
1. 簡介

上次更新時間:2022 年 9 月 22 日
本程式碼實驗室會實作一種模式,讓您使用 BigQueryUI 和 AI Platform Notebooks,存取及分析 BigQuery 中匯總的醫療保健資料。本程式碼研究室將說明如何使用 Pandas、Matplotlib 等熟悉的工具,在符合 HIPPA 規範的 AI Platform Notebooks 中探索龐大的醫療保健資料集。訣竅在於透過 BigQuery 處理匯總作業的第一個階段,取得 Pandas 資料集,然後再於本機處理較小的 Pandas 資料集。AI Platform Notebooks 提供代管 Jupyter 服務,因此您不必自行執行筆記本伺服器。AI Platform Notebooks 與 BigQuery 和 Cloud Storage 等其他 GCP 服務整合良好,因此您可以在 Google Cloud Platform 上快速輕鬆地展開資料分析和機器學習之旅。
在本程式碼研究室中,您將學到如何:
- 使用 BigQuery 使用者介面開發及測試 SQL 查詢。
- 在 GCP 中建立並啟動 AI Platform Notebooks 執行個體。
- 從筆記本執行 SQL 查詢,並將查詢結果儲存在 Pandas DataFrame 中。
- 使用 Matplotlib 建立圖表。
- 將筆記本提交並推送至 GCP 的 Cloud Source Repository。
執行本程式碼研究室需要哪些條件?
- 您必須有 GCP 專案的存取權。
- 您必須獲派 GCP 專案的擁有者角色。
- 您需要 BigQuery 中的醫療保健資料集。
如果您沒有 GCP 專案,請按照這些步驟建立新的 GCP 專案。
2. 專案設定
在本程式碼實驗室中,我們將使用 BigQuery 中的現有資料集 (hcls-testing-data.fhir_20k_patients_analytics)。這個資料集已預先填入綜合醫療照護資料。
取得合成資料集存取權
- 使用登入 Cloud Console 的電子郵件地址,傳送電子郵件至 hcls-solutions-external+subscribe@google.com,要求加入。
- 您會收到一封電子郵件,內含確認動作的操作說明。
- 使用該選項回覆電子郵件,即可加入群組。請勿點選
 按鈕。
按鈕。 - 收到確認電子郵件後,即可繼續執行程式碼研究室的下一個步驟。
釘選專案
- 在 GCP 主控台中選取專案,然後前往 BigQuery。
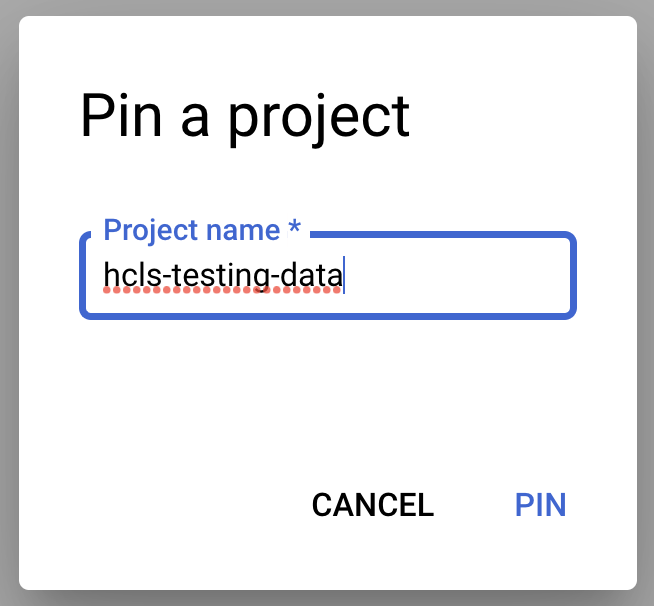
- 按一下「+新增資料」下拉式選單,然後依序選取「釘選專案」>「輸入專案名稱」。

- 輸入專案名稱「hcls-testing-data」,然後按一下「釘選」。您可以使用 BigQuery 測試資料集「fhir_20k_patients_analytics」。
3. 使用 BigQuery UI 開發查詢
BigQuery 使用者介面設定
- 從左上角的 GCP 選單 (漢堡圖示) 選取 BigQuery,前往 BigQuery 控制台。
- 在 BigQuery 控制台中,按一下「更多」→「查詢設定」,並確認「舊版 SQL」選單未勾選 (我們將使用標準 SQL)。

建構查詢
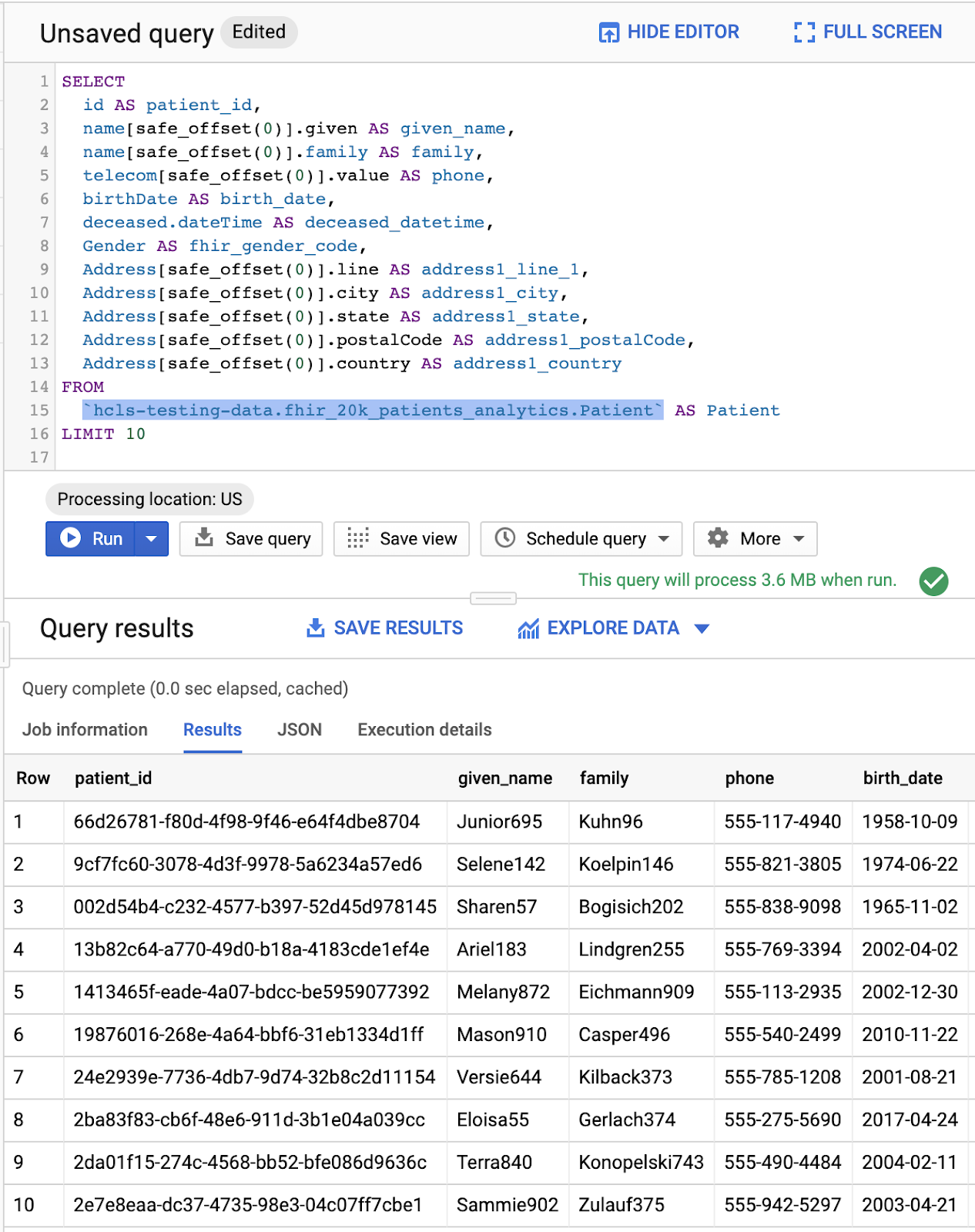
在查詢編輯器視窗中輸入下列查詢,然後點選「執行」來執行查詢。然後在「查詢結果」視窗中查看結果。
查詢病患
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
「查詢編輯器」中的查詢和結果:
查詢實務人員
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
查詢結果:

