
1. परिचय
पिछला अपडेट: 22-9-2022
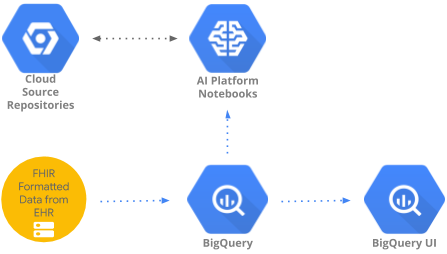
इस कोडलैब में, BigQueryUI और AI Platform Notebooks का इस्तेमाल करके, BigQuery में इकट्ठा किए गए स्वास्थ्य सेवा से जुड़े डेटा को ऐक्सेस करने और उसका विश्लेषण करने का तरीका बताया गया है. इसमें, HIPPA के मुताबिक एआई प्लैटफ़ॉर्म नोटबुक में, Pandas, Matplotlib वगैरह जैसे जाने-पहचाने टूल का इस्तेमाल करके, हेल्थकेयर के बड़े डेटासेट के डेटा एक्सप्लोरेशन के बारे में बताया गया है. "ट्रिक" यह है कि BigQuery में एग्रीगेशन का पहला हिस्सा पूरा करें. इसके बाद, Pandas डेटासेट वापस पाएं और फिर स्थानीय तौर पर छोटे Pandas डेटासेट के साथ काम करें. AI Platform Notebooks, मैनेज किया गया Jupyter अनुभव देता है. इसलिए, आपको नोटबुक सर्वर खुद नहीं चलाने पड़ते. AI Platform Notebooks को BigQuery और Cloud Storage जैसी अन्य GCP सेवाओं के साथ इंटिग्रेट किया गया है. इससे Google Cloud Platform पर डेटा ऐनलिटिक्स और एमएल की यात्रा को तेज़ी से और आसानी से शुरू किया जा सकता है.
इस कोड लैब में, आपको इनके बारे में जानकारी मिलेगी:
- BigQuery यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके, एसक्यूएल क्वेरी डेवलप और टेस्ट करें.
- GCP में AI Platform Notebooks का इंस्टेंस बनाएं और लॉन्च करें.
- नोटबुक से एसक्यूएल क्वेरी चलाएं और क्वेरी के नतीजों को Pandas DataFrame में सेव करें.
- Matplotlib का इस्तेमाल करके चार्ट और ग्राफ़ बनाएं.
- नोटबुक को GCP में मौजूद Cloud Source Repository में कमिट और पुश करें.
इस कोडलैब को चलाने के लिए, आपको किन चीज़ों की ज़रूरत होगी?
- आपके पास GCP प्रोजेक्ट का ऐक्सेस होना चाहिए.
- आपको GCP प्रोजेक्ट के लिए, मालिक की भूमिका असाइन की जानी चाहिए.
- आपके पास BigQuery में हेल्थकेयर डेटासेट होना चाहिए.
अगर आपके पास GCP प्रोजेक्ट नहीं है, तो नया GCP प्रोजेक्ट बनाने के लिए यह तरीका अपनाएं.
2. प्रोजेक्ट सेटअप करना
इस कोडलैब के लिए, हम BigQuery में मौजूद डेटासेट (hcls-testing-data.fhir_20k_patients_analytics) का इस्तेमाल करेंगे. इस डेटासेट में, स्वास्थ्य सेवा से जुड़ा सिंथेटिक डेटा पहले से मौजूद होता है.
सिंथेटिक डेटासेट का ऐक्सेस पाना
- Cloud Console में लॉग इन करने के लिए इस्तेमाल किए जा रहे ईमेल पते से, hcls-solutions-external+subscribe@google.com पर शामिल होने का अनुरोध करने वाला ईमेल भेजें.
- आपको एक ईमेल मिलेगा, जिसमें कार्रवाई की पुष्टि करने के निर्देश होंगे.
- ग्रुप में शामिल होने के लिए, ईमेल का जवाब देने वाले विकल्प का इस्तेमाल करें.
 बटन पर क्लिक न करें.
बटन पर क्लिक न करें. - पुष्टि करने वाला ईमेल मिलने के बाद, कोडलैब के अगले चरण पर जाएं.
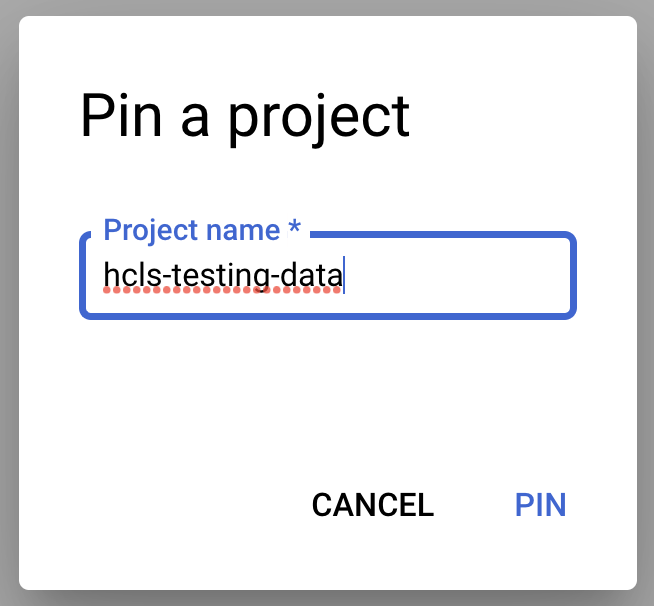
प्रोजेक्ट को पिन करना
- GCP Console में, अपना प्रोजेक्ट चुनें. इसके बाद, BigQuery पर जाएं.
- +डेटा जोड़ें ड्रॉपडाउन पर क्लिक करें. इसके बाद, "किसी प्रोजेक्ट को पिन करें" > "प्रोजेक्ट का नाम डालें" चुनें.

- प्रोजेक्ट का नाम, "hcls-testing-data" डालें. इसके बाद, पिन करें पर क्लिक करें. BigQuery का टेस्ट डेटासेट "fhir_20k_patients_analytics" इस्तेमाल के लिए उपलब्ध है.
3. BigQuery यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके क्वेरी डेवलप करना
BigQuery के यूज़र इंटरफ़ेस (यूआई) की सेटिंग
- सबसे ऊपर बाईं ओर मौजूद ("हैमबर्गर") GCP मेन्यू में जाकर, BigQuery कंसोल पर जाएं.
- BigQuery कंसोल में, ज़्यादा → क्वेरी सेटिंग पर क्लिक करें. साथ ही, पक्का करें कि लेगसी एसक्यूएल मेन्यू पर निशान न लगा हो (हम स्टैंडर्ड एसक्यूएल का इस्तेमाल करेंगे).

क्वेरी बनाना
क्वेरी एडिटर विंडो में, यह क्वेरी टाइप करें और इसे चलाने के लिए "चलाएं" पर क्लिक करें. इसके बाद, "क्वेरी के नतीजे" विंडो में नतीजे देखें.
मरीजों के बारे में क्वेरी करना
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"क्वेरी एडिटर" में क्वेरी और नतीजे:

क्वेरी प्रैक्टिशनर
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
क्वेरी के नतीजे:

क्वेरी संगठन
संगठन का आईडी बदलकर, उसे अपने डेटासेट से मैच करें.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
क्वेरी के नतीजे:

मरीज़ की क्वेरी
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
क्वेरी के नतीजे:

GET AVG LENGTH OF ENCOUNTERS BY ENCOUNTER TYPE
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
क्वेरी के नतीजे:

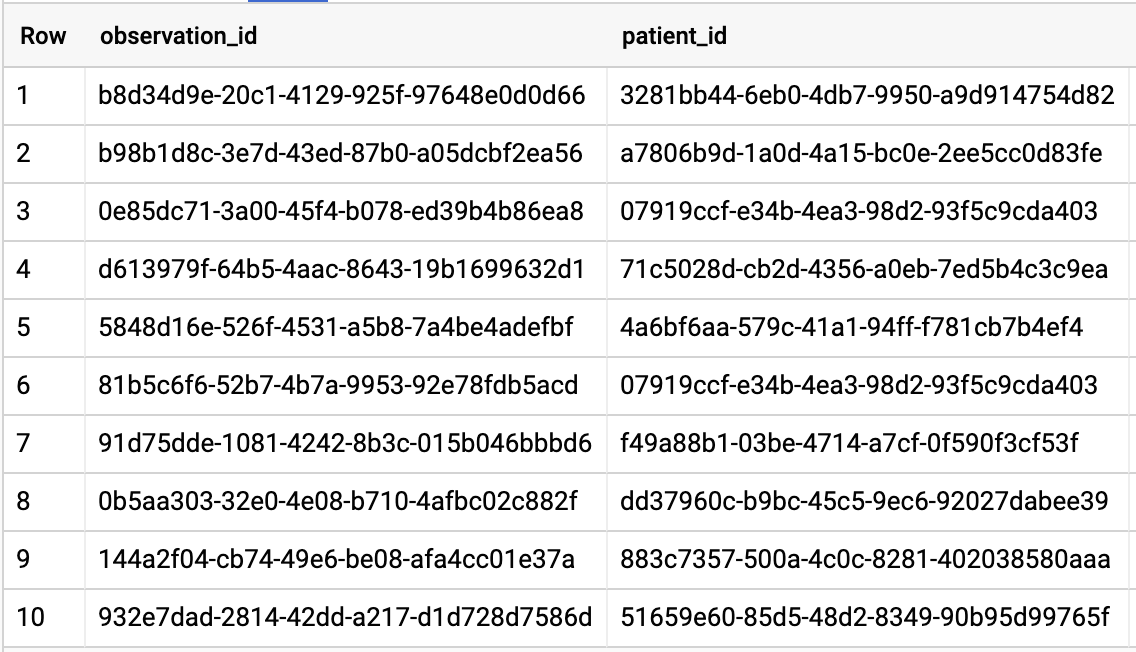
उन सभी मरीज़ों की जानकारी पाएं जिनका A1C रेट 6.5 या इससे ज़्यादा है
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
क्वेरी के नतीजे:
4. AI Platform Notebooks इंस्टेंस बनाना
नया AI Platform Notebooks (JupyterLab) इंस्टेंस बनाने के लिए, इस लिंक में दिए गए निर्देशों का पालन करें.
कृपया पक्का करें कि आपने Compute Engine API चालू किया हो.
आपके पास " डिफ़ॉल्ट विकल्पों के साथ नई नोटबुक बनाएं" या " नई नोटबुक बनाएं और अपने विकल्प तय करें" में से किसी एक को चुनने का विकल्प होता है.
5. डेटा विश्लेषण नोटबुक बनाना
AI Platform Notebooks का इंस्टेंस खोलें
इस सेक्शन में, हम शुरुआत से एक नई Jupyter notebook बनाएंगे और उसे कोड करेंगे.
- Google Cloud Platform Console में AI Platform Notebooks पेज पर जाकर, कोई नोटबुक इंस्टेंस खोलें. AI Platform Notebooks पेज पर जाएं
- आपको जिस इंस्टेंस को खोलना है उसके लिए, JupyterLab खोलें को चुनें.

- AI Platform Notebooks, आपको नोटबुक इंस्टेंस के यूआरएल पर रीडायरेक्ट करता है.
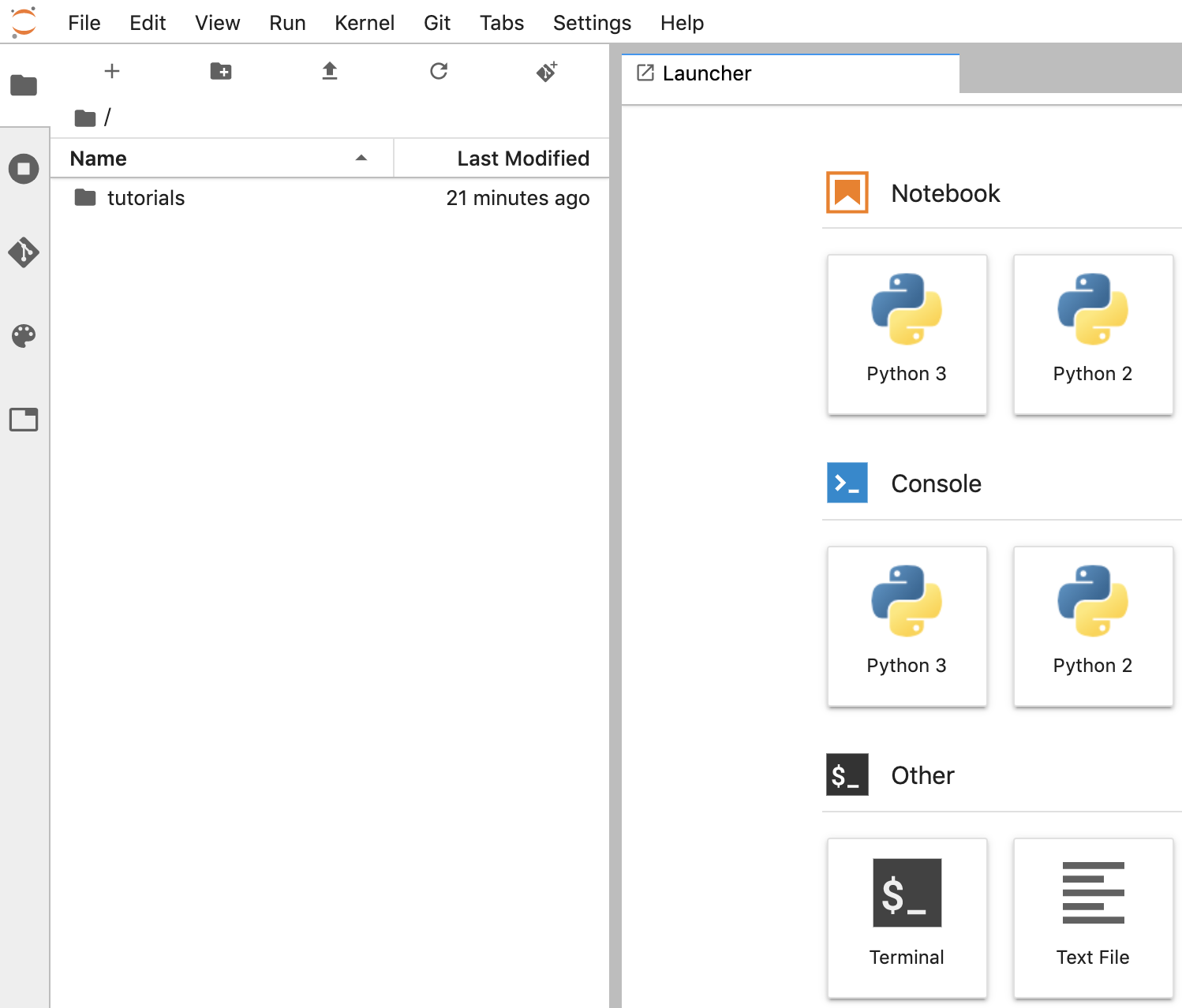
नोटबुक बनाना
- JupyterLab में, File -> New -> Notebook पर जाएं. इसके बाद, पॉप-अप में "Python 3" कर्नल चुनें. इसके अलावा, लॉन्चर विंडो में Notebook सेक्शन में जाकर "Python 3" चुनें, ताकि Untitled.ipynbnotebook बनाया जा सके.
- Untitled.ipynb पर राइट क्लिक करें और नोटबुक का नाम बदलकर "fhir_data_from_bigquery.ipynb" करें. इसे खोलने के लिए दो बार क्लिक करें, क्वेरी बनाएं, और नोटबुक सेव करें.
- नोटबुक डाउनलोड करने के लिए, *.ipynb फ़ाइल पर राइट क्लिक करें. इसके बाद, मेन्यू से डाउनलोड करें चुनें.
- "ऊपर की ओर वाला ऐरो" बटन पर क्लिक करके, मौजूदा नोटबुक भी अपलोड की जा सकती है.

नोटबुक में मौजूद हर कोड ब्लॉक को बनाना और उसे चलाना
इस सेक्शन में दिए गए हर कोड ब्लॉक को एक-एक करके कॉपी करें और चलाएं. कोड लागू करने के लिए, "चलाएं" (ट्रायंगल) पर क्लिक करें.

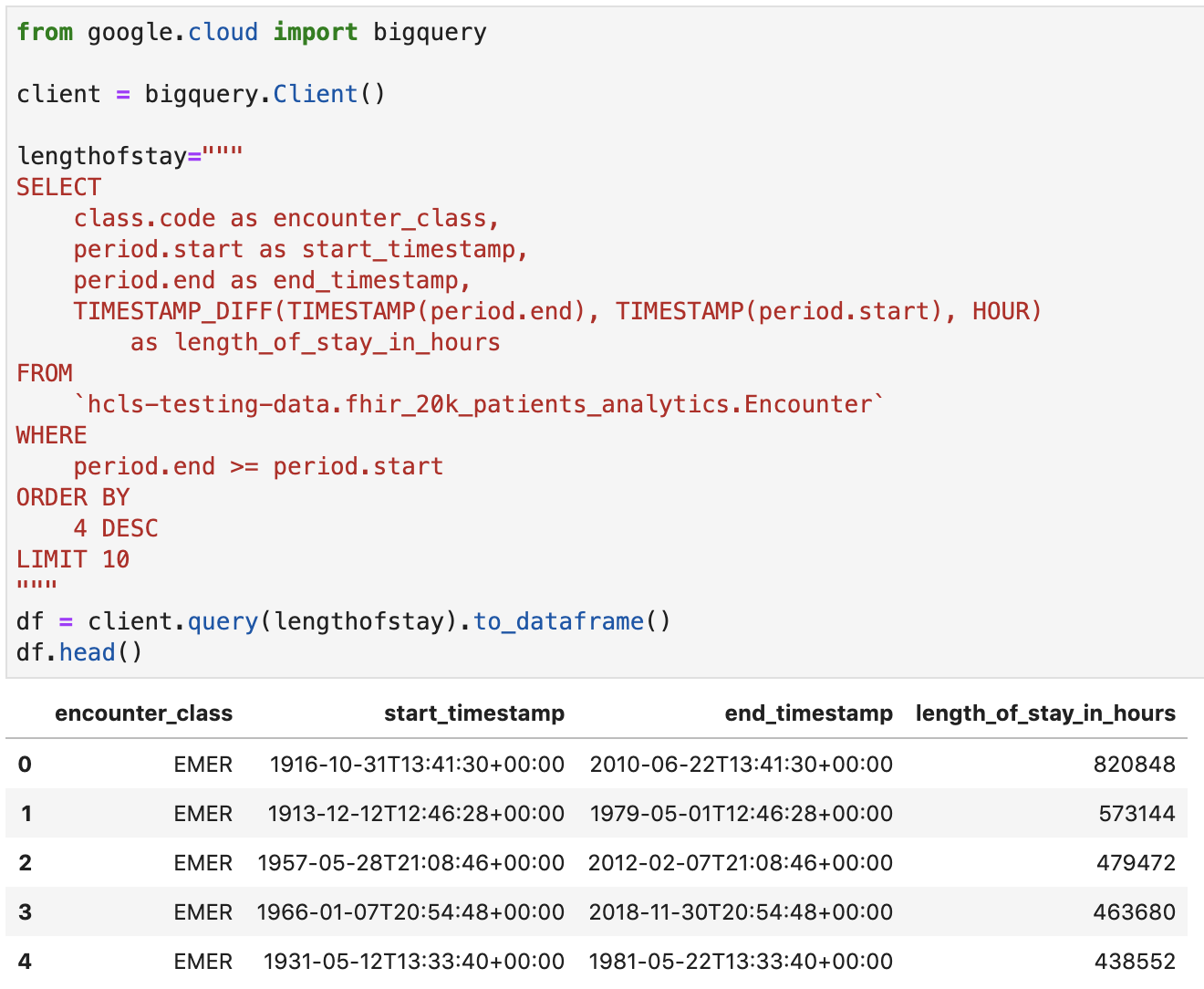
मुलाक़ातों के दौरान ठहरने की अवधि, घंटों में पाएं
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
कोड और एक्ज़ीक्यूशन का आउटपुट:
कोलेस्ट्रॉल की वैल्यू से जुड़ी जानकारी पाना
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
कोड चलाए जाने का आउटपुट:

अनुमानित एनकाउंटर क्वांटाइल पाएं
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
कोड चलाए जाने का आउटपुट:

मुलाक़ात की औसत अवधि (मिनटों में)
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
कोड चलाए जाने का आउटपुट:

हर मरीज़ के लिए, इलाज से जुड़ी जानकारी पाना
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
कोड चलाए जाने का आउटपुट:

संगठन पाना
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
स्क्रिप्ट रन करने का नतीजा:

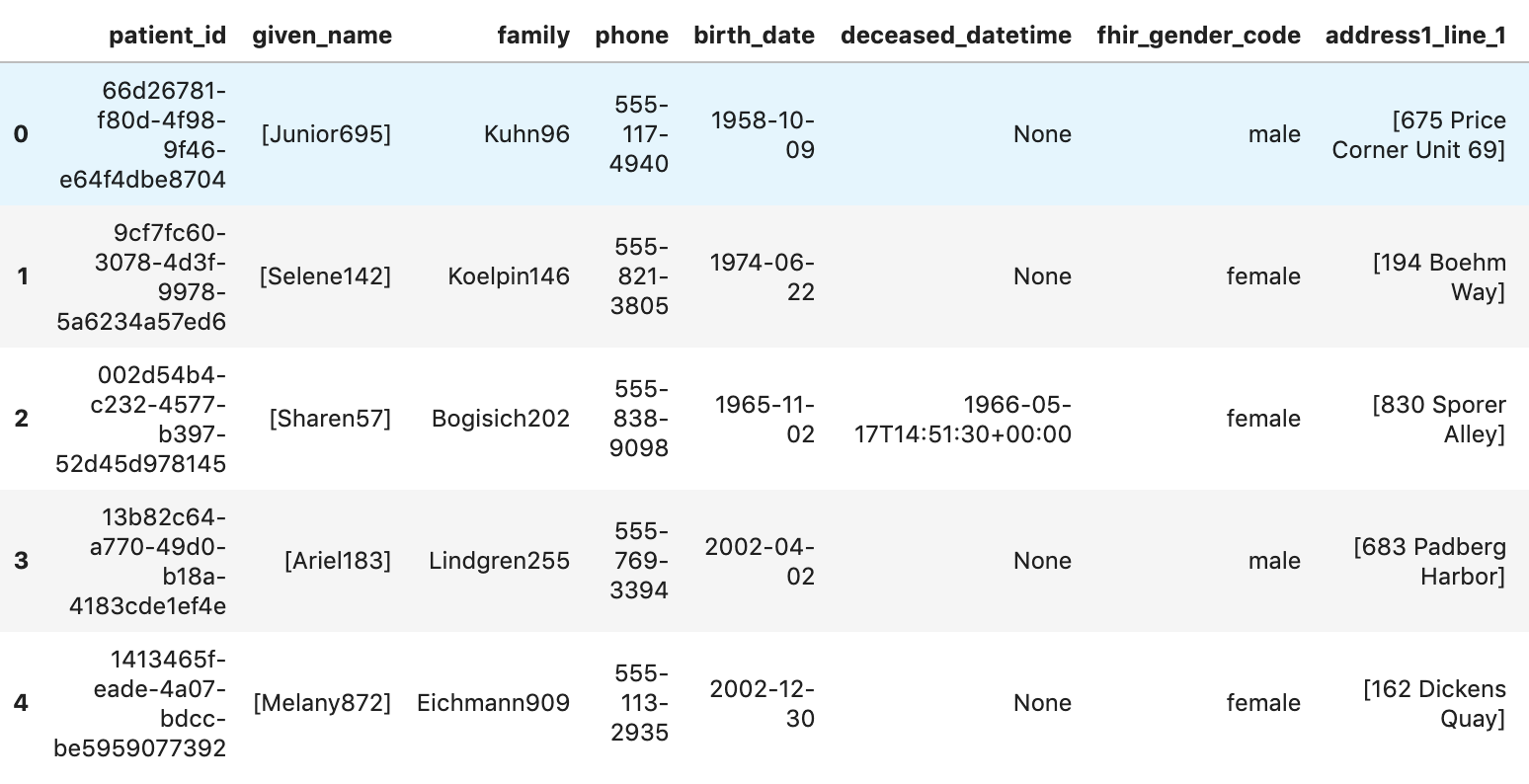
मरीज़ पाना
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
स्क्रिप्ट रन करने के नतीजे:
6. AI Platform Notebooks में चार्ट और ग्राफ़ बनाना
बार ग्राफ़ बनाने के लिए, नोटबुक "fhir_data_from_bigquery.ipynb" में कोड सेल लागू करें.
उदाहरण के लिए, मुठभेड़ों की औसत अवधि मिनटों में पता करें.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
कोड और उसे लागू करने के नतीजे:

7. नोटबुक को Cloud Source Repository में कमिट करना
- GCP Console में, Source Repositories पर जाएं. अगर इसका इस्तेमाल पहली बार किया जा रहा है, तो शुरू करें पर क्लिक करें. इसके बाद, रिपॉज़िटरी बनाएं पर क्लिक करें.

- इसके बाद, GCP -> Cloud Source Repositories पर जाएं और नई रिपॉज़िटरी बनाने के लिए, +रिपॉज़िटरी जोड़ें पर क्लिक करें.

- "Create a new Repository" चुनें. इसके बाद, Continue पर क्लिक करें.
- रिपॉज़िटरी और प्रोजेक्ट का नाम डालें. इसके बाद, बनाएं पर क्लिक करें.

- "अपनी रिपॉज़िटरी को लोकल Git रिपॉज़िटरी में क्लोन करें" को चुनें. इसके बाद, मैन्युअल तरीके से जनरेट किए गए क्रेडेंशियल चुनें.
- पहले चरण "Git क्रेडेंशियल जनरेट और सेव करना" के निर्देशों का पालन करें. इसके लिए, नीचे दिया गया तरीका देखें. अपनी स्क्रीन पर दिखने वाली स्क्रिप्ट को कॉपी करें.

- Jupyter में टर्मिनल सेशन शुरू करें.

- "Git कॉन्फ़िगर करें" विंडो से सभी कमांड कॉपी करके, Jupyter टर्मिनल में चिपकाएं.
- GCP Cloud source repositories से, रिपॉज़िटरी क्लोन पाथ को कॉपी करें. यह स्क्रीनशॉट में दूसरा चरण है.

- इस कमांड को JupiterLab टर्मिनल में चिपकाएं. कमांड कुछ इस तरह दिखेगी:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- Jupyterlab में "my-ai-notebooks" फ़ोल्डर बनाया जाता है.
- अपनी नोटबुक (fhir_data_from_bigquery.ipynb) को "my-ai-notebooks" फ़ोल्डर में ले जाएं.
- Jupyter टर्मिनल में, डायरेक्ट्री को "cd my-ai-notebooks" में बदलें.
- Jupyter टर्मिनल का इस्तेमाल करके, अपने बदलावों को स्टेज करें. इसके अलावा, Jupyter UI का इस्तेमाल किया जा सकता है. इसके लिए, Untracked एरिया में मौजूद फ़ाइलों पर राइट क्लिक करें. इसके बाद, Track को चुनें. ऐसा करने पर, फ़ाइलें Tracked एरिया में चली जाती हैं. इसके उलट, Tracked एरिया में मौजूद फ़ाइलों को Untracked एरिया में ले जाने के लिए, उन पर राइट क्लिक करें. इसके बाद, Untrack को चुनें. बदले गए हिस्से में, बदली गई फ़ाइलें शामिल होती हैं).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- Jupyter टर्मिनल या Jupyter UI का इस्तेमाल करके, अपने बदलावों को कमिट करें. इसके लिए, मैसेज टाइप करें. इसके बाद, "Checked" बटन पर क्लिक करें.
git commit -m "message goes here"
- Jupyter टर्मिनल या Jupyter UI का इस्तेमाल करके, बदलावों को रिमोट रिपॉज़िटरी में पुश करें. इसके लिए, "कमिट किए गए बदलावों को पुश करें" आइकॉन
 पर क्लिक करें.
पर क्लिक करें.
git push --all
- GCP कंसोल में, Source Repositories पर जाएं. my-ai-notebooks पर क्लिक करें. ध्यान दें कि "fhir_data_from_bigquery.ipynb" अब GCP Source Repository में सेव हो गया है.

8. साफ़-सफ़ाई सेवा
इस कोडलैब में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud Platform खाते से शुल्क न लिए जाने के लिए, ट्यूटोरियल पूरा करने के बाद, GCP पर बनाए गए संसाधनों को मिटाया जा सकता है. इससे वे आपके कोटे का इस्तेमाल नहीं करेंगे और आपसे आने वाले समय में उनका शुल्क नहीं लिया जाएगा. इन संसाधनों को मिटाने या बंद करने का तरीका यहां बताया गया है.
BigQuery डेटासेट मिटाना
इस ट्यूटोरियल के हिस्से के तौर पर बनाए गए BigQuery डेटासेट को मिटाने के लिए, इन निर्देशों का पालन करें. इसके अलावा, BigQuery कंसोल पर जाएं. अगर आपने टेस्ट डेटासेट fhir_20k_patients_analytics का इस्तेमाल किया है, तो प्रोजेक्ट hcls-testing-data को अनपिन करें.
AI Platform Notebooks इंस्टेंस बंद करना
AI Platform Notebooks इंस्टेंस को बंद करने के लिए, इस लिंक में दिए गए निर्देशों का पालन करें: नोटबुक इंस्टेंस बंद करना | AI Platform Notebooks.
प्रोजेक्ट मिटाना
बिलिंग को बंद करने का सबसे आसान तरीका यह है कि ट्यूटोरियल के लिए बनाया गया प्रोजेक्ट मिटा दें.
प्रोजेक्ट मिटाने के लिए:
- GCP Console में, प्रोजेक्ट पेज पर जाएं. प्रोजेक्ट पेज पर जाएं
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
9. बधाई हो
बधाई हो! आपने BigQuery और AI Platform Notebooks का इस्तेमाल करके, FHIR फ़ॉर्मैट में मौजूद स्वास्थ्य सेवा से जुड़े डेटा को ऐक्सेस करने, क्वेरी करने, और उसका विश्लेषण करने के लिए, कोड लैब को पूरा कर लिया है.
आपने GCP में मौजूद BigQuery के सार्वजनिक डेटासेट को ऐक्सेस किया हो.
आपने BigQuery यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके एसक्यूएल क्वेरी बनाई हैं और उनकी जांच की है.
आपने AI Platform Notebooks का इंस्टेंस बनाया और लॉन्च किया हो.
आपने JupyterLab में एसक्यूएल क्वेरी चलाई हैं और क्वेरी के नतीजों को Pandas DataFrame में सेव किया है.
आपने Matplotlib का इस्तेमाल करके चार्ट और ग्राफ़ बनाए हों.
आपने अपने नोटबुक को GCP में Cloud Source Repository में कमिट और पुश किया हो.
अब आपको Google Cloud Platform पर BigQuery और AI Platform Notebooks की मदद से, हेल्थकेयर डेटा का विश्लेषण करने के लिए ज़रूरी मुख्य चरणों के बारे में पता चल गया है.
©Google, Inc. या उसकी सहयोगी कंपनियां. सभी अधिकार सुरक्षित हैं. इसे डिस्ट्रिब्यूट न करें.