
1. 简介
生成式 AI 产品相对较新,应用的行为可能比早期形式的软件更加多变。因此,务必要探查所用的机器学习模型,检查模型行为的示例并调查意外情况。
Learning Interpretability Tool(LIT;网站、GitHub)是一个用于调试和分析机器学习模型的平台,可帮助您了解模型为何以及如何以特定方式运行。
在此 Codelab 中,您将学习如何使用 LIT 来充分利用 Google 的 Gemma 模型。此 Codelab 演示了如何使用序列显著性(一种可解释性技术)来分析不同的提示工程方法。
学习目标:
- 了解序列显著性及其在模型分析中的用途。
- 为 Gemma 设置 LIT,以计算提示输出和序列显著性。
- 通过 LM Salience 模块使用序列显著性来了解提示设计对模型输出的影响。
- 在 LIT 中测试假设的提示改进,并查看其影响。
注意:此 Codelab 使用 Gemma 的 KerasNLP 实现,并使用 TensorFlow v2 作为后端。强烈建议您使用 GPU 内核来学习本教程。

2. 序列显著性及其在模型分析中的应用
文生文生成模型(例如 Gemma)会以标记化文本的形式接收输入序列,并生成通常是该输入的后续内容或补全内容的新标记。此生成过程一次生成一个 token,并循环将每个新生成的 token 附加到输入和任何之前的生成结果中,直到模型达到停止条件。例如,当模型生成序列结束 (EOS) token 或达到预定义的最大长度时。
显著性方法是一类可解释 AI (XAI) 技术,可告知您输入的哪些部分对于模型输出的不同部分很重要。LIT 支持多种分类任务的显著性方法,这些方法可解释一系列输入 token 对预测标签的影响。序列显著性将这些方法推广到文生文生成模型,并解释了前面的 token 对生成的 token 的影响。
您将在此处使用 Grad L2 Norm 方法来计算序列显著性,该方法会分析模型的梯度,并提供每个前面的令牌对输出的影响程度。这种方法简单高效,并且已证明在分类和其他设置中表现良好。显著性得分越高,影响力越大。此方法在 LIT 中使用,因为它易于理解,并且在可解释性研究社区中得到广泛应用。
更高级的基于梯度的显著性方法包括 Grad ⋅ Input 和积分梯度。此外,还有基于消融的方法,例如 LIME 和 SHAP,这些方法可能更稳健,但计算成本也更高。如需详细比较不同的显著性方法,请参阅这篇文章。
如需详细了解显著性方法的科学原理,请参阅这篇关于显著性的互动式探索性入门文章。
3. 导入、环境和其他设置代码
最好在新版 Colab 中学习此 Codelab。我们建议使用加速器运行时,因为您会将模型加载到内存中,但请注意,加速器选项会随时间变化,并且受到限制。如果您想使用更强大的加速器,可以考虑订阅 Colab 的付费方案。或者,如果您的机器配备了合适的 GPU,也可以使用本地运行时。
注意:您可能会看到一些如下形式的警告
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. bigframes 0.21.0 requires scikit-learn>=1.2.2, but you have scikit-learn 1.0.2 which is incompatible. google-colab 1.0.0 requires ipython==7.34.0, but you have ipython 8.14.0 which is incompatible.
