
1. Wprowadzenie
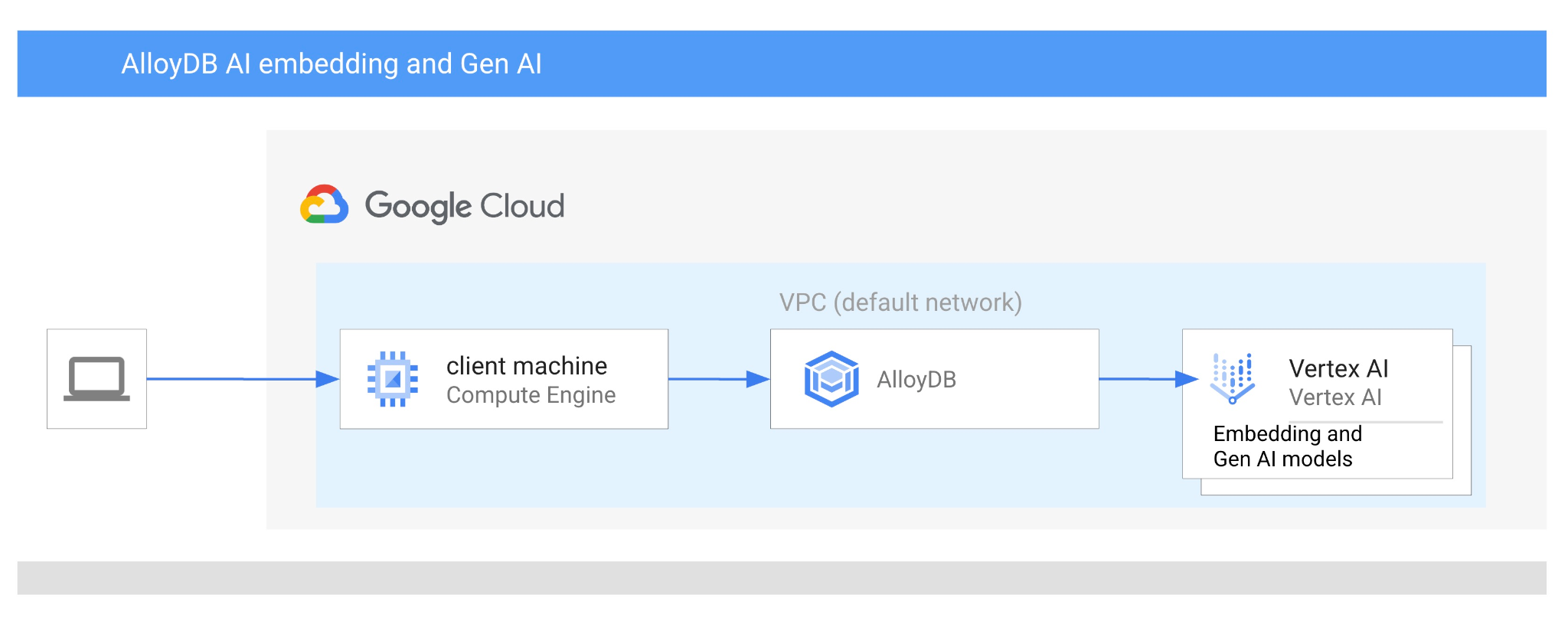
Z tego ćwiczenia dowiesz się, jak używać AlloyDB AI, łącząc wyszukiwanie wektorowe z wektorami dystrybucyjnymi Vertex AI. Ten moduł należy do kolekcji modułów poświęconych funkcjom AlloyDB AI. Więcej informacji znajdziesz na stronie AlloyDB AI w dokumentacji.
Wymagania wstępne
- Podstawowa wiedza o konsoli Google Cloud
- Podstawowe umiejętności w zakresie interfejsu wiersza poleceń i powłoki Google
Czego się nauczysz
- Jak wdrożyć klaster i instancję główną AlloyDB
- Jak połączyć się z AlloyDB z maszyny wirtualnej Google Compute Engine
- Tworzenie bazy danych i włączanie AlloyDB AI
- Wczytywanie danych do bazy danych
- Jak korzystać z AlloyDB Studio
- Jak używać modelu wektorów dystrybucyjnych Vertex AI w AlloyDB
- Jak korzystać z Vertex AI Studio
- Jak wzbogacić wynik za pomocą modelu generatywnego Vertex AI
- Jak poprawić skuteczność za pomocą indeksu wektorów
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka, np. Chrome;
2. Konfiguracja i wymagania
Konfiguracja projektu
- Zaloguj się w konsoli Google Cloud. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
- Utwórz nowy projekt lub użyj istniejącego. Aby utworzyć nowy projekt w konsoli Google Cloud, w nagłówku kliknij przycisk Wybierz projekt. Otworzy się okno wyskakujące.

W oknie Wybierz projekt kliknij przycisk Nowy projekt, który otworzy okno dialogowe nowego projektu.
W oknie dialogowym wpisz preferowaną nazwę projektu i wybierz lokalizację.
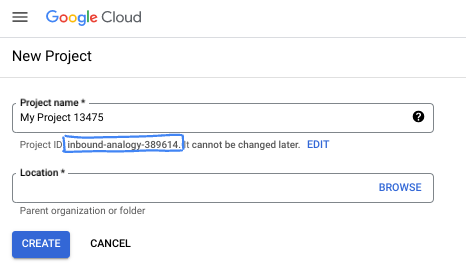
- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Nazwa projektu nie jest używana przez interfejsy API Google i można ją w każdej chwili zmienić.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Google Cloud automatycznie generuje unikalny identyfikator, ale możesz go dostosować. Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować kolejny losowy identyfikator lub podać własny, aby sprawdzić jego dostępność. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu, który jest zwykle oznaczony zmienną PROJECT_ID.
- Warto wiedzieć, że istnieje trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
Włącz płatności
Płatności możesz włączyć na 2 sposoby. Możesz użyć osobistego konta rozliczeniowego lub wykorzystać środki, wykonując te czynności.
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 3 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchom Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Możesz też nacisnąć G, a potem S. Ta sekwencja aktywuje Cloud Shell, jeśli korzystasz z konsoli Google Cloud. Możesz też użyć tego linku.
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Zanim zaczniesz
Włącz API
Dane wyjściowe:
Aby korzystać z usług AlloyDB, Compute Engine, usług sieciowych i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
Włączanie interfejsów API
W terminalu Cloud Shell sprawdź, czy identyfikator projektu jest skonfigurowany:
gcloud config set project [YOUR-PROJECT-ID]
Ustaw zmienną środowiskową PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Włącz wszystkie niezbędne interfejsy API:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Oczekiwane dane wyjściowe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Przedstawiamy interfejsy API
- AlloyDB API (
alloydb.googleapis.com) umożliwia tworzenie klastrów AlloyDB for PostgreSQL, zarządzanie nimi i ich skalowanie. Jest to w pełni zarządzana usługa bazy danych zgodnej z PostgreSQL, która została zaprojektowana z myślą o wymagających firmowych zbiorach zadań transakcyjnych i analitycznych. - Compute Engine API (
compute.googleapis.com) umożliwia tworzenie maszyn wirtualnych, dysków trwałych i ustawień sieciowych oraz zarządzanie nimi. Zapewnia podstawową infrastrukturę jako usługę (IaaS) potrzebną do uruchamiania zbiorów zadań i hostowania infrastruktury bazowej dla wielu usług zarządzanych. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) umożliwia zautomatyzowane zarządzanie metadanymi i konfiguracją projektu Google Cloud. Umożliwia organizowanie zasobów, obsługę zasad Identity and Access Management (IAM) i weryfikowanie uprawnień w hierarchii projektu. - Service Networking API (
servicenetworking.googleapis.com) umożliwia automatyzację konfiguracji prywatnej łączności między siecią Virtual Private Cloud (VPC) a usługami zarządzanymi Google. Jest to szczególnie ważne w przypadku ustanawiania dostępu do usług za pomocą prywatnego adresu IP, takich jak AlloyDB, aby mogły one bezpiecznie komunikować się z innymi zasobami. - Interfejs Vertex AI API (
aiplatform.googleapis.com) umożliwia aplikacjom tworzenie, wdrażanie i skalowanie modeli uczenia maszynowego. Zapewnia on ujednolicony interfejs dla wszystkich usług AI w Google Cloud, w tym dostęp do modeli generatywnej AI (takich jak Gemini) i trenowania modeli niestandardowych.
Opcjonalnie możesz skonfigurować domyślny region, aby używać modeli wektorów dystrybucyjnych Vertex AI. Więcej informacji o lokalizacjach, w których jest dostępna usługa Vertex AI W przykładzie używamy regionu us-central1.
gcloud config set compute/region us-central1
4. Wdrażanie AlloyDB
Przed utworzeniem klastra AlloyDB musimy mieć dostępny zakres prywatnych adresów IP w naszej sieci VPC, który będzie używany przez przyszłą instancję AlloyDB. Jeśli go nie mamy, musimy go utworzyć i przypisać do użytku przez wewnętrzne usługi Google. Dopiero wtedy będziemy mogli utworzyć klaster i instancję.
Tworzenie prywatnego zakresu adresów IP
Musimy skonfigurować prywatny dostęp do usług w naszej sieci VPC dla AlloyDB. Zakładamy, że w projekcie mamy sieć VPC „default”, która będzie używana do wszystkich działań.
Utwórz zakres prywatnych adresów IP:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Utwórz połączenie prywatne, używając przydzielonego zakresu adresów IP:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Tworzenie klastra AlloyDB
W tej sekcji utworzymy klaster AlloyDB w regionie us-central1.
Określ hasło użytkownika postgres. Możesz zdefiniować własne hasło lub użyć funkcji losowej, aby je wygenerować.
export PGPASSWORD=`openssl rand -hex 12`
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Zapisz hasło do PostgreSQL, aby użyć go w przyszłości.
echo $PGPASSWORD
To hasło będzie Ci potrzebne w przyszłości do połączenia z instancją jako użytkownik postgres. Sugeruję zapisanie go lub skopiowanie w inne miejsce, aby móc go później użyć.
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Tworzenie bezpłatnego klastra próbnego
Jeśli nie używasz jeszcze AlloyDB, możesz utworzyć bezpłatny klaster próbny:
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Tworzenie klastra AlloyDB Standard
Jeśli nie jest to Twój pierwszy klaster AlloyDB w projekcie, utwórz klaster standardowy.
Określ region i nazwę klastra AlloyDB. Użyjemy regionu us-central1 i nazwy klastra alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Uruchom polecenie, aby utworzyć klaster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Oczekiwane dane wyjściowe konsoli:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Utwórz instancję główną AlloyDB dla klastra w tej samej sesji Cloud Shell. Jeśli połączenie zostanie przerwane, musisz ponownie zdefiniować zmienne środowiskowe regionu i nazwy klastra.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Łączenie z AlloyDB
AlloyDB jest wdrażana przy użyciu połączenia prywatnego, więc do pracy z bazą danych potrzebujemy maszyny wirtualnej z zainstalowanym klientem PostgreSQL.
Wdrażanie maszyny wirtualnej GCE
Utwórz maszynę wirtualną GCE w tym samym regionie i sieci VPC co klaster AlloyDB.
W Cloud Shell wykonaj to polecenie:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Zainstaluj klienta Postgres
Zainstaluj oprogramowanie klienta PostgreSQL na wdrożonej maszynie wirtualnej.
Połącz się z maszyną wirtualną:
gcloud compute ssh instance-1 --zone=us-central1-a
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Zainstaluj oprogramowanie, uruchamiając w maszynie wirtualnej to polecenie:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Oczekiwane dane wyjściowe konsoli:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Łączenie się z instancją
Połącz się z instancją podstawową z maszyny wirtualnej za pomocą psql.
Na tej samej karcie Cloud Shell, na której otwarto sesję SSH z maszyną wirtualną instance-1.
Aby połączyć się z AlloyDB z maszyny wirtualnej GCE, użyj podanej wartości hasła AlloyDB (PGPASSWORD) i identyfikatora klastra AlloyDB:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Oczekiwane dane wyjściowe konsoli:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Zamknij sesję psql:
exit
6. Przygotowywanie bazy danych
Musimy utworzyć bazę danych, włączyć integrację z Vertex AI, utworzyć obiekty bazy danych i zaimportować dane.
Przyznawanie AlloyDB niezbędnych uprawnień
Dodaj uprawnienia Vertex AI do agenta usługi AlloyDB.
Otwórz kolejną kartę Cloud Shell, klikając znak „+” u góry.
Na nowej karcie Cloud Shell wykonaj to polecenie:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Zamknij kartę, wpisując na niej polecenie „exit”:
exit
Utwórz bazę danych
Szybki start dotyczący tworzenia bazy danych.
W sesji maszyny wirtualnej GCE wykonaj to polecenie:
Utwórz bazę danych:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Oczekiwane dane wyjściowe konsoli:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Włączanie integracji z Vertex AI
Włącz integrację z Vertex AI i rozszerzenia pgvector w bazie danych.
Na maszynie wirtualnej GCE wykonaj te czynności:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Oczekiwane dane wyjściowe konsoli:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Importuj dane
Pobierz przygotowane dane i zaimportuj je do nowej bazy danych.
Na maszynie wirtualnej GCE wykonaj te czynności:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Oczekiwane dane wyjściowe konsoli:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Obliczanie wektorów dystrybucyjnych
Po zaimportowaniu danych otrzymaliśmy dane o produktach w tabeli cymbal_products, asortyment pokazujący liczbę dostępnych produktów w każdym sklepie w tabeli cymbal_inventory oraz listę sklepów w tabeli cymbal_stores. Musimy obliczyć dane wektorowe na podstawie opisów naszych produktów i w tym celu użyjemy funkcji embedding. Za pomocą tej funkcji wykorzystamy integrację z Vertex AI, aby obliczyć dane wektorowe na podstawie opisów produktów i dodać je do tabeli. Więcej informacji o używanej technologii znajdziesz w dokumentacji.
Łatwo jest wygenerować go dla kilku wierszy, ale jak sprawić, aby był wydajny, gdy mamy ich tysiące? Pokażę, jak generować i zarządzać osadzaniem w przypadku dużych tabel. Więcej informacji o różnych opcjach i metodach znajdziesz w przewodniku.
Włącz szybkie generowanie osadzania
Połącz się z bazą danych za pomocą psql z maszyny wirtualnej, używając adresu IP instancji AlloyDB i hasła postgres:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Sprawdź wersję rozszerzenia google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Wersja powinna być co najmniej 1.5.2. Oto przykład danych wyjściowych:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
Domyślna wersja powinna być nowsza niż 1.5.2, ale jeśli Twoja instancja pokazuje starszą wersję, prawdopodobnie wymaga aktualizacji. Sprawdź, czy konserwacja została wyłączona w przypadku instancji.
Następnie musimy zweryfikować flagę bazy danych. Musimy włączyć flagę google_ml_integration.enable_faster_embedding_generation. W tej samej sesji psql sprawdź wartość flagi.
show google_ml_integration.enable_faster_embedding_generation;
Jeśli flaga jest w prawidłowej pozycji, oczekiwane dane wyjściowe wyglądają tak:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Jeśli jednak wyświetla się „wyłączone”, musimy zaktualizować instancję. Możesz to zrobić za pomocą konsoli internetowej lub polecenia gcloud, zgodnie z opisem w dokumentacji. Poniżej pokazuję, jak to zrobić za pomocą polecenia gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Może to potrwać kilka minut, ale ostatecznie wartość flagi powinna zmienić się na „włączona”. Następnie możesz przejść do kolejnych kroków.
Tworzenie kolumny wektorów dystrybucyjnych
Połącz się z bazą danych za pomocą psql i utwórz kolumnę wirtualną z danymi wektorowymi, korzystając z funkcji osadzania w tabeli cymbal_products. Funkcja osadzania zwraca dane wektorowe z Vertex AI na podstawie danych z kolumny product_description.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
W sesji psql po połączeniu się z bazą danych wykonaj to polecenie:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Polecenie utworzy kolumnę wirtualną i wypełni ją danymi wektorowymi.
Oczekiwane dane wyjściowe konsoli:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Teraz możemy generować osadzanie za pomocą partii zawierających po 50 wierszy. Możesz eksperymentować z różnymi rozmiarami partii i sprawdzać, czy wpływa to na czas wykonania. W tej samej sesji psql wykonaj to polecenie:
Włącz pomiar czasu, aby sprawdzić, ile czasu zajmie wykonanie zadania:
\timing
Uruchom to polecenie:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
Dane wyjściowe konsoli pokazują, że wygenerowanie osadzenia zajęło mniej niż 2 sekundy:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Domyślnie osadzanie nie będzie odświeżane, jeśli odpowiednia kolumna product_description zostanie zaktualizowana lub zostanie wstawiony cały nowy wiersz. Możesz to zrobić, definiując parametr incremental_refresh_mode. Utwórzmy kolumnę „product_embeddings” i sprawmy, aby była automatycznie aktualizowana.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
A teraz, jeśli wstawimy nowy wiersz do tabeli.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Różnicę w kolumnach możemy porównać za pomocą zapytania:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
W danych wyjściowych widać, że kolumna embedding pozostaje pusta, a kolumna product_embedding jest automatycznie aktualizowana.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Uruchom wyszukiwanie podobieństw
Możemy teraz przeprowadzić wyszukiwanie podobieństwa na podstawie wartości wektorowych obliczonych dla opisów i wartości wektorowej uzyskanej dla naszego żądania.
Zapytanie SQL można wykonać z tego samego interfejsu wiersza poleceń psql lub alternatywnie z AlloyDB Studio. Wszelkie dane wyjściowe obejmujące wiele wierszy i złożone dane mogą wyglądać lepiej w AlloyDB Studio.
Łączenie się z AlloyDB Studio
W kolejnych rozdziałach wszystkie polecenia SQL wymagające połączenia z bazą danych można alternatywnie wykonywać w AlloyDB Studio. Aby uruchomić to polecenie, otwórz interfejs konsoli internetowej klastra AlloyDB, klikając instancję główną.
Następnie po lewej stronie kliknij AlloyDB Studio:
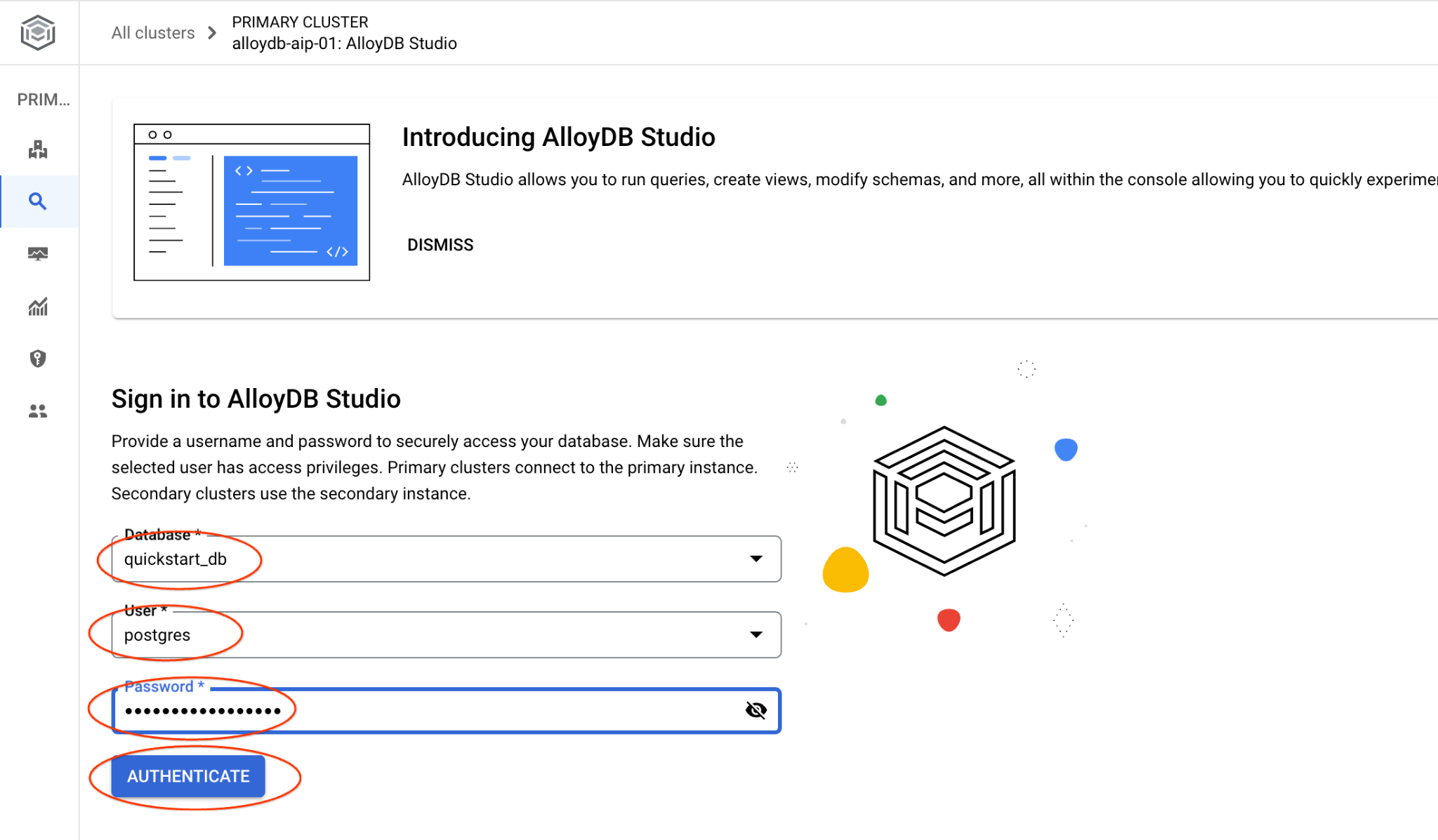
Wybierz bazę danych quickstart_db, użytkownika postgres i podaj hasło, które zostało zapisane podczas tworzenia klastra. Następnie kliknij przycisk „Uwierzytelnij”.
Otworzy się interfejs AlloyDB Studio. Aby uruchomić polecenia w bazie danych, kliknij kartę „Edytor 1” po prawej stronie.
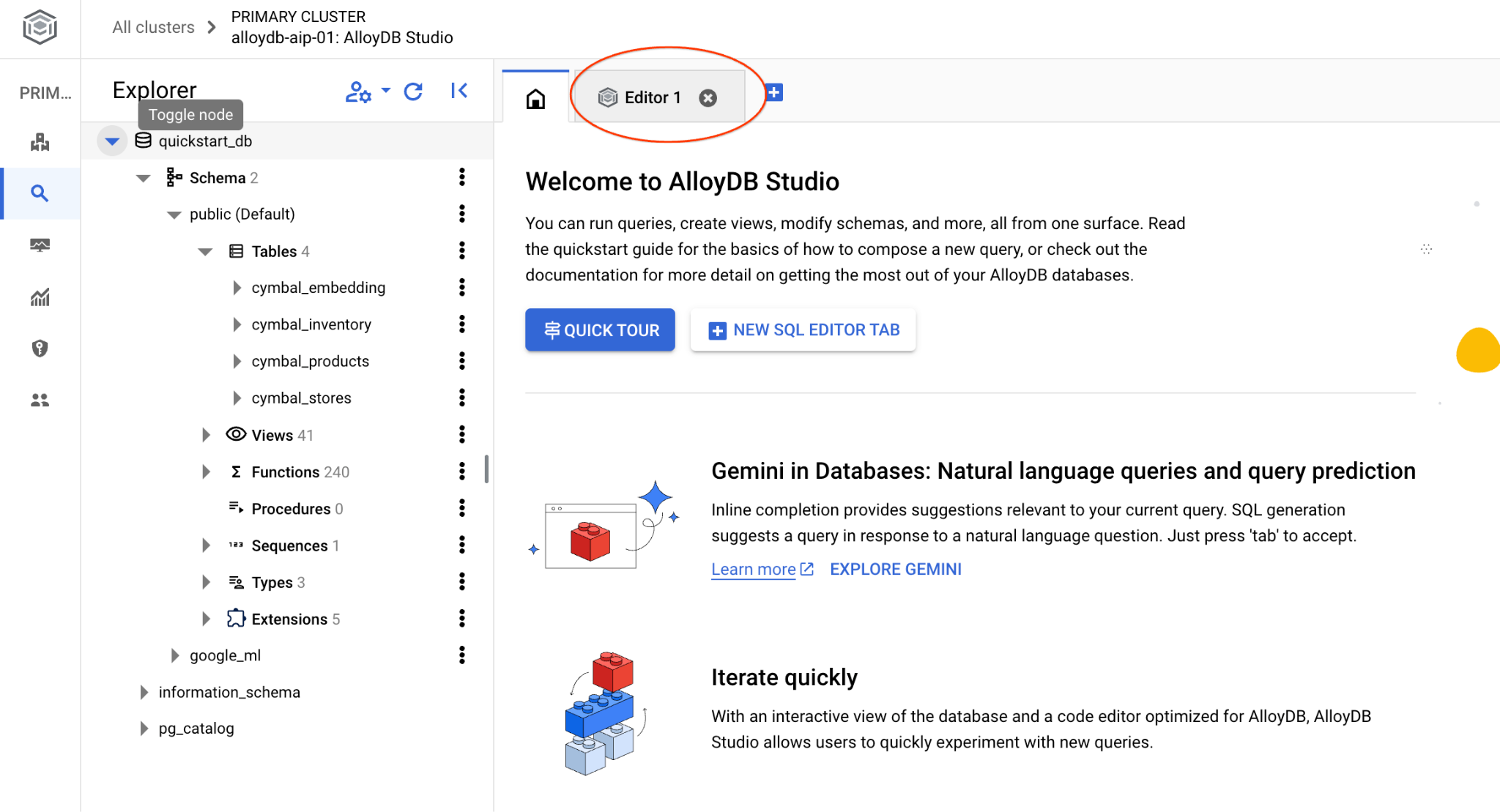
Otworzy się interfejs, w którym możesz uruchamiać polecenia SQL.
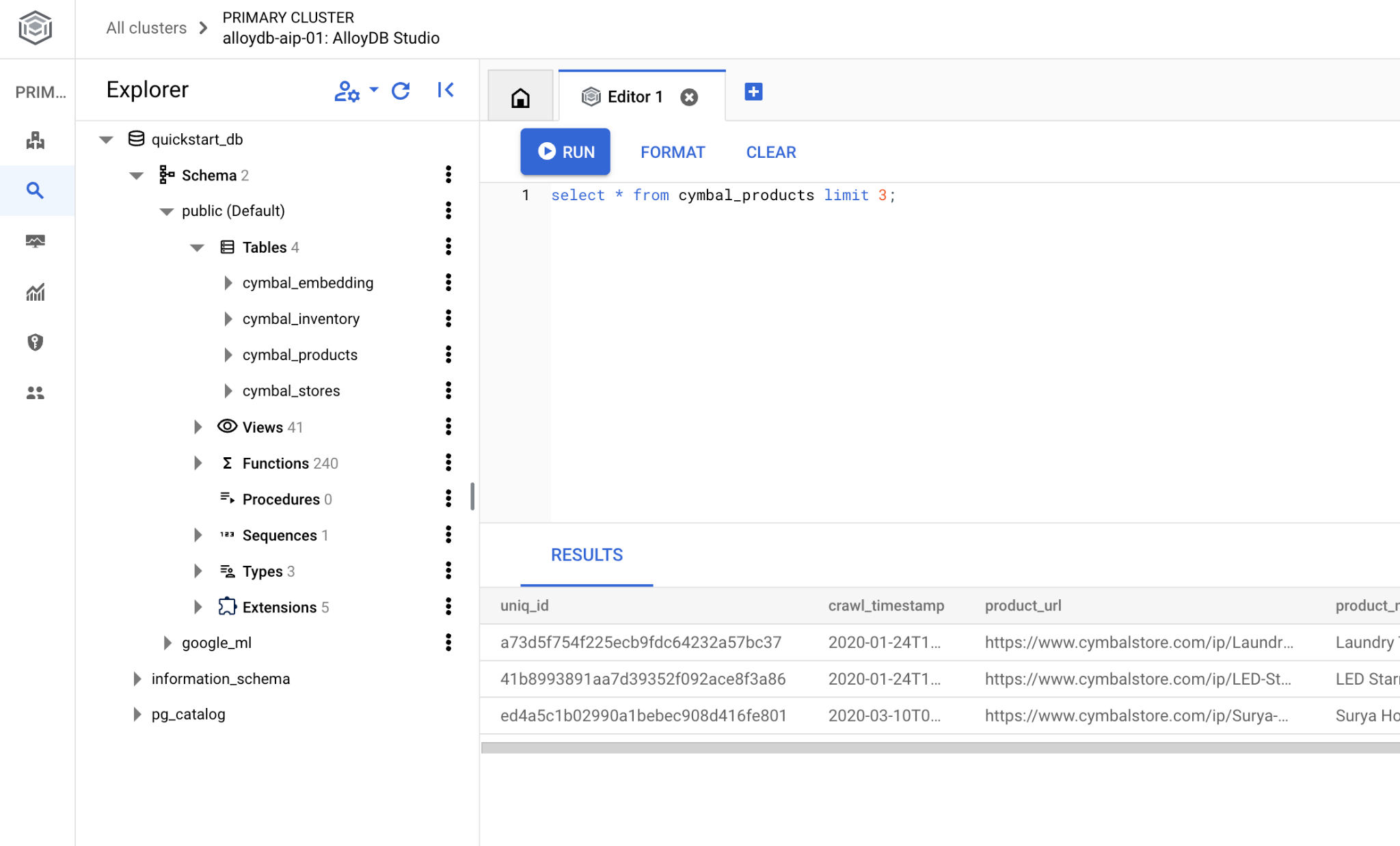
Jeśli wolisz używać wiersza poleceń psql, wybierz alternatywną ścieżkę i połącz się z bazą danych z sesji SSH na maszynie wirtualnej, jak opisano w poprzednich rozdziałach.
Uruchamianie wyszukiwania podobieństw z poziomu psql
Jeśli sesja bazy danych została odłączona, połącz się z bazą danych ponownie za pomocą psql lub AlloyDB Studio.
Połącz się z bazą danych:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Uruchom zapytanie, aby uzyskać listę dostępnych produktów najbardziej zbliżonych do prośby klienta. Żądanie, które przekażemy do Vertex AI, aby uzyskać wartość wektorową, będzie brzmieć: „Jakie drzewa owocowe dobrze tu rosną?”.
Oto zapytanie, które możesz uruchomić, aby wybrać 10 pierwszych elementów najbardziej odpowiednich dla Twojej prośby:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Oto oczekiwane dane wyjściowe:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Ulepsz odpowiedź
Możesz ulepszyć odpowiedź dla aplikacji klienta, korzystając z wyniku zapytania, i przygotować znaczące dane wyjściowe, używając dostarczonych wyników zapytania jako części promptu dla generatywnego modelu językowego Vertex AI.
W tym celu planujemy wygenerować plik JSON z wynikami wyszukiwania wektorowego, a następnie użyć go jako dodatku do prompta dla tekstowego modelu LLM w Vertex AI, aby uzyskać przydatne dane wyjściowe. W pierwszym kroku generujemy kod JSON, następnie testujemy go w Vertex AI Studio, a w ostatnim kroku włączamy go do instrukcji SQL, której można używać w aplikacji.
Generowanie danych wyjściowych w formacie JSON
Zmodyfikuj zapytanie, aby wygenerować dane wyjściowe w formacie JSON i zwrócić tylko jeden wiersz do przekazania do Vertex AI.
Oto przykład zapytania:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Oto oczekiwany format JSON w danych wyjściowych:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Uruchom prompt w Vertex AI Studio
Wygenerowany kod JSON możemy wykorzystać jako część prompta dla modelu generatywnej AI w Vertex AI Studio.
Otwórz Vertex AI Studio w konsoli Google Cloud.
Jeśli nie używasz go po raz pierwszy, może wyświetlić prośbę o zaakceptowanie warunków korzystania. Kliknij przycisk „Zgadzam się i kontynuuję”.
Wpisz prompta w interfejsie.
Może poprosić Cię o włączenie dodatkowych interfejsów API, ale możesz zignorować tę prośbę. Do ukończenia modułu nie potrzebujemy żadnych dodatkowych interfejsów API.
Oto prompt, którego użyjemy z danymi wyjściowymi JSON z wcześniejszego zapytania o drzewa:
Jesteś przyjaznym doradcą, który pomaga znaleźć produkt na podstawie potrzeb klienta.
Na podstawie prośby klienta załadowaliśmy listę produktów ściśle powiązanych z wyszukiwaniem.
Lista w formacie JSON z listą wartości, np. {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Oto lista produktów:
{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Klient zapytał: „Jakie drzewo rośnie tu najlepiej?”
Musisz podać informacje o produkcie, cenie i dodatkowe informacje
A oto wynik po uruchomieniu promptu z wartościami JSON i przy użyciu modelu gemini-2.5-flash-light:
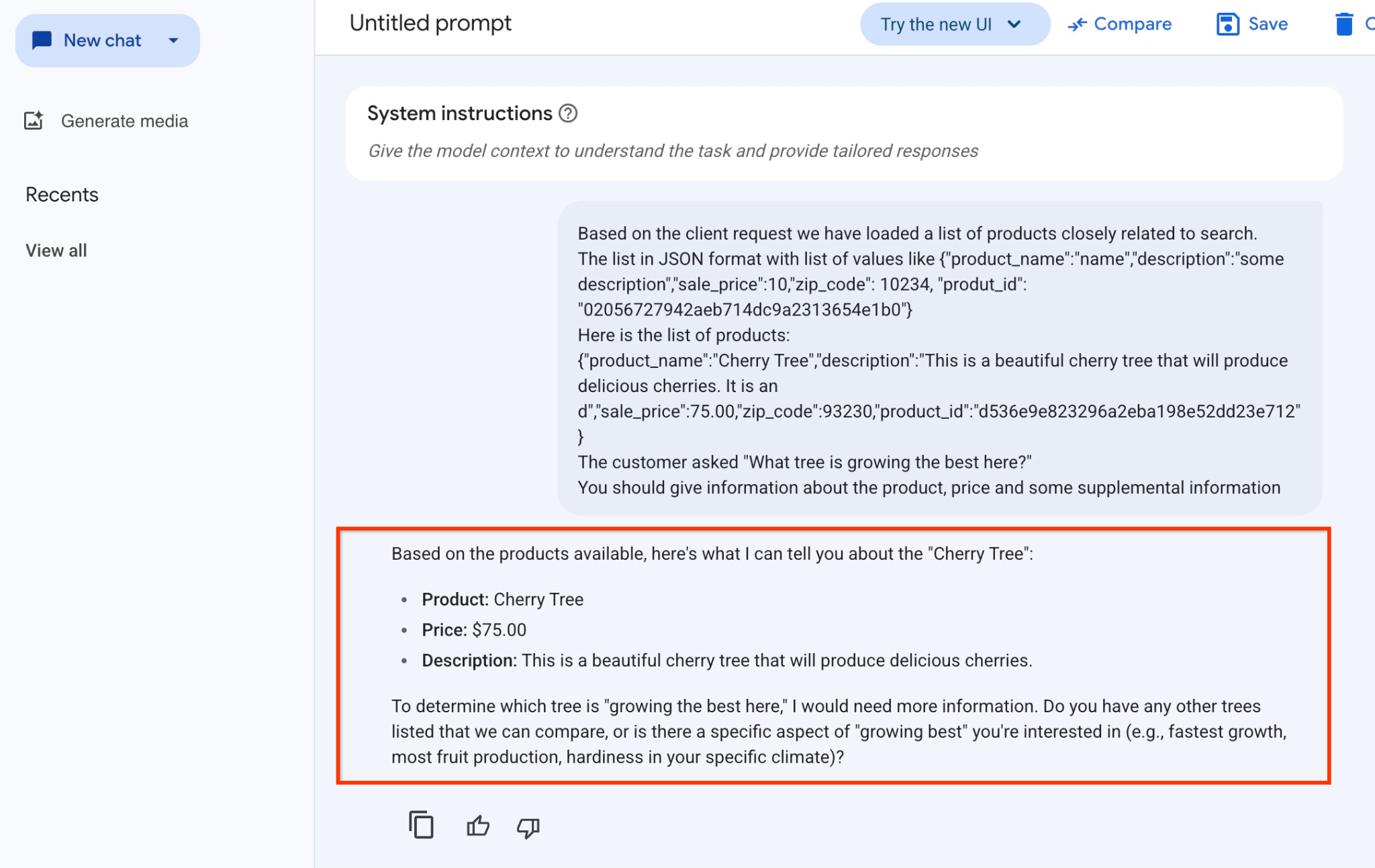
Odpowiedź, którą uzyskaliśmy od modelu w tym przykładzie, jest następująca. Pamiętaj, że Twoja odpowiedź może się różnić ze względu na zmiany modelu i parametrów w czasie:
„Na podstawie dostępnych produktów mogę Ci powiedzieć o „Cherry Tree”:
Produkt: Cherry Tree
Cena: 75,00 zł
Opis: to piękne drzewo wiśniowe, które będzie rodzić pyszne wiśnie.
Aby określić, które drzewo „rośnie tu najlepiej”, potrzebuję więcej informacji. Czy masz na liście inne drzewa, które możemy porównać, lub czy interesuje Cię konkretny aspekt „najlepszego wzrostu” (np. najszybszy wzrost, największa produkcja owoców, odporność w Twoim klimacie)?
Uruchamianie prompta w PSQL
Możemy użyć integracji AlloyDB AI z Vertex AI, aby uzyskać tę samą odpowiedź z modelu generatywnego za pomocą SQL bezpośrednio w bazie danych. Aby jednak używać modelu gemini-1.5-flash, musimy go najpierw zarejestrować.
Sprawdź rozszerzenie google_ml_integration. Powinna być w wersji 1.4.2 lub nowszej.
Połącz się z bazą danych quickstart_db z poziomu psql, jak pokazano wcześniej (lub użyj AlloyDB Studio), i wykonaj to polecenie:
SELECT extversion from pg_extension where extname='google_ml_integration';
Sprawdź flagę bazy danych google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
Oczekiwane dane wyjściowe sesji psql to „on”:
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Jeśli wyświetla się „off”, musimy ustawić flagę bazy danych google_ml_integration.enable_model_support na „on”. Możesz to zrobić za pomocą interfejsu konsoli internetowej AlloyDB lub uruchamiając to polecenie gcloud.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Wykonanie polecenia w tle zajmuje około 1–3 minut. Następnie możesz ponownie zweryfikować zgłoszenie.
W przypadku naszego zapytania potrzebujemy 2 modeli. Pierwszy to używany już model text-embedding-005, a drugi to jeden z ogólnych modeli Google Gemini.
Zaczynamy od modelu wektora dystrybucyjnego tekstu. Aby zarejestrować uruchomienie modelu w psql lub AlloyDB Studio, użyj tego kodu:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Kolejny model, który musimy zarejestrować, to gemini-2.0-flash-001. Będzie on używany do generowania przyjaznych dla użytkownika danych wyjściowych.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Listę zarejestrowanych modeli możesz zawsze sprawdzić, wybierając informacje z google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Przykładowe dane wyjściowe
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Teraz możemy użyć wygenerowanego w zapytaniu podrzędnym kodu JSON, aby przekazać go jako część prompta do generatywnego modelu tekstowego AI za pomocą SQL.
W sesji psql lub AlloyDB Studio w bazie danych uruchom zapytanie
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Oto oczekiwane dane wyjściowe. Wynik może się różnić w zależności od wersji modelu i parametrów:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Utwórz indeks wektorowy
Nasz zbiór danych jest dość mały, a czas odpowiedzi zależy głównie od interakcji z modelami AI. Gdy jednak masz miliony wektorów, wyszukiwanie wektorowe może zająć znaczną część czasu odpowiedzi i mocno obciążyć system. Aby to poprawić, możemy utworzyć indeks na podstawie naszych wektorów.
Tworzenie indeksu ScaNN
Aby utworzyć indeks SCANN, musimy włączyć jeszcze jedno rozszerzenie. Rozszerzenie alloydb_scann udostępnia interfejs do pracy z indeksem wektorowym typu ANN za pomocą algorytmu ScaNN Google.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Oczekiwane dane wyjściowe:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
Indeks można utworzyć w trybie RĘCZNYM lub AUTOMATYCZNYM. Tryb RĘCZNY jest domyślnie włączony. Możesz utworzyć indeks i zarządzać nim tak jak każdym innym indeksem. Jeśli jednak włączysz tryb AUTOMATYCZNY, możesz utworzyć indeks, który nie wymaga od Ciebie żadnej konserwacji. Szczegółowe informacje o wszystkich opcjach znajdziesz w dokumentacji. Poniżej pokażę Ci, jak włączyć tryb AUTO i utworzyć indeks. W naszym przypadku nie mamy wystarczającej liczby wierszy, aby utworzyć indeks w trybie AUTO, więc utworzymy go w trybie MANUAL.
W tym przykładzie większość parametrów pozostawiam domyślną i podaję tylko liczbę partycji (num_leaves) dla indeksu:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Więcej informacji o dostrajaniu parametrów indeksu znajdziesz w dokumentacji.
Oczekiwane dane wyjściowe:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Porównaj odpowiedź
Teraz możemy uruchomić zapytanie w ramach wyszukiwania wektorowego w trybie EXPLAIN i sprawdzić, czy indeks został użyty.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Oczekiwane dane wyjściowe (w celu uniknięcia wątpliwości):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Z danych wyjściowych wyraźnie widać, że zapytanie używało „Index Scan using cymbal_products_embeddings_scann on cymbal_products”.
A jeśli uruchomimy zapytanie bez polecenia explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Oczekiwane dane wyjściowe:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Widzimy, że wynik jest taki sam jak w przypadku drzewa wiśni, które było na górze w naszym wyszukiwaniu bez indeksu. Czasami może się zdarzyć, że odpowiedź nie będzie zawierać tego samego drzewa, ale inne drzewa z góry. Indeks zapewnia więc wydajność, ale jest wystarczająco dokładny, aby przynosić dobre wyniki.
Możesz wypróbować różne indeksy dostępne dla wektorów, a więcej modułów i przykładów integracji z langchain znajdziesz na stronie dokumentacji.
11. Zwalnianie miejsca w środowisku
Po zakończeniu modułu zniszcz instancje i klaster AlloyDB.
Usuwanie klastra AlloyDB i wszystkich instancji
Jeśli korzystasz z wersji próbnej AlloyDB. Nie usuwaj klastra próbnego, jeśli planujesz testować inne laboratoria i zasoby przy użyciu tego klastra. Nie będzie można utworzyć kolejnego klastra próbnego w tym samym projekcie.
Klaster zostanie zniszczony z opcją force, która powoduje też usunięcie wszystkich instancji należących do klastra.
W Cloud Shell zdefiniuj projekt i zmienne środowiskowe, jeśli połączenie zostało przerwane i wszystkie poprzednie ustawienia zostały utracone:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Usuń klaster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Usuwanie kopii zapasowych AlloyDB
Usuń wszystkie kopie zapasowe AlloyDB dla klastra:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Teraz możemy usunąć maszynę wirtualną.
Usuwanie maszyny wirtualnej GCE
W Cloud Shell wykonaj to polecenie:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Oczekiwane dane wyjściowe konsoli:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Gratulacje
Gratulujemy ukończenia ćwiczenia.
Ten moduł jest częścią ścieżki szkoleniowej Wdrożenie AI w Google Cloud.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Podziel się swoimi postępami, używając hashtagu
#ProductionReadyAI.
Omówione zagadnienia
- Jak wdrożyć klaster i instancję główną AlloyDB
- Jak połączyć się z AlloyDB z maszyny wirtualnej Google Compute Engine
- Tworzenie bazy danych i włączanie AlloyDB AI
- Wczytywanie danych do bazy danych
- Jak korzystać z AlloyDB Studio
- Jak używać modelu wektorów dystrybucyjnych Vertex AI w AlloyDB
- Jak korzystać z Vertex AI Studio
- Jak wzbogacić wynik za pomocą modelu generatywnego Vertex AI
- Jak poprawić skuteczność za pomocą indeksu wektorów
13. Ankieta
Dane wyjściowe: