
1. Introduzione
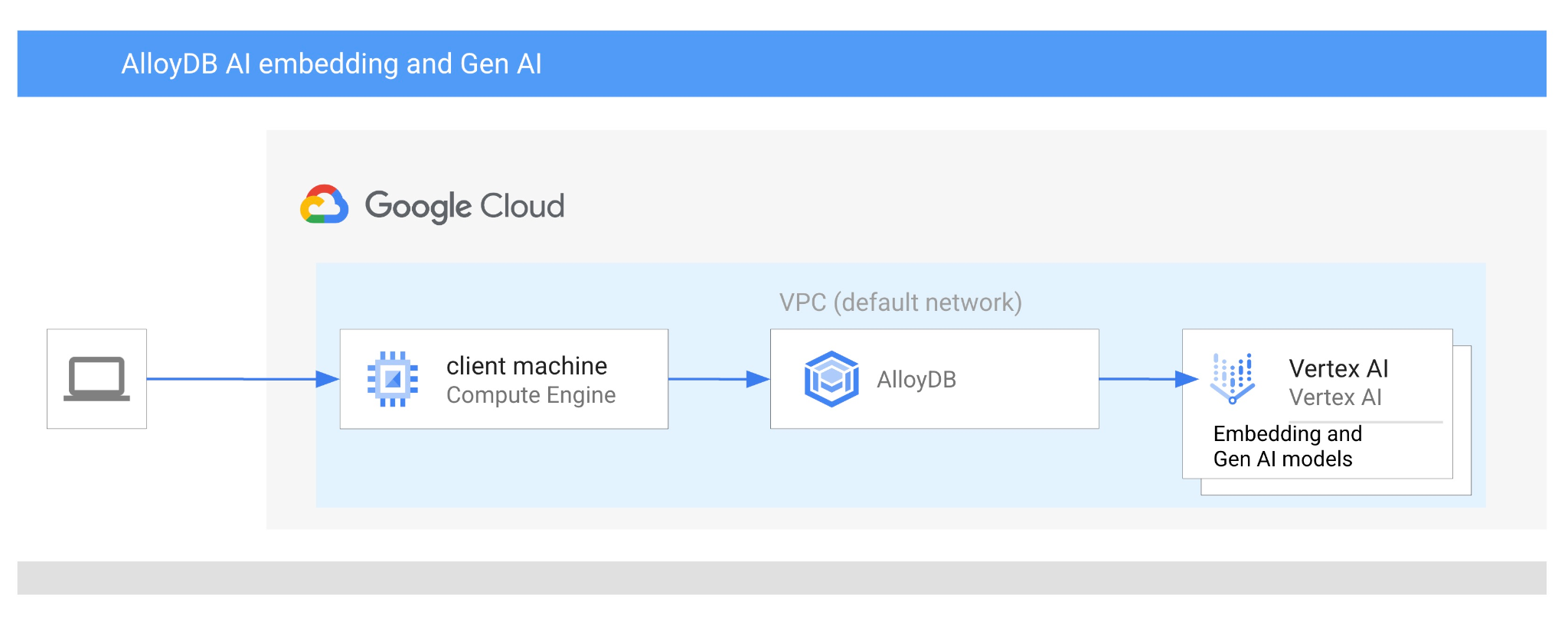
In questo codelab imparerai a utilizzare AlloyDB AI combinando la ricerca vettoriale con gli incorporamenti di Vertex AI. Questo lab fa parte di una raccolta dedicata alle funzionalità di AI di AlloyDB. Per saperne di più, consulta la pagina di AlloyDB AI nella documentazione.
Prerequisiti
- Una conoscenza di base di Google Cloud Console
- Competenze di base nell'interfaccia a riga di comando e in Google Shell
Cosa imparerai a fare
- Come eseguire il deployment del cluster e dell'istanza principale di AlloyDB
- Come connettersi ad AlloyDB da una VM Google Compute Engine
- Come creare un database e abilitare AlloyDB AI
- Come caricare i dati nel database
- Come utilizzare AlloyDB Studio
- Come utilizzare il modello di embedding Vertex AI in AlloyDB
- Come utilizzare Vertex AI Studio
- Come arricchire il risultato utilizzando il modello generativo Vertex AI
- Come migliorare il rendimento utilizzando l'indice vettoriale
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
2. Configurazione e requisiti
Configurazione del progetto
- Accedi alla console Google Cloud. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
- Crea un nuovo progetto o riutilizzane uno esistente. Per creare un nuovo progetto nella console Google Cloud, fai clic sul pulsante Seleziona un progetto nell'intestazione per aprire una finestra popup.

Nella finestra Seleziona un progetto, premi il pulsante Nuovo progetto per aprire una finestra di dialogo per il nuovo progetto.
Nella finestra di dialogo, inserisci il nome del progetto che preferisci e scegli la posizione.
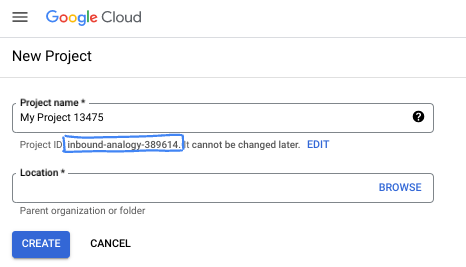
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. Il nome del progetto non viene utilizzato dalle API di Google e può essere modificato in qualsiasi momento.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Google Cloud genera automaticamente un ID univoco, ma puoi personalizzarlo. Se non ti piace l'ID generato, puoi generarne un altro casuale o fornire il tuo per verificarne la disponibilità. Nella maggior parte dei codelab, devi fare riferimento all'ID progetto, che in genere è identificato con il segnaposto PROJECT_ID.
- Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
Abilita fatturazione
Per attivare la fatturazione, hai due opzioni. Puoi utilizzare il tuo account di fatturazione personale o riscattare i crediti seguendo questi passaggi.
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 3 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
In alternativa, puoi premere G e poi S. Questa sequenza attiverà Cloud Shell se ti trovi nella console Google Cloud o utilizza questo link.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Prima di iniziare
Abilita l'API
Output:
Per utilizzare AlloyDB, Compute Engine, servizi di rete e Vertex AI, devi abilitare le rispettive API nel tuo progetto Google Cloud.
Abilitazione delle API
All'interno di Cloud Shell nel terminale, assicurati che l'ID progetto sia configurato:
gcloud config set project [YOUR-PROJECT-ID]
Imposta la variabile di ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Abilita tutte le API necessarie:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Output previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Presentazione delle API
- L'API AlloyDB (
alloydb.googleapis.com) consente di creare, gestire e scalare i cluster AlloyDB per PostgreSQL. Fornisce un servizio di database completamente gestito e compatibile con PostgreSQL progettato per carichi di lavoro transazionali e analitici aziendali impegnativi. - L'API Compute Engine (
compute.googleapis.com) consente di creare e gestire macchine virtuali (VM), dischi permanenti e impostazioni della rete. Fornisce le basi di Infrastructure as a Service (IaaS) necessarie per eseguire i carichi di lavoro e ospitare l'infrastruttura sottostante per molti servizi gestiti. - L'API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) ti consente di gestire in modo programmatico i metadati e la configurazione del tuo progetto Google Cloud. Consente di organizzare le risorse, gestire i criteri IAM (Identity and Access Management) e convalidare le autorizzazioni nella gerarchia dei progetti. - L'API Service Networking (
servicenetworking.googleapis.com) ti consente di automatizzare la configurazione della connettività privata tra la tua rete Virtual Private Cloud (VPC) e i servizi gestiti di Google. È necessario in particolare per stabilire l'accesso IP privato per servizi come AlloyDB, in modo che possano comunicare in modo sicuro con le altre risorse. - L'API Vertex AI (
aiplatform.googleapis.com) consente alle tue applicazioni di creare, eseguire il deployment e scalare modelli di machine learning. Fornisce l'interfaccia unificata per tutti i servizi di AI di Google Cloud, incluso l'accesso ai modelli di AI generativa (come Gemini) e l'addestramento di modelli personalizzati.
Facoltativamente, puoi configurare la regione predefinita per utilizzare i modelli di incorporamento Vertex AI. Scopri di più sulle località disponibili per Vertex AI. Nell'esempio viene utilizzata la regione us-central1.
gcloud config set compute/region us-central1
4. Esegui il deployment di AlloyDB
Prima di creare un cluster AlloyDB, abbiamo bisogno di un intervallo di indirizzi IP privati disponibile nella nostra VPC da utilizzare per la futura istanza AlloyDB. Se non lo abbiamo, dobbiamo crearlo, assegnarlo per l'utilizzo da parte dei servizi Google interni e solo dopo potremo creare il cluster e l'istanza.
Crea intervallo IP privato
Dobbiamo configurare la configurazione dell'accesso privato ai servizi nel nostro VPC per AlloyDB. Il presupposto è che nel progetto sia presente la rete VPC "default" e che verrà utilizzata per tutte le azioni.
Crea l'intervallo IP privato:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crea una connessione privata utilizzando l'intervallo IP allocato:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Crea cluster AlloyDB
In questa sezione creiamo un cluster AlloyDB nella regione us-central1.
Definisci la password per l'utente postgres. Puoi definire una password personalizzata o utilizzare una funzione casuale per generarla.
export PGPASSWORD=`openssl rand -hex 12`
Output console previsto:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Prendi nota della password PostgreSQL per utilizzarla in futuro.
echo $PGPASSWORD
In futuro ti servirà questa password per connetterti all'istanza come utente postgres. Ti consiglio di annotarlo o copiarlo da qualche parte per poterlo utilizzare in un secondo momento.
Output console previsto:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Creare un cluster di prova senza costi aggiuntivi
Se non hai mai utilizzato AlloyDB, puoi creare un cluster di prova senza costi:
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Crea un cluster AlloyDB Standard
Se non è il tuo primo cluster AlloyDB nel progetto, procedi con la creazione di un cluster standard.
Definisci la regione e il nome del cluster AlloyDB. Utilizzeremo la regione us-central1 e alloydb-aip-01 come nome del cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Esegui il comando per creare il cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Output console previsto:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crea un'istanza principale AlloyDB per il nostro cluster nella stessa sessione della shell Cloud. Se la connessione viene interrotta, dovrai definire nuovamente le variabili di ambiente del nome della regione e del cluster.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Connetterti ad AlloyDB
AlloyDB viene implementato utilizzando una connessione solo privata, quindi abbiamo bisogno di una VM con il client PostgreSQL installato per lavorare con il database.
Esegui il deployment della VM GCE
Crea una VM GCE nella stessa regione e nello stesso VPC del cluster AlloyDB.
In Cloud Shell, esegui:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Output console previsto:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Installa il client Postgres
Installa il software client PostgreSQL sulla VM di cui è stato eseguito il deployment
Connettiti alla VM:
gcloud compute ssh instance-1 --zone=us-central1-a
Output console previsto:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Installa il comando di esecuzione del software all'interno della VM:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Output console previsto:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Connettiti all'istanza
Connettiti all'istanza primaria dalla VM utilizzando psql.
Nella stessa scheda Cloud Shell con la sessione SSH aperta alla VM instance-1.
Utilizza il valore della password AlloyDB (PGPASSWORD) annotato e l'ID cluster AlloyDB per connetterti ad AlloyDB dalla VM GCE:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Output console previsto:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Chiudi la sessione psql:
exit
6. Prepara il database
Dobbiamo creare un database, abilitare l'integrazione di Vertex AI, creare oggetti di database e importare i dati.
Concedere le autorizzazioni necessarie ad AlloyDB
Aggiungi le autorizzazioni Vertex AI al service agent AlloyDB.
Apri un'altra scheda di Cloud Shell utilizzando il segno "+" in alto.
Nella nuova scheda di Cloud Shell, esegui:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Chiudi la scheda con il comando di esecuzione "exit":
exit
Crea database
Guida rapida alla creazione di un database.
Nella sessione VM GCE esegui:
Crea database:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Output console previsto:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Abilitare l'integrazione di Vertex AI
Abilita l'integrazione di Vertex AI e le estensioni pgvector nel database.
Nella VM GCE esegui:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Output console previsto:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Importa i dati
Scarica i dati preparati e importali nel nuovo database.
Nella VM GCE esegui:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Output console previsto:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Calcolare gli incorporamenti
Dopo aver importato i dati, abbiamo ottenuto i dati di prodotto nella tabella cymbal_products, l'inventario che mostra il numero di prodotti disponibili in ogni negozio nella tabella cymbal_inventory e l'elenco dei negozi nella tabella cymbal_stores. Dobbiamo calcolare i dati vettoriali in base alle descrizioni dei nostri prodotti e utilizzeremo la funzione embedding. Utilizzando la funzione, useremo l'integrazione di Vertex AI per calcolare i dati vettoriali in base alle descrizioni dei nostri prodotti e aggiungerli alla tabella. Per saperne di più sulla tecnologia utilizzata, consulta la documentazione.
È facile generarlo per poche righe, ma come si fa a renderlo efficiente se ne abbiamo migliaia? Qui mostrerò come generare e gestire gli incorporamenti per tabelle di grandi dimensioni. Puoi anche leggere di più su diverse opzioni e tecniche nella guida.
Attiva la generazione rapida di incorporamenti
Connettiti al database utilizzando psql dalla tua VM utilizzando l'IP dell'istanza AlloyDB e la password di postgres:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Verifica la versione dell'estensione google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
La versione deve essere 1.5.2 o successive. Ecco un esempio di output:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
La versione predefinita deve essere 1.5.2 o successive, ma se la tua istanza mostra una versione precedente, probabilmente deve essere aggiornata. Controlla se la manutenzione è stata disattivata per l'istanza.
Dobbiamo quindi verificare il flag di database. Dobbiamo attivare il flag google_ml_integration.enable_faster_embedding_generation. Nella stessa sessione psql, controlla il valore del flag.
show google_ml_integration.enable_faster_embedding_generation;
Se il flag si trova nella posizione corretta, l'output previsto è simile al seguente:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Se invece è impostato su "off", dobbiamo aggiornare l'istanza. Puoi farlo utilizzando la console web o il comando gcloud, come descritto nella documentazione. Di seguito mostro come farlo utilizzando il comando gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Potrebbero essere necessari alcuni minuti, ma alla fine il valore del flag dovrebbe essere impostato su "on". Dopodiché, puoi procedere con i passaggi successivi.
Creare una colonna di incorporamento
Connettiti al database utilizzando psql e crea una colonna virtuale con i dati vettoriali utilizzando la funzione di embedding nella tabella cymbal_products. La funzione di embedding restituisce i dati vettoriali da Vertex AI in base ai dati forniti dalla colonna product_description.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Nella sessione psql dopo la connessione al database, esegui:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Il comando creerà la colonna virtuale e la compilerà con i dati vettoriali.
Output console previsto:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Ora possiamo generare incorporamenti utilizzando batch di 50 righe ciascuno. Puoi sperimentare diverse dimensioni dei batch e vedere se il tempo di esecuzione cambia. Nella stessa sessione psql esegui:
Attiva la misurazione del tempo per calcolare la durata:
\timing
Esegui il comando:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
L'output della console mostra meno di 2 secondi per la generazione dell'incorporamento:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Per impostazione predefinita, gli incorporamenti non verranno aggiornati se la colonna product_description corrispondente viene aggiornata o se viene inserita una nuova riga. Tuttavia, puoi farlo definendo il parametro incremental_refresh_mode. Creiamo una colonna "product_embeddings" e rendiamola aggiornabile automaticamente.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Ora, se inseriamo una nuova riga nella tabella.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Possiamo confrontare la differenza nelle colonne utilizzando la query:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
Nell'output possiamo vedere che, mentre la colonna embedding rimane vuota, la colonna product_embedding viene aggiornata automaticamente.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Esegui ricerca di somiglianze
Ora possiamo eseguire la ricerca utilizzando la ricerca di somiglianze in base ai valori dei vettori calcolati per le descrizioni e al valore del vettore ottenuto per la nostra richiesta.
La query SQL può essere eseguita dalla stessa interfaccia a riga di comando psql o, in alternativa, da AlloyDB Studio. Qualsiasi output complesso e multiriga potrebbe avere un aspetto migliore in AlloyDB Studio.
Connettersi ad AlloyDB Studio
Nei capitoli seguenti, tutti i comandi SQL che richiedono la connessione al database possono essere eseguiti in alternativa in AlloyDB Studio. Per eseguire il comando, devi aprire l'interfaccia della console web per il cluster AlloyDB facendo clic sull'istanza principale.
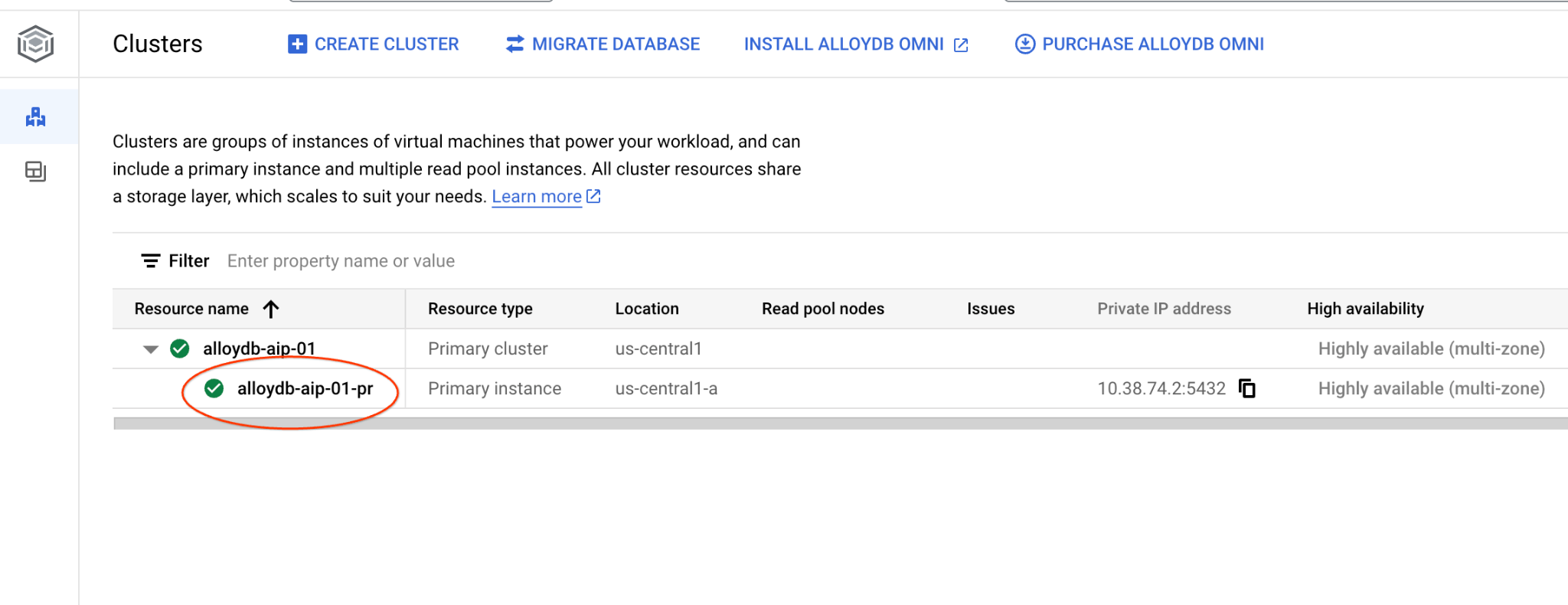
Quindi, fai clic su AlloyDB Studio a sinistra:
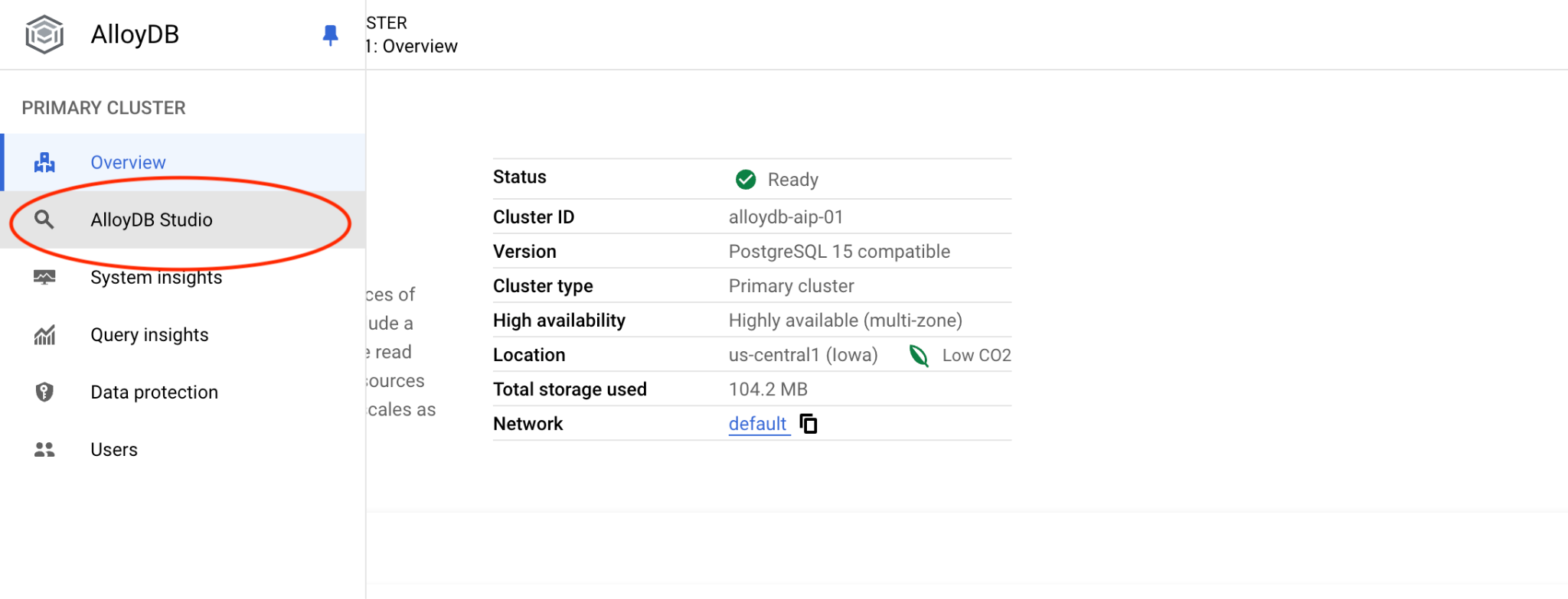
Scegli il database quickstart_db, l'utente postgres e fornisci la password annotata durante la creazione del cluster. Poi fai clic sul pulsante "Autentica".
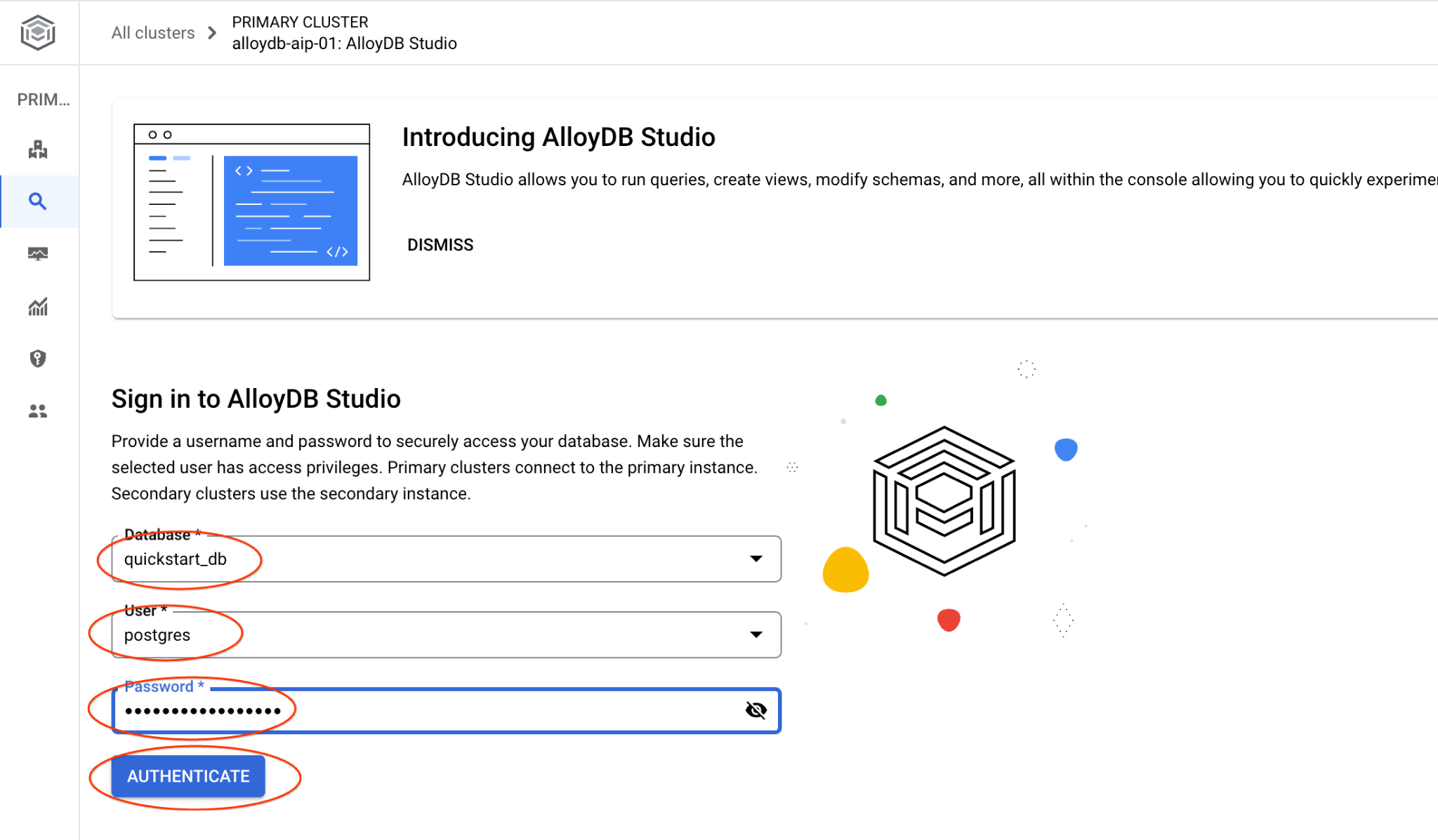
Si aprirà l'interfaccia di AlloyDB Studio. Per eseguire i comandi nel database, fai clic sulla scheda "Editor 1" a destra.
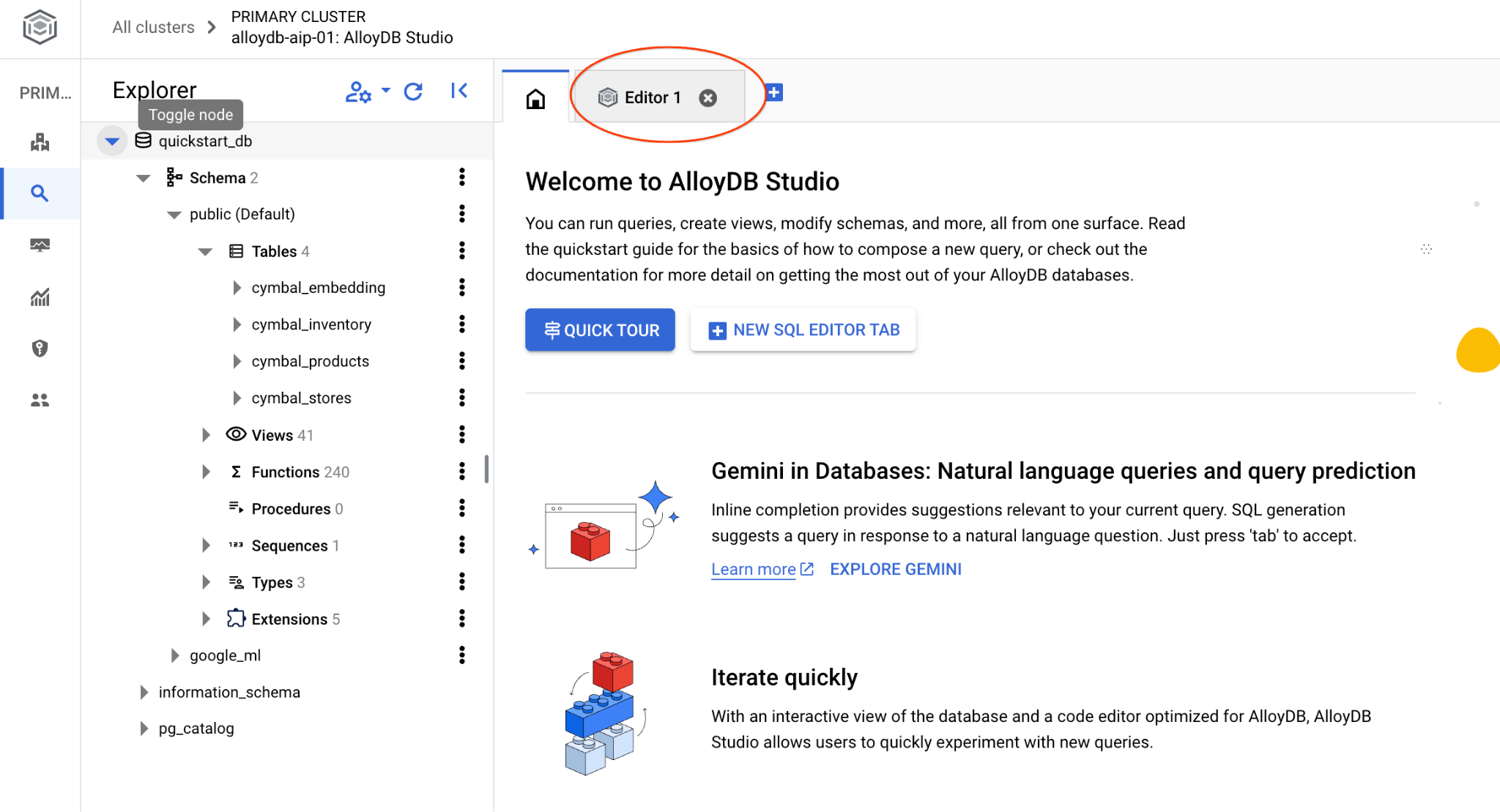
Si apre l'interfaccia in cui puoi eseguire i comandi SQL
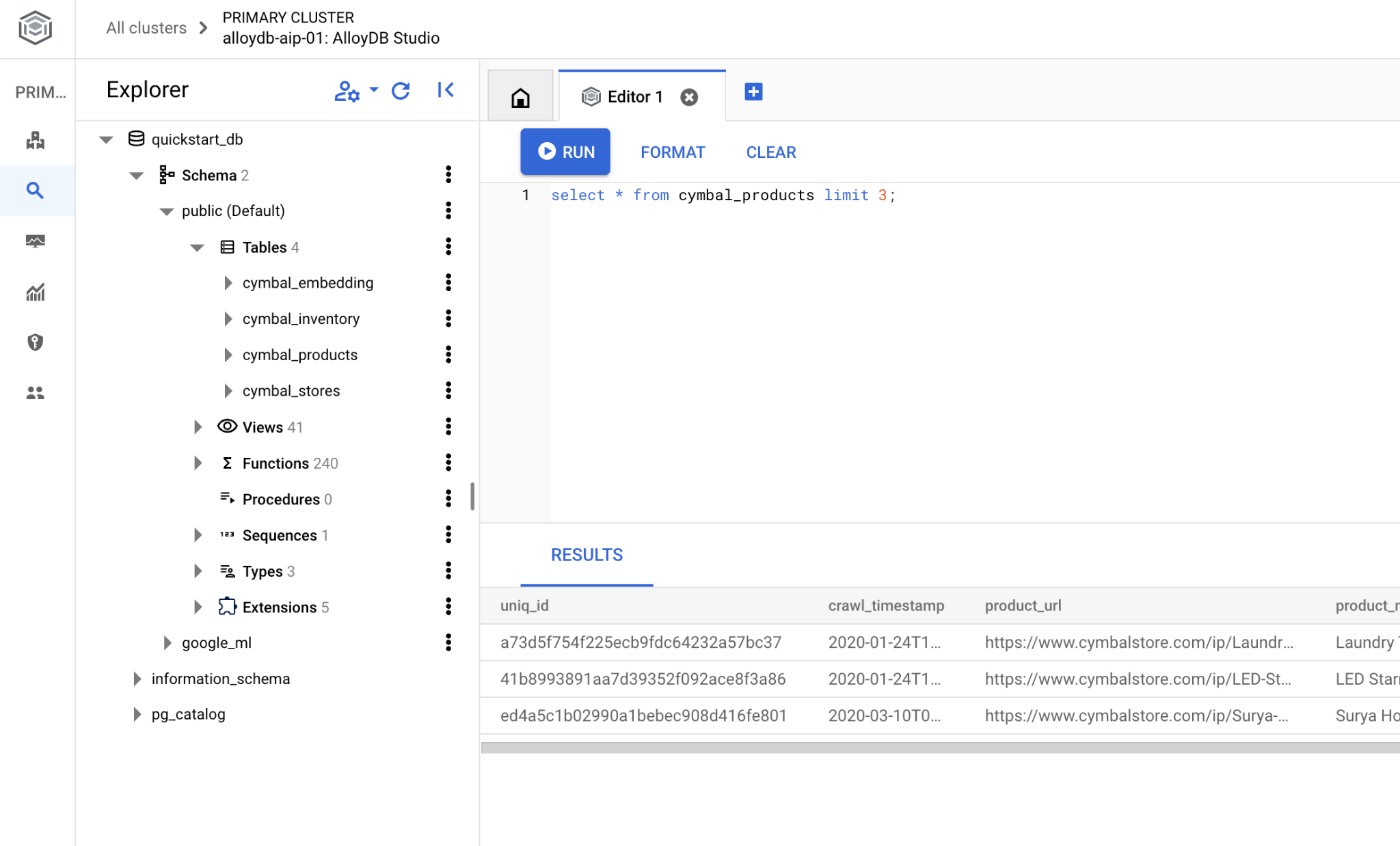
Se preferisci utilizzare psql da riga di comando, segui il percorso alternativo e connettiti al database dalla sessione SSH della VM come descritto nei capitoli precedenti.
Esegui la ricerca di somiglianze da psql
Se la sessione del database è stata disconnessa, connettiti di nuovo al database utilizzando psql o AlloyDB Studio.
Connettiti al database:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Esegui una query per ottenere un elenco dei prodotti disponibili più strettamente correlati alla richiesta di un cliente. La richiesta che passeremo a Vertex AI per ottenere il valore del vettore è: "Quali tipi di alberi da frutto crescono bene qui?"
Ecco la query che puoi eseguire per scegliere i primi 10 elementi più adatti alla nostra richiesta:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Ecco l'output previsto:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Migliora risposta
Puoi migliorare la risposta a un'applicazione client utilizzando il risultato della query e preparare un output significativo utilizzando i risultati della query forniti come parte del prompt per il modello linguistico di base di AI generativa di Vertex AI.
A questo scopo, prevediamo di generare un file JSON con i risultati della ricerca vettoriale, quindi di utilizzare questo file JSON generato come aggiunta a un prompt per un modello LLM di testo in Vertex AI per creare un output significativo. Nel primo passaggio generiamo il JSON, poi lo testiamo in Vertex AI Studio e nell'ultimo passaggio lo incorporiamo in un'istruzione SQL che può essere utilizzata in un'applicazione.
Genera output in formato JSON
Modifica la query per generare l'output in formato JSON e restituire una sola riga da passare a Vertex AI
Ecco un esempio di query:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ecco il JSON previsto nell'output:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Esegui il prompt in Vertex AI Studio
Possiamo utilizzare il JSON generato per fornirlo come parte del prompt al modello di testo di AI generativa in Vertex AI Studio
Apri Vertex AI Studio nella console cloud.
Se non l'hai mai usato, potrebbe chiederti di accettare i termini di utilizzo. Premi il pulsante "Accetta e continua".
Scrivi il prompt nell'interfaccia.
Potrebbe chiederti di attivare API aggiuntive, ma puoi ignorare la richiesta. Non abbiamo bisogno di API aggiuntive per completare il lab.
Ecco il prompt che utilizzeremo con l'output JSON della prima query sugli alberi:
Sei un consulente amichevole che aiuta a trovare un prodotto in base alle esigenze del cliente.
In base alla richiesta del cliente, abbiamo caricato un elenco di prodotti strettamente correlati alla ricerca.
L'elenco in formato JSON con l'elenco dei valori come {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Ecco l'elenco dei prodotti:
{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. È un d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Il cliente ha chiesto: "Quale albero cresce meglio qui?"
Devi fornire informazioni sul prodotto, sul prezzo e alcune informazioni supplementari
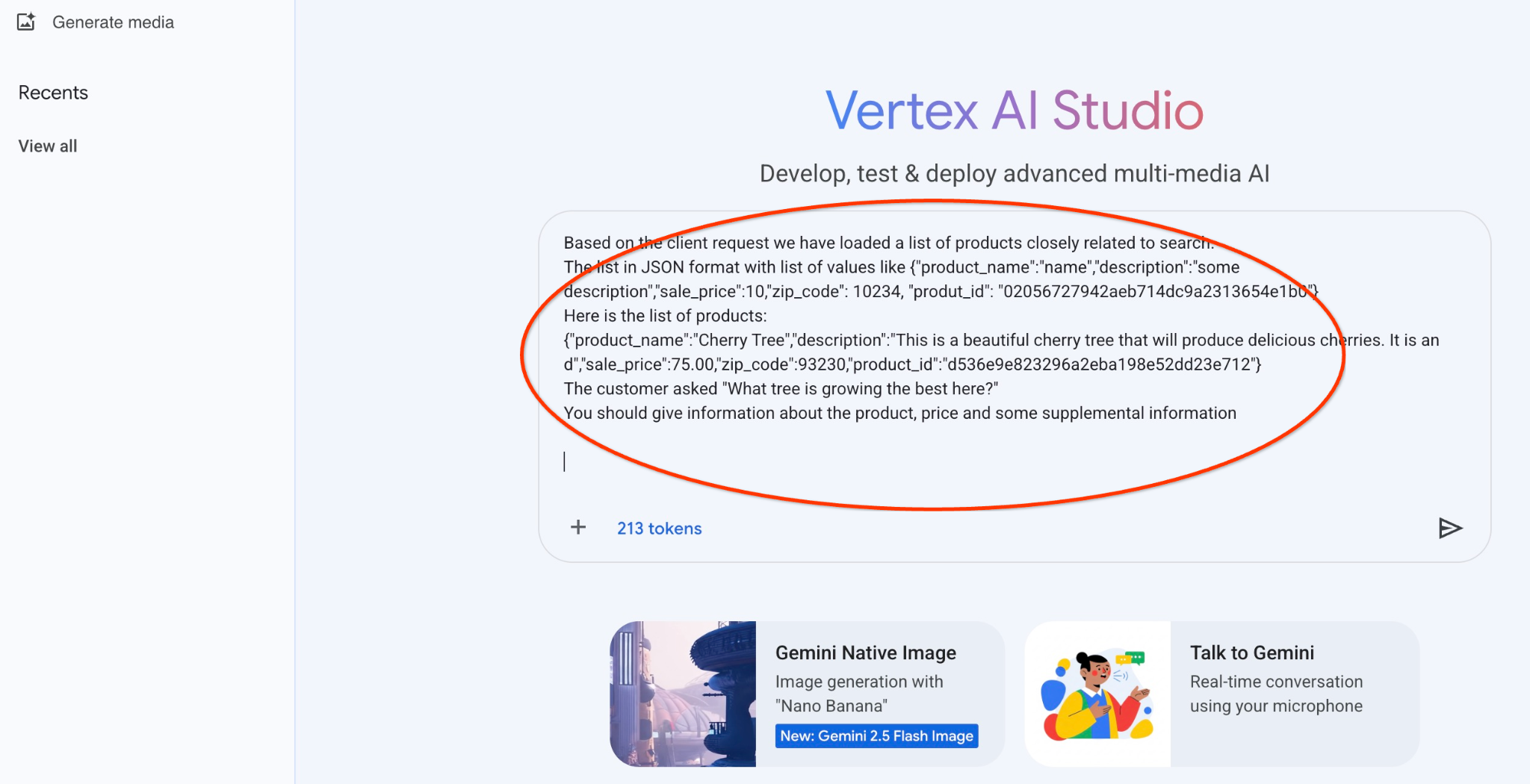
Ecco il risultato quando eseguiamo il prompt con i nostri valori JSON e utilizzando il modello gemini-2.5-flash-light:
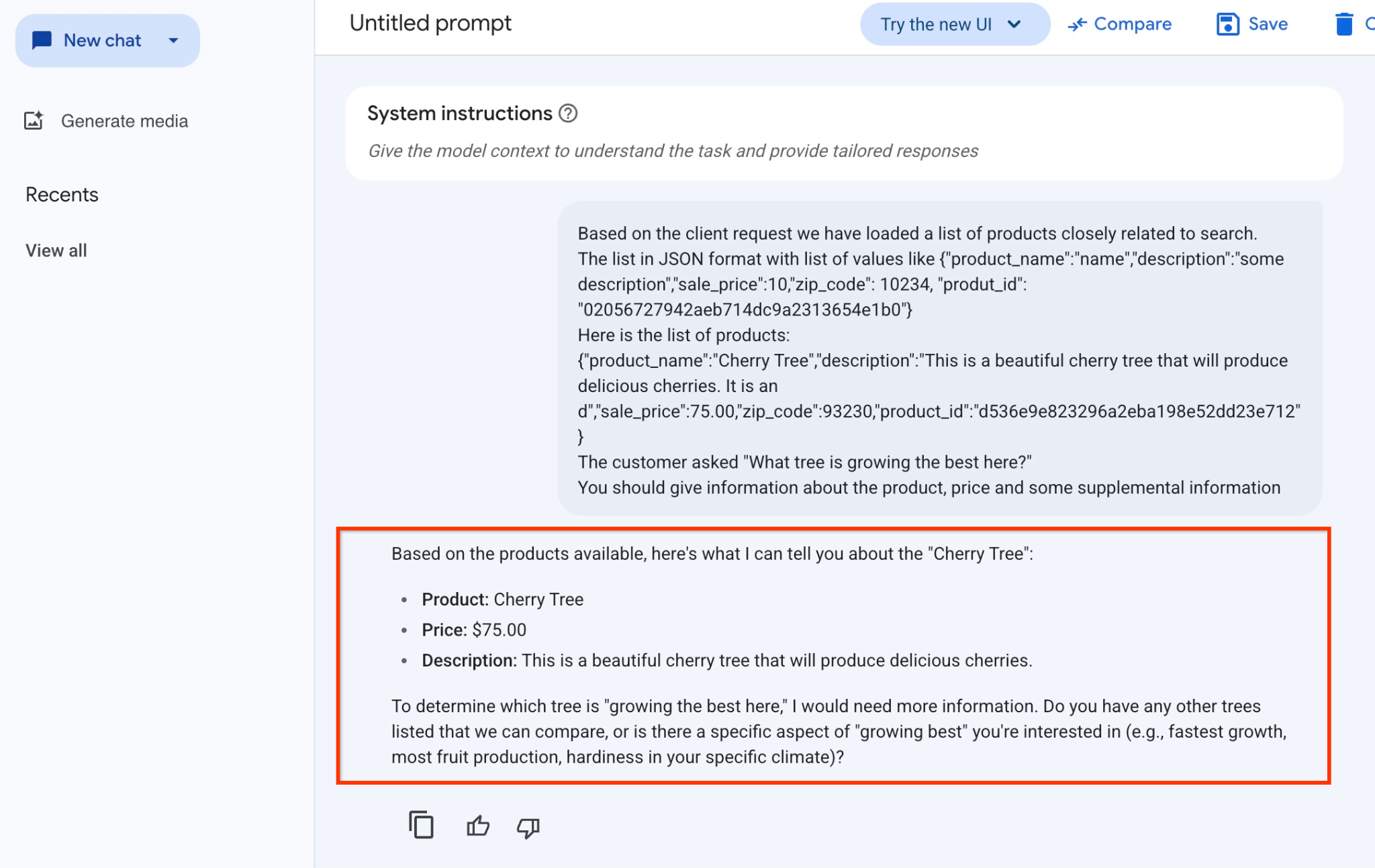
Di seguito è riportata la risposta ottenuta dal modello in questo esempio. Tieni presente che la tua risposta potrebbe essere diversa a causa delle modifiche al modello e ai parametri nel tempo:
"In base ai prodotti disponibili, ecco cosa posso dirti di "Cherry Tree":
Prodotto: Ciliegio
Prezzo: 75,00 $
Descrizione: questo è un bellissimo ciliegio che produrrà deliziose ciliegie.
Per determinare quale albero "cresce meglio qui", avrei bisogno di maggiori informazioni. Hai altri alberi elencati che possiamo confrontare o c'è un aspetto specifico della"migliore crescita" che ti interessa (ad es. crescita più rapida, maggiore produzione di frutta, resistenza nel tuo clima specifico)?"
Esegui il prompt in PSQL
Possiamo utilizzare l'integrazione di AlloyDB AI con Vertex AI per ottenere la stessa risposta da un modello generativo utilizzando SQL direttamente nel database. Tuttavia, per utilizzare il modello gemini-1.5-flash dobbiamo prima registrarlo.
Verifica l'estensione google_ml_integration. Deve avere la versione 1.4.2 o successive.
Connettiti al database quickstart_db da psql come mostrato in precedenza (o utilizza AlloyDB Studio) ed esegui:
SELECT extversion from pg_extension where extname='google_ml_integration';
Controlla il flag di database google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
L'output previsto dalla sessione psql è "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Se viene visualizzato "off", dobbiamo impostare il flag di database google_ml_integration.enable_model_support su "on". Per farlo, puoi utilizzare l'interfaccia della console web di AlloyDB o eseguire il seguente comando gcloud.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
L'esecuzione del comando in background richiede circa 1-3 minuti. A questo punto, puoi verificare di nuovo il flag.
Per la nostra query abbiamo bisogno di due modelli. Il primo è il modello text-embedding-005 già utilizzato, mentre il secondo è uno dei modelli Google Gemini generici.
Partiamo dal modello di text embedding. Per registrare l'esecuzione del modello in psql o AlloyDB Studio, esegui questo codice:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Il modello successivo da registrare è gemini-2.0-flash-001, che verrà utilizzato per generare l'output di facile utilizzo.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Puoi sempre verificare l'elenco dei modelli registrati selezionando le informazioni da google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Ecco un output di esempio
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Ora possiamo utilizzare il JSON generato in una sottoquery per fornirlo come parte del prompt al modello di testo di AI generativa utilizzando SQL.
Nella sessione psql o AlloyDB Studio al database, esegui la query
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Ecco l'output previsto. L'output potrebbe variare a seconda della versione del modello e dei parametri:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Crea indice vettoriale
Il nostro set di dati è piuttosto piccolo e il tempo di risposta dipende principalmente dall'interazione con i modelli di AI. Tuttavia, quando hai milioni di vettori, la parte di ricerca vettoriale può richiedere una parte significativa del nostro tempo di risposta e sovraccaricare il sistema. Per migliorare, possiamo creare un indice in base ai nostri vettori.
Crea indice ScaNN
Per creare l'indice SCANN, dobbiamo abilitare un'altra estensione. L'estensione alloydb_scann fornisce un'interfaccia per lavorare con l'indice vettoriale di tipo ANN utilizzando l'algoritmo ScaNN di Google.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Output previsto:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
L'indice può essere creato in modalità MANUALE o AUTOMATICA. La modalità MANUALE è attivata per impostazione predefinita e puoi creare un indice e gestirlo come qualsiasi altro indice. Tuttavia, se attivi la modalità AUTO, puoi creare l'indice che non richiede alcuna manutenzione da parte tua. Puoi leggere in dettaglio tutte le opzioni nella documentazione. Qui ti mostrerò come attivare la modalità AUTO e creare l'indice. Nel nostro caso non abbiamo righe sufficienti per creare l'indice in modalità AUTO, quindi lo creeremo come MANUALE.
Nell'esempio seguente lascio la maggior parte dei parametri come predefiniti e fornisco solo un numero di partizioni (num_leaves) per l'indice:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Per informazioni sulla regolazione dei parametri di indice, consulta la documentazione.
Output previsto:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Confronta la risposta
Ora possiamo eseguire la query di ricerca vettoriale in modalità EXPLAIN e verificare se l'indice è stato utilizzato.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output previsto (modificato per chiarezza):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Dall'output possiamo vedere chiaramente che la query utilizzava "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
Se eseguiamo la query senza explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output previsto:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Possiamo vedere che il risultato è lo stesso ciliegio che si trovava in cima alla nostra ricerca senza indice. A volte potrebbe non essere così e la risposta può restituire non lo stesso albero, ma altri alberi dall'alto. Pertanto, l'indice ci fornisce un rendimento comunque abbastanza preciso da fornire buoni risultati.
Puoi provare diversi indici disponibili per i vettori e altri lab ed esempi con l'integrazione di Langchain disponibili nella pagina della documentazione.
11. Liberare spazio
Elimina le istanze e il cluster AlloyDB al termine del lab.
Elimina il cluster AlloyDB e tutte le istanze
Se hai utilizzato la versione di prova di AlloyDB. Non eliminare il cluster di prova se prevedi di testare altri lab e risorse utilizzando il cluster di prova. Non potrai creare un altro cluster di prova nello stesso progetto.
Il cluster viene eliminato con l'opzione force, che elimina anche tutte le istanze appartenenti al cluster.
In Cloud Shell definisci le variabili di progetto e di ambiente se la connessione è stata interrotta e tutte le impostazioni precedenti sono andate perse:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Elimina il cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Elimina i backup di AlloyDB
Elimina tutti i backup AlloyDB per il cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Ora possiamo eliminare la nostra VM
Elimina VM GCE
In Cloud Shell, esegui:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Output console previsto:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Complimenti
Congratulazioni per aver completato il codelab.
Questo lab fa parte del percorso di apprendimento per l'AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
#ProductionReadyAI.
Argomenti trattati
- Come eseguire il deployment del cluster e dell'istanza principale di AlloyDB
- Come connettersi ad AlloyDB da una VM Google Compute Engine
- Come creare un database e abilitare AlloyDB AI
- Come caricare i dati nel database
- Come utilizzare AlloyDB Studio
- Come utilizzare il modello di embedding Vertex AI in AlloyDB
- Come utilizzare Vertex AI Studio
- Come arricchire il risultato utilizzando il modello generativo Vertex AI
- Come migliorare il rendimento utilizzando l'indice vettoriale
13. Sondaggio
Output: