
1. 概要
このラボでは、Vertex AI Workbench を使用してノートブックの実行を構成して起動する方法について学習します。
学習内容
次の方法を学習します。
- ノートブックでパラメータを使用する
- Vertex AI Workbench UI からノートブックの実行を構成して起動する
このラボを Google Cloud で実行するための総費用は約 $2 です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルにそれぞれ個別のサービスを介してアクセスする必要がありましたが、Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API にまとめます。既存のプロジェクトを Vertex AI に移行することもできます。ご意見やご質問がありましたら、サポートページからお寄せください。
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、Vertex AI Workbench に焦点を当てます。
Vertex AI Workbench は、データサービス(Dataproc、Dataflow、BigQuery、Dataplex など)や Vertex AI との緊密なインテグレーションを通じて、ノートブック ベースのエンドツーエンドのワークフローをすばやく構築するのに便利です。データ サイエンティストは Vertex AI Workbench を使用して、GCP データサービスへの接続、データセットの分析、各種モデリング手法のテスト、トレーニング済みモデルの本番環境へのデプロイ、モデル ライフサイクルを通した MLOps の管理を行うことができます。
3. ユースケースの概要
このラボでは、転移学習を使用して、DeepWeeds データセットを TensorFlow Datasets から取得し、画像分類モデルをトレーニングします。TensorFlow Hub を使用して、ImageNet ベンチマーク データセットで事前トレーニングされた ResNet50、Inception、MobileNet などのさまざまなモデル アーキテクチャから抽出された特徴ベクトルを試します。Vertex AI Workbench UI を介してノートブック Executor を活用することで、これらの事前トレーニング済みモデルを使用するジョブを Vertex AI Training で起動し、最後のレイヤを再トレーニングして DeepWeeds データセットのクラスを認識します。
4. 環境の設定
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
ステップ 1: Compute Engine API を有効にする
[Compute Engine] に移動して、まだ有効になっていない場合は [**有効にする**] を選択します。
ステップ 2: Vertex AI API を有効にする
Cloud コンソールの [Vertex AI] セクションに移動し、[**Vertex AI API を有効にする**] をクリックします。

ステップ 3: Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。

Notebooks API をまだ有効にしていない場合は、有効にします。

有効にしたら、[マネージド ノートブック] をクリックします。

[新しいノートブック] を選択します。

ノートブックに名前を付けて、[詳細設定] をクリックします。

[詳細設定] で、アイドル状態でのシャットダウンを有効にして、シャットダウンまでの時間(分)を 60 に設定します。これにより、使用されていないノートブックが自動的にシャットダウンされるため、不要なコストが発生しません。

詳細設定のその他の設定はそのままで構いません。
[作成] をクリックします。
インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

新しいインスタンスを初めて使用するときに、認証が求められます。

Vertex AI Workbench には、TensorFlow、PySpark、R などのカーネルを 1 つのノートブック インスタンスから起動できるコンピューティング互換レイヤがあります。認証後、ランチャーから使用するノートブックのタイプを選択できます。
このラボでは、TensorFlow 2 カーネルを選択します。

5. トレーニング コードを作成する
DeepWeeds データセットは、オーストラリア原産の 8 種類の雑草を撮影した 17,509 枚の画像で構成されています。このセクションでは、DeepWeeds データセットを前処理し、TensorFlow Hub からダウンロードした特徴ベクトルを使用して画像分類モデルを構築してトレーニングするコードを作成します。
次のコード スニペットをノートブックのセルにコピーする必要があります。セルの実行は省略可能です。
ステップ 1: データセットをダウンロードして前処理する
まず、TensorFlow データセットの nightly バージョンをインストールして、DeepWeeds データセットの最新バージョンを取得していることを確認します。
!pip install tfds-nightly
次に、必要なライブラリをインポートします。
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
TensorFlow Datasets からデータをダウンロードし、クラス数とデータセット サイズを抽出します。
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
画像データを 255 でスケーリングする前処理関数を定義します。
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds データセットには、トレーニング用と検証用の分割はありません。トレーニング データセットのみが付属しています。次のコードでは、そのデータの 80% をトレーニングに使用し、残りの 20% を検証に使用します。
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
ステップ 2: モデルを作成する
トレーニング データセットと検証データセットを作成したので、モデルを構築する準備ができました。TensorFlow Hub には、最上位の分類レイヤのない事前トレーニング済みモデルである特徴ベクトルが用意されています。事前トレーニング済みモデルを hub.KerasLayer でラップして特徴抽出器を作成します。これは TensorFlow SavedModel を Keras レイヤとしてラップします。次に、分類レイヤを追加し、Keras Sequential API を使用してモデルを作成します。
まず、パラメータ feature_extractor_model を定義します。これは、モデルのベースとして使用する TensorFlow Hub 特徴ベクトルの名前です。
feature_extractor_model = "inception_v3"
次に、このセルをパラメータ セルにします。これにより、実行時に feature_extractor_model の値を渡すことができます。
まず、セルを選択し、右側のパネルのプロパティ インスペクタをクリックします。

タグは、ノートブックにメタデータを追加する簡単な方法です。[タグを追加] ボックスに「parameters」と入力し、Enter キーを押します。後で実行を構成する際に、テストするさまざまな値(この場合は TensorFlow Hub モデル)を渡します。ノートブック Executor がパラメータ化するセルを認識する方法であるため、「parameters」という単語を入力する必要があります(他の単語は使用できません)。
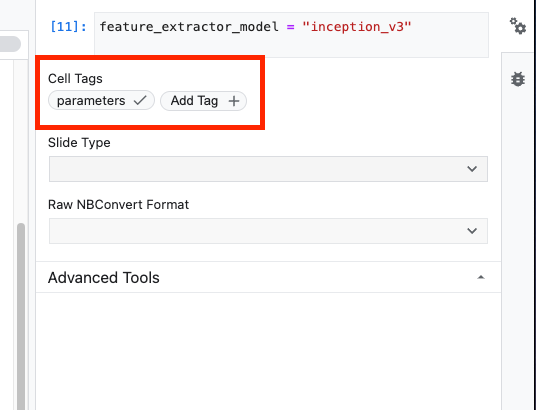
ダブル歯車アイコンをもう一度クリックすると、プロパティ インスペクタを閉じることができます。
新しいセルを作成し、tf_hub_uri を定義します。ここでは、文字列補間を使用して、ノートブックの特定の実行のベースモデルとして使用する事前トレーニング済みモデルの名前を代入します。デフォルトでは、feature_extractor_model は "inception_v3" に設定されていますが、有効な値は "resnet_v2_50" または "mobilenet_v1_100_224" です。その他のオプションについては、TensorFlow Hub カタログをご覧ください。
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
次に、hub.KerasLayer を使用して特徴抽出器を作成し、上記で定義した tf_hub_uri を渡します。trainable=False 引数を設定して変数をフリーズします。これにより、トレーニングでは最上位に追加する新しい分類子レイヤのみが変更されます。
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
モデルを完成させるには、特徴抽出器レイヤを tf.keras.Sequential モデルでラップし、分類用の 全結合レイヤ を追加します。この分類ヘッドのユニット数は、データセット内のクラス数と同じにする必要があります。
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
最後に、モデルをコンパイルして適合させます。
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. ノートブックを実行する
ノートブックの上部にある [Executor] アイコンをクリックします。

ステップ 1: トレーニング ジョブを構成する
実行に名前を付け、プロジェクトにストレージ バケットを指定します。

マシンタイプを [4 個の CPU、15 GB の RAM] に設定します。
1 個の NVIDIA GPU を追加します。
環境を TensorFlow Enterprise 2.6(GPU)に設定します。
[1 回だけの実行] を選択します。
ステップ 2: パラメータを構成する
[詳細設定] プルダウンをクリックして、パラメータを設定します。ボックスに「feature_extractor_model=resnet_v2_50」と入力します。これにより、ノートブックでこのパラメータに設定したデフォルト値 inception_v3 が resnet_v2_50 でオーバーライドされます。

[デフォルトのサービス アカウントを使用する] ボックスはオンのままにしておきます。
[送信] をクリックします。
ステップ 3: 結果を確認する
コンソール UI の [実行] タブで、ノートブックの実行ステータスを確認できます。

実行名をクリックすると、ノートブックが実行されている Vertex AI Training ジョブに移動します。

ジョブが完了したら、[VIEW RESULT] をクリックして出力ノートブックを表示できます。

出力ノートブックでは、feature_extractor_model の値が実行時に渡した値で上書きされていることがわかります。

お疲れさまでした🎉
Vertex AI Workbench を使って次のことを行う方法を学びました。
- ノートブックでパラメータを使用する
- Vertex AI Workbench UI からノートブックの実行を構成して起動する
Vertex AI のさまざまな機能の詳細については、こちらの ドキュメントをご覧ください。
7. クリーンアップ
デフォルトでは、マネージド ノートブックは 180 分間操作がないと自動的にシャットダウンされます。インスタンスを手動でシャットダウンする場合は、コンソールで [Vertex AI Workbench] セクションにある [停止] ボタンをクリックします。ノートブックを完全に削除する場合は、[削除] ボタンをクリックします。

ストレージ バケットを削除するには、Cloud Console のナビゲーション メニューで [ストレージ] を移動してバケットを選択し、[削除] をクリックします。
