1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך להשתמש בשגרות חיזוי מותאמות אישית ב-Vertex AI כדי לכתוב לוגיקה מותאמת אישית לעיבוד מקדים ולעיבוד פוסט. בדוגמה הזו נעשה שימוש ב-Scikit-learn, אבל אפשר להשתמש בשגרות חיזוי מותאמות אישית גם עם מסגרות אחרות של למידת מכונה ב-Python, כמו XGBoost, PyTorch ו-TensorFlow.
מה לומדים
במאמר הזה נסביר איך:
- כתיבת לוגיקה מותאמת אישית של חיזוי באמצעות שגרות חיזוי מותאמות אישית
- בדיקה מקומית של קונטיינר ההגשה והמודל בהתאמה אישית
- בדיקת קונטיינר מותאם אישית להצגת מודלים ב-Vertex AI Predictions
העלות הכוללת להרצת שיעור ה-Lab הזה ב-Google Cloud היא בערך 1$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. בשיעור ה-Lab הזה נתמקד ב-Predictions וב-Workbench.

3. סקירה כללית של תרחיש לדוגמה
תרחיש לדוגמה
בשיעור ה-Lab הזה תבנו מודל רגרסיה של יער אקראי כדי לחזות את המחיר של יהלום על סמך מאפיינים כמו ליטוש, ניקיון וגודל.
תכתבו לוגיקה מותאמת אישית לעיבוד מקדים כדי לוודא שהנתונים בזמן ההצגה הם בפורמט שהמודל מצפה לו. תצטרכו גם לכתוב לוגיקה מותאמת אישית לעיבוד נתונים אחרי העיבוד כדי לעגל את התחזיות ולהמיר אותן למחרוזות. כדי לכתוב את הלוגיקה הזו, תשתמשו בתרחישי חיזוי בהתאמה אישית.
מבוא לתרחישים מותאמים אישית של חיזוי
קונטיינרים מוכנים מראש של Vertex AI מטפלים בבקשות לחיזוי על ידי ביצוע פעולת החיזוי של מסגרת למידת המכונה. לפני שהיו שגרות חיזוי בהתאמה אישית, אם רציתם לבצע עיבוד מקדים של הקלט לפני החיזוי, או עיבוד פוסט של החיזוי של המודל לפני החזרת התוצאה, הייתם צריכים ליצור קונטיינר בהתאמה אישית.
כדי ליצור קונטיינר מותאם אישית להצגת מודל, צריך לכתוב שרת HTTP שעוטף את המודל שאומן, מתרגם בקשות HTTP לקלט של המודל ומתרגם את הפלט של המודל לתשובות.
באמצעות שגרות חיזוי בהתאמה אישית, מערכת Vertex AI מספקת לכם את הרכיבים שקשורים למילוי בקשות, כדי שתוכלו להתמקד במודל ובהמרות הנתונים.
4. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל. תצטרכו את זה כדי ליצור את מופע המחברת.
שלב 2: הפעלת Artifact Registry API
עוברים אל Artifact Registry ובוחרים באפשרות Enable (הפעלה) אם היא עדיין לא מסומנת. תשתמשו בזה כדי ליצור קונטיינר מותאם אישית להצגת מודעות.
שלב 3: הפעלת Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על הפעלת Vertex AI API.

שלב 4: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:

מפעילים את Notebooks API אם הוא עדיין לא מופעל.

אחרי ההפעלה, לוחצים על מופעים ואז על יצירת מופע חדש.
מאשרים את אפשרויות ברירת המחדל ולוחצים על יצירה.
כשהמופע מוכן, לוחצים על OPEN JUPYTERLAB כדי לפתוח את המופע.
5. כתיבת קוד לאימון
שלב 1: יצירת קטגוריה של אחסון בענן
תאחסנו את המודל ואת פריטי האומנות של העיבוד המקדים בקטגוריה של Cloud Storage. אם כבר יש לכם קטגוריה בפרויקט שבה אתם רוצים להשתמש, אתם יכולים לדלג על השלב הזה.
במרכז האפליקציות, פותחים סשן טרמינל חדש.

מריצים את הפקודה הבאה במסוף כדי להגדיר משתנה סביבה לפרויקט. חשוב להחליף את your-cloud-project במזהה הפרויקט:
PROJECT_ID='your-cloud-project'
לאחר מכן, מריצים את הפקודה הבאה בטרמינל כדי ליצור קטגוריה חדשה בפרויקט.
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
שלב 2: אימון המודל
בטרמינל, יוצרים ספרייה חדשה בשם cpr-codelab ועוברים אליה באמצעות הפקודה cd.
mkdir cpr-codelab
cd cpr-codelab
במנהל הקבצים והתיקיות, עוברים לספרייה החדשה cpr-codelab, ואז משתמשים במפעיל כדי ליצור מחברת חדשה של Python 3 בשם task.ipynb.

הספרייה cpr-codelab אמורה להיראות עכשיו כך:
+ cpr-codelab/
+ task.ipynb
במחברת, מדביקים את הקוד הבא.
קודם כותבים קובץ requirements.txt.
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
למודל שתפרסו יהיה סט שונה של תלות שהותקנו מראש בהשוואה לסביבת המחברת. לכן, כדאי לרשום את כל התלויות של המודל ב-requirements.txt ואז להשתמש ב-pip כדי להתקין את אותן תלויות בדיוק במחברת. בהמשך, תבדקו את המודל באופן מקומי לפני הפריסה ב-Vertex AI, כדי לוודא שהסביבות זהות.
מריצים pip install כדי להתקין את יחסי התלות במחברת.
!pip install -U --user -r requirements.txt
הערה: צריך להפעיל מחדש את הליבה אחרי שמתקינים את pip.

לאחר מכן, יוצרים את הספריות שבהן יישמרו המודל ופריטי האומנות של העיבוד המקדים.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
הספרייה cpr-codelab אמורה להיראות עכשיו כך:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
אחרי שמגדירים את מבנה הספריות, אפשר לאמן את המודל.
קודם מייבאים את הספריות.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
לאחר מכן מגדירים את המשתנים הבאים. חשוב להחליף את PROJECT_ID במזהה הפרויקט ואת BUCKET_NAME בקטגוריה שיצרתם בשלב הקודם.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
טוענים את הנתונים מהספרייה של seaborn ואז יוצרים שני פריימים של נתונים, אחד עם התכונות והשני עם התווית.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
בואו נסתכל על נתוני האימון. אפשר לראות שכל שורה מייצגת יהלום.
x_train.head()
והתוויות, שהן המחירים המתאימים.
y_train.head()
עכשיו מגדירים column transform של sklearn כדי לבצע קידוד one-hot לתכונות הקטגוריות ולשנות את קנה המידה של התכונות המספריות
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
הגדרת מודל היער האקראי
regr = RandomForestRegressor(max_depth=10, random_state=0)
לאחר מכן, יוצרים צינור עיבוד נתונים של sklearn. כלומר, הנתונים שמוזנים לפייפליין הזה יעברו קודם קידוד או שינוי קנה מידה, ואז יועברו למודל.
my_pipeline = make_pipeline(column_transform, regr)
התאמת צינור עיבוד הנתונים לנתוני האימון
my_pipeline.fit(x_train, y_train)
כדאי לנסות את המודל כדי לוודא שהוא פועל כמו שצריך. מבצעים קריאה לשיטה predict במודל ומעבירים דוגמה לבדיקה.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
עכשיו אפשר לשמור את צינור הנתונים בספרייה model_artifacts ולהעתיק אותו לקטגוריה של Cloud Storage.
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
שלב 3: שמירת ארטיפקט של עיבוד מקדים
בשלב הבא יוצרים פריט מידע שנוצר בתהליך פיתוח (Artifact) של עיבוד מקדים. הארטיפקט הזה ייטען במאגר התגים המותאם אישית כשהשרת של המודל יופעל. הארטיפקט של העיבוד המקדים יכול להיות כמעט בכל פורמט (למשל קובץ pickle), אבל במקרה הזה תכתבו מילון לקובץ JSON.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
התכונה clarity בנתוני האימון שלנו תמיד הייתה בקיצור (למשל, 'FL' במקום 'Flawless'). בזמן הצגת המודעות, אנחנו רוצים לוודא שהנתונים של התכונה הזו גם מקוצרים. הסיבה לכך היא שהמודל שלנו יודע איך לבצע קידוד one-hot של 'FL', אבל לא של 'Flawless'. תכתבו את הלוגיקה המותאמת אישית הזו לעיבוד מוקדם בהמשך. אבל בינתיים, פשוט שומרים את טבלת החיפוש הזו בקובץ JSON ואז כותבים אותה לקטגוריה של Cloud Storage.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
הספרייה המקומית cpr-codelab אמורה להיראות כך:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
6. יצירת קונטיינר מותאם אישית להצגת מודלים באמצעות שרת המודלים של CPR
אחרי שהמודל אומן והפריט שנוצר במהלך העיבוד המקדים נשמר, הגיע הזמן ליצור את קובץ ה-Docker המותאם אישית להצגת המודל. בדרך כלל, כדי ליצור קונטיינר להצגת מודל צריך לכתוב קוד של שרת מודלים. עם זאת, באמצעות שגרות חיזוי בהתאמה אישית, Vertex AI Predictions יוצר שרת מודלים ובונה בשבילכם קובץ אימג' של קונטיינר בהתאמה אישית.
מאגר תגים מותאם אישית להצגת מודעות מכיל את 3 חלקי הקוד הבאים:
- שרת מודלים (ייווצר אוטומטית על ידי ה-SDK ויאוחסן ב-
scr_dir/)- שרת HTTP שמארח את המודל
- אחראי להגדרת מסלולים/יציאות/וכו'.
- Request Handler
- אחראי על היבטים של שרת אינטרנט בטיפול בבקשה, כמו ביטול הסריאליזציה של גוף הבקשה, סריאליזציה של התגובה, הגדרת כותרות תגובה וכו'.
- בדוגמה הזו, תשתמשו ב-Handler שמוגדר כברירת מחדל,
google.cloud.aiplatform.prediction.handler.PredictionHandler, שסופק ב-SDK.
- Predictor
- אחראי ללוגיקה של למידת המכונה לעיבוד בקשת חיזוי.
אפשר להתאים אישית כל אחד מהרכיבים האלה בהתאם לדרישות של תרחיש השימוש. בדוגמה הזו, מטמיעים רק את כלי החיזוי.
המודל לחיזוי אחראי על הלוגיקה של ה-ML לעיבוד בקשת חיזוי, כמו עיבוד מקדים ועיבוד אחרי של נתונים בהתאמה אישית. כדי לכתוב לוגיקה מותאמת אישית לחיזוי, צריך ליצור מחלקת משנה של הממשק Vertex AI Predictor.
בגרסה הזו של שגרות חיזוי מותאמות אישית יש מחזים לשימוש חוזר של XGBoost ו-Sklearn, אבל אם אתם צריכים להשתמש במסגרת אחרת, אתם יכולים ליצור משלכם על ידי יצירת מחלקת משנה של המחזים הבסיסיים.
כאן אפשר לראות דוגמה ל-Sklearn predictor. זה כל הקוד שצריך לכתוב כדי לבנות את שרת המודלים המותאם אישית הזה.

