
۱. مقدمه
تصور کنید که بتوانید دادههای خود را بدون نیاز به متخصص کدنویسی، سریعتر و کارآمدتر برای تجزیه و تحلیل آماده کنید. با BigQuery Data Preparation ، این یک واقعیت است. این ویژگی قدرتمند، دریافت، تبدیل و پاکسازی دادهها را ساده میکند و آمادهسازی دادهها را در اختیار همه متخصصان داده در سازمان شما قرار میدهد.
آمادهاید تا اسرار پنهان در دادههای محصول خود را کشف کنید؟
پیشنیازها
- درک اولیه از گوگل کلود، کنسول
- درک اولیه از SQL
آنچه یاد خواهید گرفت
- چگونه آمادهسازی دادههای BigQuery میتواند دادههای خام شما را با استفاده از یک مثال واقعگرایانه از صنعت مد و زیبایی، پالایش و به هوش تجاری کاربردی تبدیل کند.
- نحوه اجرا و زمانبندی آمادهسازی دادهها برای دادههای پاکشده
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
۲. تنظیمات اولیه و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .


- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چیست. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
۳. قبل از شروع
فعال کردن API
برای استفاده از Gemini در BigQuery، باید Gemini for Google Cloud API را فعال کنید. معمولاً یک مدیر سرویس یا صاحب پروژه با مجوز IAM serviceusage.services.enable این مرحله را انجام میدهد.
- برای فعال کردن Gemini for Google Cloud API، به صفحه Gemini for Google Cloud در Google Cloud Marketplace بروید. به Gemini for Google Cloud بروید
- در انتخابگر پروژه، یک پروژه را انتخاب کنید.
- روی فعال کردن کلیک کنید. صفحه بهروزرسانی میشود و وضعیت «فعال» را نشان میدهد. Gemini در BigQuery اکنون در پروژه انتخابشده Google Cloud برای همه کاربرانی که مجوزهای IAM لازم را دارند، در دسترس است.
تنظیم نقشها و مجوزها برای توسعه آمادهسازی دادهها
- در بخش مدیریت و مدیریت، گزینه IAM را انتخاب کنید.
- کاربر خود را انتخاب کنید و روی نماد مداد کلیک کنید تا «ویرایش مدیر» انجام شود.
برای استفاده از BigQuery Data Preparation، به نقشها و مجوزهای زیر نیاز دارید:
- ویرایشگر داده BigQuery (roles/bigquery.dataEditor)
- مصرفکنندهی استفاده از سرویس (roles/serviceusage.serviceUsageConsumer)
۴. پیدا کردن و عضویت در فهرست «نسخه آزمایشی آمادهسازی دادههای bq» در مرکز تجزیه و تحلیل BigQuery
ما برای این آموزش از مجموعه داده bq data preparation demo استفاده خواهیم کرد. این یک مجموعه داده مرتبط در BigQuery Analytics Hub است که ما از آن اطلاعات را خواهیم خواند.
آمادهسازی دادهها هرگز در منبع داده دوباره نوشته نمیشود و از شما میخواهیم که یک جدول مقصد برای نوشتن در آن تعریف کنید. جدولی که برای این تمرین با آن کار خواهیم کرد، فقط ۱۰۰۰ ردیف دارد تا هزینهها به حداقل برسد، اما آمادهسازی دادهها روی BigQuery اجرا میشود و در کنار آن مقیاسپذیر خواهد بود.
برای یافتن و اشتراک در مجموعه دادههای پیوندی، این مراحل را دنبال کنید:
- دسترسی به مرکز تجزیه و تحلیل : در کنسول Google Cloud، به BigQuery بروید.
- در منوی ناوبری BigQuery، در قسمت «مدیریت»، «مرکز تجزیه و تحلیل» را انتخاب کنید.
- جستجوی آگهی: در رابط کاربری Analytics Hub، روی «جستجوی آگهیها » کلیک کنید.
- عبارت
bq data preparation demoدر نوار جستجو تایپ کرده و Enter را بزنید.
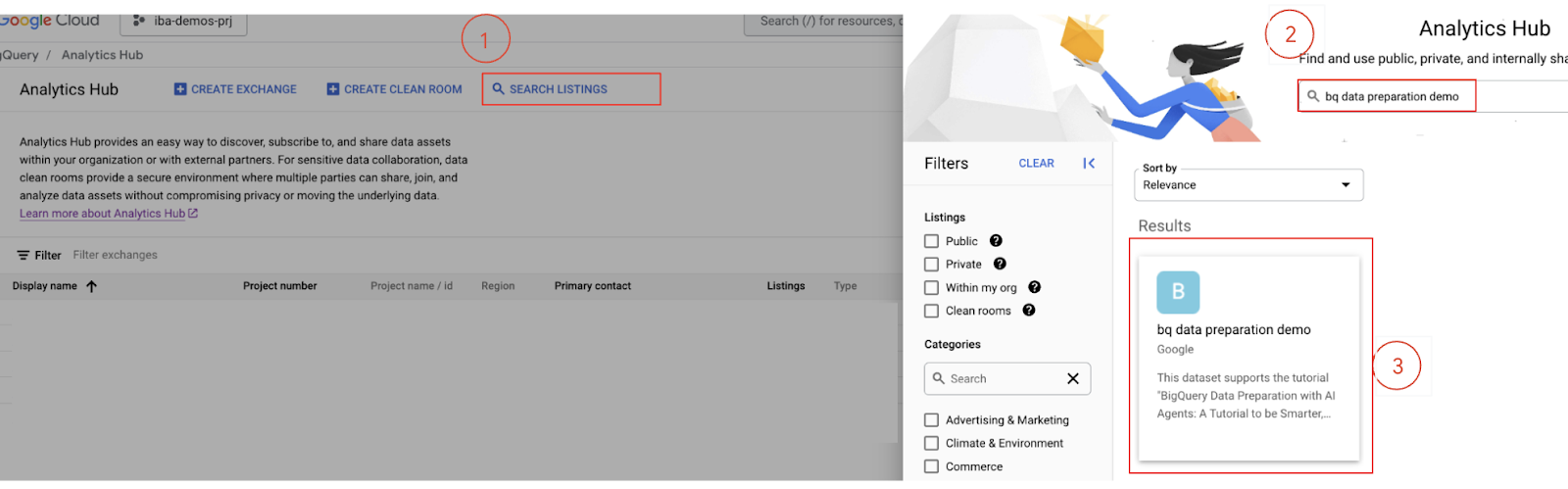
- مشترک شدن در فهرست: فهرست
bq data preparation demoرا از نتایج جستجو انتخاب کنید. - در صفحه جزئیات آگهی، روی دکمه عضویت کلیک کنید.
- هرگونه کادر تأیید را بررسی کنید و در صورت نیاز، پروژه/مجموعه داده را بهروزرسانی کنید. پیشفرضها باید صحیح باشند.
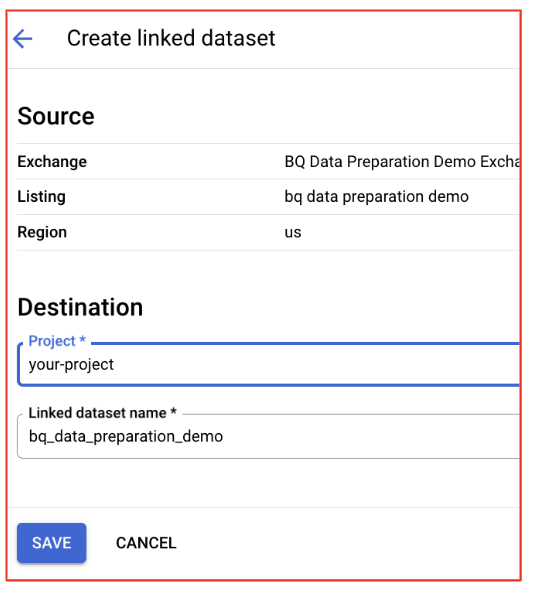
- دسترسی به مجموعه دادهها در BigQuery: پس از اینکه با موفقیت مشترک شدید، مجموعه دادههای موجود در فهرست به پروژه BigQuery شما پیوند داده میشوند.
بازگشت به استودیوی BigQuery .
۵. دادهها را بررسی کنید و آمادهسازی دادهها را آغاز کنید
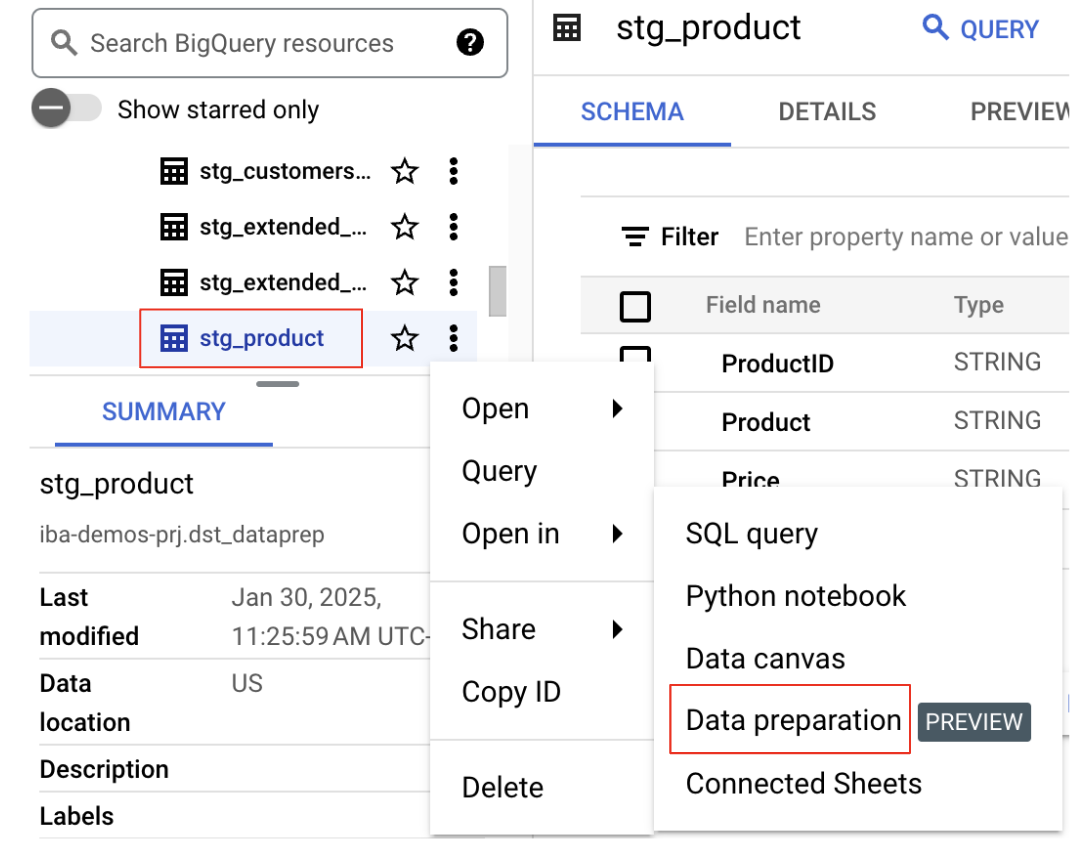
- مجموعه داده و جدول را پیدا کنید: در پنل Explorer، پروژه خود را انتخاب کنید و سپس مجموعه دادهای را که در فهرست
bq data preparation demoوجود داشت، پیدا کنید. جدولstg_productرا انتخاب کنید. - باز کردن در آمادهسازی دادهها: روی سه نقطه عمودی کنار نام جدول کلیک کنید و گزینه
Open in Data Preparationرا انتخاب کنید.
این کار جدول را در رابط آمادهسازی دادهها باز میکند و آماده است تا تبدیل دادههای خود را آغاز کنید.
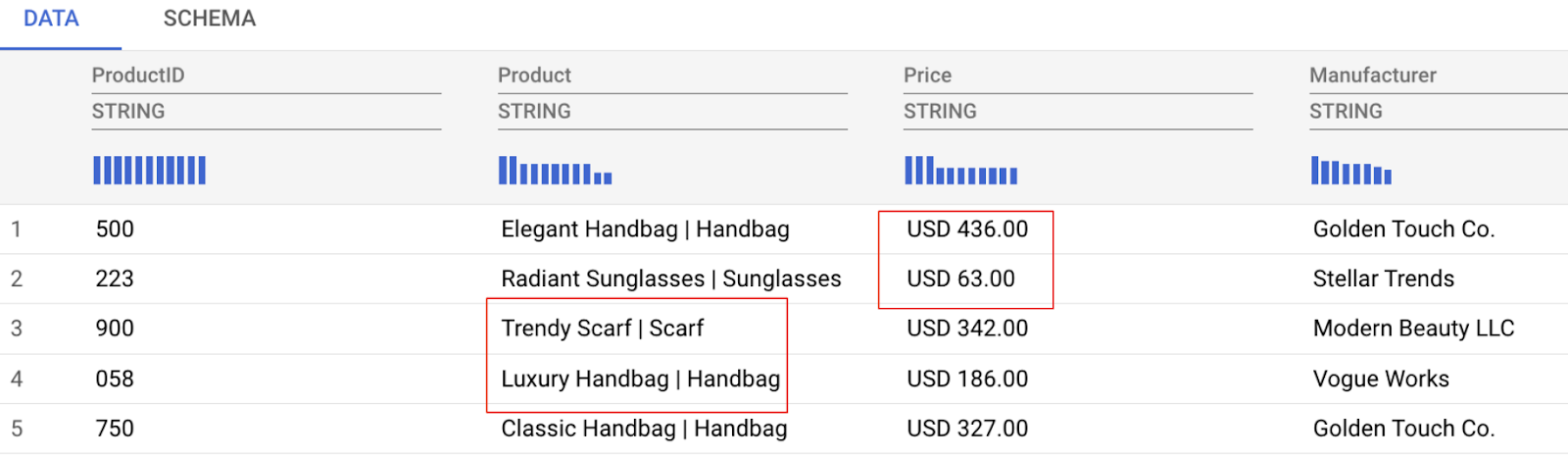
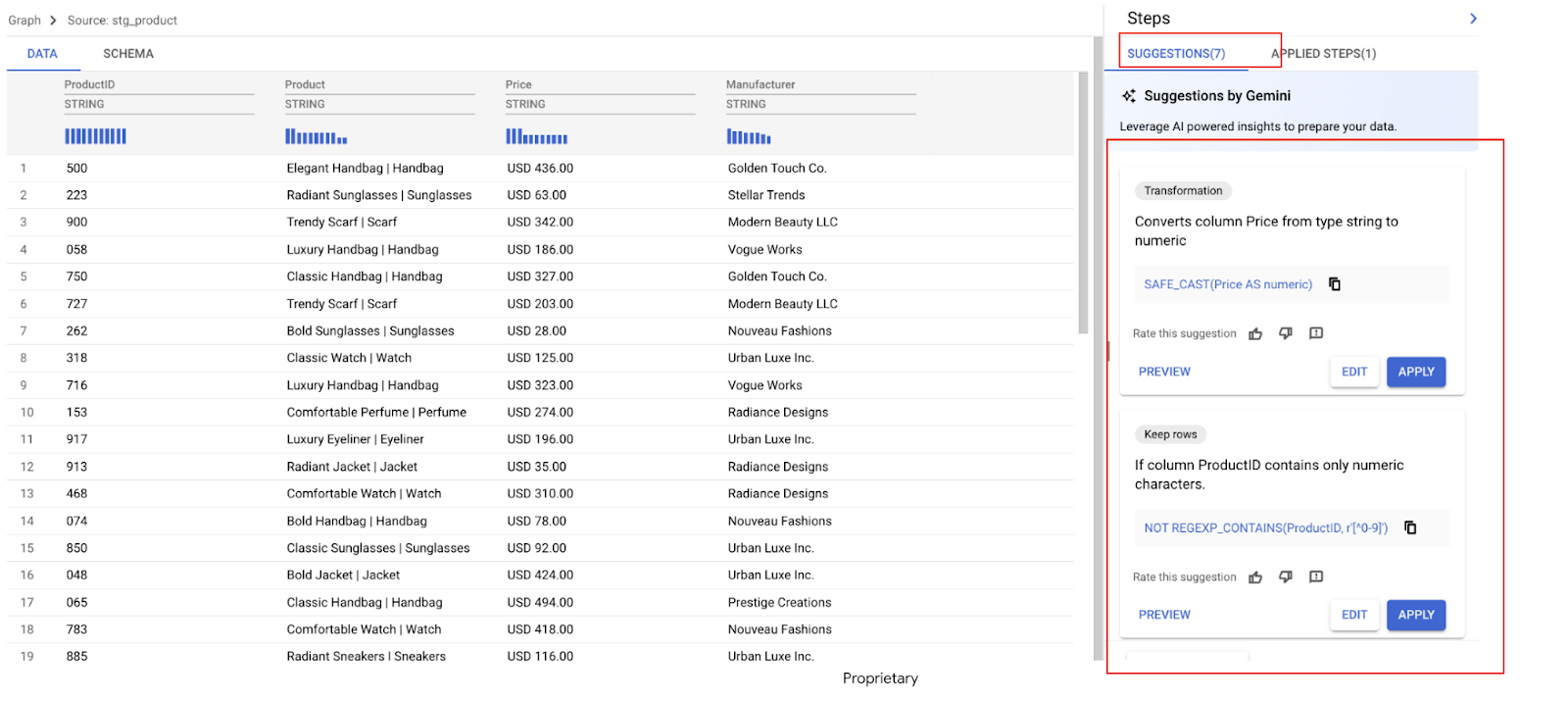
همانطور که در پیشنمایش دادهها در زیر مشاهده میکنید، ما با برخی چالشهای دادهای روبرو هستیم که به آنها خواهیم پرداخت، از جمله:
- ستون قیمت شامل مبلغ و واحد پول است که تحلیل را دشوار میکند.
- ستون محصول، نام محصول و دستهبندی آن را (که با نماد | از هم جدا شدهاند) با هم ترکیب میکند.
بلافاصله، Gemini دادههای شما را تجزیه و تحلیل میکند و چندین تبدیل پیشنهاد میدهد. در این مثال، تعدادی توصیه میبینیم. در مراحل بعدی، مواردی را که نیاز داریم اعمال خواهیم کرد.
۶. مدیریت ستون قیمت
بیایید به ستون قیمت بپردازیم. همانطور که دیدیم، این ستون شامل هر دو گزینه ارز و مبلغ است. هدف ما این است که این دو را در دو ستون مجزا قرار دهیم: ارز و مبلغ .
جمینی چندین توصیه برای ستون قیمت شناسایی کرده است.
- توصیهای پیدا کنید که چیزی شبیه به این بگوید:
شرح: «این عبارت، 'USD' را از ابتدای فیلد مشخصشده حذف میکند.»
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- پیشنمایش را انتخاب کنید

- انتخاب کنید اعمال شود
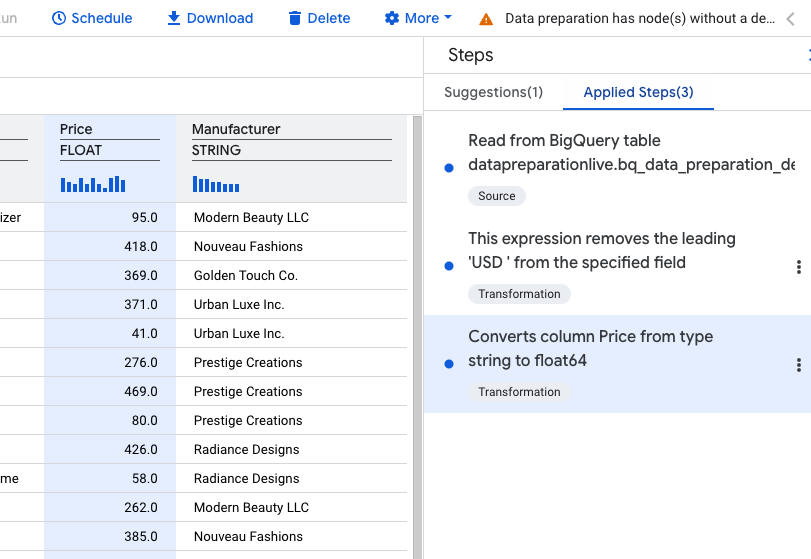
در مرحله بعد، برای ستون Price ، نوع داده را از STRING به NUMERIC تبدیل میکنیم.
- توصیهای پیدا کنید که چیزی شبیه به این بگوید:
توضیحات: "قیمت ستون را از نوع رشته به float64 تبدیل میکند"
SAFE_CAST(Price AS float64)
- اعمال را انتخاب کنید.
اکنون باید سه مرحله اعمال شده را در لیست مراحل خود مشاهده کنید.
۷. مدیریت ستون محصول
ستون محصول شامل نام محصول و دستهبندی آن است که با یک خط عمودی (|) از هم جدا شدهاند.
در حالی که میتوانیم دوباره از زبان طبیعی استفاده کنیم، بیایید یکی دیگر از ویژگیهای قدرتمند جمینی را بررسی کنیم.
نام محصول را اصلاح کنید
- بخش دستهبندی یک محصول شامل کاراکتر
|را انتخاب کرده و آن را حذف کنید.
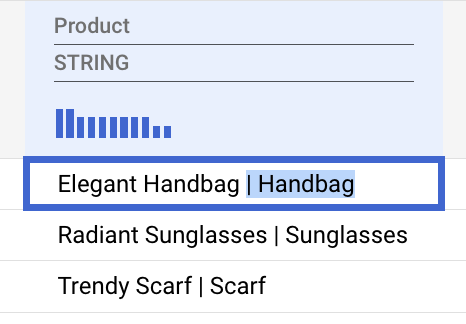
جمینی هوشمندانه این الگو را تشخیص میدهد و تبدیلی را برای اعمال روی کل ستون پیشنهاد میدهد.
- «ویرایش» را انتخاب کنید.
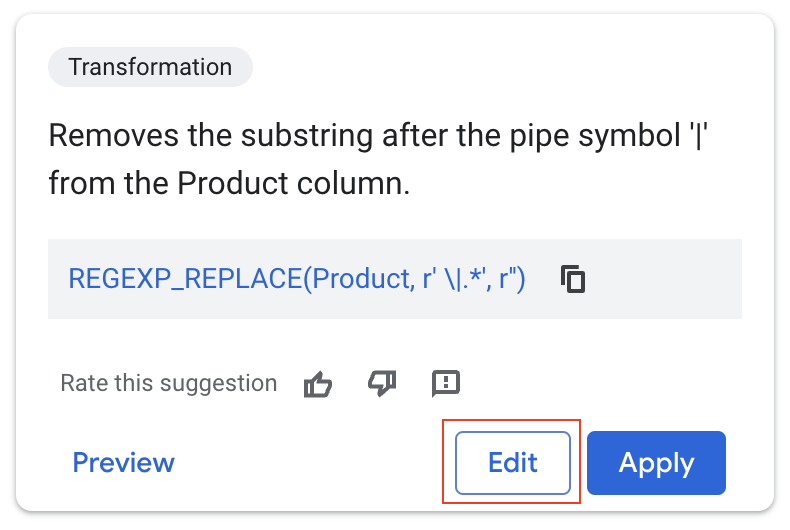
توصیهی Gemini کاملاً درست است: هر چیزی را که بعد از کاراکتر '|' قرار دارد حذف میکند و عملاً نام محصول را ایزوله میکند.
اما این بار نمیخواهیم دادههای اصلی خود را بازنویسی کنیم.
- در منوی کشویی ستون هدف، گزینه «ایجاد ستون جدید» را انتخاب کنید.
- نام را روی ProductName تنظیم کنید.
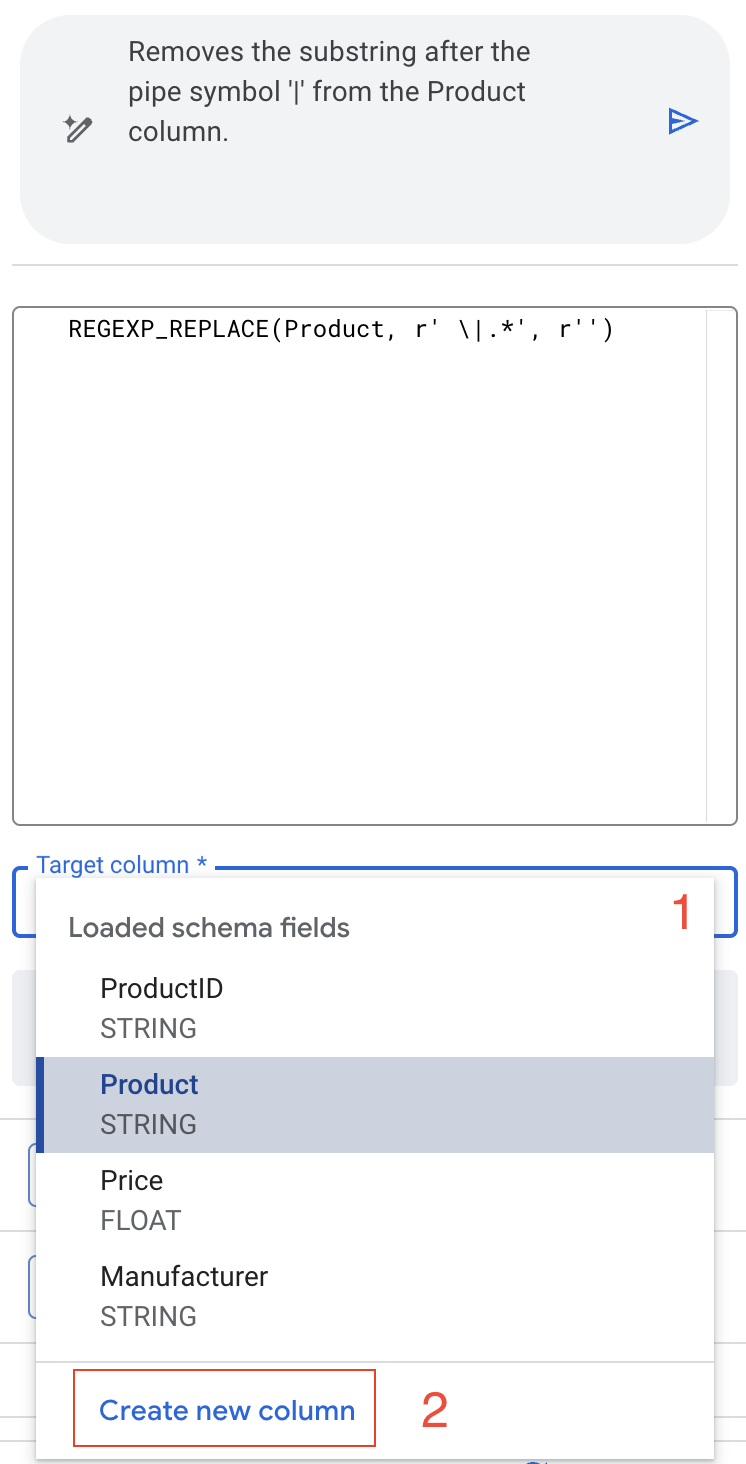
- پیشنمایش تغییرات را ببینید تا مطمئن شوید همه چیز خوب به نظر میرسد.
- تبدیل را اعمال کنید.
استخراج دسته بندی محصولات
با استفاده از زبان طبیعی، به Gemini دستور میدهیم که کلمه بعد از علامت پایپ (|) را در ستون Product استخراج کند. این مقدار استخراج شده در ستون موجود به نام Product بازنویسی خواهد شد.
- برای افزودن یک مرحله تبدیل جدید، روی
Add Stepکلیک کنید.
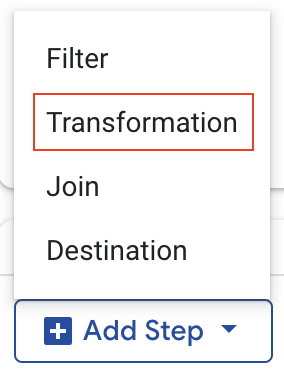
- از منوی کشویی،
Transformationرا انتخاب کنید. - در فیلد اعلان زبان طبیعی، عبارت «کلمه بعد از علامت عمودی (|) را در ستون محصول استخراج کنید» را وارد کنید. سپس برای تولید SQL، دکمه return را فشار دهید .
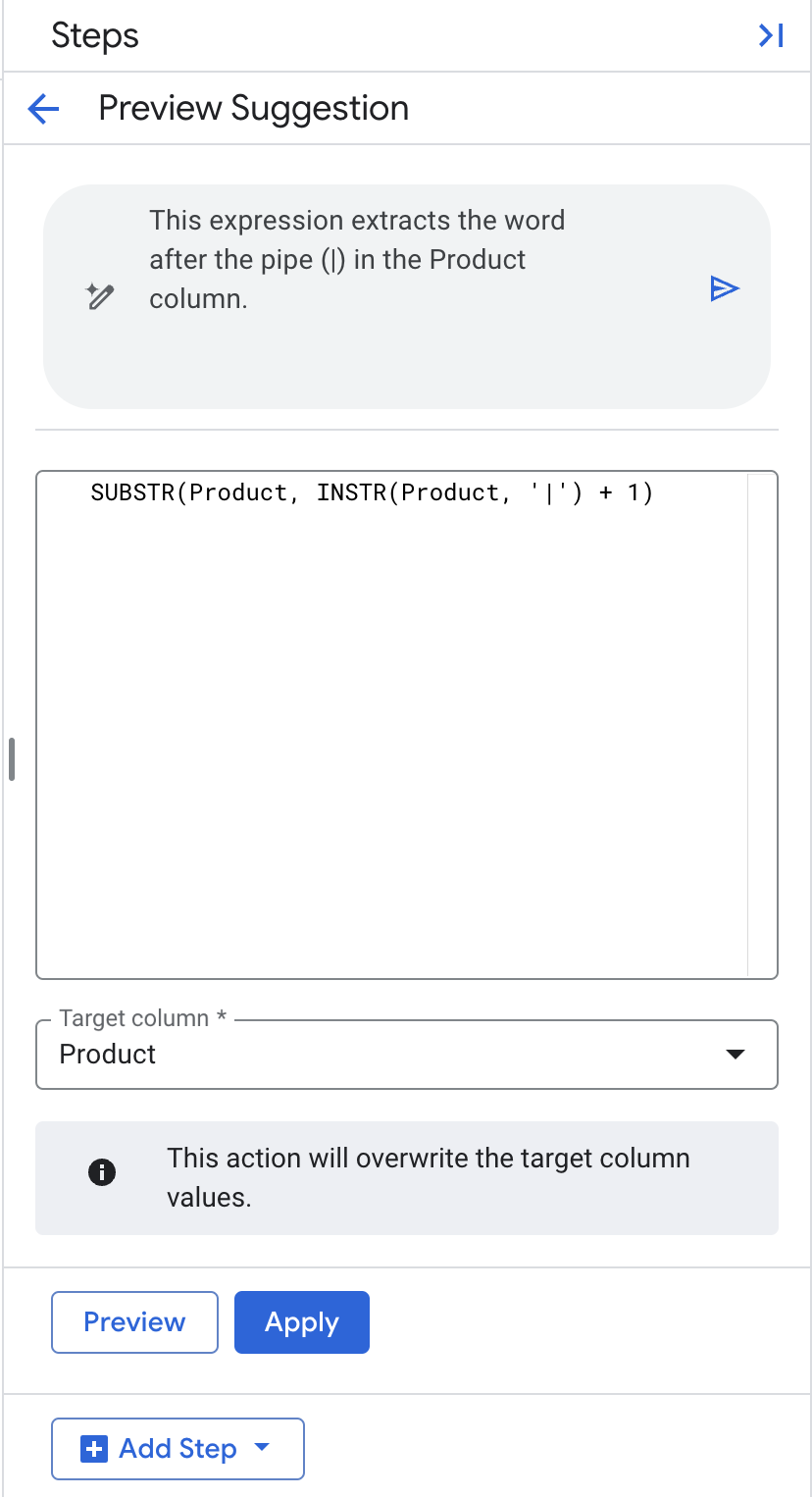
- ستون هدف را به همان صورت "محصول" باقی بگذارید.
- روی اعمال کلیک کنید.
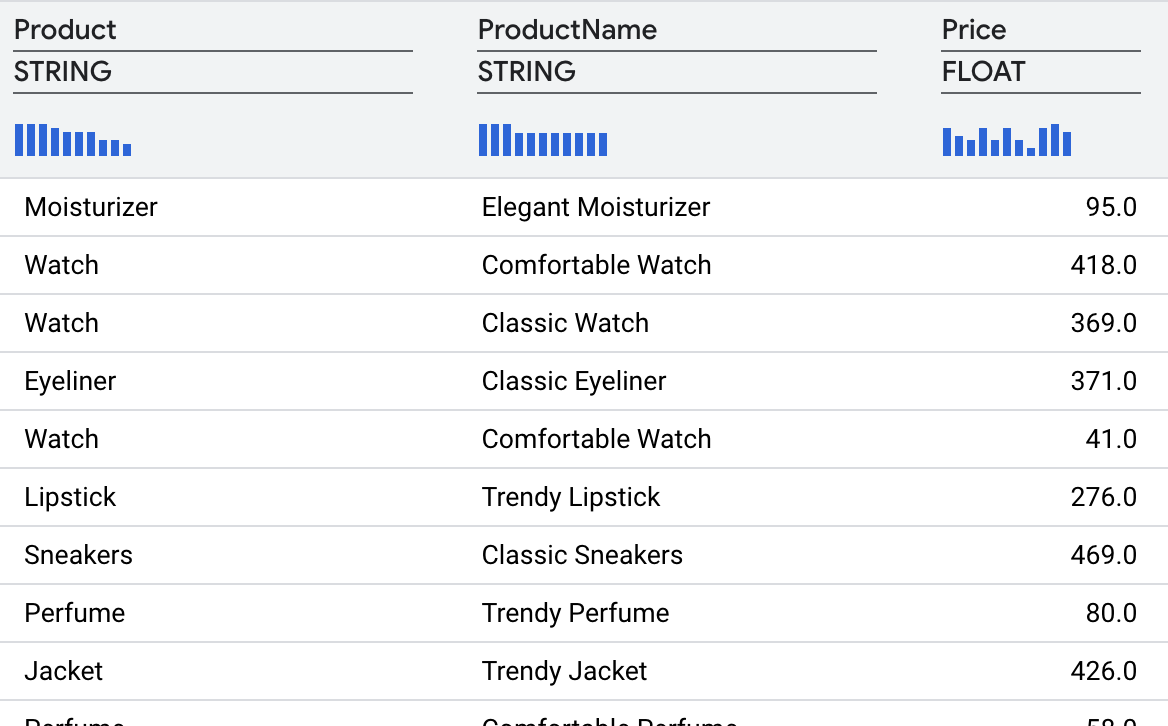
این تبدیل باید نتایج زیر را به شما بدهد.
۸. اتصال برای غنیسازی دادهها
اغلب، شما میخواهید دادههای خود را با اطلاعات منابع دیگر غنی کنید. در مثال ما، دادههای محصول خود را با ویژگیهای توسعهیافته محصول، stg_extended_product ، از یک جدول شخص ثالث، ادغام میکنیم. این جدول شامل جزئیاتی مانند برند و تاریخ عرضه است.
- روی
Add Stepکلیک کنید - انتخاب کنید
Join - به جدول
stg_extended_productبروید.

Gemini در BigQuery به طور خودکار کلید اتصال productid را برای ما انتخاب کرد و سمت چپ و راست را از آنجایی که نام کلید یکسان است، واجد شرایط کرد.
نکته: مطمئن شوید که فیلد توضیحات عبارت «Join by productid» را نشان میدهد. اگر شامل کلیدهای اتصال اضافی است، فیلد توضیحات را به «Join by productid» بازنویسی کنید و دکمه تولید را در فیلد توضیحات انتخاب کنید تا عبارت اتصال با شرط L دوباره تولید شود.
productid
= ر.
productid 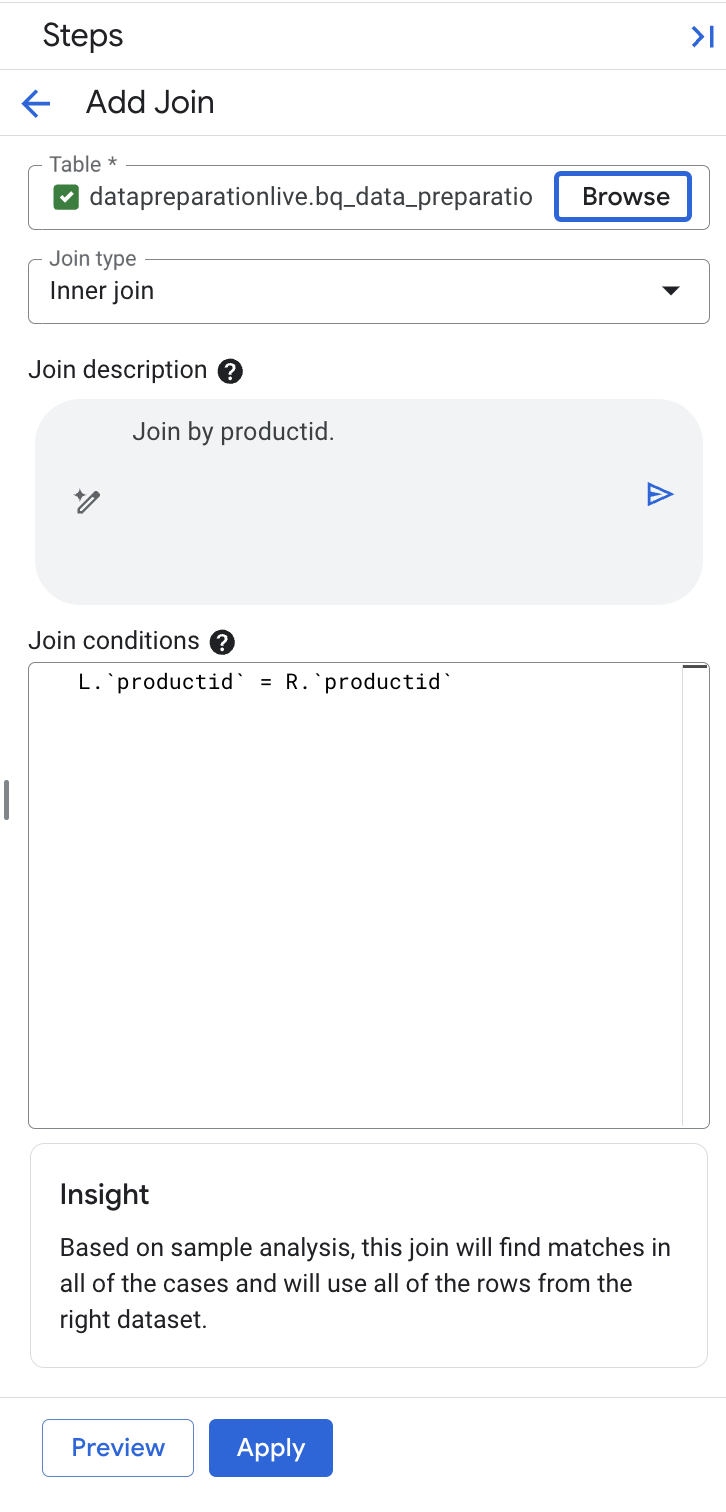
- در صورت تمایل، برای پیشنمایش نتایج، پیشنمایش را انتخاب کنید.
-
Applyکلیک کنید.
پاکسازی ویژگیهای توسعهیافته
اگرچه اتصال موفقیتآمیز بود، دادههای ویژگیهای توسعهیافته نیاز به کمی پاکسازی دارند. ستون LaunchDate فرمتهای تاریخ ناسازگاری دارد و ستون Brand حاوی برخی مقادیر از دست رفته است.
ما با پرداختن به ستون LaunchDate شروع خواهیم کرد.

قبل از ایجاد هرگونه تغییر شکل، توصیههای Gemini را بررسی کنید.
- روی نام ستون
LaunchDateکلیک کنید. باید برخی از توصیههای تولید شده مشابه موارد موجود در تصویر زیر را ببینید.
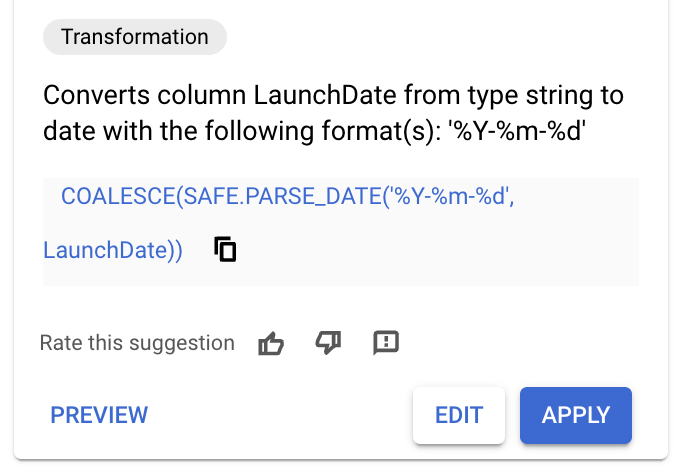
- اگر توصیهای با SQL زیر مشاهده کردید، آن توصیه را اعمال کنید و مراحل بعدی را رد کنید.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- اگر توصیهای مطابق با SQL بالا نمیبینید، روی
Add Stepکلیک کنید. -
Transformationانتخاب کنید. - در قسمت SQL، عبارت زیر را وارد کنید:
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
-
Target ColumnsرویLaunchDateتنظیم کنید. -
Applyکلیک کنید.
ستون LaunchDate اکنون فرمت تاریخ ثابتی دارد.

۹. افزودن جدول مقصد
مجموعه داده ما اکنون تمیز و آماده بارگذاری در جدول ابعاد در انبار داده ما است.
- روی
ADD STEPکلیک کنید. -
Destinationرا انتخاب کنید. - پارامترهای مورد نیاز را وارد کنید: مجموعه داده:
bq_data_preparation_demoجدول:DimProduct - روی
Saveکلیک کنید.

ما اکنون با تبهای «داده» و «طرحواره» کار کردهایم. علاوه بر اینها، BigQuery Data Preparation یک نمای «نمودار» ارائه میدهد که توالی مراحل تبدیل را در خط لوله شما به صورت بصری نمایش میدهد.

۱۰. نکتهی اضافهی الف: مدیریت ستون تولیدکننده و ایجاد جدول خطا
ما همچنین مقادیر خالی را در ستون Manufacturer شناسایی کردهایم. برای این رکوردها، میخواهیم یک بررسی کیفیت داده پیادهسازی کنیم و آنها را برای بررسی بیشتر به یک جدول خطا منتقل کنیم.
ایجاد جدول خطا
- روی دکمهی
Moreکنار عنوانstg_product data preparationکلیک کنید. - در بخش
Setting،Error Tableرا انتخاب کنید. - کادر
Enable error tableعلامت بزنید، تنظیمات را به صورت زیر پیکربندی کنید:
- مجموعه داده: انتخاب کنید
bq_data_preparation_demo - جدول:
err_dataprepرا وارد کنید - در قسمت
Define duration for keeping errors،30 days (default)
- روی
Saveکلیک کنید.

اعتبارسنجی را روی ستون تولیدکننده تنظیم کنید
- ستون تولیدکننده را انتخاب کنید.
- Gemini احتمالاً یک تبدیل مرتبط را شناسایی کرده است. توصیهای را پیدا کنید که فقط ردیفهایی را نگه میدارد که فیلد Manufacturer خالی نیست. SQL آن مشابه زیر خواهد بود:
Manufacturer IS NOT NULL
۲. برای بررسی این توصیه، روی دکمه «ویرایش» کلیک کنید.
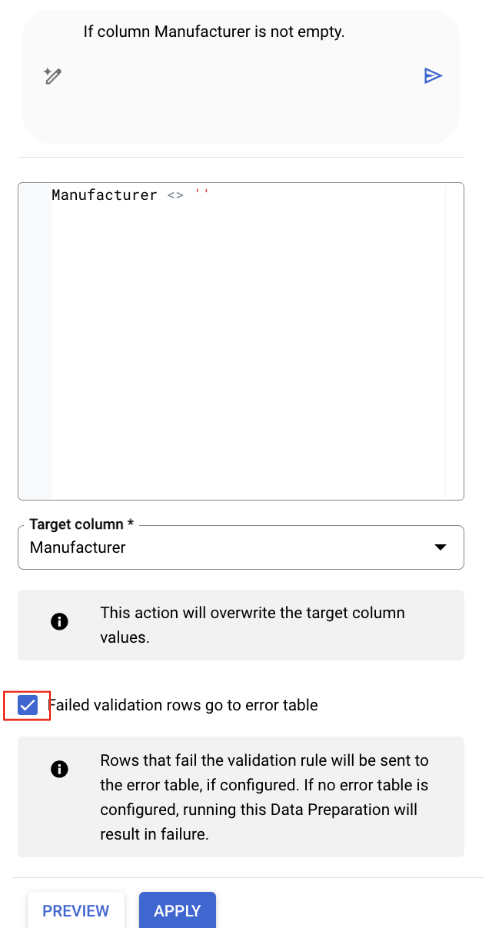
- اگر گزینهی «ردیفهای اعتبارسنجی ناموفق به جدول خطا میروند» تیک نخورده است، آن را علامت بزنید.
-
Applyکلیک کنید.
در هر مرحله، میتوانید با کلیک بر روی دکمهی «مراحل اعمال شده»، تبدیلهایی را که اعمال کردهاید، مرور، اصلاح یا حذف کنید.

ستون اضافی ProductID_1 را پاک کنید
ستون ProductID_1 که شناسه محصول را از جدول پیوند داده شده ما کپی میکند، اکنون میتواند حذف شود.
- به برگه
Schemaبروید - روی سه نقطه کنار ستون
ProductID_1کلیک کنید. - روی
Dropکلیک کنید.
اکنون آماده اجرای کار آمادهسازی دادهها و اعتبارسنجی کل خط لوله خود هستیم. هنگامی که از نتایج راضی بودیم، میتوانیم کار را برای اجرای خودکار برنامهریزی کنیم.
- قبل از خروج از نمای آمادهسازی دادهها، آمادهسازیهای خود را ذخیره کنید. در کنار عنوان
stg_product data preparation، باید دکمهSaveرا ببینید. برای ذخیره، روی دکمه کلیک کنید.
۱۱. محیط را تمیز کنید
-
stg_product data preparationرا حذف کنید - مجموعه دادههای
bq data preparation demoرا حذف کنید
۱۲. تبریک
تبریک میگویم که آزمایشگاه کد را تمام کردی.
آنچه ما پوشش دادهایم
- تنظیم آمادهسازی دادهها
- باز کردن جداول و پیمایش آمادهسازی دادهها
- تقسیم ستونها با دادههای عددی و توصیفگر واحد
- استانداردسازی قالبهای تاریخ
- اجرای آمادهسازی دادهها