
1. บทนำ
ผลิตภัณฑ์ Generative AI ค่อนข้างใหม่และลักษณะการทำงานของแอปพลิเคชันอาจแตกต่างกันมากกว่าซอฟต์แวร์รูปแบบก่อนหน้า ด้วยเหตุนี้จึงจำเป็นต้องตรวจสอบโมเดลแมชชีนเลิร์นนิงที่ใช้ ดูตัวอย่างพฤติกรรมของโมเดล และตรวจสอบสิ่งที่น่าประหลาดใจ
เครื่องมือการเรียนรู้เพื่อความสามารถในการตีความ (LIT; เว็บไซต์, GitHub) เป็นแพลตฟอร์มสำหรับการแก้ไขข้อบกพร่องและการวิเคราะห์โมเดล ML เพื่อทำความเข้าใจเหตุผลและวิธีการทำงานของโมเดล
ในโค้ดแล็บนี้ คุณจะได้เรียนรู้วิธีใช้ LIT เพื่อรับประโยชน์เพิ่มเติมจากโมเดล Gemma ของ Google Codelab นี้แสดงวิธีใช้ความโดดเด่นของลำดับ ซึ่งเป็นเทคนิคการตีความ เพื่อวิเคราะห์แนวทางการสร้างพรอมต์ต่างๆ
วัตถุประสงค์การเรียนรู้:
- ทำความเข้าใจความโดดเด่นของลำดับและการใช้งานในการวิเคราะห์โมเดล
- การตั้งค่า LIT สำหรับ Gemma เพื่อคำนวณเอาต์พุตพรอมต์และลำดับความโดดเด่น
- ใช้ความโดดเด่นของลำดับผ่านโมดูลความโดดเด่นของ LM เพื่อทำความเข้าใจผลกระทบของการออกแบบพรอมต์ต่อเอาต์พุตของโมเดล
- ทดสอบการปรับปรุงพรอมต์ที่ตั้งสมมติฐานไว้ใน LIT และดูผลลัพธ์
โปรดทราบว่า Codelab นี้ใช้การติดตั้งใช้งาน KerasNLP ของ Gemma และ TensorFlow v2 สำหรับแบ็กเอนด์ เราขอแนะนำอย่างยิ่งให้ใช้เคอร์เนล GPU เพื่อทำตาม

2. ความโดดเด่นของลำดับและการใช้งานในการวิเคราะห์โมเดล
โมเดล Generative แบบข้อความต่อข้อความ เช่น Gemma จะรับลำดับอินพุตในรูปแบบข้อความที่แปลงเป็นโทเค็น แล้วสร้างโทเค็นใหม่ซึ่งมักจะเป็นโทเค็นที่ต่อท้ายหรือเติมเต็มอินพุตนั้น การสร้างนี้จะเกิดขึ้นทีละโทเค็น โดยจะต่อท้าย (ในลูป) โทเค็นที่สร้างขึ้นใหม่แต่ละรายการกับอินพุตบวกกับการสร้างก่อนหน้าจนกว่าโมเดลจะถึงเงื่อนไขการหยุด เช่น เมื่อโมเดลสร้างโทเค็นท้ายลำดับ (EOS) หรือมีความยาวถึงขีดจำกัดสูงสุดที่กำหนดไว้ล่วงหน้า
วิธีการวัดความโดดเด่นเป็นเทคนิค Explainable AI (XAI) ประเภทหนึ่งที่สามารถบอกคุณได้ว่าส่วนใดของอินพุตมีความสําคัญต่อโมเดลสําหรับเอาต์พุตส่วนต่างๆ LIT รองรับวิธีการความโดดเด่นสำหรับงานการจัดประเภทที่หลากหลาย ซึ่งอธิบายผลกระทบของลำดับโทเค็นอินพุตต่อป้ายกำกับที่คาดการณ์ไว้ ความโดดเด่นของลำดับจะสรุปวิธีการเหล่านี้เป็นโมเดล Generative AI แบบข้อความเป็นข้อความ และอธิบายผลกระทบของโทเค็นก่อนหน้าต่อโทเค็นที่สร้างขึ้น
คุณจะใช้วิธี Grad L2 Norm ที่นี่เพื่อความโดดเด่นของลำดับ ซึ่งจะวิเคราะห์การไล่ระดับของโมเดลและให้ขนาดของอิทธิพลที่โทเค็นก่อนหน้าแต่ละรายการมีต่อเอาต์พุต วิธีนี้ง่ายและมีประสิทธิภาพ และแสดงให้เห็นแล้วว่าทำงานได้ดีในการจัดประเภทและการตั้งค่าอื่นๆ ยิ่งคะแนนความโดดเด่นสูง อิทธิพลก็จะยิ่งสูง เราใช้วิธีนี้ภายใน LIT เนื่องจากเป็นวิธีที่เข้าใจได้ง่ายและใช้กันอย่างแพร่หลายในชุมชนการวิจัยด้านความสามารถในการตีความ
วิธีการหาความโดดเด่นโดยอิงตามการไล่สีขั้นสูงเพิ่มเติม ได้แก่ Grad ⋅ Input และการไล่สีแบบผสานรวม นอกจากนี้ยังมีวิธีการที่อิงตามการตัดออก เช่น LIME และ SHAP ซึ่งอาจมีความแข็งแกร่งมากกว่า แต่มีค่าใช้จ่ายในการคำนวณสูงกว่าอย่างมาก ดูการเปรียบเทียบโดยละเอียดของวิธีการวัดความโดดเด่นต่างๆ ได้ในบทความนี้
ดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีการทางวิทยาศาสตร์ของความโดดเด่นได้ในคำอธิบายแบบอินเทอร์แอกทีฟเบื้องต้นเกี่ยวกับความโดดเด่นนี้
3. การนำเข้า สภาพแวดล้อม และรหัสการตั้งค่าอื่นๆ
ขอแนะนำให้ทำตาม Codelab นี้ใน Colab เวอร์ชันใหม่ เราขอแนะนำให้ใช้รันไทม์ของตัวเร่ง เนื่องจากคุณจะโหลดโมเดลลงในหน่วยความจำ แต่โปรดทราบว่าตัวเลือกตัวเร่งจะแตกต่างกันไปตามเวลาและขึ้นอยู่กับข้อจำกัด Colab มีการสมัครใช้บริการแบบชำระเงินหากคุณต้องการเข้าถึงตัวเร่งความเร็วที่ทรงพลังมากขึ้น หรือจะใช้รันไทม์ในเครื่องก็ได้หากเครื่องมี GPU ที่เหมาะสม
หมายเหตุ: คุณอาจเห็นคำเตือนบางอย่างในแบบฟอร์ม
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
คุณไม่ต้องสนใจข้อความเหล่านี้
ติดตั้ง LIT และ Keras NLP
สำหรับโค้ดแล็บนี้ คุณจะต้องมี keras (3) keras-nlp (0.14.) และ lit-nlp (1.2) เวอร์ชันล่าสุด รวมถึงบัญชี Kaggle เพื่อดาวน์โหลดโมเดลพื้นฐาน
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
การเข้าถึง Kaggle
หากต้องการตรวจสอบสิทธิ์กับ Kaggle คุณทำได้ดังนี้
- จัดเก็บข้อมูลเข้าสู่ระบบในไฟล์ เช่น
~/.kaggle/kaggle.json - ใช้ตัวแปรสภาพแวดล้อม
KAGGLE_USERNAMEและKAGGLE_KEYหรือ - เรียกใช้คำสั่งต่อไปนี้ในสภาพแวดล้อม Python แบบอินเทอร์แอกทีฟ เช่น Google Colab
import kagglehub
kagglehub.login()
ดูรายละเอียดเพิ่มเติมในkagglehubเอกสารประกอบ และอย่าลืมยอมรับข้อตกลงใบอนุญาตของ Gemma
การกำหนดค่า Keras
Keras 3 รองรับแบ็กเอนด์การเรียนรู้เชิงลึกหลายรายการ ซึ่งรวมถึง TensorFlow (ค่าเริ่มต้น), PyTorch และ JAX ระบบจะกำหนดค่าแบ็กเอนด์โดยใช้ตัวแปรสภาพแวดล้อม KERAS_BACKEND ซึ่งต้องตั้งค่าก่อนนำเข้าไลบรารี Keras ข้อมูลโค้ดต่อไปนี้แสดงวิธีตั้งค่าตัวแปรนี้ในสภาพแวดล้อม Python แบบอินเทอร์แอกทีฟ
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. การตั้งค่า LIT
คุณใช้ LIT ใน Python Notebook หรือผ่านเว็บเซิร์ฟเวอร์ได้ Codelab นี้มุ่งเน้นที่กรณีการใช้งาน Notebook เราขอแนะนำให้ทำตามใน Google Colab
ใน Codelab นี้ คุณจะโหลด Gemma v2 2B IT โดยใช้ค่าที่กำหนดล่วงหน้าของ KerasNLP ข้อมูลโค้ดต่อไปนี้จะเริ่มต้น Gemma และโหลดชุดข้อมูลตัวอย่างในวิดเจ็ตสมุดบันทึก LIT
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
คุณกำหนดค่าวิดเจ็ตได้โดยเปลี่ยนค่าที่ส่งไปยังอาร์กิวเมนต์ตำแหน่งที่จำเป็น 2 รายการ
datasets_config: รายการสตริงที่มีชื่อชุดข้อมูลและเส้นทางที่จะโหลดจาก "dataset:path" โดยที่เส้นทางอาจเป็น URL หรือเส้นทางไฟล์ในเครื่อง ตัวอย่างด้านล่างใช้ค่าพิเศษsample_promptsเพื่อโหลดพรอมต์ตัวอย่างที่ระบุในการเผยแพร่ LITmodels_config: รายการสตริงที่มีชื่อโมเดลและเส้นทางที่จะโหลดจาก "model:path" โดยที่เส้นทางอาจเป็น URL, เส้นทางไฟล์ในเครื่อง หรือชื่อของค่าที่กำหนดล่วงหน้าสำหรับเฟรมเวิร์กการเรียนรู้เชิงลึกที่กำหนดค่าไว้
เมื่อกำหนดค่า LIT ให้ใช้โมเดลที่คุณสนใจแล้ว ให้เรียกใช้ข้อมูลโค้ดต่อไปนี้เพื่อแสดงวิดเจ็ตใน Notebook
lit_widget.render(open_in_new_tab=True)
การใช้ข้อมูลของคุณเอง
Gemma เป็นโมเดล Generative แบบข้อความเป็นข้อความ ซึ่งรับอินพุตข้อความและสร้างเอาต์พุตข้อความ LIT ใช้ API ที่มีข้อจำกัดเพื่อสื่อสารโครงสร้างของชุดข้อมูลที่โหลดไปยังโมเดล LLM ใน LIT ออกแบบมาให้ทำงานกับชุดข้อมูลที่มี 2 ฟิลด์ ได้แก่
prompt: อินพุตไปยังโมเดลที่จะสร้างข้อความ และtarget: ลำดับเป้าหมายที่ไม่บังคับ เช่น คำตอบ "ข้อมูลจากการสังเกตการณ์โดยตรง" จากผู้ให้คะแนนที่เป็นมนุษย์หรือคำตอบที่สร้างไว้ล่วงหน้าจากโมเดลอื่น
LIT มีชุดsample_promptsขนาดเล็กพร้อมตัวอย่างจากแหล่งข้อมูลต่อไปนี้ที่รองรับ Codelab นี้และบทแนะนำการแก้ไขข้อบกพร่องของพรอมต์แบบขยายของ LIT
- GSM8K: การแก้โจทย์คณิตศาสตร์ระดับประถมศึกษาด้วยตัวอย่างแบบ Few-Shot
- การเปรียบเทียบ Gigaword: การสร้างบรรทัดแรกสำหรับคอลเล็กชันบทความสั้นๆ
- การแจ้งตามรัฐธรรมนูญ: การสร้างไอเดียใหม่ๆ เกี่ยวกับวิธีใช้วัตถุตามหลักเกณฑ์/ขอบเขต
คุณยังโหลดข้อมูลของคุณเองได้อย่างง่ายดาย ไม่ว่าจะเป็น.jsonlไฟล์ที่มีบันทึกพร้อมฟิลด์ prompt และอาจมี target (ตัวอย่าง) หรือจากรูปแบบใดก็ได้โดยใช้ Dataset API ของ LIT
เรียกใช้เซลล์ด้านล่างเพื่อโหลดพรอมต์ตัวอย่าง
5. การวิเคราะห์พรอมต์แบบ Few-Shot สำหรับ Gemma ใน LIT
ปัจจุบันการเขียนพรอมต์เป็นทั้งศาสตร์และศิลป์ และ LIT สามารถช่วยคุณปรับปรุงพรอมต์สำหรับโมเดลภาษาขนาดใหญ่ เช่น Gemma ได้อย่างเป็นรูปธรรม ต่อไปนี้ คุณจะเห็นตัวอย่างวิธีใช้ LIT เพื่อสำรวจลักษณะการทำงานของ Gemma คาดการณ์ปัญหาที่อาจเกิดขึ้น และปรับปรุงความปลอดภัย
ระบุข้อผิดพลาดในพรอมต์ที่ซับซ้อน
เทคนิคการแจ้งที่สำคัญที่สุด 2 อย่างสำหรับต้นแบบและแอปพลิเคชันที่ใช้ LLM คุณภาพสูง ได้แก่ การแจ้งแบบไม่กี่นัด (รวมถึงตัวอย่างลักษณะการทำงานที่ต้องการในการแจ้ง) และเชนออฟทอท (รวมถึงรูปแบบคำอธิบายหรือการให้เหตุผลก่อนเอาต์พุตสุดท้ายของ LLM) แต่การสร้างพรอมต์ที่มีประสิทธิภาพก็ยังคงเป็นเรื่องท้าทายอยู่
ลองพิจารณาตัวอย่างการช่วยให้ผู้อื่นประเมินว่าตนเองจะชอบอาหารหรือไม่ตามรสนิยม เทมเพลตพรอมต์แบบเชนออฟธ็อตสำหรับตัวอย่างผลิตภัณฑ์เบื้องต้นอาจมีลักษณะดังนี้
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
คุณเห็นปัญหาในพรอมต์นี้ไหม LIT จะช่วยคุณตรวจสอบพรอมต์ด้วยโมดูลความโดดเด่นของ LM
6. ใช้ความโดดเด่นของลำดับสำหรับการแก้ไขข้อบกพร่อง
LIT จะคำนวณความโดดเด่นที่ระดับที่เล็กที่สุดเท่าที่จะเป็นไปได้ (เช่น สำหรับโทเค็นอินพุตแต่ละรายการ) แต่สามารถรวบรวมความโดดเด่นของโทเค็นเป็นช่วงที่ใหญ่ขึ้นซึ่งตีความได้ง่ายกว่า เช่น บรรทัด ประโยค หรือคำ ดูข้อมูลเพิ่มเติมเกี่ยวกับความโดดเด่นและวิธีใช้เพื่อระบุอคติที่ไม่ตั้งใจใน Saliency Explorable
มาเริ่มต้นด้วยการป้อนข้อมูลตัวอย่างใหม่สำหรับตัวแปรเทมเพลตพรอมต์
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
หากเปิด UI ของ LIT ในเซลล์ด้านบนหรือในแท็บแยกต่างหาก คุณจะใช้เครื่องมือแก้ไขจุดข้อมูลของ LIT เพื่อเพิ่มพรอมต์นี้ได้
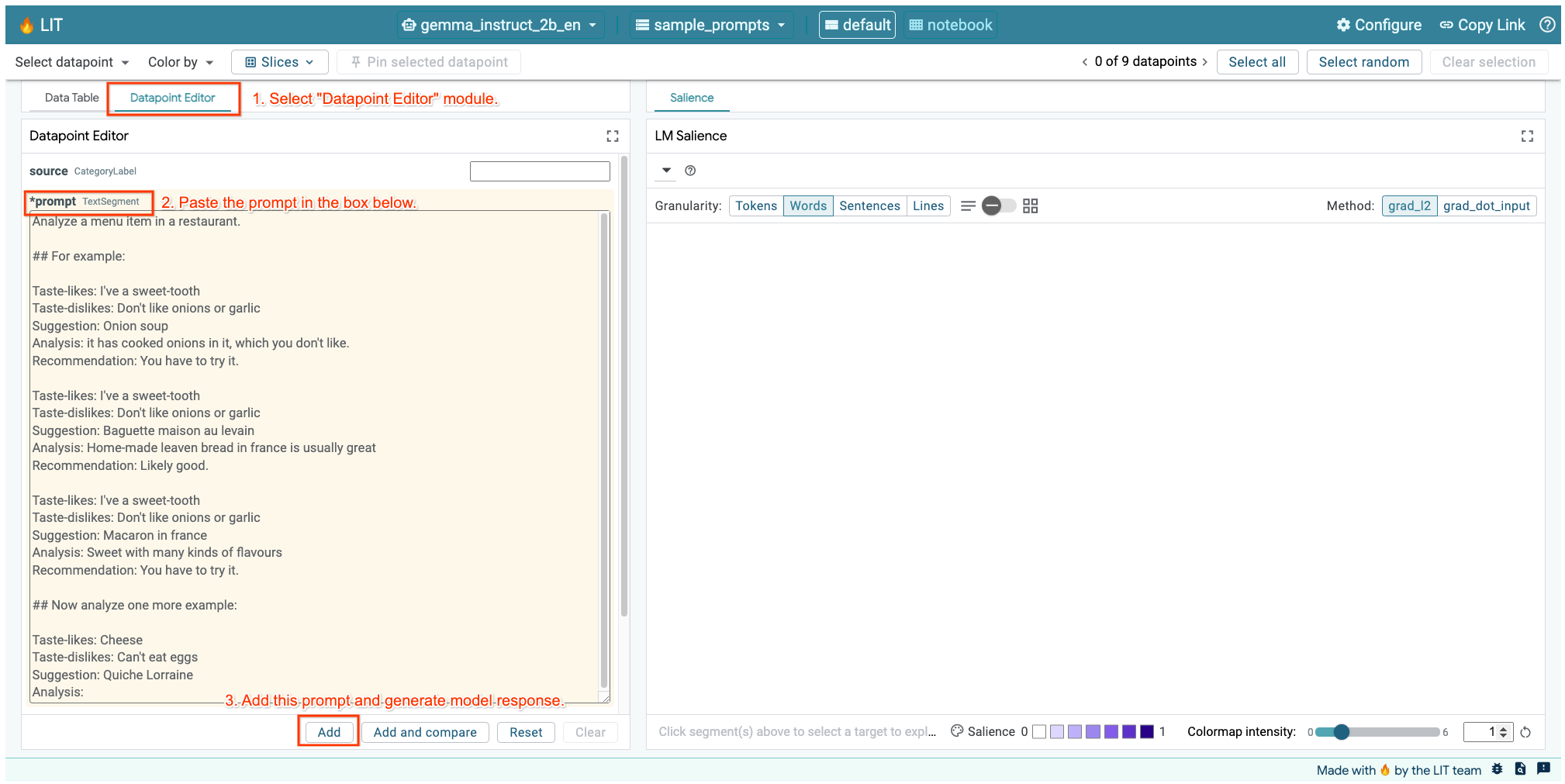
อีกวิธีหนึ่งคือการแสดงวิดเจ็ตอีกครั้งโดยตรงด้วยพรอมต์ที่สนใจ
lit_widget.render(data=[fewshot_mistake_example])
โปรดสังเกตว่าโมเดลทำงานได้น่าประหลาดใจ
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
ทำไมโมเดลจึงแนะนำให้คุณกินอาหารที่คุณบอกอย่างชัดเจนว่ากินไม่ได้
ความโดดเด่นของลำดับช่วยไฮไลต์ปัญหาหลักซึ่งอยู่ในตัวอย่างแบบ Few-Shot ในตัวอย่างแรก การให้เหตุผลแบบ Chain-of-Thought ในส่วนการวิเคราะห์ it has cooked onions in it, which you don't like ไม่ตรงกับคำแนะนำสุดท้าย You have to try it
ในโมดูลความโดดเด่นของ LM ให้เลือก "ประโยค" แล้วเลือกบรรทัดคำแนะนำ ตอนนี้ UI ควรมีลักษณะดังนี้

ซึ่งแสดงให้เห็นถึงข้อผิดพลาดที่เกิดจากมนุษย์ นั่นคือการคัดลอกและวางส่วนคำแนะนำโดยไม่ตั้งใจ และไม่ได้อัปเดตส่วนดังกล่าว
ตอนนี้เรามาแก้ไข "คำแนะนำ" ในตัวอย่างแรกเป็น Avoid แล้วลองอีกครั้ง LIT มีตัวอย่างนี้โหลดไว้ล่วงหน้าในพรอมต์ตัวอย่าง คุณจึงใช้ฟังก์ชันยูทิลิตีเล็กๆ นี้เพื่อดึงข้อมูลได้
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
ตอนนี้คำตอบของโมเดลจะเป็นดังนี้
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
บทเรียนสำคัญที่ควรได้รับจากเรื่องนี้คือ การสร้างต้นแบบตั้งแต่เนิ่นๆ จะช่วยเผยให้เห็นความเสี่ยงที่คุณอาจไม่เคยคิดถึงมาก่อน และลักษณะของโมเดลภาษาที่มักเกิดข้อผิดพลาดหมายความว่าคุณต้องออกแบบเพื่อรองรับข้อผิดพลาดล่วงหน้า คุณสามารถดูการสนทนาเพิ่มเติมเกี่ยวกับเรื่องนี้ได้ในคู่มือ People + AI สำหรับการออกแบบด้วย AI
แม้ว่าพรอมต์แบบ Few-Shot ที่แก้ไขแล้วจะดีขึ้น แต่ก็ยังไม่ถูกต้องนัก โดยบอกให้ผู้ใช้หลีกเลี่ยงไข่ได้อย่างถูกต้อง แต่เหตุผลไม่ถูกต้อง โดยบอกว่าผู้ใช้ไม่ชอบไข่ ในขณะที่ผู้ใช้ระบุว่ากินไข่ไม่ได้ ในส่วนต่อไปนี้ คุณจะเห็นวิธีปรับปรุงให้ดีขึ้น
7. ทดสอบสมมติฐานเพื่อปรับปรุงลักษณะการทำงานของโมเดล
LIT ช่วยให้คุณทดสอบการเปลี่ยนแปลงพรอมต์ภายในอินเทอร์เฟซเดียวกันได้ ในกรณีนี้ คุณจะทดสอบการเพิ่มรัฐธรรมนูญเพื่อปรับปรุงลักษณะการทำงานของโมเดล รัฐธรรมนูญอ้างอิงถึงพรอมต์การออกแบบที่มีหลักการเพื่อช่วยเป็นแนวทางในการสร้างโมเดล วิธีการล่าสุดยังช่วยให้การอนุมานเชิงโต้ตอบของหลักการตามรัฐธรรมนูญเป็นไปได้อีกด้วย
มาใช้ไอเดียนี้เพื่อช่วยปรับปรุงพรอมต์กัน เพิ่มส่วนที่มีหลักการสำหรับการสร้างที่ด้านบนของพรอมต์ ซึ่งตอนนี้จะเริ่มต้นดังนี้
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
การอัปเดตนี้ช่วยให้คุณเรียกใช้ตัวอย่างอีกครั้งและสังเกตเอาต์พุตที่แตกต่างกันได้
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
จากนั้นจึงตรวจสอบความโดดเด่นของพรอมต์อีกครั้งเพื่อช่วยให้ทราบสาเหตุของการเปลี่ยนแปลงนี้

โปรดสังเกตว่าคำแนะนำนั้นปลอดภัยกว่ามาก นอกจากนี้ "ไม่เหมาะกับคุณ" ยังได้รับอิทธิพลจากหลักการระบุความเหมาะสมอย่างชัดเจนตามข้อจำกัดด้านอาหาร พร้อมกับการวิเคราะห์ (ที่เรียกว่าห่วงโซ่ความคิด) ซึ่งจะช่วยเพิ่มความมั่นใจว่าเอาต์พุตเกิดขึ้นด้วยเหตุผลที่ถูกต้อง
8. รวมทีมที่ไม่ใช่ด้านเทคนิคไว้ในการตรวจสอบและสำรวจโมเดล
ความสามารถในการตีความควรเป็นความพยายามของทีม โดยครอบคลุมความเชี่ยวชาญด้าน XAI, นโยบาย, กฎหมาย และอื่นๆ
โดยปกติแล้ว การโต้ตอบกับโมเดลในระยะแรกของการพัฒนาต้องใช้ความเชี่ยวชาญด้านเทคนิคอย่างมาก ซึ่งทำให้ผู้ร่วมงานบางรายเข้าถึงและตรวจสอบโมเดลได้ยากขึ้น ที่ผ่านมาไม่มีเครื่องมือที่ช่วยให้ทีมเหล่านี้เข้าร่วมในระยะการสร้างต้นแบบช่วงแรกๆ ได้
เราหวังว่า LIT จะช่วยเปลี่ยนกระบวนทัศน์นี้ได้ ดังที่คุณได้เห็นผ่าน Codelab นี้ สื่อภาพและความสามารถแบบอินเทอร์แอกทีฟของ LIT ในการตรวจสอบความโดดเด่นและสำรวจตัวอย่างจะช่วยให้ผู้มีส่วนเกี่ยวข้องต่างๆ แชร์และสื่อสารผลการค้นพบได้ ซึ่งจะช่วยให้คุณมีเพื่อนร่วมทีมที่หลากหลายมากขึ้นเพื่อสำรวจ ตรวจสอบ และแก้ไขข้อบกพร่องของโมเดล การให้ผู้ใช้ได้เห็นวิธีการทางเทคนิคเหล่านี้จะช่วยเพิ่มความเข้าใจเกี่ยวกับวิธีการทำงานของโมเดล นอกจากนี้ ความเชี่ยวชาญที่หลากหลายมากขึ้นในการทดสอบโมเดลระยะแรกยังช่วยให้ค้นพบผลลัพธ์ที่ไม่พึงประสงค์ซึ่งสามารถปรับปรุงได้อีกด้วย
9. สรุป
กล่าวโดยสรุปคือ
- LIT UI มีอินเทอร์เฟซสำหรับการดำเนินการโมเดลแบบอินเทอร์แอกทีฟ ซึ่งช่วยให้ผู้ใช้สร้างเอาต์พุตได้โดยตรง รวมถึงทดสอบสถานการณ์ "จะเกิดอะไรขึ้น" ซึ่งมีประโยชน์อย่างยิ่งสําหรับการทดสอบพรอมต์รูปแบบต่างๆ
- โมดูลความโดดเด่นของ LM แสดงภาพความโดดเด่น และให้ความละเอียดของข้อมูลที่ควบคุมได้เพื่อให้คุณสื่อสารเกี่ยวกับโครงสร้างที่เน้นมนุษย์เป็นศูนย์กลาง (เช่น ประโยคและคำ) แทนโครงสร้างที่เน้นโมเดลเป็นศูนย์กลาง (เช่น โทเค็น)
เมื่อพบตัวอย่างที่มีปัญหาในการประเมินโมเดล ให้นำตัวอย่างเหล่านั้นไปไว้ใน LIT เพื่อทำการแก้ไขข้อบกพร่อง เริ่มต้นด้วยการวิเคราะห์หน่วยเนื้อหาที่ใหญ่ที่สุดที่สมเหตุสมผลซึ่งคุณคิดว่าเกี่ยวข้องกับงานการสร้างโมเดลอย่างมีตรรกะ ใช้ภาพเพื่อดูว่าโมเดลให้ความสนใจเนื้อหาพรอมต์อย่างถูกต้องหรือผิดพลาดที่ใด จากนั้นเจาะลึกลงไปในหน่วยเนื้อหาที่เล็กลงเพื่ออธิบายลักษณะการทำงานที่ไม่ถูกต้องที่คุณเห็นเพิ่มเติมเพื่อระบุการแก้ไขที่เป็นไปได้
สุดท้ายนี้ Lit จะได้รับการปรับปรุงอย่างต่อเนื่อง ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์ของเราและแชร์คำแนะนำได้ที่นี่