
1. Panoramica

Che cos'è Document AI?
Document AI è una piattaforma che ti consente di estrarre insight dai tuoi documenti. In sostanza, offre un elenco crescente di elaboratori di documenti (chiamati anche analizzatori o separatori, a seconda della loro funzionalità).
Esistono due modi per gestire i processori Document AI:
- manualmente, dalla console web;
- in modo programmatico, utilizzando l'API Document AI.
Ecco uno screenshot di esempio che mostra l'elenco dei processori, sia dalla console web sia dal codice Python:
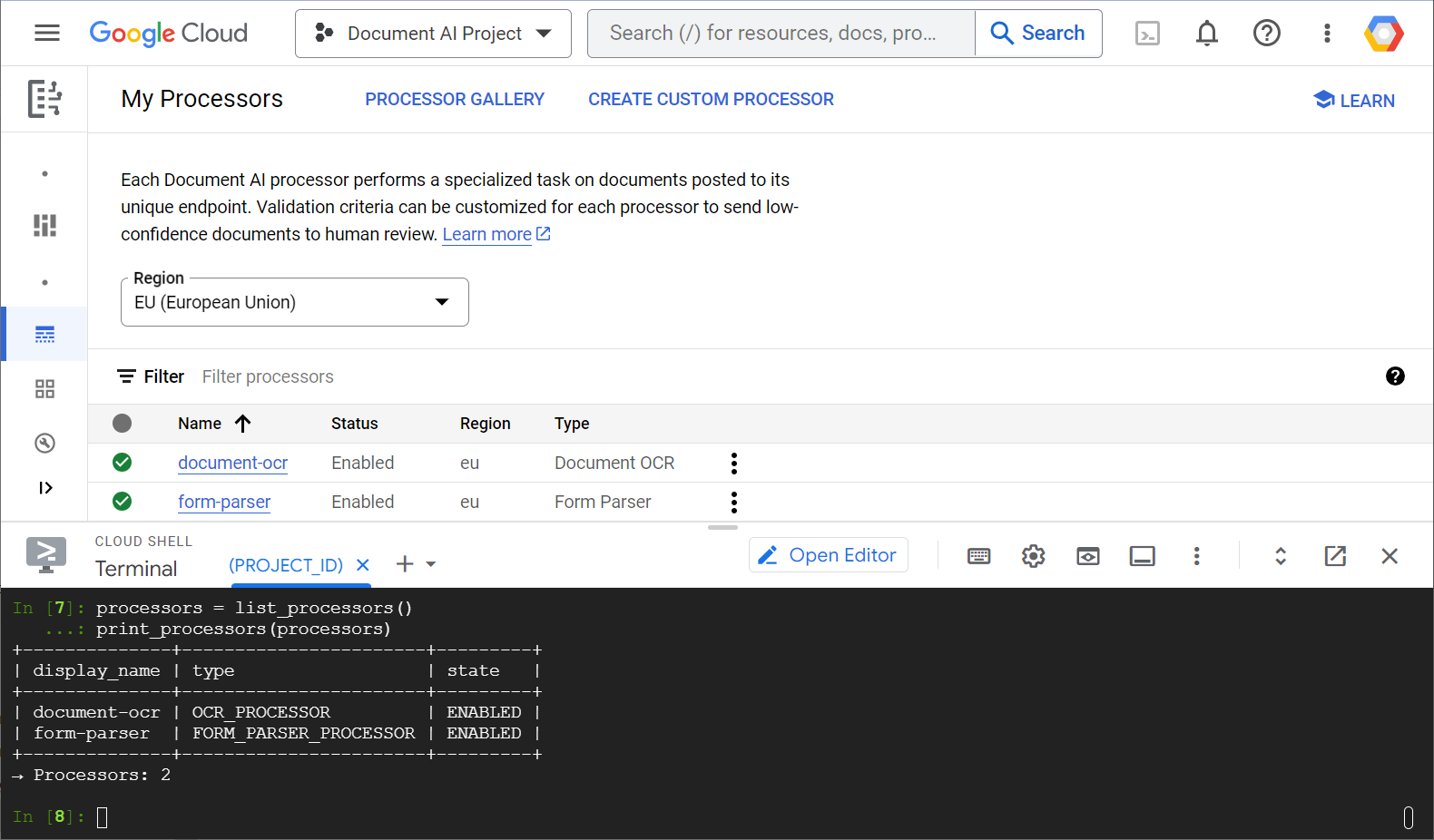
In questo lab ti concentrerai sulla gestione dei processori Document AI a livello di programmazione con la libreria client Python.
Informazioni visualizzate
- Come configurare l'ambiente
- Come recuperare i tipi di processore
- Come creare processori
- Come elencare i responsabili del trattamento del progetto
- Come utilizzare i processori
- Come attivare/disattivare i processori
- Come gestire le versioni del processore
- Come eliminare i responsabili del trattamento
Che cosa ti serve
- Un progetto Google Cloud
- Un browser, ad esempio Chrome o Firefox
- Familiarità con l'utilizzo di Python
Sondaggio
Come utilizzerai questo tutorial?
Come valuteresti la tua esperienza con Python?
Come valuteresti la tua esperienza con i servizi Google Cloud?
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

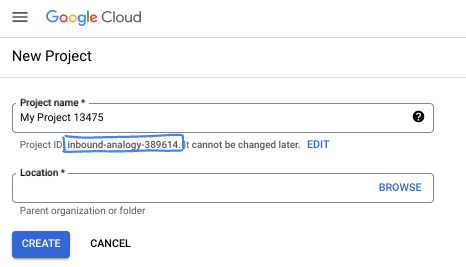
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo lab utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Attiva Cloud Shell
- Nella console Cloud, fai clic su Attiva Cloud Shell
 .
.

Se è la prima volta che avvii Cloud Shell, viene visualizzata una schermata intermedia che ne descrive le funzionalità. Se è stata visualizzata una schermata intermedia, fai clic su Continua.
Bastano pochi istanti per eseguire il provisioning e connettersi a Cloud Shell.

Questa macchina virtuale è caricata con tutti gli strumenti di sviluppo necessari. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Gran parte del lavoro per questo codelab, se non tutto, può essere svolto con un browser.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è autenticato e il progetto è impostato sul tuo ID progetto.
- Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto:
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
3. Configurazione dell'ambiente
Prima di poter iniziare a utilizzare Document AI, esegui il seguente comando in Cloud Shell per abilitare l'API Document AI:
gcloud services enable documentai.googleapis.com
Il risultato dovrebbe essere simile a questo:
Operation "operations/..." finished successfully.
Ora puoi utilizzare Document AI.
Vai alla home directory:
cd ~
Crea un ambiente virtuale Python per isolare le dipendenze:
virtualenv venv-docai
Attiva l'ambiente virtuale:
source venv-docai/bin/activate
Installa IPython, la libreria client Document AI e python-tabulate (che utilizzerai per stampare in modo leggibile i risultati della richiesta):
pip install ipython google-cloud-documentai tabulate
Il risultato dovrebbe essere simile a questo:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Ora puoi utilizzare la libreria client Document AI.
Imposta le seguenti variabili di ambiente:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
D'ora in poi, tutti i passaggi devono essere completati nella stessa sessione.
Assicurati che le variabili di ambiente siano definite correttamente:
echo $PROJECT_ID
echo $API_LOCATION
Nei passaggi successivi, utilizzerai un interprete Python interattivo chiamato IPython, che hai appena installato. Avvia una sessione eseguendo ipython in Cloud Shell:
ipython
Il risultato dovrebbe essere simile a questo:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Copia il seguente codice nella sessione IPython:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Ora puoi effettuare la tua prima richiesta e recuperare i tipi di processore.
4. Recupero dei tipi di processore
Prima di creare un processore nel passaggio successivo, recupera i tipi di processore disponibili. Puoi recuperare questo elenco con fetch_processor_types.
Aggiungi le seguenti funzioni alla sessione IPython:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Elenca i tipi di processore:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Dovresti ottenere un risultato simile al seguente:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Ora hai tutte le informazioni necessarie per creare i processori nel passaggio successivo.
5. Creazione di processori
Per creare un processore, chiama create_processor con un nome visualizzato e un tipo di processore.
Aggiungi la seguente funzione:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Crea i processori di test:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Dovresti ottenere quanto segue:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Hai creato nuovi processori.
Successivamente, scopri come elencare i responsabili del trattamento.
6. Elenco dei processori di progetti
list_processors restituisce l'elenco di tutti i processori appartenenti al tuo progetto.
Aggiungi le seguenti funzioni:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Chiama le funzioni:
processors = list_processors()
print_processors(processors)
Dovresti ottenere quanto segue:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Per recuperare un processore in base al nome visualizzato, aggiungi la seguente funzione:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Testa la funzione:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Il risultato dovrebbe essere simile a questo:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Ora sai come elencare i responsabili del trattamento del tuo progetto e recuperarli in base ai loro nomi visualizzati. Successivamente, scopri come utilizzare un processore.
7. Utilizzo dei processori
I documenti possono essere elaborati in due modi:
- In modo sincrono: chiama
process_documentper analizzare un singolo documento e utilizzare direttamente i risultati. - In modo asincrono: chiama
batch_process_documentsper avviare l'elaborazione batch su più documenti o documenti di grandi dimensioni.
Il documento di test ( PDF) è un questionario scansionato compilato con risposte scritte a mano. Scaricalo nella directory di lavoro direttamente dalla sessione IPython:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Controlla il contenuto della directory di lavoro:
!ls
Devi disporre di quanto segue:
... form.pdf ... venv-docai ...
Puoi utilizzare il metodo sincrono process_document per analizzare un file locale. Aggiungi la seguente funzione:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Poiché il tuo documento è un questionario, scegli il parser del modulo. Oltre a estrarre il testo (stampato e scritto a mano), come fanno tutti i processori, questo processore generico rileva i campi del modulo.
Analizza il documento:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Tutti i processori eseguono una prima passata di riconoscimento ottico dei caratteri (OCR) sul documento. Esamina il testo rilevato dal passaggio OCR:
document.text.split("\n")
Dovresti visualizzare un risultato simile al seguente:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Aggiungi le seguenti funzioni per stampare i campi del modulo rilevati:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Aggiungi anche queste funzioni di utilità:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Stampa i campi del modulo rilevati:
print_form_fields(document)
Dovresti ottenere una stampa simile alla seguente:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Esamina i nomi e i valori dei campi rilevati ( PDF). Ecco la prima metà del questionario:

Hai analizzato un modulo che contiene testo stampato e scritto a mano. Hai anche rilevato i relativi campi con un grado di confidenza elevato. Il risultato è che i pixel sono stati trasformati in dati strutturati.
8. Attivazione e disattivazione dei processori
Con disable_processor e enable_processor, puoi controllare se un processore può essere utilizzato.
Aggiungi le seguenti funzioni:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Disattiva il processore dell'analizzatore sintattico di moduli e controlla lo stato dei processori:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Dovresti ottenere quanto segue:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Riattiva il processore dell'analizzatore sintattico di moduli:
enable_processor(processor)
print_processors()
Dovresti ottenere quanto segue:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Successivamente, scopri come gestire le versioni del processore.
9. Gestione delle versioni del processore
I processori possono essere disponibili in più versioni. Scopri come utilizzare i metodi list_processor_versions e set_default_processor_version.
Aggiungi le seguenti funzioni:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Elenca le versioni disponibili per il processore OCR:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Vengono visualizzate le versioni del processore:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Ora aggiungi una funzione per modificare la versione predefinita del processore:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Passa all'ultima versione del processore:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Viene visualizzata la configurazione della nuova versione:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Infine, il metodo di gestione definitivo del processore (eliminazione).
10. Eliminazione dei processori
Infine, scopri come utilizzare il metodo delete_processor.
Aggiungi la seguente funzione:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Elimina i processori di test:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Dovresti ottenere quanto segue:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Hai esaminato tutti i metodi di gestione del processore. Ci siamo quasi…
11. Complimenti!
Hai imparato a gestire i processori Document AI utilizzando Python.
Esegui la pulizia
Per pulire l'ambiente di sviluppo, da Cloud Shell:
- Se sei ancora nella sessione IPython, torna alla shell:
exit - Interrompi l'utilizzo dell'ambiente virtuale Python:
deactivate - Elimina la cartella dell'ambiente virtuale:
cd ~ ; rm -rf ./venv-docai
Per eliminare il progetto Google Cloud, da Cloud Shell:
- Recupera l'ID progetto corrente:
PROJECT_ID=$(gcloud config get-value core/project) - Assicurati che sia il progetto che vuoi eliminare:
echo $PROJECT_ID - Elimina il progetto:
gcloud projects delete $PROJECT_ID
Scopri di più
- Prova Document AI nel browser: https://cloud.google.com/document-ai/docs/drag-and-drop
- Dettagli del processore Document AI: https://cloud.google.com/document-ai/docs/processors-list
- Python su Google Cloud: https://cloud.google.com/python
- Librerie client di Cloud per Python: https://github.com/googleapis/google-cloud-python
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 2.0 Generic.