您可以放心地忽略这些消息。
安装 LIT 和 Keras NLP
在此 Codelab 中,您需要使用最新版本的 keras (3) keras-nlp (0.14.) 和 lit-nlp (1.2),并拥有 Kaggle 账号才能下载基础模型。
pip install -q -U 'keras >= 3.0' 'keras-nlp >= 0.14' 'lit-nlp >= 1.2'
Kaggle Access
如需向 Kaggle 进行身份验证,您可以执行以下任一操作:
- 将凭据存储在文件(例如
~/.kaggle/kaggle.json)中; - 使用
KAGGLE_USERNAME和KAGGLE_KEY环境变量;或者 - 在交互式 Python 环境(例如 Google Colab)中运行以下代码。
import kagglehub
kagglehub.login()
如需了解详情,请参阅 kagglehub 文档,并务必接受 Gemma 许可协议。
配置 Keras
Keras 3 支持多个深度学习后端,包括 TensorFlow(默认)、PyTorch 和 JAX。后端使用 KERAS_BACKEND 环境变量进行配置,该环境变量必须在导入 Keras 库之前设置。以下代码段展示了如何在交互式 Python 环境中设置此变量。
import os
os.environ["KERAS_BACKEND"] = "tensorflow" # or "jax" or "torch"
4. 设置 LIT
LIT 可在 Python 笔记本中或通过 Web 服务器使用。此 Codelab 侧重于笔记本使用场景,我们建议您在 Google Colab 中跟随操作。
在此 Codelab 中,您将使用 KerasNLP 预设加载 Gemma v2 2B IT。以下代码段用于初始化 Gemma,并在 LIT Notebook widget 中加载示例数据集。
from lit_nlp.examples.prompt_debugging import notebook as lit_pdbnb
lit_widget = lit_pdbnb.make_notebook_widget(
['sample_prompts'],
["gemma2_2b_it:gemma2_instruct_2b_en"],
)
您可以通过更改传递给两个必需的位置实参的值来配置 widget:
datasets_config:一个字符串列表,包含要加载的数据集名称和路径,格式为“dataset:path”,其中 path 可以是网址或本地文件路径。以下示例使用特殊值sample_prompts加载 LIT 分发中提供的示例提示。models_config:一个字符串列表,包含要加载的模型名称和路径,格式为“model:path”,其中 path 可以是网址、本地文件路径或已配置的深度学习框架的预设名称。
将 LIT 配置为使用您感兴趣的模型后,运行以下代码段以在笔记本中呈现 widget。
lit_widget.render(open_in_new_tab=True)
使用您自己的数据
作为一种文生文生成模型,Gemma 接受文本输入并生成文本输出。LIT 使用有主张的 API 将已加载数据集的结构传达给模型。LIT 中的 LLM 旨在与提供以下两个字段的数据集搭配使用:
prompt:模型将根据此输入生成文本;以及target:可选的目标序列,例如人工评估者的“标准答案”或另一模型预先生成的回答。
LIT 包含一小部分 sample_prompts,其中包含以下来源的示例,这些示例支持本 Codelab 和 LIT 的扩展提示调试教程。
- GSM8K:通过少样本示例解决小学数学问题。
- Gigaword 基准:为短篇文章集合生成标题。
- 宪法提示:根据指南/界限生成有关如何使用对象的新想法。
您还可以轻松加载自己的数据,可以是包含字段 prompt 和可选字段 target 的 .jsonl 文件(示例),也可以通过使用 LIT 的 Dataset API 加载任何格式的数据。
运行以下单元格以加载示例提示。
5. 在 LIT 中分析 Gemma 的少样本提示
如今,提示工程既是一门艺术,也是一门科学,而 LIT 可以帮助您通过实证方式改进大语言模型(例如 Gemma)的提示。接下来,您将看到一个示例,了解如何使用 LIT 来探索 Gemma 的行为、预测潜在问题并提高其安全性。
识别复杂提示中的错误
对于基于 LLM 的高质量原型和应用,最重要的两种提示技术是少样本提示(在提示中包含所需行为的示例)和思维链(在 LLM 的最终输出之前包含某种形式的说明或推理)。不过,创建有效的提示通常仍然是一项挑战。
不妨考虑一个示例,即根据某人的口味帮助其评估是否会喜欢某种食物。初始原型思维链提示模板可能如下所示:
def analyze_menu_item_template(food_likes, food_dislikes, menu_item):
return f"""Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in france is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in france
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyze one more example:
Taste-likes: {food_likes}
Taste-dislikes: {food_dislikes}
Suggestion: {menu_item}
Analysis:"""
您是否发现了此提示存在的问题?LIT 将帮助您使用 LM Salience 模块检查提示。
6. 使用序列显著性进行调试
显著性是在尽可能小的级别(即针对每个输入令牌)计算的,但 LIT 可以将令牌显著性聚合为更易于理解的较大范围,例如行、句子或字词。如需详细了解显著性以及如何使用显著性来识别无意中的偏差,请参阅我们的显著性可探索性图表。
我们先为提示模板变量提供一个新的提示示例输入:
food_likes = """Cheese"""
food_dislikes = """Can't eat eggs"""
menu_item = """Quiche Lorraine"""
prompt = analyze_menu_item_template(food_likes, food_dislikes, menu_item)
print(prompt)
fewshot_mistake_example = {'prompt': prompt} # you'll use this below
Analyze a menu item in a restaurant. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: You have to try it. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Baguette maison au levain Analysis: Home-made leaven bread in france is usually great Recommendation: Likely good. Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Macaron in france Analysis: Sweet with many kinds of flavours Recommendation: You have to try it. ## Now analyze one more example: Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis:
如果您在上面的单元格中或在单独的标签页中打开了 LIT 界面,可以使用 LIT 的数据点编辑器添加此提示:
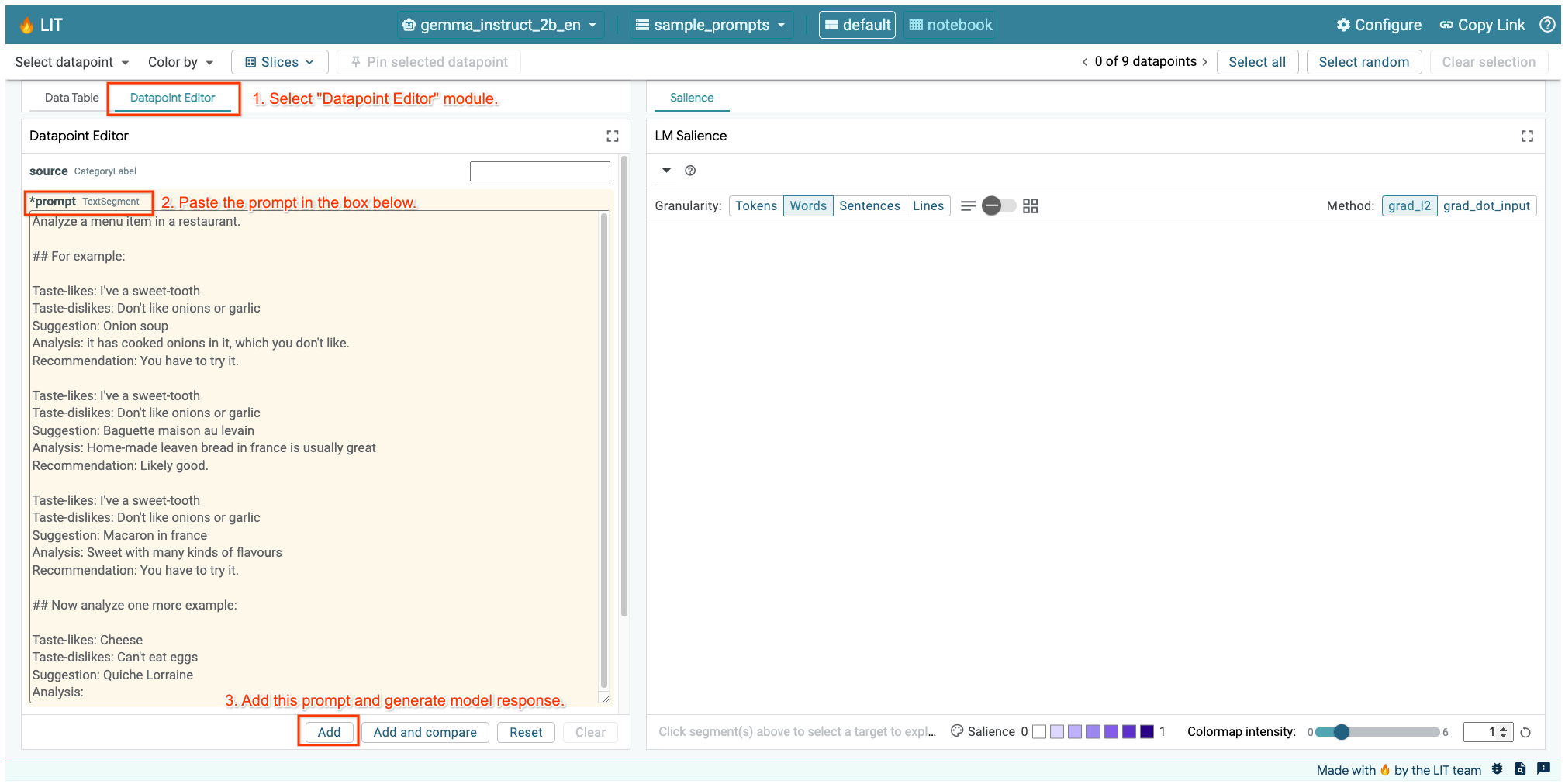
另一种方法是直接使用感兴趣的提示重新渲染 widget:
lit_widget.render(data=[fewshot_mistake_example])
请注意令人惊讶的模型补全:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
为什么模型会建议您吃您明确表示不能吃的东西?
