
1. Ringkasan

Apa itu Document AI?
Document AI adalah platform yang memungkinkan Anda mengekstrak insight dari dokumen Anda. Pada dasarnya, fitur ini menawarkan daftar pemroses dokumen yang terus bertambah (juga disebut parser atau pemisah, bergantung pada fungsinya).
Ada dua cara untuk mengelola pemroses Document AI:
- secara manual, dari konsol web;
- secara terprogram, menggunakan Document AI API.
Berikut adalah contoh screenshot yang menampilkan daftar pemroses Anda, baik dari konsol web maupun dari kode Python:
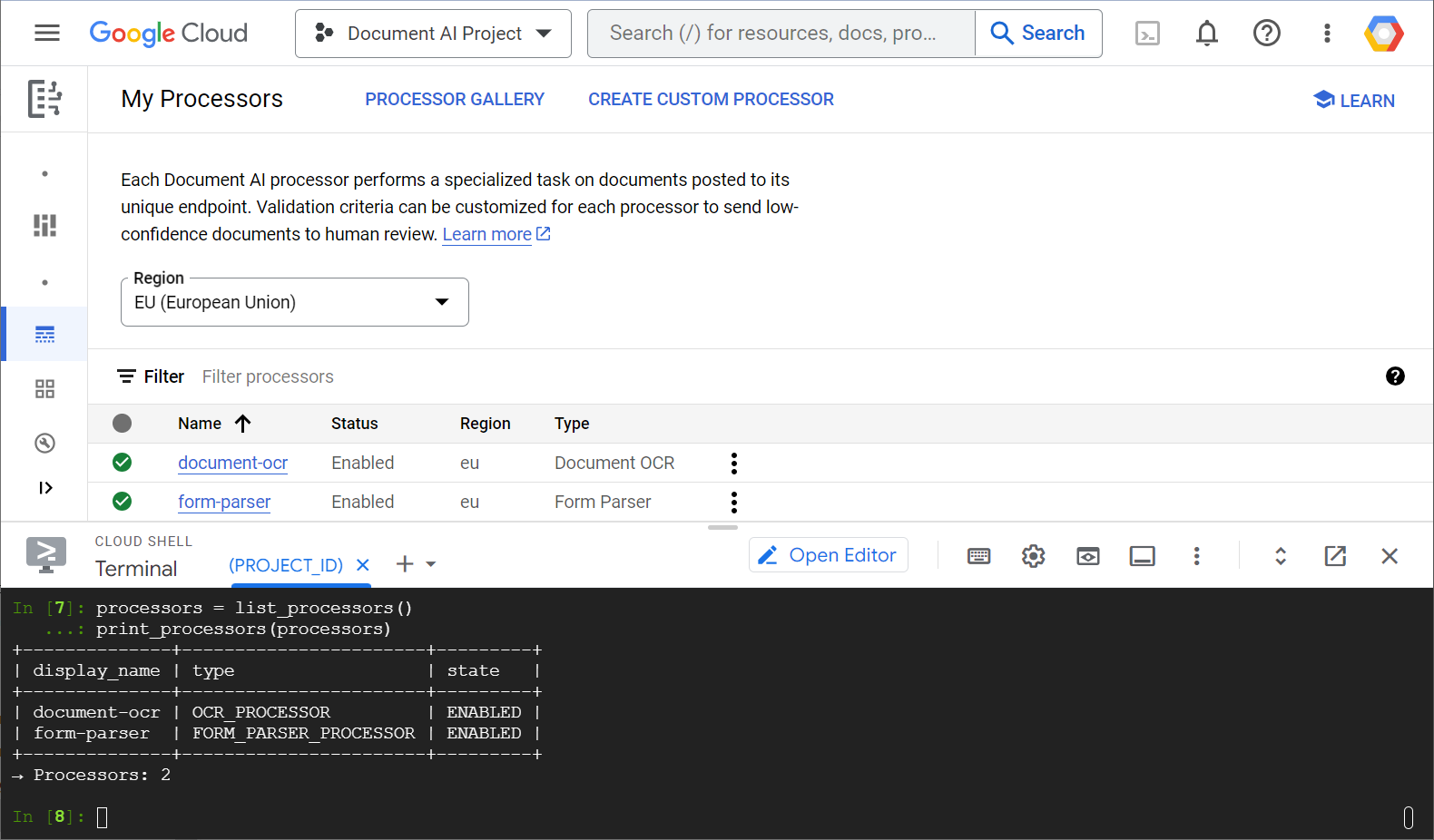
Di lab ini, Anda akan berfokus pada pengelolaan pemroses Document AI secara terprogram dengan library klien Python.
Yang akan Anda lihat
- Cara menyiapkan lingkungan Anda
- Cara mengambil jenis pemroses
- Cara membuat pemroses
- Cara mencantumkan pemroses project
- Cara menggunakan pemroses
- Cara mengaktifkan/menonaktifkan prosesor
- Cara mengelola versi pemroses
- Cara menghapus pemroses
Yang Anda butuhkan
Survei
Bagaimana Anda akan menggunakan tutorial ini?
Bagaimana penilaian Anda terhadap pengalaman dengan Python?
Bagaimana penilaian Anda terhadap pengalaman menggunakan layanan Google Cloud?
2. Penyiapan dan persyaratan
Penyiapan lingkungan mandiri
- Login ke Google Cloud Console dan buat project baru atau gunakan kembali project yang sudah ada. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.

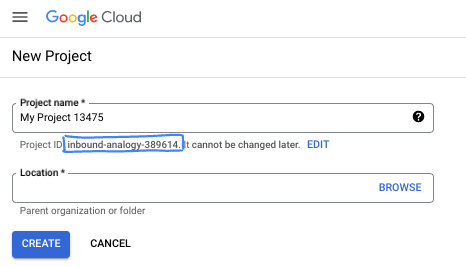
- Project name adalah nama tampilan untuk peserta project ini. String ini adalah string karakter yang tidak digunakan oleh Google API. Anda dapat memperbaruinya kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Cloud Console otomatis membuat string unik; biasanya Anda tidak mementingkan kata-katanya. Di sebagian besar codelab, Anda harus merujuk Project ID-nya (umumnya diidentifikasi sebagai
PROJECT_ID). Jika tidak suka dengan ID yang dibuat, Anda dapat membuat ID acak lainnya. Atau, Anda dapat mencobanya sendiri, dan lihat apakah ID tersebut tersedia. ID tidak dapat diubah setelah langkah ini dan tersedia selama durasi project. - Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
- Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource/API Cloud. Menjalankan operasi dalam codelab ini tidak akan memakan banyak biaya, bahkan mungkin tidak sama sekali. Guna mematikan resource agar tidak menimbulkan penagihan di luar tutorial ini, Anda dapat menghapus resource yang dibuat atau menghapus project-nya. Pengguna baru Google Cloud memenuhi syarat untuk mengikuti program Uji Coba Gratis senilai $300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam lab ini, Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Cloud.
Mengaktifkan Cloud Shell
- Dari Cloud Console, klik Aktifkan Cloud Shell
 .
.

Jika ini adalah pertama kalinya Anda memulai Cloud Shell, Anda akan melihat layar perantara yang menjelaskan apa itu Cloud Shell. Jika Anda melihat layar perantara, klik Continue.
Perlu waktu beberapa saat untuk menyediakan dan terhubung ke Cloud Shell.

Virtual machine ini dilengkapi dengan semua alat pengembangan yang diperlukan. VM ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Sebagian besar pekerjaan Anda dalam codelab ini dapat dilakukan dengan browser.
Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda telah diautentikasi dan project telah ditetapkan ke project ID Anda.
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa Anda telah diautentikasi:
gcloud auth list
Output perintah
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda:
gcloud config list project
Output perintah
[core] project = <PROJECT_ID>
Jika tidak, Anda dapat menyetelnya dengan perintah ini:
gcloud config set project <PROJECT_ID>
Output perintah
Updated property [core/project].
3. Penyiapan lingkungan
Sebelum dapat mulai menggunakan Document AI, jalankan perintah berikut di Cloud Shell untuk mengaktifkan Document AI API:
gcloud services enable documentai.googleapis.com
Anda akan melihat yang seperti ini:
Operation "operations/..." finished successfully.
Sekarang, Anda dapat menggunakan Document AI.
Buka direktori utama Anda:
cd ~
Buat lingkungan virtual Python untuk mengisolasi dependensi:
virtualenv venv-docai
Aktifkan lingkungan virtual:
source venv-docai/bin/activate
Instal IPython, library klien Document AI, dan python-tabulate (yang akan Anda gunakan untuk mencetak hasil permintaan dengan rapi):
pip install ipython google-cloud-documentai tabulate
Anda akan melihat yang seperti ini:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Sekarang, Anda siap menggunakan library klien Document AI.
Tetapkan variabel lingkungan berikut:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
Mulai sekarang, semua langkah harus diselesaikan dalam sesi yang sama.
Pastikan variabel lingkungan Anda ditentukan dengan benar:
echo $PROJECT_ID
echo $API_LOCATION
Pada langkah berikutnya, Anda akan menggunakan penafsir Python interaktif yang disebut IPython, yang baru saja Anda instal. Mulai sesi dengan menjalankan ipython di Cloud Shell:
ipython
Anda akan melihat yang seperti ini:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Salin kode berikut ke sesi IPython Anda:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Anda siap membuat permintaan pertama dan mengambil jenis pemroses.
4. Mengambil jenis pemroses
Sebelum membuat pemroses di langkah berikutnya, ambil jenis pemroses yang tersedia. Anda dapat mengambil daftar ini dengan fetch_processor_types.
Tambahkan fungsi berikut ke sesi IPython Anda:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Mencantumkan jenis pemroses:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Anda akan mendapatkan sesuatu seperti berikut:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Sekarang, Anda memiliki semua info yang diperlukan untuk membuat pemroses di langkah berikutnya.
5. Membuat pemroses
Untuk membuat prosesor, panggil create_processor dengan nama tampilan dan jenis prosesor.
Tambahkan fungsi berikut:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Buat pemroses pengujian:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Anda akan mendapatkan hasil berikut:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Anda telah membuat prosesor baru.
Selanjutnya, lihat cara mencantumkan prosesor.
6. Mencantumkan pemroses project
list_processors menampilkan daftar semua pemroses yang termasuk dalam project Anda.
Tambahkan fungsi berikut:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Panggil fungsi:
processors = list_processors()
print_processors(processors)
Anda akan mendapatkan hasil berikut:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Untuk mengambil prosesor berdasarkan nama tampilannya, tambahkan fungsi berikut:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Uji fungsi:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Anda akan melihat yang seperti ini:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Sekarang, Anda mengetahui cara mencantumkan pemroses project dan mengambilnya berdasarkan nama tampilannya. Selanjutnya, lihat cara menggunakan prosesor.
7. Menggunakan prosesor
Dokumen dapat diproses dengan dua cara:
- Secara sinkron: Panggil
process_documentuntuk menganalisis satu dokumen dan langsung menggunakan hasilnya. - Secara asinkron: Panggil
batch_process_documentsuntuk meluncurkan pemrosesan batch pada beberapa dokumen atau dokumen berukuran besar.
Dokumen uji Anda ( PDF) adalah kuesioner hasil pindaian yang diisi dengan jawaban tulisan tangan. Download ke direktori kerja Anda, langsung dari sesi IPython Anda:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Periksa konten direktori kerja Anda:
!ls
Anda harus memiliki hal berikut:
... form.pdf ... venv-docai ...
Anda dapat menggunakan metode process_document sinkron untuk menganalisis file lokal. Tambahkan fungsi berikut:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Karena dokumen Anda adalah kuesioner, pilih pengurai formulir. Selain mengekstrak teks (cetak dan tulis tangan), yang dilakukan oleh semua pemroses, pemroses umum ini mendeteksi kolom formulir.
Menganalisis dokumen:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Semua pemroses menjalankan pengenalan karakter optik (OCR) pada dokumen terlebih dahulu. Tinjau teks yang terdeteksi oleh proses OCR:
document.text.split("\n")
Anda akan melihat sesuatu seperti berikut:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Tambahkan fungsi berikut untuk mencetak kolom formulir yang terdeteksi:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Tambahkan juga fungsi utilitas berikut:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Mencetak kolom formulir yang terdeteksi:
print_form_fields(document)
Anda akan mendapatkan hasil cetak seperti berikut:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Tinjau nama dan nilai kolom yang telah terdeteksi ( PDF). Berikut adalah bagian atas kuesioner:

Anda telah menganalisis formulir yang berisi teks cetak dan tulisan tangan. Anda juga telah mendeteksi kolomnya dengan keyakinan tinggi. Hasilnya, piksel Anda telah diubah menjadi data terstruktur.
8. Mengaktifkan dan menonaktifkan pemroses
Dengan disable_processor dan enable_processor, Anda dapat mengontrol apakah suatu pemroses dapat digunakan.
Tambahkan fungsi berikut:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Nonaktifkan pemroses parser formulir, dan periksa status pemroses Anda:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Anda akan mendapatkan hasil berikut:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Aktifkan kembali pemroses parser formulir:
enable_processor(processor)
print_processors()
Anda akan mendapatkan hasil berikut:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Selanjutnya, lihat cara mengelola versi pemroses.
9. Mengelola versi pemroses
Prosesor dapat tersedia dalam beberapa versi. Lihat cara menggunakan metode list_processor_versions dan set_default_processor_version.
Tambahkan fungsi berikut:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Mencantumkan versi yang tersedia untuk pemroses OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Anda akan mendapatkan versi pemroses:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Sekarang, tambahkan fungsi untuk mengubah versi pemroses default:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Beralih ke versi pemroses terbaru:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Anda mendapatkan konfigurasi versi baru:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Selanjutnya, metode pengelolaan prosesor utama (penghapusan).
10. Menghapus pemroses
Terakhir, lihat cara menggunakan metode delete_processor.
Tambahkan fungsi berikut:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Hapus pemroses pengujian Anda:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Anda akan mendapatkan hasil berikut:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Anda telah mempelajari semua metode pengelolaan prosesor. Anda hampir selesai...
11. Selamat!
Anda telah mempelajari cara mengelola pemroses Document AI menggunakan Python.
Pembersihan
Untuk membersihkan lingkungan pengembangan Anda, dari Cloud Shell:
- Jika Anda masih berada di sesi IPython, kembali ke shell:
exit - Berhenti menggunakan lingkungan virtual Python:
deactivate - Hapus folder lingkungan virtual Anda:
cd ~ ; rm -rf ./venv-docai
Untuk menghapus project Google Cloud Anda, dari Cloud Shell:
- Ambil project ID Anda saat ini:
PROJECT_ID=$(gcloud config get-value core/project) - Pastikan ini adalah project yang ingin Anda hapus:
echo $PROJECT_ID - Menghapus project:
gcloud projects delete $PROJECT_ID
Pelajari lebih lanjut
- Coba Document AI di browser Anda: https://cloud.google.com/document-ai/docs/drag-and-drop
- Detail prosesor Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python di Google Cloud: https://cloud.google.com/python
- Library Klien Cloud untuk Python: https://github.com/googleapis/google-cloud-python
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 2.0.