
۱. مقدمه
آخرین بهروزرسانی: ۱۵-۰۹-۲۰۲۱
دادههای مورد نیاز برای هدایت بینش قیمتگذاری و بهینهسازی، ماهیتاً متفاوت هستند (سیستمهای مختلف، واقعیتهای محلی متفاوت و غیره)، بنابراین ایجاد یک جدول CDM ساختاریافته، استاندارد و تمیز بسیار مهم است. این شامل ویژگیهای کلیدی برای بهینهسازی قیمتگذاری، مانند معاملات، محصولات، قیمتها و مشتریان است. در این سند، مراحل ذکر شده در زیر را به شما آموزش میدهیم و شروع سریعی برای تجزیه و تحلیل قیمتگذاری ارائه میدهیم که میتوانید آن را برای نیازهای خود گسترش داده و سفارشی کنید. نمودار زیر مراحل پوشش داده شده در این سند را شرح میدهد.

- ارزیابی منابع داده: ابتدا، باید فهرستی از منابع دادهای که برای ایجاد CDM استفاده خواهند شد، تهیه کنید. در این مرحله، از Dataprep برای بررسی و شناسایی مشکلات دادههای ورودی نیز استفاده میشود. به عنوان مثال، مقادیر گمشده و نامتناسب، قراردادهای نامگذاری متناقض، موارد تکراری، مشکلات یکپارچگی دادهها، دادههای پرت و غیره.
- استانداردسازی دادهها: در مرحله بعد، مشکلات شناساییشده قبلی برطرف میشوند تا از صحت، یکپارچگی، ثبات و کامل بودن دادهها اطمینان حاصل شود. این فرآیند میتواند شامل تبدیلهای مختلفی در Dataprep باشد، مانند قالببندی تاریخ، استانداردسازی مقادیر، تبدیل واحد، فیلتر کردن فیلدها و مقادیر غیرضروری و تقسیم، اتصال یا حذف دادههای تکراری از منبع.
- یکپارچهسازی در یک ساختار: مرحله بعدی خط لوله، هر منبع داده را در یک جدول واحد و گسترده در BigQuery که شامل تمام ویژگیها در بهترین سطح جزئیات است، به هم متصل میکند. این ساختار غیرنرمالسازی شده امکان پرسوجوهای تحلیلی کارآمدی را فراهم میکند که نیازی به اتصال ندارند.
- ارائه تجزیه و تحلیل و یادگیری ماشین/هوش مصنوعی: هنگامی که دادهها تمیز و برای تجزیه و تحلیل قالببندی شدند، تحلیلگران میتوانند دادههای تاریخی را بررسی کنند تا تأثیر تغییرات قیمتگذاری قبلی را درک کنند. علاوه بر این، BigQuery ML میتواند برای ایجاد مدلهای پیشبینیکنندهای که فروش آینده را تخمین میزنند، استفاده شود. خروجی این مدلها را میتوان در داشبوردهای Looker گنجاند تا "سناریوهای چه میشود اگر" ایجاد شود که در آن کاربران تجاری میتوانند تجزیه و تحلیل کنند که فروش با تغییرات قیمت خاص چگونه خواهد بود.
نمودار زیر اجزای Google Cloud مورد استفاده برای ساخت خط لوله تجزیه و تحلیل بهینهسازی قیمتگذاری را نشان میدهد.

آنچه خواهید ساخت
در اینجا به شما نشان خواهیم داد که چگونه یک انبار داده بهینهسازی قیمتگذاری طراحی کنید، آمادهسازی دادهها را در طول زمان خودکار کنید، از یادگیری ماشینی برای پیشبینی تأثیر تغییرات در قیمتگذاری محصول استفاده کنید و گزارشهایی را برای ارائه بینشهای عملی به تیم خود تهیه کنید.
آنچه یاد خواهید گرفت
- نحوه اتصال Dataprep به منابع داده برای تجزیه و تحلیل قیمتگذاری، که میتوانند در پایگاههای داده رابطهای، فایلهای مسطح، Google Sheets و سایر برنامههای پشتیبانی شده ذخیره شوند.
- نحوه ساخت یک جریان آمادهسازی داده (Dataprep) برای ایجاد یک جدول CDM در انبار داده BigQuery شما.
- نحوه استفاده از BigQuery ML برای پیشبینی درآمد آینده.
- نحوه ساخت گزارشها در Looker برای تحلیل قیمتگذاریهای تاریخی و روند فروش و درک تأثیر تغییرات قیمت در آینده.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب. یاد بگیرید که چگونه تأیید کنید که پرداخت صورتحساب برای پروژه شما فعال است .
- BigQuery باید در پروژه شما فعال باشد. این قابلیت به طور خودکار در پروژههای جدید فعال میشود. در غیر این صورت، آن را در یک پروژه موجود فعال کنید . همچنین میتوانید اطلاعات بیشتری در مورد شروع کار با BigQuery را از کنسول ابری اینجا کسب کنید.
- Dataprep نیز باید در پروژه شما فعال باشد. Dataprep از طریق کنسول گوگل ، از منوی ناوبری سمت چپ در بخش Big Data فعال میشود. برای فعال کردن آن، مراحل ثبت نام را دنبال کنید.
