
۱. مرور کلی
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه از روالهای پیشبینی سفارشی در Vertex AI برای نوشتن منطق پیشپردازش و پسپردازش سفارشی استفاده کنید. در حالی که این نمونه از Scikit-learn استفاده میکند، روالهای پیشبینی سفارشی میتوانند با سایر چارچوبهای یادگیری ماشین پایتون مانند XGBoost، PyTorch و TensorFlow نیز کار کنند.
آنچه یاد میگیرید
شما یاد خواهید گرفت که چگونه:
- منطق پیشبینی سفارشی را با روالهای پیشبینی سفارشی بنویسید
- ظرف سرو سفارشی را آزمایش کنید و به صورت محلی مدلسازی کنید
- ظرف سرو سفارشی را در پیشبینیهای هوش مصنوعی Vertex آزمایش کنید
هزینه کل اجرای این آزمایشگاه در گوگل کلود حدود ۱ دلار آمریکا است.
۲. مقدمهای بر هوش مصنوعی ورتکس
این آزمایشگاه از جدیدترین محصول هوش مصنوعی موجود در Google Cloud استفاده میکند. Vertex AI، محصولات یادگیری ماشین را در سراسر Google Cloud در یک تجربه توسعه یکپارچه ادغام میکند. پیش از این، مدلهای آموزشدیده با AutoML و مدلهای سفارشی از طریق سرویسهای جداگانه قابل دسترسی بودند. این محصول جدید، هر دو را در یک API واحد، به همراه سایر محصولات جدید، ترکیب میکند. همچنین میتوانید پروژههای موجود را به Vertex AI منتقل کنید.
هوش مصنوعی ورتکس شامل محصولات مختلفی برای پشتیبانی از گردشهای کاری یادگیری ماشینی سرتاسری است. این آزمایشگاه بر پیشبینیها و میز کار تمرکز خواهد داشت.

۳. بررسی اجمالی موارد استفاده
مورد استفاده
در این آزمایش، شما یک مدل رگرسیون جنگل تصادفی خواهید ساخت تا قیمت یک الماس را بر اساس ویژگیهایی مانند برش، شفافیت و اندازه پیشبینی کنید.
شما منطق پیشپردازش سفارشی خواهید نوشت تا بررسی کنید که دادهها در زمان ارائه، در قالب مورد انتظار مدل هستند یا خیر. همچنین منطق پسپردازش سفارشی خواهید نوشت تا پیشبینیها را گرد کرده و آنها را به رشته تبدیل کنید. برای نوشتن این منطق، از روالهای پیشبینی سفارشی استفاده خواهید کرد.
مقدمهای بر روالهای پیشبینی سفارشی
کانتینرهای از پیش ساخته شده Vertex AI با انجام عملیات پیشبینی چارچوب یادگیری ماشین، درخواستهای پیشبینی را مدیریت میکنند. قبل از روالهای پیشبینی سفارشی، اگر میخواستید ورودی را قبل از انجام پیشبینی پیشپردازش کنید، یا پیشبینی مدل را قبل از بازگرداندن نتیجه پسپردازش کنید، باید یک کانتینر سفارشی بسازید.
ساخت یک کانتینر سرو سفارشی نیاز به نوشتن یک سرور HTTP دارد که مدل آموزش دیده را در بر میگیرد، درخواستهای HTTP را به ورودیهای مدل ترجمه میکند و خروجیهای مدل را به پاسخها تبدیل میکند.
با استفاده از روالهای پیشبینی سفارشی، Vertex AI اجزای مرتبط با سرویسدهی را برای شما فراهم میکند تا بتوانید روی مدل و تبدیل دادهها تمرکز کنید.
۴. محیط خود را آماده کنید
برای اجرای این codelab به یک پروژه Google Cloud Platform با قابلیت پرداخت صورتحساب نیاز دارید. برای ایجاد یک پروژه، دستورالعملهای اینجا را دنبال کنید.
مرحله ۱: فعال کردن رابط برنامهنویسی کاربردی موتور محاسبات
به Compute Engine بروید و اگر از قبل فعال نشده است، آن را فعال کنید . برای ایجاد نمونه نوتبوک خود به این مورد نیاز خواهید داشت.
مرحله ۲: فعال کردن API رجیستری مصنوعات
به بخش Artifact Registry بروید و اگر فعال نیست، آن را فعال کنید. از این گزینه برای ایجاد یک ظرف سرو سفارشی استفاده خواهید کرد.
مرحله 3: فعال کردن API هوش مصنوعی Vertex
به بخش Vertex AI در کنسول ابری خود بروید و روی Enable Vertex AI API کلیک کنید.

مرحله ۴: ایجاد یک نمونه از Vertex AI Workbench
از بخش Vertex AI در کنسول ابری خود، روی Workbench کلیک کنید:

اگر API نوتبوکها فعال نیست، آن را فعال کنید.
پس از فعال کردن، روی INSTANCES کلیک کنید و سپس CREATE NEW را انتخاب کنید.
گزینههای پیشفرض را بپذیرید و روی «ایجاد» کلیک کنید.
وقتی نمونه آماده شد، روی OPEN JUPYTERLAB کلیک کنید تا نمونه باز شود.
۵. کد آموزشی را بنویسید
مرحله ۱: ایجاد یک فضای ذخیرهسازی ابری
شما مدل و مصنوعات پیشپردازش را در یک مخزن ذخیرهسازی ابری ذخیره خواهید کرد. اگر از قبل یک مخزن در پروژه خود دارید که میخواهید از آن استفاده کنید، میتوانید از این مرحله صرف نظر کنید.
از طریق لانچر، یک بخش ترمینال جدید باز کنید.

از ترمینال خود، دستور زیر را برای تعریف یک متغیر env برای پروژه خود اجرا کنید، و مطمئن شوید که your-cloud-project را با شناسه پروژه خود جایگزین میکنید:
PROJECT_ID='your-cloud-project'
در مرحله بعد، دستور زیر را در ترمینال خود اجرا کنید تا یک باکت جدید در پروژه شما ایجاد شود.
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
مرحله ۲: مدل قطار
از طریق ترمینال، یک دایرکتوری جدید به نام cpr-codelab ایجاد کنید و با دستور cd وارد آن شوید.
mkdir cpr-codelab
cd cpr-codelab
در مرورگر فایل، به دایرکتوری جدید cpr-codelab بروید و سپس از لانچر برای ایجاد یک نوتبوک پایتون ۳ جدید به نام task.ipynb استفاده کنید.
پوشه cpr-codelab شما اکنون باید به شکل زیر باشد:
+ cpr-codelab/
+ task.ipynb
در دفترچه یادداشت، کد زیر را وارد کنید.
ابتدا، یک فایل requirements.txt بنویسید.
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
مدلی که شما مستقر میکنید، مجموعهای از وابستگیهای از پیش نصبشدهی متفاوت از محیط نوتبوک شما خواهد داشت. به همین دلیل، شما باید تمام وابستگیهای مدل را در requirements.txt فهرست کنید و سپس از pip برای نصب دقیقاً همان وابستگیها در نوتبوک استفاده کنید. بعداً، قبل از استقرار در Vertex AI، مدل را به صورت محلی آزمایش خواهید کرد تا از مطابقت محیطها اطمینان حاصل کنید.
پیپ وابستگیها را در نوتبوک نصب میکند.
!pip install -U --user -r requirements.txt
توجه داشته باشید که پس از اتمام نصب pip، باید هسته را مجدداً راهاندازی کنید.

در مرحله بعد، دایرکتوریهایی را ایجاد کنید که مدل و مصنوعات پیشپردازش را در آنها ذخیره خواهید کرد.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
پوشه cpr-codelab شما اکنون باید به شکل زیر باشد:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
حالا که ساختار دایرکتوری تنظیم شده، وقت آموزش مدل است!
ابتدا کتابخانهها را ایمپورت کنید.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
سپس متغیرهای زیر را تعریف کنید. حتماً PROJECT_ID با شناسه پروژه خود و BUCKET_NAME با باکتی که در مرحله قبل ایجاد کردید جایگزین کنید.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
دادهها را از کتابخانهی سیبورن بارگذاری کنید و سپس دو دیتافریم ایجاد کنید، یکی شامل ویژگیها و دیگری شامل برچسب.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
بیایید نگاهی به دادههای آموزشی بیندازیم. میتوانید ببینید که هر ردیف نشان دهنده یک الماس است.
x_train.head()
و برچسبها، که قیمتهای مربوطه هستند.
y_train.head()
حالا، یک تبدیل ستونی sklearn تعریف کنید که ویژگیهای دستهبندیشده را به یک کدگذاری داغ تبدیل کند و ویژگیهای عددی را مقیاسبندی کند.
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
مدل جنگل تصادفی را تعریف کنید
regr = RandomForestRegressor(max_depth=10, random_state=0)
در مرحله بعد، یک خط لوله sklearn ایجاد کنید. این بدان معناست که دادههای ارسالی به این خط لوله ابتدا کدگذاری/مقیاسبندی شده و سپس به مدل ارسال میشوند.
my_pipeline = make_pipeline(column_transform, regr)
خط لوله را روی دادههای آموزشی قرار دهید
my_pipeline.fit(x_train, y_train)
بیایید مدل را امتحان کنیم تا مطمئن شویم که طبق انتظار کار میکند. متد predict را روی مدل فراخوانی کنید و یک نمونه آزمایشی به آن ارسال کنید.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
حالا میتوانیم pipeline را در دایرکتوری model_artifacts ذخیره کنیم و آن را در فضای ذخیرهسازی ابری کپی کنیم.
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
مرحله ۳: ذخیره یک مصنوع پیشپردازش
در مرحله بعد، یک مصنوع پیشپردازش ایجاد خواهید کرد. این مصنوع هنگام راهاندازی سرور مدل در کانتینر سفارشی بارگذاری میشود. مصنوع پیشپردازش شما میتواند تقریباً به هر شکلی باشد (مانند یک فایل pickle)، اما در این حالت، یک دیکشنری را در یک فایل JSON خواهید نوشت.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
ویژگی clarity در دادههای آموزشی ما همیشه به صورت اختصاری بود (یعنی "FL" به جای "Flawless"). در زمان ارائه، میخواهیم بررسی کنیم که دادههای این ویژگی نیز اختصاری باشند. دلیل این امر این است که مدل ما میداند چگونه "FL" را به صورت یکجا کدگذاری کند اما "Flawless" را نه. این منطق پیشپردازش سفارشی را بعداً خواهید نوشت. اما فعلاً، فقط این جدول جستجو را در یک فایل json ذخیره کنید و سپس آن را در فضای ذخیرهسازی ابری بنویسید.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
دایرکتوری محلی cpr-codelab شما اکنون باید به شکل زیر باشد:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
۶. با استفاده از سرور مدل CPR، یک ظرف سرو سفارشی بسازید
اکنون که مدل آموزش داده شده و مصنوع پیشپردازش ذخیره شده است، زمان ساخت ظرف سرو سفارشی فرا رسیده است. معمولاً ساخت یک ظرف سرو نیاز به نوشتن کد سرور مدل دارد. با این حال، با روالهای پیشبینی سفارشی، Vertex AI Predictions یک سرور مدل تولید میکند و یک تصویر کانتینر سفارشی برای شما میسازد.
یک ظرف سرو سفارشی شامل ۳ قطعه کد زیر است:
- سرور مدل (این سرور به طور خودکار توسط SDK تولید و در
scr_dir/ذخیره میشود)- سرور HTTP که میزبان مدل است
- مسئول تنظیم مسیرها/پورتها/و غیره.
- درخواست رسیدگی کننده
- مسئول جنبههای وبسرور در رسیدگی به یک درخواست، مانند deserialize کردن بدنه درخواست و serialize کردن پاسخ، تنظیم هدرهای پاسخ و غیره.
- در این مثال، شما از Handler پیشفرض،
google.cloud.aiplatform.prediction.handler.PredictionHandlerکه در SDK ارائه شده است، استفاده خواهید کرد.
- پیشبینیکننده
- مسئول منطق ML برای پردازش یک درخواست پیشبینی.
هر یک از این اجزا میتوانند بر اساس الزامات مورد استفاده شما سفارشیسازی شوند. در این مثال، شما فقط پیشبینیکننده را پیادهسازی خواهید کرد.
پیشبینیکننده مسئول منطق یادگیری ماشین برای پردازش یک درخواست پیشبینی، مانند پیشپردازش و پسپردازش سفارشی است. برای نوشتن منطق پیشبینی سفارشی، باید از رابط پیشبینیکننده هوش مصنوعی ورتکس، زیرکلاس ایجاد کنید.
این نسخه از روالهای پیشبینی سفارشی با پیشبینیکنندههای قابل استفاده مجدد XGBoost و Sklearn ارائه میشود، اما اگر نیاز به استفاده از چارچوب دیگری دارید، میتوانید با زیرکلاس کردن پیشبینیکننده پایه، چارچوب خودتان را ایجاد کنید.
میتوانید نمونهای از پیشبینیکنندهی Sklearn را در زیر مشاهده کنید. این تمام کدی است که برای ساخت این سرور مدل سفارشی باید بنویسید.

در دفترچه یادداشت خود، کد زیر را برای زیرکلاس کردن SklearnPredictor وارد کنید و آن را در یک فایل پایتون در src_dir/ بنویسید. توجه داشته باشید که در این مثال، ما فقط متدهای load ، preprocess و postprocess را سفارشی میکنیم و متد predict را نه.
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
بیایید نگاهی عمیقتر به هر یک از این روشها بیندازیم.
- متد
load، مصنوع پیشپردازش را بارگذاری میکند، که در این مورد یک فرهنگ لغت است که مقادیر وضوح الماس را به اختصارات آنها نگاشت میکند. - روش
preprocessاز آن مصنوع استفاده میکند تا اطمینان حاصل کند که در زمان ارائه، ویژگی وضوح در قالب اختصاری خود قرار دارد. در غیر این صورت، رشته کامل را به اختصار آن تبدیل میکند. - متد
postprocessمقدار پیشبینیشده را به صورت یک رشته با علامت $ برمیگرداند و مقدار را گرد میکند.
در مرحله بعد، از Vertex AI Python SDK برای ساخت ایمیج استفاده کنید. با استفاده از روالهای پیشبینی سفارشی، Dockerfile تولید شده و ایمیج برای شما ساخته خواهد شد.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
یک فایل آزمایشی با دو نمونه برای پیشبینی بنویسید. یکی از نمونهها نام اختصاری وضوح را دارد، اما دیگری ابتدا باید تبدیل شود.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
با استفاده از یک مدل محلی، کانتینر را به صورت محلی آزمایش کنید.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
نتایج پیشبینی را میتوانید با موارد زیر مشاهده کنید:
predict_response.content
۷. مدل را در Vertex AI مستقر کنید
حالا که کانتینر را به صورت محلی آزمایش کردهاید، وقت آن رسیده که تصویر را به Artifact Registry منتقل کنید و مدل را در Vertex AI Model Registry آپلود کنید.
ابتدا، Docker را برای دسترسی به رجیستری Artifact پیکربندی کنید.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
سپس، تصویر را فشار دهید.
local_model.push_image()
و مدل را آپلود کنید.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
وقتی مدل آپلود شد، باید آن را در کنسول مشاهده کنید:

در مرحله بعد، مدل را مستقر کنید تا بتوانید از آن برای پیشبینیهای آنلاین استفاده کنید. روالهای پیشبینی سفارشی با پیشبینی دستهای نیز کار میکنند، بنابراین اگر مورد استفاده شما نیازی به پیشبینیهای آنلاین ندارد، نیازی به استقرار مدل ندارید.
endpoint = model.deploy(machine_type="n1-standard-2")
در نهایت، مدل پیادهسازی شده را با دریافت یک پیشبینی آزمایش کنید.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 تبریک میگویم! 🎉
شما یاد گرفتید که چگونه از Vertex AI برای موارد زیر استفاده کنید:
- نوشتن منطق پیشپردازش و پسپردازش سفارشی با روالهای پیشبینی سفارشی
برای کسب اطلاعات بیشتر در مورد بخشهای مختلف Vertex AI، مستندات را بررسی کنید.
۸. پاکسازی
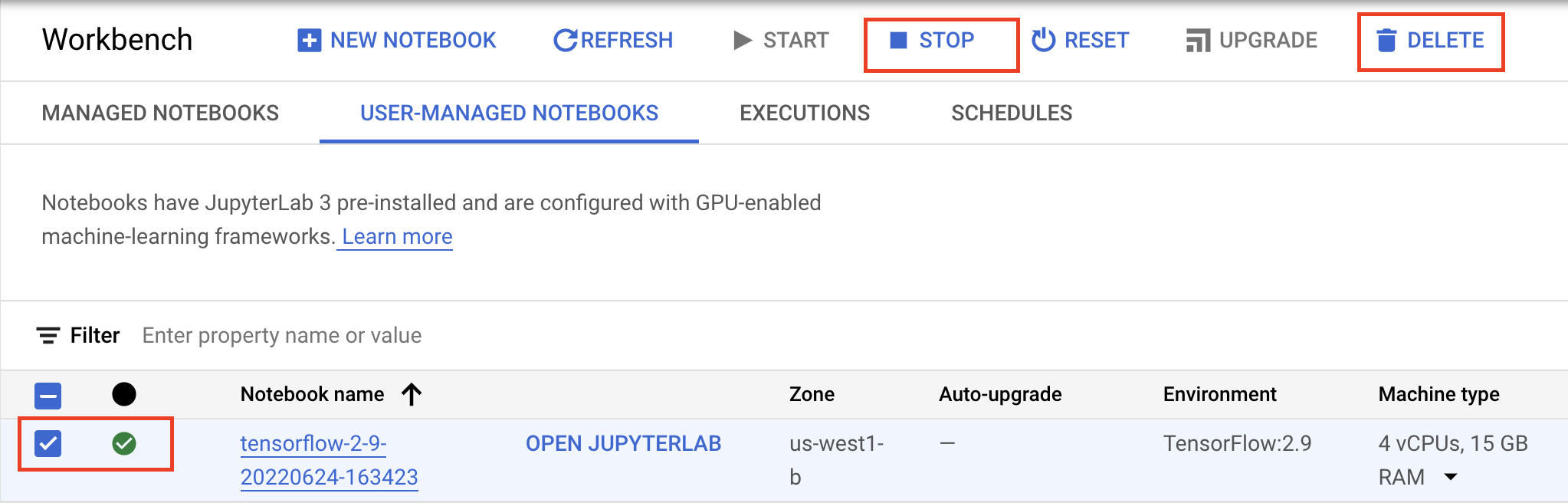
اگر میخواهید به استفاده از دفترچه یادداشتی که در این آزمایشگاه ایجاد کردهاید ادامه دهید، توصیه میشود در صورت عدم استفاده آن را خاموش کنید. از رابط کاربری Workbench در کنسول Google Cloud، دفترچه یادداشت را انتخاب کرده و سپس Stop را انتخاب کنید.
اگر میخواهید دفترچه یادداشت را به طور کامل حذف کنید، روی دکمه حذف در بالا سمت راست کلیک کنید.
برای حذف نقطه پایانی که مستقر کردهاید، به بخش نقاط پایانی کنسول بروید، روی نقطه پایانی که ایجاد کردهاید کلیک کنید و سپس Undeploy model from endpoint را انتخاب کنید:

برای حذف تصویر کانتینر، به Artifact Registry بروید، مخزنی را که ایجاد کردهاید انتخاب کنید و Delete را انتخاب کنید.

برای حذف Storage Bucket، با استفاده از منوی ناوبری در Cloud Console خود، به Storage بروید، Bucket خود را انتخاب کنید و روی Delete کلیک کنید:
