
1. مقدمة
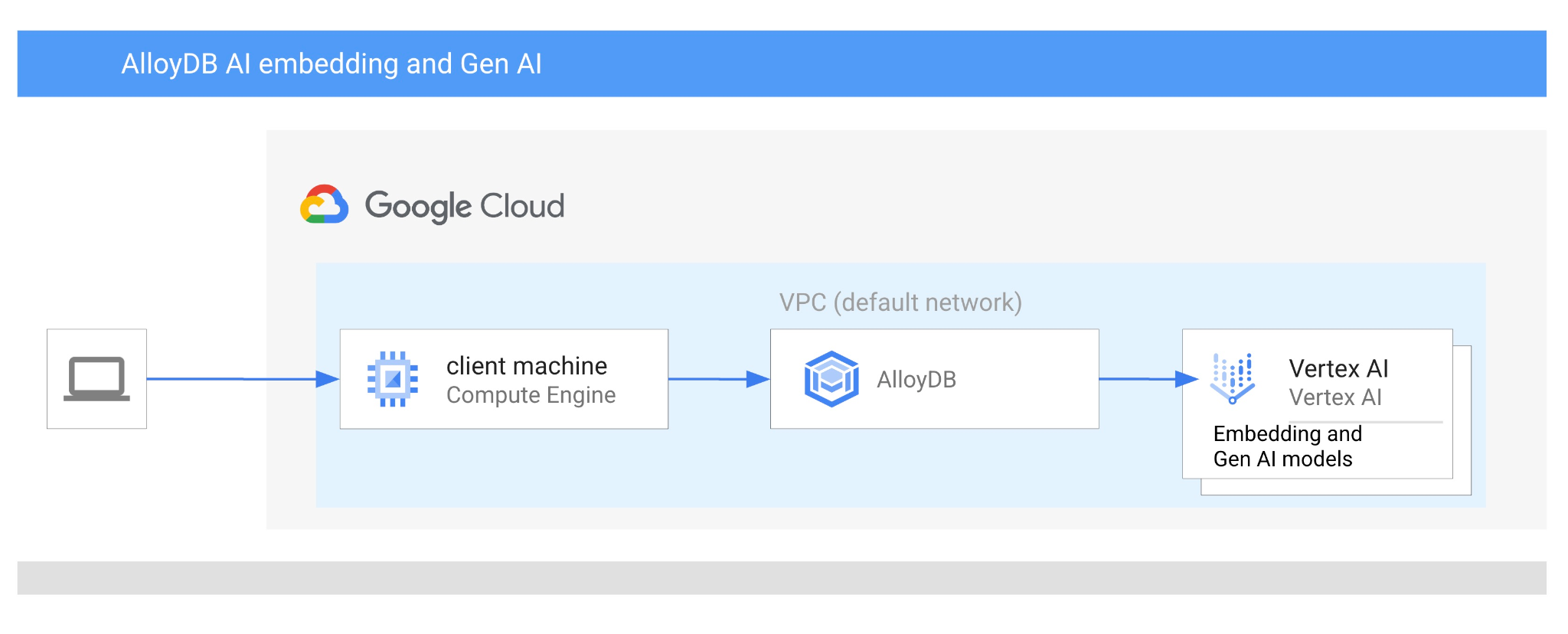
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية استخدام AlloyDB AI من خلال الجمع بين البحث عن المتّجهات وتضمينات Vertex AI. يشكّل هذا المختبر جزءًا من مجموعة مختبرات مخصّصة لميزات AlloyDB AI. يمكنك الاطّلاع على مزيد من المعلومات في صفحة AlloyDB AI ضمن المستندات.
المتطلبات الأساسية
- فهم أساسي لـ Google Cloud وConsole
- مهارات أساسية في واجهة سطر الأوامر وGoogle Shell
ما ستتعلمه
- كيفية نشر مجموعة AlloyDB ومثيل أساسي
- كيفية الاتصال بـ AlloyDB من جهاز Google Compute Engine الافتراضي
- كيفية إنشاء قاعدة بيانات وتفعيل AlloyDB AI
- كيفية تحميل البيانات إلى قاعدة البيانات
- كيفية استخدام AlloyDB Studio
- كيفية استخدام نموذج التضمين في Vertex AI في AlloyDB
- كيفية استخدام Vertex AI Studio
- كيفية تحسين النتيجة باستخدام نموذج الذكاء الاصطناعي التوليدي من Vertex AI
- كيفية تحسين الأداء باستخدام فهرس المتّجه
المتطلبات
- حساب على Google Cloud ومشروع على Google Cloud
- متصفّح ويب، مثل Chrome
2. الإعداد والمتطلبات
إعداد المشروع
- سجِّل الدخول إلى Google Cloud Console. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.
استخدام حساب شخصي بدلاً من حساب تديره المؤسسة التعليمية أو حساب تابع للعمل.
- أنشئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. لإنشاء مشروع جديد في Google Cloud Console، انقر على الزر "اختيار مشروع" في العنوان، ما سيؤدي إلى فتح نافذة منبثقة.

في نافذة "اختيار مشروع"، انقر على الزر "مشروع جديد" الذي سيفتح مربع حوار للمشروع الجديد.
في مربّع الحوار، أدخِل اسم المشروع المفضّل لديك واختَر الموقع الجغرافي.
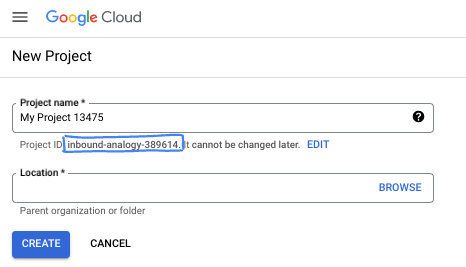
- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. لا تستخدم Google APIs اسم المشروع، ويمكن تغييره في أي وقت.
- رقم تعريف المشروع هو رقم تعريف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره (لا يمكن تغييره بعد ضبطه). تنشئ وحدة تحكّم Google Cloud تلقائيًا معرّفًا فريدًا، ولكن يمكنك تخصيصه. إذا لم يعجبك المعرّف الذي تم إنشاؤه، يمكنك إنشاء معرّف عشوائي آخر أو تقديم معرّفك الخاص للتحقّق من توفّره. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك، والذي يتم تحديده عادةً باستخدام العنصر النائب PROJECT_ID.
- للعلم، هناك قيمة ثالثة، وهي رقم المشروع، وتستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات حول هذه القيم الثلاث في المستندات.
تفعيل الفوترة
لتفعيل الفوترة، لديك خياران. يمكنك استخدام حساب الفوترة الشخصي أو تحصيل قيمة الرصيد باتّباع الخطوات التالية.
تحصيل قيمة أرصدة Google Cloud (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. يمكنك تخطّي هذه الخطوة إذا كنت مرتبطًا بحساب فوترة.
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، انتقِل إلى هنا لتفعيل الفوترة في Cloud Console.
بعض الملاحظات:
- يجب أن تكلّف إكمال هذا المختبر أقل من 3 دولارات أمريكية من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:
يمكنك بدلاً من ذلك الضغط على G ثم S. سيؤدي هذا التسلسل إلى تفعيل Cloud Shell إذا كنت تستخدم Google Cloud Console أو هذا الرابط.
لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا دائمًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- قبل البدء
تفعيل واجهة برمجة التطبيقات
إخراج:
لاستخدام AlloyDB وCompute Engine وخدمات الشبكات وVertex AI، عليك تفعيل واجهات برمجة التطبيقات الخاصة بها في مشروعك على Google Cloud.
تفعيل واجهات برمجة التطبيقات
داخل Cloud Shell في الوحدة الطرفية، تأكَّد من إعداد رقم تعريف مشروعك:
gcloud config set project [YOUR-PROJECT-ID]
اضبط متغيّر البيئة PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
فعِّل جميع واجهات برمجة التطبيقات اللازمة:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
الناتج المتوقّع
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
لمحة عن واجهات برمجة التطبيقات
- تتيح لك AlloyDB API (
alloydb.googleapis.com) إنشاء مجموعات AlloyDB for PostgreSQL وإدارتها وتوسيع نطاقها. توفّر خدمة قواعد بيانات مُدارة بالكامل ومتوافقة مع PostgreSQL ومصمَّمة لتلبية متطلبات مهام العمل التحليلية والمعاملات على مستوى المؤسسة. - تتيح لك Compute Engine API (
compute.googleapis.com) إنشاء الأجهزة الافتراضية والأقراص الثابتة وإعدادات الشبكة وإدارتها. توفّر هذه المنطقة الأساس المطلوب لتشغيل أحمال العمل واستضافة البنية التحتية الأساسية للعديد من الخدمات المُدارة. - تتيح لك Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) إدارة البيانات الوصفية وإعدادات مشروعك على Google Cloud آليًا. تتيح لك هذه الخدمة تنظيم الموارد والتعامل مع سياسات "إدارة الهوية والوصول" (IAM) والتحقّق من صحة الأذونات في جميع مستويات بنية المشروع. - تتيح لك Service Networking API (
servicenetworking.googleapis.com) إمكانية إعداد الاتصال الخاص بين شبكة السحابة الافتراضية الخاصة (VPC) وخدمات Google المُدارة بشكل آلي. وهي مطلوبة تحديدًا لإتاحة الوصول إلى عناوين IP الخاصة للخدمات، مثل AlloyDB، حتى تتمكّن من التواصل بأمان مع مواردك الأخرى. - تتيح Vertex AI API (
aiplatform.googleapis.com) لتطبيقاتك إنشاء نماذج تعلُّم الآلة ونشرها وتوسيع نطاقها. توفّر هذه المنصة واجهة موحّدة لجميع خدمات الذكاء الاصطناعي من Google Cloud، بما في ذلك إمكانية الوصول إلى نماذج الذكاء الاصطناعي التوليدي (مثل Gemini) وتدريب النماذج المخصّصة.
يمكنك اختياريًا ضبط منطقتك التلقائية لاستخدام نماذج التضمين في Vertex AI. مزيد من المعلومات حول المواقع الجغرافية التي تتوفّر فيها Vertex AI في المثال، نستخدم المنطقة us-central1.
gcloud config set compute/region us-central1
4. تفعيل AlloyDB
قبل إنشاء مجموعة AlloyDB، نحتاج إلى نطاق عناوين IP خاصة متاح في شبكة السحابة الافتراضية الخاصة (VPC) لاستخدامه في مثيل AlloyDB المستقبلي. إذا لم يكن لدينا، علينا إنشاؤه وتعيينه ليتم استخدامه من قِبل خدمات Google الداخلية، وبعد ذلك سنتمكّن من إنشاء المجموعة والآلة الافتراضية.
إنشاء نطاق عناوين IP خاص
علينا ضبط إعدادات الوصول إلى الخدمات الخاصة في شبكة VPC لخدمة AlloyDB. الافتراض هنا هو أنّ لدينا شبكة VPC "تلقائية" في المشروع وسيتم استخدامها في جميع الإجراءات.
أنشئ نطاق عناوين IP الخاصة:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
أنشئ اتصالاً خاصًا باستخدام نطاق عناوين IP المخصّص:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
إنشاء مجموعة AlloyDB
في هذا القسم، سننشئ مجموعة AlloyDB في المنطقة us-central1.
حدِّد كلمة مرور لمستخدم postgres. يمكنك تحديد كلمة المرور الخاصة بك أو استخدام دالة عشوائية لإنشاء كلمة مرور
export PGPASSWORD=`openssl rand -hex 12`
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
دوِّن كلمة مرور PostgreSQL لاستخدامها في المستقبل.
echo $PGPASSWORD
ستحتاج إلى كلمة المرور هذه في المستقبل للاتصال بالجهاز الظاهري بصفتك مستخدم postgres. أقترح عليك تدوينها أو نسخها في مكان ما لتتمكّن من استخدامها لاحقًا.
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
إنشاء مجموعة من الفترات التجريبية المجانية
إذا لم يسبق لك استخدام AlloyDB، يمكنك إنشاء مجموعة تجريبية مجانية باتّباع الخطوات التالية:
حدِّد المنطقة واسم مجموعة AlloyDB. سنستخدم المنطقة us-central1 وalloydb-aip-01 كاسم مجموعة:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
نفِّذ الأمر التالي لإنشاء المجموعة:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
الناتج المتوقّع في وحدة التحكّم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
أنشئ مثيلاً أساسيًا من AlloyDB لمجموعتك في جلسة Cloud Shell نفسها. في حال انقطاع الاتصال، عليك تحديد متغيرات بيئة اسم المنطقة واسم المجموعة مرة أخرى.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
إنشاء مجموعة AlloyDB Standard
إذا لم تكن هذه هي مجموعة AlloyDB الأولى في المشروع، يمكنك المتابعة لإنشاء مجموعة عادية.
حدِّد المنطقة واسم مجموعة AlloyDB. سنستخدم المنطقة us-central1 وalloydb-aip-01 كاسم مجموعة:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
نفِّذ الأمر التالي لإنشاء المجموعة:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
الناتج المتوقّع في وحدة التحكّم:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
أنشئ مثيلاً أساسيًا من AlloyDB لمجموعتك في جلسة Cloud Shell نفسها. في حال انقطاع الاتصال، عليك تحديد متغيرات بيئة اسم المنطقة واسم المجموعة مرة أخرى.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5- الربط بـ AlloyDB
يتم نشر AlloyDB باستخدام اتصال خاص فقط، لذلك نحتاج إلى جهاز افتراضي مثبَّت عليه برنامج PostgreSQL للتعامل مع قاعدة البيانات.
نشر جهاز افتراضي على "محرك حساب Google"
أنشئ جهازًا افتراضيًا على Google Compute Engine في المنطقة نفسها والسحابة الإلكترونية الخاصة الافتراضية (VPC) نفسها التي تضم مجموعة AlloyDB.
في Cloud Shell، نفِّذ ما يلي:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
تثبيت عميل Postgres
تثبيت برنامج عميل PostgreSQL على الجهاز الافتراضي الذي تم نشره
اتّصِل بالجهاز الافتراضي:
gcloud compute ssh instance-1 --zone=us-central1-a
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
ثبِّت البرنامج الذي يشغّل الأمر داخل الجهاز الافتراضي:
sudo apt-get update
sudo apt-get install --yes postgresql-client
الناتج المتوقّع في وحدة التحكّم:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
الربط بالجهاز الافتراضي
اتّصِل بالمثيل الأساسي من الجهاز الافتراضي باستخدام psql.
في علامة التبويب نفسها في Cloud Shell التي تم فيها فتح جلسة SSH على الجهاز الظاهري instance-1
استخدِم قيمة كلمة مرور AlloyDB (PGPASSWORD) ومعرّف مجموعة AlloyDB للاتصال بـ AlloyDB من الجهاز الافتراضي على GCE:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
الناتج المتوقّع في وحدة التحكّم:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
أغلِق جلسة psql:
exit
6. إعداد قاعدة البيانات
علينا إنشاء قاعدة بيانات وتفعيل عملية التكامل مع Vertex AI وإنشاء عناصر قاعدة البيانات واستيراد البيانات.