- برای راهاندازی داشبوردهای Looker خود، باید به یک نمونه Looker دسترسی توسعهدهنده داشته باشید، برای درخواست نسخه آزمایشی لطفاً از اینجا با تیم ما تماس بگیرید ، یا از داشبورد عمومی ما برای بررسی نتایج خط لوله داده روی دادههای نمونه ما استفاده کنید.
- تجربه با زبان پرسوجوی ساختاریافته (SQL) و دانش پایه در موارد زیر مفید است: Dataprep by Trifacta ، BigQuery ، Looker
۲. ایجاد CDM در BigQuery
در این بخش، شما مدل دادههای مشترک (CDM) را ایجاد میکنید که یک نمای تلفیقی از اطلاعات مورد نیاز برای تجزیه و تحلیل و پیشنهاد تغییرات قیمتگذاری را ارائه میدهد.
- کنسول BigQuery را باز کنید.
- پروژهای را که میخواهید برای آزمایش این الگوی مرجع استفاده کنید، انتخاب کنید.
- از یک مجموعه داده موجود استفاده کنید یا یک مجموعه داده BigQuery ایجاد کنید . نام مجموعه داده را
Pricing_CDMبگذارید. - جدول را ایجاد کنید :
create table `CDM_Pricing`
(
Fiscal_Date DATETIME,
Product_ID STRING,
Client_ID INT64,
Customer_Hierarchy STRING,
Division STRING,
Market STRING,
Channel STRING,
Customer_code INT64,
Customer_Long_Description STRING,
Key_Account_Manager INT64,
Key_Account_Manager_Description STRING,
Structure STRING,
Invoiced_quantity_in_Pieces FLOAT64,
Gross_Sales FLOAT64,
Trade_Budget_Costs FLOAT64,
Cash_Discounts_and_other_Sales_Deductions INT64,
Net_Sales FLOAT64,
Variable_Production_Costs_STD FLOAT64,
Fixed_Production_Costs_STD FLOAT64,
Other_Cost_of_Sales INT64,
Standard_Gross_Margin FLOAT64,
Transportation_STD FLOAT64,
Warehouse_STD FLOAT64,
Gross_Margin_After_Logistics FLOAT64,
List_Price_Converged FLOAT64
);
۳. ارزیابی منابع داده
در این آموزش، شما از منابع داده نمونهای استفاده میکنید که در Google Sheets و BigQuery ذخیره شدهاند.
- برگه گوگل تراکنشها که شامل یک ردیف برای هر تراکنش است و جزئیاتی مانند مقدار هر محصول فروخته شده، کل فروش ناخالص و هزینههای مرتبط را در بر میگیرد.
- برگه قیمتگذاری محصول گوگل که شامل قیمت هر محصول برای یک مشتری مشخص در هر ماه است.
- جدول company_descriptions در BigQuery که شامل اطلاعات تک تک مشتریان است.
این جدول company_descriptions BigQuery را میتوان با استفاده از دستور زیر ایجاد کرد:
create table `Company_Descriptions`
(
Customer_ID INT64,
Customer_Long_Description STRING
);
insert into `Company_Descriptions` values (15458, 'ENELTEN');
insert into `Company_Descriptions` values (16080, 'NEW DEVICES CORP.');
insert into `Company_Descriptions` values (19913, 'ENELTENGAS');
insert into `Company_Descriptions` values (30108, 'CARTOON NT');
insert into `Company_Descriptions` values (32492, 'Thomas Ed Automobiles');
۴. جریان را بسازید
در این مرحله، شما یک جریان نمونه Dataprep را وارد میکنید که از آن برای تبدیل و یکپارچهسازی مجموعه دادههای نمونه فهرستشده در بخش قبل استفاده میکنید. یک جریان نشاندهنده یک خط لوله یا شیء است که مجموعه دادهها و دستور العملها را گرد هم میآورد و برای تبدیل و اتصال آنها استفاده میشود.
- بسته الگوی بهینهسازی قیمتگذاری (Pricing Optimization Pattern Flow) را از گیتهاپ دانلود کنید، اما آن را از حالت فشرده خارج نکنید. این فایل شامل الگوی طراحی بهینهسازی قیمتگذاری (Pricing Optimization Design Pattern Flow) است که برای تبدیل دادههای نمونه استفاده میشود.
- در Dataprep، روی آیکون Flows در نوار ناوبری سمت چپ کلیک کنید. سپس در نمای Flows، از منوی زمینه، Import را انتخاب کنید. پس از وارد کردن جریان، میتوانید آن را برای مشاهده و ویرایش انتخاب کنید.
