
1. Giới thiệu

Lần cập nhật gần đây nhất: ngày 22 tháng 9 năm 2022
Lớp học lập trình này triển khai một mẫu để truy cập và phân tích dữ liệu chăm sóc sức khoẻ được tổng hợp trong BigQuery bằng BigQueryUI và Notebooks trên Nền tảng Trí tuệ nhân tạo. Ví dụ này minh hoạ việc khám phá dữ liệu của các tập dữ liệu lớn về sức khoẻ bằng các công cụ quen thuộc như Pandas, Matplotlib, v.v. trong một Sổ tay Nền tảng Trí tuệ nhân tạo tuân thủ HIPPA. "Mẹo" là thực hiện phần đầu tiên của quá trình tổng hợp trong BigQuery, nhận lại một tập dữ liệu Pandas rồi làm việc với tập dữ liệu Pandas nhỏ hơn đó trên thiết bị. AI Platform Notebooks cung cấp trải nghiệm Jupyter được quản lý, vì vậy bạn không cần tự chạy máy chủ sổ tay. AI Platform Notebooks được tích hợp tốt với các dịch vụ khác của GCP như BigQuery và Cloud Storage, giúp bạn nhanh chóng và dễ dàng bắt đầu hành trình Phân tích dữ liệu và học máy trên Google Cloud Platform.
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách:
- Phát triển và kiểm thử các truy vấn SQL bằng giao diện người dùng BigQuery.
- Tạo và chạy một phiên bản AI Platform Notebooks trong GCP.
- Thực thi các truy vấn SQL từ sổ tay và lưu trữ kết quả truy vấn trong Pandas DataFrame.
- Tạo biểu đồ và đồ thị bằng Matplotlib.
- Xác nhận và đẩy sổ tay lên Cloud Source Repository trong GCP.
Bạn cần những gì để chạy lớp học lập trình này?
- Bạn cần có quyền truy cập vào một Dự án trên Google Cloud Platform.
- Bạn cần được chỉ định vai trò Chủ sở hữu cho Dự án GCP.
- Bạn cần có tập dữ liệu về sức khoẻ trong BigQuery.
Nếu bạn chưa có Dự án GCP, hãy làm theo các bước này để tạo một Dự án GCP mới.
2. Thiết lập dự án
Trong lớp học lập trình này, chúng ta sẽ sử dụng một tập dữ liệu hiện có trong BigQuery (hcls-testing-data.fhir_20k_patients_analytics). Tập dữ liệu này được điền sẵn dữ liệu y tế tổng hợp.
Truy cập vào tập dữ liệu tổng hợp
- Từ địa chỉ email mà bạn đang dùng để đăng nhập vào Cloud Console, hãy gửi email đến hcls-solutions-external+subscribe@google.com để yêu cầu tham gia.
- Bạn sẽ nhận được email hướng dẫn cách xác nhận hành động này.
- Sử dụng lựa chọn trả lời email để tham gia nhóm. KHÔNG nhấp vào nút
 .
. - Sau khi nhận được email xác nhận, bạn có thể chuyển sang bước tiếp theo trong lớp học lập trình.
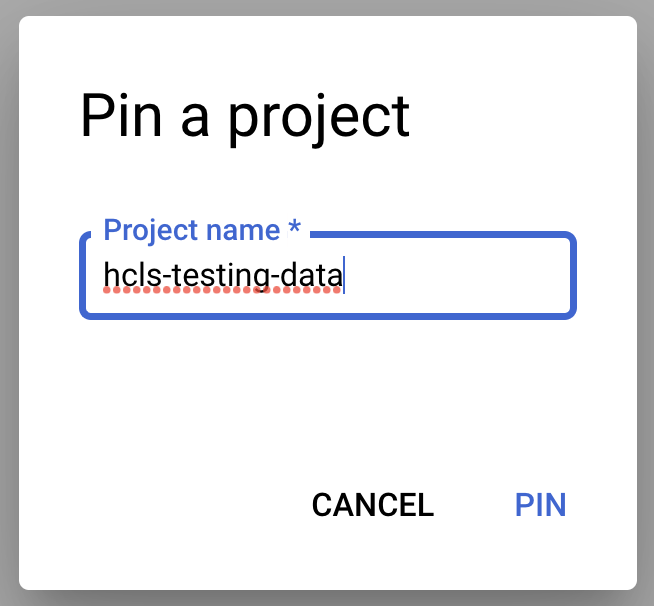
Ghim dự án
- Trong Bảng điều khiển GCP, hãy chọn dự án của bạn, rồi chuyển đến BigQuery.
- Nhấp vào trình đơn thả xuống +THÊM DỮ LIỆU, rồi chọn "Ghim dự án" > "Nhập tên dự án" .

- Nhập tên dự án "hcls-testing-data", rồi nhấp vào PIN. Bạn có thể sử dụng tập dữ liệu kiểm thử BigQuery "fhir_20k_patients_analytics".
3. Phát triển truy vấn bằng giao diện người dùng BigQuery
Chế độ cài đặt giao diện người dùng BigQuery
- Chuyển đến bảng điều khiển BigQuery bằng cách chọn BigQuery trong trình đơn GCP ("hamburger") ở trên cùng bên trái.
- Trong bảng điều khiển BigQuery, hãy nhấp vào Tuỳ chọn khác → Cài đặt truy vấn và đảm bảo rằng bạn KHÔNG đánh dấu vào trình đơn SQL cũ (chúng ta sẽ sử dụng SQL chuẩn).

Tạo truy vấn
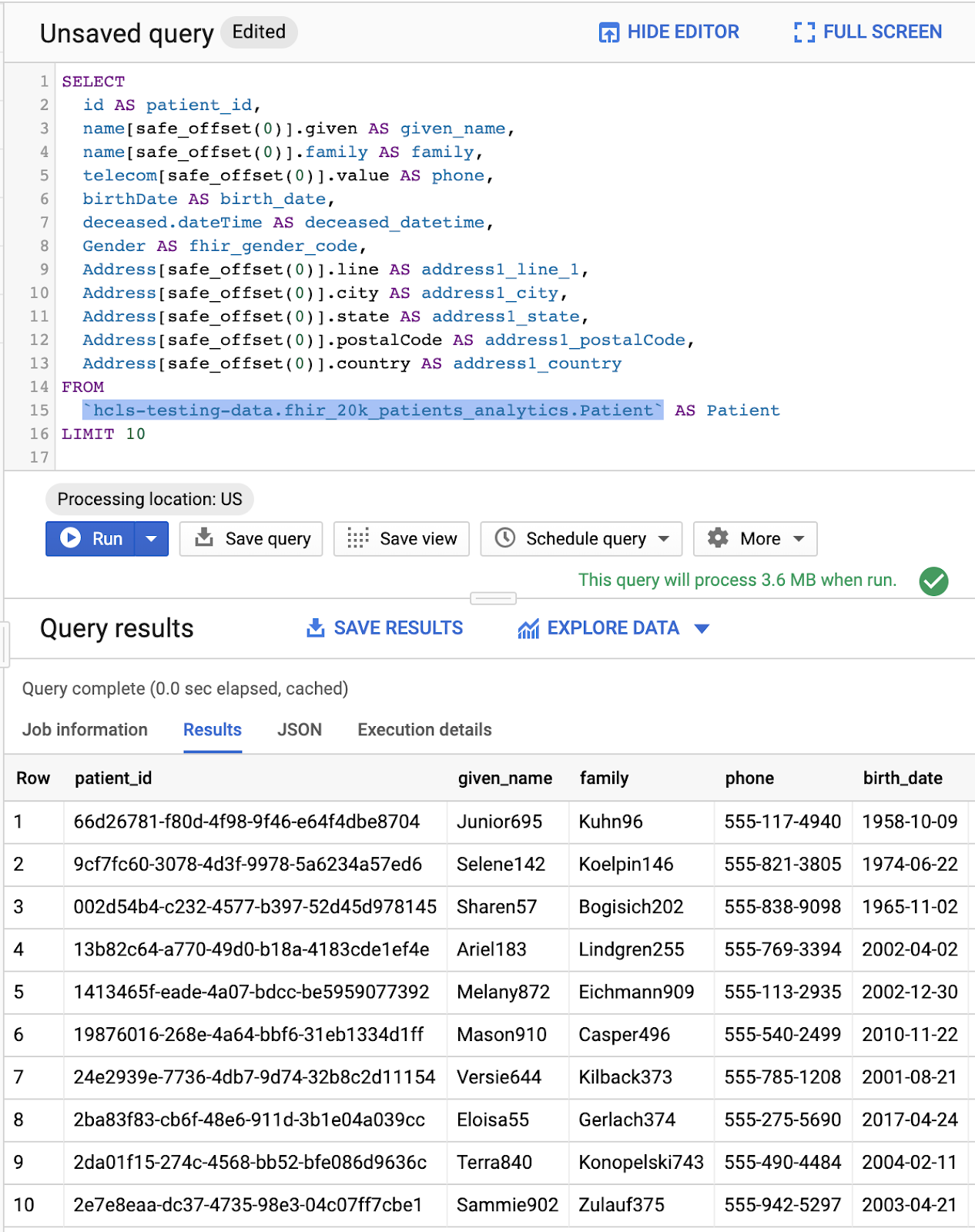
Trong cửa sổ Trình chỉnh sửa truy vấn, hãy nhập truy vấn sau rồi nhấp vào "Chạy" để thực thi truy vấn đó. Sau đó, hãy xem kết quả trong cửa sổ "Query results" (Kết quả truy vấn).
QUERY PATIENTS
#standardSQL - Query Patients
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
Truy vấn trong "Trình chỉnh sửa truy vấn" và kết quả:
QUERY PRACTITIONERS
#standardSQL - Query Practitioners
SELECT
id AS practitioner_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family_name,
gender
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Practitioner`
LIMIT 10
Kết quả truy vấn:

TỔ CHỨC TRUY VẤN
Thay đổi mã nhận dạng tổ chức cho phù hợp với tập dữ liệu của bạn.
#standardSQL - Query Organization
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
Kết quả truy vấn:

TRUY VẤN CÁC LẦN GẶP GỠ CỦA BỆNH NHÂN
#standardSQL - Query Encounters by Patient
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
Kết quả truy vấn:

GET AVG LENGTH OF ENCOUNTERS BY ENCOUNTER TYPE
#standardSQL - Get Average length of Encounters by Encounter type
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
Kết quả truy vấn:

LẤY TẤT CẢ BỆNH NHÂN CÓ TỶ LỆ A1C >= 6,5
# Query Patients who have A1C rate >= 6.5
SELECT
id AS observation_id,
subject.patientId AS patient_id,
context.encounterId AS encounter_id,
value.quantity.value,
value.quantity.unit,
code.coding[safe_offset(0)].code,
code.coding[safe_offset(0)].display AS description
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation`
WHERE
code.text like '%A1c/Hemoglobin%' AND
value.quantity.value >= 6.5 AND
status = 'final'
Kết quả truy vấn:

4. Tạo phiên bản AI Platform Notebooks
Làm theo hướng dẫn trong đường liên kết này để tạo một phiên bản AI Platform Notebooks (JupyterLab) mới.
Vui lòng nhớ bật Compute Engine API.
Bạn có thể chọn " Tạo sổ tay mới bằng các lựa chọn mặc định" hoặc " Tạo sổ tay mới và chỉ định các lựa chọn của bạn".
5. Tạo sổ tay phân tích dữ liệu
Mở phiên bản Sổ tay Nền tảng Trí tuệ nhân tạo
Trong phần này, chúng ta sẽ tạo và viết mã cho một sổ tay Jupyter mới từ đầu.
- Mở một phiên bản sổ tay bằng cách chuyển đến trang AI Platform Notebooks trong Bảng điều khiển Google Cloud Platform. CHUYỂN ĐẾN TRANG SỔ TAY CỦA NỀN TẢNG AI
- Chọn Open JupyterLab (Mở JupyterLab) cho phiên bản mà bạn muốn mở.

- Nền tảng Trí tuệ nhân tạo Notebooks sẽ chuyển hướng bạn đến một URL cho phiên bản sổ tay của bạn.

Tạo sổ ghi chú
- Trong JupyterLab, hãy chuyển đến File (Tệp) -> New (Mới) -> Notebook (Sổ tay) rồi chọn Kernel (Nhân) "Python 3" trong cửa sổ bật lên, hoặc chọn "Python 3" trong phần Notebook (Sổ tay) trong cửa sổ trình chạy để tạo một sổ tay Untitled.ipynb.

- Nhấp chuột phải vào Untitled.ipynb rồi đổi tên sổ tay thành "fhir_data_from_bigquery.ipynb". Nhấp đúp để mở, tạo truy vấn và lưu sổ tay.
- Bạn có thể tải sổ tay xuống bằng cách nhấp chuột phải vào tệp *.ipynb rồi chọn Tải xuống trong trình đơn.

- Bạn cũng có thể tải một sổ tay hiện có lên bằng cách nhấp vào nút "Mũi tên lên".

Tạo và thực thi từng khối mã trong sổ tay
Sao chép và thực thi từng khối mã được cung cấp trong phần này theo từng bước. Để thực thi mã, hãy nhấp vào "Run" (Chạy) (Hình tam giác).

Lấy thời gian lưu trú cho các lần gặp mặt tính bằng giờ
from google.cloud import bigquery
client = bigquery.Client()
lengthofstay="""
SELECT
class.code as encounter_class,
period.start as start_timestamp,
period.end as end_timestamp,
TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), HOUR)
as length_of_stay_in_hours
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
ORDER BY
4 DESC
LIMIT 10
"""
df = client.query(lengthofstay).to_dataframe()
df.head()
Mã và kết quả thực thi:

Nhận thông tin quan sát – Giá trị cholesterol
observation="""
SELECT
cc.code loinc_code,
cc.display loinc_name,
approx_quantiles(round(o.value.quantity.value,1),4) as quantiles,
count(*) as num_obs
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Observation` o, o.code.coding cc
WHERE
cc.system like '%loinc%' and lower(cc.display) like '%cholesterol%'
GROUP BY 1,2
ORDER BY 4 desc
"""
df2 = client.query(observation).to_dataframe()
df2.head()
Kết quả thực thi:

Nhận các phân vị tương đối của lượt gặp gỡ
encounters="""
SELECT
encounter_class,
APPROX_QUANTILES(num_encounters, 4) num_encounters_quantiles
FROM (
SELECT
class.code encounter_class,
subject.reference patient_id,
COUNT(DISTINCT id) AS num_encounters
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
GROUP BY
1,2
)
GROUP BY 1
ORDER BY 1
"""
df3 = client.query(encounters).to_dataframe()
df3.head()
Kết quả thực thi:

Nhận Thời lượng trung bình của các cuộc hẹn (tính bằng phút)
avgstay="""
SELECT
class.code encounter_class,
ROUND(AVG(TIMESTAMP_DIFF(TIMESTAMP(period.end), TIMESTAMP(period.start), MINUTE)),1) as avg_minutes
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter`
WHERE
period.end >= period.start
GROUP BY
1
ORDER BY
2 DESC
"""
df4 = client.query(avgstay).to_dataframe()
df4.head()
Kết quả thực thi:

Nhận số lượt gặp gỡ mỗi bệnh nhân
patientencounters="""
SELECT
id AS encounter_id,
period.start AS encounter_start,
period.end AS encounter_end,
status AS encounter_status,
class.code AS encounter_type,
subject.patientId as patient_id,
participant[safe_OFFSET(0)].individual.practitionerId as parctitioner_id,
serviceProvider.organizationId as encounter_location_id,
type[safe_OFFSET(0)].text AS encounter_reason
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Encounter` AS Encounter
WHERE
subject.patientId = "900820eb-4166-4981-ae2d-b183a064ac18"
ORDER BY
encounter_end
"""
df5 = client.query(patientencounters).to_dataframe()
df5.head()
Kết quả thực thi:

Lấy thông tin về tổ chức
orgs="""
SELECT
id AS org_id,
type[safe_offset(0)].text AS org_type,
name AS org_name,
address[safe_offset(0)].line AS org_addr,
address[safe_offset(0)].city AS org_addr_city,
address[safe_offset(0)].state AS org_addr_state,
address[safe_offset(0)].postalCode AS org_addr_postalCode,
address[safe_offset(0)].country AS org_addr_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Organization` AS Organization
WHERE
id = "b81688f5-bd0e-3c99-963f-860d3e90ab5d"
"""
df6 = client.query(orgs).to_dataframe()
df6.head()
Kết quả thực thi:

Thu hút bệnh nhân
patients="""
SELECT
id AS patient_id,
name[safe_offset(0)].given AS given_name,
name[safe_offset(0)].family AS family,
telecom[safe_offset(0)].value AS phone,
birthDate AS birth_date,
deceased.dateTime AS deceased_datetime,
Gender AS fhir_gender_code,
Address[safe_offset(0)].line AS address1_line_1,
Address[safe_offset(0)].city AS address1_city,
Address[safe_offset(0)].state AS address1_state,
Address[safe_offset(0)].postalCode AS address1_postalCode,
Address[safe_offset(0)].country AS address1_country
FROM
`hcls-testing-data.fhir_20k_patients_analytics.Patient` AS Patient
LIMIT 10
"""
df7 = client.query(patients).to_dataframe()
df7.head()
Kết quả thực thi:

6. Tạo biểu đồ và đồ thị trong Nền tảng Trí tuệ nhân tạo Notebooks
Thực thi các ô mã trong sổ tay "fhir_data_from_bigquery.ipynb" để vẽ biểu đồ thanh.
Ví dụ: lấy độ dài trung bình của các Lượt truy cập tính bằng phút.
df4.plot(kind='bar', x='encounter_class', y='avg_minutes');
Mã và kết quả thực thi:

7. Cam kết Sổ tay với Cloud Source Repository
- Trong Bảng điều khiển GCP, hãy chuyển đến Source Repositories (Kho lưu trữ mã nguồn). Nếu đây là lần đầu tiên bạn sử dụng, hãy nhấp vào Bắt đầu, rồi nhấp vào Tạo kho lưu trữ.

- Vào lần tiếp theo, hãy chuyển đến GCP -> Cloud Source Repositories rồi nhấp vào +Thêm kho lưu trữ để tạo một kho lưu trữ mới.

- Chọn "Create a new Repository" (Tạo kho lưu trữ mới), sau đó nhấp vào Continue (Tiếp tục).
- Cung cấp tên kho lưu trữ và tên dự án, sau đó nhấp vào Tạo.

- Chọn "Sao chép kho lưu trữ của bạn vào một kho lưu trữ Git cục bộ", sau đó chọn Thông tin đăng nhập được tạo theo cách thủ công.
- Làm theo hướng dẫn ở bước 1 "Tạo và lưu trữ thông tin đăng nhập Git" (xem bên dưới). Sao chép tập lệnh xuất hiện trên màn hình.

- Bắt đầu phiên thiết bị đầu cuối trong Jupyter.

- Dán tất cả các lệnh trong cửa sổ "Configure Git" (Định cấu hình Git) vào cửa sổ dòng lệnh Jupyter.
- Sao chép đường dẫn sao chép kho lưu trữ từ kho lưu trữ nguồn trên đám mây của GCP (bước 2 trong ảnh chụp màn hình bên dưới).
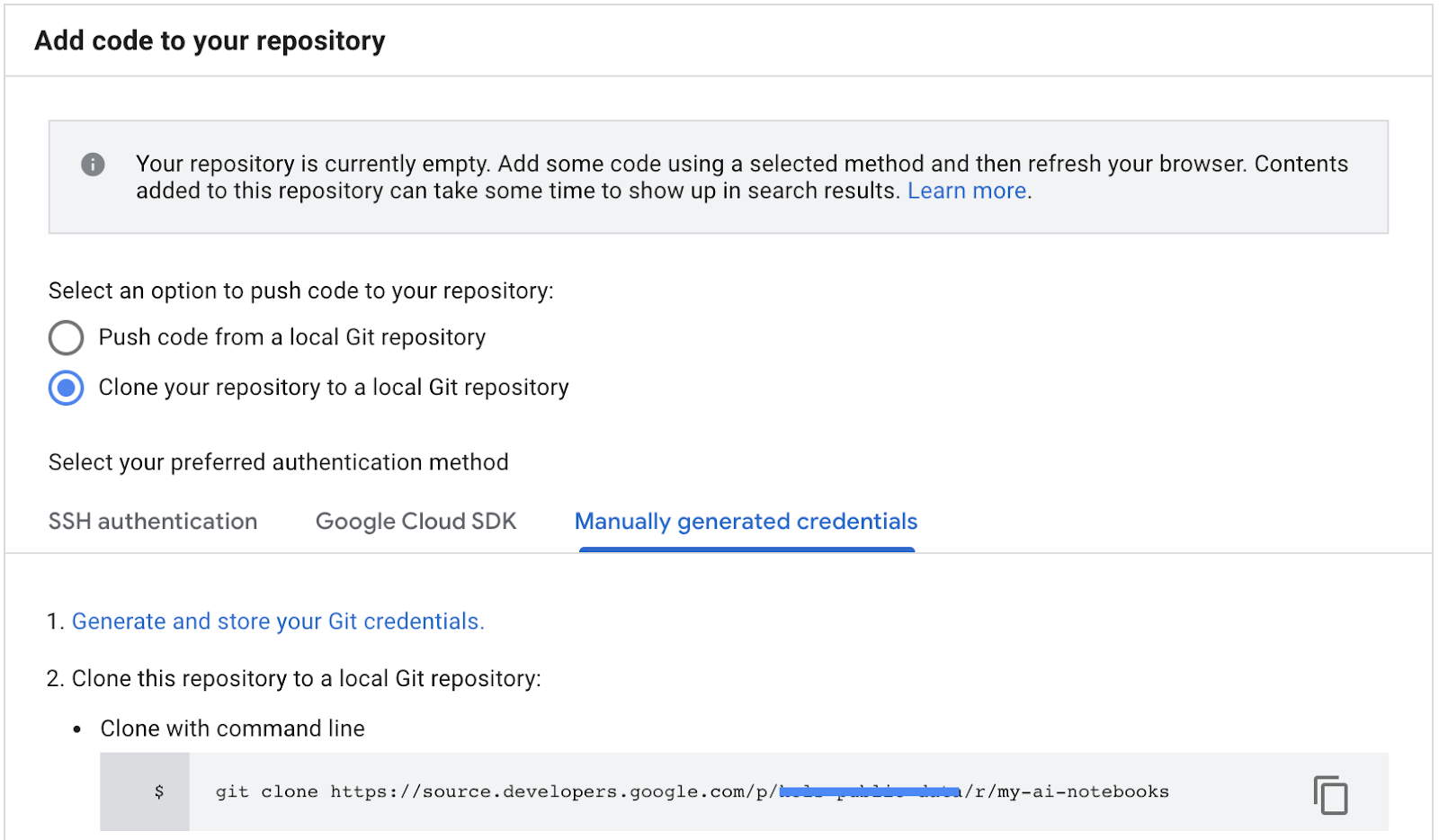
- Dán lệnh này vào dòng lệnh JupiterLab. Lệnh sẽ có dạng như sau:
git clone https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks
- Thư mục "my-ai-notebooks" được tạo trong Jupyterlab.
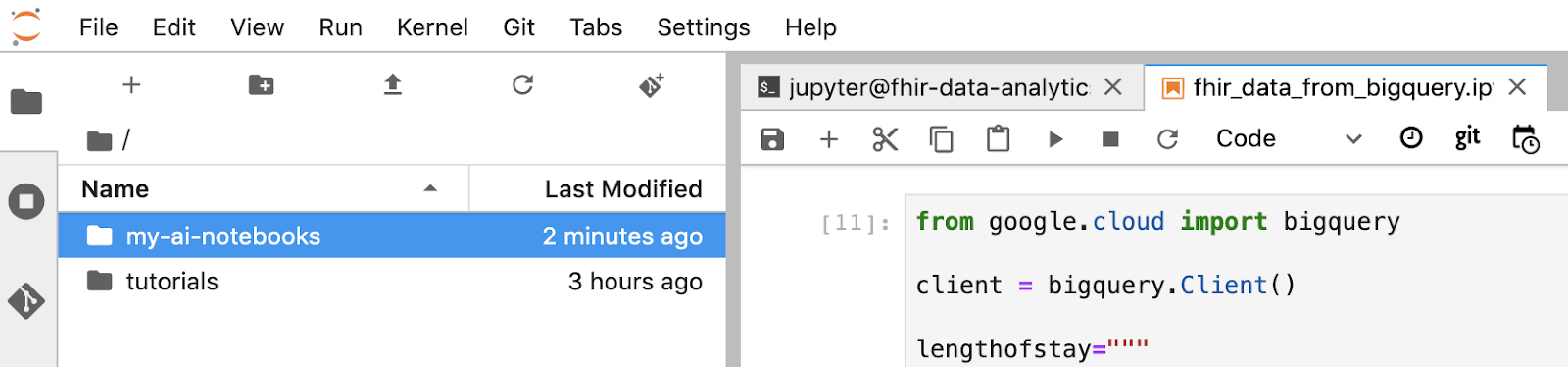
- Di chuyển sổ tay (fhir_data_from_bigquery.ipynb) vào thư mục "my-ai-notebooks".
- Trong thiết bị đầu cuối Jupyter, hãy thay đổi thư mục thành "cd my-ai-notebooks".
- Giai đoạn thay đổi bằng thiết bị đầu cuối Jupyter. Ngoài ra, bạn có thể sử dụng giao diện người dùng Jupyter (nhấp chuột phải vào các tệp trong khu vực Untracked (Chưa được theo dõi), chọn Track (Theo dõi), sau đó các tệp sẽ được chuyển vào khu vực Tracked (Đã được theo dõi) và ngược lại. Vùng thay đổi chứa các tệp đã sửa đổi).
git remote add my-ai-notebooks https://source.developers.google.com/p/<your -project-name>/r/my-ai-notebooks

- Xác nhận các thay đổi bằng cách sử dụng thiết bị đầu cuối Jupyter hoặc giao diện người dùng Jupyter (nhập thông báo, sau đó nhấp vào nút "Đã kiểm tra").
git commit -m "message goes here"
- Đẩy các thay đổi của bạn lên kho lưu trữ từ xa bằng cách sử dụng thiết bị đầu cuối Jupyter hoặc giao diện người dùng Jupyter (nhấp vào biểu tượng "đẩy các thay đổi đã cam kết"
 ).
).
git push --all
- Trong bảng điều khiển GCP, hãy chuyển đến Source Repositories (Kho lưu trữ nguồn). Nhấp vào my-ai-notebooks. Xin lưu ý rằng "fhir_data_from_bigquery.ipynb" hiện đã được lưu trong Kho lưu trữ nguồn GCP.

8. Dọn dẹp
Để tránh phát sinh phí cho tài khoản Google Cloud Platform của bạn đối với các tài nguyên được dùng trong lớp học lập trình này, sau khi hoàn tất hướng dẫn, bạn có thể dọn dẹp các tài nguyên mà bạn đã tạo trên GCP để chúng không chiếm hạn mức của bạn và bạn sẽ không bị tính phí cho các tài nguyên đó trong tương lai. Các phần sau đây mô tả cách xoá hoặc tắt các tài nguyên này.
Xoá tập dữ liệu BigQuery
Hãy làm theo các hướng dẫn này để xoá tập dữ liệu BigQuery mà bạn đã tạo trong hướng dẫn này. Hoặc chuyển đến bảng điều khiển BigQuery, bỏ GHI dự án hcls-testing-data nếu bạn đã sử dụng tập dữ liệu thử nghiệm fhir_20k_patients_analytics.
Tắt phiên bản AI Platform Notebooks
Làm theo hướng dẫn trong đường liên kết này Tắt một phiên bản sổ tay | Sổ tay Nền tảng Trí tuệ nhân tạo để tắt một phiên bản Sổ tay Nền tảng Trí tuệ nhân tạo.
Xoá dự án
Cách dễ nhất để không bị tính phí là xoá dự án mà bạn đã tạo cho hướng dẫn này.
Cách xoá dự án:
- Trong Bảng điều khiển của GCP, hãy chuyển đến trang Dự án. CHUYỂN ĐẾN TRANG DỰ ÁN
- Trong danh sách dự án, hãy chọn dự án bạn muốn xoá rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
9. Xin chúc mừng
Chúc mừng bạn đã hoàn thành thành công lớp học lập trình để truy cập, truy vấn và phân tích dữ liệu chăm sóc sức khoẻ được định dạng FHIR bằng BigQuery và Nền tảng Trí tuệ nhân tạo Notebooks.
Bạn đã truy cập vào một tập dữ liệu công khai trên BigQuery trong GCP.
Bạn đã phát triển và kiểm thử các truy vấn SQL bằng giao diện người dùng BigQuery.
Bạn đã tạo và chạy một phiên bản AI Platform Notebooks.
Bạn đã thực thi các truy vấn SQL trong JupyterLab và lưu trữ kết quả truy vấn trong Pandas DataFrame.
Bạn đã tạo biểu đồ và đồ thị bằng Matplotlib.
Bạn đã xác nhận và chuyển sổ tay của mình lên Cloud Source Repository trong GCP.
Giờ đây, bạn đã biết các bước chính cần thiết để bắt đầu hành trình Phân tích dữ liệu y tế bằng BigQuery và Nền tảng Trí tuệ nhân tạo Notebooks trên Google Cloud Platform.
©Google, Inc. hoặc các đơn vị liên kết của Google. Bảo lưu mọi quyền. Không được phân phối.