
1. 概览

Document AI 是什么?
Document AI 是一个平台,可让您从文档中提取数据洞见。从本质上讲,它提供了一个不断增长的文档处理器列表(也称为解析器或拆分器,具体取决于其功能)。
您可以通过以下两种方式管理 Document AI 处理器:
- 通过网页控制台手动执行;
- 以编程方式使用 Document AI API。
以下示例屏幕截图显示了处理器列表(通过 Web 控制台和 Python 代码获取):
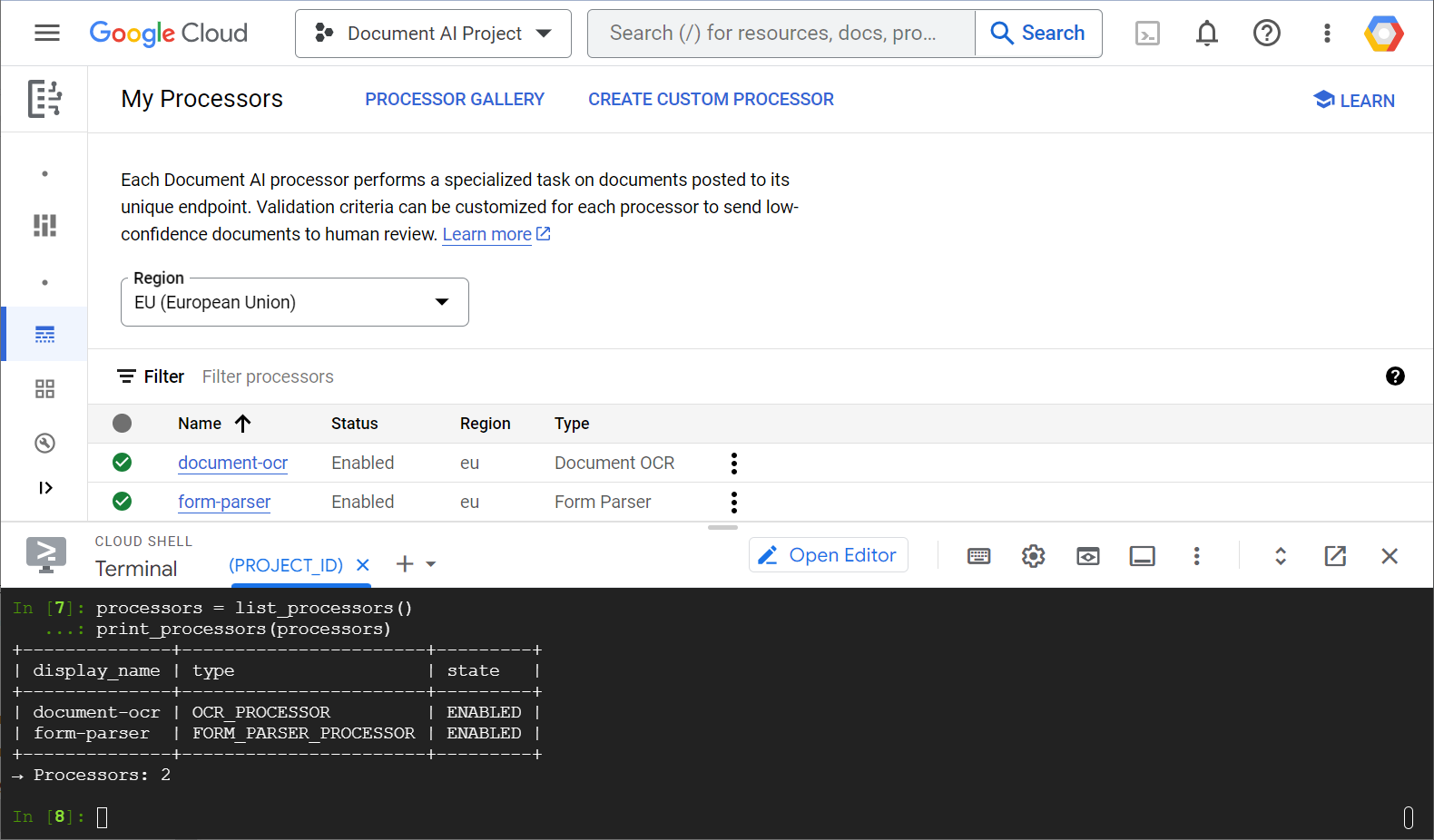
在本实验中,您将重点学习如何使用 Python 客户端库以编程方式管理 Document AI 处理器。
您将看到的内容
- 如何设置环境
- 如何获取处理器类型
- 如何创建处理器
- 如何列出项目处理器
- 如何使用处理器
- 如何启用/停用处理器
- 如何管理处理器版本
- 如何删除处理器
所需条件
调查问卷
您将如何使用本教程?
您如何评价使用 Python 的体验?
您如何评价自己在 Google Cloud 服务方面的经验水平?
2. 设置和要求
自定进度的环境设置
- 登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。

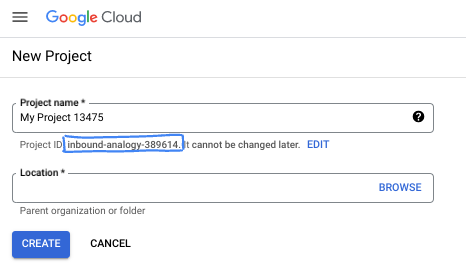
- 项目名称是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
- 接下来,您需要在 Cloud 控制台中启用结算功能,以便使用 Cloud 资源/API。运行此 Codelab 应该不会产生太多的费用(如果有的话)。若要关闭资源以避免产生超出本教程范围的结算费用,您可以删除自己创建的资源或删除项目。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此实验中,您将使用 Cloud Shell,这是一个在云端运行的命令行环境。
激活 Cloud Shell
- 在 Cloud Console 中,点击激活 Cloud Shell
 。
。

如果您是第一次启动 Cloud Shell,系统会显示一个介绍其功能的过渡页面。如果您看到了过渡页面,请点击继续。
预配和连接到 Cloud Shell 只需花几分钟时间。

这个虚拟机已加载了所需的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。只需使用一个浏览器即可完成本 Codelab 中的大部分工作。
连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的项目 ID。
- 在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目:
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
3. 环境设置
您必须先在 Cloud Shell 中运行以下命令以启用 Document AI API,然后才能开始使用 Document AI:
gcloud services enable documentai.googleapis.com
您应该会看到与以下类似的内容:
Operation "operations/..." finished successfully.
现在,您可以使用 Document AI 了!
前往您的主目录:
cd ~
创建 Python 虚拟环境以隔离依赖项:
virtualenv venv-docai
激活此虚拟环境:
source venv-docai/bin/activate
安装 IPython、Document AI 客户端库和 python-tabulate(您将使用它来美观地输出请求结果):
pip install ipython google-cloud-documentai tabulate
您应该会看到与以下类似的内容:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
现在,您可以使用 Document AI 客户端库了!
设置以下环境变量:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
从现在开始,所有步骤都应在同一会话中完成。
确保已正确定义环境变量:
echo $PROJECT_ID
echo $API_LOCATION
在接下来的步骤中,您将使用刚刚安装的名为 IPython 的交互式 Python 解释器。在 Cloud Shell 中运行 ipython 以启动会话:
ipython
您应该会看到与以下类似的内容:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
将以下代码复制到 IPython 会话中:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
您已准备好发出第一个请求并获取处理器类型。
4. 获取处理器类型
在下一步中创建处理器之前,请先获取可用的处理器类型。您可以使用 fetch_processor_types 检索此列表。
将以下函数添加到您的 IPython 会话中:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
列出处理器类型:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
您应该会看到类似以下所示的内容:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
现在,您已掌握在下一步中创建处理器所需的所有信息。
5. 创建处理器
如需创建处理器,请使用显示名和处理器类型调用 create_processor。
添加以下函数:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
创建测试处理器:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
您应该会看到以下内容:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
您已创建新的处理器!
接下来,了解如何列出处理器。
6. 列出项目处理器
list_processors 返回属于您项目的所有处理器的列表。
添加以下函数:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
调用函数:
processors = list_processors()
print_processors(processors)
您应该会看到以下内容:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
如需按显示名称检索处理器,请添加以下函数:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
测试函数:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
您应该会看到与以下类似的内容:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
现在,您已经知道如何列出项目处理器并按其显示名称检索它们了。接下来,了解如何使用处理器。
7. 使用处理器
文档可通过以下两种方式进行处理:
- 同步:调用
process_document来分析单个文档并直接使用结果。 - 异步:调用
batch_process_documents可对多个或大型文档启动批处理。
您的测试文档 ( PDF) 是一份已填写完毕的扫描版问卷,其中包含手写答案。直接从 IPython 会话中将其下载到工作目录:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
检查工作目录的内容:
!ls
您应具备以下条件:
... form.pdf ... venv-docai ...
您可以使用同步 process_document 方法来分析本地文件。添加以下函数:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
由于您的文档是问卷,请选择表单解析器。除了提取所有处理器都能提取的文本(印刷文字和手写文字)之外,此通用处理器还能检测表单字段。
分析文档:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
所有处理器都会先对文档运行光学字符识别 (OCR) 初次处理。查看 OCR 传递检测到的文本:
document.text.split("\n")
您应看到类似下图的内容:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
添加以下函数以输出检测到的表单字段:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
还添加了以下实用函数:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
输出检测到的表单字段:
print_form_fields(document)
您应该会看到如下所示的打印输出:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
查看已检测到的字段名称和值 ( PDF)。以下是问卷的上半部分:

您已分析包含印刷体文本和手写文本的表单。您还以高置信度检测到了其字段。这样一来,您的像素就已转换为结构化数据!
8. 启用和停用处理器
借助 disable_processor 和 enable_processor,您可以控制是否可以使用处理器。
添加以下函数:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
停用表单解析器处理器,并检查处理器的状态:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
您应该会看到以下内容:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
重新启用 Form Parser 处理器:
enable_processor(processor)
print_processors()
您应该会看到以下内容:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
接下来,了解如何管理处理器版本。
9. 管理处理器版本
处理器可以有多个版本。了解如何使用 list_processor_versions 和 set_default_processor_version 方法。
添加以下函数:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
列出 OCR 处理器的可用版本:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
您将获得处理器版本:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
现在,添加一个用于更改默认处理器版本的函数:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
切换到最新的处理器版本:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
您会获得新版本配置:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
接下来,介绍最终的处理器管理方法(删除)。
10. 删除处理方
最后,了解如何使用 delete_processor 方法。
添加以下函数:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
删除测试处理器:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
您应该会看到以下内容:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
您已了解所有处理器管理方法!即将大功告成…
11. 恭喜!
您已学习如何使用 Python 管理 Document AI 处理器!
清理
如需清理开发环境,请在 Cloud Shell 中执行以下操作:
- 如果您仍在 IPython 会话中,请返回到 shell:
exit - 停止使用 Python 虚拟环境:
deactivate - 删除虚拟环境文件夹:
cd ~ ; rm -rf ./venv-docai
如需删除 Google Cloud 项目,请在 Cloud Shell 中执行以下操作:
- 检索当前项目 ID:
PROJECT_ID=$(gcloud config get-value core/project) - 请确保这是您要删除的项目:
echo $PROJECT_ID - 删除项目:
gcloud projects delete $PROJECT_ID
了解详情
- 在浏览器中试用 Document AI:https://cloud.google.com/document-ai/docs/drag-and-drop
- Document AI 处理器详细信息:https://cloud.google.com/document-ai/docs/processors-list
- Google Cloud 上的 Python:https://cloud.google.com/python
- Python 版 Cloud 客户端库:https://github.com/googleapis/google-cloud-python
许可
此作品已获得 Creative Commons Attribution 2.0 通用许可授权。