序列显著性有助于突出显示根本问题,即小样本示例中的问题。在第一个示例中,分析部分 it has cooked onions in it, which you don't like 中的思维链推理与最终建议 You have to try it 不一致。
在“LM 显着性”模块中,选择“句子”,然后选择推荐行。界面现在应如下所示:
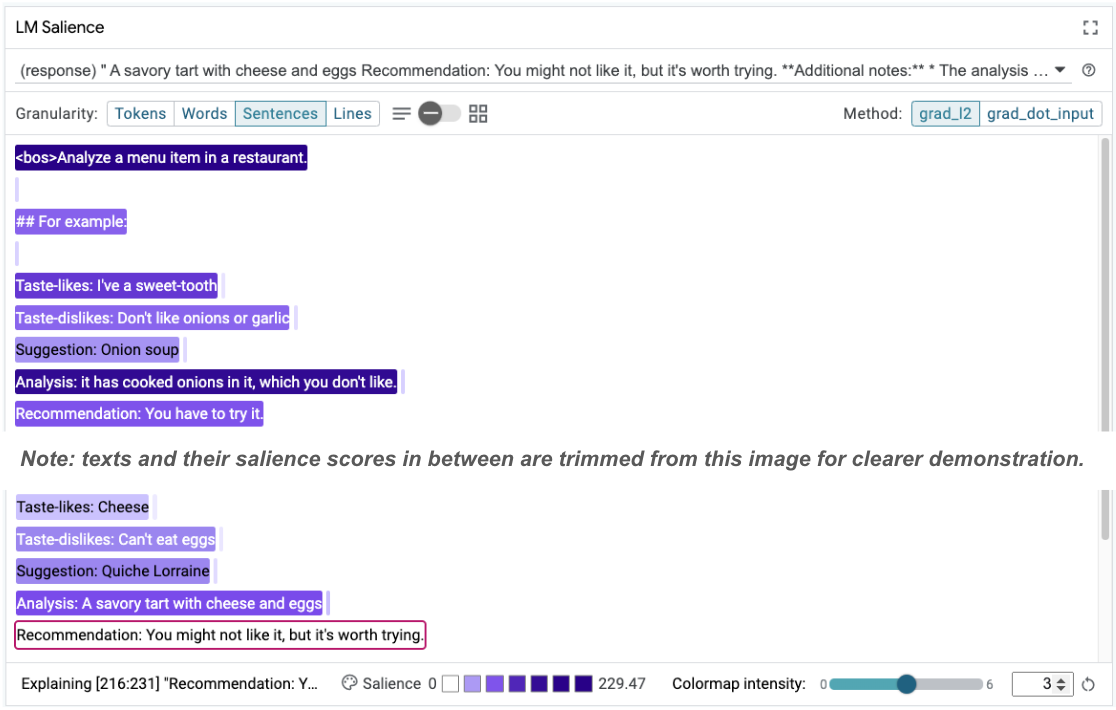
这突显了一个人为错误:意外复制并粘贴了建议部分,但未能更新!
现在,让我们将第一个示例中的“Recommendation”更正为 Avoid,然后重试。LIT 已在示例提示中预加载此示例,因此您可以使用以下实用函数来获取它:
def get_fewshot_example(source: str) -> str:
for example in datasets['sample_prompts'].examples:
if example['source'] == source:
return example['prompt']
raise ValueError(f'Source "{source}" not found in the dataset.')
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-fixed')}])
现在,模型补全变为:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs and cheese, which you don't like. Recommendation: Avoid.
从这个例子中可以学到一个重要经验:早期原型设计有助于发现您可能事先想不到的风险,而语言模型容易出错的特性意味着必须主动设计来应对错误。如需进一步了解相关信息,请参阅我们的人与 AI 指南,了解如何利用 AI 进行设计。
虽然修正后的少样本提示效果更好,但仍不太正确:它正确地告知用户要避免鸡蛋,但推理不正确,它说用户不喜欢鸡蛋,但实际上用户已声明自己不能吃鸡蛋。在下一部分中,您将了解如何做得更好。
7. 测试假设以改进模型行为
借助 LIT,您可以在同一界面中测试对提示所做的更改。在此实例中,您将测试添加宪法以改进模型的行为。宪法是指包含原则的设计提示,有助于引导模型生成内容。最近的方法甚至可以实现宪法原则的交互式推导。
让我们利用以下想法进一步改进提示。在提示顶部添加一个包含生成原则的部分,现在的提示开头如下所示:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * The analysis and recommendation should both be clear about the suitability for someone with a specified dietary restriction. ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid. ...
