
1. 概览
在本实验中,您将学习如何使用 Vertex AI Workbench 配置和启动笔记本执行。
学习内容
您将了解如何:
- 在笔记本中使用参数
- 通过 Vertex AI Workbench 界面配置和启动笔记本执行
在 Google Cloud 上运行此实验的总费用约为 2 美元 。
2. Vertex AI 简介
本实验使用的是 Google Cloud 上提供的最新 AI 产品。Vertex AI 将整个 Google Cloud 的机器学习产品集成到无缝的开发体验中。以前,使用 AutoML 训练的模型和自定义模型是通过不同的服务访问的。现在,该新产品与其他新产品一起将这两种模型合并到一个 API 中。您还可以将现有项目迁移到 Vertex AI。如果您有任何反馈,请参阅支持页面。
Vertex AI 包含许多不同的产品,可支持端到端机器学习工作流。本实验将重点介绍 Vertex AI Workbench。
Vertex AI Workbench 通过与数据服务(例如 Dataproc、Dataflow、BigQuery 和 Dataplex)和 Vertex AI 的深度集成,帮助用户快速构建基于笔记本的端到端工作流。它使数据科学家能够连接到 GCP 数据服务、分析数据集、尝试不同的建模技术、将训练的模型部署到生产环境,并通过模型生命周期管理 MLOps。
3. 用例概览
在本实验中,您将使用迁移学习在 DeepWeeds 数据集中的 TensorFlow 数据集上训练图片分类模型。您将使用 TensorFlow Hub 尝试从不同模型架构(例如 ResNet50、Inception 和 MobileNet)提取的特征向量,所有这些模型都在 ImageNet 基准数据集上进行了预训练。通过 Vertex AI Workbench 界面利用笔记本执行程序,您将在 Vertex AI Training 上启动作业,这些作业使用这些预训练模型并重新训练最后一层,以识别 DeepWeeds 数据集中的类别。
4. 设置您的环境
您需要一个启用了结算功能的 Google Cloud Platform 项目才能运行此 Codelab。如需创建项目,请按照此处的说明操作。
第 1 步:启用 Compute Engine API
前往 Compute Engine,然后选择 启用 (如果尚未启用)。
第 2 步:启用 Vertex AI API
前往 Cloud Console 的 Vertex AI 部分,然后点击 启用 Vertex AI API。

第 3 步:创建 Vertex AI Workbench 实例
在 Cloud Console 的 Vertex AI 部分中,点击“Workbench”:

启用 Notebooks API(如果尚未启用)。

启用后,点击代管式笔记本:

然后选择新建笔记本。

为您的笔记本命名,然后点击高级设置。

在“高级设置”下,启用空闲关闭,并将分钟数设置为 60。这意味着,您的笔记本处于未使用状态时会自动关闭,以免产生不必要的费用。

您可以保留所有其他高级设置。
接下来,点击创建 。
创建实例后,选择打开 JupyterLab 。

首次使用新实例时,系统会要求您进行身份验证。

Vertex AI Workbench 具有计算兼容性层,可让您从单个笔记本实例启动 TensorFlow、PySpark、R 等内核。进行身份验证后,您将能够从启动器中选择要使用的笔记本类型。
在本实验中,选择 TensorFlow 2 内核。

5. 编写训练代码
DeepWeeds 数据集包含 17,509 张图片,这些图片捕捉了澳大利亚特有的八种不同杂草。在本部分中,您将编写代码来预处理 DeepWeeds 数据集,并使用从 TensorFlow Hub 下载的特征向量构建和训练图片分类模型。
您需要将以下代码段复制到笔记本的单元中。执行单元是可选操作。
第 1 步:下载和预处理数据集
首先,安装 TensorFlow 数据集的 Nightly 版本,以确保我们获取的是最新版本的 DeepWeeds 数据集。
!pip install tfds-nightly
然后,导入必要的库:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
从 TensorFlow Datasets 下载数据,并提取类别数和数据集大小。
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
定义预处理函数,以将图片数据缩放 255 倍。
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds 数据集不包含训练/验证拆分。它仅包含训练数据集。在下面的代码中,您将使用 80% 的数据进行训练,其余 20% 的数据用于验证。
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
第 2 步:创建模型
现在,您已创建训练和验证数据集,可以构建模型了。TensorFlow Hub 提供特征向量,这些向量是不包含顶级分类层的预训练模型。您将通过使用 hub.KerasLayer 封装预训练模型来创建特征提取器,该提取器会将 TensorFlow SavedModel 封装为 Keras 层。然后,您将添加分类层并使用 Keras Sequential API 创建模型。
首先,定义参数 feature_extractor_model,它是您将用作模型基础的 TensorFlow Hub 特征向量的名称。
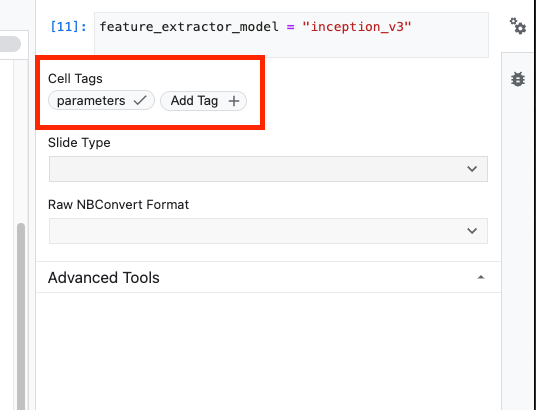
feature_extractor_model = "inception_v3"
接下来,您将此单元格设为参数单元格,这样您就可以在运行时传入 feature_extractor_model 的值。
首先,选择单元格,然后点击右侧面板中的属性检查器。

标记是一种向笔记本添加元数据的简单方法。在“添加标记”框中输入“parameters”,然后按 Enter 键。稍后在配置执行时,您将传入不同的值,在本例中,您要测试 TensorFlow Hub 模型。请注意,您必须输入“parameters”一词(而不是任何其他字词),因为笔记本执行程序就是通过这种方式知道要对哪些单元格进行参数化。
您可以再次点击双齿轮图标来关闭属性检查器。
创建一个新单元格并定义 tf_hub_uri,您将在其中使用字符串插值来替换要用作笔记本特定执行的基础模型的预训练模型的名称。默认情况下,您已将 feature_extractor_model 设置为 "inception_v3",但其他有效值为 "resnet_v2_50" 或 "mobilenet_v1_100_224"。您可以在 TensorFlow Hub 目录 中探索其他选项。
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
接下来,使用 hub.KerasLayer 创建特征提取器,并传入您在上面定义的 tf_hub_uri。将 trainable=False 实参设置为冻结变量,以便训练仅修改您将在顶部添加的新分类器层。
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
如需完成模型,请将特征提取器层封装在 tf.keras.Sequential 模型中,并添加一个 全连接层 用于分类。此分类头中的单元数应等于数据集中的类别数:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
最后,编译并拟合模型。
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. 执行笔记本
点击笔记本顶部的执行程序 图标。

第 1 步:配置训练作业
为执行命名,并在项目中提供存储分区。

将机器类型设置为 4 个 CPU,15 GB RAM 。
并添加 1 个 NVIDIA GPU 。
将环境设置为 TensorFlow Enterprise 2.6 (GPU)。
选择“一次性执行”。
第 2 步:配置参数
点击 ADVANCED OPTIONS (高级选项)下拉菜单以设置参数。在框中,输入 feature_extractor_model=resnet_v2_50。这会将您在笔记本中为此参数设置的默认值 inception_v3 替换为 resnet_v2_50。

您可以选中使用默认服务账号 框。
然后点击提交
第 3 步:检查结果
在控制台界面中的“执行”标签页中,您将能够看到笔记本执行的状态。

如果您点击执行名称,系统会将您转到笔记本正在运行的 Vertex AI Training 作业。

作业完成后,您可以通过点击查看结果 来查看输出笔记本。

在输出笔记本中,您将看到 feature_extractor_model 的值被您在运行时传入的值覆盖。

🎉 恭喜!🎉
您学习了如何使用 Vertex AI Workbench 执行以下操作:
- 在笔记本中使用参数
- 通过 Vertex AI Workbench 界面配置和启动笔记本执行
如需详细了解 Vertex AI 的不同部分,请参阅相关文档。
7. 清理
默认情况下,代管式笔记本会在闲置 180 分钟后自动关闭。如果您要手动关停实例,请点击控制台的 Vertex AI Workbench 部分中的“停止”按钮。如果您想完全删除该笔记本,请点击“删除”按钮。

如需删除存储桶,请使用 Cloud Console 中的导航菜单,浏览到“存储空间”,选择您的存储桶,然后点击“删除”:
