
۱. مرور کلی

هوش مصنوعی اسناد چیست؟
هوش مصنوعی اسناد ، پلتفرمی است که به شما امکان میدهد از اسناد خود بینش استخراج کنید. در اصل، این پلتفرم فهرست رو به رشدی از پردازندههای سند (که بسته به عملکردشان، تجزیهکننده یا تقسیمکننده نیز نامیده میشوند) ارائه میدهد.
دو روش برای مدیریت پردازندههای هوش مصنوعی اسناد وجود دارد:
- به صورت دستی، از کنسول وب؛
- به صورت برنامهنویسیشده، با استفاده از API هوش مصنوعی اسناد.
در اینجا یک نمونه اسکرینشات از لیست پردازندههای شما، هم از کنسول وب و هم از کد پایتون، نشان داده شده است:
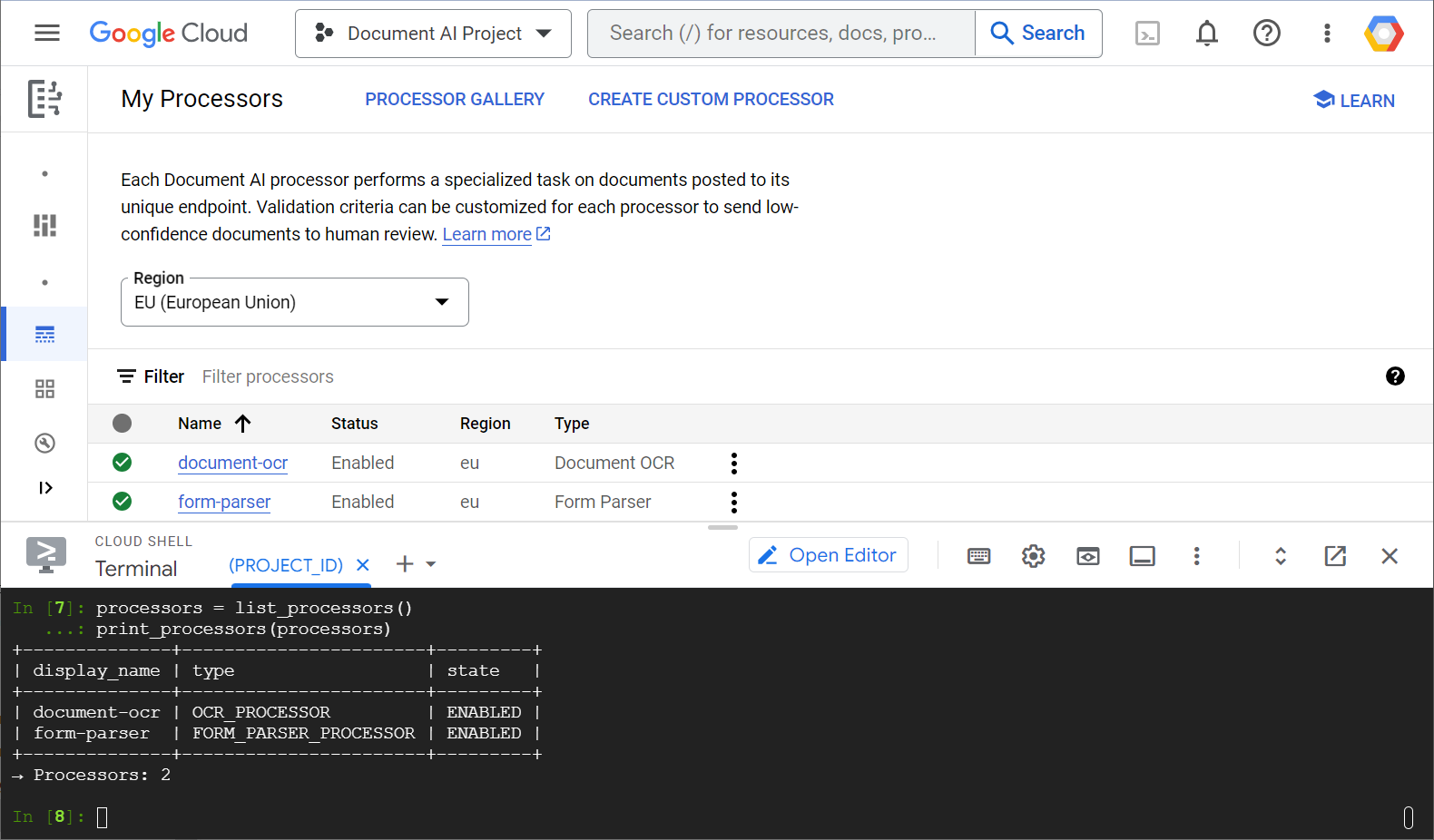
در این آزمایشگاه، شما بر مدیریت پردازندههای هوش مصنوعی اسناد به صورت برنامهنویسی شده با کتابخانه کلاینت پایتون تمرکز خواهید کرد.
آنچه خواهید دید
- چگونه محیط خود را تنظیم کنید
- نحوه دریافت انواع پردازنده
- نحوه ایجاد پردازندهها
- نحوه فهرست کردن پردازندههای پروژه
- نحوه استفاده از پردازندهها
- نحوه فعال/غیرفعال کردن پردازندهها
- نحوه مدیریت نسخههای پردازنده
- نحوه حذف پردازندهها
آنچه نیاز دارید
نظرسنجی
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را با پایتون چگونه ارزیابی میکنید؟
تجربه خود را با خدمات ابری گوگل چگونه ارزیابی میکنید؟
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان گوگل کلود را از راه دور و از طریق لپتاپ شما مدیریت کرد، اما در این آزمایشگاه از Cloud Shell ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده میکنید.
فعال کردن پوسته ابری
- از کنسول ابری، روی فعال کردن پوسته ابری کلیک کنید
 .
.

اگر این اولین باری است که Cloud Shell را اجرا میکنید، یک صفحه میانی برای توضیح آن به شما نمایش داده میشود. اگر با یک صفحه میانی مواجه شدید، روی ادامه کلیک کنید.
آمادهسازی و اتصال به Cloud Shell فقط چند لحظه طول میکشد.

این ماشین مجازی مجهز به تمام ابزارهای توسعه مورد نیاز است. این ماشین یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی افزایش میدهد. بخش عمدهای از کار شما در این آزمایشگاه کد، اگر نگوییم همه، را میتوان با یک مرورگر انجام داد.
پس از اتصال به Cloud Shell، باید ببینید که احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است.
- برای تأیید احراز هویت، دستور زیر را در Cloud Shell اجرا کنید:
gcloud auth list
خروجی دستور
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید کنید که دستور gcloud از پروژه شما اطلاع دارد:
gcloud config list project
خروجی دستور
[core] project = <PROJECT_ID>
اگر اینطور نیست، میتوانید با این دستور آن را تنظیم کنید:
gcloud config set project <PROJECT_ID>
خروجی دستور
Updated property [core/project].
۳. تنظیمات محیطی
قبل از اینکه بتوانید از Document AI استفاده کنید، دستور زیر را در Cloud Shell اجرا کنید تا Document AI API فعال شود:
gcloud services enable documentai.googleapis.com
شما باید چیزی شبیه به این را ببینید:
Operation "operations/..." finished successfully.
حالا میتوانید از هوش مصنوعی اسناد استفاده کنید!
به دایرکتوری خانگی خود بروید:
cd ~
یک محیط مجازی پایتون برای جداسازی وابستگیها ایجاد کنید:
virtualenv venv-docai
فعال کردن محیط مجازی:
source venv-docai/bin/activate
IPython، کتابخانه کلاینت Document AI، و python-tabulate (که برای چاپ زیبا نتایج درخواست از آن استفاده خواهید کرد) را نصب کنید:
pip install ipython google-cloud-documentai tabulate
شما باید چیزی شبیه به این را ببینید:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
حالا، شما آمادهی استفاده از کتابخانهی کلاینت Document AI هستید!
متغیرهای محیطی زیر را تنظیم کنید:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
از این به بعد، تمام مراحل باید در همان جلسه انجام شود.
مطمئن شوید که متغیرهای محیطی شما به درستی تعریف شدهاند:
echo $PROJECT_ID
echo $API_LOCATION
در مراحل بعدی، از یک مفسر تعاملی پایتون به نام IPython که به تازگی نصب کردهاید، استفاده خواهید کرد. با اجرای ipython در Cloud Shell، یک جلسه را آغاز کنید:
ipython
شما باید چیزی شبیه به این را ببینید:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
کد زیر را در جلسه IPython خود کپی کنید:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
شما آمادهاید تا اولین درخواست خود را ارسال کنید و انواع پردازندهها را دریافت کنید.
۴. واکشی انواع پردازنده
قبل از ایجاد پردازنده در مرحله بعد، انواع پردازندههای موجود را دریافت کنید. میتوانید این لیست را با fetch_processor_types بازیابی کنید.
توابع زیر را به جلسه IPython خود اضافه کنید:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
انواع پردازنده را فهرست کنید:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
شما باید چیزی شبیه به شکل زیر دریافت کنید:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
اکنون، تمام اطلاعات مورد نیاز برای ایجاد پردازندهها در مرحله بعدی را دارید.
۵. ایجاد پردازندهها
برای ایجاد یک پردازنده، تابع create_processor را به همراه نام نمایشی و نوع پردازنده فراخوانی کنید.
تابع زیر را اضافه کنید:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
پردازندههای آزمایشی را ایجاد کنید:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
شما باید موارد زیر را دریافت کنید:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
شما پردازندههای جدیدی ساختهاید!
در مرحله بعد، نحوه فهرست کردن پردازندهها را ببینید.
۶. فهرست کردن پردازندههای پروژه
list_processors لیست تمام پردازندههای متعلق به پروژه شما را برمیگرداند.
توابع زیر را اضافه کنید:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
توابع را فراخوانی کنید:
processors = list_processors()
print_processors(processors)
شما باید موارد زیر را دریافت کنید:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
برای بازیابی یک پردازنده با استفاده از نام نمایشی آن، تابع زیر را اضافه کنید:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
تابع را آزمایش کنید:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
شما باید چیزی شبیه به این را ببینید:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
حالا، شما میدانید که چگونه پردازندههای پروژه خود را فهرست کنید و آنها را با نام نمایشیشان بازیابی کنید. در مرحله بعد، نحوه استفاده از یک پردازنده را خواهید آموخت.
۷. استفاده از پردازندهها
اسناد را میتوان به دو صورت بررسی کرد:
- همگامسازی : برای تجزیه و تحلیل یک سند واحد و استفاده مستقیم از نتایج،
process_documentرا فراخوانی کنید. - به صورت ناهمگام : برای اجرای پردازش دستهای روی چندین سند یا اسناد بزرگ، تابع
batch_process_documentsرا فراخوانی کنید.
سند آزمایشی شما ( PDF ) یک پرسشنامه اسکن شده است که با پاسخهای دستنویس تکمیل شده است. آن را مستقیماً از جلسه IPython خود در دایرکتوری کاری خود دانلود کنید:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
محتوای دایرکتوری کاری خود را بررسی کنید:
!ls
شما باید موارد زیر را داشته باشید:
... form.pdf ... venv-docai ...
شما میتوانید از متد process_document همزمان برای تحلیل یک فایل محلی استفاده کنید. تابع زیر را اضافه کنید:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
از آنجا که سند شما یک پرسشنامه است، تجزیهگر فرم را انتخاب کنید. این پردازنده عمومی علاوه بر استخراج متن (چاپی و دستنویس) که همه پردازندهها انجام میدهند، فیلدهای فرم را نیز تشخیص میدهد.
تحلیل سند:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
همه پردازندهها یک مرحله اول تشخیص نوری کاراکتر (OCR) را روی سند اجرا میکنند. متن شناسایی شده توسط مرحله OCR را بررسی کنید:
document.text.split("\n")
شما باید چیزی شبیه به موارد زیر را ببینید:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
توابع زیر را برای چاپ فیلدهای فرم شناسایی شده اضافه کنید:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
همچنین این توابع کاربردی را اضافه کنید:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
فیلدهای فرم شناسایی شده را چاپ کنید:
print_form_fields(document)
شما باید یک نسخه چاپی مانند زیر دریافت کنید:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
نامها و مقادیر فیلدهای شناساییشده را مرور کنید ( PDF ). در اینجا نیمه بالایی پرسشنامه آمده است:

شما فرمی را که شامل متن چاپی و دستنویس است، تجزیه و تحلیل کردهاید. همچنین فیلدهای آن را با اطمینان بالا شناسایی کردهاید. نتیجه این است که پیکسلهای شما به دادههای ساختاریافته تبدیل شدهاند!
۸. فعال و غیرفعال کردن پردازندهها
با disable_processor و enable_processor میتوانید کنترل کنید که آیا یک پردازنده میتواند مورد استفاده قرار گیرد یا خیر.
توابع زیر را اضافه کنید:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
پردازندهی تجزیهگر فرم را غیرفعال کنید و وضعیت پردازندههای خود را بررسی کنید:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
شما باید موارد زیر را دریافت کنید:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
پردازنده تجزیهکننده فرم را دوباره فعال کنید:
enable_processor(processor)
print_processors()
شما باید موارد زیر را دریافت کنید:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
در مرحله بعد، نحوه مدیریت نسخههای پردازنده را ببینید.
۹. مدیریت نسخههای پردازنده
پردازندهها میتوانند در نسخههای مختلفی موجود باشند. نحوه استفاده از متدهای list_processor_versions و set_default_processor_version را بررسی کنید.
توابع زیر را اضافه کنید:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
نسخههای موجود برای پردازنده OCR را فهرست کنید:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
نسخههای پردازنده را دریافت میکنید:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
حالا، یک تابع برای تغییر نسخه پردازنده پیشفرض اضافه کنید:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
به آخرین نسخه پردازنده تغییر دهید:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
پیکربندی نسخه جدید را دریافت میکنید:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
و در مرحله بعد، روش نهایی مدیریت پردازنده (حذف).
۱۰. حذف پردازندهها
در نهایت، نحوه استفاده از متد delete_processor را بررسی کنید.
تابع زیر را اضافه کنید:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
پردازندههای آزمایشی خود را حذف کنید:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
شما باید موارد زیر را دریافت کنید:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
شما تمام روشهای مدیریت پردازنده را پوشش دادهاید! تقریباً کار تمام است...
۱۱. تبریک میگویم!
شما یاد گرفتید که چگونه پردازندههای هوش مصنوعی اسناد را با استفاده از پایتون مدیریت کنید!
تمیز کردن
برای پاکسازی محیط توسعه خود، از Cloud Shell:
- اگر هنوز در جلسه IPython خود هستید، به پوسته برگردید:
exit - استفاده از محیط مجازی پایتون را متوقف کنید:
deactivate - پوشه محیط مجازی خود را حذف کنید:
cd ~ ; rm -rf ./venv-docai
برای حذف پروژه Google Cloud خود، از Cloud Shell:
- شناسه پروژه فعلی خود را بازیابی کنید:
PROJECT_ID=$(gcloud config get-value core/project) - مطمئن شوید که این پروژهای است که میخواهید حذف کنید:
echo $PROJECT_ID - حذف پروژه:
gcloud projects delete $PROJECT_ID
بیشتر بدانید
- هوش مصنوعی اسناد را در مرورگر خود امتحان کنید: https://cloud.google.com/document-ai/docs/drag-and-drop
- جزئیات پردازنده هوش مصنوعی سند: https://cloud.google.com/document-ai/docs/processors-list
- پایتون در گوگل کلود: https://cloud.google.com/python
- کتابخانههای کلاینت ابری برای پایتون: https://github.com/googleapis/google-cloud-python
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 2.0 منتشر شده است.