
1. Présentation
Dans cet atelier, vous allez apprendre à configurer et lancer des exécutions de notebook avec Vertex AI Workbench.
Objectifs
Vous allez apprendre à effectuer les opérations suivantes :
- Utiliser des paramètres dans un notebook
- Configurer et lancer des exécutions de notebook à partir de l'interface utilisateur de Vertex AI Workbench
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 2$.
2. Présentation de Vertex AI
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles depuis des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI. Pour envoyer un commentaire, consultez la page d'assistance.
Vertex AI comprend de nombreux produits différents qui permettent de gérer les workflows de ML de bout en bout. Cet atelier se concentre sur Vertex AI Workbench.
Vertex AI Workbench permet aux utilisateurs de créer rapidement des workflows de bout en bout basés sur des notebooks, grâce à une intégration approfondie avec des services de données (Dataproc, Dataflow, BigQuery, Dataplex, etc.) et Vertex AI. Cette solution permet aux data scientists de se connecter aux services de données GCP, d'analyser des ensembles de données, de tester différentes techniques de modélisation, de déployer des modèles entraînés en production et de gérer les MLOps tout au long du cycle de vie des modèles.
3. Présentation du cas d'utilisation
Dans cet atelier, vous allez utiliser l'apprentissage par transfert pour entraîner un modèle de classification d'images sur l'ensemble de données DeepWeeds à partir d'ensembles de données TensorFlow. Vous utiliserez TensorFlow Hub pour tester les vecteurs de caractéristiques extraits de différentes architectures de modèles, telles que ResNet50, Inception et MobileNet, tous pré-entraînés sur l'ensemble de données de référence ImageNet. En exploitant l'exécuteur de notebook via l'interface utilisateur de Vertex AI Workbench, vous lancerez des jobs sur Vertex AI Training qui utilisent ces modèles pré-entraînés et réentraîneront la dernière couche pour reconnaître les classes de l'ensemble de données DeepWeeds.
4. Configurer votre environnement
Pour suivre cet atelier de programmation, vous aurez besoin d'un projet Google Cloud Platform dans lequel la facturation est activée. Pour créer un projet, suivez ces instructions.
Étape 1 : Activez l'API Compute Engine
Accédez à Compute Engine et cliquez sur Activer si ce n'est pas déjà fait.
Étape 2 : Activez l'API Vertex AI
Accédez à la section Vertex AI de Cloud Console, puis cliquez sur Activer l'API Vertex AI.

Étape 3 : créez une instance Vertex AI Workbench
Dans la section Vertex AI de Cloud Console, cliquez sur Workbench :

Activez l'API Notebooks si ce n'est pas déjà fait.

Une fois l'API activée, cliquez sur NOTEBOOKS GÉRÉS :

Sélectionnez ensuite NOUVEAU NOTEBOOK.

Attribuez un nom à votre notebook, puis cliquez sur Paramètres avancés.

Sous "Paramètres avancés", activez l'arrêt en cas d'inactivité et définissez le nombre de minutes sur 60. Cela entraîne l'arrêt automatique du notebook lorsqu'il n'est pas utilisé. Vous ne payez donc pas de frais inutiles.

Vous pouvez conserver tous les autres paramètres avancés tels quels.
Cliquez ensuite sur Créer.
Une fois l'instance créée, sélectionnez Ouvrir JupyterLab.

La première fois que vous utilisez une nouvelle instance, vous êtes invité à vous authentifier.

Vertex AI Workbench dispose d'une couche de compatibilité de calcul qui vous permet de lancer des kernels pour TensorFlow, PySpark, R, etc., le tout à partir d'une seule instance de notebook. Après l'authentification, vous pourrez sélectionner le type de notebook que vous souhaitez utiliser à partir du lanceur.
Pour cet atelier, sélectionnez le kernel TensorFlow 2.

5. Rédiger le code d'entraînement
L'ensemble de données DeepWeeds comprend 17 509 images représentant huit espèces de mauvaises herbes différentes originaires d'Australie. Dans cette section, vous allez écrire le code pour prétraiter l'ensemble de données DeepWeeds, puis créer et entraîner un modèle de classification d'images à l'aide de vecteurs de caractéristiques téléchargés depuis TensorFlow Hub.
Vous devez copier les extraits de code suivants dans les cellules de votre notebook. L'exécution des cellules est facultative.
Étape 1 : Télécharger et prétraiter l'ensemble de données
Commencez par installer la version nightly des ensembles de données TensorFlow pour vous assurer d'obtenir la dernière version de l'ensemble de données DeepWeeds.
!pip install tfds-nightly
Importez ensuite les bibliothèques nécessaires :
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Téléchargez les données à partir d'ensembles de données TensorFlow et extrayez le nombre de classes et la taille de l'ensemble de données.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Définissez une fonction de prétraitement pour mettre à l'échelle les données d'image par 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
L'ensemble de données DeepWeeds n'est pas fourni avec des divisions d'entraînement/de validation. Il n'est fourni qu'avec un ensemble de données d'entraînement. Dans le code ci-dessous, vous utiliserez 80 % de ces données pour l'entraînement et les 20 % restants pour la validation.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Étape 2 : Créer un modèle
Maintenant que vous avez créé des ensembles de données d'entraînement et de validation, vous êtes prêt à créer votre modèle. TensorFlow Hub fournit des vecteurs de caractéristiques, qui sont des modèles pré-entraînés sans la couche de classification supérieure. Vous allez créer un extracteur de caractéristiques en encapsulant le modèle pré-entraîné avec hub.KerasLayer, qui encapsule un modèle SavedModel TensorFlow en tant que couche Keras. Vous ajouterez ensuite une couche de classification et créerez un modèle avec l'API Keras Sequential.
Commencez par définir le paramètre feature_extractor_model, qui correspond au nom du vecteur de caractéristiques TensorFlow Hub que vous utiliserez comme base pour votre modèle.
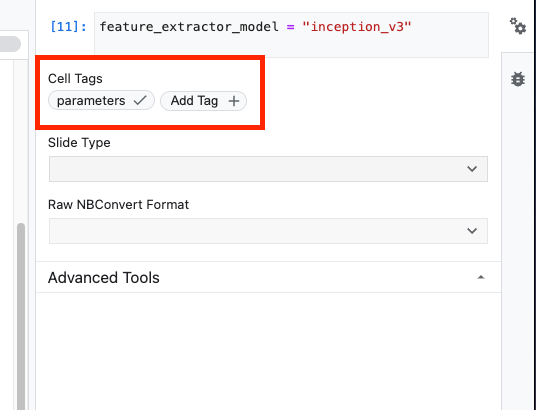
feature_extractor_model = "inception_v3"
Ensuite, vous allez faire de cette cellule une cellule de paramètre, ce qui vous permettra de transmettre une valeur pour feature_extractor_model au moment de l'exécution.
Sélectionnez d'abord la cellule, puis cliquez sur l'inspecteur de propriétés dans le panneau de droite.