lit_widget.render(data=[{'prompt': get_fewshot_example('fewshot-constitution')}])
在此更新后,您可以重新运行该示例,并观察到非常不同的输出:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
然后,可以重新检查提示的显著性,以了解发生此变化的原因:
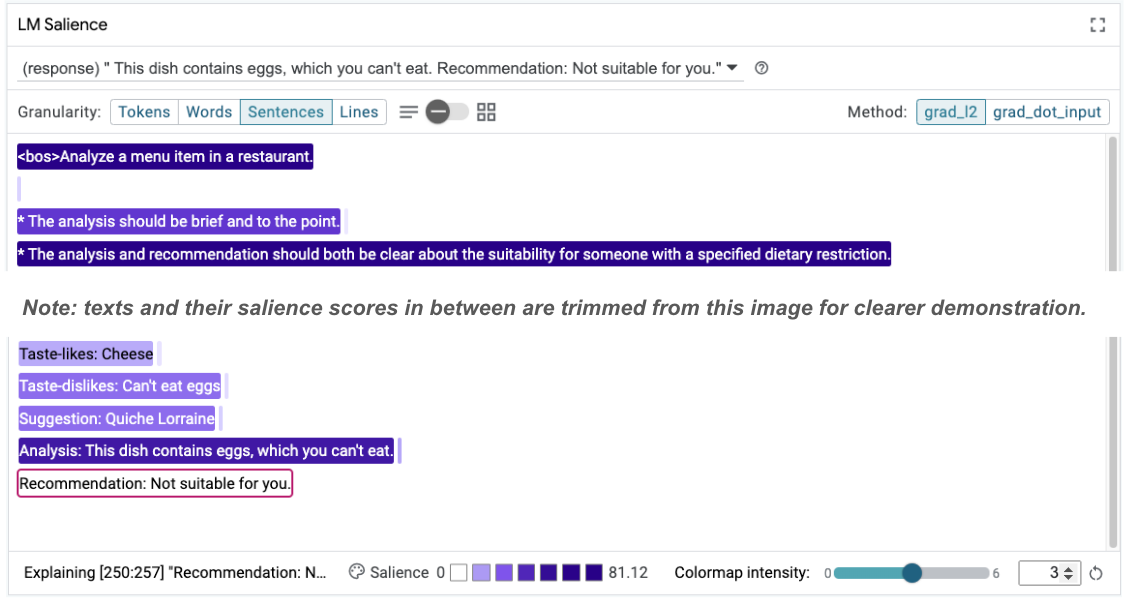
请注意,建议的密码安全性更高。此外,“不适合您”的判断依据是根据饮食限制明确说明适用性的原则,以及分析(即所谓的思路链)。这有助于进一步确信输出是出于正当理由。
8. 让非技术团队参与模型探测和探索
可解释性需要团队共同努力,涵盖 XAI、政策、法律等方面的专业知识。
在早期开发阶段与模型互动通常需要深厚的技术专业知识,这使得一些协作者更难访问和探测模型。过去,一直没有工具能让这些团队参与到早期原型设计阶段。
通过 LIT,我们希望这种范式能够发生改变。正如您在此 Codelab 中所见,LIT 的可视化媒体和检查显著性及探索示例的互动能力可帮助不同的利益相关方分享和交流发现。这样一来,您就可以招募更多不同背景的队友来探索、探测和调试模型。让他们了解这些技术方法有助于他们更好地理解模型的工作原理。此外,在早期模型测试中拥有更多样化的专业知识也有助于发现可以改进的不良结果。
9. 回顾
总结如下:
- LIT 界面提供了一个用于交互式模型执行的界面,使用户能够直接生成输出并测试“假设”情景。这对于测试不同的提示变体特别有用。
- LM Salience 模块以直观的方式呈现了显著性,并提供了可控的数据粒度,以便您能够围绕以人为中心的结构(例如句子和字词)而非以模型为中心的结构(例如令牌)进行交流。
在模型评估中发现问题示例后,可将其导入 LIT 进行调试。首先,分析您能想到的与建模任务在逻辑上相关的最大合理内容单元,使用可视化图表查看模型正确或错误地关注提示内容的位置,然后深入分析较小的内容单元,进一步描述您看到的错误行为,以便确定可能的修复方法。
最后:Lit 在不断改进!如需详细了解我们的功能并分享您的建议,请点击此处。