
1. 准备工作
AlphaGo 和 AlphaStar 的惊人突破表明,使用机器学习技术可以打造出超人类水平的游戏智能体。构建一个小型机器学习赋能的游戏是一项有趣的练习,可帮助您掌握创建强大的游戏代理所需的技能。
在此 Codelab 中,您将学习如何使用以下工具构建桌游:
- TensorFlow Agent,用于通过强化学习训练游戏代理
- 使用 TensorFlow Serving 部署模型
- 使用 Flutter 创建跨平台桌游应用
前提条件
- 了解有关使用 Dart 开发 Flutter 应用的基本知识
- 了解有关使用 TensorFlow 进行机器学习(例如训练与部署)的基本知识
- 了解有关 Python、终端和 Docker 的基本知识
学习内容
- 如何使用 TensorFlow Agents 训练非玩家角色 (NPC) 代理
- 如何使用 TensorFlow Serving 部署训练后的模型
- 如何构建跨平台 Flutter 桌游
所需条件
- Flutter SDK
- 适用于 Flutter 的 Android 和 iOS 设置
- 适用于 Flutter 的桌面设置
- 适用于 Flutter 的 Web 设置
- 适用于 Flutter 和 Dart 的 Visual Studio Code (VS Code) 设置
- Docker
- Bash
- Python 3.7 及更高版本
2. 飞机打击游戏
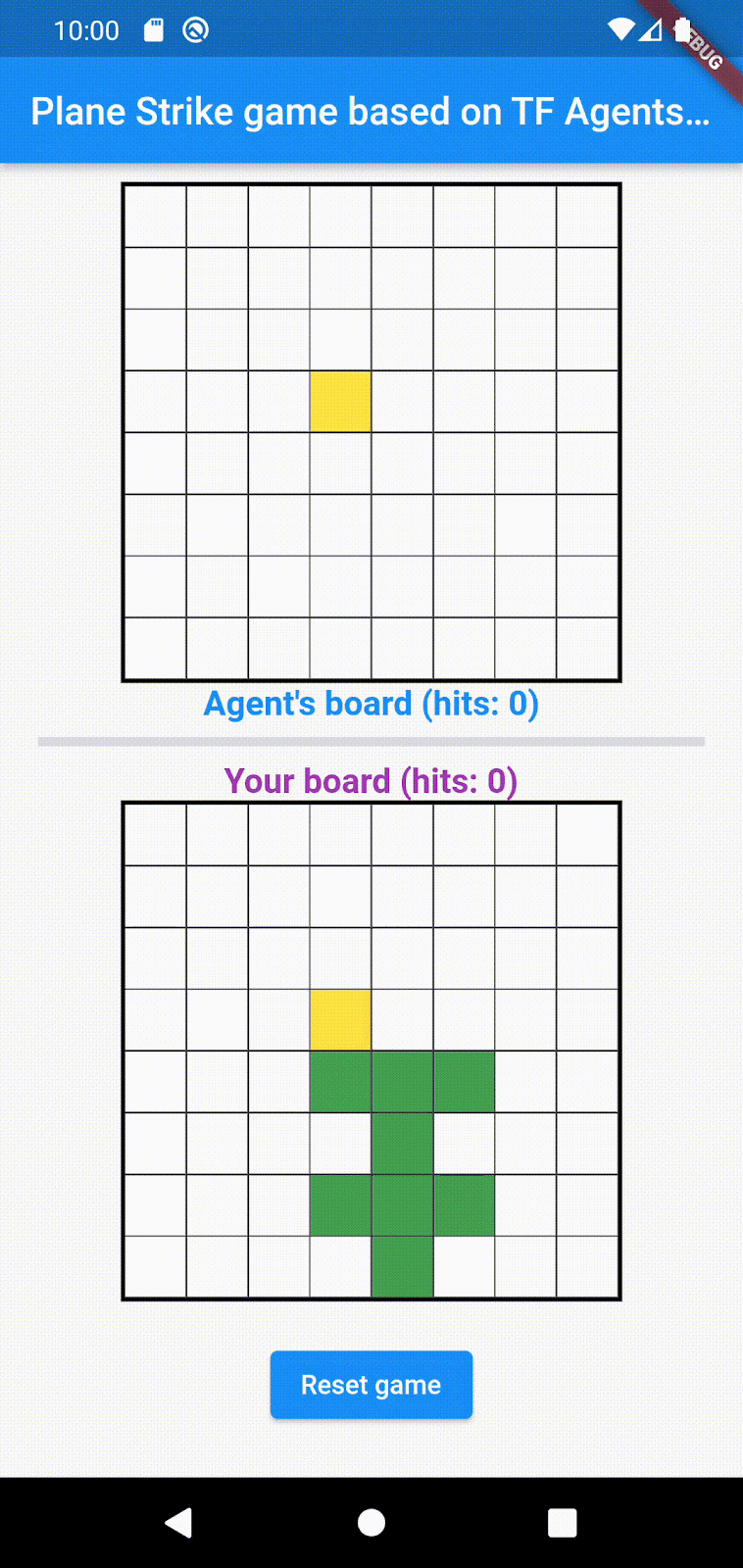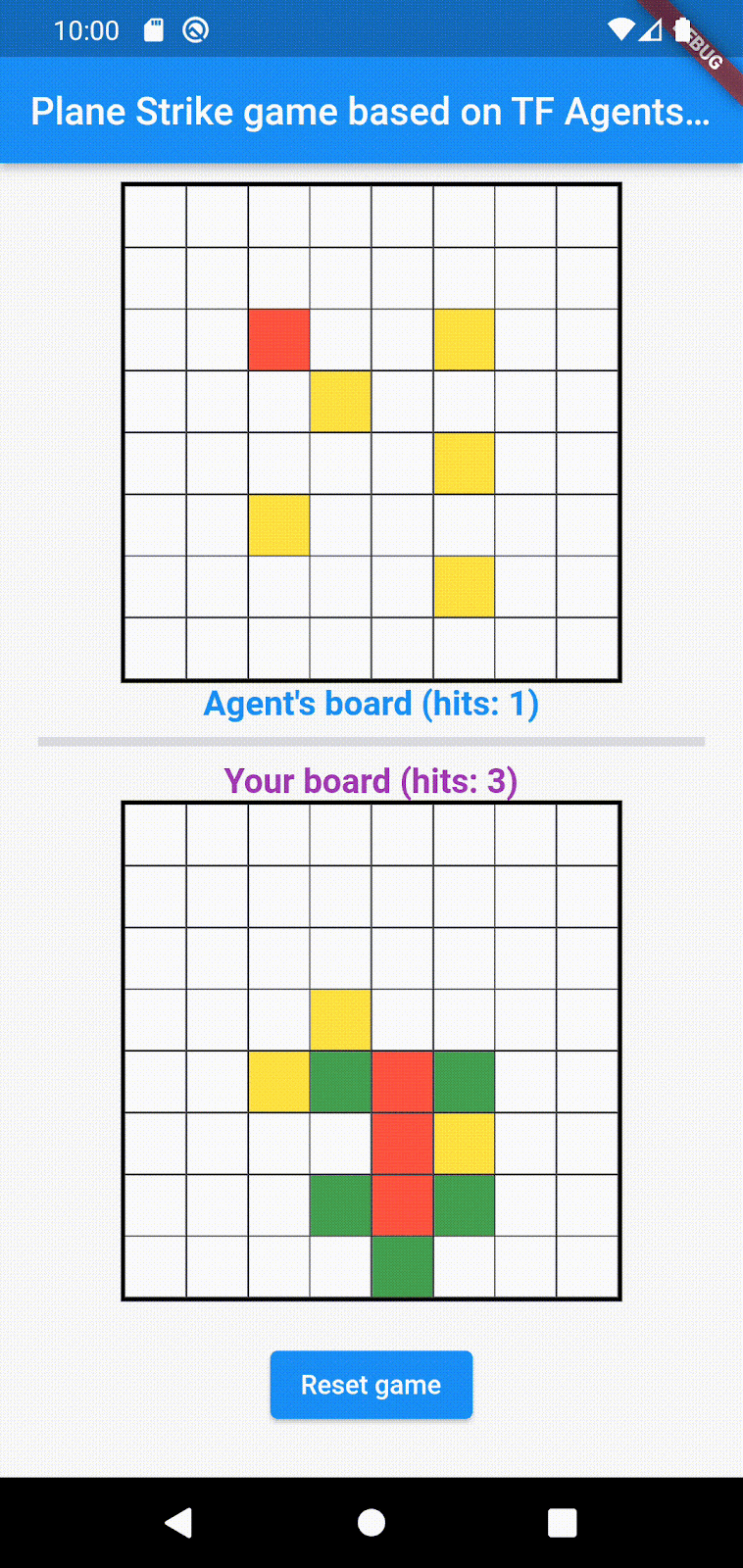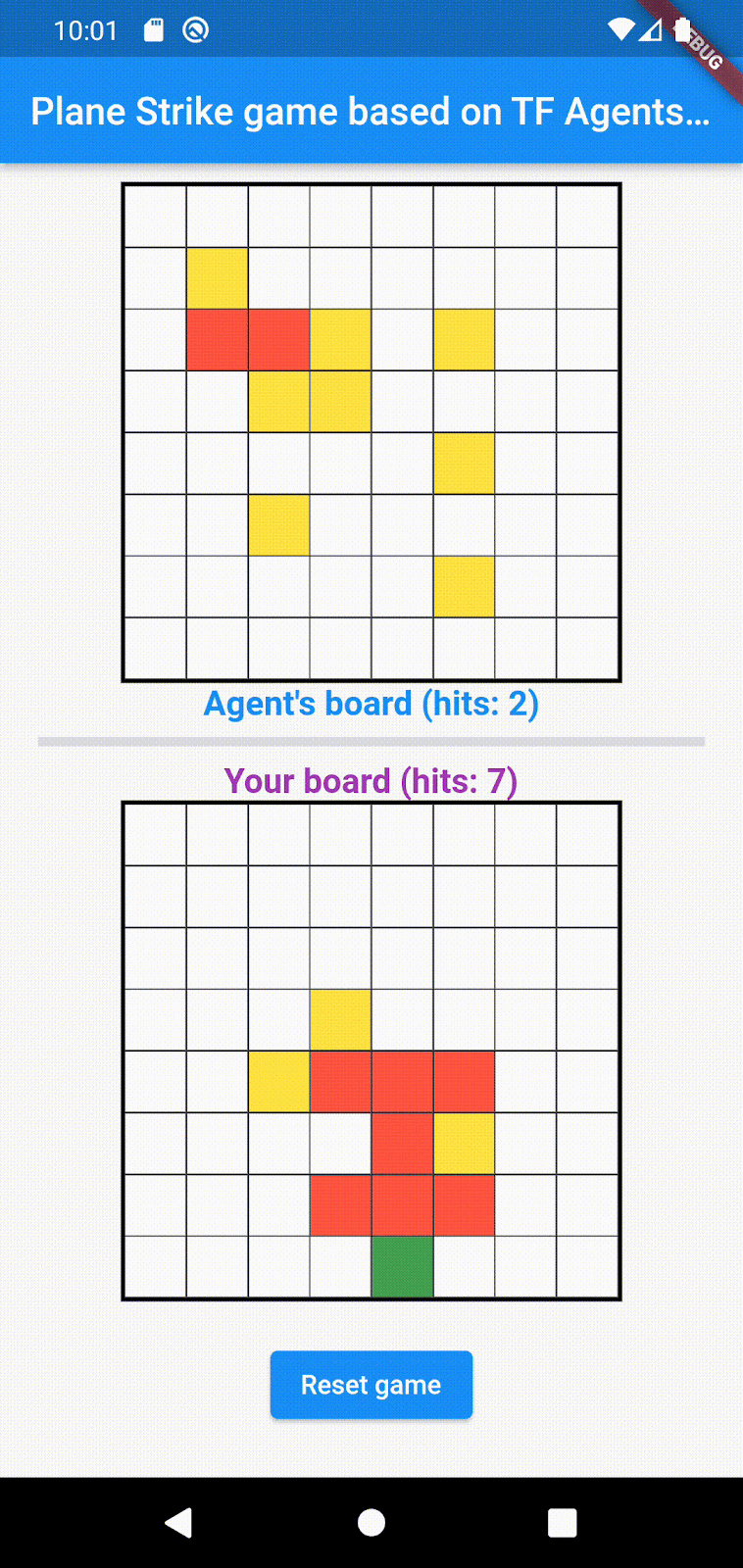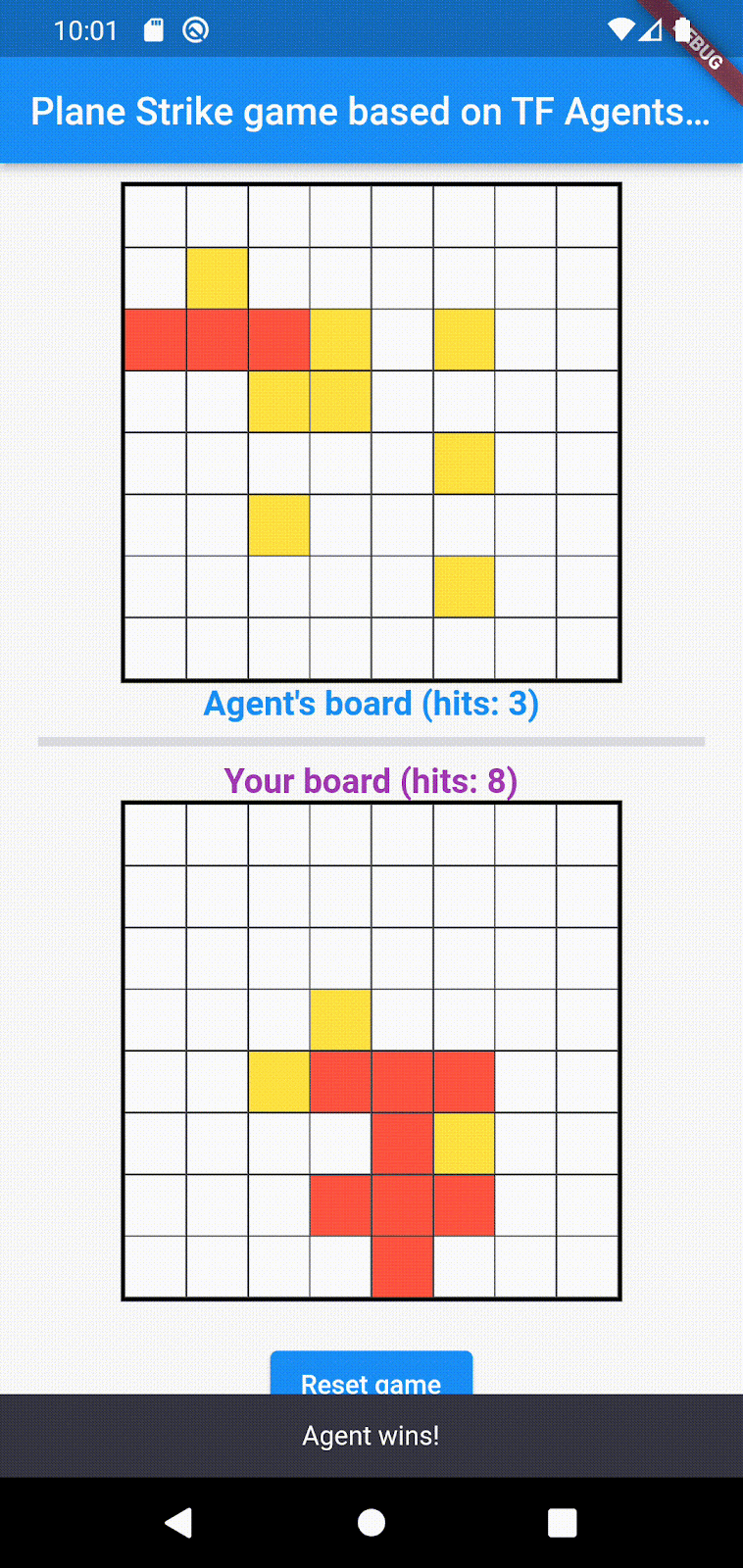
您在此 Codelab 中构建的游戏名为“Plane Strike”,是一款类似于“战舰”的小型双人桌游。规则非常简单:
- 人类玩家与由机器学习训练的 NPC 智能体对战。人类玩家可以点按代理的棋盘中的任意单元格来开始游戏。
- 游戏开始时,人类玩家和代理各自的棋盘上都有一个“飞机”对象(8 个绿色单元格,构成一架“飞机”,如动画中人类玩家的棋盘所示);这些“飞机”是随机放置的,只有棋盘的所有者可见,对手看不到。
- 人类玩家和代理轮流攻击对方棋盘上的一个单元格。人类玩家可以点按代理棋盘中的任意单元格,而代理会根据机器学习模型的预测自动做出选择。如果尝试的单元格是“飞机”单元格(“命中”),则会变成红色;否则会变成黄色(“未命中”)。
- 谁先获得 8 个红色单元格,谁就赢得游戏;然后,游戏会重新开始,并使用新的棋盘。
以下是游戏的示例玩法:
3. 设置您的 Flutter 开发环境
对于 Flutter 开发,您需要使用两款软件才能完成此 Codelab:Flutter SDK 和一款编辑器。
您可使用以下任一设备学习此 Codelab:
- iOS 模拟器(需要安装 Xcode 工具)。
- Android 模拟器(需要在 Android Studio 中设置)。
- 浏览器(需要使用 Chrome,以便进行调试)。
- 对于 Windows、Linux 或 macOS 桌面应用,您必须在打算部署到的平台上进行开发。因此,如果您要开发 Windows 桌面应用,则必须在 Windows 上进行开发,才能使用相应的构建链。如需详细了解针对各种操作系统的具体要求,请访问 docs.flutter.dev/desktop。
4. 进行设置
如需下载此 Codelab 的代码,请执行以下操作:
- 找到此 Codelab 的 GitHub 代码库。
- 点击 Code(代码)> Download zip(下载 Zip 文件),下载此 Codelab 的所有代码。

- 解压缩已下载的 ZIP 文件,这会解压缩
codelabs-main根文件夹,其中包含您需要的所有资源。
在此 Codelab 中,您只需要代码库的 tfagents-flutter/ 子目录(其中包含多个文件夹)中的文件:
step0到step6文件夹包含此 Codelab 中每一步的起始代码,您可以根据这些代码进行构建。finished文件夹包含已完成示例应用的完成后的代码。- 每个文件夹都包含一个
backbend子文件夹(其中包含后端代码)和一个frontend子文件夹(其中包含 Flutter 前端代码)
5. 下载项目的依赖项
后端
打开终端,然后进入 tfagents-flutter 子文件夹。运行以下命令:
pip install -r requirements.txt
前端
- 在 VS Code 中,点击 File(文件)> Open folder(打开文件夹),然后从您之前下载的源代码中选择
step0文件夹。 - 打开
step0/frontend/lib/main.dart文件。如果您看到一个 VS Code 对话框,提示您下载起始应用所需的软件包,请点击 Get packages。 - 如果您没有看到此对话框,请打开终端,然后在
step0/frontend文件夹中运行flutter pub get命令。

6. 第 0 步:运行起始应用
- 在 VS Code 中打开
step0/frontend/lib/main.dart文件,确保 Android 模拟器或 iOS 模拟器已正确设置并显示在状态栏中。
例如,当您将 Pixel 5 与 Android 模拟器搭配使用时,会看到以下内容:

当您将 iPhone 13 与 iOS 模拟器搭配使用时,会看到以下内容:

- 点击
 Start debugging(开始调试)。
Start debugging(开始调试)。
运行和探索应用
应用应在 Android 模拟器或 iOS 模拟器上启动。界面非常简单。游戏棋盘共有 2 个;人类玩家可以点按顶部代理的棋盘中的任意单元格作为打击位置。您将训练一个智能代理,使其能够根据人类玩家的棋盘自动预测攻击位置。
在后台,Flutter 应用会将人类玩家的当前棋盘状态发送到后端,后端会运行强化学习模型,并返回预测的下一个击打单元格位置。前端会在收到响应后在界面中显示结果。

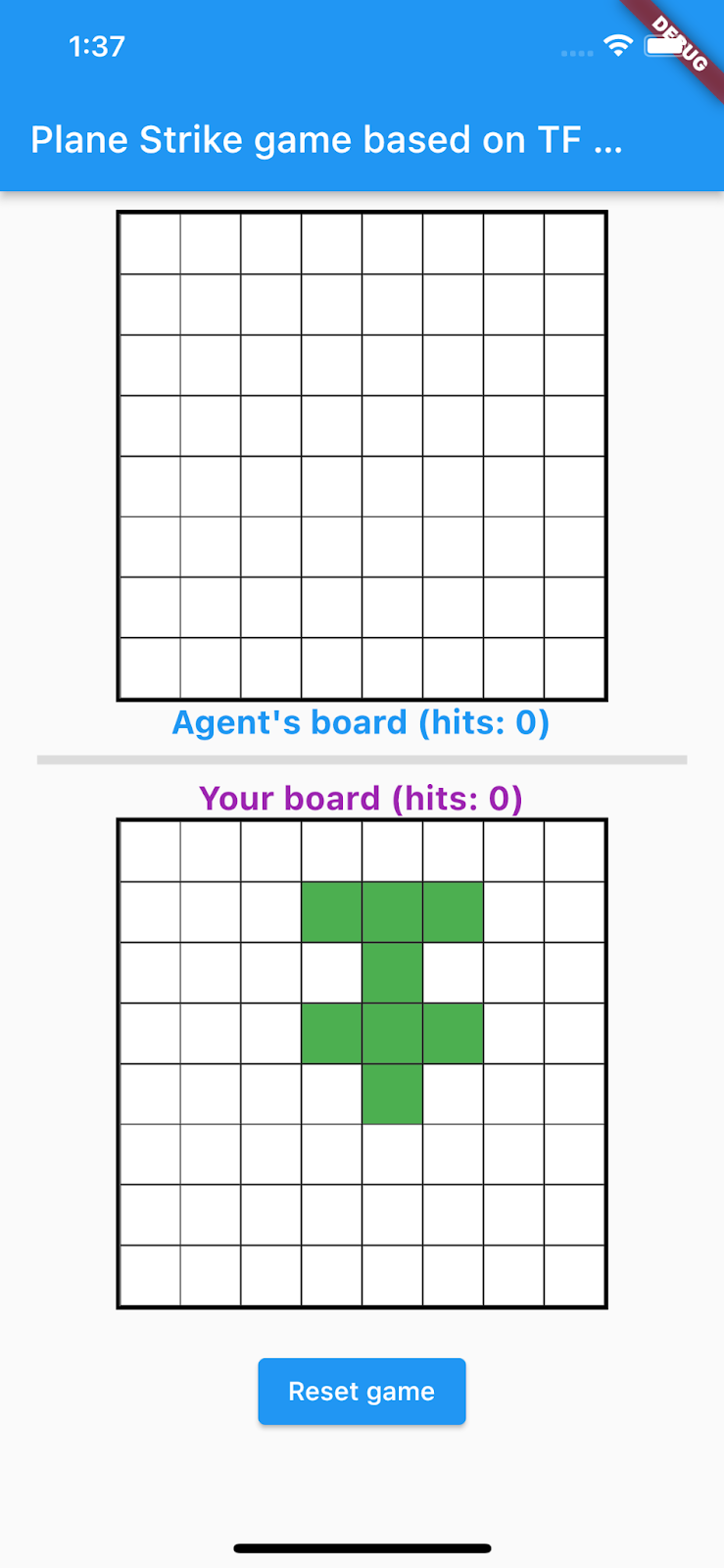
如果您现在点击代理的棋盘中的任何单元格,系统不会有任何反应,因为应用还无法与后端通信。
7. 第 1 步:创建 TensorFlow Agents Python 环境
此 Codelab 的主要目标是设计一个通过与环境互动来学习的代理。虽然“飞机打击”游戏相对简单,并且可以为 NPC 智能体手动制定规则,但您可以使用强化学习来训练智能体,以便学习相关技能,并能在未来轻松为其他游戏构建智能体。
在标准强化学习 (RL) 设置中,智能体会在每个时间步接收观测结果并选择一项操作。该动作会应用于环境,而环境会返回奖励和新的观测结果。智能体训练策略以选择可最大限度提高奖励总和(也称为回报)的行动。通过多次玩游戏,智能体能够学习模式并磨练技能,最终精通游戏。为了将“飞机打击”游戏表述为强化学习问题,请将棋盘状态视为观测结果,将打击位置视为行动,并将命中/未命中信号视为奖励。

为了训练 NPC 代理,您需要利用 TensorFlow Agents,这是一个可靠、可扩缩且易于使用的 TensorFlow 强化学习库。
TF Agents 非常适合强化学习,因为它附带了大量 Codelab、示例和详尽的文档,可帮助您快速入门。您可以使用 TF Agents 解决实际且复杂的 RL 问题,并快速开发新的 RL 算法。您可以轻松切换不同的代理和算法以进行实验。它还经过了充分的测试,并且易于配置。
OpenAI Gym(例如 Atari 游戏)、Mujuco 等中实现了许多预构建的游戏环境,TF Agents 可以轻松利用这些环境。不过,由于 Plane Strike 游戏是完全自定义的游戏,因此您需要先从头开始实现新的环境。
如需实现 TF Agents Python 环境,您需要实现以下方法:
class YourGameEnv(py_environment.PyEnvironment):
def __init__(self):
"""Initialize environment."""
def action_spec(self):
"""Return action_spec."""
def observation_spec(self):
"""Return observation_spec."""
def _reset(self):
"""Return initial_time_step."""
def _step(self, action):
"""Apply action and return new time_step."""
其中最重要的是 _step() 函数,它接受一个 action 并返回一个新的 time_step 对象。以“Plane Strike”游戏为例,您有一个游戏棋盘;当新的打击位置出现时,环境会根据游戏棋盘状态确定:
- 下一个游戏棋盘应该是什么样子(考虑到隐藏的飞机位置,单元格应该变为红色还是黄色?)
- 玩家应获得该位置的什么奖励(命中奖励或未中惩罚)?
- 游戏是否应结束(是否有人获胜?)
- 将以下代码添加到
_planestrike_py_environment.py文件中的_step()函数中:
if self._hit_count == self._plane_size:
self._episode_ended = True
return self.reset()
if self._strike_count + 1 == self._max_steps:
self.reset()
return ts.termination(
np.array(self._visible_board, dtype=np.float32), UNFINISHED_GAME_REWARD
)
self._strike_count += 1
action_x = action // self._board_size
action_y = action % self._board_size
# Hit
if self._hidden_board[action_x][action_y] == HIDDEN_BOARD_CELL_OCCUPIED:
# Non-repeat move
if self._visible_board[action_x][action_y] == VISIBLE_BOARD_CELL_UNTRIED:
self._hit_count += 1
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_HIT
# Successful strike
if self._hit_count == self._plane_size:
# Game finished
self._episode_ended = True
return ts.termination(
np.array(self._visible_board, dtype=np.float32),
FINISHED_GAME_REWARD,
)
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
HIT_REWARD,
self._discount,
)
# Repeat strike
else:
self._episode_ended = False
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
REPEAT_STRIKE_REWARD,
self._discount,
)
# Miss
else:
# Unsuccessful strike
self._episode_ended = False
self._visible_board[action_x][action_y] = VISIBLE_BOARD_CELL_MISS
return ts.transition(
np.array(self._visible_board, dtype=np.float32),
MISS_REWARD,
self._discount,
8. 第 2 步:使用 TensorFlow Agents 训练游戏代理
在 TF Agents 环境就绪后,您就可以训练游戏代理了。在此 Codelab 中,您将使用 REINFORCE 智能体。REINFORCE 是强化学习中的一种策略梯度算法。其基本思想是根据游戏过程中收集的奖励信号调整策略神经网络参数,以便策略网络在未来的游戏中实现回报最大化。
- 首先,您需要实例化训练和评估环境。将以下代码添加到
step2/backend/training.py文件中的train_agent()函数中:
train_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
eval_py_env = planestrike_py_environment.PlaneStrikePyEnvironment(
board_size=BOARD_SIZE, discount=DISCOUNT, max_steps=BOARD_SIZE**2
)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
- 接下来,您需要创建一个将要接受训练的强化学习代理。在此 Codelab 中,您将使用基于政策的 REINFORCE 智能体。在上述代码的正下方添加以下代码:
actor_net = tfa.networks.Sequential(
[
tfa.keras_layers.InnerReshape([BOARD_SIZE, BOARD_SIZE], [BOARD_SIZE**2]),
tf.keras.layers.Dense(FC_LAYER_PARAMS, activation="relu"),
tf.keras.layers.Dense(BOARD_SIZE**2),
tf.keras.layers.Lambda(lambda t: tfp.distributions.Categorical(logits=t)),
],
input_spec=train_py_env.observation_spec(),
)
optimizer = tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter,
)
- 最后,在训练循环中训练代理。在循环中,您首先将一些游戏对局收集到缓冲区中,然后使用缓冲的数据训练代理。将以下代码添加到
step2/backend/training.py文件中的train_agent()函数中:
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env,
collect_policy,
COLLECT_EPISODES_PER_ITERATION,
replay_buffer_observer,
)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
tf_agent.train(experience=trajectories)
replay_buffer.clear()
- 现在,您可以开始训练了。在终端中,前往计算机上的
step2/backend文件夹,然后运行:
python training.py
训练需要 8-12 小时才能完成,具体取决于您的硬件配置(您不必自行完成整个训练,因为 step3 中提供了预训练模型)。在此期间,您可以使用 TensorBoard 监控进度。打开一个新终端,前往计算机上的 step2/backend 文件夹,然后运行:
tensorboard --logdir tf_agents_log/
tf_agents_log 是包含训练日志的文件夹。训练运行示例如下所示:


您可以看到,随着训练的进行,平均集长度会缩短,平均回报会增加。直观上,您可以理解,如果代理更智能,做出更好的预测,游戏时长就会缩短,代理也会获得更多奖励。这是合理的,因为智能体希望在更少的步数内完成游戏,以最大限度地减少后续步骤中的大幅奖励折扣。
训练完成后,经过训练的模型会导出到 policy_model 文件夹。
9. 第 3 步:使用 TensorFlow Serving 部署训练好的模型
现在,您已经训练了游戏代理,接下来可以使用 TensorFlow Serving 部署它。
- 在终端中,前往计算机上的
step3/backend文件夹,然后使用 Docker 启动 TensorFlow Serving:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/backend/policy_model:/models/policy_model" -e MODEL_NAME=policy_model tensorflow/serving
Docker 会先自动下载 TensorFlow Serving 映像,此过程需要一分钟时间。之后,TensorFlow Serving 便会启动。日志应如下面的代码段所示:
2022-05-30 02:38:54.147771: I tensorflow_serving/model_servers/server.cc:89] Building single TensorFlow model file config: model_name: policy_model model_base_path: /models/policy_model
2022-05-30 02:38:54.148222: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-05-30 02:38:54.148273: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: policy_model
2022-05-30 02:38:54.262684: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: policy_model version: 123}
2022-05-30 02:38:54.262768: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: policy_model version: 123}
2022-05-30 02:38:54.262787: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: policy_model version: 123}
2022-05-30 02:38:54.265010: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/policy_model/123
2022-05-30 02:38:54.277811: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-05-30 02:38:54.278116: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/policy_model/123
2022-05-30 02:38:54.280229: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-05-30 02:38:54.332352: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-05-30 02:38:54.337000: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2193480000 Hz
2022-05-30 02:38:54.402803: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/policy_model/123
2022-05-30 02:38:54.410707: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 145695 microseconds.
2022-05-30 02:38:54.412726: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/policy_model/123/assets.extra/tf_serving_warmup_requests
2022-05-30 02:38:54.417277: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: policy_model version: 123}
2022-05-30 02:38:54.419846: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-05-30 02:38:54.420066: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-05-30 02:38:54.428339: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-05-30 02:38:54.431620: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
您可以向端点发送示例请求,以确保其按预期运行:
curl -d '{"signature_name":"action","instances":[{"0/discount":0.0,"0/observation":[[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],"0/reward":0.0,"0/step_type":0}]}' -X POST http://localhost:8501/v1/models/policy_model:predict
该端点将返回预测位置 45,即棋盘中心的 (5, 5)(好奇的读者可以尝试推断一下为什么棋盘中心是首次打击位置的理想猜测)。
{
"predictions": [45]
}
大功告成!您已成功构建一个后端,用于预测 NPC 代理的下一次击球位置。
10. 第 4 步:为 Android 和 iOS 创建 Flutter 应用
后端已准备就绪。您可以开始向其发送请求,以从 Flutter 应用中检索命中位置预测。
- 首先,您需要定义一个封装要发送的输入的类。将以下代码添加到
step4/frontend/lib/game_agent.dart文件中:
class Inputs {
final List<double> _boardState;
Inputs(this._boardState);
Map<String, dynamic> toJson() {
final Map<String, dynamic> data = <String, dynamic>{};
data['0/discount'] = [0.0];
data['0/observation'] = [_boardState];
data['0/reward'] = [0.0];
data['0/step_type'] = [0];
return data;
}
}
现在,您可以将请求发送到 TensorFlow Serving 以进行预测。
- 将以下代码添加到
step4/frontend/lib/game_agent.dart文件中的predict()函数中:
var flattenedBoardState = boardState.expand((i) => i).toList();
final response = await http.post(
Uri.parse('http://$server:8501/v1/models/policy_model:predict'),
body: jsonEncode(<String, dynamic>{
'signature_name': 'action',
'instances': [Inputs(flattenedBoardState)]
}),
);
if (response.statusCode == 200) {
var output = List<int>.from(
jsonDecode(response.body)['predictions'] as List<dynamic>);
return output[0];
} else {
throw Exception('Error response');
}
应用收到来自后端的响应后,您需要更新游戏界面以反映游戏进度。
- 将以下代码添加到
step4/frontend/lib/main.dart文件中的_gridItemTapped()函数中:
int agentAction =
await _policyGradientAgent.predict(_playerVisibleBoardState);
_agentActionX = agentAction ~/ _boardSize;
_agentActionY = agentAction % _boardSize;
if (_playerHiddenBoardState[_agentActionX][_agentActionY] ==
hiddenBoardCellOccupied) {
// Non-repeat move
if (_playerVisibleBoardState[_agentActionX][_agentActionY] ==
visibleBoardCellUntried) {
_agentHitCount++;
}
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellHit;
} else {
_playerVisibleBoardState[_agentActionX][_agentActionY] =
visibleBoardCellMiss;
}
setState(() {});
运行应用
- 点击 Start debugging(开始调试),然后等待应用加载。
- 点按代理的棋盘中的任意单元格即可开始游戏。


11. 第 5 步:为桌面平台启用 Flutter 应用
除了 Android 和 iOS 之外,Flutter 还支持桌面平台,包括 Linux、Mac 和 Windows。
Linux
- 确保目标设备在 VSCode 的状态栏中设置为
 。
。 - 点击 Start debugging(开始调试),然后等待应用加载。
- 点击代理人棋盘中的任意单元格即可开始游戏。

Mac
- 对于 Mac,您需要设置适当的使用权,因为应用会向后端发送 HTTP 请求。如需了解详情,请参阅使用权和应用沙盒。
将以下代码分别添加到 step4/frontend/macOS/Runner/DebugProfile.entitlements 和 step4/frontend/macOS/Runner/Release.entitlements 中:
<key>com.apple.security.network.client</key>
<true/>
- 确保目标设备在 VSCode 的状态栏中设置为
 。
。 - 点击 Start debugging(开始调试),然后等待应用加载。
- 点击代理人棋盘中的任意单元格即可开始游戏。

Windows
- 确保目标设备在 VSCode 的状态栏中设置为
 。
。 - 点击 Start debugging(开始调试),然后等待应用加载。
- 点击代理人棋盘中的任意单元格即可开始游戏。

12. 第 6 步:为 Web 平台启用 Flutter 应用
您还可以向 Flutter 应用添加 Web 支持。默认情况下,系统会自动为 Flutter 应用启用 Web 平台,因此您只需启动应用即可。
- 确保目标设备在 VSCode 的状态栏中设置为
 。
。 - 点击 Start debugging(开始调试),然后等待应用在 Chrome 浏览器中加载。
- 点击代理人棋盘中的任意单元格即可开始游戏。

13. 恭喜
您构建了一款包含机器学习赋能的代理的桌游应用,可与人类玩家对战!