
1. Visão geral
Neste laboratório, você vai aprender a usar rotinas de previsão personalizadas na Vertex AI para escrever uma lógica de pré-processamento e pós-processamento personalizada. Embora esta amostra use o Scikit-learn, as rotinas de previsão personalizadas podem funcionar com outros frameworks de ML em Python, como XGBoost, PyTorch e TensorFlow.
Conteúdo do laboratório
Você vai aprender a:
- Escrever uma lógica de previsão personalizada com rotinas de previsão personalizadas
- Testar o contêiner e o modelo de disponibilização personalizados localmente
- Testar o contêiner de disponibilização personalizada nas previsões da Vertex AI
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$1.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos para a Vertex AI.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. O foco deste laboratório é o Predictions e o Workbench.

3. Visão geral do caso de uso
Caso de uso
Neste laboratório, você vai criar um modelo de regressão de floresta aleatória para prever o preço de um diamante com base em atributos como corte, pureza e tamanho.
Você vai escrever uma lógica de pré-processamento personalizada para verificar se os dados no momento da veiculação estão no formato esperado pelo modelo. Você também vai escrever uma lógica de pós-processamento personalizada para arredondar as previsões e convertê-las em strings. Para escrever essa lógica, você vai usar rotinas de previsão personalizadas.
Introdução às rotinas de previsão personalizadas
Os contêineres pré-criados da Vertex AI processam solicitações de previsão executando a operação de previsão do framework de machine learning. Antes das rotinas de previsão personalizadas, se você quisesse pré-processar a entrada antes da previsão ou pós-processar a previsão do modelo antes de retornar o resultado, seria necessário criar um contêiner personalizado.
Para criar um contêiner de exibição personalizado, é necessário escrever um servidor HTTP que encapsule o modelo treinado, traduza as solicitações HTTP em entradas do modelo e traduza as saídas do modelo em respostas.
Com as rotinas de previsão personalizadas, a Vertex AI fornece os componentes relacionados à disponibilização para que você possa se concentrar no modelo e nas transformações de dados.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada. Você vai precisar disso para criar sua instância de notebook.
Etapa 2: ativar a API Artifact Registry
Navegue até o Artifact Registry e selecione Ativar, se essa opção ainda não estiver ativada. Você vai usar isso para criar um contêiner de exibição personalizado.
Etapa 3: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.

Etapa 4: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":

Ative a API Notebooks, se ela ainda não tiver sido ativada.

Depois de ativar, clique em INSTÂNCIAS e selecione CRIAR NOVA.
Aceite as opções padrão e clique em Criar.
Quando a instância estiver pronta, clique em ABRIR JUPYTERLAB para abrir a instância.
5. Escrever o código de treinamento
Etapa 1: criar um bucket do Cloud Storage
Você vai armazenar o modelo e os artefatos de pré-processamento em um bucket do Cloud Storage. Se você já tiver um bucket no projeto que quer usar, pule esta etapa.
Na tela de início, abra uma nova sessão de terminal.

No terminal, execute o comando a seguir para definir uma variável de ambiente para seu projeto. Não se esqueça de substituir your-cloud-project pelo ID do projeto:
PROJECT_ID='your-cloud-project'
Depois execute o comando a seguir no terminal para criar um novo bucket no projeto:
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
Etapa 2: treinar o modelo
No terminal, crie um diretório chamado cpr-codelab e coloque cd nele.
mkdir cpr-codelab
cd cpr-codelab
No navegador de arquivos, navegue até o novo diretório cpr-codelab e use a tela de início para criar um notebook Python 3 chamado task.ipynb.

Seu diretório cpr-codelab vai ficar assim:
+ cpr-codelab/
+ task.ipynb
No notebook, cole o seguinte código.
Primeiro, escreva um arquivo requirements.txt.
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
O modelo implantado terá um conjunto diferente de dependências pré-instaladas do ambiente do notebook. Por isso, liste todas as dependências do modelo em requirements.txt e use o pip para instalar as mesmas dependências no notebook. Depois, você vai testar o modelo localmente antes de implantar na Vertex AI para verificar se os ambientes correspondem.
Instale as dependências no notebook usando o pip.
!pip install -U --user -r requirements.txt
É importante lembrar que você precisa reiniciar o kernel depois que o pip install for concluído.

Em seguida, crie os diretórios em que você vai armazenar o modelo e os artefatos de pré-processamento.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
Seu diretório cpr-codelab vai ficar assim:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
Agora que a estrutura de diretórios está configurada, é hora de treinar um modelo.
Primeiro, importe as bibliotecas.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
Em seguida, defina as variáveis a seguir. Substitua PROJECT_ID pelo ID do projeto e BUCKET_NAME pelo bucket criado na etapa anterior.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
Carregue os dados da biblioteca do Seaborn e crie dois dataframes, um com os atributos e outro com o rótulo.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
Vamos analisar os dados de treinamento. Cada linha representa um diamante.
x_train.head()
e os rótulos, que são os preços correspondentes.
y_train.head()
Agora, defina uma transformação de coluna do sklearn para codificar em one-hot os atributos categóricos e escalonar os atributos numéricos.
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
Definir o modelo de floresta aleatória
regr = RandomForestRegressor(max_depth=10, random_state=0)
Em seguida, crie um pipeline sklearn. Isso significa que os dados transmitidos para esse pipeline serão primeiro codificados/escalonados e depois transmitidos para o modelo.
my_pipeline = make_pipeline(column_transform, regr)
Ajustar o pipeline aos dados de treinamento
my_pipeline.fit(x_train, y_train)
Vamos testar o modelo para garantir que ele está funcionando como esperado. Chame o método predict no modelo, transmitindo um exemplo de teste.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
Agora podemos salvar o pipeline no diretório model_artifacts e copiá-lo para o bucket do Cloud Storage.
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Etapa 3: salvar um artefato de pré-processamento
Em seguida, crie um artefato de pré-processamento. Esse artefato será carregado no contêiner personalizado quando o servidor de modelo for iniciado. O artefato de pré-processamento pode ter quase qualquer forma (como um arquivo Pickle), mas nesse caso você gravará um dicionário em um arquivo JSON.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
O recurso clarity nos nossos dados de treinamento sempre estava na forma abreviada (ou seja, "FL" em vez de "Flawless"). No momento da disponibilização, queremos verificar se os dados desse atributo também são abreviados. Isso ocorre porque nosso modelo sabe como fazer uma codificação one-hot "FL", mas não "Flawless". Você vai escrever essa lógica de pré-processamento personalizada mais tarde. Mas, por enquanto, salve essa tabela de consulta em um arquivo JSON e, em seguida, grave-a no bucket do Cloud Storage.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Seu diretório cpr-codelab local vai ficar assim:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
6. Crie um contêiner de veiculação personalizado usando o servidor do modelo de CPR
Agora que o modelo foi treinado e o artefato de pré-processamento foi salvo, é hora de criar o contêiner de exibição personalizado. Normalmente, a criação de um contêiner de veiculação exige a gravação de código do servidor de modelo. No entanto, com rotinas de previsão personalizadas, a Vertex AI Predictions gera um servidor de modelo e cria uma imagem de contêiner personalizada para você.
Um contêiner de serviço personalizado contém os três trechos de código a seguir:
- Servidor de modelo (gerado automaticamente pelo SDK e armazenado em
scr_dir/)- Servidor HTTP que hospeda o modelo
- Responsável por configurar rotas/portas etc.
- Processador de solicitações
- Responsável pelos aspectos do servidor da Web no processamento de uma solicitação, como desserializar o corpo da solicitação e serializar a resposta, definir cabeçalhos de resposta etc.
- Neste exemplo, você vai usar o gerenciador padrão,
google.cloud.aiplatform.prediction.handler.PredictionHandler, fornecido no SDK.
- Preditor
- Responsável pela lógica de ML para processar uma solicitação de previsão.
Cada um desses componentes pode ser personalizado com base nos requisitos do seu caso de uso. Neste exemplo, você vai implementar apenas o preditor.
O preditor é responsável pela lógica de ML para processar uma solicitação de previsão, como pré e pós-processamento personalizados. Para escrever uma lógica de previsão personalizada, crie uma subclasse da interface Predictor da Vertex AI.
Esta versão de rotinas de previsão personalizadas vem com previsores XGBoost e Sklearn reutilizáveis. No entanto, se você precisar usar uma estrutura diferente, crie a sua própria usando subclasse do previsor de base.
Confira um exemplo do preditor do Sklearn abaixo. Esse é todo o código que você precisaria escrever para criar esse servidor de modelo personalizado.

No notebook, cole o código a seguir para criar uma subclasse do SklearnPredictor e gravá-la em um arquivo Python em src_dir/. Neste exemplo, estamos apenas personalizando os métodos load, preprocess e postprocess, e não o método predict.
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
Vamos analisar cada um desses métodos com mais detalhes.
- O método
loadcarrega o artefato de pré-processamento, que, neste caso, é um dicionário que mapeia os valores de pureza do diamante para as abreviações. - O método
preprocessusa esse artefato para garantir que, no momento da exibição, o recurso de clareza esteja no formato abreviado. Caso contrário, ele converte a string completa na abreviação. - O método
postprocessretorna o valor previsto como uma string com um sinal de dólar e arredonda o valor.
Em seguida, use o SDK da Vertex AI para Python para criar a imagem. Usando rotinas de previsão personalizadas, o Dockerfile será gerado e a imagem será criada para você.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
Escreva um arquivo de teste com dois exemplos para previsão. Uma das instâncias tem o nome abreviado, mas a outra precisa ser convertida primeiro.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
Teste o contêiner localmente implantando um modelo local.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
Para conferir os resultados da previsão, use:
predict_response.content
7. Implantar o modelo na Vertex AI
Agora que você testou o contêiner localmente, é hora de enviar a imagem para o Artifact Registry e fazer upload do modelo para o Vertex AI Model Registry.
Primeiro, configure o Docker para acessar o Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
Em seguida, envie a imagem.
local_model.push_image()
e faça o upload do modelo.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
Quando o modelo for enviado, ele vai aparecer no console:

Em seguida, implante o modelo para usá-lo em previsões on-line. As rotinas de previsão personalizadas também funcionam com a previsão em lote. Portanto, se seu caso de uso não exigir previsões on-line, não será necessário implantar o modelo.
endpoint = model.deploy(machine_type="n1-standard-2")
Por fim, teste o modelo implantado recebendo uma previsão.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Escrever lógica de pré-processamento e pós-processamento personalizada com rotinas de previsão personalizadas
Para saber mais sobre partes diferentes da Vertex AI, acesse a documentação.
8. Limpeza
Se você quiser continuar usando o notebook que criou neste laboratório, é recomendado que você o desligue quando não estiver usando. Na interface do Workbench no console do Google Cloud, selecione o notebook e clique em Parar.
Se quiser excluir o notebook completamente, clique no botão Excluir no canto superior direito.

Para excluir o endpoint que você implantou, acesse a seção "Endpoints" do console, clique no endpoint criado e selecione Cancelar a implantação do modelo do endpoint:
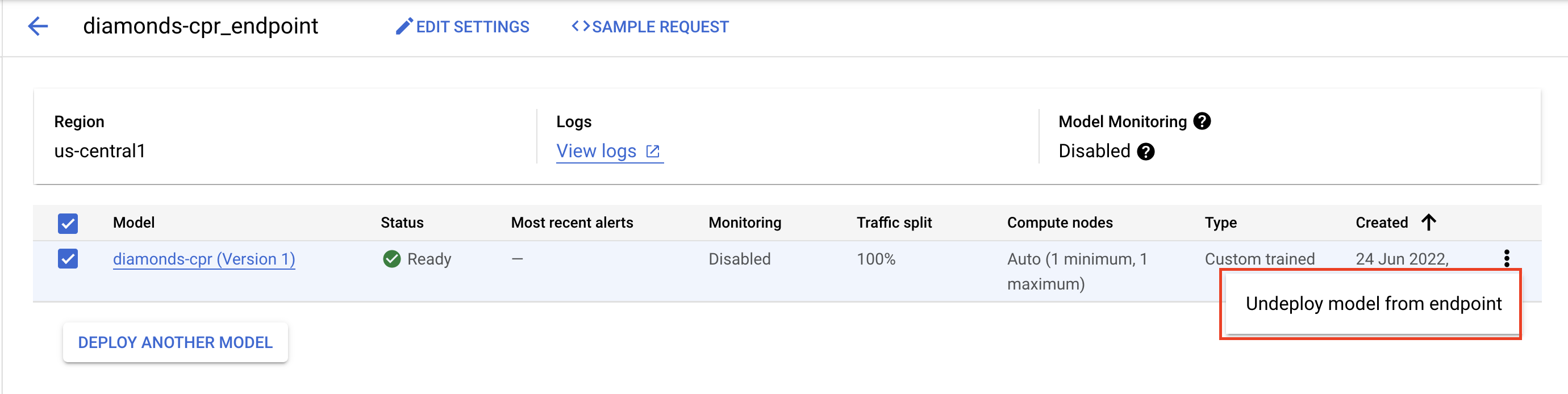
Para excluir a imagem do contêiner, navegue até o Artifact Registry, selecione o repositório que você criou e clique em Excluir.

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em Excluir:
