
1. はじめに
コーディングの専門家でなくても、データをより迅速かつ効率的に分析の準備ができることを想像してみてください。BigQuery Data Preparation を使用すると、それが実現します。この強力な機能により、データの取り込み、変換、クレンジングが簡素化され、組織内のすべてのデータ担当者がデータ準備を行えるようになります。
商品データに隠された秘密を解き明かしましょう。
前提条件
- Google Cloud コンソールの基本的な知識
- SQL の基本的な知識
学習内容
- BigQuery のデータ準備で、ファッション業界と美容業界の現実的な例を使用して、未加工データをクリーンアップして、実用的なビジネス インテリジェンスに変換する方法。
- クリーンアップしたデータのデータ準備を実行してスケジュールする方法
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
2. 基本的な設定と要件
セルフペース型の環境設定
- Google Cloud コンソールにログインして、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

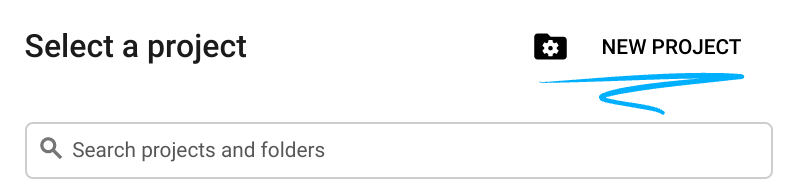
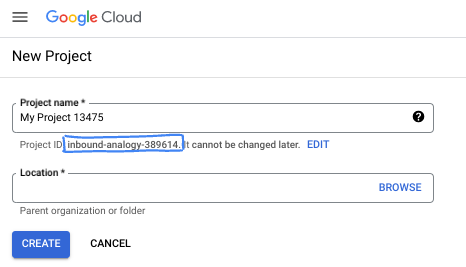
- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
3. はじめに
API を有効にする
Gemini in BigQuery を使用するには、Gemini for Google Cloud API を有効にする必要があります。通常、この手順は、serviceusage.services.enable IAM 権限を持つサービス管理者またはプロジェクト オーナーが行います。
- Gemini for Google Cloud API を有効にするには、Google Cloud Marketplace の [Gemini for Google Cloud] ページに移動します。[Gemini for Google Cloud] に移動
- プロジェクト セレクタで、プロジェクトを選択します。
- [有効にする] をクリックします。ページが更新され、[有効] のステータスが表示されます。これで、必要な IAM 権限を持つすべてのユーザーが、選択した Google Cloud プロジェクトで Gemini in BigQuery を使用できるようになりました。
データ準備を開発するためのロールと権限を設定する
- [IAM と管理] で [IAM] を選択します。
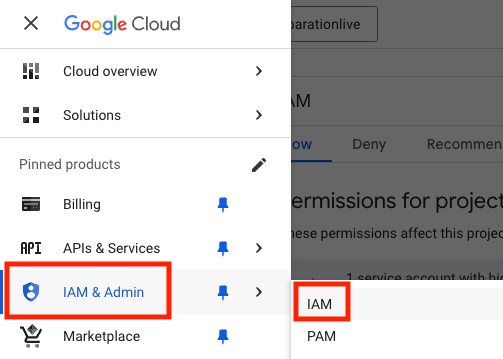
- ユーザーを選択し、鉛筆アイコンをクリックして [プリンシパルを編集] を行います。
BigQuery データ準備を使用するには、次のロールと権限が必要です。
- BigQuery データ編集者 (roles/bigquery.dataEditor)
- Service Usage ユーザー (roles/serviceusage.serviceUsageConsumer)
4. BigQuery Analytics Hub で「bq data preparation demo」リスティングを見つけてサブスクライブする
このチュートリアルでは、bq data preparation demo データセットを使用します。これは、読み取り元の BigQuery Analytics Hub のリンクされたデータセットです。
データ準備では、ソースに書き戻すことはありません。書き込み先のテーブルを定義する必要があります。この演習で使用するテーブルには 1,000 行しかありません。これは、費用を最小限に抑えるためです。ただし、データ準備は BigQuery で実行され、それに合わせてスケーリングされます。
リンクされたデータセットを見つけて登録する手順は次のとおりです。
- Analytics Hub にアクセスする: Google Cloud コンソールで、BigQuery に移動します。
- BigQuery のナビゲーション メニューで、[ガバナンス] の [Analytics Hub] を選択します。
- リスティングを検索する: Analytics Hub UI で、[リスティングを検索] をクリックします。
- 検索バーに「
bq data preparation demo」と入力して、Enter キーを押します。
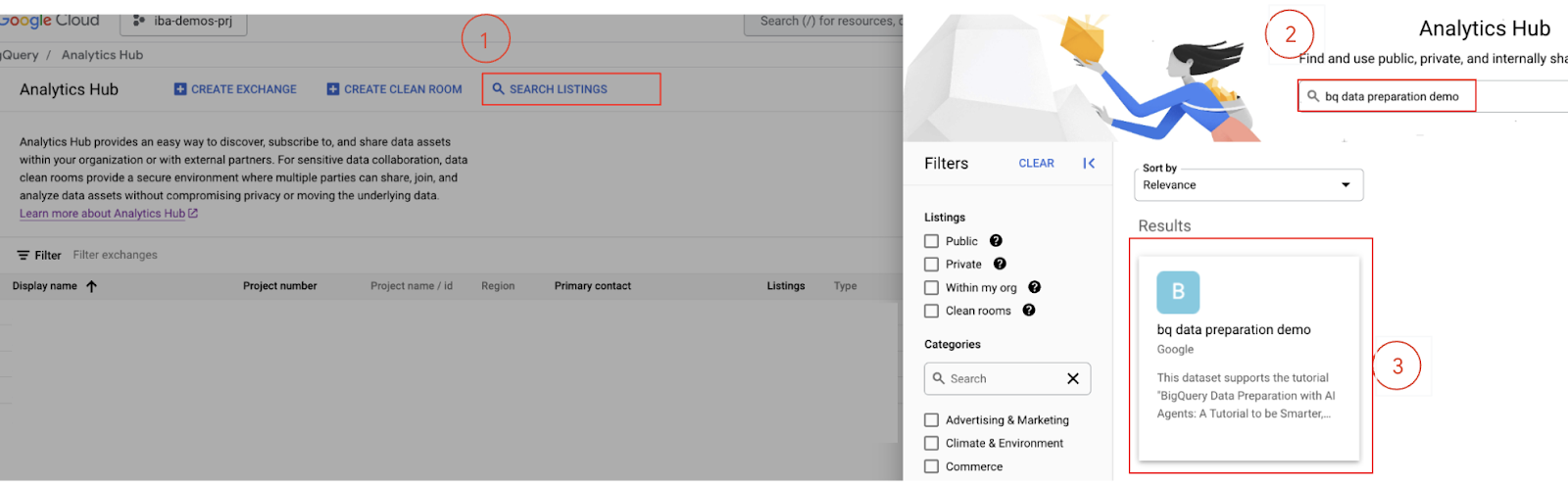
- リスティングに登録する: 検索結果から
bq data preparation demoリスティングを選択します。 - リスティングの詳細ページで、[登録] ボタンをクリックします。
- 確認ダイアログを確認し、必要に応じてプロジェクト/データセットを更新します。デフォルト値はそのまま使用できるはずです。

- BigQuery でデータセットにアクセスする: サブスクリプションが完了すると、リスティング内のデータセットが BigQuery プロジェクトにリンクされます。
BigQuery Studio に戻ります。
5. データを探索してデータ準備を開始する
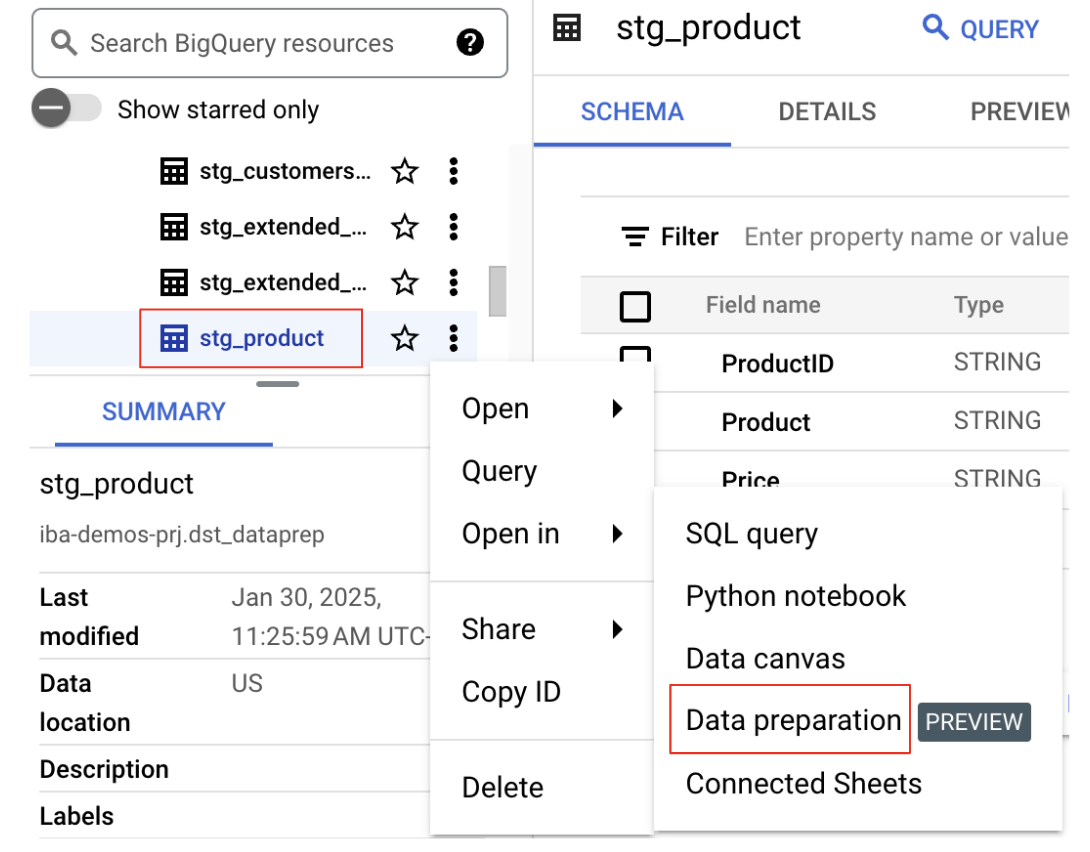
- データセットとテーブルを見つける: [エクスプローラ] パネルでプロジェクトを選択し、
bq data preparation demoリストに含まれていたデータセットを見つけます。stg_productテーブルを選択します。 - データ準備で開く: テーブル名の横にあるその他アイコンをクリックし、
Open in Data Preparationを選択します。
これにより、データ準備インターフェースでテーブルが開き、データの変換を開始する準備が整います。
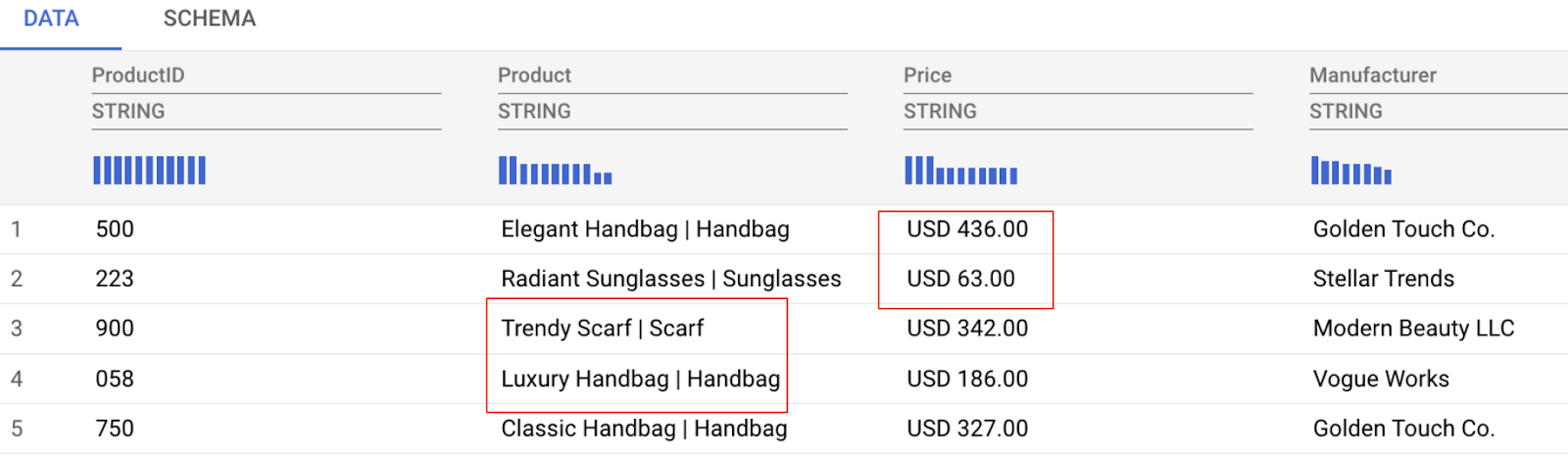
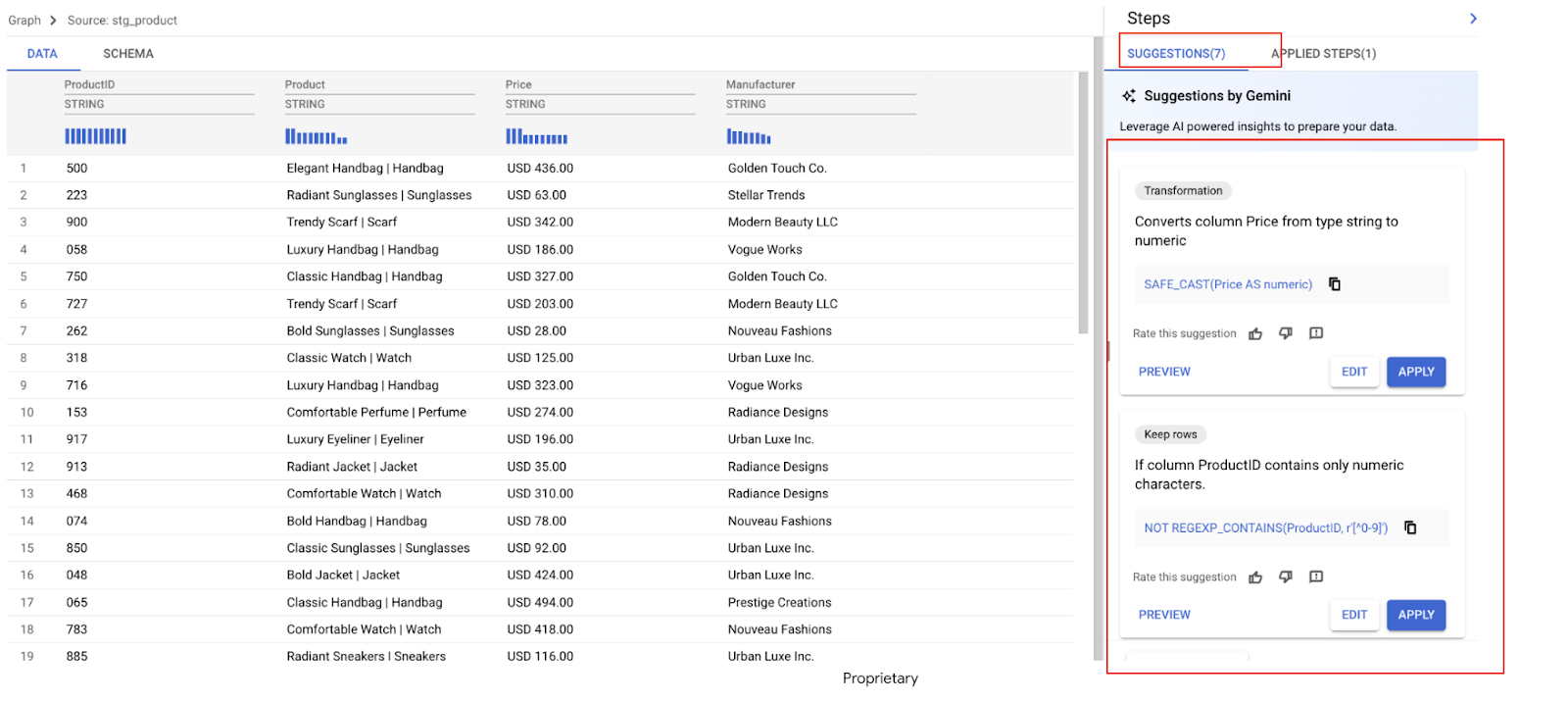
下のデータ プレビューでわかるように、次のようなデータに関する課題があります。
- 価格列に金額と通貨の両方が含まれているため、分析が困難です。
- 商品列には、商品名とカテゴリが混在しています(パイプ記号 | で区切られています)。
Gemini はすぐにデータを分析し、いくつかの変換を提案します。この例では、複数の推奨事項が表示されています。次のステップでは、必要なものを適用します。
6. 価格列の処理
[Price] 列に取り組みましょう。ご覧のとおり、通貨と金額の両方が含まれています。目標は、これらを通貨と金額の 2 つの異なる列に分割することです。
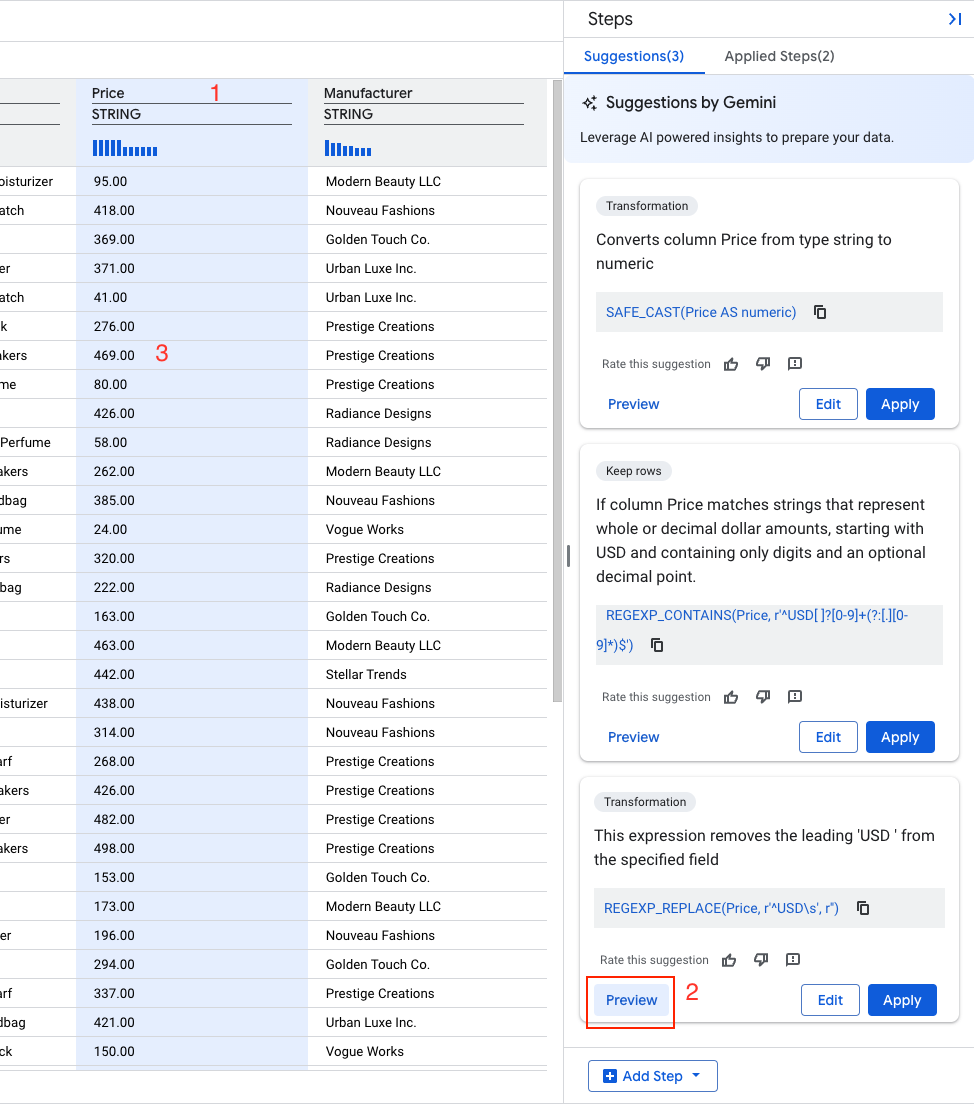
Gemini は、[Price] 列に対していくつかの推奨事項を特定しました。
- 次のような推奨事項を探します。
説明: 「この式は、指定されたフィールドから先頭の「USD 」を削除します」
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- [プレビュー] を選択します
- [適用] を選択します。
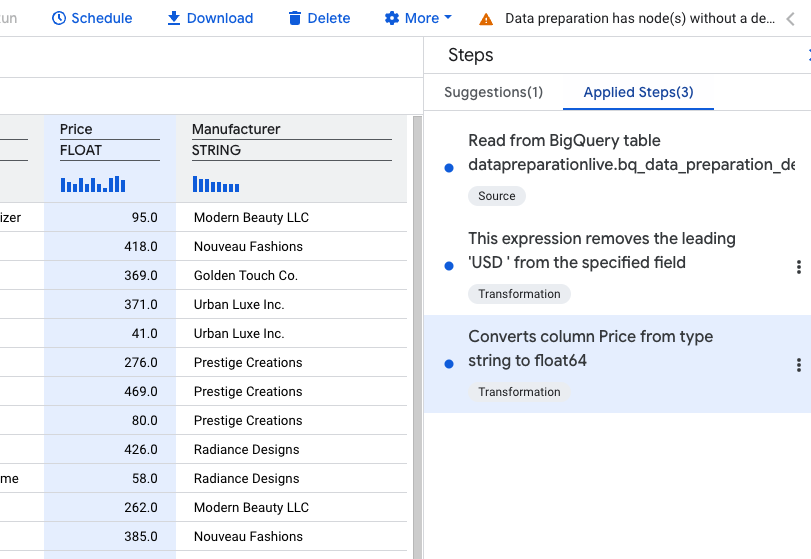
次に、Price 列のデータ型を STRING から NUMERIC に変換します。
- 次のような推奨事項を探します。
説明: 「列 Price の型を文字列から float64 に変換します」
SAFE_CAST(Price AS float64)
- [適用] を選択します。
ステップリストに 3 つの適用済みステップが表示されます。
7. 商品列の処理
商品列には、商品名とカテゴリの両方が含まれており、パイプ(|)で区切られています。
ここでも自然言語を使用できますが、Gemini のもう一つの強力な機能を見てみましょう。
商品名をクリーンアップする
|文字を含む商品エントリのカテゴリ部分を選択して削除します。
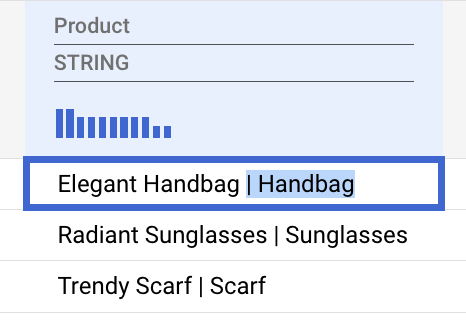
Gemini はこのパターンをインテリジェントに認識し、列全体に適用する変換を提案します。
- [編集] を選択します。
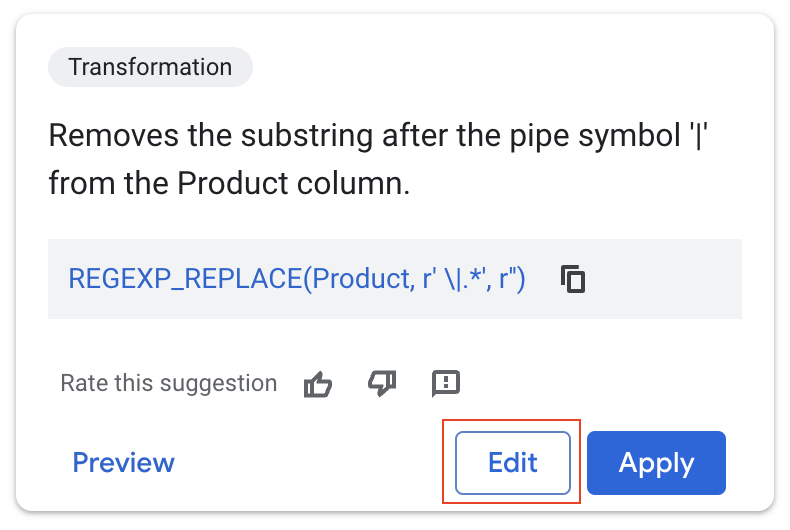
Gemini の推奨事項は的確です。「|」文字の後のすべてを削除し、商品名を効果的に分離します。
今回は元のデータを上書きしないようにします。
- [ターゲット列] プルダウンで、[新しい列を作成] を選択します。
- 名前を ProductName に設定します。

- 変更内容をプレビューして、すべてが正しく表示されていることを確認します。
- 変換を適用します。
商品カテゴリを抽出する
自然言語を使用して、Gemini に [Product] 列のパイプ(|)の後の単語を抽出するよう指示します。抽出された値は、商品という既存の列に上書きされます。
Add Stepをクリックして、新しい変換ステップを追加します。
- プルダウン メニューから [
Transformation] を選択します。 - 自然言語プロンプト フィールドに「Product 列のパイプ(|)の後の単語を抽出します」と入力し、Return キーを押して SQL を生成します。
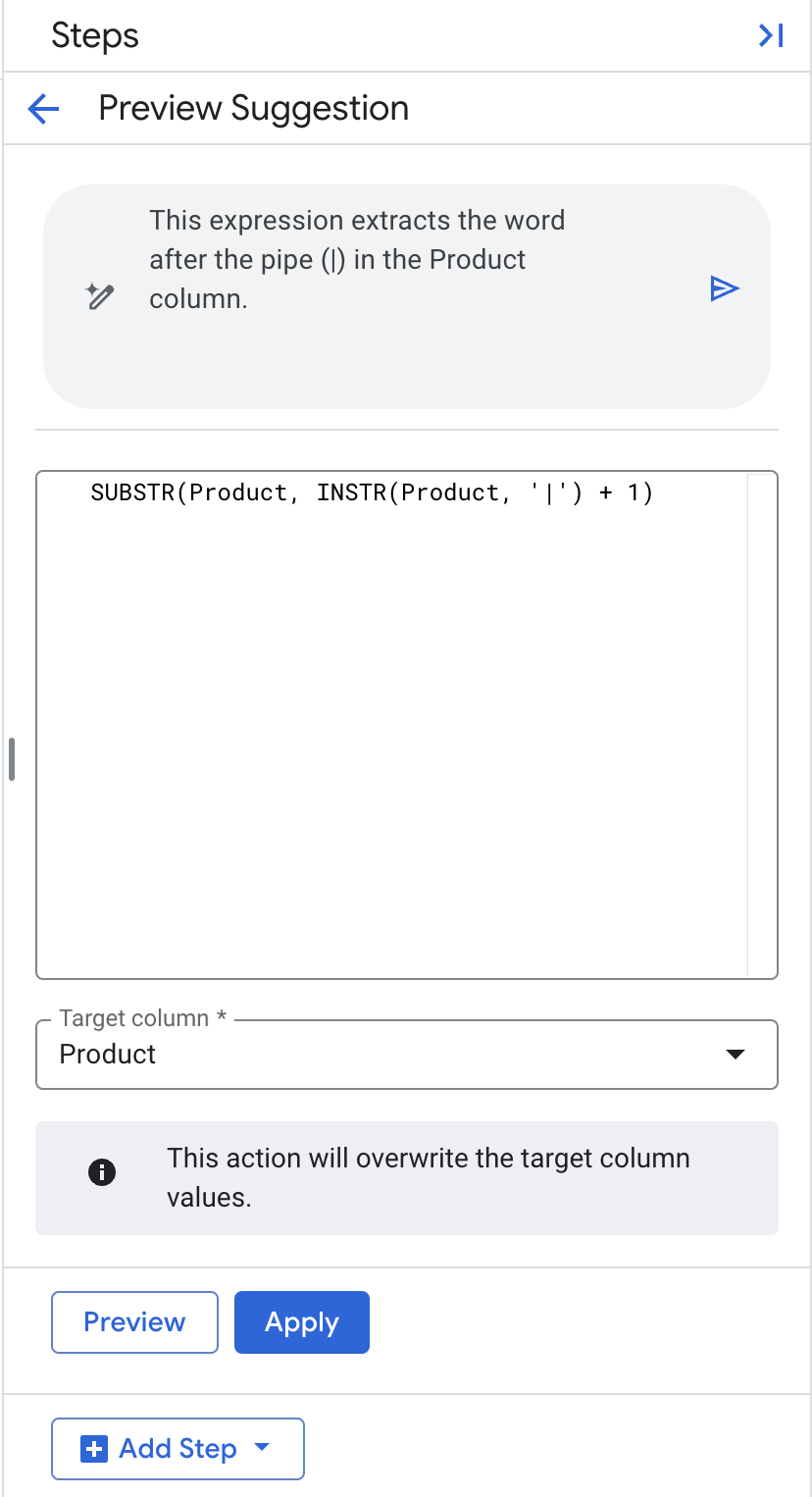
- [ターゲット列] は [商品] のままにします。
- [適用] をクリックします。
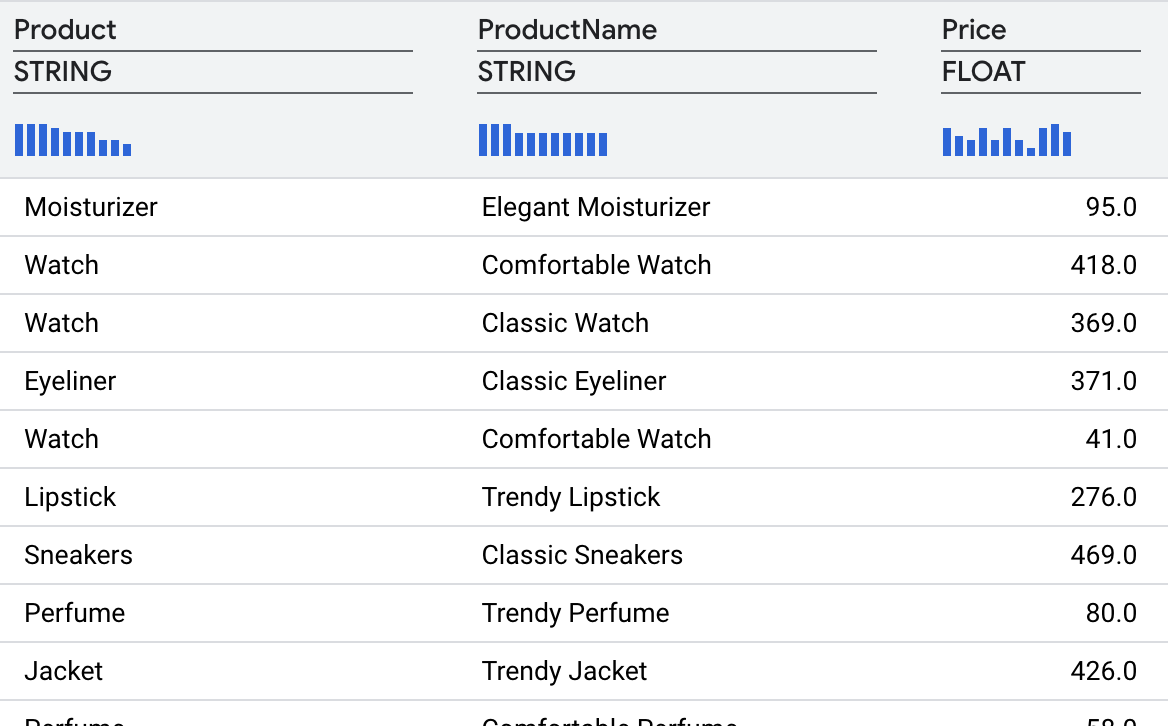
変換を行うと、次の結果が得られます。
8. 結合してデータを拡充する
多くの場合、他のソースからの情報でデータを拡充する必要があります。この例では、商品データをサードパーティのテーブルから取得した拡張商品属性 stg_extended_product と結合します。この表には、ブランドやリリース日などの詳細が含まれています。
Add Stepをクリックします。- 「
Join」を選択する stg_extended_productテーブルを参照します。

Gemini in BigQuery は、productid 結合キーを自動的に選択し、キー名が同じであるため、左側と右側を修飾しました。
注: 説明フィールドに「Join by productid」と表示されていることを確認します。追加の結合キーが含まれている場合は、説明フィールドを「Join by productid」に上書きし、説明フィールドの生成ボタンを選択して、次の条件 L. で結合式を再生成します。
productid
= R.
productid。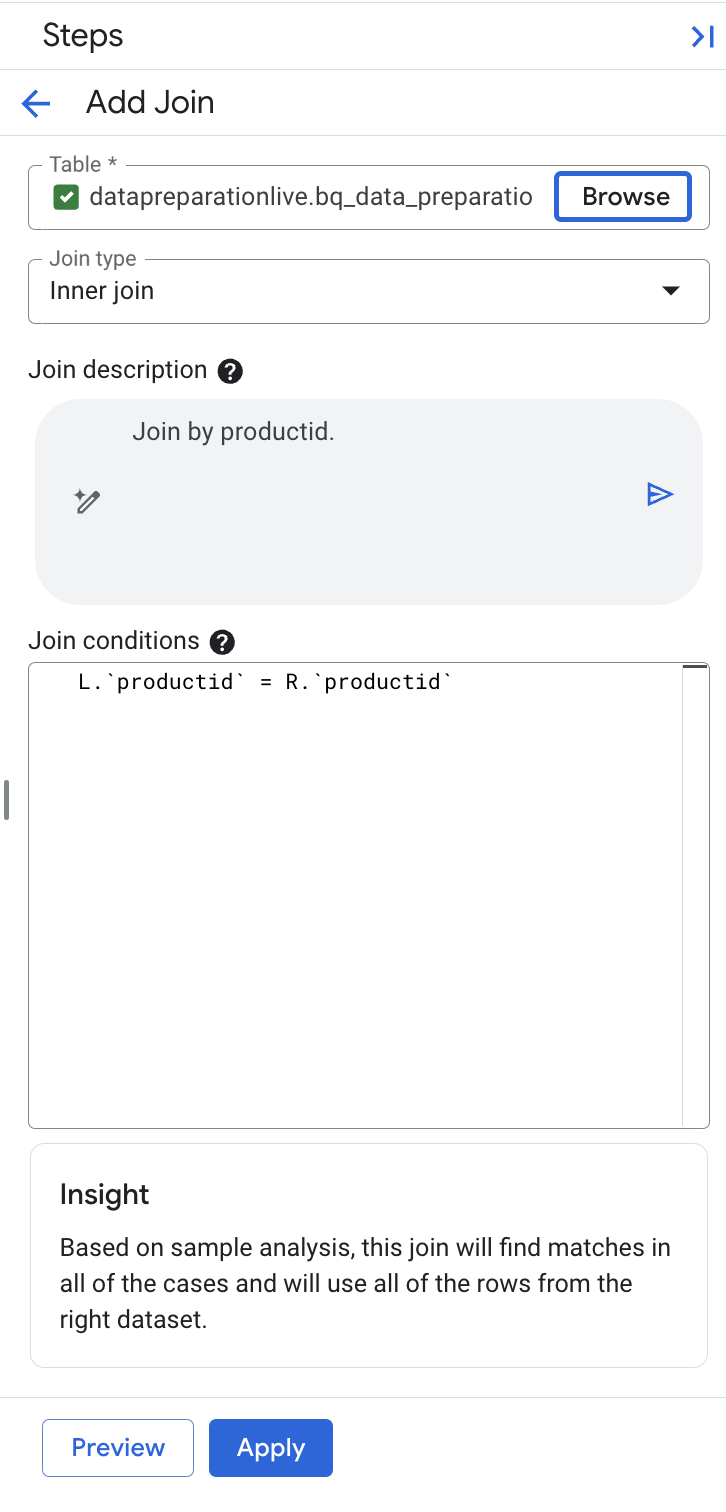
- 必要に応じて、[プレビュー] を選択して結果をプレビューします。
Applyをクリックします。
拡張属性のクリーンアップ
結合は成功しましたが、拡張属性データにはクリーンアップが必要です。LaunchDate 列の日付形式に一貫性がなく、Brand 列には欠損値が含まれています。
まず、LaunchDate 列から処理します。

変換を作成する前に、Gemini の推奨事項を確認します。
- [
LaunchDate] 列の名前をクリックします。次の画像のような推奨事項が表示されます。
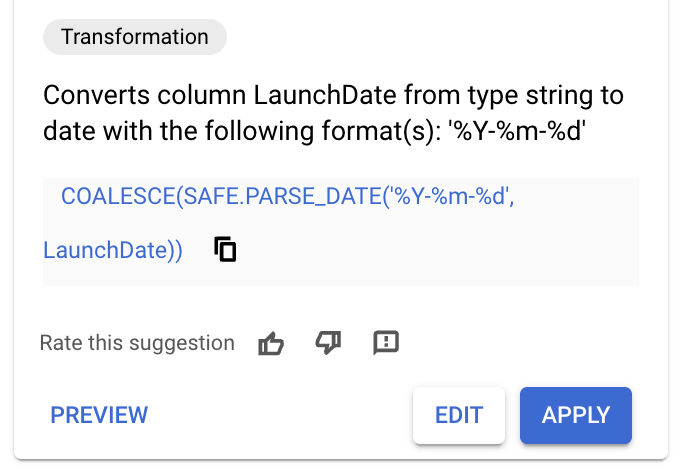
- 次の SQL を含む推奨事項が表示された場合は、推奨事項を適用して、次の手順をスキップします。
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- 上記の SQL に一致する推奨事項が表示されない場合は、
Add Stepをクリックします。 Transformationを選択します。- [SQL] フィールドに、次のように入力します。
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
Target ColumnsをLaunchDateに設定します。Applyをクリックします。
LaunchDate 列の日付形式が統一されました。

9. 宛先テーブルを追加する
これでデータセットがクリーンになり、データ ウェアハウスのディメンション テーブルに読み込む準備が整いました。
ADD STEPをクリックします。Destinationを選択します。- 必須パラメータ(データセット:
bq_data_preparation_demo、テーブル:DimProduct)を入力します。 Saveをクリックします。

これで、[データ] タブと [スキーマ] タブの操作は完了です。このほか、BigQuery Data Preparation には、パイプライン内の変換ステップのシーケンスを視覚的に表示する「グラフ」ビューが用意されています。

10. ボーナス A: [Manufacturer] 列の処理とエラー テーブルの作成
また、Manufacturer 列に空の値があることも確認しました。これらのレコードに対してデータ品質チェックを実施し、エラー テーブルに移動してさらに確認します。
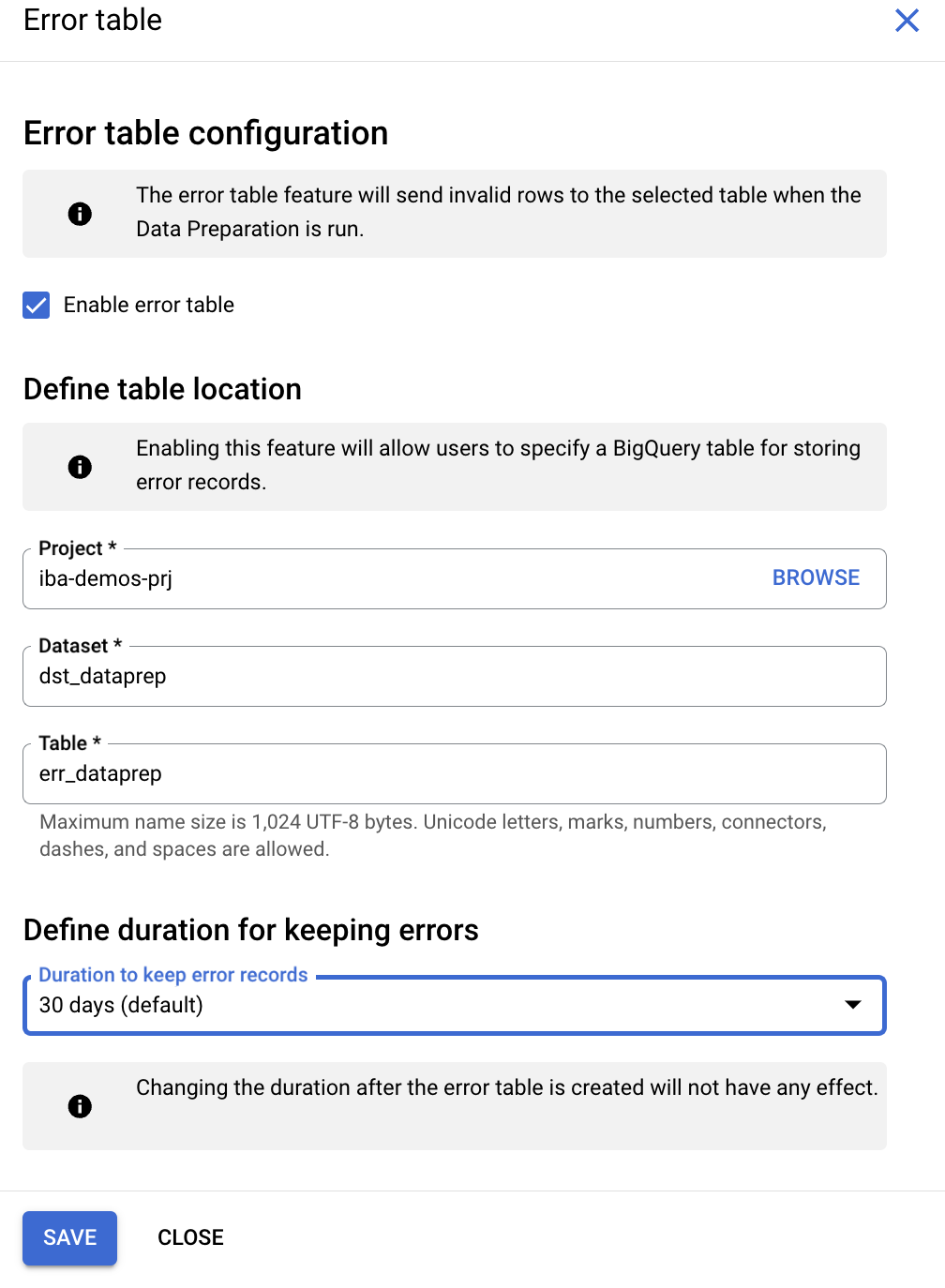
エラーテーブルを作成する
stg_product data preparationタイトルの横にあるMoreボタンをクリックします。- [
Setting] セクションで、[Error Table] を選択します。 - [
Enable error table] チェックボックスをオンにして、次のように設定します。
- データセット:
bq_data_preparation_demoを選択します。 - テーブル:
err_dataprepと入力します。 - [
Define duration for keeping errors] で、[30 days (default)] を選択します。
Saveをクリックします。
[Manufacturer] 列の検証を設定する
- [メーカー] 列を選択します。
- Gemini は関連する変換を特定している可能性があります。[メーカー] フィールドが空でない行のみを保持する最適化案を見つけます。SQL は次のようになります。
Manufacturer IS NOT NULL
2. この最適化案の [編集] ボタンをクリックして確認します。
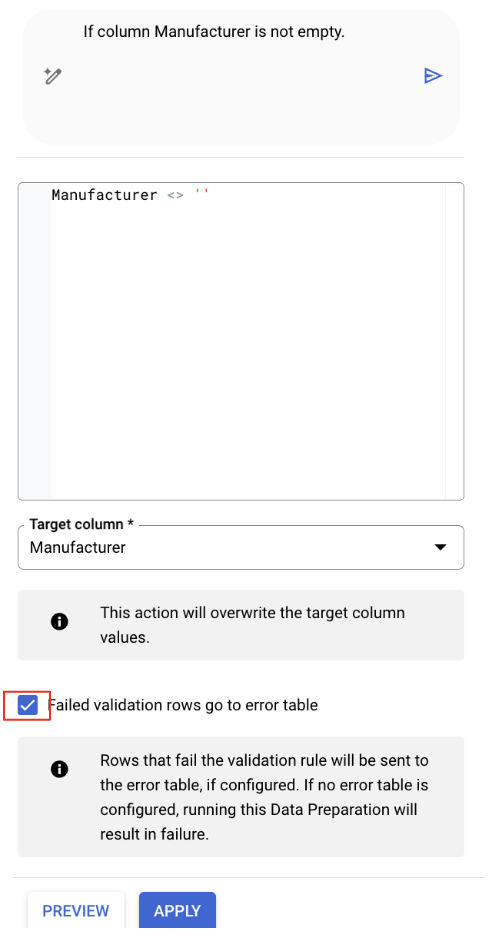
- [検証に失敗した行をエラーテーブルに送信する] オプションがオンになっていない場合は、オンにします。
Applyをクリックします。
適用した変換は、[適用したステップ] ボタンをクリックして、いつでも確認、変更、削除できます。
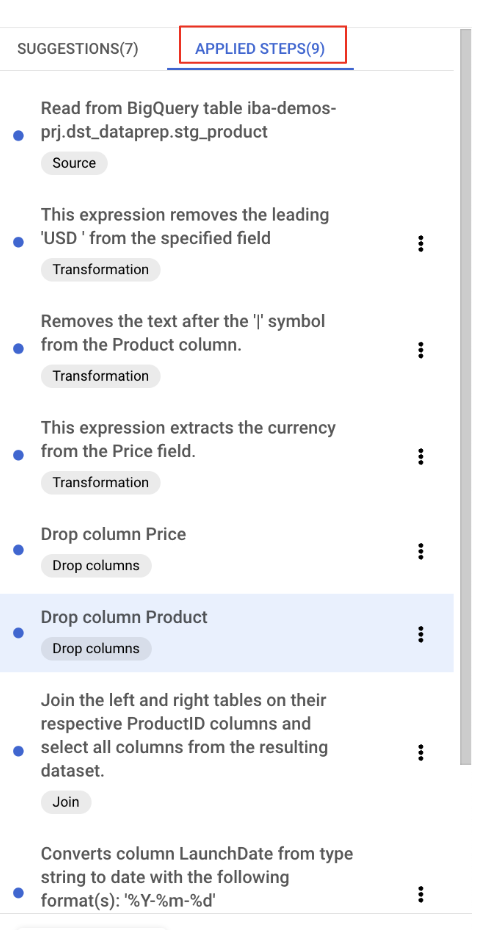
冗長な ProductID_1 列をクリーンアップする
結合されたテーブルの ProductID を複製する ProductID_1 列を削除できるようになりました。
- [
Schema] タブに移動します。 - [
ProductID_1] 列の横にあるその他アイコンをクリックします。 Dropをクリックします。
これで、データ準備ジョブを実行して、パイプライン全体を検証する準備が整いました。結果に満足したら、ジョブを自動で実行するようにスケジュール設定できます。
- データ準備ビューから移動する前に、準備を保存します。
stg_product data preparationタイトルの横にSaveボタンが表示されます。ボタンをクリックして保存します。
11. 環境をクリーンアップする
stg_product data preparationを削除するbq data preparation demoデータセットを削除する
12. 完了
以上で、この Codelab は完了です。
学習した内容
- データ準備の設定
- テーブルを開いてデータ準備をナビゲートする
- 数値と単位記述子データを含む列を分割する
- 日付形式の標準化
- データ準備の実行