- Jumlah filter biasanya menjadi mirip dengan jumlah kelas di akhir jaringan (mengapa? lihat trik "global average pooling" di bawah). Jika Anda mengklasifikasikan ke dalam ratusan kelas, tingkatkan jumlah filter secara progresif di lapisan berurutan. Untuk set data bunga dengan 5 kelas, pemfilteran dengan hanya 5 filter tidak akan cukup. Anda dapat menggunakan jumlah filter yang sama di sebagian besar lapisan, misalnya 32, dan menguranginya di bagian akhir.
- Lapisan Dense akhir mahal. Bobotnya bisa lebih banyak daripada gabungan semua lapisan konvolusional. Misalnya, meskipun dengan output yang sangat wajar dari kubus data terakhir dengan 24x24x10 titik data, lapisan padat 100 neuron akan berharga 24x24x10x100=576.000 bobot. Coba pikirkan baik-baik, atau coba penggabungan rata-rata global (lihat di bawah).
Penggabungan rata-rata global
Daripada menggunakan lapisan padat yang mahal di akhir jaringan saraf tiruan konvolusional, Anda dapat membagi "kubus" data yang masuk menjadi sebanyak yang Anda miliki kelas, menghitung rata-rata nilainya, dan memasukkannya melalui fungsi aktivasi softmax. Cara membangun head klasifikasi ini tidak memerlukan bobot. Di Keras, sintaksisnya adalah tf.keras.layers.GlobalAveragePooling2D().

Solusi
Berikut adalah notebook solusi. Anda dapat menggunakannya jika mengalami masalah.
Keras_Flowers_TPU (solution).ipynb
Yang telah kita bahas
- 🤔 Bereksperimen dengan lapisan konvolusional
- 🤓 Bereksperimen dengan penggabungan maks, langkah, penggabungan rata-rata global, ...
- 😀 melakukan iterasi pada model dunia nyata dengan cepat di TPU
Luangkan waktu sejenak untuk meninjau checklist ini dalam pikiran Anda.
7. Selamat!
Anda telah membangun jaringan neural konvolusional modern pertama dan melatihnya hingga akurasi 80% +, dengan melakukan iterasi pada arsitekturnya hanya dalam beberapa menit berkat TPU. Lanjutkan ke lab berikutnya untuk mempelajari arsitektur konvolusional modern:
- Pipeline data berkecepatan TPU: tf.data.Dataset dan TFRecords
- Model Keras pertama Anda, dengan pemelajaran transfer
- [LAB INI] Jaringan neural konvolusional, dengan Keras dan TPU
- Convnets, squeezenet, dan Xception modern, dengan Keras dan TPU
TPU dalam praktik
TPU dan GPU tersedia di Cloud AI Platform:
- Di Deep Learning VM
- Di AI Platform Notebooks
- Dalam tugas AI Platform Training
Terakhir, kami menyambut masukan dengan tangan terbuka. Beri tahu kami jika Anda melihat sesuatu yang tidak beres di lab ini atau jika menurut Anda lab ini harus ditingkatkan. Masukan dapat diberikan melalui masalah GitHub [ link masukan].

|