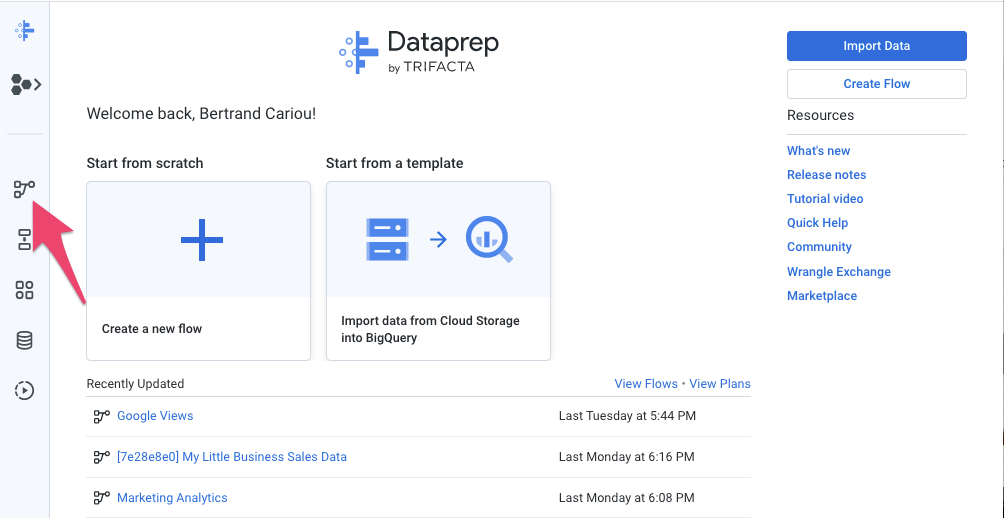
- در سمت چپ جریان، قیمتگذاری محصول و هر یک از سه برگه گوگل تراکنشها باید به عنوان مجموعه دادهها به هم متصل شوند. برای انجام این کار، روی اشیاء مجموعه دادههای برگههای گوگل کلیک راست کرده و گزینه Replace را انتخاب کنید. سپس روی پیوند Import Datasets کلیک کنید. همانطور که در نمودار زیر نشان داده شده است، روی مداد "ویرایش مسیر" کلیک کنید.
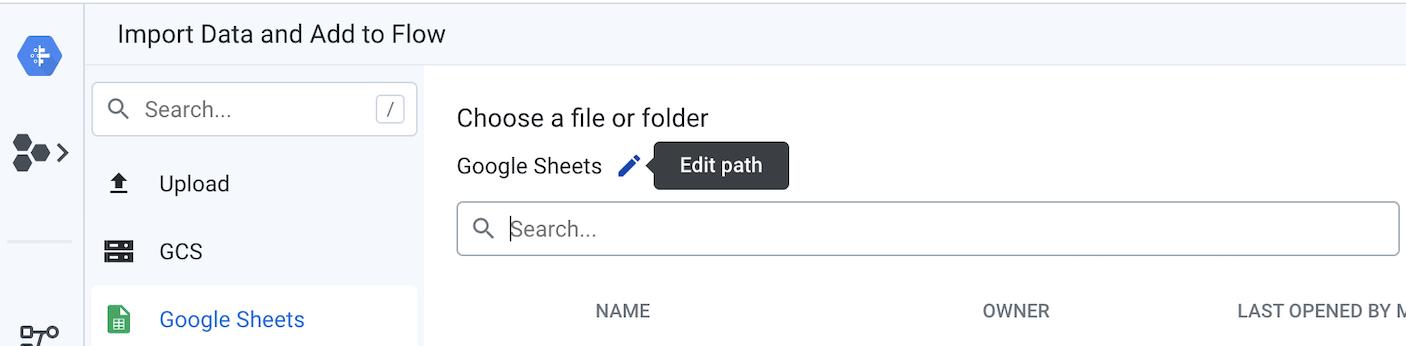
مقدار فعلی را با پیوندی که به معاملات و قیمتگذاری محصول در Google Sheets اشاره دارد، جایگزین کنید .
وقتی صفحات گوگل شامل چندین تب است، میتوانید تبی را که میخواهید از آن استفاده کنید در منو انتخاب کنید. روی ویرایش کلیک کنید و تبهایی را که میخواهید به عنوان منبع داده استفاده کنید انتخاب کنید، سپس روی ذخیره کلیک کنید و روی وارد کردن و افزودن به جریان کلیک کنید. وقتی به پنجرهی نمایش برگشتید، روی جایگزینی کلیک کنید. در این جریان، هر صفحه به عنوان مجموعه دادهی خودش نمایش داده میشود تا ادغام منابع متفاوت بعداً در یک دستور العمل بعدی نشان داده شود.

- جداول خروجی BigQuery را تعریف کنید:
در این مرحله، شما مکان جدول خروجی BigQuery CDM_Pricing را که قرار است هر بار که کار Dataoprep را اجرا میکنید، بارگذاری شود، مشخص خواهید کرد.
در نمای جریان، روی آیکون خروجی نگاشت طرحواره کلیک کنید، در پنل جزئیات، روی تب مقصدها کلیک کنید. از آنجا، هم خروجی مقصد دستی که برای آزمایش استفاده میشود و هم خروجی مقصد برنامهریزیشده که وقتی میخواهید کل جریان خود را خودکار کنید استفاده میشود را ویرایش کنید. برای انجام این کار، این دستورالعملها را دنبال کنید:
- ویرایش «مقصدهای دستی» در پنل جزئیات، در بخش «مقصدهای دستی»، روی دکمه ویرایش کلیک کنید. در صفحه تنظیمات انتشار ، در زیر «اقدامات انتشار»، اگر یک اقدام انتشار از قبل وجود دارد، آن را ویرایش کنید، در غیر این صورت روی دکمه افزودن اقدام کلیک کنید. از آنجا، مجموعه دادههای BigQuery را به مجموعه دادههای
Pricing_CDMکه در مرحله قبل ایجاد کردهاید، هدایت کنید و جدولCDM_Pricingرا انتخاب کنید. تأیید کنید که گزینه «افزودن به این جدول در هر اجرا» تیک خورده باشد و سپس روی «افزودن» کلیک کنید. روی «ذخیره تنظیمات» کلیک کنید. - «مقصدهای زمانبندیشده» را ویرایش کنید
در پنل جزئیات، در بخش «مقصدهای زمانبندیشده»، روی «ویرایش» کلیک کنید.
تنظیمات از Manual Destinations گرفته شدهاند و نیازی به ایجاد تغییر ندارید. روی ذخیره تنظیمات کلیک کنید.
۵. استانداردسازی دادهها
اتحادیههای جریان ارائه شده، دادههای تراکنشها را قالببندی و پاکسازی میکنند و سپس نتیجه را با توضیحات شرکت و دادههای قیمتگذاری تجمیعشده برای گزارشگیری ترکیب میکنند. در اینجا اجزای جریان را که در تصویر زیر قابل مشاهده است، بررسی خواهید کرد.

6. دستورالعمل دادههای تراکنشی را بررسی کنید
ابتدا، بررسی خواهید کرد که چه اتفاقی در دستورالعمل دادههای تراکنشی میافتد، که برای تهیه دادههای تراکنشها استفاده میشود. روی شیء دادههای تراکنش در نمای جریان کلیک کنید، در پنل جزئیات، روی دکمه ویرایش دستورالعمل کلیک کنید.
صفحه تبدیلکننده با دستور پخت ارائه شده در پنل جزئیات باز میشود. دستور پخت شامل تمام مراحل تبدیلی است که بر روی دادهها اعمال میشوند. میتوانید با کلیک کردن بین هر یک از مراحل، در دستور پخت حرکت کنید تا وضعیت دادهها را در این موقعیت خاص در دستور پخت مشاهده کنید.
همچنین میتوانید برای هر مرحله از دستور پخت، روی منوی «بیشتر» کلیک کنید و «برو به انتخابشدهها» یا «ویرایش آن» را انتخاب کنید تا نحوهی عملکرد تبدیل را بررسی کنید.
- تراکنشهای اتحادیه: اولین گام در تهیهی دادههای تراکنشی، تراکنشهای اتحادیه است که در برگههای مختلف ذخیره میشوند و هر ماه را نشان میدهند.
- استانداردسازی توضیحات مشتری: مرحله بعدی در این دستورالعمل، استانداردسازی توضیحات مشتری است. این بدان معناست که نامهای مشتری ممکن است با تغییرات جزئی مشابه باشند و ما میخواهیم آنها را مانند نام، نرمالسازی کنیم. این دستورالعمل دو رویکرد بالقوه را نشان میدهد. اول، از الگوریتم استانداردسازی استفاده میکند که میتواند با گزینههای استانداردسازی مختلف مانند "رشتههای مشابه" که در آن مقادیر با کاراکترهای مشترک در کنار هم قرار میگیرند، یا "تلفظ" که در آن مقادیری که صدای مشابهی دارند در کنار هم قرار میگیرند، پیکربندی شود. به عنوان یک روش جایگزین، میتوانید توضیحات شرکت را در جدول BigQuery که در بالا به آن اشاره شد ، با استفاده از شناسه شرکت جستجو کنید .
میتوانید در ادامهی دستورالعمل، تکنیکهای مختلف دیگری را که برای تمیز کردن و قالببندی دادهها اعمال میشوند، کشف کنید: حذف ردیفها، قالببندی بر اساس الگوها، غنیسازی دادهها با جستجو، رسیدگی به مقادیر گمشده یا جایگزینی کاراکترهای ناخواسته.
۷. دستورالعمل دادههای قیمتگذاری محصول را بررسی کنید
در مرحله بعد، میتوانید بررسی کنید که در دستورالعمل دادههای قیمتگذاری محصول چه اتفاقی میافتد، که دادههای تراکنشهای آمادهشده را به دادههای قیمتگذاری تجمیعشده متصل میکند.
برای بستن صفحه تبدیلکننده و بازگشت به نمای جریان، روی الگوی طراحی بهینهسازی قیمتگذاری در بالای صفحه کلیک کنید. از آنجا روی شیء داده قیمتگذاری محصول کلیک کنید و دستور پخت را ویرایش کنید.
- ستونهای قیمت ماهانه Unpivot: برای مشاهده نحوه نمایش دادهها قبل از مرحله Unpivot، روی دستور العمل بین مراحل ۲ و ۳ کلیک کنید. متوجه خواهید شد که دادهها شامل ارزش تراکنش در یک ستون مجزا برای هر ماه هستند: ژانویه، فوریه، مارس. این فرمتی نیست که برای اعمال محاسبات تجمیعی (یعنی مجموع، میانگین تراکنش) در SQL مناسب باشد. دادهها باید بدون چرخش باشند تا هر ستون در جدول BigQuery به یک ردیف تبدیل شود. این دستور العمل از تابع unpivot برای تبدیل ۳ ستون به یک ردیف برای هر ماه استفاده میکند، بنابراین اعمال محاسبات گروهی نیز آسانتر است.
- محاسبه میانگین ارزش تراکنش بر اساس مشتری، محصول و تاریخ : ما میخواهیم میانگین ارزش تراکنش را برای هر مشتری، محصول و داده محاسبه کنیم. میتوانیم از تابع Aggregate استفاده کنیم و یک جدول جدید ایجاد کنیم (گزینه "گروهبندی بر اساس به عنوان یک جدول جدید"). در این صورت، دادهها در سطح گروه تجمیع میشوند و جزئیات هر تراکنش جداگانه را از دست میدهیم. یا میتوانیم تصمیم بگیریم که هم جزئیات و هم مقادیر تجمیع شده را در یک مجموعه داده نگه داریم (گزینه "گروهبندی بر اساس به عنوان یک ستون(های) جدید") که برای اعمال یک نسبت (یعنی درصد سهم دسته محصول از درآمد کلی) بسیار مناسب میشود. میتوانید این رفتار را با ویرایش دستور العمل مرحله 7 امتحان کنید و گزینه "گروهبندی بر اساس به عنوان یک جدول جدید" یا "گروهبندی بر اساس به عنوان یک ستون(های) جدید" را انتخاب کنید تا تفاوتها را ببینید.
- تاریخ قیمتگذاری را به هم متصل کنید: در نهایت، از یک اتصال برای ترکیب چندین مجموعه داده در یک مجموعه بزرگتر با اضافه کردن ستونها به مجموعه داده اولیه استفاده میشود. در این مرحله، دادههای قیمتگذاری با خروجی دستور العمل دادههای تراکنشی بر اساس 'Pricing Data.Product Code' = Transaction Data.SKU' و 'Pricing Data.Price Date' = 'Transaction Data.Fiscal Date' ادغام میشوند.
برای کسب اطلاعات بیشتر در مورد تبدیلهایی که میتوانید با Dataprep اعمال کنید، به برگه تقلب Trifacta Data Wrangling مراجعه کنید.
۸. دستور تهیه نقشه طرحواره را بررسی کنید
آخرین دستورالعمل، نگاشت طرحواره (Schema Mapping) تضمین میکند که جدول CDM حاصل با طرحواره جدول خروجی BigQuery موجود مطابقت داشته باشد. در اینجا، از قابلیت Rapid Target برای قالببندی مجدد ساختار داده برای مطابقت با جدول BigQuery با استفاده از تطبیق فازی برای مقایسه هر دو طرحواره و اعمال تغییرات خودکار استفاده میشود.
۹. در یک ساختار متحد شوید
اکنون که منابع و مقاصد پیکربندی شدهاند و مراحل جریانها بررسی شدهاند، میتوانید جریان را برای تبدیل و بارگذاری جدول CDM در BigQuery اجرا کنید.
- اجرای خروجی نگاشت طرحواره: در نمای جریان، شیء خروجی نگاشت طرحواره را انتخاب کنید و روی دکمه "اجرا" در پنل جزئیات کلیک کنید. "Trifacta Photon" Running Environment را انتخاب کنید و تیک گزینه "نادیده گرفتن خطاهای دستور پخت" را بردارید. سپس روی دکمه اجرا کلیک کنید. اگر جدول BigQuery مشخص شده وجود داشته باشد، Dataprep ردیفهای جدید را اضافه میکند، در غیر این صورت، یک جدول جدید ایجاد میکند.
- مشاهده وضعیت کار: Dataprep به طور خودکار صفحه اجرای کار را باز میکند تا بتوانید اجرای کار را زیر نظر داشته باشید. ادامه و بارگذاری جدول BigQuery باید چند دقیقه طول بکشد. پس از اتمام کار، خروجی CDM قیمتگذاری در BigQuery با فرمتی تمیز، ساختاریافته و نرمالشده، آماده برای تجزیه و تحلیل، بارگذاری خواهد شد.
۱۰. ارائه تحلیلها و یادگیری ماشین/هوش مصنوعی
پیشنیازهای تجزیه و تحلیل
برای اجرای برخی تحلیلها و یک مدل پیشبینی با نتایج جالب، ما یک مجموعه داده ایجاد کردهایم که بزرگتر و مرتبط با کشف بینشهای خاص است. قبل از ادامه این راهنما، باید این دادهها را در مجموعه داده BigQuery خود بارگذاری کنید.
- مجموعه دادههای بزرگ را از این مخزن گیتهاب دانلود کنید
- در کنسول گوگل برای BigQuery، به پروژه خود و مجموعه داده CDM_Pricing بروید.
- روی منو کلیک کنید و مجموعه داده را باز کنید. ما با بارگذاری دادهها از یک فایل محلی، جدول را ایجاد خواهیم کرد.
روی دکمه + ایجاد جدول کلیک کنید و این پارامترها را تعریف کنید:
- جدول را از آپلود ایجاد کنید و فایل CDM_Pricing_Large_Table.csv را انتخاب کنید
- تشخیص خودکار طرحواره، بررسی طرحواره و پارامترهای ورودی
- گزینههای پیشرفته، اولویت نوشتن، جدول بازنویسی

- روی ایجاد جدول کلیک کنید
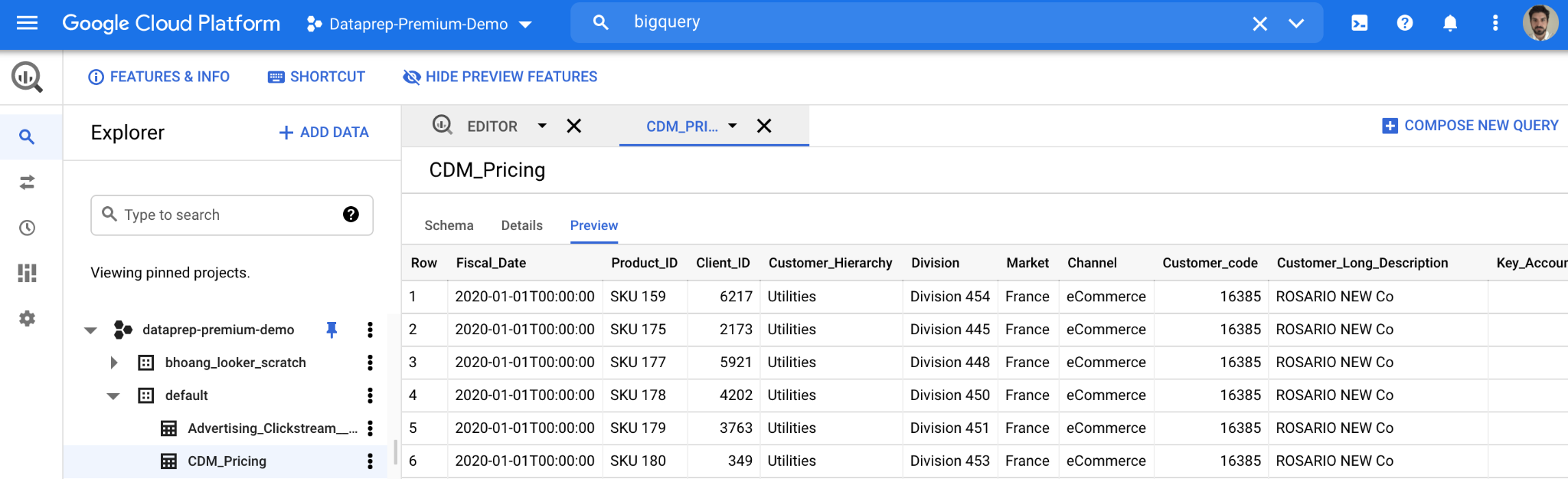
پس از ایجاد جدول و آپلود دادهها، در کنسول گوگل برای BigQuery ، باید جزئیات جدول جدید را مطابق شکل زیر مشاهده کنید. با دادههای قیمتگذاری در BigQuery، میتوانیم به راحتی سوالات جامعتری بپرسیم تا دادههای قیمتگذاری شما را در سطح عمیقتری تجزیه و تحلیل کنیم.
۱۱. مشاهده تأثیر تغییرات قیمتگذاری
یک نمونه از مواردی که ممکن است بخواهید تجزیه و تحلیل کنید، تغییر در رفتار سفارش است، زمانی که قبلاً قیمت یک کالا را تغییر دادهاید.
- ابتدا، یک جدول موقت ایجاد میکنید که هر بار قیمت یک محصول تغییر میکند، یک خط دارد و اطلاعاتی در مورد قیمتگذاری آن محصول خاص مانند تعداد اقلام سفارش داده شده با هر قیمت و کل فروش خالص مرتبط با آن قیمت را در خود جای میدهد.
create temp table price_changes as (
select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from `{{my_project}}.{{my_dataset}}.CDM_Pricing` AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
);
select * from price_changes where previous_list is not null order by product_id, first_price_date desc

- در مرحله بعد، با استفاده از جدول موقت، میتوانید میانگین تغییر قیمت را در بین SKU ها محاسبه کنید:
select avg((previous_list-list_price_converged)/nullif(previous_list,0))*100 as average_price_change from price_changes;
- در نهایت، میتوانید با بررسی رابطه بین هر تغییر قیمت و کل تعداد اقلام سفارش داده شده، اتفاقات پس از تغییر قیمت را تجزیه و تحلیل کنید:
select
(total_ordered_pieces-previous_total_ordered_pieces)/nullif(previous_total_ordered_pieces,0)
به عنوان
price_changes_percent_ordered_change,
(list_price_converged-previous_list)/nullif(previous_list,0)
به عنوان
price_changes_percent_price_change
from price_changes
۱۲. ساخت یک مدل پیشبینی سری زمانی
در مرحله بعد، با قابلیتهای یادگیری ماشینی داخلی BigQuery ، میتوانید یک مدل پیشبینی سری زمانی ARIMA بسازید تا مقدار هر کالایی که فروخته خواهد شد را پیشبینی کنید.
- ابتدا یک مدل ARIMA_PLUS ایجاد میکنید
create or replace `{{my_project}}.{{my_dataset}}.bqml_arima`
options
(model_type = 'ARIMA_PLUS',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = TRUE,
data_frequency = 'AUTO_FREQUENCY',
decompose_time_series = TRUE
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
`{{my_project}}.{{my_dataset}}.CDM_Pricing`
group by 1,2;
- در مرحله بعد، از تابع ML.FORECAST برای پیشبینی فروش آینده هر محصول استفاده میکنید:
select
*
from
ML.FORECAST(model testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level));
- با استفاده از این پیشبینیها، میتوانید سعی کنید بفهمید که اگر قیمتها را افزایش دهید چه اتفاقی ممکن است بیفتد. به عنوان مثال، اگر قیمت هر محصول را ۱۵٪ افزایش دهید، میتوانید کل درآمد تخمینی برای ماه آینده را با یک پرسوجو مانند این محاسبه کنید:
select
sum(forecast_value * list_price) as total_revenue
from ml.forecast(mode testing.bqml_arima,
struct(30 as horizon, 0.8 as confidence_level)) forecasts
left join (select product_id,
array_agg(list_price_converged
order by fiscal_date desc limit 1)[offset(0)] as list_price
from `leigha-bq-dev.retail.cdm_pricing` group by 1) recent_prices
using (product_id);
۱۳. یک گزارش بسازید
اکنون که دادههای قیمتگذاری غیرنرمالشده شما در BigQuery متمرکز شدهاند و شما میدانید که چگونه میتوان پرسوجوهای معنادار را روی این دادهها اجرا کرد، زمان آن رسیده است که گزارشی بسازید تا کاربران تجاری بتوانند این اطلاعات را بررسی و بر اساس آن اقدام کنند.
اگر از قبل یک نمونه Looker دارید، میتوانید از LookML موجود در این مخزن GitHub برای شروع تجزیه و تحلیل دادههای قیمتگذاری برای این الگو استفاده کنید. کافیست یک پروژه Looker جدید ایجاد کنید ، LookML را اضافه کنید و نامهای اتصال و جدول را در هر یک از فایلهای view جایگزین کنید تا با پیکربندی BigQuery شما مطابقت داشته باشد.
در این مدل، جدول مشتقشده ( در این فایل view ) را که قبلاً برای بررسی تغییرات قیمت نشان دادیم ، خواهید یافت:
view: price_changes {
derived_table: {
sql: select
product_id,
list_price_converged,
total_ordered_pieces,
total_net_sales,
first_price_date,
lag(list_price_converged) over(partition by product_id order by first_price_date asc) as previous_list,
lag(total_ordered_pieces) over(partition by product_id order by first_price_date asc) as previous_total_ordered_pieces,
lag(total_net_sales) over(partition by product_id order by first_price_date asc) as previous_total_net_sales,
lag(first_price_date) over(partition by product_id order by first_price_date asc) as previous_first_price_date
from (
select
product_id,list_price_converged,sum(invoiced_quantity_in_pieces) as total_ordered_pieces, sum(net_sales) as total_net_sales, min(fiscal_date) as first_price_date
from ${cdm_pricing.SQL_TABLE_NAME} AS cdm_pricing
group by 1,2
order by 1, 2 asc
)
;;
}
...
}
و همچنین مدل BigQuery ML ARIMA که قبلاً نشان دادیم ، برای پیشبینی فروش آینده ( در این فایل view )
view: arima_model {
derived_table: {
persist_for: "24 hours"
sql_create:
create or replace model ${sql_table_name}
options
(model_type = 'arima_plus',
time_series_timestamp_col = 'fiscal_date',
time_series_data_col = 'total_quantity',
time_series_id_col = 'product_id',
auto_arima = true,
data_frequency = 'auto_frequency',
decompose_time_series = true
) as
select
fiscal_date,
product_id,
sum(invoiced_quantity_in_pieces) as total_quantity
from
${cdm_pricing.sql_table_name}
group by 1,2 ;;
}
}
...
}
LookML همچنین شامل یک داشبورد نمونه است. میتوانید از اینجا به نسخه آزمایشی داشبورد دسترسی پیدا کنید. بخش اول داشبورد اطلاعات سطح بالایی در مورد تغییرات در فروش، هزینهها، قیمتگذاری و حاشیه سود به کاربران میدهد. به عنوان یک کاربر تجاری، ممکن است بخواهید هشداری ایجاد کنید تا بدانید که آیا فروش به زیر X٪ کاهش یافته است یا خیر، زیرا این ممکن است به معنای آن باشد که باید قیمتها را کاهش دهید.

بخش بعدی که در زیر نشان داده شده است، به کاربران این امکان را میدهد که روند تغییرات قیمت را بررسی کنند. در اینجا، میتوانید محصولات خاص را بررسی کنید تا قیمت دقیق لیست و قیمتهای تغییر یافته را ببینید - که میتواند برای مشخص کردن محصولات خاص برای انجام تحقیقات بیشتر مفید باشد.

در نهایت، در پایین گزارش، نتایج مدل BigQueryML ما را مشاهده میکنید. با استفاده از فیلترهای بالای داشبورد Looker، میتوانید به راحتی پارامترهایی را برای شبیهسازی سناریوهای مختلف مشابه آنچه در بالا توضیح داده شد، وارد کنید. به عنوان مثال، ببینید اگر حجم سفارش به ۷۵٪ از مقدار پیشبینیشده کاهش یابد و قیمتگذاری در تمام محصولات ۲۵٪ افزایش یابد، همانطور که در زیر نشان داده شده است، چه اتفاقی میافتد.

این قابلیت توسط پارامترهای LookML پشتیبانی میشود که سپس مستقیماً در محاسبات اندازهگیری موجود در اینجا گنجانده میشوند. با این نوع گزارش، میتوانید قیمت بهینه را برای همه محصولات پیدا کنید یا محصولات خاص را بررسی کنید تا مشخص کنید که در کجا باید قیمتها را افزایش یا تخفیف دهید و نتیجه آن بر درآمد ناخالص و خالص چه خواهد بود.
۱۴. با سیستمهای قیمتگذاری خود سازگار شوید
اگرچه این آموزش منابع داده نمونه را تبدیل میکند، اما برای داراییهای قیمتگذاری که در پلتفرمهای مختلف شما وجود دارند، با چالشهای دادهای بسیار مشابهی روبرو خواهید شد. داراییهای قیمتگذاری برای نتایج خلاصه و تفصیلی، قالبهای خروجی متفاوتی (اغلب xls، sheets، csv، txt، پایگاههای داده رابطهای، برنامههای تجاری) دارند که هر کدام میتوانند به Dataprep متصل شوند. توصیه میکنیم با توصیف الزامات تبدیل خود، مشابه مثالهای ارائه شده در بالا، شروع کنید. پس از روشن شدن مشخصات و شناسایی انواع تبدیلهای مورد نیاز، میتوانید آنها را با Dataprep طراحی کنید.
- یک کپی از جریان Dataprep که میخواهید سفارشی کنید، تهیه کنید (روی دکمه **... "**more" در سمت راست جریان کلیک کنید و گزینه Duplicate را انتخاب کنید) یا با استفاده از یک جریان Dataprep جدید، از ابتدا شروع کنید.
- به مجموعه دادههای قیمتگذاری خود متصل شوید. فرمتهای فایل مانند اکسل، CSV، Google Sheets و JSON به صورت پیشفرض توسط Dataprep پشتیبانی میشوند. همچنین میتوانید با استفاده از کانکتورهای Dataprep به سیستمهای دیگر متصل شوید.
- دادههای خود را در دستههای مختلف تبدیل که شناسایی کردهاید، توزیع کنید. برای هر دسته، یک دستور پخت ایجاد کنید. از جریان ارائه شده در این الگوی طراحی برای تبدیل دادهها و نوشتن دستور پختهای خودتان الهام بگیرید. اگر در جایی گیر کردید، نگران نباشید، در گفتگوی چت در پایین سمت چپ صفحه Dataprep درخواست کمک کنید.
- دستور پخت خود را به نمونه BigQuery خود متصل کنید. نیازی نیست نگران ایجاد دستی جداول در BigQuery باشید، Dataprep به طور خودکار این کار را برای شما انجام میدهد. پیشنهاد میکنیم هنگام اضافه کردن خروجی به جریان خود، یک Manual Destination انتخاب کنید و جدول را در هر اجرا حذف کنید. هر دستور پخت را به صورت جداگانه تا رسیدن به نتایج مورد انتظار آزمایش کنید. پس از انجام آزمایش، خروجی را به Append to the table در هر اجرا تبدیل خواهید کرد تا از حذف دادههای قبلی جلوگیری شود.
- شما میتوانید به صورت اختیاری جریان را طوری تنظیم کنید که طبق برنامه اجرا شود. این مورد در صورتی مفید است که فرآیند شما نیاز به اجرای مداوم داشته باشد. میتوانید برنامهای تعریف کنید که پاسخ را هر روز یا هر ساعت بر اساس تازگی مورد نیاز شما بارگذاری کند. اگر تصمیم دارید جریان را طبق یک برنامه اجرا کنید، باید برای هر دستور غذا یک خروجی مقصد برنامه (Schedule Destination Output) در جریان اضافه کنید.
اصلاح مدل یادگیری ماشین BigQuery
این آموزش یک مدل ARIMA نمونه ارائه میدهد. با این حال، پارامترهای اضافی وجود دارد که میتوانید هنگام توسعه مدل کنترل کنید تا مطمئن شوید که به بهترین شکل با دادههای شما مطابقت دارد. میتوانید جزئیات بیشتر را در مثال موجود در مستندات ما اینجا مشاهده کنید. علاوه بر این، میتوانید از توابع BigQuery ML.ARIMA_EVALUATE ، ML.ARIMA_COEFFICIENTS و ML.EXPLAIN_FORECAST نیز برای دریافت جزئیات بیشتر در مورد مدل خود و تصمیمگیریهای بهینهسازی استفاده کنید.
ویرایش گزارشهای Looker
پس از وارد کردن LookML به پروژه خود، همانطور که در بالا توضیح داده شد ، میتوانید ویرایشهای مستقیم را برای اضافه کردن فیلدهای اضافی، اصلاح محاسبات یا پارامترهای وارد شده توسط کاربر و تغییر تجسمات روی داشبوردها متناسب با نیازهای تجاری خود انجام دهید. میتوانید جزئیات مربوط به توسعه در LookML را اینجا و تجسم دادهها در Looker را اینجا بیابید.
۱۵. تبریک
اکنون مراحل کلیدی مورد نیاز برای بهینهسازی قیمتگذاری محصولات خردهفروشی خود را میدانید!
بعدش چی؟
سایر الگوهای مرجع تجزیه و تحلیل هوشمند را بررسی کنید
مطالعه بیشتر
- وبلاگ را اینجا بخوانید
- درباره Dataprep اینجا بیشتر بدانید
- درباره یادگیری ماشینی BigQuery اینجا بیشتر بدانید
- درباره Looker اینجا بیشتر بدانید