Les tags sont un moyen simple d'ajouter des métadonnées à votre notebook. Saisissez "parameters" dans la zone "Add Tag" (Ajouter un tag), puis appuyez sur Entrée. Lorsque vous configurerez votre exécution, vous transmettrez les différentes valeurs, dans ce cas le modèle TensorFlow Hub, que vous souhaitez tester. Notez que vous devez saisir le mot "parameters" (et aucun autre mot), car c'est ainsi que l'exécuteur de notebook sait quelles cellules paramétrer.
Vous pouvez fermer l'inspecteur de propriétés en cliquant à nouveau sur l'icône à double engrenage.
Créez une cellule et définissez l'élément tf_hub_uri, où vous utiliserez l'interpolation de chaînes pour remplacer le nom du modèle pré-entraîné que vous souhaitez utiliser comme modèle de base pour une exécution spécifique de votre notebook. Par défaut, vous avez défini feature_extractor_model sur "inception_v3", mais d'autres valeurs valides sont "resnet_v2_50" ou "mobilenet_v1_100_224". Vous pouvez explorer d'autres options dans le catalogue TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Ensuite, créez l'extracteur de caractéristiques à l'aide de hub.KerasLayer et en transmettant l'élément tf_hub_uri que vous avez défini ci-dessus. Définissez l'argument trainable=False pour figer les variables afin que l'entraînement ne modifie que la nouvelle couche de classifieur que vous ajouterez en haut.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Pour terminer le modèle, encapsulez la couche d'extracteur de caractéristiques dans un tf.keras.Sequential modèle et ajoutez une couche entièrement connectée pour la classification. Le nombre d'unités dans cette tête de classification doit être égal au nombre de classes dans l'ensemble de données :
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Enfin, compilez et ajustez le modèle.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Exécuter le notebook
Cliquez sur l'icône Exécuteur en haut du notebook.

Étape 1 : Configurez le job d'entraînement
Donnez un nom à votre exécution et fournissez un bucket de stockage dans votre projet.

Définissez le type de machine sur 4 processeurs, 15 Go de RAM.
Ajoutez ensuite 1 GPU NVIDIA.
Définissez l'environnement sur TensorFlow Enterprise 2.6 (GPU).
Choisissez "One-time execution" (Exécution unique).
Étape 2 : Configurez les paramètres
Cliquez sur le menu déroulant OPTIONS AVANCÉES pour définir votre paramètre. Dans la zone, saisissez feature_extractor_model=resnet_v2_50. Cela remplacera inception_v3, la valeur par défaut que vous avez définie pour ce paramètre dans le notebook, par resnet_v2_50.

Vous pouvez laisser la case use default service account (utiliser le compte de service par défaut) cochée.
Cliquez ensuite sur Envoyer.
Étape 3 : Examinez les résultats
Dans l'onglet "Exécutions" de l'interface utilisateur de la console, vous pourrez voir l'état de l'exécution de votre notebook.

Si vous cliquez sur le nom de l'exécution, vous serez redirigé vers le job Vertex AI Training où votre notebook est en cours d'exécution.

Une fois votre job terminé, vous pourrez afficher le notebook de sortie en cliquant sur VIEW RESULT (AFFICHER LE RÉSULTAT).

Dans le notebook de sortie, vous verrez que la valeur de feature_extractor_model a été remplacée par la valeur que vous avez transmise au moment de l'exécution.

🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI Workbench pour :
- Utiliser des paramètres dans un notebook
- Configurer et lancer des exécutions de notebook à partir de l'interface utilisateur de Vertex AI Workbench
Pour en savoir plus sur les différentes parties de Vertex AI, consultez la documentation.
7. Nettoyage
Par défaut, les notebooks gérés s'arrêtent automatiquement après 180 minutes d'inactivité. Si vous souhaitez arrêter l'instance manuellement, cliquez sur le bouton "Arrêter" dans la section "Vertex AI Workbench" de la console. Si vous souhaitez supprimer le notebook définitivement, cliquez sur le bouton "Supprimer".

Pour supprimer le bucket de stockage, utilisez le menu de navigation de Cloud Console pour accéder à Stockage > Cloud Storage, sélectionnez votre bucket puis cliquez sur "Supprimer" :
