
1. Einführung
Spanner ist ein vollständig verwalteter, horizontal skalierbarer, global verteilter Datenbankdienst, der sich sowohl für relationale als auch für nicht relationale Arbeitslasten eignet.
Mit der Cassandra-Schnittstelle von Spanner können Sie die vollständig verwaltete, skalierbare und hochverfügbare Infrastruktur von Spanner mit vertrauten Cassandra-Tools und ‑Syntax nutzen.
Lerninhalte
- So richten Sie eine Spanner-Instanz und -Datenbank ein.
- So konvertieren Sie Ihr Cassandra-Schema und ‑Datenmodell.
- So exportieren Sie Ihre Verlaufsdaten aus Cassandra in Spanner.
- So richten Sie Ihre Anwendung auf Spanner anstelle von Cassandra aus.
Voraussetzungen
- Ein Google Cloud-Projekt, das mit einem Rechnungskonto verknüpft ist.
- Sie benötigen Zugriff auf einen Computer, auf dem die
gcloudCLI installiert und konfiguriert ist, oder Sie verwenden die Google Cloud Shell. - Ein Webbrowser wie Chrome oder Firefox.
2. Einrichtung und Anforderungen
GCP-Projekt erstellen
Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

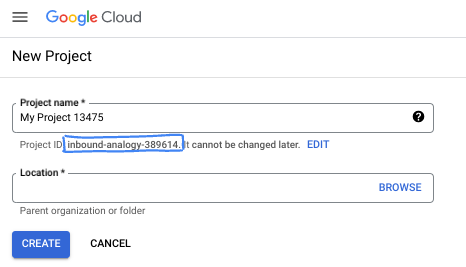
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten finden Sie in der Dokumentation.
Abrechnungseinrichtung
Als Nächstes müssen Sie der Anleitung zur Abrechnungsverwaltung folgen und die Abrechnung in der Cloud Console aktivieren. Neue Google Cloud-Nutzer können am Programm Kostenloser Testzeitraum mit einem Guthaben von 300$ teilnehmen. Wenn Sie vermeiden möchten, dass nach Abschluss dieses Codelabs weitere Kosten anfallen, können Sie die Spanner-Instanz am Ende des Codelabs herunterfahren. Folgen Sie dazu der Anleitung unter „Schritt 9: Bereinigen“.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:

Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
Nächster Schritt
Als Nächstes stellen Sie den Cassandra-Cluster bereit.
3. Cassandra-Cluster bereitstellen (Quelle)
In diesem Codelab richten wir einen Cassandra-Cluster mit einem Knoten in Compute Engine ein.
1. GCE-VM für Cassandra erstellen
Verwenden Sie zum Erstellen einer Instanz den Befehl gcloud compute instances create aus der zuvor bereitgestellten Cloud Shell.
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. Cassandra installieren
Rufen Sie VM Instances über die Seite Navigation menu auf. Folgen Sie dazu dieser Anleitung: 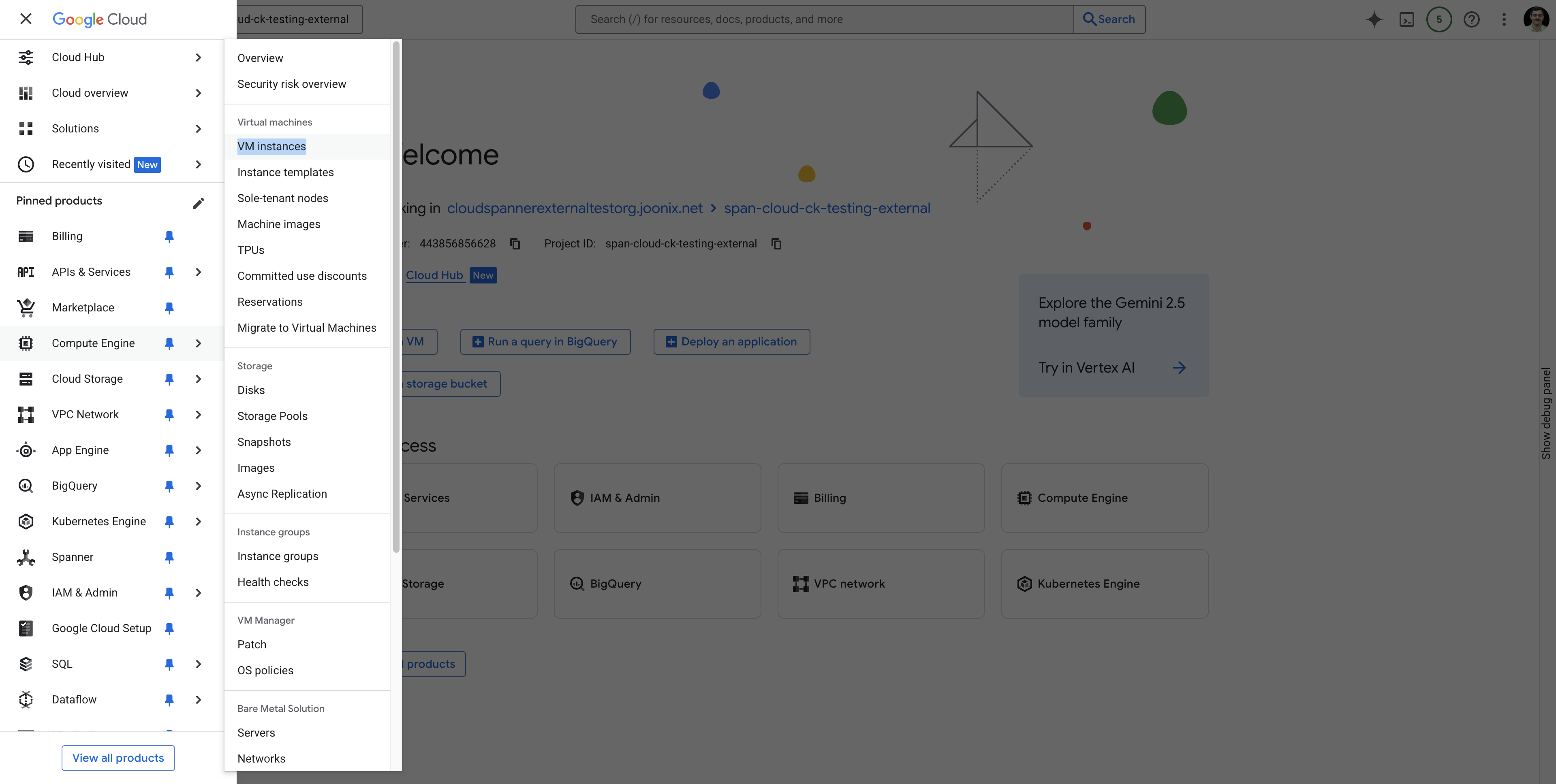 .
.
Suchen Sie nach der cassandra-origin-VM und stellen Sie wie gezeigt eine SSH-Verbindung zur VM her:
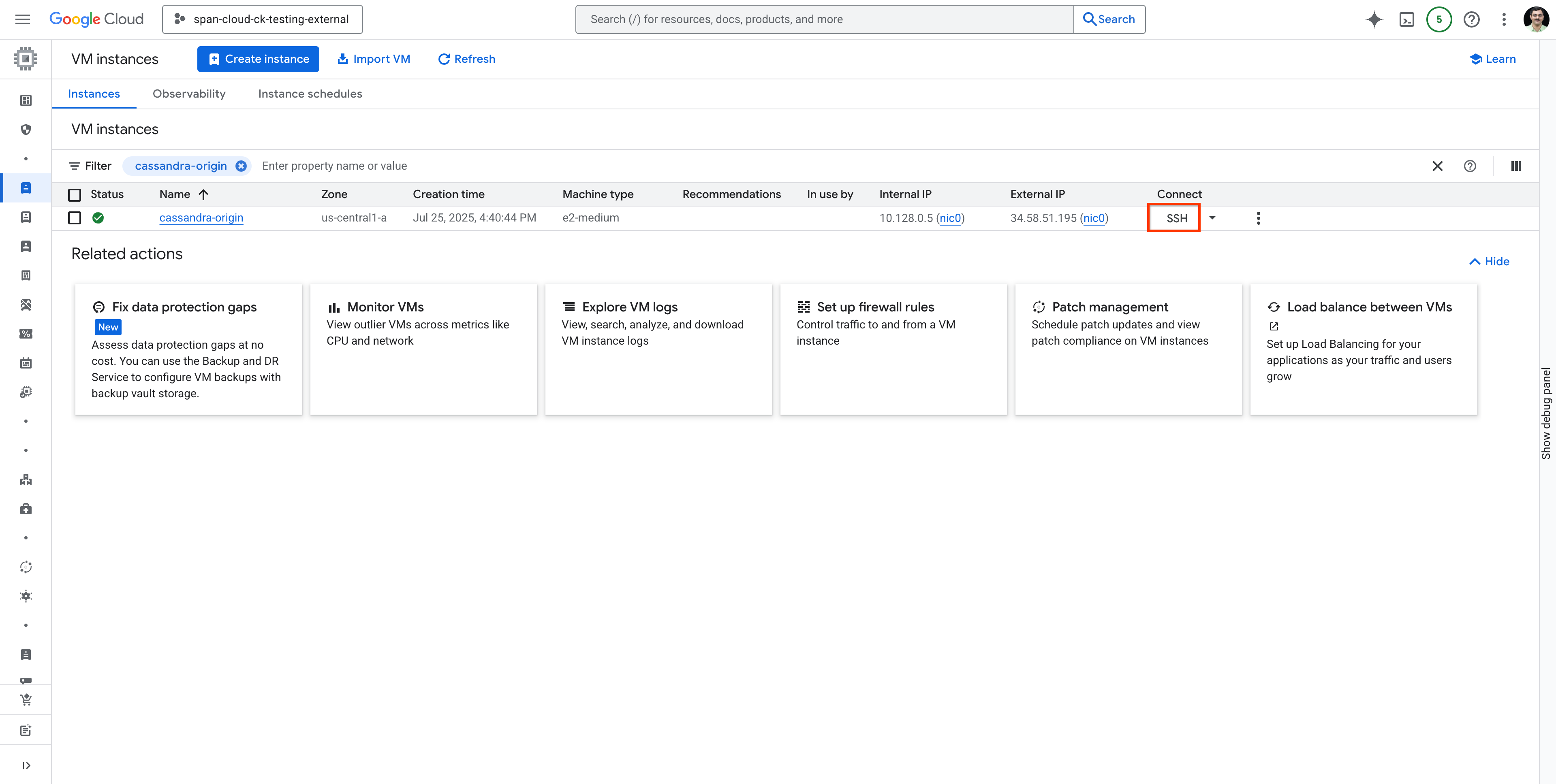 .
.
Führen Sie die folgenden Befehle aus, um Cassandra auf der VM zu installieren, die Sie erstellt und auf die Sie per SSH zugegriffen haben.
Java installieren (Cassandra-Abhängigkeit)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
Cassandra-Repository hinzufügen
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
Cassandra installieren
sudo apt-get update
sudo apt-get install -y cassandra
Legen Sie die Listen-Adresse für den Cassandra-Dienst fest.
Hier verwenden wir die interne IP-Adresse der Cassandra-VM, um die Sicherheit zu erhöhen.
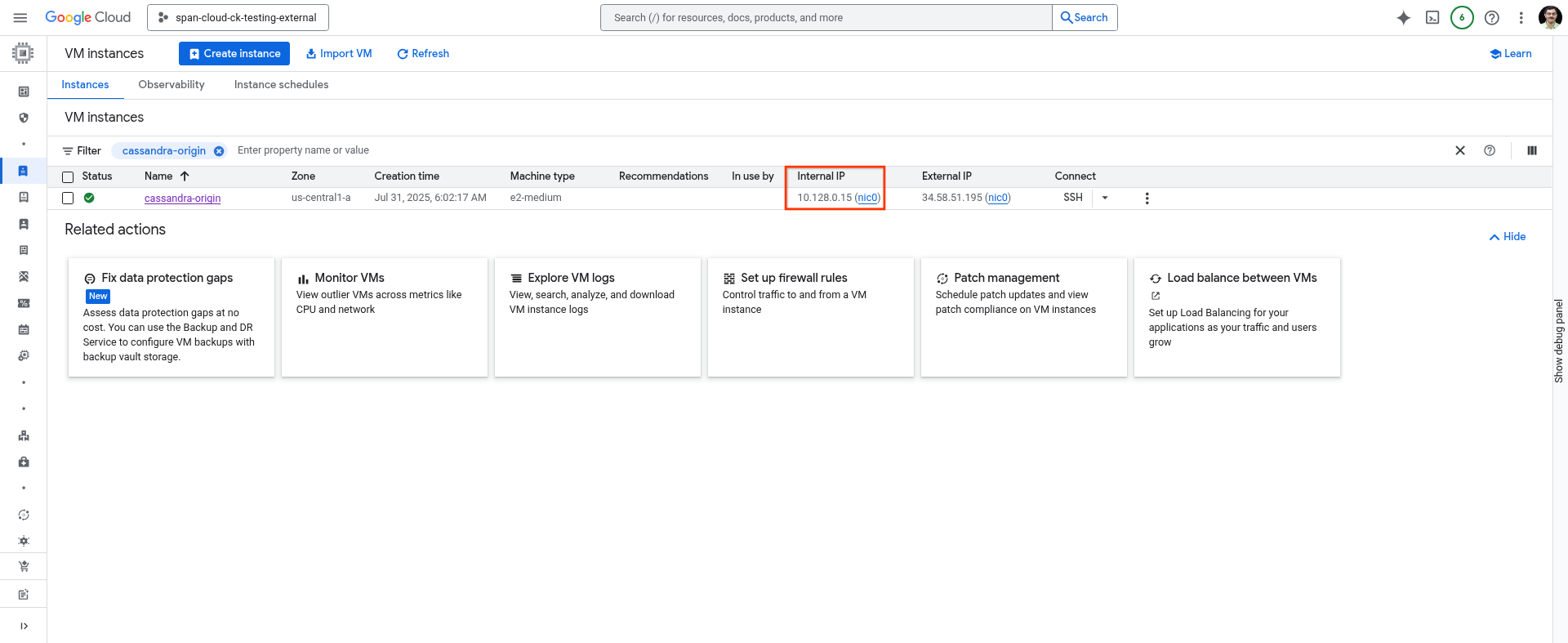
Notieren Sie sich die IP-Adresse Ihres Hostcomputers.
Sie können entweder den folgenden Befehl in der Cloud Shell verwenden oder ihn auf der Seite VM Instances in der Cloud Console abrufen.
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
ODER
 .
.
Adresse in der Konfigurationsdatei aktualisieren
Sie können die Cassandra-Konfigurationsdatei mit einem beliebigen Editor aktualisieren.
sudo vim /etc/cassandra/cassandra.yaml
Ändern Sie rpc_address: in die IP-Adresse der VM, speichern Sie die Datei und schließen Sie sie.
Cassandra-Dienst auf der VM aktivieren
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. Keyspace und Tabelle erstellen {create-keyspace-and-table}
Wir verwenden das Beispiel einer Tabelle namens „users“ und erstellen einen Keyspace namens „analytics“.
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
In cqlsh:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
Lassen Sie die SSH-Sitzung geöffnet oder notieren Sie sich die IP-Adresse dieser VM (hostname -I).
Nächster Schritt
Als Nächstes richten Sie eine Cloud Spanner-Instanz und -Datenbank ein.
4. Spanner-Instanz (Ziel) erstellen
In Spanner ist eine Instanz ein Cluster aus Rechen- und Speicherressourcen, auf dem eine oder mehrere Spanner-Datenbanken gehostet werden. Für dieses Codelab benötigen Sie mindestens eine Instanz zum Hosten einer Spanner-Datenbank.
gcloud SDK-Version prüfen
Bevor Sie eine Instanz erstellen, müssen Sie das gcloud SDK in der Google Cloud Shell auf die erforderliche Version aktualisieren. Das ist jede Version, die höher als gcloud SDK 531.0.0 ist. Sie können Ihre gcloud SDK-Version mit dem folgenden Befehl ermitteln.
$ gcloud version | grep Google
Hier ein Beispiel für die Ausgabe:
Google Cloud SDK 489.0.0
Wenn die von Ihnen verwendete Version älter als die erforderliche Version 531.0.0 (489.0.0 im vorherigen Beispiel) ist, müssen Sie Ihr Google Cloud SDK mit dem folgenden Befehl aktualisieren:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
Spanner API aktivieren
Prüfen Sie in Cloud Shell, ob Ihre Projekt-ID eingerichtet ist. Mit dem ersten Befehl unten können Sie die aktuell konfigurierte Projekt-ID ermitteln. Wenn das Ergebnis nicht den Erwartungen entspricht, wird mit dem zweiten Befehl unten das richtige Ergebnis festgelegt.
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
Konfigurieren Sie Ihre Standardregion auf us-central1. Sie können dies in eine andere Region ändern, die von regionalen Konfigurationen von Spanner unterstützt wird.
gcloud config set compute/region us-central1
Aktivieren Sie die Spanner API:
gcloud services enable spanner.googleapis.com
Spanner-Instanz erstellen
In diesem Abschnitt erstellen Sie entweder eine kostenlose Testinstanz oder eine bereitgestellte Instanz. In diesem Codelab wird die Spanner Cassandra Adapter-Instanz-ID cassandra-adapter-demo verwendet, die mit der Befehlszeile export als Variable SPANNER_INSTANCE_ID festgelegt wird. Optional können Sie einen eigenen Namen für die Instanz-ID auswählen.
Spanner-Instanz für den kostenlosen Testzeitraum erstellen
Eine 90-tägige kostenlose Spanner-Testinstanz ist für alle Nutzer mit einem Google-Konto verfügbar, in deren Projekt die Cloud-Abrechnung aktiviert ist. Kosten entstehen Ihnen erst dann, wenn Sie ein Upgrade Ihrer Testinstanz auf eine kostenpflichtige Instanz durchführen. Der Spanner Cassandra Adapter wird in der kostenlosen Testinstanz unterstützt. Wenn Sie berechtigt sind, erstellen Sie eine Instanz für den kostenlosen Testzeitraum, indem Sie Cloud Shell öffnen und diesen Befehl ausführen:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Befehlsausgabe:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. Cassandra-Schema und -Datenmodell zu Spanner migrieren
Die erste und entscheidende Phase der Migration von Daten aus einer Cassandra-Datenbank zu Spanner umfasst die Umwandlung des vorhandenen Cassandra-Schemas, um es an die strukturellen Anforderungen und Datentypanforderungen von Spanner anzupassen.
Um diesen komplexen Schemamigrationsprozess zu optimieren, können Sie eines der beiden wertvollen Open-Source-Tools von Spanner verwenden:
- Spanner-Migrationstool: Mit diesem Tool können Sie das Schema migrieren, indem Sie eine Verbindung zu einer vorhandenen Cassandra-Datenbank herstellen und das Schema zu Spanner migrieren. Dieses Tool ist als Teil von
gcloud cliverfügbar. - Spanner Cassandra Schema Tool: Mit diesem Tool können Sie eine exportierte DDL aus Cassandra in Spanner konvertieren. Sie können eines dieser beiden Tools für das Codelab verwenden. In diesem Codelab verwenden wir das Cloud Spanner-Migrationstool, um das Schema zu migrieren.
Spanner Migration Tool
Mit dem Spanner-Migrationstool können Sie Schemas aus verschiedenen Datenquellen wie MySQL, Postgres und Cassandra migrieren.
In diesem Codelab verwenden wir die CLI dieses Tools. Wir empfehlen Ihnen jedoch dringend, die UI-basierte Version des Tools zu verwenden, mit der Sie auch Änderungen an Ihrem Spanner-Schema vornehmen können, bevor es angewendet wird.
Wenn der spanner-migration-tool in Cloud Shell ausgeführt wird, hat er möglicherweise keinen Zugriff auf die interne IP-Adresse Ihrer Cassandra-VM. Daher empfehlen wir, den Befehl auf der VM auszuführen, auf der Sie Cassandra installiert haben.
Führen Sie den folgenden Befehl auf der VM aus, auf der Sie Cassandra installiert haben.
Spanner Migration Tool installieren
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
Wenn Sie Probleme mit der Installation haben, finden Sie unter installing-spanner-migration-tool eine detaillierte Anleitung.
Gcloud-Anmeldedaten aktualisieren
gcloud auth login
gcloud auth application-default login
Schema migrieren
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
Spanner-DDL überprüfen
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
Am Ende der Schemamigration sollte die Ausgabe dieses Befehls so aussehen:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(Optional) Konvertierte DDL ansehen
Sie können die konvertierte DDL ansehen und sie in Spanner neu anwenden (wenn zusätzliche Änderungen erforderlich sind).
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
Die Ausgabe dieses Befehls wäre
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
Optional: Conversion-Bericht ansehen
cat `ls -t cassandra_*report.txt | head -n 1`
Im Konvertierungsbericht werden die Probleme hervorgehoben, die Sie beachten sollten. Wenn es beispielsweise einen Unterschied bei der maximalen Genauigkeit einer Spalte zwischen Quelle und Spanner gibt, wird dies hier hervorgehoben.
6. Verlaufsdaten im Bulk-Verfahren exportieren
Für die Bulk-Migration müssen Sie Folgendes tun:
- Stellen Sie einen GCS-Bucket bereit oder verwenden Sie einen vorhandenen Bucket.
- Konfigurationsdatei für Cassandra-Treiber in den Bucket hochladen
- Starten Sie die Bulk-Migration.
Sie können die Massenmigration entweder über die Cloud Shell oder die neu bereitgestellte VM starten. Wir empfehlen jedoch, die VM für dieses Codelab zu verwenden, da bei einigen Schritten, z. B. beim Erstellen einer Konfigurationsdatei, Dateien im lokalen Speicher gespeichert werden.
Stellen Sie einen GCS-Bucket bereit.
Am Ende dieses Schritts sollten Sie einen GCS-Bucket bereitgestellt und seinen Pfad in einer Variablen mit dem Namen CASSANDRA_BUCKET_NAME exportiert haben. Wenn Sie einen vorhandenen Bucket wiederverwenden möchten, können Sie einfach mit dem Exportieren des Pfads fortfahren.
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
Treiberkonfigurationsdatei erstellen und hochladen
Hier laden wir eine sehr einfache Konfigurationsdatei für den Cassandra-Treiber hoch. Hier finden Sie das vollständige Format der Datei.
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
Bulk-Migration ausführen
Dies ist ein Beispielbefehl zum Ausführen der Bulk-Migration Ihrer Daten zu Spanner. Für tatsächliche Produktionsanwendungsfälle müssen Sie den Maschinentyp und die Anzahl entsprechend der gewünschten Skalierung und des gewünschten Durchsatzes anpassen. Eine vollständige Liste der Optionen finden Sie unter README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration.
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
Die Ausgabe sollte in etwa so aussehen: Notieren Sie sich die generierte id und verwenden Sie sie, um den Status des Dataflow-Jobs abzufragen.
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
Führen Sie den folgenden Befehl aus, um den Status des Jobs zu prüfen, und warten Sie, bis sich der Status in JOB_STATE_DONE ändert.
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
Anfangs befindet sich der Job in einem Warteschlangenstatus, z. B.
currentState: JOB_STATE_QUEUED
Während der Job in der Warteschlange steht oder ausgeführt wird, empfehlen wir Ihnen dringend, die Seite Dataflow/Jobs in der Cloud Console-UI aufzurufen, um den Job zu überwachen.
Danach ändert sich der Status des Jobs in:
currentState: JOB_STATE_DONE
7. Anwendung auf Spanner verweisen (Umstellung)
Nachdem Sie die Richtigkeit und Integrität Ihrer Daten nach der Migrationsphase sorgfältig geprüft haben, müssen Sie den operativen Fokus Ihrer Anwendung von Ihrem alten Cassandra-System auf die neu gefüllte Spanner-Datenbank verlagern. Dieser kritische Übergangszeitraum wird allgemein als Umstellung bezeichnet.
In der Umstellungsphase wird der Live-Anwendungstraffic vom ursprünglichen Cassandra-Cluster weg und direkt zur robusten und skalierbaren Spanner-Infrastruktur umgeleitet. Dieser Übergang zeigt, wie einfach Anwendungen die Leistungsfähigkeit von Spanner nutzen können, insbesondere wenn die Spanner Cassandra-Schnittstelle verwendet wird.
Mit der Cassandra-Schnittstelle von Spanner wird der Umstellungsprozess optimiert. Dabei müssen Sie in erster Linie Ihre Clientanwendungen so konfigurieren, dass für alle Dateninteraktionen der native Spanner Cassandra-Client verwendet wird. Anstatt mit Ihrer Cassandra-Datenbank (Quelle) zu kommunizieren, lesen und schreiben Ihre Anwendungen Daten nahtlos direkt in Spanner (Ziel). Diese grundlegende Änderung der Konnektivität wird in der Regel durch die Verwendung von SpannerCqlSessionBuilder erreicht, einer Schlüsselkomponente der Spanner Cassandra-Clientbibliothek, die das Herstellen von Verbindungen zu Ihrer Spanner-Instanz erleichtert. Dadurch wird der gesamte Datenverkehr Ihrer Anwendung effektiv zu Spanner umgeleitet.
Bei Java-Anwendungen, die bereits die cassandra-java-driver-Bibliothek verwenden, sind für die Einbindung des Spanner Cassandra Java-Clients nur geringfügige Änderungen an der CqlSession-Initialisierung erforderlich.
Abrufen der Abhängigkeit „google-cloud-spanner-cassandra“
Bevor Sie den Spanner Cassandra-Client verwenden können, müssen Sie die entsprechende Abhängigkeit in Ihr Projekt einbinden. Die google-cloud-spanner-cassandra-Artefakte werden in Maven Central unter der Gruppen-ID com.google.cloud veröffentlicht. Fügen Sie in Ihrem Java-Projekt unter dem vorhandenen Abschnitt <dependencies> die folgende neue Abhängigkeit hinzu. Hier ein vereinfachtes Beispiel dafür, wie Sie die google-cloud-spanner-cassandra-Abhängigkeit einfügen:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
Verbindungskonfiguration ändern, um eine Verbindung zu Spanner herzustellen
Nachdem Sie die erforderliche Abhängigkeit hinzugefügt haben, müssen Sie als Nächstes die Verbindungskonfiguration ändern, um eine Verbindung zur Spanner-Datenbank herzustellen.
Eine typische Anwendung, die mit einem Cassandra-Cluster interagiert, verwendet häufig Code wie den folgenden, um eine Verbindung herzustellen:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
Wenn Sie diese Verbindung zu Spanner umleiten möchten, müssen Sie die Logik zum Erstellen von CqlSession ändern. Anstatt die Standard-CqlSessionBuilder aus der cassandra-java-driver direkt zu verwenden, nutzen Sie die SpannerCqlSession.builder(), die vom Spanner Cassandra-Client bereitgestellt wird. Hier sehen Sie ein Beispiel dafür, wie Sie Ihren Verbindungscode ändern können:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
Durch das Instanziieren von CqlSession mit SpannerCqlSession.builder() und die Angabe des richtigen databaseUri stellt Ihre Anwendung jetzt eine Verbindung über den Spanner Cassandra-Client zu Ihrer Ziel-Spanner-Datenbank her. Durch diese wichtige Änderung werden alle nachfolgenden Lese- und Schreibvorgänge Ihrer Anwendung an Spanner weitergeleitet und von Spanner ausgeführt. So wird die ursprüngliche Umstellung abgeschlossen. Ihre Anwendung sollte jetzt wie erwartet funktionieren, unterstützt durch die Skalierbarkeit und Zuverlässigkeit von Spanner.
Hinter den Kulissen: Funktionsweise des Spanner Cassandra-Clients
Der Spanner Cassandra-Client fungiert als lokaler TCP-Proxy und fängt die Rohbytes des Cassandra-Protokolls ab, die von einem Treiber oder Clienttool gesendet werden. Anschließend werden diese Byte zusammen mit den erforderlichen Metadaten in gRPC-Nachrichten für die Kommunikation mit Spanner verpackt. Antworten von Spanner werden wieder in das Cassandra-Wire-Format übersetzt und an den ursprünglichen Treiber oder das ursprüngliche Tool zurückgesendet.
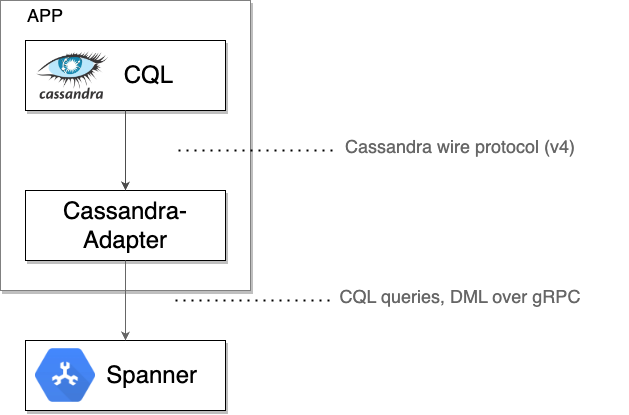
Wenn Sie sicher sind, dass Spanner den gesamten Traffic korrekt verarbeitet, können Sie Folgendes tun:
- Nehmen Sie den ursprünglichen Cassandra-Cluster außer Betrieb.
8. Bereinigen (optional)
Rufen Sie zum Bereinigen einfach den Spanner-Bereich der Cloud Console auf und löschen Sie die cassandra-adapter-demo-Instanz, die wir im Codelab erstellt haben.
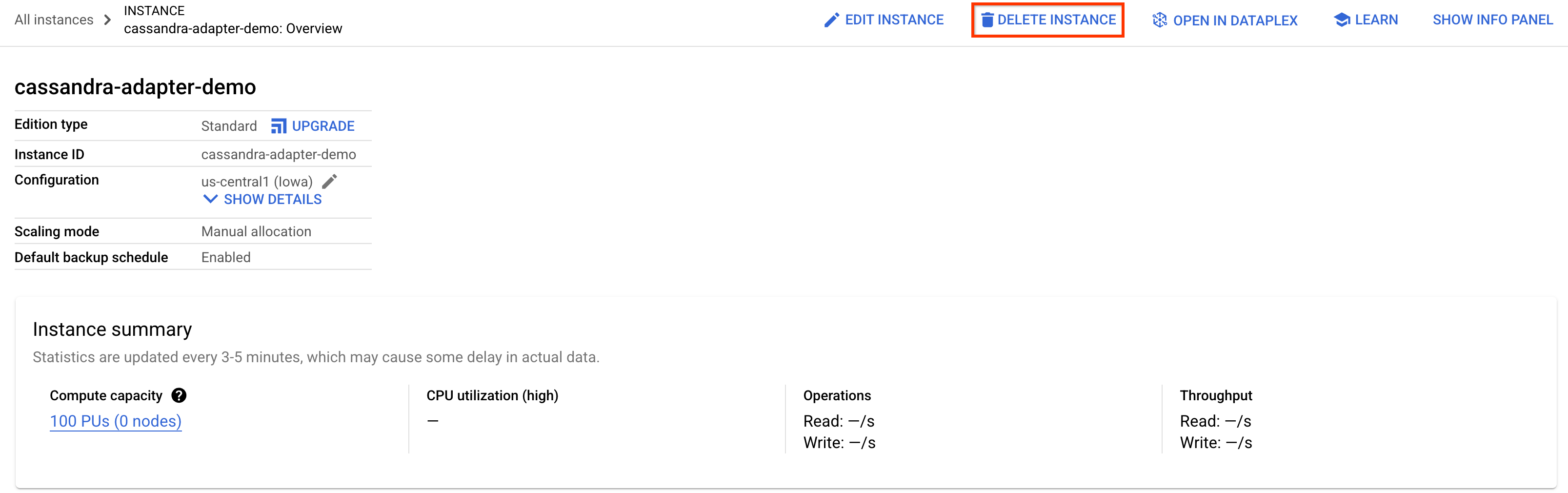
Cassandra-Datenbank löschen (falls lokal installiert oder persistent)
Wenn Sie Cassandra außerhalb einer hier erstellten Compute Engine-VM installiert haben, folgen Sie den entsprechenden Schritten, um die Daten zu entfernen oder Cassandra zu deinstallieren.