במחברת, מדביקים את הקוד הבא כדי ליצור מחלקת משנה של SklearnPredictor ולכתוב אותה לקובץ Python ב-src_dir/. שימו לב שבדוגמה הזו אנחנו מתאימים אישית רק את השיטות load, preprocess ו-postprocess, ולא את השיטה predict.
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
בואו נבחן לעומק כל אחת מהשיטות האלה.
- השיטה
loadטוענת את ארטיפקט טרום העיבוד, שבמקרה הזה הוא מילון שממפה את ערכי הניקיון של היהלום לקיצורים שלהם. - השיטה
preprocessמשתמשת בארטיפקט הזה כדי לוודא שבזמן הצגת המודעה, התכונה 'בהירות' מוצגת בפורמט המקוצר שלה. אם לא, הפונקציה ממירה את המחרוזת המלאה לקיצור שלה. - השיטה
postprocessמחזירה את הערך החזוי כמחרוזת עם סימן $ ומעגלת את הערך.
לאחר מכן, משתמשים ב-Vertex AI Python SDK כדי ליצור את התמונה. באמצעות שגרות חיזוי בהתאמה אישית, ייווצר Dockerfile וייבנה אימג' בשבילכם.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
כותבים קובץ בדיקה עם שתי דוגמאות לחיזוי. באחד מהמקרים מופיע השם המקוצר של Clarity, אבל במקרה השני צריך להמיר אותו קודם.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
בודקים את הקונטיינר באופן מקומי על ידי פריסת מודל מקומי.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
תוכלו לראות את תוצאות התחזית עם:
predict_response.content
7. פריסת המודל ב-Vertex AI
אחרי שבדקתם את הקונטיינר באופן מקומי, הגיע הזמן לדחוף את התמונה אל Artifact Registry ולהעלות את המודל אל מרשם המודלים של Vertex AI.
קודם צריך להגדיר את Docker כדי לגשת ל-Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
לאחר מכן, דוחפים את התמונה.
local_model.push_image()
מעלים את המודל.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
אחרי העלאת המודל, הוא אמור להופיע במסוף:
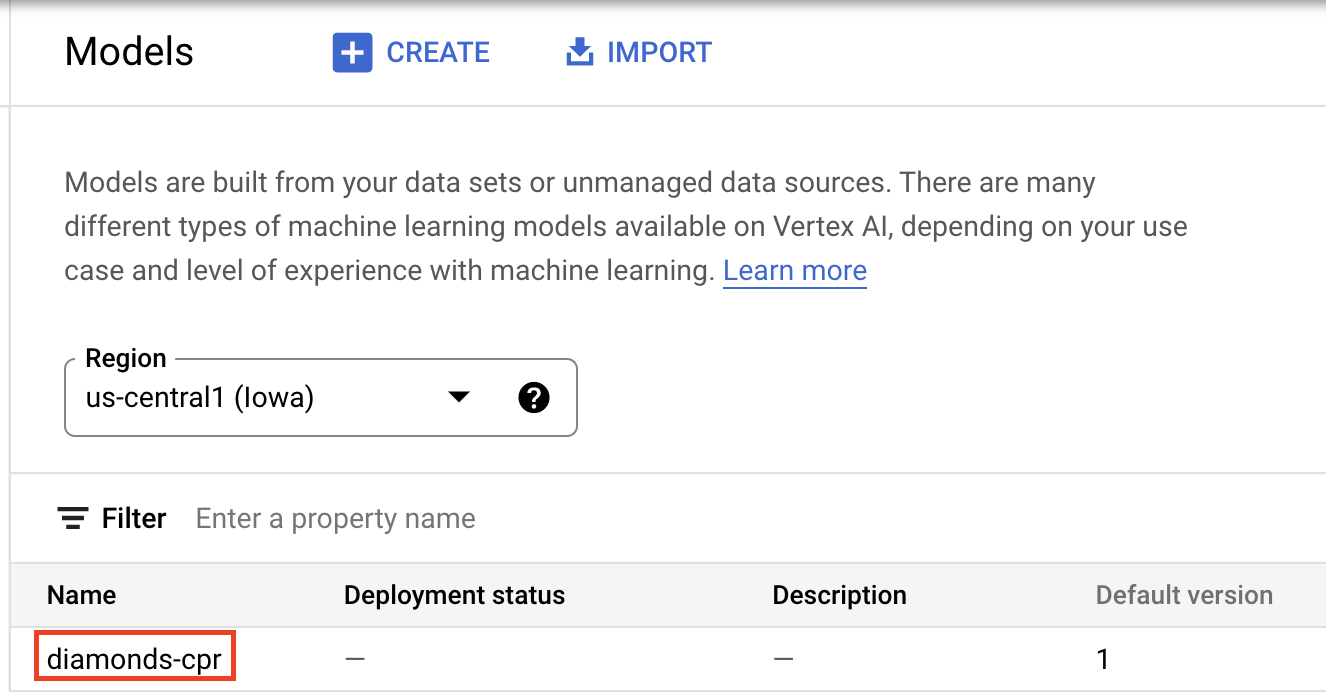
בשלב הבא, פורסים את המודל כדי שתוכלו להשתמש בו לתחזיות אונליין. שגרות מותאמות אישית של תחזיות פועלות גם עם תחזיות באצווה, כך שאם תרחיש השימוש שלכם לא דורש תחזיות אונליין, אתם לא צריכים לפרוס את המודל.
endpoint = model.deploy(machine_type="n1-standard-2")
לבסוף, בודקים את המודל שנפרס על ידי קבלת חיזוי.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI כדי:
- כתיבת לוגיקה מותאמת אישית לעיבוד מקדים ולעיבוד שלאחר מכן באמצעות שגרות חיזוי מותאמות אישית
מידע נוסף על חלקים שונים ב-Vertex AI זמין בתיעוד.
8. הסרת המשאבים
אם אתם רוצים להמשיך להשתמש ב-notebook שיצרתם בשיעור Lab הזה, מומלץ לכבות אותו כשאתם לא משתמשים בו. בממשק המשתמש של Workbench במסוף Google Cloud, בוחרים את מחברת ה-Notebook ואז בוחרים באפשרות Stop (הפסקה).
אם רוצים למחוק את המחברת לגמרי, לוחצים על הלחצן מחיקה בפינה השמאלית העליונה.

כדי למחוק את נקודת הקצה שפרסתם, עוברים לקטע Endpoints (נקודות קצה) במסוף, לוחצים על נקודת הקצה שיצרתם ובוחרים באפשרות Undeploy model from endpoint (ביטול פריסת המודל מנקודת הקצה):

כדי למחוק את קובץ האימג' של הקונטיינר, עוברים אל Artifact Registry, בוחרים את המאגר שיצרתם ולוחצים על מחיקה.

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete: