
1. 概要
このラボでは、Vertex AI でカスタム予測ルーチンを使用して、カスタムの前処理ロジックと後処理ロジックを作成する方法を学びます。このサンプルでは Scikit-learn を使用しますが、カスタム予測ルーチンは XGBoost、PyTorch、TensorFlow などの他の Python ML フレームワークでも使用できます。
学習内容
次の方法を学習します。
- カスタム予測ルーチンを使用してカスタム予測ロジックを作成する
- カスタム サービング コンテナとモデルをローカルでテストする
- Vertex AI Predictions でカスタム サービング コンテナをテストする
Google Cloud でこのラボを実行するための総費用は約 $1 USD です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルにそれぞれ個別のサービスを介してアクセスする必要がありましたが、Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API へと結合します。既存のプロジェクトを Vertex AI に移行することもできます。
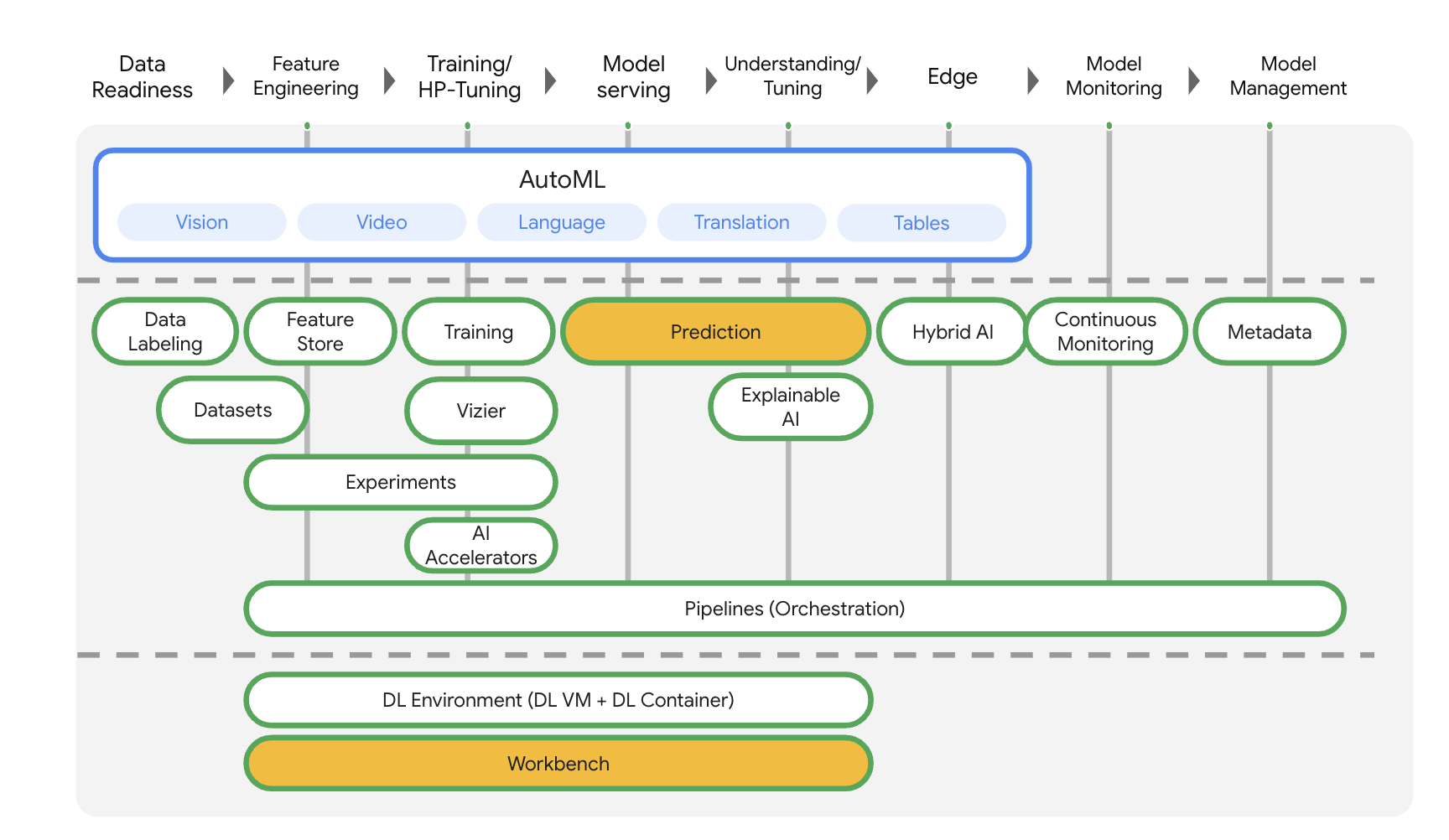
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、Predictions と Workbench を中心に説明します。
3. ユースケースの概要
ユースケース
このラボでは、カット、透明度、サイズなどの属性に基づいてダイヤモンドの価格を予測するランダム フォレスト回帰モデルを構築します。
カスタムの前処理ロジックを作成して、サービング時のデータがモデルで想定される形式であることを確認します。また、カスタムの後処理ロジックを作成して、予測を丸めて文字列に変換します。このロジックを作成するには、カスタム予測ルーチンを使用します。
カスタム予測ルーチンの概要
Vertex AI の事前構築済みコンテナによって、機械学習フレームワークの予測オペレーションを実行することで予測リクエストが処理されます。カスタム予測ルーチンが登場する前は、予測の実行前に入力を前処理したり、結果を返す前にモデルの予測を後処理したりする場合、カスタム コンテナを構築する必要がありました。
カスタム サービング コンテナを構築するには、トレーニング済みモデルのラップ、HTTP リクエストからモデル入力への変換、モデル出力から応答への変換を行う HTTP サーバーを記述する必要があります。
カスタム予測ルーチンでは Vertex AI によってサービング関連コンポーネントが提供されるため、モデルとデータの変換に集中できます。
4. 環境の設定
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
ステップ 1: Compute Engine API を有効にする
Compute Engine に移動し、まだ有効になっていない場合は [有効にする] を選択します。これはノートブック インスタンスを作成するために必要です。
ステップ 2: Artifact Registry API を有効にする
まだ有効になっていない場合は、[Artifact Registry] に移動して [**有効にする**] を選択します。これは、カスタム サービング コンテナを作成するために使用します。
ステップ 3: Vertex AI API を有効にする
Cloud コンソールの [Vertex AI] セクションに移動し、[Vertex AI API を有効にする] をクリックします。

ステップ 4: Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。

Notebooks API をまだ有効にしていない場合は、有効にします。
有効にしたら、[**インスタンス**] をクリックし、[**新規作成**] を選択します。
デフォルトのオプションをそのまま使用して、[作成] をクリックします。
インスタンスの準備ができたら、[JUPYTERLAB を開く] をクリックしてインスタンスを開きます。
5. トレーニング コードを作成する
ステップ 1: Cloud Storage バケットを作成する
モデルと前処理アーティファクトを Cloud Storage バケットに保存します。使用するバケットがプロジェクトにすでにある場合は、このステップをスキップできます。
ランチャーから新しいターミナル セッションを開きます。

ターミナルで以下のように実行して、プロジェクトの環境変数を定義します。その際、your-cloud-project は実際のプロジェクト ID で置き換えてください。
PROJECT_ID='your-cloud-project'
次に、ターミナルで次のコマンドを実行して、プロジェクトに新しいバケットを作成します。
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
ステップ 2: モデルをトレーニングする
ターミナルで、cpr-codelab という新しいディレクトリを作成し、そのディレクトリに移動します。
mkdir cpr-codelab
cd cpr-codelab
ファイル ブラウザで、新しい cpr-codelab ディレクトリに移動し、ランチャーを使用して task.ipynb という新しい Python 3 ノートブックを作成します。
cpr-codelab ディレクトリは次のようになります。
+ cpr-codelab/
+ task.ipynb
ノートブックに次のコードを貼り付けます。
まず、requirements.txt ファイルを作成します。
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
デプロイするモデルには、ノートブック環境とは異なる依存関係が事前にインストールされています。 そのため、モデルのすべての依存関係を requirements.txt にリストし、pip を使用してノートブックにまったく同じ依存関係をインストールします。後で、Vertex AI にデプロイする前にモデルをローカルでテストして、環境が一致していることを再確認します。
pip を使用して、ノートブックに依存関係をインストールします。
!pip install -U --user -r requirements.txt
pip のインストールが完了したら、カーネルを再起動する必要があります。

次に、モデルと前処理アーティファクトを保存するディレクトリを作成します。
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
cpr-codelab ディレクトリは次のようになります。
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
ディレクトリ構造が設定されたので、モデルをトレーニングしましょう。
まず、ライブラリをインポートします。
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
次に、次の変数を定義します。PROJECT_ID は実際のプロジェクト ID に置き換え、BUCKET_NAME は前のステップで作成したバケットに置き換えます。
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
Seaborn ライブラリからデータを読み込み、2 つのデータフレーム(1 つは特徴付き、もう 1 つはラベル付き)を作成します。
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
トレーニング データを見てみましょう。各行はダイヤモンドを表しています。
x_train.head()
ラベルは対応する価格です。
y_train.head()
次に、sklearn 列変換をワンホット エンコーディングのカテゴリ特徴量に変換するように定義し、数値特徴をスケーリングします。
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
ランダム フォレスト モデルを定義します。
regr = RandomForestRegressor(max_depth=10, random_state=0)
次に、sklearn パイプラインを作成します。つまり、このパイプラインに供給されるデータは、最初にエンコード/スケーリングされ、次にモデルに渡されます。
my_pipeline = make_pipeline(column_transform, regr)
トレーニング データにパイプラインを適合させます。
my_pipeline.fit(x_train, y_train)
モデルを試して、想定どおりに動作していることを確認しましょう。モデルで predict メソッドを呼び出して、テストサンプルを渡します。
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
これで、パイプラインを model_artifacts ディレクトリに保存し、Cloud Storage バケットにコピーできます。
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
ステップ 3: 前処理アーティファクトを保存する
次に、前処理アーティファクトを作成します。このアーティファクトは、モデルサーバーの起動時にカスタム コンテナに読み込まれます。前処理アーティファクトは、ほぼすべての形式(pickle ファイルなど)にできますが、この場合は、JSON ファイルにディクショナリを書き込みます。
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
トレーニング データの clarity 特徴は、常に省略形式(「Flawless」ではなく「FL」など)でした。サービス提供時に、この機能のデータも省略されていることを確認します。モデルは「FL」をワンホット エンコードする方法を認識していますが、「Flawless」は認識していないことが要因です。このカスタム前処理ロジックは後で記述します。ここでは、このルックアップ テーブルを JSON ファイルに保存してから、Cloud Storage バケットに書き込みます。
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
ローカルの cpr-codelab ディレクトリは次のようになります。
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
6. CPR モデルサーバーを使用してカスタム サービング コンテナを構築する
モデルのトレーニングが完了し、 と前処理アーティファクトが保存されたので、カスタム サービング コンテナを構築します。通常、サービング コンテナを構築するには、モデルサーバー コードを記述する必要があります。ただし、カスタム予測ルーチンを使用すると、Vertex AI Predictions がモデルサーバーを生成し、カスタム コンテナ イメージを構築します。
カスタム サービング コンテナには、次の 3 つのコードが含まれています。
- モデルサーバー(SDK によって自動的に生成され、
scr_dir/に保存されます)- モデルをホストする HTTP サーバー
- ルート / ポートなどの設定を担当します。
- リクエスト ハンドラ
- リクエスト本文のデシリアライズ、レスポンスのシリアライズ、レスポンス ヘッダーの設定など、リクエストの処理のウェブサーバーの側面を担当します。
- この例では、SDK で提供されているデフォルトのハンドラ
google.cloud.aiplatform.prediction.handler.PredictionHandlerを使用します。
- 予測子
- 予測リクエストを処理するための ML ロジックを担当します。
これらの各コンポーネントは、ユースケースの要件に基づいてカスタマイズできます。この例では、予測子のみを実装します。
予測子は、カスタムの前処理や後処理など、予測リクエストを処理するための ML ロジックを担当します。カスタム予測ロジックを記述するには、Vertex AI Predictor インターフェースをサブクラス化します。
カスタム予測ルーチンの今回のリリースには再利用可能な XGBoost 予測子と Sklearn 予測子が用意されていますが、別のフレームワークを使用する必要がある場合は、ベース予測子をサブクラス化することで独自の予測子を作成できます。
以下に Sklearn 予測子 の例を示します。このカスタム モデル サーバーを構築するために記述する必要があるコードはこれだけです。

ノートブックに次のコードを貼り付けて実行し、SklearnPredictor をサブクラス化して、src_dir/ の Python ファイルに書き込みます。この例では、predict メソッドではなく、load、preprocess、postprocess メソッドのみをカスタマイズしています。
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
これらの各メソッドについて詳しく見ていきましょう。
loadメソッドは、前処理アーティファクトを読み込みます。このアーティファクトは、ダイヤモンドの透明度の値をその略語にマッピングするディクショナリです。preprocessメソッドは、そのアーティファクトを使用して、サービング時に透明度の特徴が省略形式であることを確認します。そうでない場合は、完全な文字列を省略形に変換します。postprocessメソッドは、予測値を $ 記号付きの文字列として返し、値を丸めます。
次に、Vertex AI Python SDK を使用してイメージをビルドします。カスタム予測ルーチンを使用すると、Dockerfile が生成され、イメージがビルドされます。
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
予測用の 2 つのサンプルを含むテストファイルを作成します。一方のインスタンスには明瞭な略称が使われていますが、もう一方のインスタンスは最初に変換する必要があります。
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
ローカルモデルをデプロイして、コンテナをローカルでテストします。
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
予測結果は、次のコマンドで確認できます。
predict_response.content
7. モデルを Vertex AI にデプロイする
コンテナをローカルでテストしたので、次はイメージを Artifact Registry に push し、モデルを Vertex AI Model Registry にアップロードします。
まず、Artifact Registry にアクセスできるように Docker を構成します。
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
次に、イメージを push します。
local_model.push_image()
モデルをアップロードします。
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
モデルのアップロードが完了すると、コンソールに表示されます。

次に、モデルをデプロイして、オンライン予測に使用できるようにします。カスタム予測ルーチンはバッチ予測でも機能するため、ユースケースでオンライン予測が必要ない場合は、モデルをデプロイする必要はありません。
endpoint = model.deploy(machine_type="n1-standard-2")
最後に、予測を取得して、デプロイされたモデルをテストします。
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
お疲れさまでした🎉
Vertex AI を使って次のことを行う方法を学びました。
- カスタム予測ルーチンを使用してカスタムの前処理ロジックと後処理ロジックを作成する
Vertex AI のさまざまな機能の詳細については、こちらの ドキュメントをご覧ください。
8. クリーンアップ
このラボで作成したノートブックを引き続き使用する場合は、未使用時にオフにすることをおすすめします。Google Cloud コンソールの Workbench UI で、ノートブックを選択して [停止] をクリックします。
ノートブックを完全に削除する場合は、右上にある [削除] ボタンをクリックします。

デプロイしたエンドポイントを削除するには、コンソールの [エンドポイント] セクションに移動し、作成したエンドポイントをクリックして、[エンドポイントからモデルのデプロイを解除] を選択します。

コンテナ イメージを削除するには、Artifact Registry に移動し、作成したリポジトリを選択して [削除] を選択します。

ストレージ バケットを削除するには、Cloud コンソールのナビゲーション メニューで [ストレージ] に移動してバケットを選択し、[**削除**] をクリックします。
