
1. Introdução
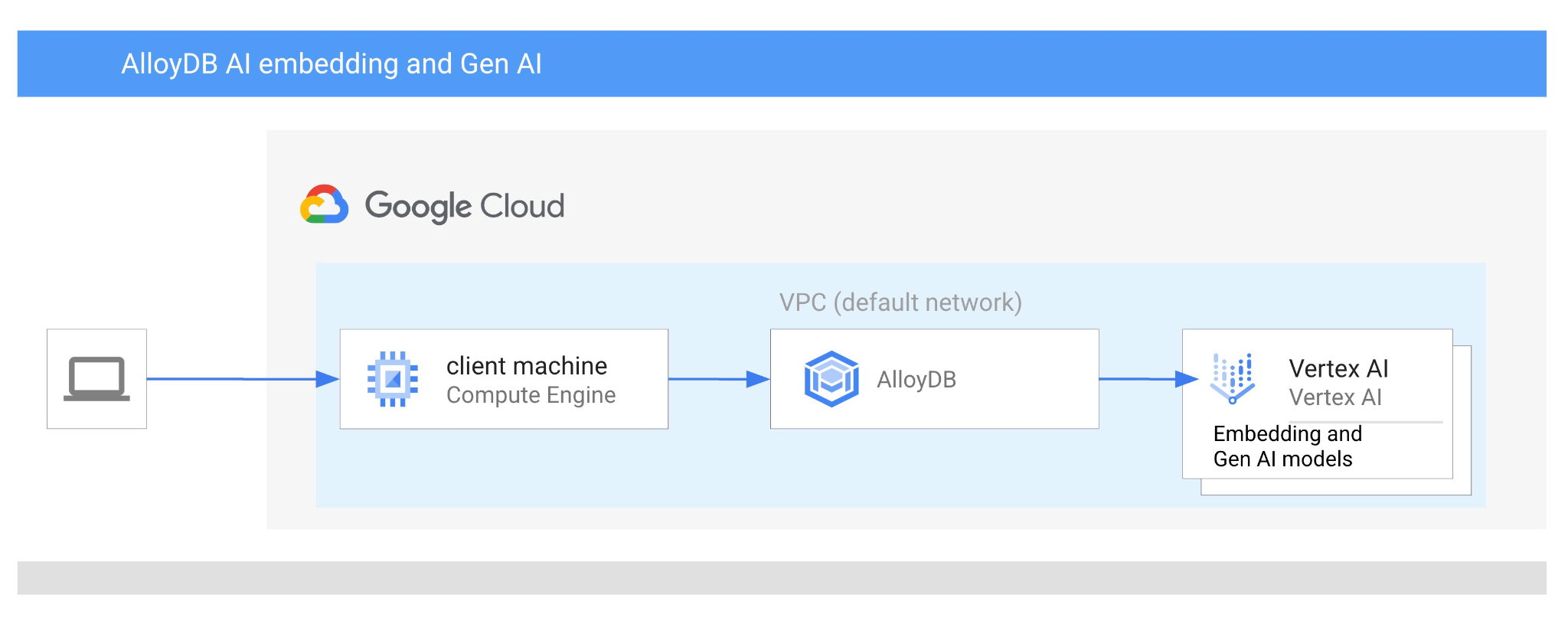
Neste codelab, você vai aprender a usar o AlloyDB AI combinando a pesquisa vetorial com embeddings da Vertex AI. Este laboratório faz parte de uma coleção dedicada aos recursos de IA do AlloyDB. Leia mais na página do AlloyDB AI na documentação.
Pré-requisitos
- Conhecimentos básicos sobre o Google Cloud e o console
- Habilidades básicas na interface de linha de comando e no Google Shell
O que você vai aprender
- Como implantar um cluster e uma instância principal do AlloyDB
- Como se conectar ao AlloyDB de uma VM do Google Compute Engine
- Como criar um banco de dados e ativar a IA do AlloyDB
- Como carregar dados no banco de dados
- Como usar o AlloyDB Studio
- Como usar o modelo de embedding da Vertex AI no AlloyDB
- Como usar o Vertex AI Studio
- Como enriquecer o resultado usando o modelo generativo da Vertex AI
- Como melhorar a performance usando o índice de vetor
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
2. Configuração e requisitos
Configuração do projeto
- Faça login no Console do Google Cloud. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
- Crie um novo projeto ou reutilize um existente. Para criar um projeto no console do Google Cloud, clique no botão "Selecionar um projeto" no cabeçalho, que vai abrir uma janela pop-up.

Na janela "Selecionar um projeto", clique no botão "Novo projeto", que vai abrir uma caixa de diálogo para o novo projeto.
Na caixa de diálogo, coloque o nome do projeto de sua preferência e escolha o local.
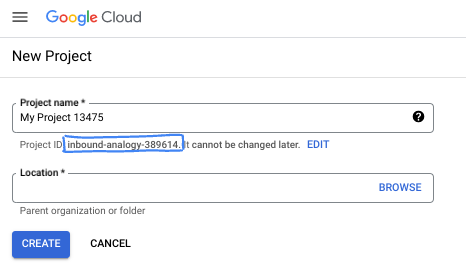
- O Nome do projeto é o nome de exibição para os participantes do projeto. O nome do projeto não é usado pelas APIs do Google e pode ser alterado a qualquer momento.
- O ID do projeto é exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Google Cloud gera automaticamente um ID exclusivo, mas você pode personalizá-lo. Se você não gostar do ID gerado, crie outro aleatório ou forneça o seu para verificar a disponibilidade. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, que normalmente é identificado com o marcador de posição PROJECT_ID.
- Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
Ativar faturamento
Para ativar o faturamento, você tem duas opções. Você pode usar sua conta de faturamento pessoal ou resgatar créditos seguindo estas etapas.
Resgatar créditos do Google Cloud (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $3 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
Ou pressione G e S. Essa sequência vai ativar o Cloud Shell se você estiver no console do Google Cloud ou usar este link.
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
3. Antes de começar
Ativar API
Saída:
Para usar o AlloyDB, o Compute Engine, os serviços de rede e a Vertex AI, é necessário ativar as APIs respectivas no seu projeto do Google Cloud.
Como ativar as APIs
No terminal do Cloud Shell, verifique se o ID do projeto está configurado:
gcloud config set project [YOUR-PROJECT-ID]
Defina a variável de ambiente PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Ative todas as APIs necessárias:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Apresentação das APIs
- A API AlloyDB (
alloydb.googleapis.com) permite criar, gerenciar e escalonar clusters do AlloyDB para PostgreSQL. Ele oferece um serviço de banco de dados totalmente gerenciado e compatível com PostgreSQL, projetado para cargas de trabalho empresariais transacionais e analíticas exigentes. - A API Compute Engine (
compute.googleapis.com) permite criar e gerenciar máquinas virtuais (VMs), discos permanentes e configurações de rede. Ela fornece a base principal de infraestrutura como serviço (IaaS) necessária para executar suas cargas de trabalho e hospedar a infraestrutura subjacente de muitos serviços gerenciados. - A API Resource Manager (
cloudresourcemanager.googleapis.com) permite gerenciar de forma programática os metadados e a configuração do seu projeto do Google Cloud. Ele permite organizar recursos, processar políticas de gerenciamento de identidade e acesso (IAM) e validar permissões em toda a hierarquia do projeto. - A API Service Networking (
servicenetworking.googleapis.com) permite automatizar a configuração da conectividade particular entre sua rede de nuvem privada virtual (VPC) e os serviços gerenciados do Google. Ele é especificamente necessário para estabelecer o acesso a IP particular para serviços como o AlloyDB, para que eles possam se comunicar com segurança com seus outros recursos. - A API Vertex AI (
aiplatform.googleapis.com) permite que seus aplicativos criem, implantem e escalonem modelos de machine learning. Ela oferece a interface unificada para todos os serviços de IA do Google Cloud, incluindo acesso a modelos de IA generativa (como o Gemini) e treinamento de modelos personalizados.
Se quiser, configure a região padrão para usar os modelos de embedding da Vertex AI. Leia mais sobre os locais disponíveis para a Vertex AI. No exemplo, usamos a região "us-central1".
gcloud config set compute/region us-central1
4. Implantar o AlloyDB
Antes de criar um cluster do AlloyDB, é necessário ter um intervalo de IP privado disponível na VPC para ser usado pela instância futura do AlloyDB. Se não tivermos, precisamos criar e atribuir para uso por serviços internos do Google. Depois disso, será possível criar o cluster e a instância.
Criar um intervalo de IP privado
É preciso configurar o acesso a serviços particulares na VPC para o AlloyDB. Vamos supor que o projeto tem uma rede VPC "padrão" a ser usada para todas as ações.
Crie o intervalo de IP privado:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Crie uma conexão privada com o intervalo de IP alocado:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Criar cluster do AlloyDB
Nesta seção, vamos criar um cluster do AlloyDB na região us-central1.
Defina a senha do usuário postgres. Você pode definir sua própria senha ou usar uma função aleatória para gerar uma.
export PGPASSWORD=`openssl rand -hex 12`
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Anote a senha do PostgreSQL para uso futuro.
echo $PGPASSWORD
Você vai precisar dessa senha no futuro para se conectar à instância como o usuário postgres. Recomendamos anotar ou copiar em algum lugar para usar depois.
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Criar um cluster de teste sem custo financeiro
Se você nunca usou o AlloyDB, crie um cluster de teste sem custo financeiro:
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Criar cluster padrão do AlloyDB
Se não for seu primeiro cluster do AlloyDB no projeto, crie um cluster padrão.
Defina a região e o nome do cluster do AlloyDB. Vamos usar a região us-central1 e alloydb-aip-01 como nome do cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Execute o comando para criar o cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Saída esperada do console:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Crie uma instância principal do AlloyDB para o cluster na mesma sessão do Cloud Shell. Se você se desconectar, será necessário definir as variáveis de ambiente de região e nome do cluster novamente.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Conectar-se ao AlloyDB
O AlloyDB é implantado usando uma conexão somente privada. Por isso, precisamos de uma VM com o cliente do PostgreSQL instalado para trabalhar com o banco de dados.
Implantar a VM do GCE
Crie uma VM do GCE na mesma região e VPC que o cluster do AlloyDB.
No Cloud Shell, execute:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Instalar o cliente do Postgres
Instale o software do cliente PostgreSQL na VM implantada.
Conecte-se à VM:
gcloud compute ssh instance-1 --zone=us-central1-a
Saída esperada do console:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Instale o comando em execução do software na VM:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Saída esperada do console:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Conectar-se à instância
Conecte-se à instância principal pela VM com psql.
Na mesma guia do Cloud Shell com a sessão SSH aberta na VM instance-1.
Use o valor da senha do AlloyDB (PGPASSWORD) e o ID do cluster do AlloyDB para se conectar ao AlloyDB pela VM do GCE:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Saída esperada do console:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Feche a sessão psql:
exit
6. Preparar banco de dados
Precisamos criar um banco de dados, ativar a integração da Vertex AI, criar objetos de banco de dados e importar os dados.
Conceder as permissões necessárias ao AlloyDB
Adicione permissões da Vertex AI ao agente de serviço do AlloyDB.
Abra outra guia do Cloud Shell pelo sinal "+" na parte superior.
Na nova guia do Cloud Shell, execute:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Feche a guia pelo comando de execução "sair" na guia:
exit
Criar banco de dados
Início rápido para criar um banco de dados.
Na sessão da VM do GCE, execute:
Crie o banco de dados:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Saída esperada do console:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Ativar a integração da Vertex AI
Ative a integração da Vertex AI e as extensões pgvector no banco de dados.
Na VM do GCE, execute:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Saída esperada do console:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Importar dados
Faça o download dos dados preparados e importe-os para o novo banco de dados.
Na VM do GCE, execute:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Saída esperada do console:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Calcular embeddings
Depois de importar os dados, recebemos os dados de produtos na tabela "cymbal_products", o inventário mostrando o número de produtos disponíveis em cada loja na tabela "cymbal_inventory" e a lista das lojas na tabela "cymbal_stores". Precisamos calcular os dados vetoriais com base nas descrições dos nossos produtos e vamos usar a função embedding para isso. Usando a função, vamos usar a integração da Vertex AI para calcular dados de vetor com base nas descrições dos produtos e adicioná-los à tabela. Leia mais sobre a tecnologia usada na documentação.
É fácil gerar para algumas linhas, mas como fazer isso de forma eficiente se tivermos milhares? Aqui, vou mostrar como gerar e gerenciar embeddings para tabelas grandes. Leia mais sobre diferentes opções e técnicas no guia.
Ativar a geração rápida de incorporações
Conecte-se ao banco de dados usando o psql da VM com o IP da instância do AlloyDB e a senha do postgres:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Verifique a versão da extensão google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
A versão precisa ser 1.5.2 ou mais recente. Confira um exemplo da saída:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
A versão padrão precisa ser 1.5.2 ou mais recente, mas se a instância mostrar uma versão mais antiga, ela provavelmente precisará ser atualizada. Verifique se a manutenção foi desativada para a instância.
Em seguida, precisamos verificar a flag do banco de dados. Precisamos que a flag google_ml_integration.enable_faster_embedding_generation esteja ativada. Na mesma sessão do psql, verifique o valor da flag.
show google_ml_integration.enable_faster_embedding_generation;
Se a flag estiver na posição correta, a saída esperada será assim:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Mas, se aparecer "desativado", será necessário atualizar a instância. Faça isso usando o console da Web ou o comando gcloud, conforme descrito na documentação. Aqui mostro como fazer isso usando o comando gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Pode levar alguns minutos, mas o valor da flag será alterado para "ativado". Depois disso, siga para as próximas etapas.
Criar coluna de embedding
Conecte-se ao banco de dados usando psql e crie uma coluna virtual com os dados de vetor usando a função de embedding na tabela "cymbal_products". A função de embedding retorna dados de vetor da Vertex AI com base nos dados fornecidos pela coluna "product_description".
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Na sessão psql, depois de se conectar ao banco de dados, execute:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
O comando vai criar a coluna virtual e preenchê-la com dados de vetor.
Saída esperada do console:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Agora podemos gerar embeddings usando lotes de 50 linhas cada. Teste diferentes tamanhos de lote e veja se isso muda o tempo de execução. Na mesma sessão psql, execute:
Ative a marcação de tempo para medir quanto tempo vai levar:
\timing
Execute o comando:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
E a saída do console mostrou menos de 2 segundos para a geração de incorporação:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Por padrão, as incorporações não serão atualizadas se a coluna "product_description" correspondente for atualizada ou se uma linha inteira for inserida. Para isso, defina o parâmetro incremental_refresh_mode. Vamos criar uma coluna "product_embeddings" e fazer com que ela seja atualizada automaticamente.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Agora, se inserirmos uma nova linha na tabela.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Podemos comparar a diferença nas colunas usando a consulta:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
Na saída, podemos ver que, embora a coluna embedding permaneça vazia, a coluna product_embedding é atualizada automaticamente.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Fazer uma pesquisa de similaridade
Agora podemos executar nossa pesquisa usando a pesquisa de similaridade com base nos valores de vetor calculados para as descrições e o valor de vetor que recebemos para nossa solicitação.
A consulta SQL pode ser executada na mesma interface de linha de comando psql ou, como alternativa, no AlloyDB Studio. Qualquer saída complexa e de várias linhas pode ficar melhor no AlloyDB Studio.
Conectar-se ao AlloyDB Studio
Nos capítulos a seguir, todos os comandos SQL que exigem conexão com o banco de dados podem ser executados alternativamente no AlloyDB Studio. Para executar o comando, clique na instância principal e abra a interface do console da Web do cluster do AlloyDB.
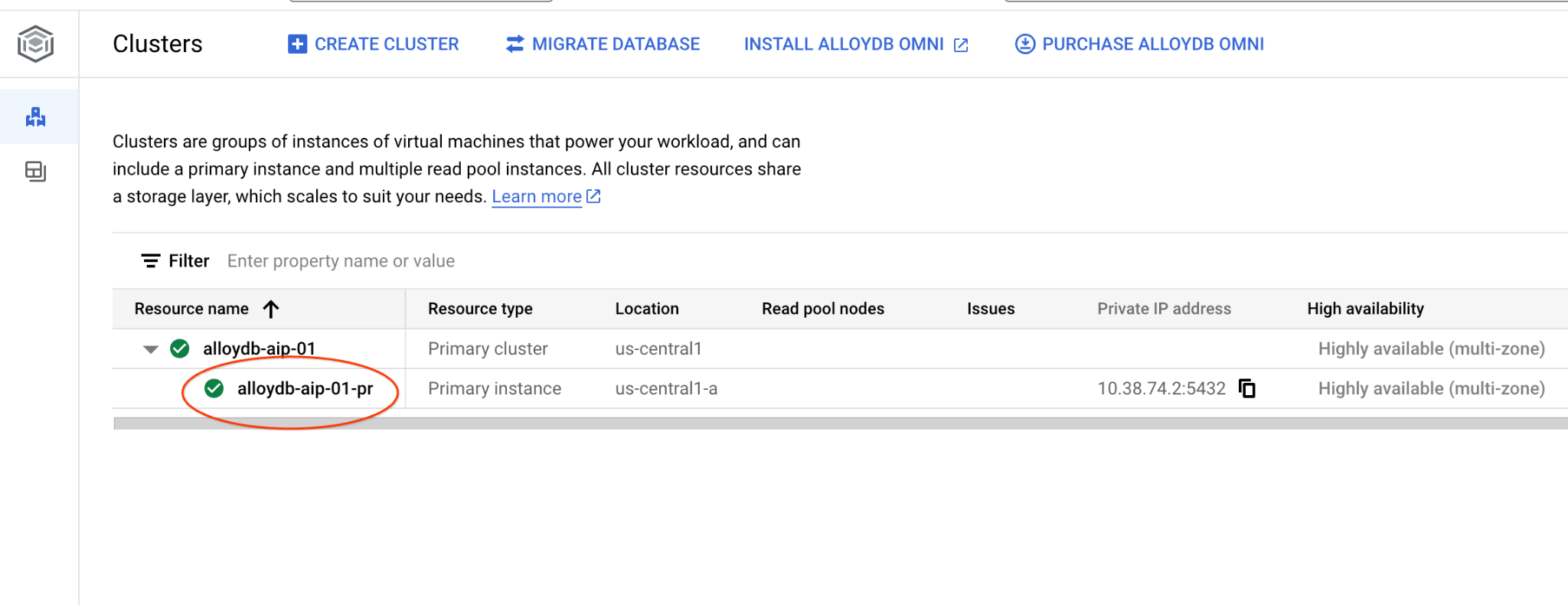
Em seguida, clique em "AlloyDB Studio" à esquerda:
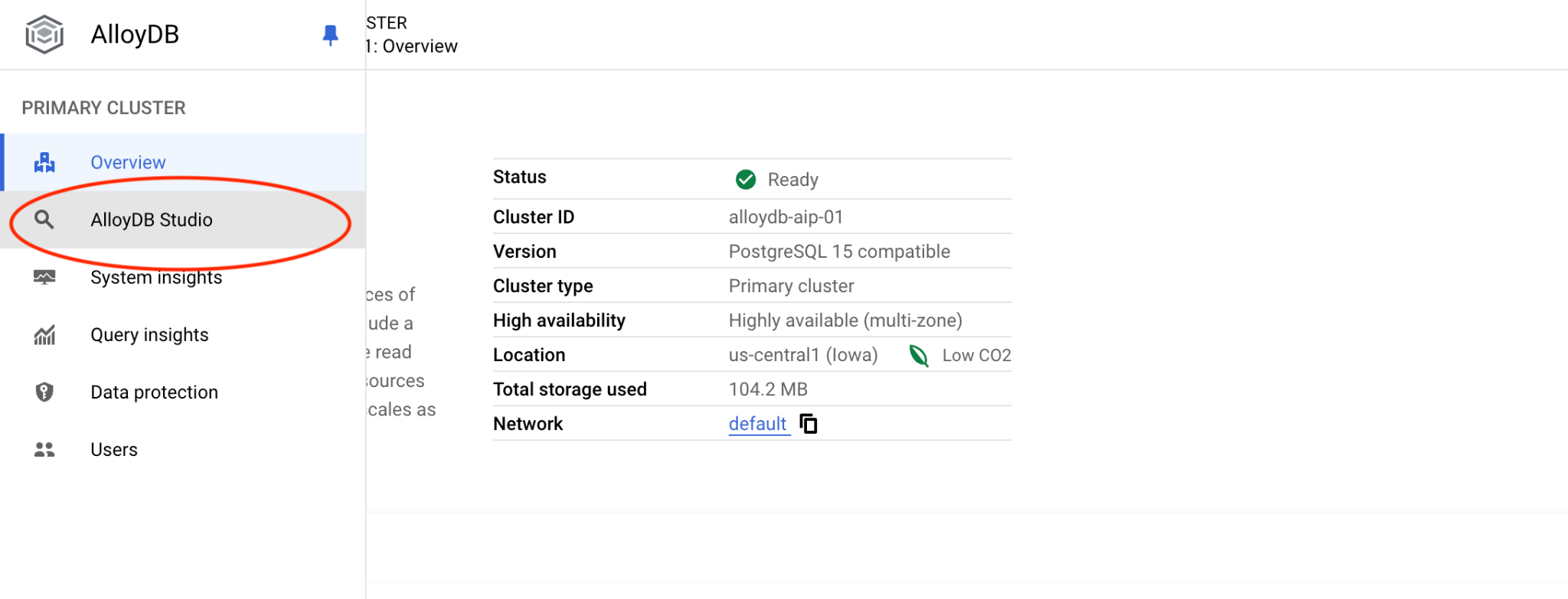
Escolha o banco de dados quickstart_db, o usuário postgres e forneça a senha anotada quando criamos o cluster. Em seguida, clique no botão "Autenticar".
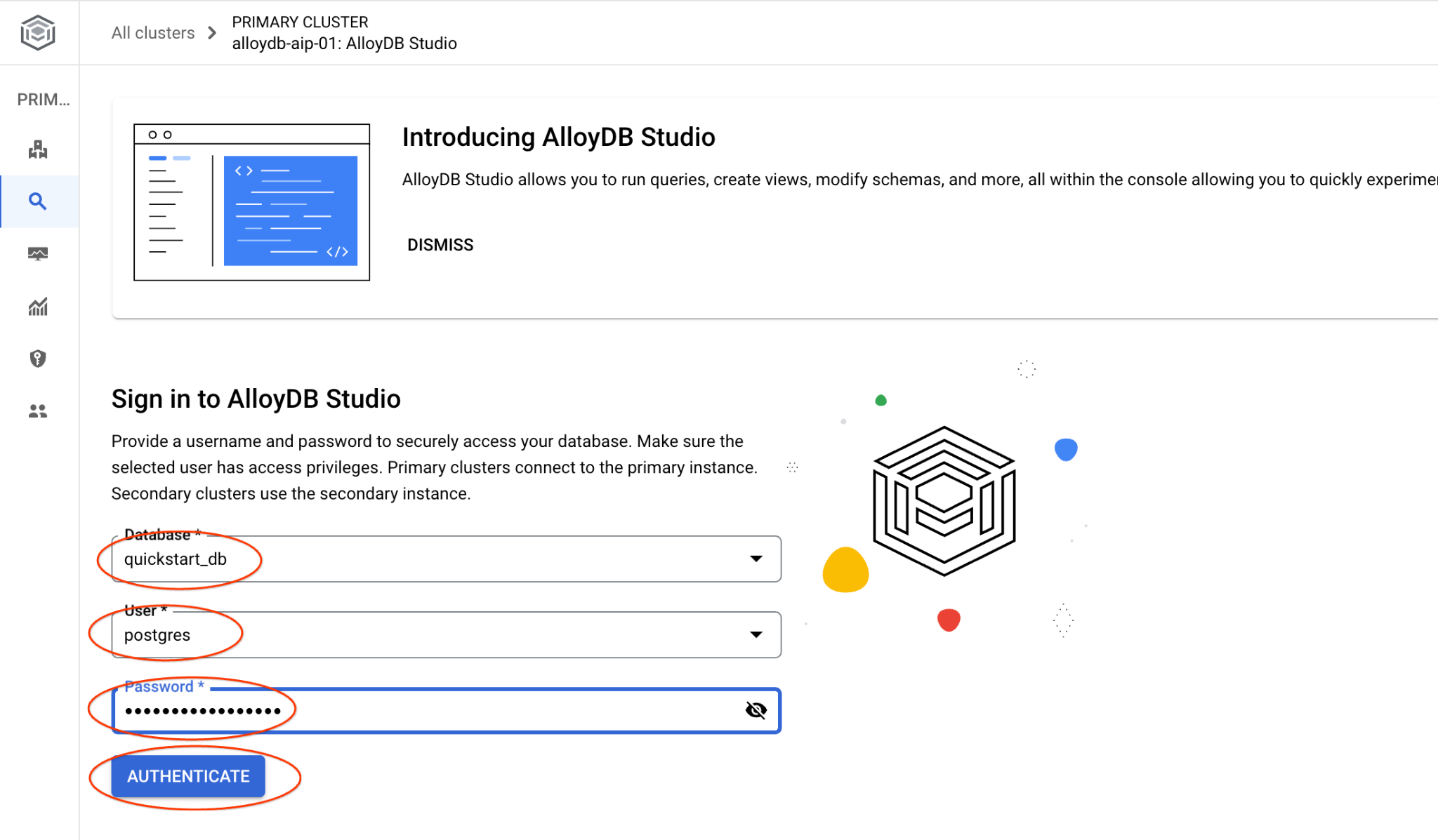
A interface do AlloyDB Studio será aberta. Para executar os comandos no banco de dados, clique na guia "Editor 1" à direita.
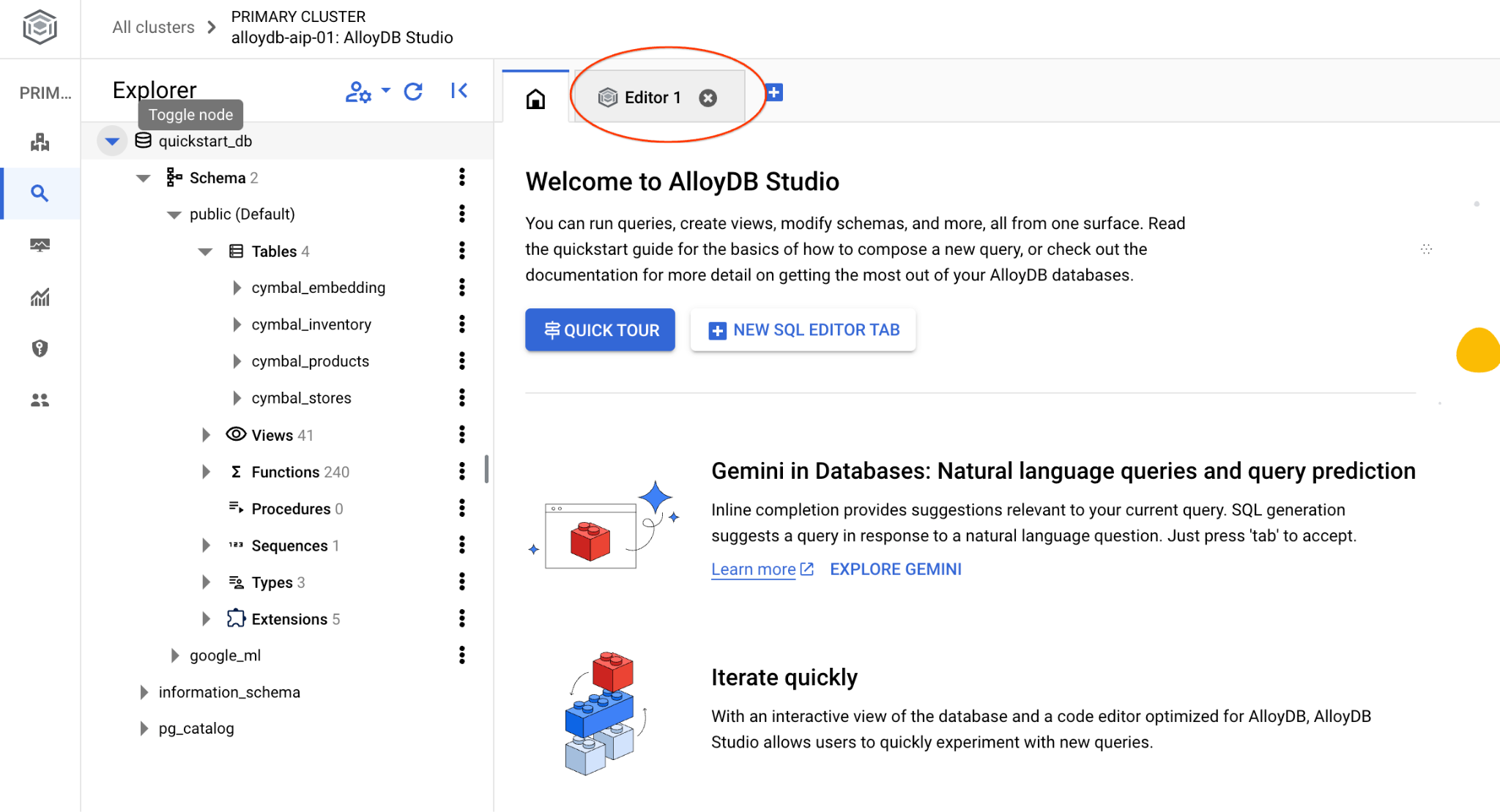
Ela abre uma interface em que é possível executar comandos SQL.
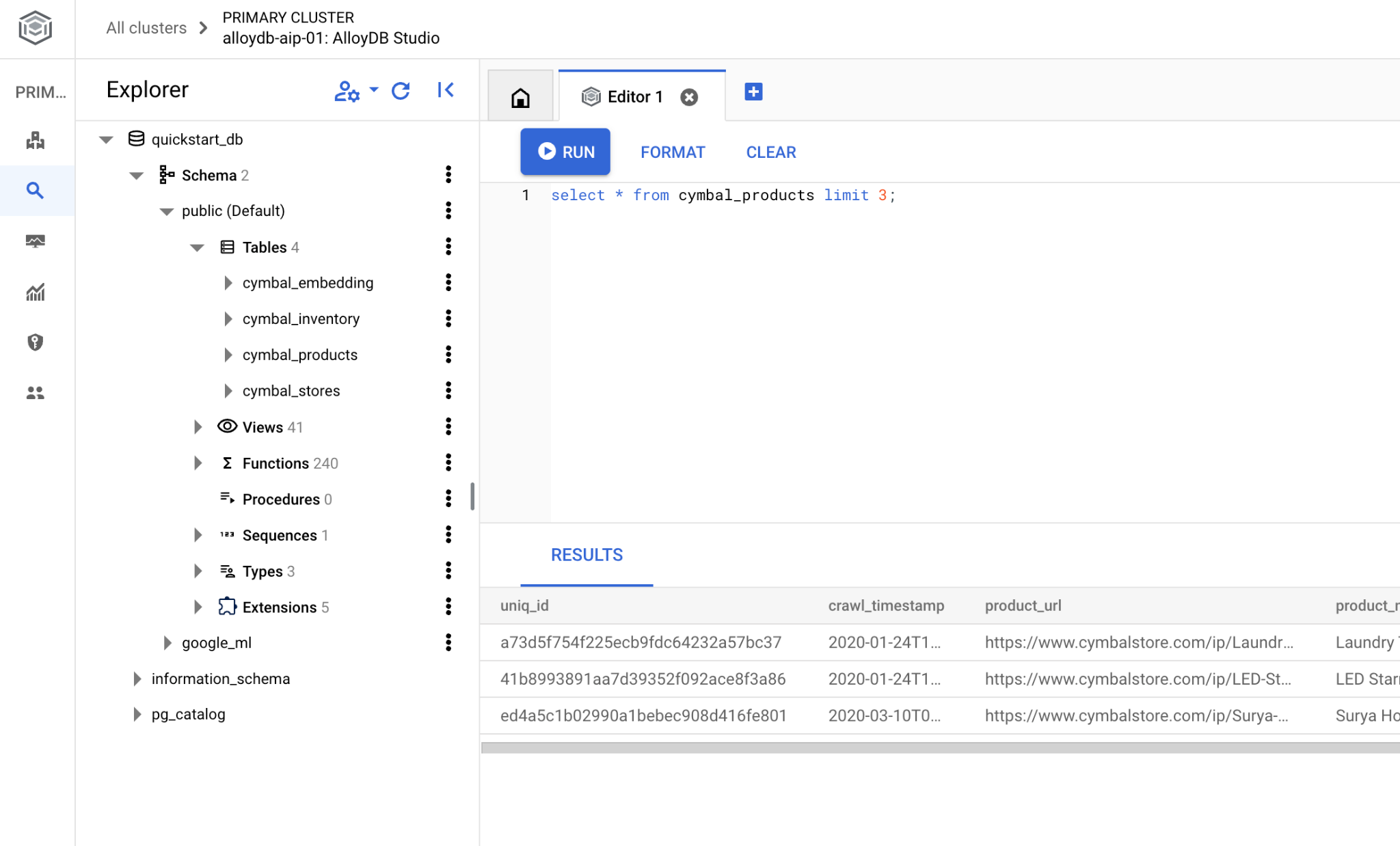
Se você preferir usar o psql da linha de comando, siga a rota alternativa e conecte-se ao banco de dados na sessão SSH da VM, conforme descrito nos capítulos anteriores.
Executar a pesquisa de similaridade no psql
Se a sessão do banco de dados foi desconectada, conecte-se novamente usando o psql ou o AlloyDB Studio.
Conecte-se ao banco de dados:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Execute uma consulta para receber uma lista de produtos disponíveis mais relacionados ao pedido de um cliente. A solicitação que vamos transmitir à Vertex AI para receber o valor do vetor é algo como "Que tipo de árvores frutíferas crescem bem aqui?"
Esta é a consulta que você pode executar para escolher os 10 primeiros itens mais adequados à nossa solicitação:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Esta é a saída esperada:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Melhorar resposta
É possível melhorar a resposta a um aplicativo cliente usando o resultado da consulta e preparar uma saída significativa usando os resultados da consulta fornecida como parte do comando para o modelo de linguagem de base generativa da Vertex AI.
Para isso, planejamos gerar um JSON com nossos resultados da pesquisa vetorial e usar esse JSON gerado como complemento de um comando para um modelo de LLM de texto na Vertex AI para criar uma saída significativa. Na primeira etapa, geramos o JSON e o testamos no Vertex AI Studio. Na última etapa, incorporamos o JSON a uma instrução SQL que pode ser usada em um aplicativo.
Gerar saída no formato JSON
Modifique a consulta para gerar a saída no formato JSON e retorne apenas uma linha para passar para a Vertex AI.
Confira um exemplo de consulta:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Este é o JSON esperado na saída:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Executar o prompt no Vertex AI Studio
Podemos usar o JSON gerado como parte do comando para o modelo de texto de IA generativa no Vertex AI Studio.
Abra o Vertex AI Studio no console do Cloud.
Talvez seja necessário concordar com os termos de uso se você nunca tiver usado o recurso. Clique no botão "Concordar e continuar".
Escreva seu comando na interface.
Talvez seja necessário ativar outras APIs, mas você pode ignorar a solicitação. Não precisamos de outras APIs para concluir o laboratório.
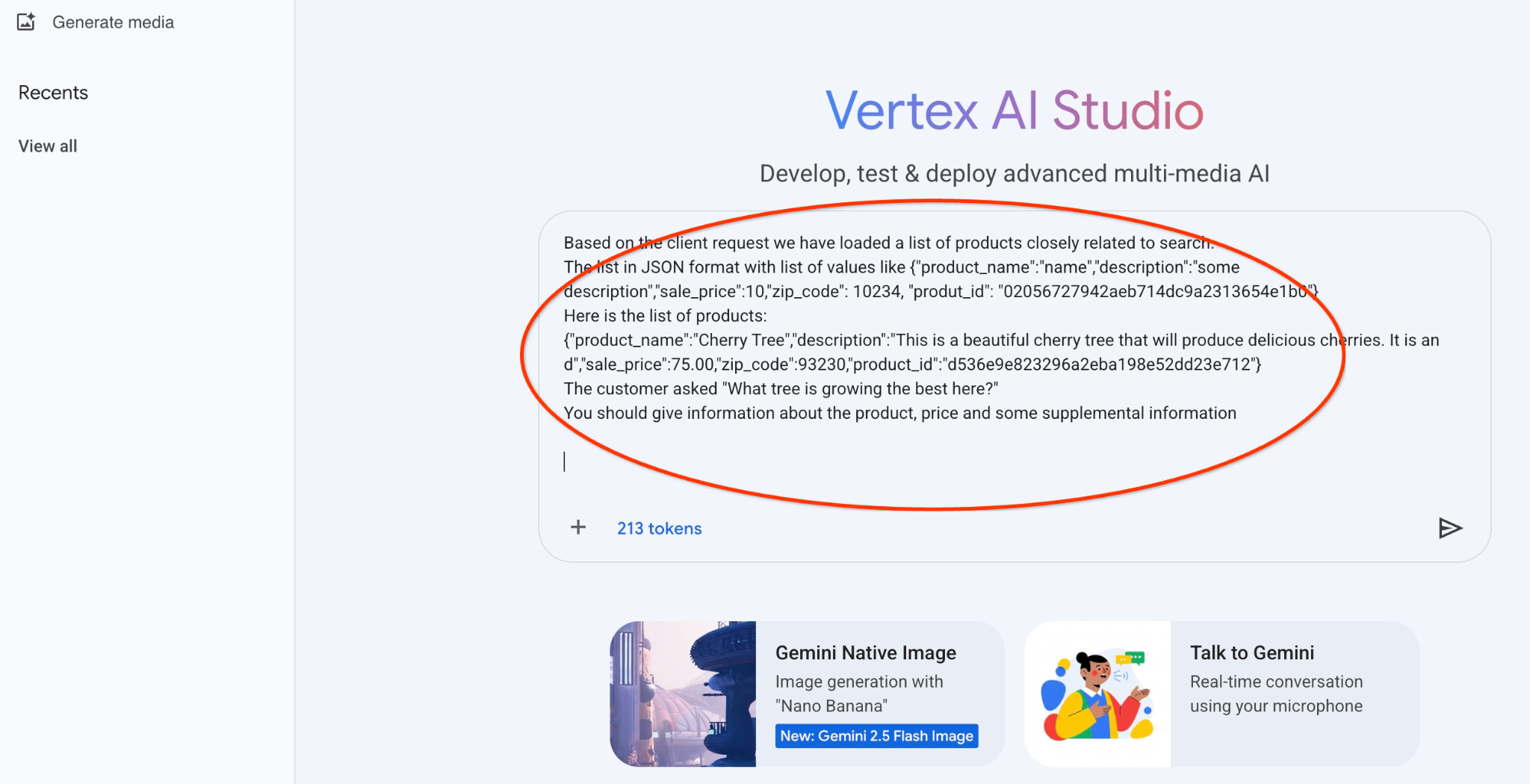
Este é o comando que vamos usar com a saída JSON da consulta inicial sobre as árvores:
Você é um consultor simpático que ajuda a encontrar um produto com base nas necessidades do cliente.
Com base na solicitação do cliente, carregamos uma lista de produtos relacionados à pesquisa.
A lista no formato JSON com lista de valores como {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Esta é a lista de produtos:
{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
O cliente perguntou: "Qual árvore está crescendo melhor aqui?"
Você precisa informar sobre o produto, o preço e algumas informações complementares
Este é o resultado quando executamos o comando com nossos valores JSON e usando o modelo gemini-2.5-flash-light:
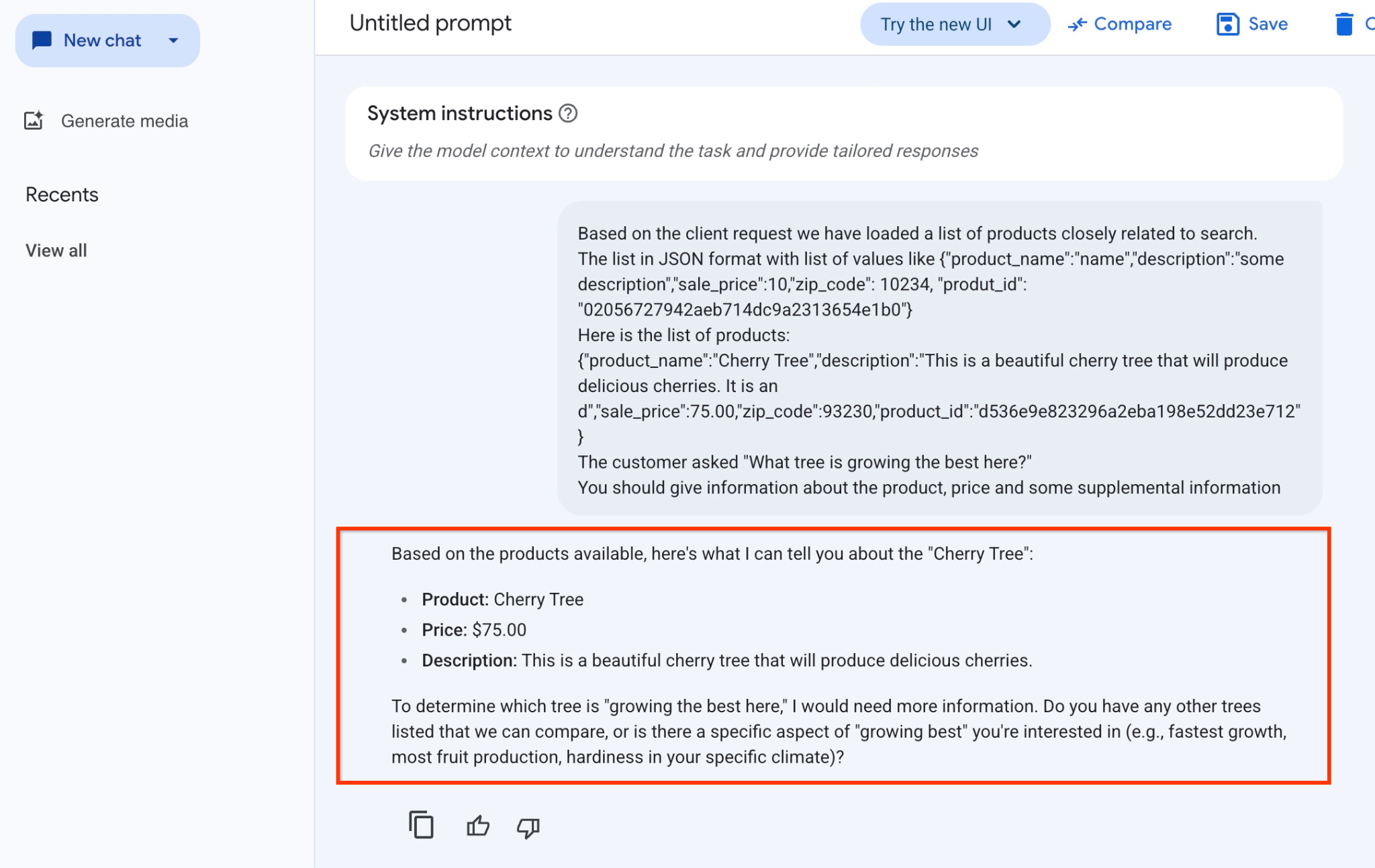
Confira a resposta que recebemos do modelo neste exemplo. Sua resposta pode ser diferente devido a mudanças no modelo e nos parâmetros ao longo do tempo:
"Com base nos produtos disponíveis, aqui está o que posso dizer sobre a "Cherry Tree":
Produto: Cherry Tree
Preço: US$ 75,00
Descrição: esta é uma linda cerejeira que vai produzir cerejas deliciosas.
Para determinar qual árvore está "crescendo melhor aqui", preciso de mais informações. Você tem outras árvores listadas para compararmos ou há um aspecto específico de "crescimento ideal" que interessa a você (por exemplo, crescimento mais rápido, maior produção de frutas, resistência no seu clima específico)?"
Executar o comando no PSQL
Podemos usar a integração do AlloyDB AI com a Vertex AI para receber a mesma resposta de um modelo generativo usando SQL diretamente no banco de dados. Mas, para usar o modelo gemini-1.5-flash, primeiro precisamos registrá-lo.
Verifique a extensão google_ml_integration. Ela precisa ter a versão 1.4.2 ou mais recente.
Conecte-se ao banco de dados quickstart_db do psql, como mostrado anteriormente, ou use o AlloyDB Studio e execute:
SELECT extversion from pg_extension where extname='google_ml_integration';
Verifique a flag do banco de dados google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
A saída esperada da sessão psql é "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Se aparecer "off", defina a flag de banco de dados google_ml_integration.enable_model_support como "on". Para fazer isso, use a interface do console da Web do AlloyDB ou execute o seguinte comando gcloud.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
O comando leva de 1 a 3 minutos para ser executado em segundo plano. Em seguida, verifique a flag novamente.
Para nossa consulta, precisamos de dois modelos. O primeiro é o modelo text-embedding-005 já usado, e o segundo é um dos modelos genéricos do Google Gemini.
Começamos com o modelo de embedding de texto. Para registrar a execução do modelo no psql ou no AlloyDB Studio, use o seguinte código:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
O próximo modelo que precisamos registrar é o gemini-2.0-flash-001, que será usado para gerar a saída fácil de usar.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Você pode verificar a lista de modelos registrados selecionando informações de google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Confira um exemplo de saída:
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Agora podemos usar o JSON gerado em uma subconsulta para fornecê-lo como parte do comando ao modelo de texto de IA generativa usando SQL.
Na sessão do psql ou do AlloyDB Studio para o banco de dados, execute a consulta
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Esta é a saída esperada. A saída pode variar dependendo da versão e dos parâmetros do modelo:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Criar índice vetorial
Nosso conjunto de dados é bem pequeno, e o tempo de resposta depende principalmente da interação com modelos de IA. Mas quando você tem milhões de vetores, a parte da pesquisa vetorial pode levar uma parte significativa do nosso tempo de resposta e colocar uma carga alta no sistema. Para melhorar isso, podemos criar um índice sobre nossos vetores.
Criar índice do ScaNN
Para criar o índice SCANN, precisamos ativar mais uma extensão. A extensão alloydb_scann fornece uma interface para trabalhar com o índice vetorial do tipo ANN usando o algoritmo ScaNN do Google.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Saída esperada:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
O índice pode ser criado no modo MANUAL ou AUTO. O modo MANUAL é ativado por padrão, e você pode criar e manter um índice como qualquer outro. Mas se você ativar o modo AUTO, poderá criar o índice sem precisar fazer nenhuma manutenção. Leia em detalhes sobre todas as opções na documentação. Aqui, vou mostrar como ativar o modo AUTO e criar o índice. No nosso caso, não temos linhas suficientes para criar o índice no modo AUTO. Por isso, vamos criá-lo como MANUAL.
No exemplo a seguir, deixo a maioria dos parâmetros como padrão e forneço apenas um número de partições (num_leaves) para o índice:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Leia sobre o ajuste de parâmetros de índice na documentação.
Saída esperada:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Comparar resposta
Agora podemos executar a consulta de pesquisa vetorial no modo EXPLAIN e verificar se o índice foi usado.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Saída esperada (editada para fins de esclarecimento):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Na saída, é possível ver claramente que a consulta estava usando "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
E se executarmos a consulta sem a explicação:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Saída esperada:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Podemos ver que o resultado é a mesma cerejeira que estava no topo da nossa pesquisa sem índice. Às vezes, isso não acontece, e a resposta pode retornar não a mesma árvore, mas outras árvores do topo. Assim, o índice oferece performance, mas ainda é preciso o suficiente para gerar bons resultados.
Você pode testar diferentes índices disponíveis para os vetores e mais laboratórios e exemplos com integração do LangChain na página de documentação.
11. Limpar o ambiente
Destrua as instâncias e o cluster do AlloyDB quando terminar o laboratório.
Excluir o cluster do AlloyDB e todas as instâncias
Se você usou a versão de teste do AlloyDB. Não exclua o cluster de teste se você planeja testar outros laboratórios e recursos usando esse cluster. Não será possível criar outro cluster de teste no mesmo projeto.
O cluster é destruído com a opção "force" que também exclui todas as instâncias pertencentes.
No Cloud Shell, defina o projeto e as variáveis de ambiente se tiver ocorrido uma desconexão e todas as configurações anteriores forem perdidas:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Exclua o cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Excluir backups do AlloyDB
Exclua todos os backups do AlloyDB do cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Agora você pode destruir a VM.
Excluir a VM do GCE
No Cloud Shell, execute:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Saída esperada do console:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Parabéns
Parabéns por concluir o codelab.
Este laboratório faz parte do programa de aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para ir do protótipo à produção.
- Compartilhe seu progresso com a hashtag
#ProductionReadyAI.
O que vimos
- Como implantar um cluster e uma instância principal do AlloyDB
- Como se conectar ao AlloyDB de uma VM do Google Compute Engine
- Como criar um banco de dados e ativar a IA do AlloyDB
- Como carregar dados no banco de dados
- Como usar o AlloyDB Studio
- Como usar o modelo de embedding da Vertex AI no AlloyDB
- Como usar o Vertex AI Studio
- Como enriquecer o resultado usando o modelo generativo da Vertex AI
- Como melhorar a performance usando o índice de vetor
13. Pesquisa
Saída: