
1. 簡介
Spanner 是全代管、可水平擴充的全球分散式資料庫服務,非常適合關聯式和非關聯式工作負載。
Spanner 的 Cassandra 介面可讓您使用熟悉的 Cassandra 工具和語法,充分運用 Spanner 全代管、可擴充且高可用性的基礎架構。
課程內容
- 如何設定 Spanner 執行個體和資料庫。
- 如何轉換 Cassandra 結構定義和資料模型。
- 如何從 Cassandra 大量匯出歷來資料至 Spanner。
- 如何將應用程式指向 Spanner,而非 Cassandra。
軟硬體需求
- 已連結至帳單帳戶的 Google Cloud 專案。
- 存取已安裝及設定
gcloudCLI 的機器,或使用 Google Cloud Shell。 - 網路瀏覽器,例如 Chrome 或 Firefox。
2. 設定和需求條件
建立 GCP 專案
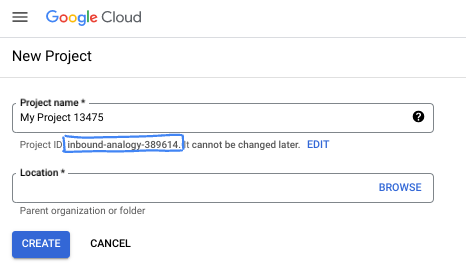
登入 Google Cloud 控制台,然後建立新專案或重複使用現有專案。如果沒有 Gmail 或 Google Workspace 帳戶,請先建立帳戶。

- 專案名稱是這個專案參與者的顯示名稱。這是 Google API 未使用的字元字串。你隨時可以更新。
- 專案 ID 在所有 Google Cloud 專案中都是不重複的,而且設定後即無法變更。Cloud 控制台會自動產生專屬字串,通常您不需要在意該字串為何。在大多數程式碼研究室中,您需要參照專案 ID (通常標示為
PROJECT_ID)。如果您不喜歡產生的 ID,可以產生另一個隨機 ID。你也可以嘗試使用自己的名稱,看看是否可用。完成這個步驟後就無法變更,且專案期間會維持不變。 - 請注意,有些 API 會使用第三個值,也就是「專案編號」。如要進一步瞭解這三種值,請參閱說明文件。
帳單設定
接著,請按照管理帳單的使用者指南,在 Cloud Console 中啟用帳單。Google Cloud 新使用者可參加價值$300 美元的免費試用計畫。為避免在本教學課程結束後產生費用,請按照「步驟 9:清除所用資源」的說明,在程式碼研究室結束時關閉 Spanner 執行個體。
啟動 Cloud Shell
雖然可以透過筆電遠端操作 Google Cloud,但在本程式碼研究室中,您將使用 Google Cloud Shell,這是可在雲端執行的指令列環境。
在 Google Cloud 控制台中,點選右上工具列的 Cloud Shell 圖示:

佈建並連線至環境的作業需要一些時間才能完成。完成後,您應該會看到如下的內容:

這部虛擬機器搭載各種您需要的開發工具,並提供永久的 5GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。您可以在瀏覽器中完成本程式碼研究室的所有作業。您不需要安裝任何軟體。
下一步
接著,您將部署 Cassandra 叢集。
3. 部署 Cassandra 叢集 (來源)
在本程式碼研究室中,我們會在 Compute Engine 上設定單一節點的 Cassandra 叢集。
1. 為 Cassandra 建立 GCE VM
如要建立執行個體,請使用先前佈建的 Cloud Shell 中的 gcloud compute instances create 指令。
gcloud compute instances create cassandra-origin \
--machine-type=e2-medium \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=cassandra-migration \
--boot-disk-size=20GB \
--zone=us-central1-a
2. 安裝 Cassandra
按照下列指示,從「Navigation menu」頁面前往「VM Instances」: 。
。
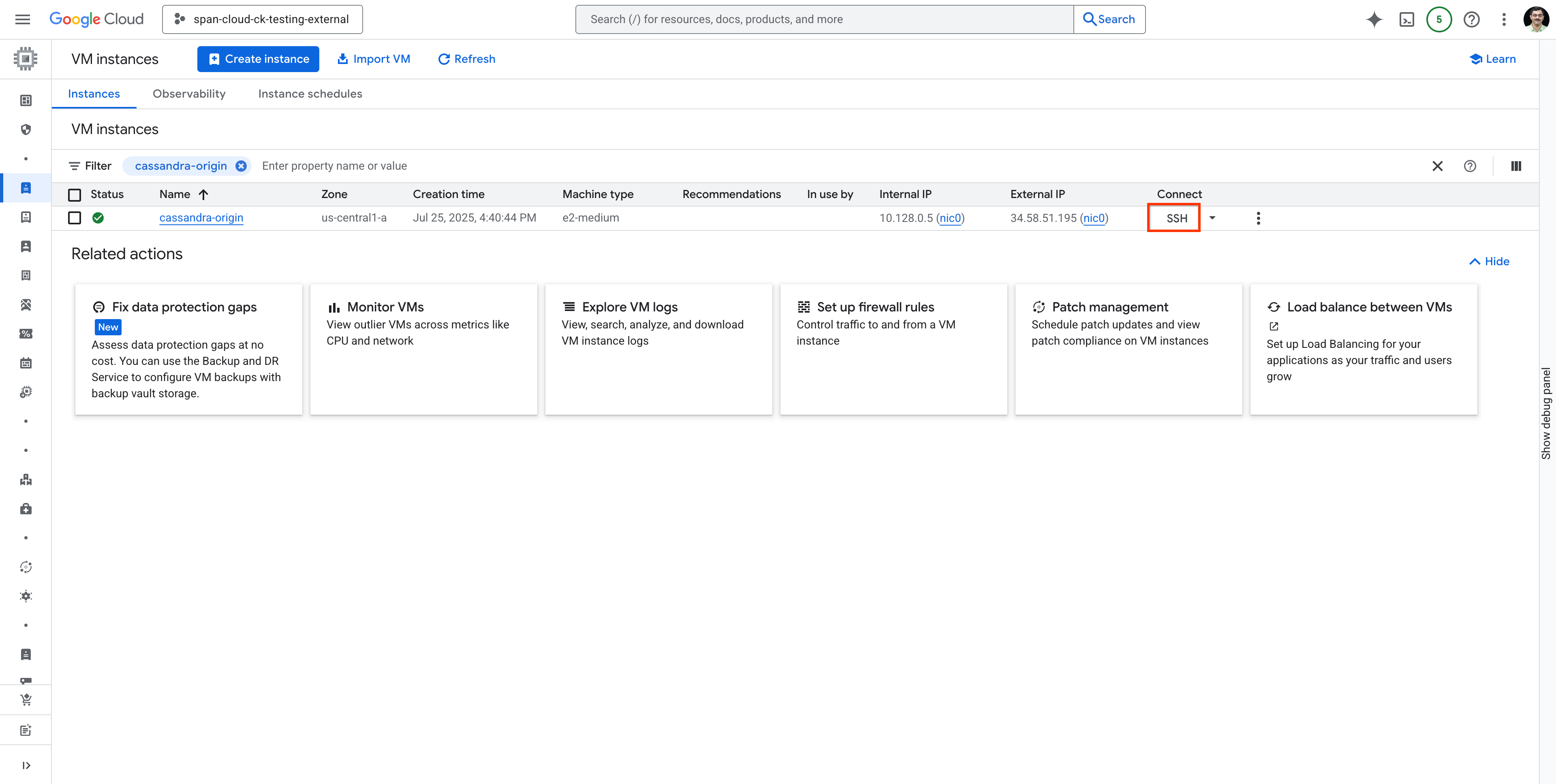
搜尋 cassandra-origin VM,然後使用 SSH 連線至 VM,如下所示:
 。
。
在您建立並透過 SSH 連線的 VM 上執行下列指令,安裝 Cassandra。
安裝 Java (Cassandra 依附元件)
sudo apt-get update
sudo apt-get install -y openjdk-11-jre-headless
新增 Cassandra 存放區
echo "deb [signed-by=/etc/apt/keyrings/apache-cassandra.asc] https://debian.cassandra.apache.org 41x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
sudo curl -o /etc/apt/keyrings/apache-cassandra.asc https://downloads.apache.org/cassandra/KEYS
安裝 Cassandra
sudo apt-get update
sudo apt-get install -y cassandra
設定 Cassandra 服務的接聽位址。
為提高安全性,我們在此使用 Cassandra VM 的內部 IP 位址。
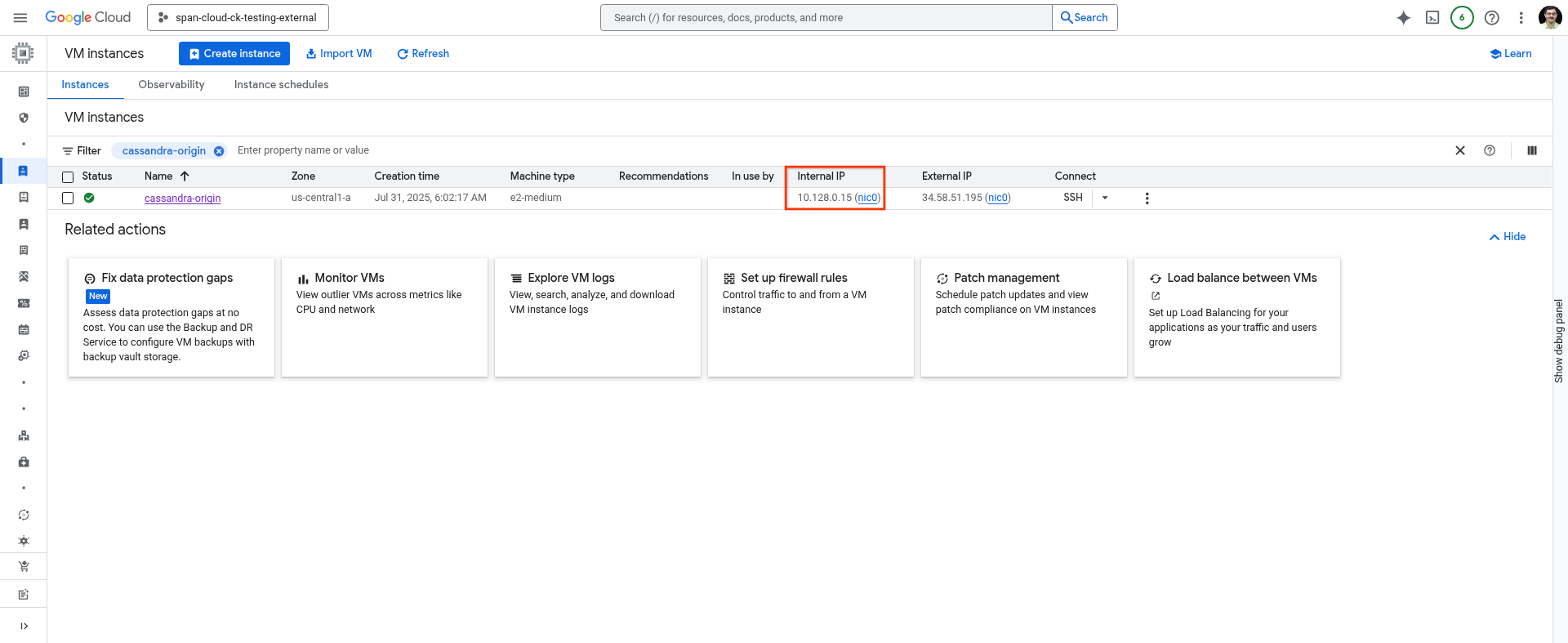
記下主體機器的 IP 位址
您可以使用 Cloud Shell 上的下列指令,或從 Cloud Console 的 VM Instances 頁面取得。
gcloud compute instances describe cassandra-origin --format="get(networkInterfaces[0].networkIP)" --zone=us-central1-a
或
 。
。
更新設定檔中的位址
您可以使用所選的編輯器更新 Cassandra 設定檔
sudo vim /etc/cassandra/cassandra.yaml
將 rpc_address: 變更為 VM 的 IP 位址,然後儲存並關閉檔案。
在 VM 上啟用 Cassandra 服務
sudo systemctl enable cassandra
sudo systemctl stop cassandra
sudo systemctl start cassandra
sudo systemctl status cassandra
3. 建立鍵空間和資料表 {create-keyspace-and-table}
我們將使用「users」表格範例,並建立名為「analytics」的鍵空間。
export CQLSH_HOST=<IP of the VM added as rpc_address>
/usr/bin/cqlsh
在 cqlsh 中:
-- Create keyspace (adjust replication for production)
CREATE KEYSPACE analytics WITH replication = {'class':'SimpleStrategy', 'replication_factor':1};
-- Use the keyspace
USE analytics;
-- Create the users table
CREATE TABLE users (
id int PRIMARY KEY,
active boolean,
username text,
);
-- Insert 5 rows
INSERT INTO users (id, active, username) VALUES (1, true, 'd_knuth');
INSERT INTO users (id, active, username) VALUES (2, true, 'sanjay_ghemawat');
INSERT INTO users (id, active, username) VALUES (3, false, 'gracehopper');
INSERT INTO users (id, active, username) VALUES (4, true, 'brian_kernighan');
INSERT INTO users (id, active, username) VALUES (5, true, 'jeff_dean');
INSERT INTO users (id, active, username) VALUES (6, true, 'jaime_levy');
-- Select all users to verify the inserts.
SELECT * from users;
-- Exit cqlsh
EXIT;
讓 SSH 工作階段保持開啟狀態,或記下這個 VM 的 IP 位址 (hostname -I)。
下一步
接著,您將設定 Cloud Spanner 執行個體和資料庫。
4. 建立 Spanner 執行個體 (目標)
在 Spanner 中,執行個體是運算和儲存資源的叢集,可代管一或多個 Spanner 資料庫。您至少需要 1 個執行個體,才能為本程式碼研究室代管 Spanner 資料庫。
檢查 gcloud SDK 版本
建立執行個體前,請務必將 Google Cloud Shell 中的 gcloud SDK 更新至必要版本 (任何高於 gcloud SDK 531.0.0 的版本)。您可以執行下列指令,查看 gcloud SDK 版本。
$ gcloud version | grep Google
輸出內容範例如下:
Google Cloud SDK 489.0.0
如果您使用的版本早於必要版本 531.0.0 (上例中的 489.0.0),則需要執行下列指令,升級 Google Cloud SDK:
sudo apt-get update \
&& sudo apt-get --only-upgrade install google-cloud-cli-anthoscli google-cloud-cli-cloud-run-proxy kubectl google-cloud-cli-skaffold google-cloud-cli-cbt google-cloud-cli-docker-credential-gcr google-cloud-cli-spanner-migration-tool google-cloud-cli-cloud-build-local google-cloud-cli-pubsub-emulator google-cloud-cli-app-engine-python google-cloud-cli-kpt google-cloud-cli-bigtable-emulator google-cloud-cli-datastore-emulator google-cloud-cli-spanner-emulator google-cloud-cli-app-engine-go google-cloud-cli-app-engine-python-extras google-cloud-cli-config-connector google-cloud-cli-package-go-module google-cloud-cli-istioctl google-cloud-cli-anthos-auth google-cloud-cli-gke-gcloud-auth-plugin google-cloud-cli-app-engine-grpc google-cloud-cli-kubectl-oidc google-cloud-cli-terraform-tools google-cloud-cli-nomos google-cloud-cli-local-extract google-cloud-cli-firestore-emulator google-cloud-cli-harbourbridge google-cloud-cli-log-streaming google-cloud-cli-minikube google-cloud-cli-app-engine-java google-cloud-cli-enterprise-certificate-proxy google-cloud-cli
啟用 Spanner API
在 Cloud Shell 中,確認專案 ID 已設定完畢。使用下列第一個指令找出目前設定的專案 ID。如果結果不如預期,請使用下方的第二個指令設定正確的結果。
gcloud config get-value project
gcloud config set project [YOUR-DESIRED-PROJECT-ID]
將預設區域設為 us-central1。您可以將這個區域變更為 Spanner 區域設定支援的其他區域。
gcloud config set compute/region us-central1
啟用 Spanner API:
gcloud services enable spanner.googleapis.com
建立 Spanner 執行個體
在本節中,您將建立免費試用執行個體或佈建的執行個體。在本程式碼實驗室中,使用的 Spanner Cassandra 介面卡執行個體 ID 為 cassandra-adapter-demo,並透過 export 指令列設為 SPANNER_INSTANCE_ID 變數。您可以選擇自行設定執行個體 ID 名稱。
建立免費試用 Spanner 執行個體
只要擁有 Google 帳戶,並在專案中啟用 Cloud Billing,即可建立 Spanner 90 天免費試用執行個體。除非您選擇將免費試用執行個體升級為付費執行個體,否則我們不會向您收費。免費試用執行個體支援 Spanner Cassandra Adapter。如果符合資格,請開啟 Cloud Shell 並執行下列指令,建立免費試用執行個體:
export SPANNER_INSTANCE_ID=cassandra-adapter-demo
export SPANNER_REGION=regional-us-central1
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
指令輸出:
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--config=$SPANNER_REGION \
--instance-type=free-instance \
--description="Spanner Cassandra Adapter demo"
Creating instance...done.
5. 將 Cassandra 結構定義和資料模型遷移至 Spanner
從 Cassandra 資料庫遷移至 Spanner 的初期重要階段,是將現有 Cassandra 結構定義轉換為符合 Spanner 的結構和資料類型需求。
為簡化這項複雜的結構定義遷移程序,請使用 Spanner 提供的任一項實用開放原始碼工具:
- Spanner 遷移工具:這項工具可連線至現有的 Cassandra 資料庫,並將結構定義遷移至 Spanner,協助您遷移結構定義。這項工具是
gcloud cli的一部分。 - Spanner Cassandra 結構定義工具:這個工具可協助您將從 Cassandra 匯出的 DDL 轉換為 Spanner。您可以在程式碼研究室中使用這兩項工具的任一項。在本程式碼研究室中,我們將使用 Spanner 遷移工具遷移結構定義。
Spanner 遷移工具
Spanner 遷移工具可協助從各種資料來源 (例如 MySQL、Postgres、Cassandra 等) 遷移結構定義。
雖然在本程式碼研究室中,我們會使用這項工具的 CLI,但強烈建議您探索並使用這項工具的 UI 版本,因為該版本也能協助您在套用 Spanner 結構定義前進行修改。
請注意,如果 spanner-migration-tool 是在 Cloud Shell 上執行,可能無法存取 Cassandra VM 的內部 IP 位址。因此,建議您在安裝 Cassandra 的 VM 上執行相同作業。
在安裝 Cassandra 的 VM 上執行下列指令。
安裝 Spanner 遷移工具
sudo apt-get update
sudo apt-get install --upgrade google-cloud-sdk-spanner-migration-tool
如果在安裝時遇到任何問題,請參閱「installing-spanner-migration-tool」瞭解詳細步驟。
重新整理 Gcloud 憑證
gcloud auth login
gcloud auth application-default login
遷移結構定義
export CASSANDRA_HOST=`<ip address of the VM used as rpc_address above>`
export PROJECT=`<PROJECT_ID>`
gcloud alpha spanner migrate schema \
--source=cassandra \
--source-profile="host=${CASSANDRA_HOST},user=cassandra,password=cassandra,port=9042,keyspace=analytics,datacenter=datacenter1" \
--target-profile="project=${PROJECT},instance=cassandra-adapter-demo,dbName=analytics" \
--project=${PROJECT}
驗證 Spanner DDL
gcloud spanner databases ddl describe analytics --instance=cassandra-adapter-demo
結構定義遷移作業完成後,這項指令的輸出內容應如下所示:
CREATE TABLE users (
active BOOL OPTIONS (
cassandra_type = 'boolean'
),
id INT64 NOT NULL OPTIONS (
cassandra_type = 'int'
),
username STRING(MAX) OPTIONS (
cassandra_type = 'text'
),
) PRIMARY KEY(id);
(選用) 查看轉換後的 DDL
您可以查看轉換後的 DDL,並在 Spanner 上重新套用 (如果需要進行其他變更)
cat `ls -t cassandra_*schema.ddl.txt | head -n 1`
這項指令的輸出內容如下
CREATE TABLE `users` (
`active` BOOL OPTIONS (cassandra_type = 'boolean'),
`id` INT64 NOT NULL OPTIONS (cassandra_type = 'int'),
`username` STRING(MAX) OPTIONS (cassandra_type = 'text'),
) PRIMARY KEY (`id`)
(選用) 查看轉換報表
cat `ls -t cassandra_*report.txt | head -n 1`
轉換報表會列出您應注意的問題。舉例來說,如果來源和 Spanner 之間某個資料欄的最大精確度不相符,系統就會在這裡醒目顯示。
6. 大量匯出歷來資料
如要大量遷移,請按照下列步驟操作:
- 佈建或重複使用現有的 GCS bucket。
- 將 Cassandra Driver 設定檔上傳至 bucket
- 啟動大量遷移作業。
您可以從 Cloud Shell 或新佈建的 VM 啟動大量遷移作業,但我們建議使用 VM 進行本程式碼研究室,因為建立設定檔等步驟會將檔案保留在本機儲存空間中。
佈建 GCS bucket。
完成這個步驟後,您應該已佈建 GCS 值區,並將其路徑匯出至名為 CASSANDRA_BUCKET_NAME 的變數。如要重複使用現有值區,只要匯出路徑即可。
if [ -z ${CASSANDRA_BUCKET_NAME} ]; then
export CASSANDRA_BUCKET_NAME="gs://cassandra-demo-$(date +%Y-%m-%d-%H-%M-%S)-$(head /dev/urandom | tr -dc a-z | head -c 20)"
gcloud storage buckets create "${CASSANDRA_BUCKET_NAME}"
else
echo "using existing bucket ${CASSANDRA_BUCKET_NAME}"
fi
建立及上傳驅動程式設定檔
我們在這裡上傳非常基本的 Cassandra 驅動程式設定檔。如需檔案的完整格式,請參閱這篇文章。
# Configuration for the Cassandra instance and GCS bucket
INSTANCE_NAME="cassandra-origin"
ZONE="us-central1-a"
CASSANDRA_PORT="9042"
# Retrieve the internal IP address of the Cassandra instance
CASSANDRA_IP=$(gcloud compute instances describe "${INSTANCE_NAME}" \
--format="get(networkInterfaces[0].networkIP)" \
--zone="${ZONE}")
# Check if the IP was successfully retrieved
if [[ -z "${CASSANDRA_IP}" ]]; then
echo "Error: Could not retrieve Cassandra instance IP."
exit 1
fi
# Define the full contact point
CONTACT_POINT="${CASSANDRA_IP}:${CASSANDRA_PORT}"
# Create a temporary file with the specified content
TMP_FILE=$(mktemp)
cat <<EOF > "${TMP_FILE}"
# Reference configuration for the DataStax Java driver for Apache Cassandra®.
# This file is in HOCON format, see https://github.com/typesafehub/config/blob/master/HOCON.md.
datastax-java-driver {
basic.contact-points = ["${CONTACT_POINT}"]
basic.session-keyspace = analytics
basic.load-balancing-policy.local-datacenter = datacenter1
advanced.auth-provider {
class = PlainTextAuthProvider
username = cassandra
password = cassandra
}
}
EOF
# Upload the temporary file to the specified GCS bucket
if gsutil cp "${TMP_FILE}" "${CASSANDRA_BUCKET_NAME}/cassandra.conf"; then
echo "Successfully uploaded ${TMP_FILE} to ${CASSANDRA_BUCKET_NAME}/cassandra.conf"
# Concatenate (cat) the uploaded file from GCS
echo "Displaying the content of the uploaded file:"
gsutil cat "${CASSANDRA_BUCKET_NAME}/cassandra.conf"
else
echo "Error: Failed to upload file to GCS."
fi
# Clean up the temporary file
rm "${TMP_FILE}"
執行大量遷移作業
這是將資料大量遷移至 Spanner 的範例指令。在實際的生產環境使用案例中,您必須根據所需的規模和輸送量調整機型和數量。如需完整選項清單,請參閱 README_Sourcedb_to_Spanner.md#cassandra-to-spanner-bulk-migration。
gcloud dataflow flex-template run "sourcedb-to-spanner-flex-job" \
--project "`gcloud config get-value project`" \
--region "us-central1" \
--max-workers "2" \
--num-workers "1" \
--worker-machine-type "e2-standard-8" \
--template-file-gcs-location "gs://dataflow-templates-us-central1/latest/flex/Sourcedb_to_Spanner_Flex" \
--additional-experiments="[\"disable_runner_v2\"]" \
--parameters "sourceDbDialect=CASSANDRA" \
--parameters "insertOnlyModeForSpannerMutations=true" \
--parameters "sourceConfigURL=$CASSANDRA_BUCKET_NAME/cassandra.conf" \
--parameters "instanceId=cassandra-adapter-demo" \
--parameters "databaseId=analytics" \
--parameters "projectId=`gcloud config get-value project`" \
--parameters "outputDirectory=$CASSANDRA_BUCKET_NAME/output" \
--parameters "batchSizeForSpannerMutations=1"
這會產生類似下方的輸出內容。請記下產生的 id,並使用相同的值查詢 Dataflow 工作的狀態。
job: createTime: '2025-08-08T09:41:09.820267Z' currentStateTime: '1970-01-01T00:00:00Z' id: 2025-08-08_02_41_09-17637291823018196600 location: us-central1 name: sourcedb-to-spanner-flex-job projectId: span-cloud-ck-testing-external startTime: '2025-08-08T09:41:09.820267Z'
執行下列指令檢查工作狀態,並等待狀態變更為 JOB_STATE_DONE。
gcloud dataflow jobs describe --region=us-central1 <dataflow job id> | grep "currentState:"
工作一開始會處於佇列狀態,例如
currentState: JOB_STATE_QUEUED
工作排入佇列/執行時,我們強烈建議您在 Cloud 控制台 UI 中探索「Dataflow/Jobs」頁面,監控工作。
完成後,工作狀態會變更為:
currentState: JOB_STATE_DONE
7. 將應用程式指向 Spanner (轉換)
在遷移階段後,請仔細驗證資料的準確性和完整性,然後將應用程式的運作重心從舊版 Cassandra 系統轉移至新填入的 Spanner 資料庫,這是至關重要的步驟。這個關鍵的轉換期通常稱為「轉換」。
在轉換階段,系統會將即時應用程式流量從原始 Cassandra 叢集重新導向,並直接連線至強大且可擴充的 Spanner 基礎架構。這項轉換作業顯示應用程式可輕鬆運用 Spanner 的強大功能,特別是使用 Spanner Cassandra 介面時。
透過 Spanner Cassandra 介面,可簡化轉換程序。主要做法是設定用戶端應用程式,以便透過原生 Spanner Cassandra 用戶端進行所有資料互動。應用程式會直接開始讀取及寫入 Spanner (目標) 的資料,而不會與 Cassandra (來源) 資料庫通訊。這項連線方式的重大轉變,通常是透過 SpannerCqlSessionBuilder 達成,這是 Spanner Cassandra 用戶端程式庫的重要元件,可協助建立與 Spanner 執行個體的連線。這項操作會將應用程式的整個資料流量重新導向至 Spanner。
如果 Java 應用程式已使用 cassandra-java-driver 程式庫,整合 Spanner Cassandra Java 用戶端時,只需要對 CqlSession 初始化作業進行微幅變更。
取得 google-cloud-spanner-cassandra 依附元件
如要開始使用 Spanner Cassandra 用戶端,請先將其依附元件併入專案。google-cloud-spanner-cassandra 構件會發布至 Maven Central,群組 ID 為 com.google.cloud。在 Java 專案的現有 <dependencies> 區段下方新增下列依附元件。以下是簡化的範例,說明如何加入 google-cloud-spanner-cassandra 依附元件:
<!-- native Spanner Cassandra Client -->
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-cassandra</artifactId>
<version>0.2.0</version>
</dependency>
</dependencies>
變更連線設定,連線至 Spanner
新增必要依附元件後,下一步是變更連線設定,連線至 Spanner 資料庫。
與 Cassandra 叢集互動的應用程式通常會使用類似下列的程式碼建立連線:
CqlSession session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withLocalDatacenter("datacenter1")
.withAuthCredentials("username", "password")
.build();
如要將這個連線重新導向至 Spanner,請修改 CqlSession 建立邏輯。您將使用 Spanner Cassandra Client 提供的 SpannerCqlSession.builder(),而不是直接使用 cassandra-java-driver 中的標準 CqlSessionBuilder。以下是修改連線程式碼的示意範例:
String databaseUri = "projects/<your-gcp-project>/instances/<your-spanner-instance>/databases/<your-spanner-database>";
CqlSession session = SpannerCqlSession.builder()
.setDatabaseUri(databaseUri)
.addContactPoint(new InetSocketAddress("localhost", 9042))
.withLocalDatacenter("datacenter1")
.build();
透過例項化 CqlSession SpannerCqlSession.builder() 並提供正確的 databaseUri,應用程式現在會透過 Spanner Cassandra 用戶端,與目標 Spanner 資料庫建立連線。這項重大變更可確保應用程式後續執行的所有讀取和寫入作業,都會導向 Spanner 並由 Spanner 處理,有效完成初始轉換。此時,您的應用程式應會繼續正常運作,並由 Spanner 的擴充性和可靠性提供支援。
深入瞭解:Spanner Cassandra 用戶端運作方式
Spanner Cassandra 用戶端會做為本機 TCP Proxy,攔截驅動程式或用戶端工具傳送的原始 Cassandra 通訊協定位元組。然後將這些位元組連同必要的中繼資料包裝成 gRPC 訊息,以便與 Spanner 通訊。Spanner 的回應會翻譯回 Cassandra 連線格式,並傳回給原始驅動程式或工具。
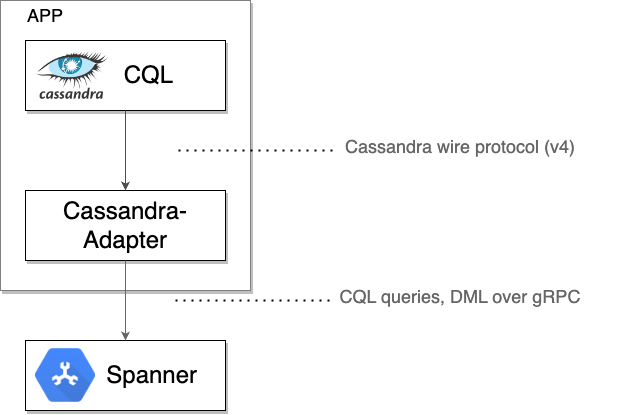
確認 Spanner 能正確處理所有流量後,您最終可以:
- 停用原始 Cassandra 叢集。
8. 清除 (選用)
如要清理資源,請前往 Cloud 控制台的 Spanner 專區,然後刪除我們在程式碼研究室中建立的 cassandra-adapter-demo 執行個體。
刪除 Cassandra 資料庫 (如果是在本機安裝或持續存在)
如果您在 Compute Engine VM 以外的位置安裝 Cassandra,請按照適當步驟移除資料或解除安裝 Cassandra。
9. 恭喜!
後續步驟
- 進一步瞭解 Spanner。
- 進一步瞭解 Cassandra 介面。