查詢機構
變更機構 ID,使其與資料集相符。
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
查詢結果:

依病患查詢就診記錄
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
查詢結果:

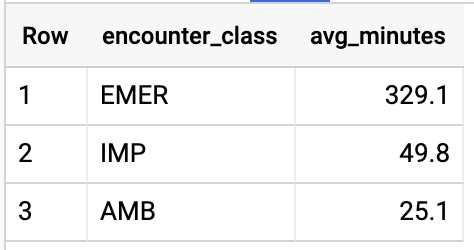
GET AVG LENGTH OF ENCOUNTERS BY ENCOUNTER TYPE
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
查詢結果:
GET ALL PATIENTS WHO HAVE A1C RATE >= 6.5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
查詢結果:

4. 建立 AI Platform Notebooks 執行個體
按照這個連結中的操作說明,建立新的 AI Platform Notebooks (JupyterLab) 執行個體。
請務必啟用 Compute Engine API。
您可以選擇「以預設選項建立新的筆記本」或「建立新的筆記本並指定選項」。
5. 建立資料分析筆記本
開啟 AI Platform Notebooks 執行個體
在本節中,我們將從頭開始撰寫及編寫新的 Jupyter 筆記本。
- 前往 Google Cloud Platform 主控台的「AI Platform Notebooks」頁面,開啟筆記本執行個體。前往 AI Platform Notebooks 頁面
- 針對您要開啟的執行個體選取 [Open JupyterLab] (開啟 JupyterLab)。

- AI Platform Notebooks 會將您導向筆記本執行個體的網址,

建立筆記本
- 在 JupyterLab 中,依序前往「File」->「New」->「Notebook」,然後在彈出式視窗中選取「Python 3」核心,或在啟動器視窗的「Notebook」部分下方選取「Python 3」,即可建立 Untitled.ipynb 筆記本。
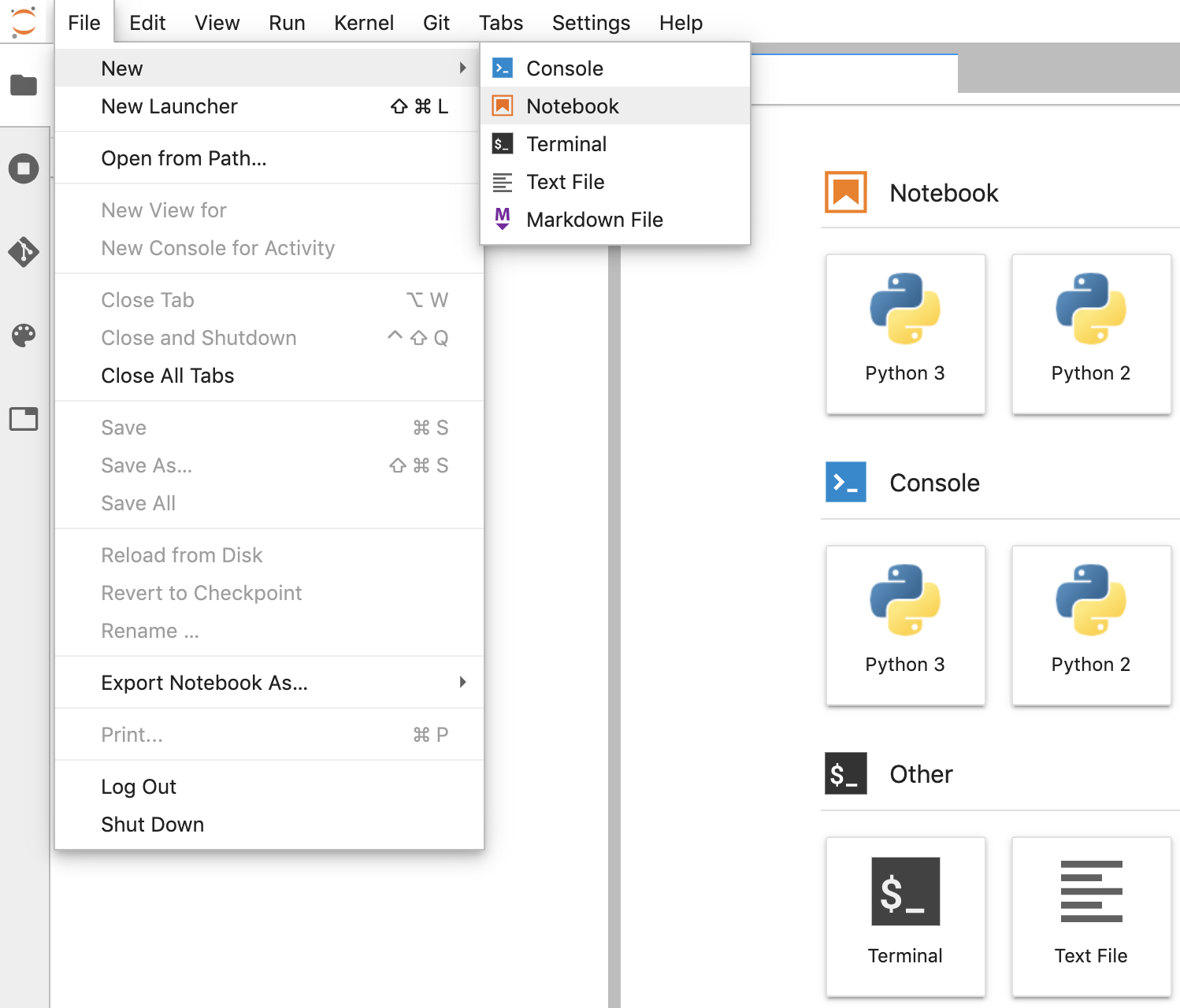
- 在 Untitled.ipynb 上按一下滑鼠右鍵,然後將筆記本重新命名為「fhir_data_from_bigquery.ipynb」。按兩下開啟,建立查詢,然後儲存筆記本。
- 如要下載筆記本,請在 *.ipynb 檔案上按一下滑鼠右鍵,然後從選單中選取「下載」。

- 你也可以點按「向上箭頭」按鈕上傳現有筆記本。

建構及執行筆記本中的每個程式碼區塊
逐一複製並執行本節提供的每個程式碼區塊。如要執行程式碼,請按一下「執行」(三角形)。
以小時為單位取得就診的住院時間長度
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
程式碼和執行作業輸出內容:

取得觀察結果 - 膽固醇值
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
執行作業輸出內容:

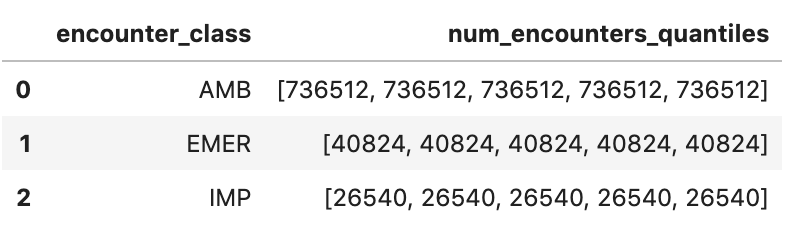
取得近似遭遇分位數
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
執行作業輸出內容:
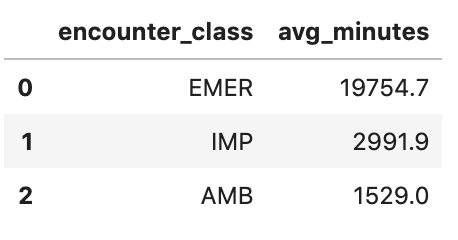
取得平均就診時間 (分鐘)
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
執行作業輸出內容:
取得每位病患的就診次數
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
執行作業輸出內容:
取得機構
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
執行結果:

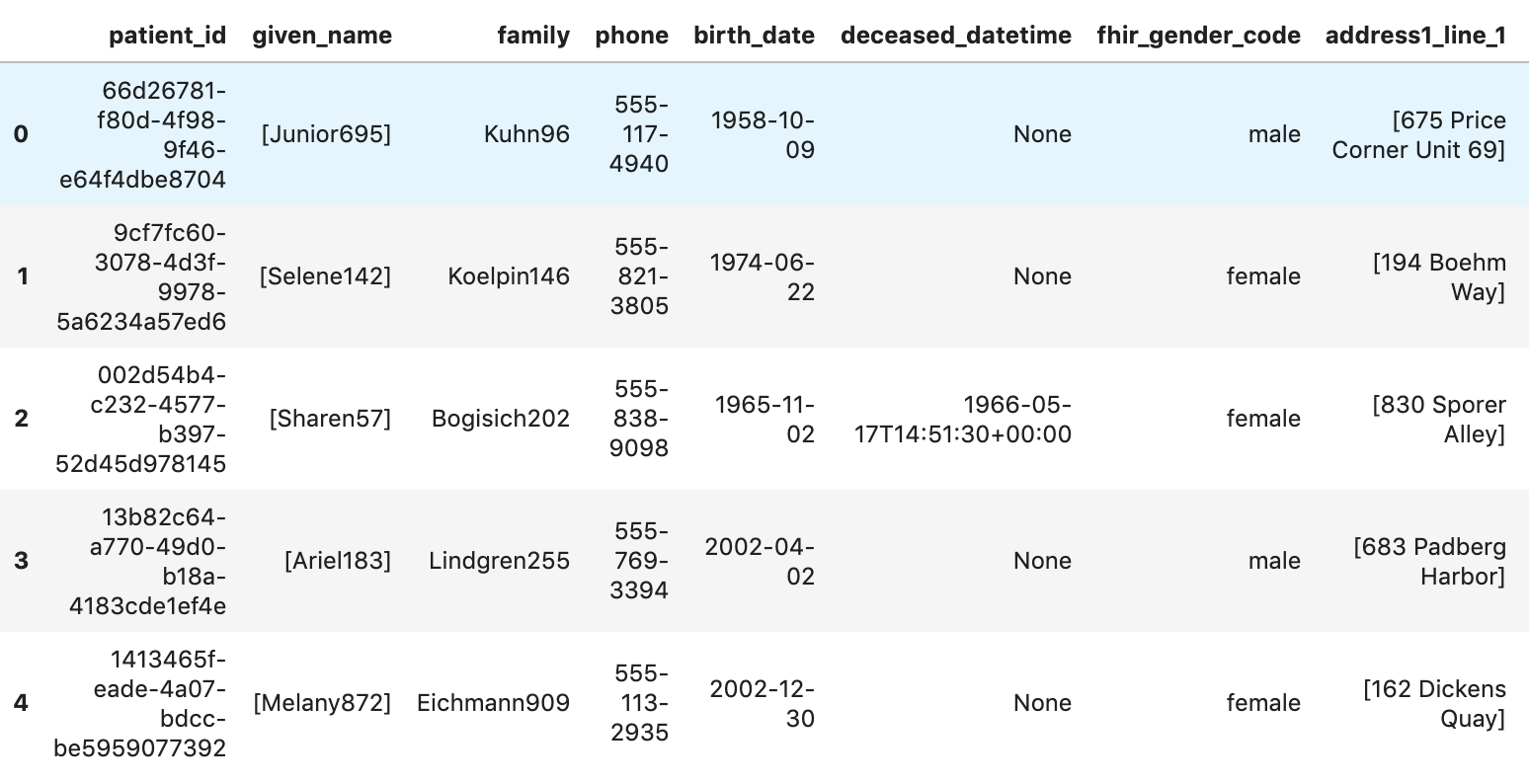
可取得病患
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
執行結果:
6. 在 AI Platform Notebooks 中建立圖表
在「fhir_data_from_bigquery.ipynb」筆記本中執行程式碼儲存格,繪製長條圖。
舉例來說,您可以取得「會面」的平均時間長度 (以分鐘為單位)。
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
程式碼和執行結果:

7. 將 Notebook 提交至 Cloud Source Repositories
- 在 GCP 主控台中,前往 Source Repositories。如果是第一次使用,請按一下「開始使用」,然後按一下「建立存放區」。

- 如要再次建立存放區,請前往 GCP -> Cloud Source Repositories,然後按一下「+新增存放區」建立新存放區。

- 選取「建立新的存放區」,然後按一下「繼續」。
- 提供存放區名稱和專案名稱,然後按一下「建立」。

- 選取「Clone your repository to a local Git repository」(將存放區複製到本機 Git 存放區),然後選取「Manually generated credentials」(手動產生的憑證)。
- 按照步驟 1「產生及儲存 Git 憑證」的說明操作 (請參閱下方)。複製畫面上顯示的指令碼。

- 在 Jupyter 中啟動終端機工作階段。

- 將「設定 Git」視窗中的所有指令貼到 Jupyter 終端機。
- 從 GCP Cloud 原始碼存放區複製存放區複製路徑 (如下方螢幕截圖中的步驟 2)。
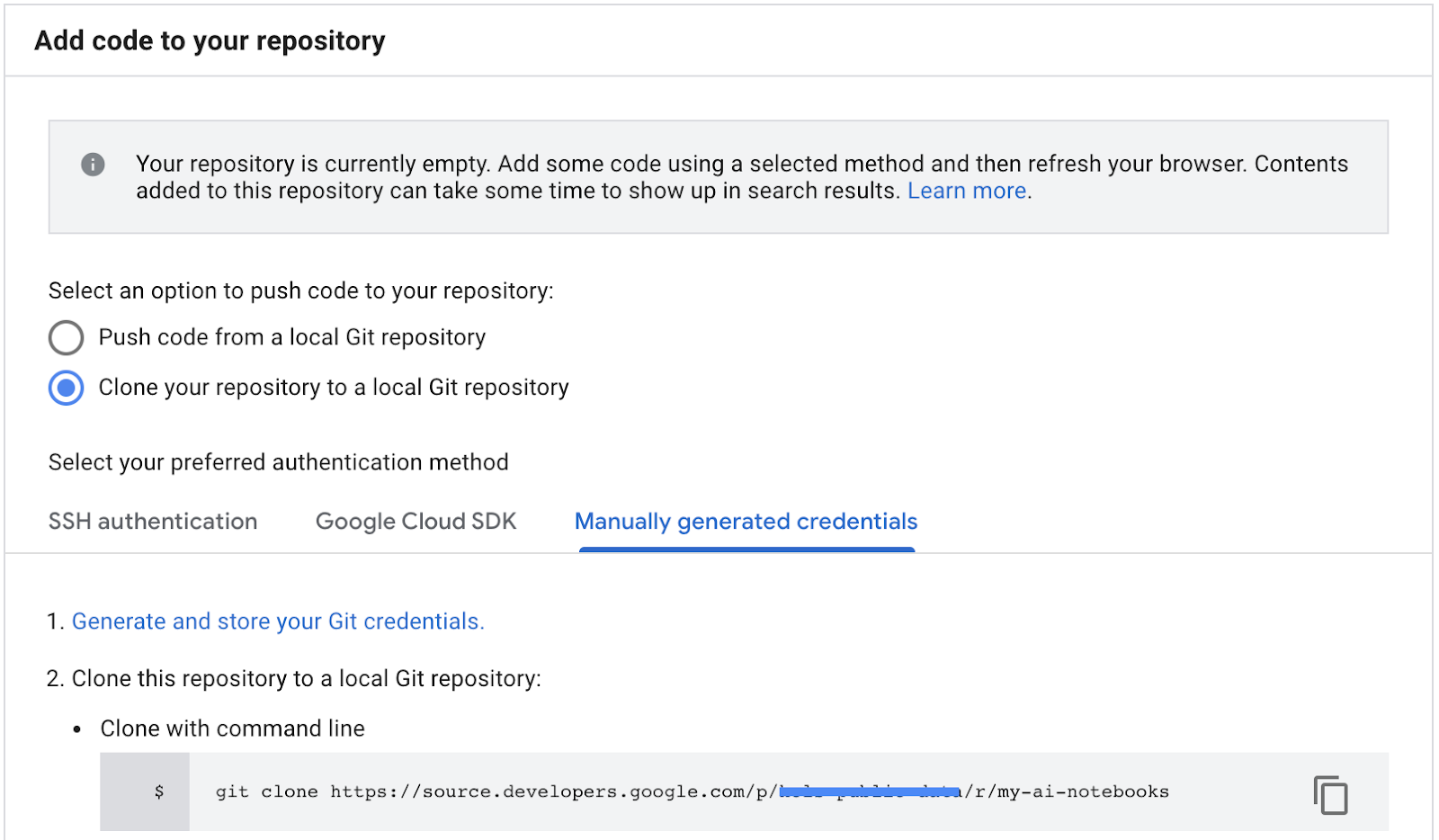
- 將這個指令貼到 JupiterLab 終端機。指令如下所示:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- JupyterLab 中會建立「my-ai-notebooks」資料夾。

- 將筆記本 (fhir_data_from_bigquery.ipynb) 移至「my-ai-notebooks」資料夾。
- 在 Jupyter 終端機中,將目錄變更為「cd my-ai-notebooks」。
- 使用 Jupyter 終端機暫存變更。或者,您也可以使用 Jupyter UI (在「Untracked」區域中對檔案按一下滑鼠右鍵,選取「Track」,然後檔案就會移至「Tracked」區域,反之亦然)。變更區域包含修改過的檔案)。
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- 使用 Jupyter 終端機或 Jupyter UI 提交變更 (輸入訊息,然後按一下「已勾選」按鈕)。
git commit -m "message goes here"
- 使用 Jupyter 終端機或 Jupyter UI,將變更推送至遠端存放區 (按一下「推送已提交的變更」圖示
 )。
)。
git push --all
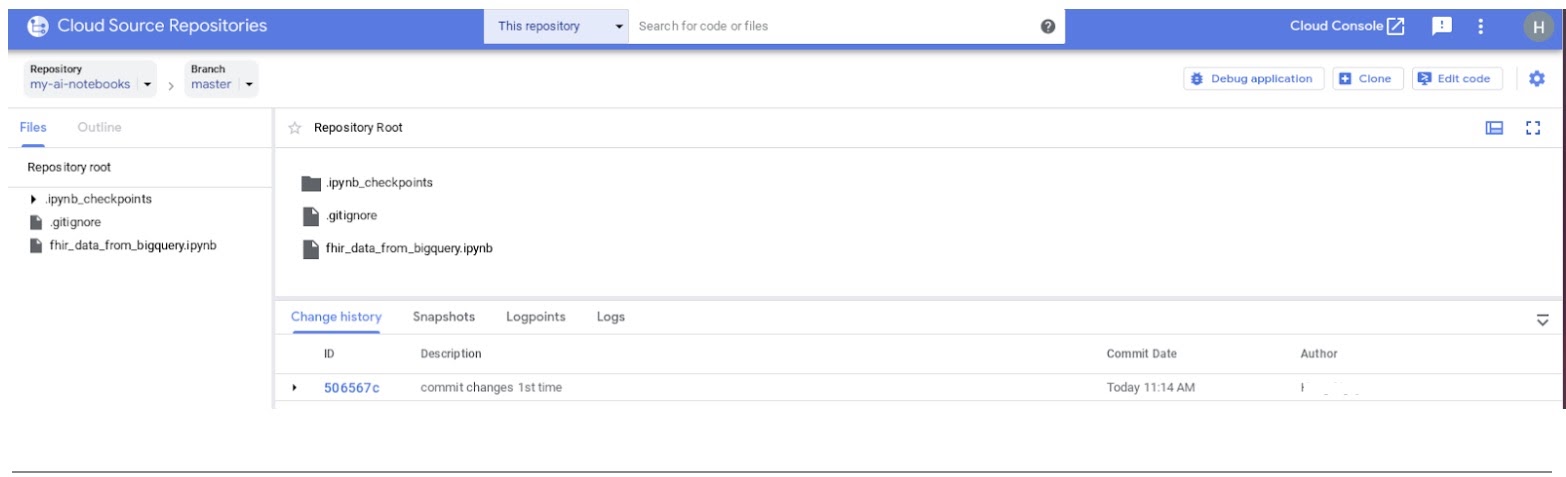
- 在 GCP 主控台中,前往 Source Repositories。按一下「my-ai-notebooks」。請注意,「fhir_data_from_bigquery.ipynb」現在已儲存在 GCP 來源存放區。
8. 清除
為避免系統向您的 Google Cloud Platform 帳戶收取本程式碼研究室中使用資源的相關費用,請在完成教學課程後,清除您在 GCP 上建立的資源,這樣資源就不會占用配額,而您日後也無須為其付費。下列各節將說明如何刪除或停用這些資源。
刪除 BigQuery 資料集
按照這些操作說明刪除您在本教學課程中建立的 BigQuery 資料集。或者,如果您使用測試資料集 fhir_20k_patients_analytics,請前往 BigQuery 控制台,取消固定專案 hcls-testing-data。
關閉 AI Platform Notebooks 執行個體
請按照這個連結中的操作說明「關閉筆記本執行個體 | AI Platform Notebooks」關閉 AI Platform Notebooks 執行個體。
刪除專案
如要避免付費,最簡單的方法就是刪除您為了本教學課程所建立的專案。
如要刪除專案,請進行以下操作:
- 前往 GCP 主控台的「Projects」(專案) 頁面。前往「PROJECTS」(專案) 頁面
- 在專案清單中選取要刪除的專案,然後點按「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下「Shut down」(關閉) 即可刪除專案。
9. 恭喜
恭喜!您已成功完成程式碼研究室,瞭解如何使用 BigQuery 和 AI Platform Notebooks 存取、查詢及分析 FHIR 格式的醫療保健資料。
您已在 GCP 中存取 BigQuery 公開資料集。
您使用 BigQuery UI 開發及測試 SQL 查詢。
您已建立並啟動 AI Platform Notebooks 執行個體。
您在 JupyterLab 中執行 SQL 查詢,並將查詢結果儲存在 Pandas DataFrame 中。
您使用 Matplotlib 建立圖表。
您已將筆記本提交並推送到 GCP 中的 Cloud Source Repository。
您現在已瞭解在 Google Cloud Platform 上使用 BigQuery 和 AI Platform Notebooks,展開醫療保健資料分析之旅的必要步驟。
©Google Inc. 或其關係企業。版權所有。請勿散布。