منح الأذونات اللازمة إلى AlloyDB
أضِف أذونات Vertex AI إلى وكيل خدمة AlloyDB.
افتح علامة تبويب أخرى في Cloud Shell باستخدام علامة "+" في أعلى الصفحة.
في علامة تبويب Cloud Shell الجديدة، نفِّذ ما يلي:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
أغلِق علامة التبويب من خلال تنفيذ الأمر "exit" في علامة التبويب:
exit
إنشاء قاعدة بيانات
إنشاء قاعدة بيانات باستخدام التشغيل السريع
في جلسة الجهاز الافتراضي على GCE، نفِّذ ما يلي:
إنشاء قاعدة بيانات:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
الناتج المتوقّع في وحدة التحكّم:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
تفعيل ميزة "التكامل مع Vertex AI"
فعِّل عملية دمج Vertex AI وإضافات pgvector في قاعدة البيانات.
في جهاز GCE الافتراضي، نفِّذ ما يلي:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
الناتج المتوقّع في وحدة التحكّم:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
استيراد البيانات
نزِّل البيانات المُعدّة واستوردها إلى قاعدة البيانات الجديدة.
في جهاز GCE الافتراضي، نفِّذ ما يلي:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
الناتج المتوقّع في وحدة التحكّم:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. احتساب عمليات التضمين
بعد استيراد البيانات، حصلنا على بيانات المنتجات في جدول cymbal_products، والمستودع الذي يعرض عدد المنتجات المتوفرة في كل متجر في جدول cymbal_inventory، وقائمة المتاجر في جدول cymbal_stores. علينا حساب بيانات المتجهات استنادًا إلى أوصاف منتجاتنا، وسنستخدم الدالة embedding لهذا الغرض. باستخدام الدالة، سنستخدم عملية دمج Vertex AI لحساب بيانات المتّجهات استنادًا إلى أوصاف منتجاتنا وإضافتها إلى الجدول. يمكنك الاطّلاع على مزيد من المعلومات حول التكنولوجيا المستخدَمة في المستندات.
من السهل إنشاء هذا المعرّف لعدد قليل من الصفوف، ولكن كيف يمكن جعله فعّالاً إذا كان لدينا الآلاف منها؟ سأوضّح هنا كيفية إنشاء عمليات تضمين وإدارتها للجداول الكبيرة. يمكنك أيضًا الاطّلاع على مزيد من المعلومات حول الخيارات والأساليب المختلفة في الدليل.
تفعيل ميزة "إنشاء التضمينات السريع"
اتّصِل بقاعدة البيانات باستخدام psql من جهازك الافتراضي باستخدام عنوان IP لمثيل AlloyDB وكلمة مرور postgres:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
تحقَّق من إصدار إضافة google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
يجب أن يكون الإصدار 1.5.2 أو إصدارًا أحدث. في ما يلي مثال على الناتج:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
يجب أن يكون الإصدار التلقائي 1.5.2 أو إصدارًا أحدث، ولكن إذا كانت مثيلتك تعرض إصدارًا أقدم، من المحتمل أن تحتاج إلى التحديث. تحقَّق مما إذا كانت الصيانة غير مفعَّلة للآلة الافتراضية.
بعد ذلك، علينا التحقّق من علامة قاعدة البيانات. يجب تفعيل العلامة google_ml_integration.enable_faster_embedding_generation. في جلسة psql نفسها، تحقّق من قيمة العلامة.
show google_ml_integration.enable_faster_embedding_generation;
إذا كانت العلامة في الموضع الصحيح، سيبدو الناتج المتوقّع على النحو التالي:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
ولكن إذا ظهرت الحالة "إيقاف"، علينا تحديث الجهاز الظاهري. يمكنك إجراء ذلك باستخدام وحدة تحكّم الويب أو أمر gcloud كما هو موضّح في المستندات. في ما يلي كيفية إجراء ذلك باستخدام أمر gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
قد يستغرق ذلك بضع دقائق، ولكن من المفترض أن يتم تبديل قيمة العلامة إلى "مفعَّل" في النهاية. بعد ذلك، يمكنك المتابعة إلى الخطوات التالية.
إنشاء عمود التضمين
اتّصِل بقاعدة البيانات باستخدام psql وأنشئ عمودًا افتراضيًا يتضمّن بيانات المتّجهات باستخدام دالة التضمين في جدول cymbal_products. تعرض دالة التضمين بيانات المتّجهات من Vertex AI استنادًا إلى البيانات المقدَّمة من عمود product_description.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
في جلسة psql بعد الاتصال بقاعدة البيانات، نفِّذ ما يلي:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
سينشئ الأمر العمود الظاهري ويملأه ببيانات متجهة.
الناتج المتوقّع في وحدة التحكّم:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
يمكننا الآن إنشاء تضمينات باستخدام دفعات تحتوي كل منها على 50 صفًا. يمكنك تجربة أحجام دفعات مختلفة ومعرفة ما إذا كانت ستؤدي إلى تغيير وقت التنفيذ. في جلسة psql نفسها، نفِّذ ما يلي:
فعِّل ميزة تحديد الوقت لقياس المدة التي سيستغرقها:
\timing
نفِّذ الأمر التالي:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
وكان الناتج في وحدة التحكّم أقل من ثانيتَين لإنشاء التضمين:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
بشكلٍ تلقائي، لن يتم إعادة تحميل التضمينات إذا تم تعديل عمود product_description المقابل أو إذا تم إدراج صف جديد بالكامل. ولكن يمكنك إجراء ذلك عن طريق تحديد المَعلمة incremental_refresh_mode. لننشئ العمود product_embeddings ونجعله قابلاً للتعديل تلقائيًا.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
والآن، إذا أدرجنا صفًا جديدًا في الجدول،
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
يمكننا مقارنة الفرق في الأعمدة باستخدام طلب البحث التالي:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
وفي الناتج، يمكننا أن نرى أنّه بينما يظل عمود embedding فارغًا، يتم تعديل عمود product_embedding تلقائيًا.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. تشغيل ميزة "البحث عن صور مشابهة"
يمكننا الآن إجراء البحث باستخدام البحث عن التشابه استنادًا إلى قيم المتجهات المحسوبة للأوصاف وقيمة المتجه التي نحصل عليها لطلبنا.
يمكن تنفيذ طلب بحث SQL من واجهة سطر الأوامر نفسها في psql أو من AlloyDB Studio كبديل. قد تبدو أي نتائج معقّدة ومتعددة الصفوف أفضل في AlloyDB Studio.
الربط بـ AlloyDB Studio
في الفصول التالية، يمكن تنفيذ جميع أوامر SQL التي تتطلّب الاتصال بقاعدة البيانات بشكل بديل في AlloyDB Studio. لتنفيذ الأمر، عليك فتح واجهة وحدة تحكّم الويب لمجموعة AlloyDB من خلال النقر على المثيل الأساسي.
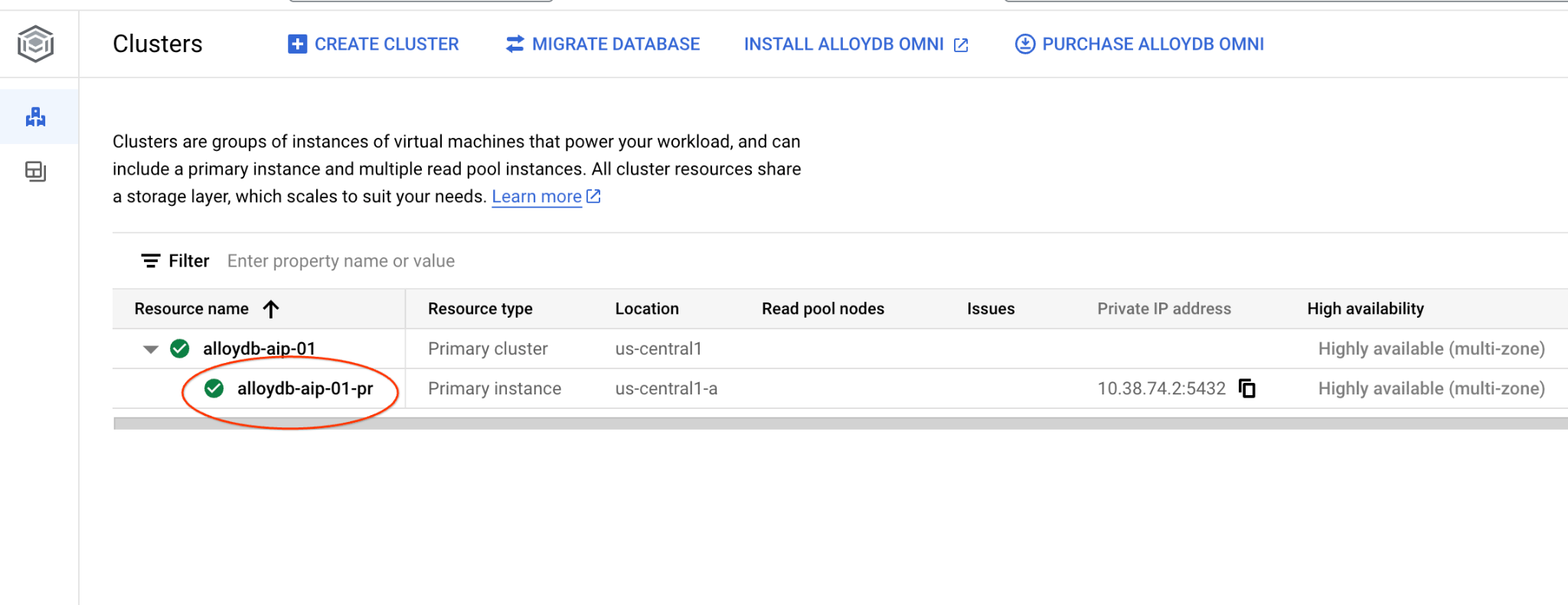
بعد ذلك، انقر على AlloyDB Studio في يمين الصفحة:
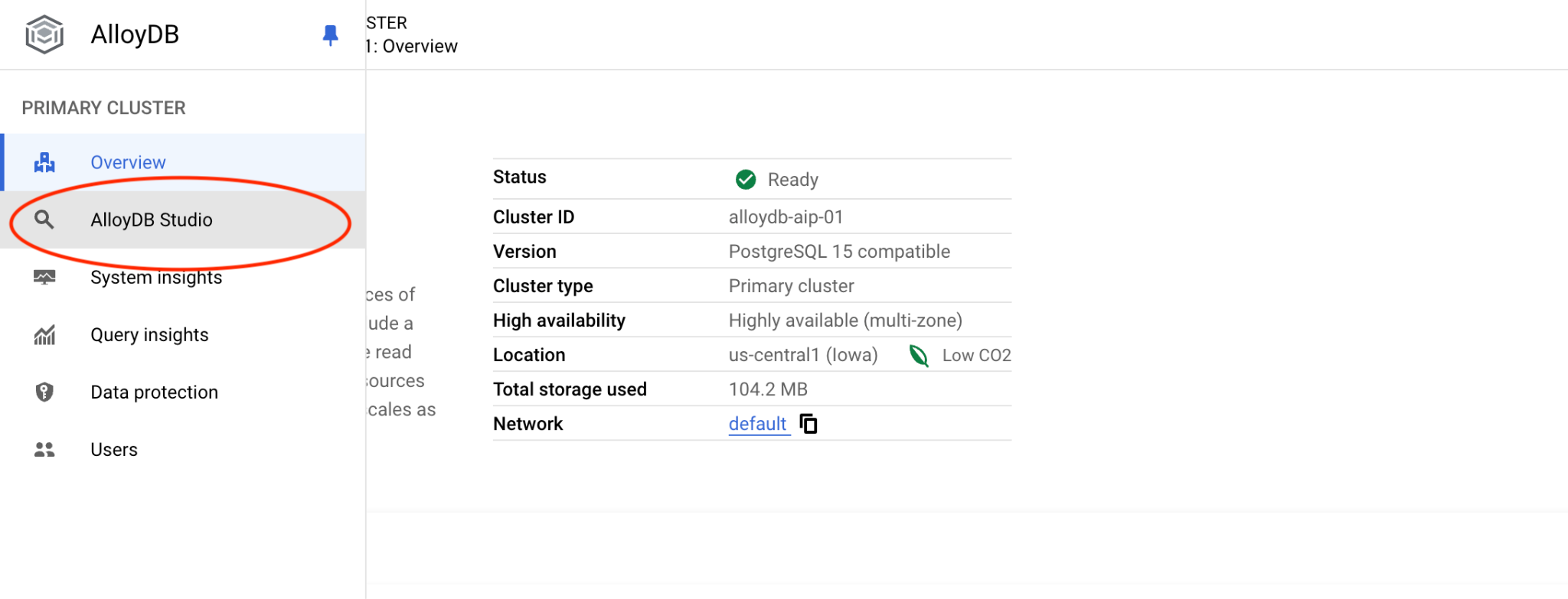
اختَر قاعدة بيانات quickstart_db والمستخدم postgres وأدخِل كلمة المرور التي دوّنتها عند إنشاء المجموعة. بعد ذلك، انقر على الزر "المصادقة".
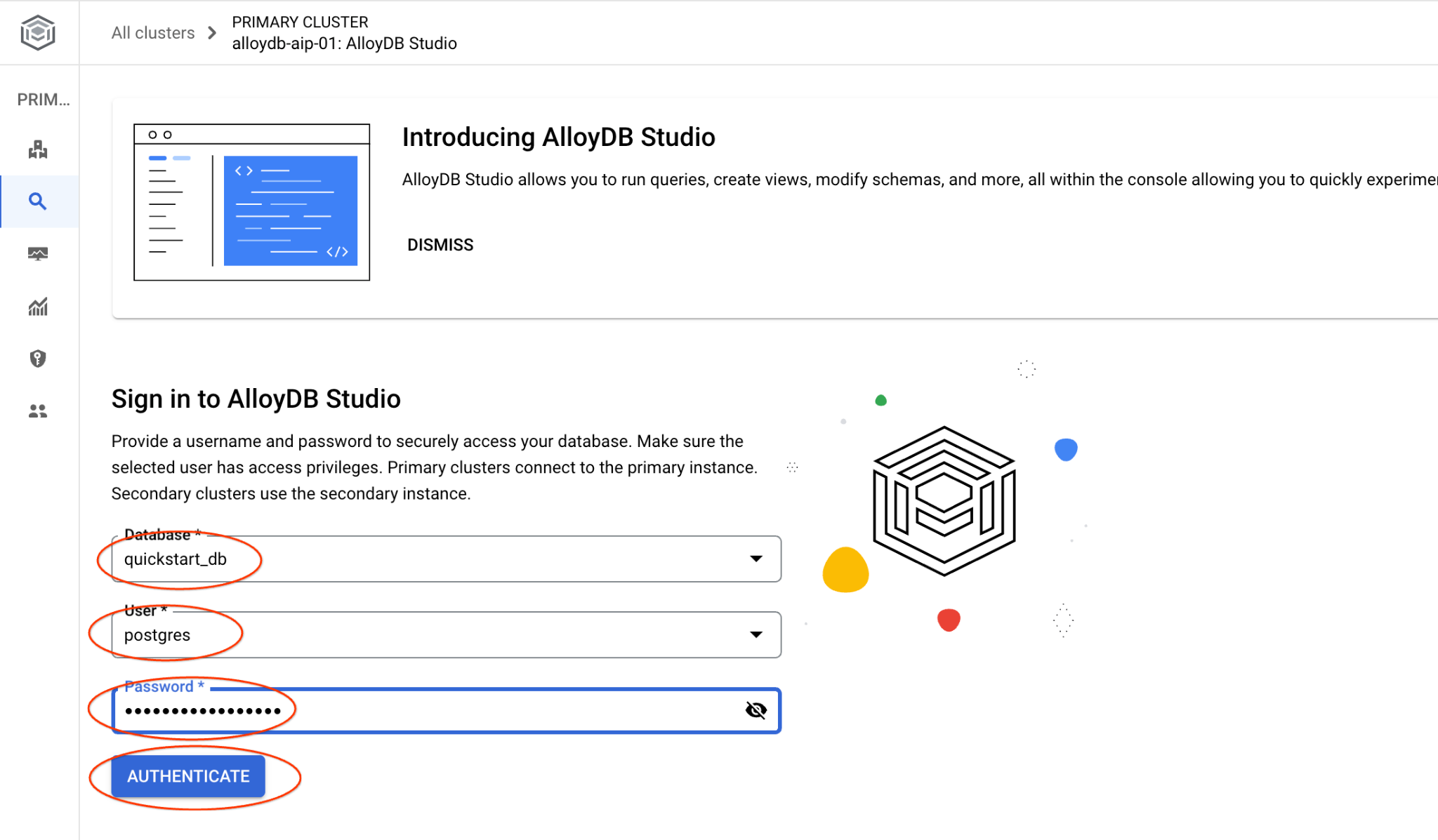
سيؤدي ذلك إلى فتح واجهة AlloyDB Studio. لتنفيذ الأوامر في قاعدة البيانات، انقر على علامة التبويب "المحرّر 1" على اليسار.
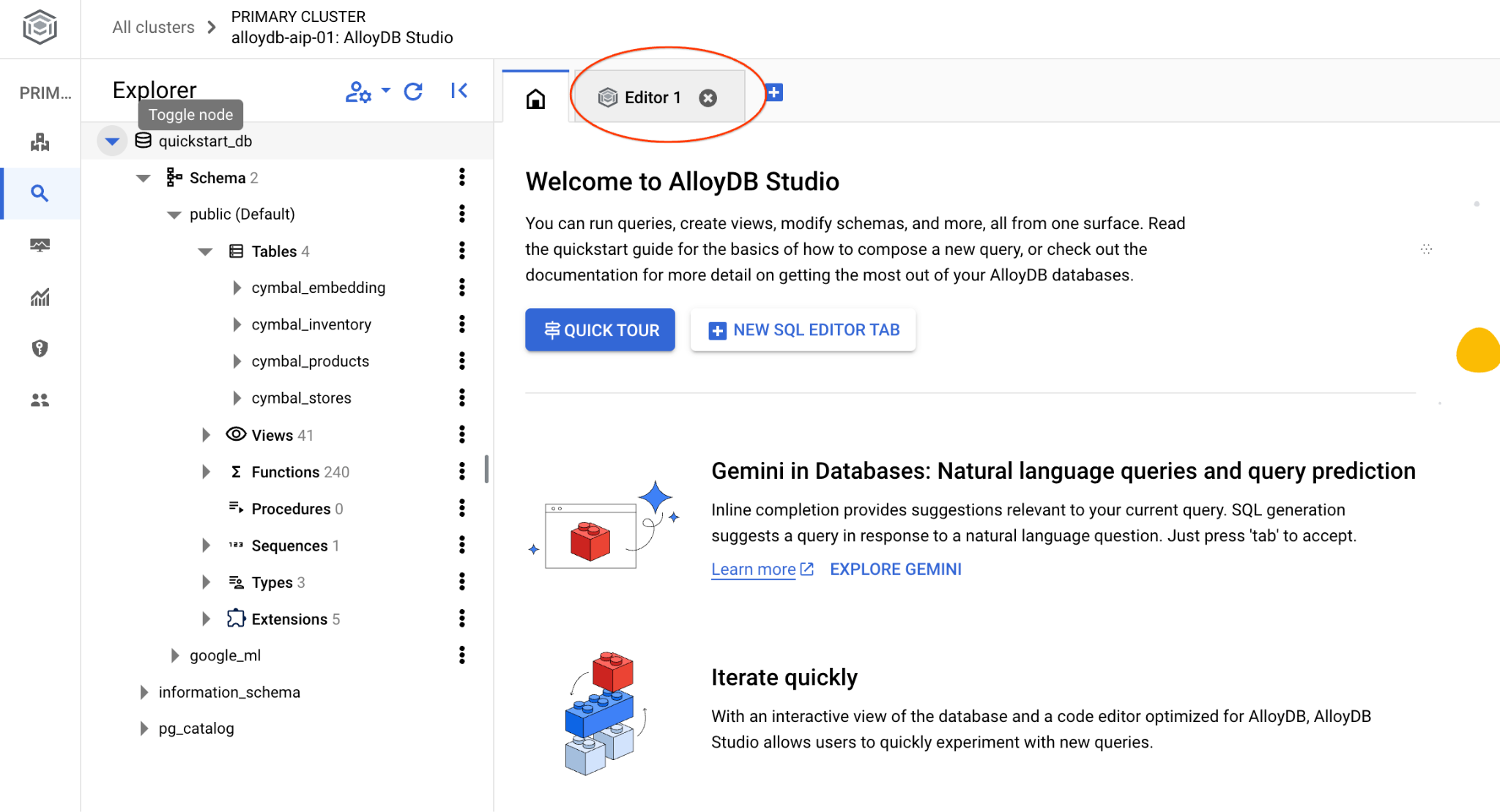
يفتح واجهة يمكنك من خلالها تنفيذ أوامر SQL
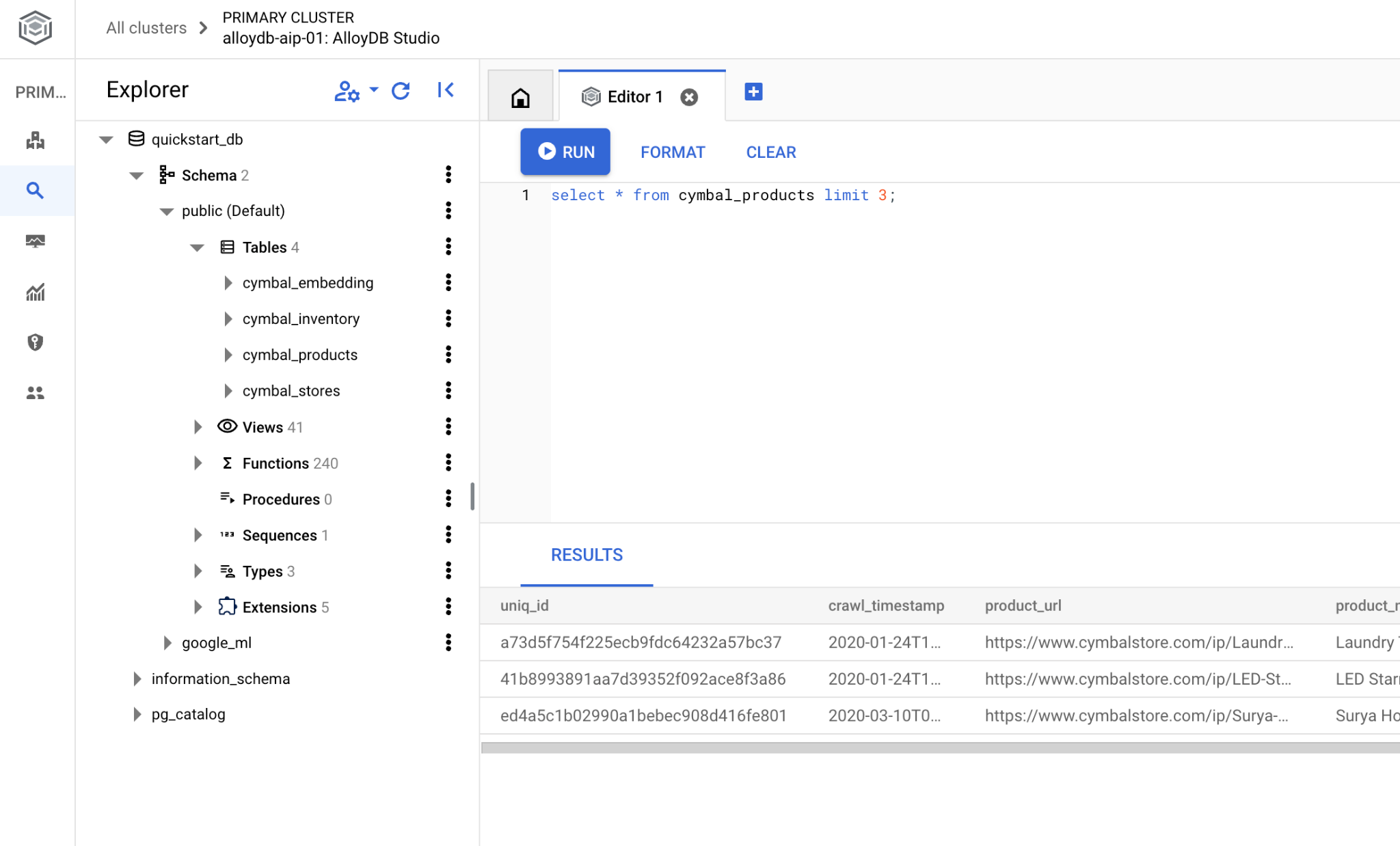
إذا كنت تفضّل استخدام سطر الأوامر psql، اتّبِع المسار البديل واتّصِل بقاعدة البيانات من خلال جلسة SSH على جهازك الافتراضي كما هو موضّح في الفصول السابقة.
تشغيل ميزة "البحث المشابه" من psql
إذا تم قطع اتصال جلسة قاعدة البيانات، أعِد الاتصال بقاعدة البيانات باستخدام psql أو AlloyDB Studio.
الربط بقاعدة البيانات:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
نفِّذ طلب بحث للحصول على قائمة بالمنتجات المتاحة الأكثر صلةً بطلب العميل. سيبدو الطلب الذي سنمرّره إلى Vertex AI للحصول على قيمة المتّجه على النحو التالي: "ما هي أنواع أشجار الفاكهة التي تنمو جيدًا هنا؟"
إليك طلب البحث الذي يمكنك تنفيذه لاختيار أول 10 عناصر الأنسب لطلبنا:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
إليك الناتج المتوقّع:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. تحسين الردّ
يمكنك تحسين الردّ على تطبيق العميل باستخدام نتيجة الطلب وإعداد ناتج مفيد باستخدام نتائج الطلب المقدَّمة كجزء من الطلب إلى نموذج اللغة الأساسي التوليدي في Vertex AI.
لتحقيق ذلك، نخطّط لإنشاء ملف JSON يتضمّن نتائج البحث المستند إلى المتّجهات، ثم استخدام ملف JSON الذي تم إنشاؤه كإضافة إلى طلب موجّه إلى نموذج لغوي كبير (LLM) نصي في Vertex AI لإنشاء إخراج ذي معنى. في الخطوة الأولى، ننشئ ملف JSON، ثم نختبره في Vertex AI Studio، وفي الخطوة الأخيرة، ندمجه في عبارة SQL يمكن استخدامها في أحد التطبيقات.
إنشاء الناتج بتنسيق JSON
عدِّل الاستعلام لإنشاء الإخراج بتنسيق JSON وعرض صف واحد فقط لتمريره إلى Vertex AI
في ما يلي مثال على طلب البحث:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
في ما يلي تنسيق JSON المتوقّع في الناتج:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
تشغيل الطلب في Vertex AI Studio
يمكننا استخدام ملف JSON الذي تم إنشاؤه لتضمينه كجزء من الطلب في نموذج الذكاء الاصطناعي التوليدي المستند إلى نص في Vertex AI Studio.
افتح Vertex AI Studio في Cloud Console.
قد يُطلب منك الموافقة على بنود الاستخدام إذا لم يسبق لك استخدامها. انقر على الزر "الموافقة والمتابعة"
اكتب طلبك في الواجهة.
قد يُطلب منك تفعيل واجهات برمجة تطبيقات إضافية، ولكن يمكنك تجاهل الطلب. لا نحتاج إلى أي واجهات برمجة تطبيقات إضافية لإكمال الدرس التطبيقي.
في ما يلي الطلب الذي سنستخدمه مع ناتج JSON الخاص بالاستعلام الأوّلي حول الأشجار:
أنت مستشار ودود يساعد في العثور على منتج بناءً على احتياجات العميل.
استنادًا إلى طلب العميل، حمّلنا قائمة بالمنتجات ذات الصلة الوثيقة بالبحث.
القائمة بتنسيق JSON مع قائمة بالقيم مثل {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
إليك قائمة المنتجات:
{"product_name":"شجرة كرز","description":"هذه شجرة كرز جميلة ستنتج كرزًا لذيذًا. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
سأل العميل "ما هي الشجرة التي تنمو بشكل أفضل هنا؟"
يجب تقديم معلومات عن المنتج والسعر وبعض المعلومات التكميلية
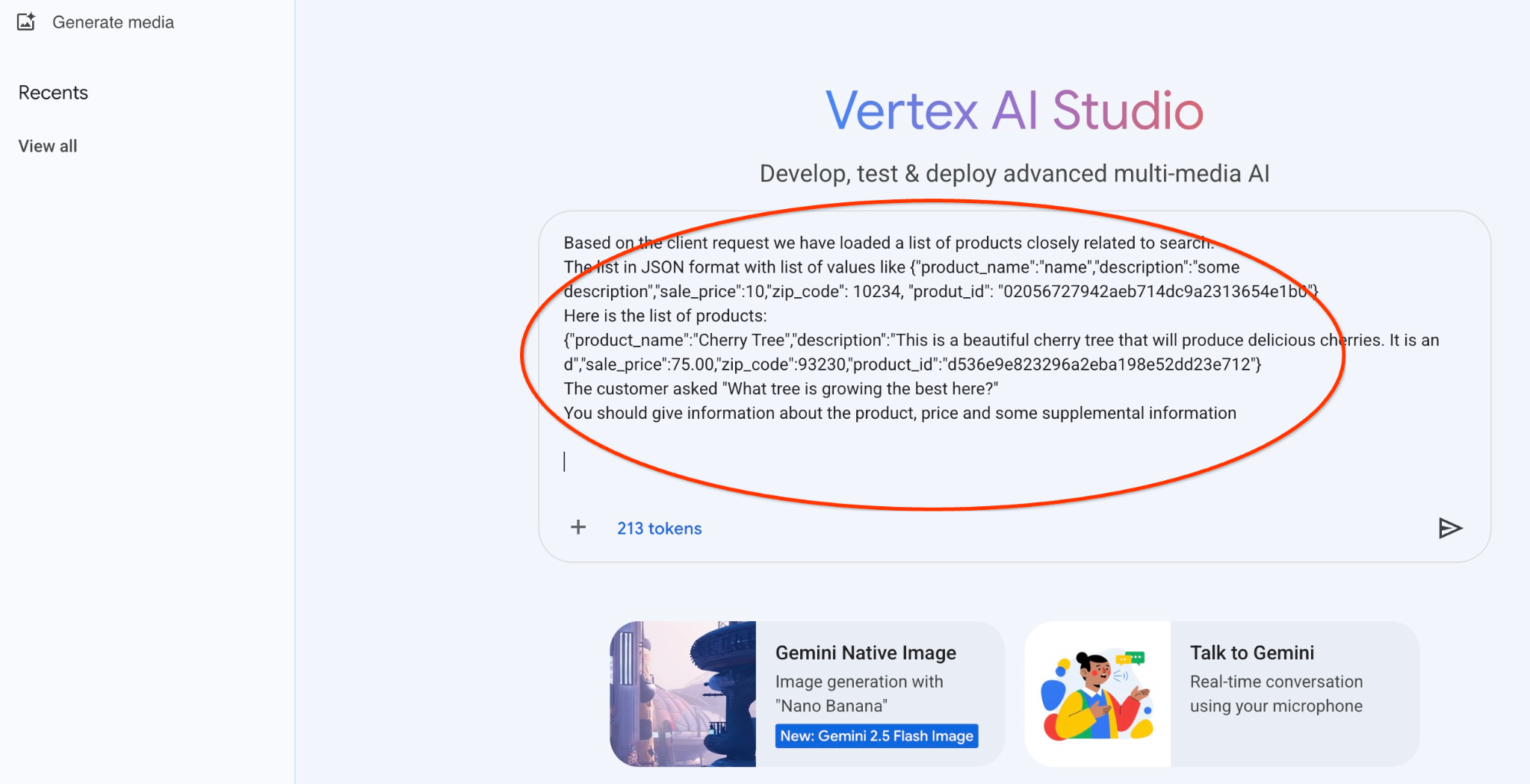
في ما يلي النتيجة عند تنفيذ الطلب باستخدام قيم JSON وباستخدام نموذج gemini-2.5-flash-light:
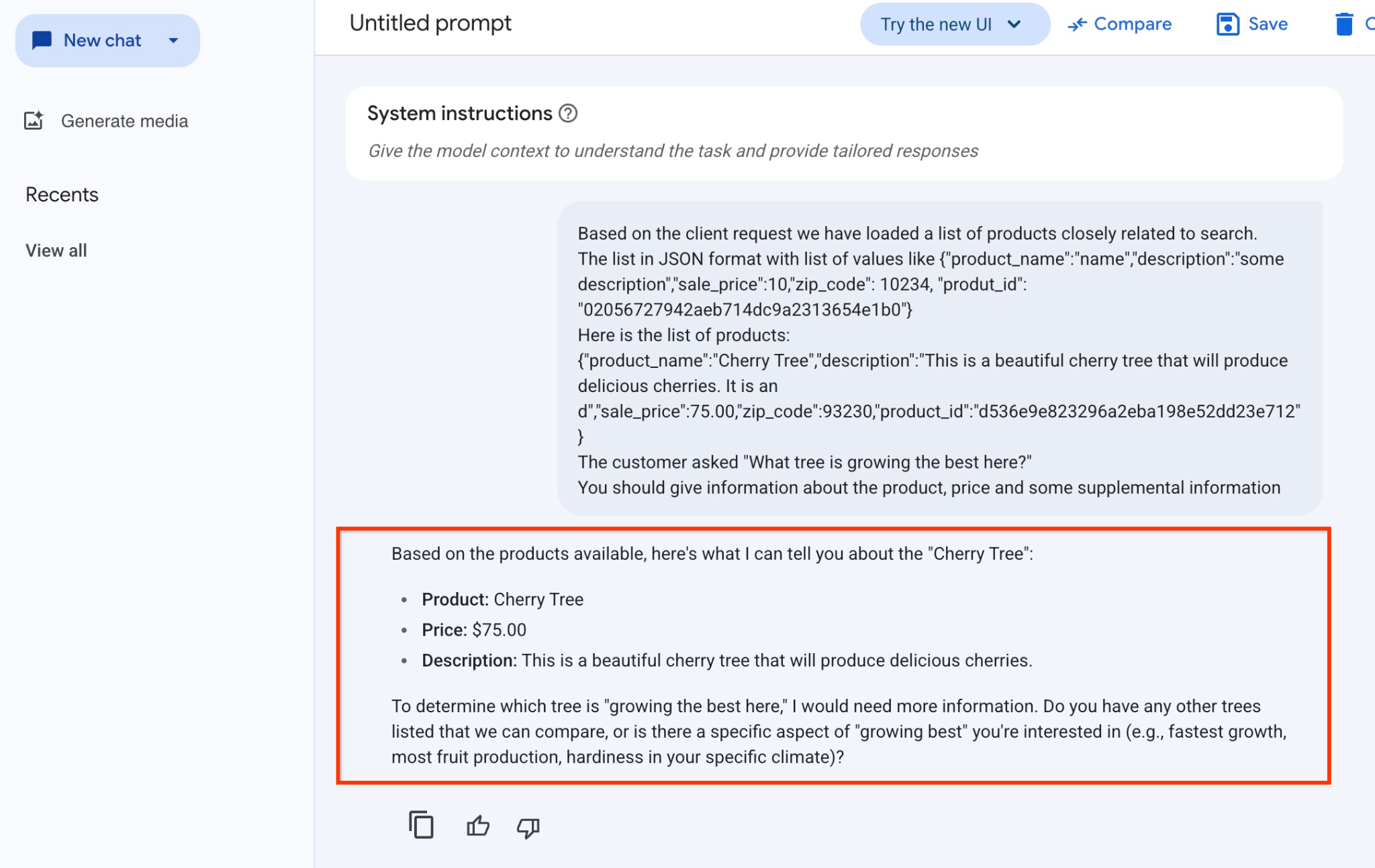
في ما يلي الإجابة التي حصلنا عليها من النموذج في هذا المثال. يُرجى العِلم أنّ إجابتك قد تختلف بسبب التغييرات التي تطرأ على النموذج والمعلَمات بمرور الوقت:
"استنادًا إلى المنتجات المتاحة، إليك ما يمكنني إخبارك به عن "شجرة الكرز":
المنتج: شجرة الكرز
السعر: 75.00 دولار أمريكي
الوصف: هذه شجرة كرز جميلة ستنتج كرزًا لذيذًا.
لتحديد الشجرة التي "تنمو بشكل أفضل هنا"، أحتاج إلى مزيد من المعلومات. هل لديك أي أشجار أخرى مدرَجة يمكننا مقارنتها، أو هل هناك جانب محدّد من "النمو الأفضل" يهمّك (مثل النمو الأسرع أو إنتاج أكبر كمية من الفاكهة أو القدرة على تحمّل المناخ في منطقتك)؟"
تشغيل الطلب في PSQL
يمكننا استخدام عملية الدمج بين AlloyDB AI وVertex AI للحصول على الردّ نفسه من نموذج توليدي باستخدام SQL مباشرةً في قاعدة البيانات. ولكن لاستخدام نموذج gemini-1.5-flash، علينا تسجيله أولاً.
تحقَّق من إضافة google_ml_integration. يجب أن يكون الإصدار 1.4.2 أو إصدارًا أحدث.
اتّصِل بقاعدة بيانات quickstart_db من psql كما هو موضّح سابقًا (أو استخدِم AlloyDB Studio) ونفِّذ ما يلي:
SELECT extversion from pg_extension where extname='google_ml_integration';
تحقَّق من علامة قاعدة البيانات google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
الناتج المتوقّع من جلسة psql هو "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
إذا ظهرت القيمة "إيقاف"، يجب ضبط علامة قاعدة البيانات google_ml_integration.enable_model_support على "تفعيل". لإجراء ذلك، يمكنك استخدام واجهة وحدة تحكّم AlloyDB على الويب أو تنفيذ أمر gcloud التالي.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
يستغرق تنفيذ الأمر في الخلفية من دقيقة واحدة إلى 3 دقائق تقريبًا. بعد ذلك، يمكنك تأكيد الإبلاغ مرة أخرى.
نحتاج إلى نموذجين للاستعلام. الأول هو نموذج text-embedding-005 المستخدَم حاليًا، والثاني هو أحد نماذج Google gemini العامة.
نبدأ بنموذج تضمين النص. لتسجيل عملية تنفيذ النموذج في psql أو AlloyDB Studio، استخدِم الرمز التالي:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
والنموذج التالي الذي يجب تسجيله هو gemini-2.0-flash-001 الذي سيتم استخدامه لإنشاء النتائج سهلة الاستخدام.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
يمكنك دائمًا التحقّق من قائمة النماذج المسجّلة من خلال اختيار معلومات من google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
في ما يلي مثال على الناتج
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
يمكننا الآن استخدام JSON الذي تم إنشاؤه في طلب فرعي لتوفيره كجزء من الطلب إلى نموذج نصي للذكاء الاصطناعي التوليدي باستخدام SQL.
في جلسة psql أو AlloyDB Studio لقاعدة البيانات، شغِّل طلب البحث
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
وفي ما يلي الناتج المتوقّع. قد يختلف الناتج حسب إصدار النموذج والمعلَمات.:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. إنشاء فهرس متجهات
مجموعة البيانات لدينا صغيرة جدًا، ويعتمد وقت الاستجابة بشكل أساسي على التفاعل مع نماذج الذكاء الاصطناعي. ولكن عندما يكون لديك ملايين المتجهات، يمكن أن يستغرق جزء البحث المتّجه وقتًا كبيرًا من وقت الاستجابة ويفرض حملاً كبيرًا على النظام. لتحسين ذلك، يمكننا إنشاء فهرس فوق المتجهات.
إنشاء فهرس ScaNN
لإنشاء فهرس SCANN، علينا تفعيل إضافة أخرى. توفّر الإضافة alloydb_scann واجهة للعمل مع فهرس متّجه من النوع ANN باستخدام خوارزمية Google ScaNN.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
الناتج المتوقّع:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
يمكن إنشاء الفهرس في الوضع MANUAL أو AUTO. يكون الوضع MANUAL مفعَّلاً تلقائيًا ويمكنك إنشاء فهرس والاحتفاظ به كأي فهرس آخر. ولكن إذا فعّلت الوضع "تلقائي"، ستتمكّن من إنشاء الفهرس الذي لا يتطلّب أي صيانة من جانبك. يمكنك الاطّلاع على تفاصيل حول جميع الخيارات في المستندات، وسأوضّح لك هنا كيفية تفعيل الوضع "تلقائي" وإنشاء الفهرس. في حالتنا، لا تتوفّر لدينا صفوف كافية لإنشاء الفهرس في الوضع AUTO، لذا سننشئه في الوضع MANUAL.
في المثال التالي، سأترك معظم المَعلمات كإعدادات تلقائية وسأقدّم فقط عددًا من الأقسام (num_leaves) للفهرس:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
يمكنك الاطّلاع على معلومات حول ضبط مَعلمات الفهرس في المستندات.
الناتج المتوقّع:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
مقارنة الردود
يمكننا الآن تشغيل طلب البحث عن المتجهات في وضع EXPLAIN والتحقّق مما إذا كان قد تم استخدام الفهرس.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
الناتج المتوقّع (تم إخفاء بعض المعلومات لتوضيح المثال):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
من الناتج، يمكننا أن نرى بوضوح أنّ طلب البحث كان يستخدم "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
وإذا نفّذنا الاستعلام بدون explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
الناتج المتوقّع:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
يمكننا أن نرى أنّ النتيجة هي شجرة الكرز نفسها التي ظهرت في أعلى نتائج البحث بدون فهرس. في بعض الأحيان، قد لا يكون الأمر كذلك وقد يعرض الردّ أشجارًا أخرى من الأعلى بدلاً من الشجرة نفسها. وبالتالي، يقدّم لنا الفهرس أداءً جيدًا مع الحفاظ على دقة كافية لتحقيق نتائج جيدة.
يمكنك تجربة فهارس مختلفة متاحة للمتجهات والمزيد من المعامل والأمثلة مع إمكانية دمج Langchain المتوفّرة على صفحة المستندات.
11. تنظيف البيئة
إتلاف مثيلات AlloyDB ومجموعة AlloyDB عند الانتهاء من الدرس التطبيقي
حذف مجموعة AlloyDB وجميع مثيلاتها
إذا سبق لك استخدام الإصدار التجريبي من AlloyDB لا تحذف المجموعة التجريبية إذا كنت تخطّط لاختبار مختبرات ومراجع أخرى باستخدام المجموعة التجريبية. لن تتمكّن من إنشاء مجموعة تجريبية أخرى في المشروع نفسه.
يتم إيقاف المجموعة باستخدام الخيار force الذي يؤدي أيضًا إلى حذف جميع المثيلات التابعة للمجموعة.
في Cloud Shell، حدِّد متغيرات المشروع والبيئة إذا تم قطع الاتصال وفقدت جميع الإعدادات السابقة:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
احذف المجموعة:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
حذف نُسخ AlloyDB الاحتياطية
احذف جميع النُسخ الاحتياطية من AlloyDB للمجموعة:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
يمكننا الآن محو الجهاز الافتراضي
حذف جهاز GCE الافتراضي
في Cloud Shell، نفِّذ ما يلي:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
الناتج المتوقّع في وحدة التحكّم:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. تهانينا
تهانينا على إكمال درس البرمجة.
يشكّل هذا المختبر جزءًا من مسار "الذكاء الاصطناعي الجاهز للإنتاج" التعليمي على Google Cloud.
- استكشِف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج.
- شارِك مستوى تقدّمك باستخدام الهاشتاغ
#ProductionReadyAI.
المواضيع التي تناولناها
- كيفية نشر مجموعة AlloyDB ومثيل أساسي
- كيفية الاتصال بـ AlloyDB من جهاز Google Compute Engine الافتراضي
- كيفية إنشاء قاعدة بيانات وتفعيل AlloyDB AI
- كيفية تحميل البيانات إلى قاعدة البيانات
- كيفية استخدام AlloyDB Studio
- كيفية استخدام نموذج التضمين في Vertex AI في AlloyDB
- كيفية استخدام Vertex AI Studio
- كيفية تحسين النتيجة باستخدام نموذج الذكاء الاصطناعي التوليدي من Vertex AI
- كيفية تحسين الأداء باستخدام فهرس المتّجه
13. الاستطلاع
إخراج: