
1. परिचय
कल्पना करें कि आपको कोडिंग का विशेषज्ञ होने की ज़रूरत नहीं है, लेकिन फिर भी आपको डेटा का विश्लेषण करने के लिए, डेटा को तेज़ी से और ज़्यादा आसानी से तैयार करना है. BigQuery डेटा तैयारी की मदद से, ऐसा किया जा सकता है. इस बेहतर सुविधा की मदद से, डेटा को आसानी से इकट्ठा किया जा सकता है, उसे बदला जा सकता है, और उसे साफ़ किया जा सकता है. इससे, आपके संगठन के सभी डेटा प्रैक्टिशनर को डेटा तैयार करने में मदद मिलती है.
क्या आप अपने प्रॉडक्ट डेटा में छिपी जानकारी को अनलॉक करने के लिए तैयार हैं?
ज़रूरी शर्तें
- Google Cloud Console की बुनियादी जानकारी
- एसक्यूएल की बुनियादी जानकारी
आपको क्या सीखने को मिलेगा
- BigQuery में डेटा तैयार करने की सुविधा का इस्तेमाल करके, रॉ डेटा को कारोबार से जुड़ी अहम जानकारी में कैसे बदला जा सकता है. इसके लिए, फ़ैशन और ब्यूटी इंडस्ट्री का एक उदाहरण दिया गया है.
- साफ़ किए गए डेटा के लिए, डेटा तैयार करने की प्रोसेस को चलाने और शेड्यूल करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
2. बुनियादी सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

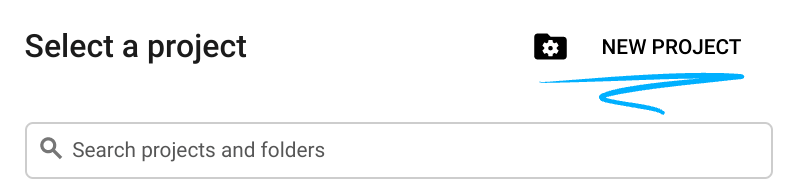
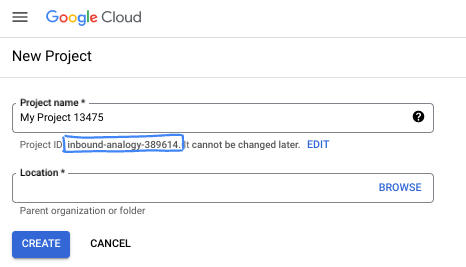
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होता है. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग को अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको अपने प्रोजेक्ट आईडी (आम तौर पर
PROJECT_IDके तौर पर पहचाना जाता है) का रेफ़रंस देना होगा. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहता है. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, Cloud Console में बिलिंग चालू करें, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा समय नहीं लगेगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, 300 डॉलर का क्रेडिट मिलता है. इसका इस्तेमाल वे मुफ़्त में आज़माने की अवधि के दौरान कर सकते हैं.
3. शुरू करने से पहले
एपीआई चालू करना
BigQuery में Gemini का इस्तेमाल करने के लिए, आपको Gemini for Google Cloud API चालू करना होगा. आम तौर पर, यह चरण सेवा एडमिन या प्रोजेक्ट के मालिक के पास मौजूद serviceusage.services.enable आईएएम की अनुमति की मदद से पूरा किया जाता है.
- Gemini for Google Cloud API चालू करने के लिए, Google Cloud Marketplace में Gemini for Google Cloud पेज पर जाएं. Gemini for Google Cloud पर जाएं
- प्रोजेक्ट चुनने वाले टूल में जाकर, कोई प्रोजेक्ट चुनें.
- चालू करें पर क्लिक करें. पेज अपडेट हो जाता है और चालू है की स्थिति दिखाता है. Gemini in BigQuery अब चुने गए Google Cloud प्रोजेक्ट में उन सभी उपयोगकर्ताओं के लिए उपलब्ध है जिनके पास ज़रूरी IAM अनुमतियां हैं.
डेटा तैयार करने के लिए भूमिकाएं और अनुमतियां सेट अप करना
- IAM और एडमिन में जाकर, IAM चुनें
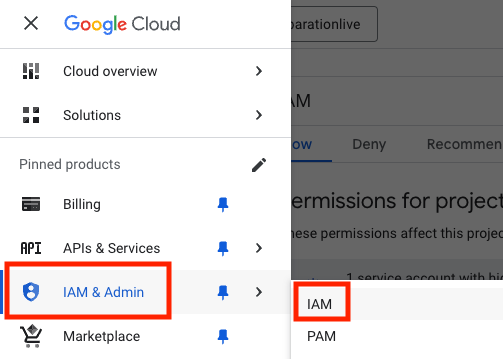
- अपने उपयोगकर्ता को चुनें और ‘मुख्य उपयोगकर्ता के तौर पर बदलाव करें' के लिए पेंसिल आइकॉन पर क्लिक करें
BigQuery डेटा तैयार करने की सुविधा का इस्तेमाल करने के लिए, आपको इन भूमिकाओं और अनुमतियों की ज़रूरत होगी:
- BigQuery डेटा एडिटर (roles/bigquery.dataEditor)
- Service Usage Consumer (roles/serviceusage.serviceUsageConsumer)
4. BigQuery Analytics Hub में "bq data preparation demo" लिस्टिंग को ढूंढना और उसकी सदस्यता लेना
इस ट्यूटोरियल के लिए, हम bq data preparation demo डेटासेट का इस्तेमाल करेंगे. यह BigQuery Analytics Hub में लिंक किया गया डेटासेट है. हम इससे डेटा पढ़ेंगे.
डेटा तैयार करने की प्रोसेस में, डेटा को कभी भी सोर्स में वापस नहीं लिखा जाता. इसलिए, हम आपसे डेस्टिनेशन टेबल तय करने के लिए कहेंगे, ताकि डेटा को उसमें लिखा जा सके. इस टेबल में सिर्फ़ 1,000 लाइनें हैं, ताकि लागत कम रहे. हालांकि, डेटा तैयार करने की प्रोसेस BigQuery पर चलती है और यह प्रोसेस, डेटा के साथ-साथ बढ़ती जाएगी.
लिंक किए गए डेटासेट को ढूंढने और उसकी सदस्यता लेने के लिए, यह तरीका अपनाएं:
- Analytics Hub को ऐक्सेस करना: Google Cloud Console में, BigQuery पर जाएं.
- BigQuery के नेविगेशन मेन्यू में, "गवर्नेंस" में जाकर,"Analytics Hub" चुनें.
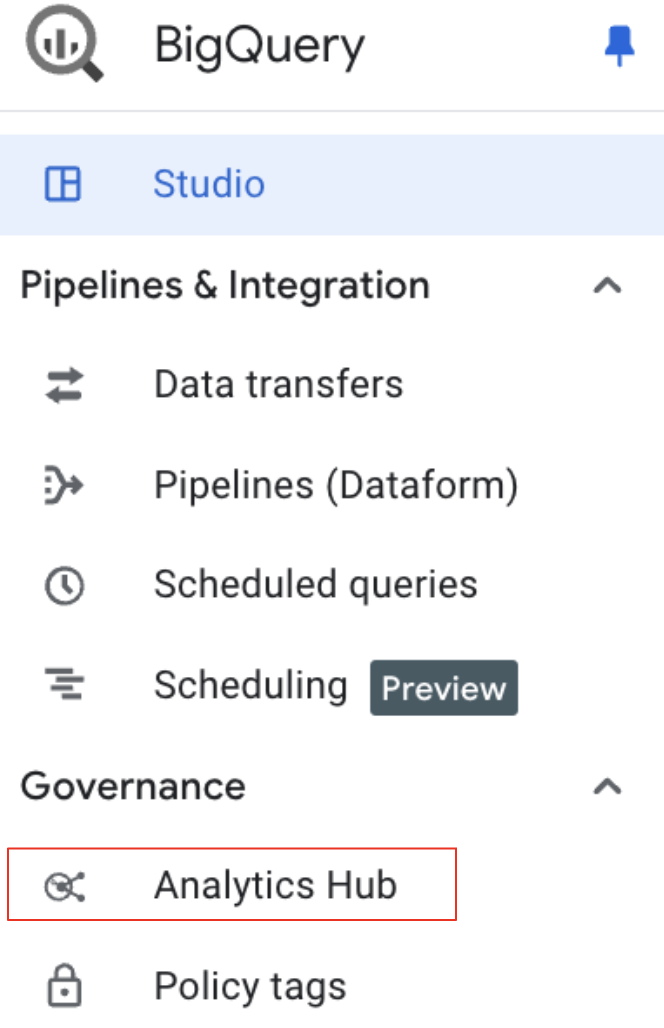
- लिस्टिंग खोजें: Analytics हब के यूज़र इंटरफ़ेस (यूआई) में, लिस्टिंग खोजें पर क्लिक करें."
- खोज बार में
bq data preparation demoलिखें और Enter दबाएं.
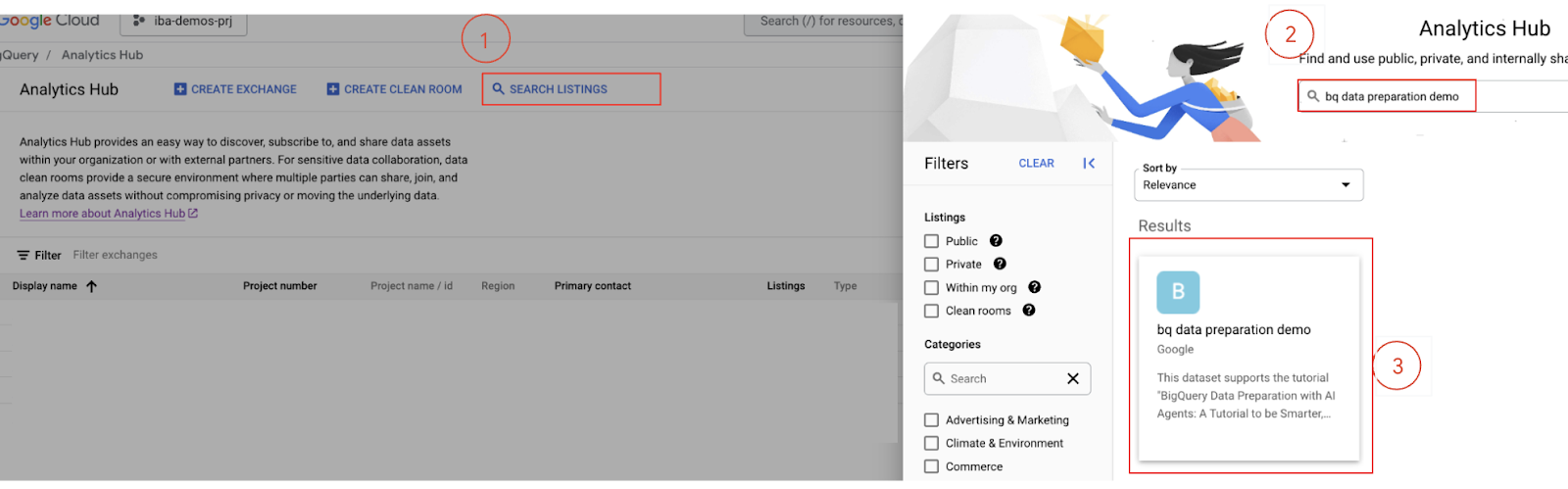
- लिस्टिंग की सदस्यता लें: खोज के नतीजों में से
bq data preparation demoलिस्टिंग चुनें. - लिस्टिंग की ज़्यादा जानकारी वाले पेज पर, सदस्यता लें बटन पर क्लिक करें.
- पुष्टि करने वाले किसी भी डायलॉग बॉक्स की समीक्षा करें. अगर ज़रूरी हो, तो प्रोजेक्ट/डेटासेट अपडेट करें. डिफ़ॉल्ट वैल्यू सही होनी चाहिए.

- BigQuery में डेटासेट ऐक्सेस करना: सदस्यता लेने के बाद, लिस्टिंग में मौजूद डेटासेट आपके BigQuery प्रोजेक्ट से लिंक हो जाएंगे.
BigQuery Studio पर वापस जाएं.
5. डेटा एक्सप्लोर करना और डेटा तैयार करने की प्रोसेस शुरू करना
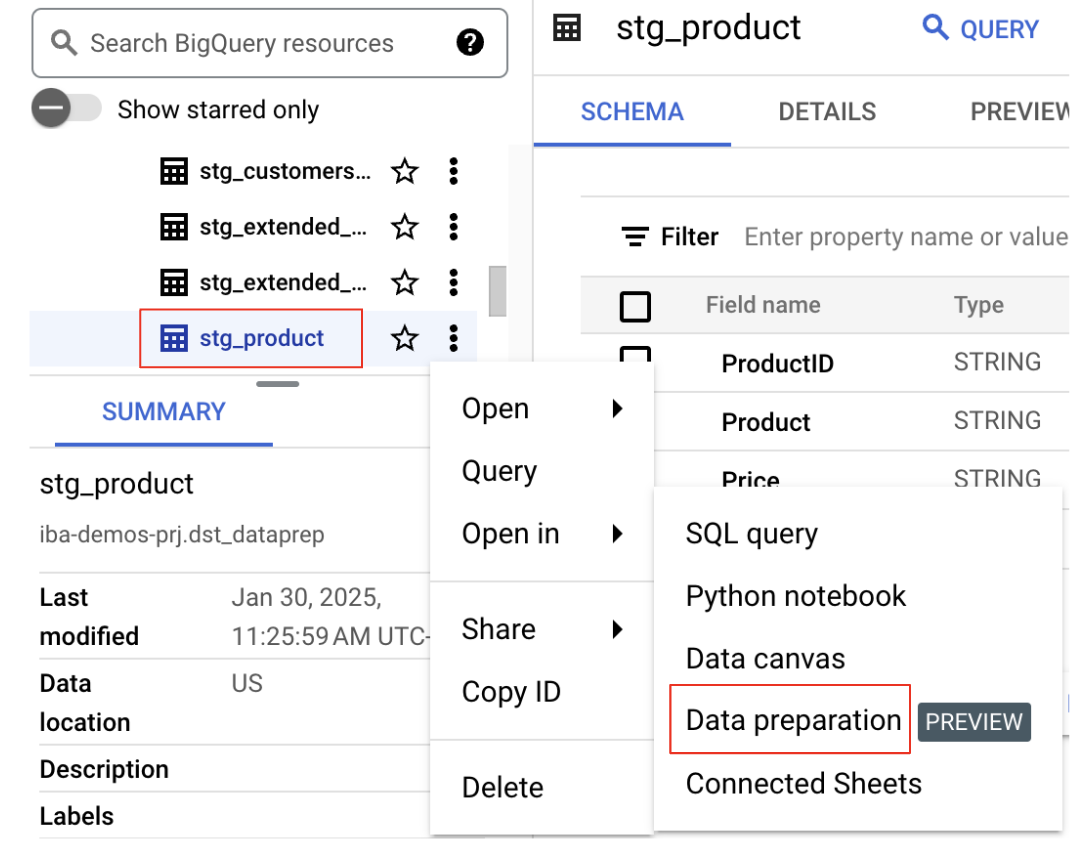
- डेटासेट और टेबल ढूंढें: एक्सप्लोरर पैनल में, अपना प्रोजेक्ट चुनें. इसके बाद, वह डेटासेट ढूंढें जिसे
bq data preparation demoलिस्टिंग में शामिल किया गया था.stg_productटेबल चुनें. - डेटा तैयारी में खोलें: टेबल के नाम के बगल में मौजूद तीन वर्टिकल डॉट पर क्लिक करें और
Open in Data Preparationचुनें.
इससे डेटा तैयारी इंटरफ़ेस में टेबल खुल जाएगी. अब डेटा को ट्रांसफ़ॉर्म किया जा सकता है.
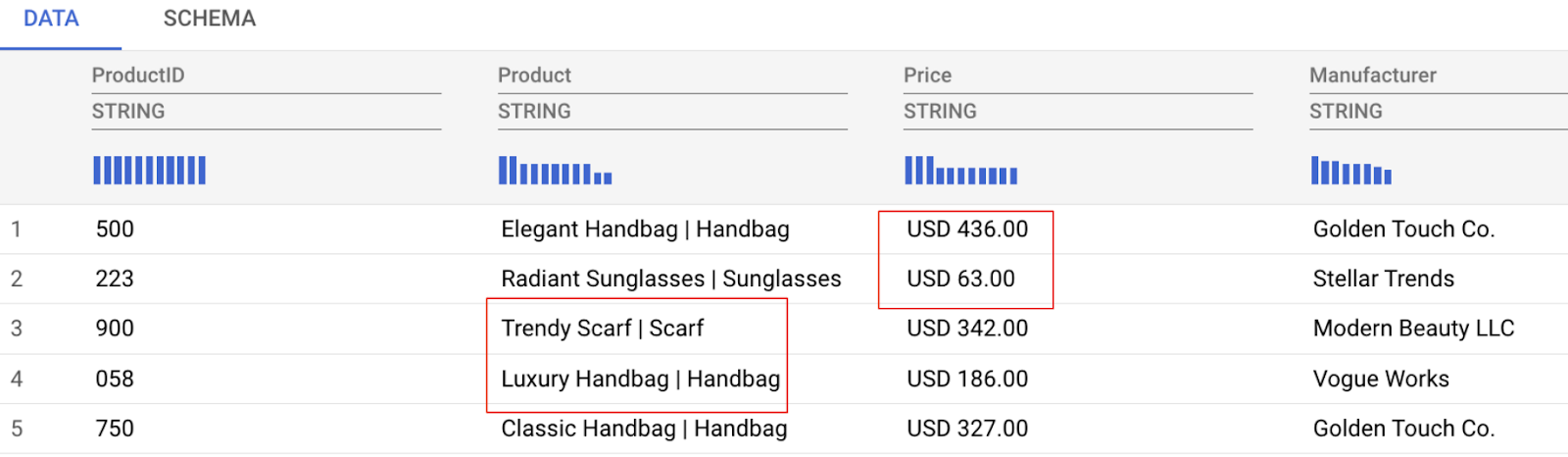
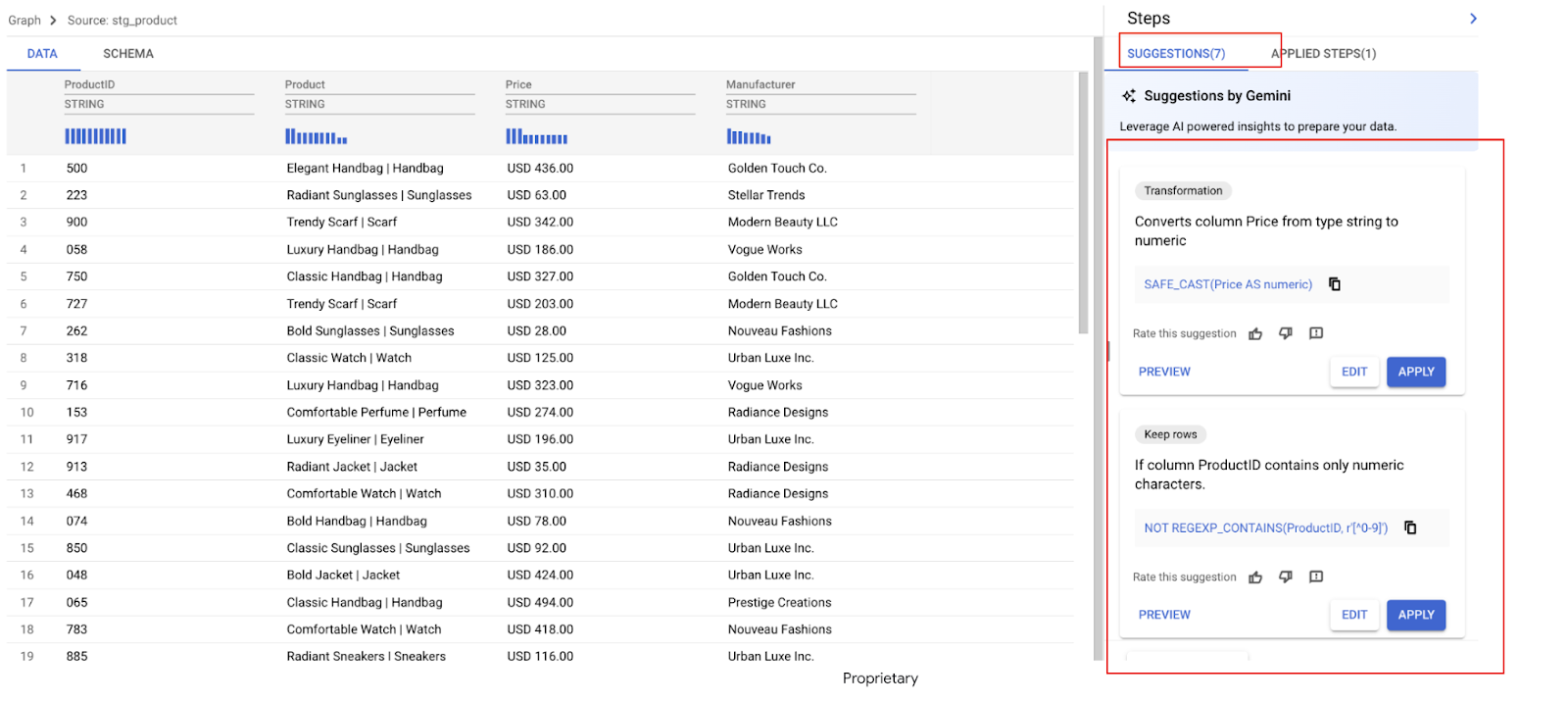
नीचे दी गई डेटा की झलक में, आपको डेटा से जुड़ी कुछ समस्याएं दिखेंगी. हम इन समस्याओं को हल करेंगे. इनमें ये समस्याएं शामिल हैं:
- कीमत वाले कॉलम में, रकम और मुद्रा, दोनों की जानकारी शामिल है. इसलिए, इसका विश्लेषण करना मुश्किल है.
- प्रॉडक्ट कॉलम में, प्रॉडक्ट का नाम और कैटगरी को एक साथ दिखाया जाता है. इन्हें पाइप सिंबल | से अलग किया जाता है.
Gemini तुरंत आपके डेटा का विश्लेषण करता है और कई ट्रांसफ़ॉर्मेशन के सुझाव देता है. इस उदाहरण में, हमें कई सुझाव दिख रहे हैं. अगले चरणों में, हम उन फ़िल्टर को लागू करेंगे जिनकी हमें ज़रूरत है.
6. कीमत वाले कॉलम को मैनेज करना
आइए, कीमत कॉलम के बारे में जानते हैं. जैसा कि हमने देखा, इसमें मुद्रा और रकम, दोनों शामिल होती हैं. हमारा मकसद, इन्हें दो अलग-अलग कॉलम में बांटना है:मुद्रा और रकम.
Gemini ने कीमत कॉलम के लिए कई सुझावों की पहचान की है.
- ऐसा सुझाव ढूंढें जिसमें कुछ ऐसा लिखा हो:
ब्यौरा: "यह एक्सप्रेशन, तय किए गए फ़ील्ड से ‘USD ' को हटाता है"
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- झलक देखें चुनें
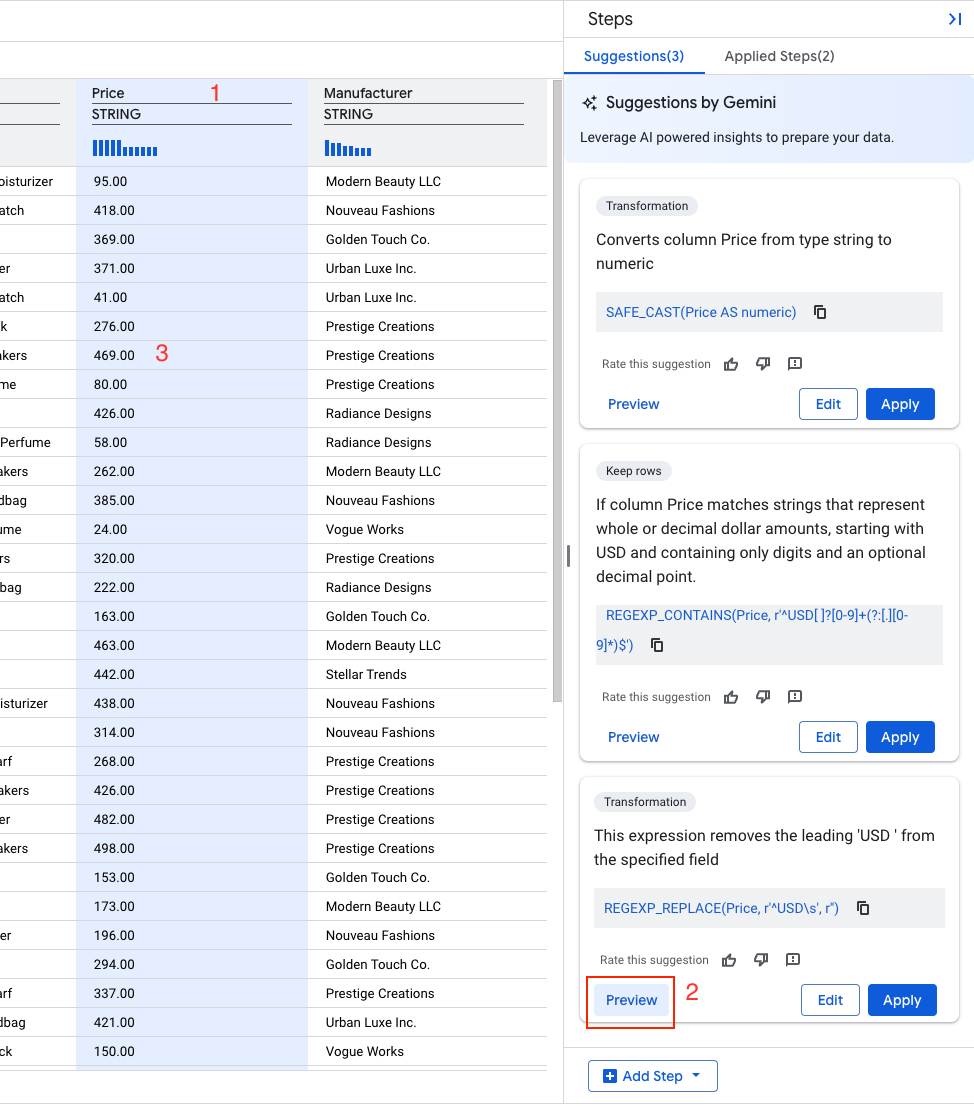
- लागू करें चुनें
इसके बाद, कीमत कॉलम के लिए, डेटा टाइप को STRING से NUMERIC में बदलें.
- ऐसा सुझाव ढूंढें जिसमें कुछ ऐसा लिखा हो:
जानकारी: "Converts column Price from type string to float64"
SAFE_CAST(Price AS float64)
- 'लागू करें' को चुनें.
अब आपको अपनी चरण सूची में, लागू किए गए तीन चरण दिखेंगे.

7. प्रॉडक्ट कॉलम को मैनेज करना
प्रॉडक्ट कॉलम में, प्रॉडक्ट का नाम और कैटगरी, दोनों शामिल हैं. इन्हें पाइप (|) से अलग किया गया है.
हम फिर से सामान्य भाषा का इस्तेमाल कर सकते हैं. हालांकि, आइए Gemini की एक और बेहतरीन सुविधा के बारे में जानें.
प्रॉडक्ट का नाम हटाना
- प्रॉडक्ट एंट्री के कैटगरी वाले हिस्से को चुनें. इसमें
|वर्ण शामिल है. इसके बाद, इसे मिटाएं.
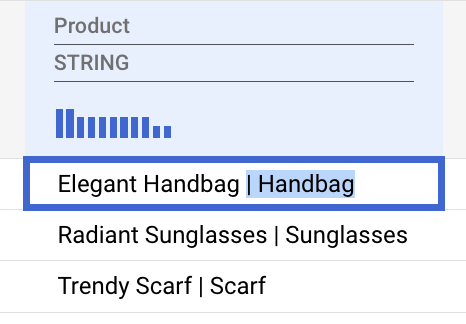
Gemini इस पैटर्न को समझदारी से पहचान लेगा और पूरे कॉलम पर लागू करने के लिए, डेटा में बदलाव करने का सुझाव देगा.
- "बदलाव करें" को चुनें.
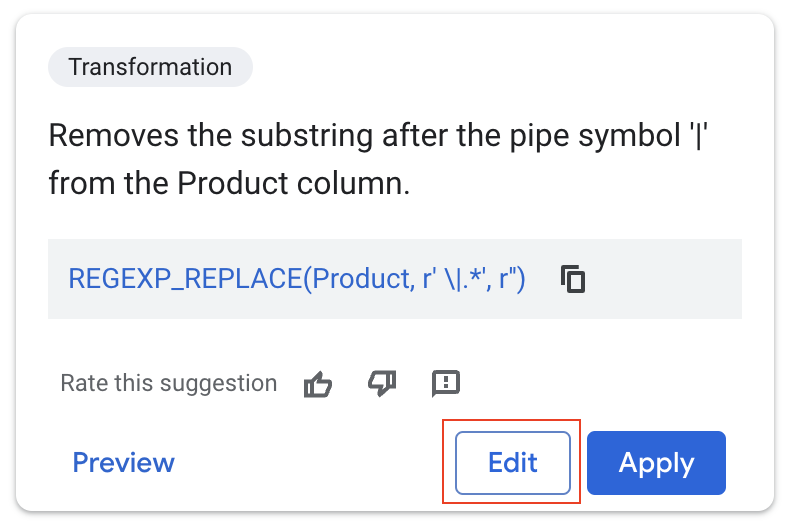
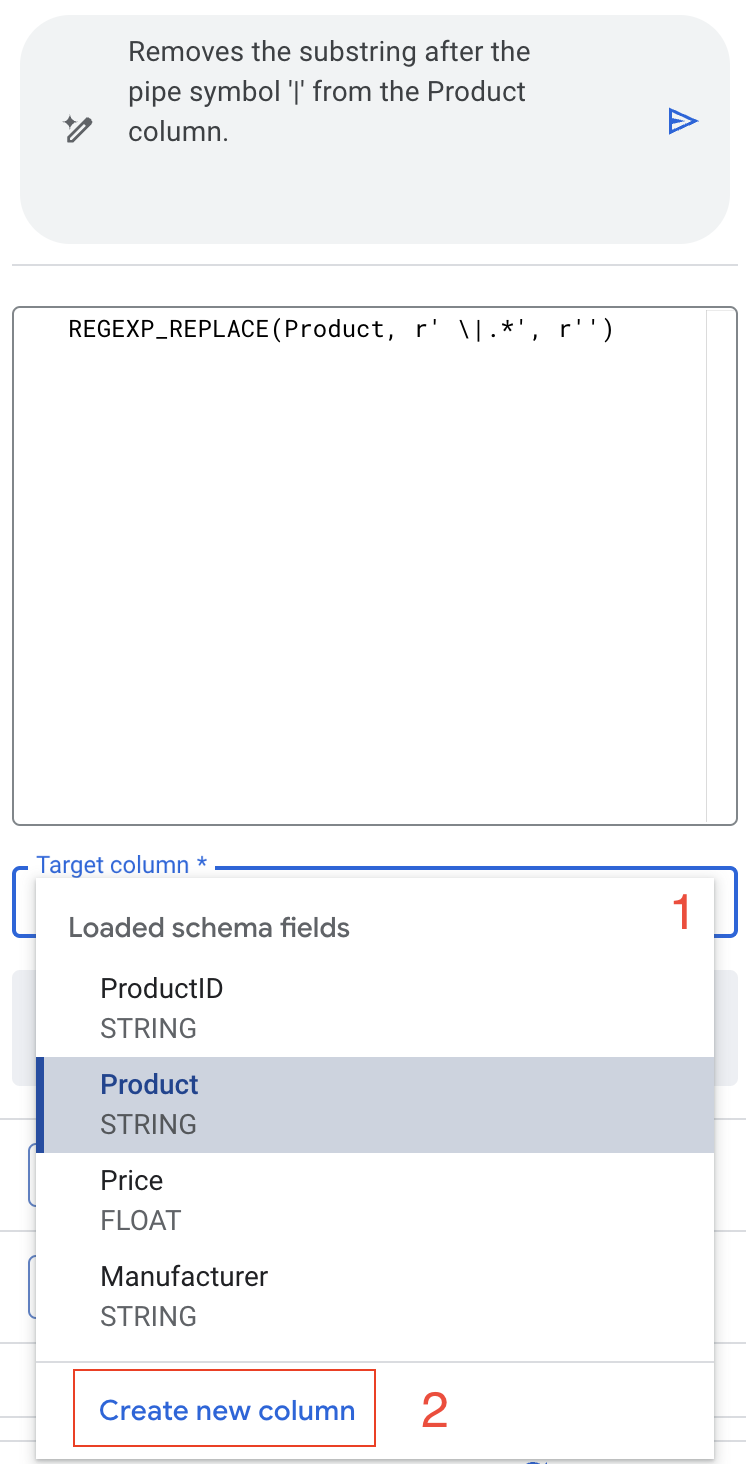
Gemini का सुझाव सही है: यह ‘|' वर्ण के बाद के सभी वर्णों को हटा देता है. इससे प्रॉडक्ट का नाम अलग हो जाता है.
हालांकि, इस बार हमें अपने ओरिजनल डेटा को ओवरराइट नहीं करना है.
- टारगेट कॉलम के ड्रॉपडाउन में, "नया कॉलम बनाएं" चुनें.
- नाम को ProductName पर सेट करें.
- बदलावों की झलक देखें, ताकि यह पक्का किया जा सके कि सब कुछ ठीक दिख रहा है.
- बदलाव लागू करें.
प्रॉडक्ट कैटगरी की जानकारी निकालना
हम Gemini को सामान्य भाषा में यह निर्देश देंगे कि वह प्रॉडक्ट कॉलम में पाइप (|) के बाद मौजूद शब्द को निकाले. निकाली गई इस वैल्यू को, प्रॉडक्ट नाम वाले मौजूदा कॉलम में बदल दिया जाएगा.
- नया ट्रांसफ़ॉर्मेशन चरण जोड़ने के लिए,
Add Stepपर क्लिक करें.
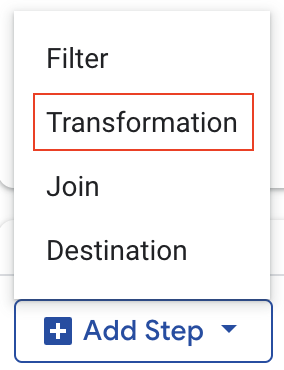
- ड्रॉपडाउन मेन्यू से
Transformationचुनें - भाषा से जुड़े सामान्य प्रॉम्प्ट वाले फ़ील्ड में, "प्रॉडक्ट कॉलम में पाइप (|) के बाद मौजूद शब्द निकालें." डालें. इसके बाद, एसक्यूएल जनरेट करने के लिए Return दबाएं.
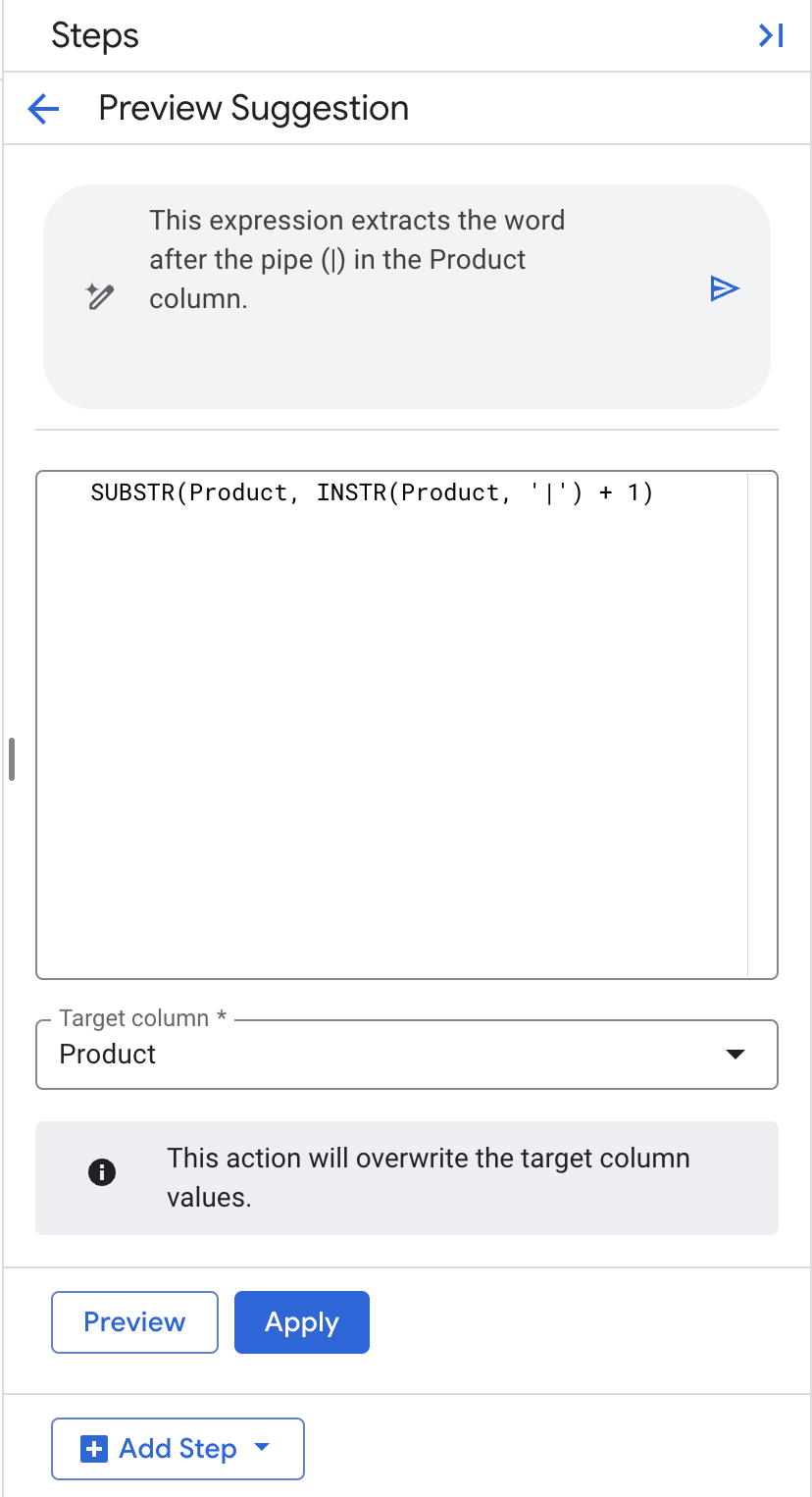
- टारगेट कॉलम को "प्रॉडक्ट" के तौर पर ही रहने दें.
- लागू करें पर क्लिक करें.
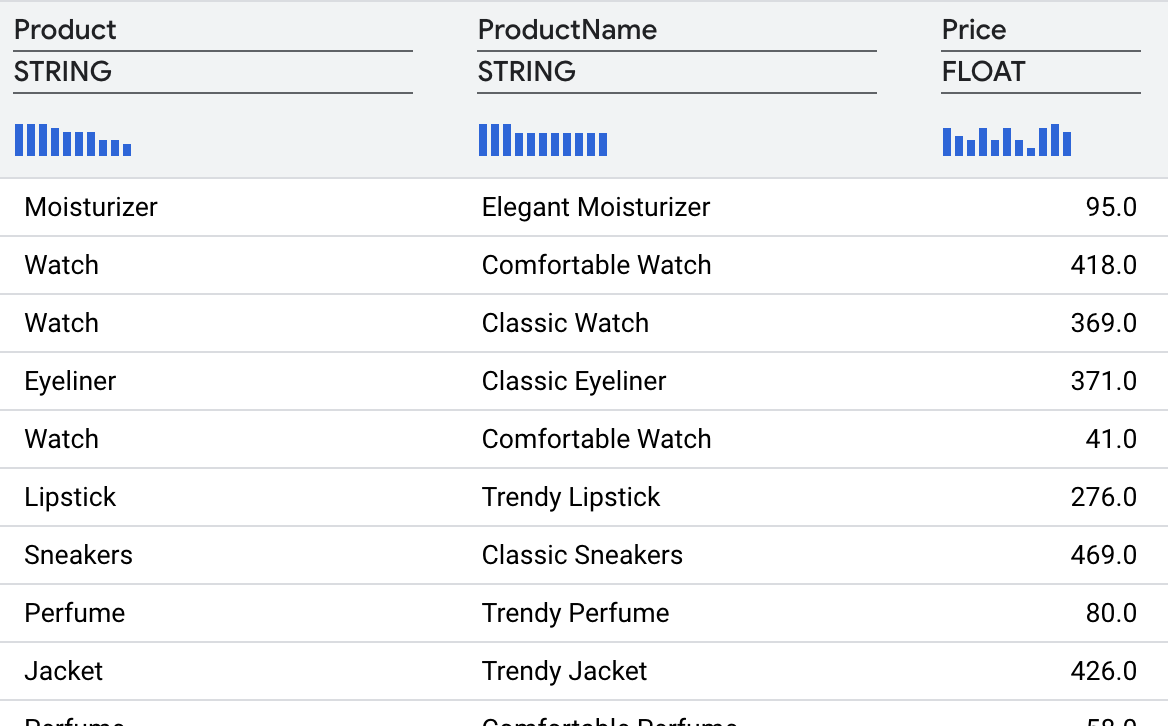
ट्रांसफ़ॉर्मेशन के बाद, आपको ये नतीजे मिलेंगे.
8. डेटा को बेहतर बनाने के लिए जोड़ना
अक्सर, आपको अपने डेटा को अन्य सोर्स से मिली जानकारी के साथ बेहतर बनाना होता है. इस उदाहरण में, हम अपने प्रॉडक्ट डेटा को तीसरे पक्ष की टेबल से मिले एक्सटेंडेड प्रॉडक्ट एट्रिब्यूट, stg_extended_product, के साथ जोड़ेंगे. इस टेबल में, ब्रैंड और लॉन्च की तारीख जैसी जानकारी शामिल होती है.
Add Stepपर क्लिक करेंJoinचुनेंstg_extended_productटेबल पर जाएं.
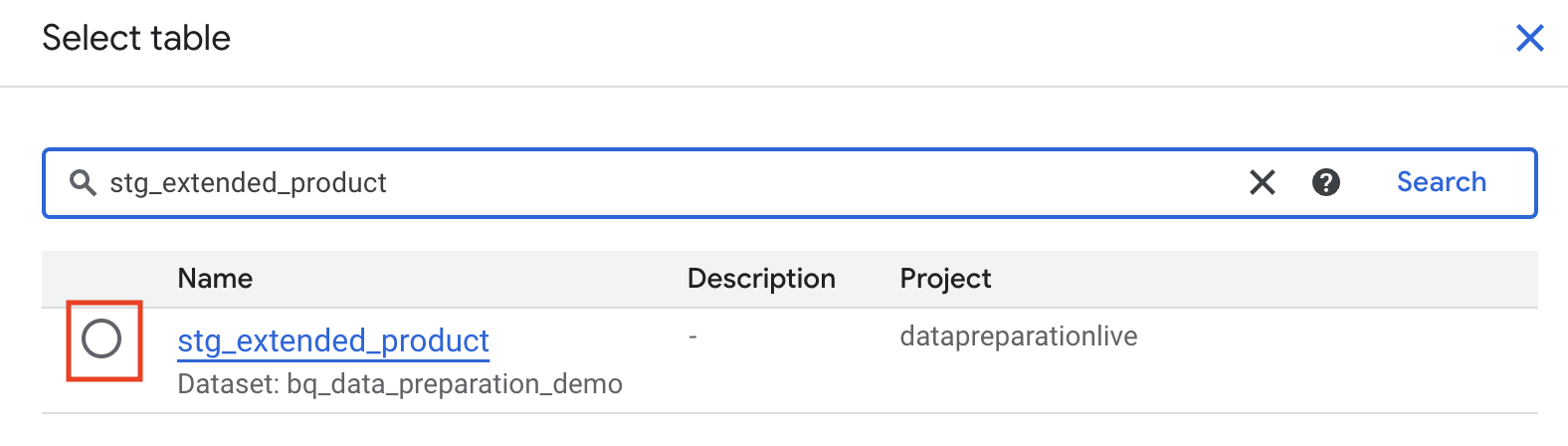
BigQuery में Gemini ने हमारे लिए, अपने-आप productid जॉइन की चुनी है. साथ ही, उसने लेफ्ट और राइट हैंड साइड को क्वालिफ़ाई किया है, क्योंकि कुंजी का नाम एक जैसा है.
ध्यान दें: पक्का करें कि ब्यौरे वाले फ़ील्ड में ‘Join by productid' लिखा हो. अगर इसमें अतिरिक्त जॉइन की शामिल हैं, तो जानकारी वाले फ़ील्ड को ‘Join by productid' से बदलें. इसके बाद, जानकारी वाले फ़ील्ड में मौजूद जनरेट करें बटन को चुनें, ताकि नीचे दी गई शर्त L. के साथ जॉइन एक्सप्रेशन को फिर से जनरेट किया जा सके
productid
= R.
productid. 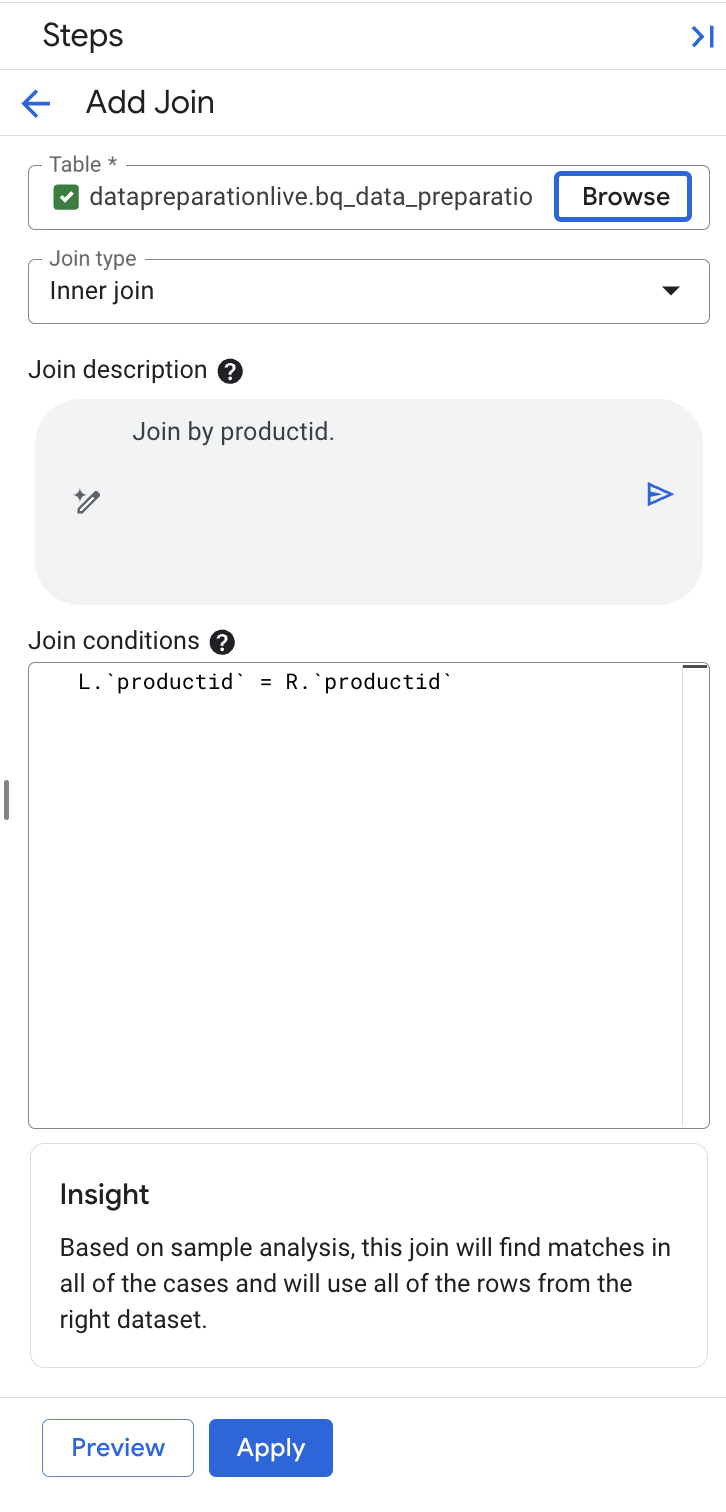
- इसके अलावा, नतीजों की झलक देखने के लिए, 'झलक देखें' को चुनें.
Applyपर क्लिक करें.
एक्सटेंड किए गए एट्रिब्यूट की वैल्यू ठीक करना
डेटा सोर्स जुड़ गया है. हालांकि, एक्सटेंड किए गए एट्रिब्यूट के डेटा को ठीक करने की ज़रूरत है. LaunchDate कॉलम में तारीख के फ़ॉर्मैट अलग-अलग हैं. साथ ही, Brand कॉलम में कुछ वैल्यू मौजूद नहीं हैं.
हम LaunchDate कॉलम से शुरुआत करेंगे.

कोई भी बदलाव करने से पहले, Gemini की सुझाई गई कार्रवाइयां देखें.
LaunchDateकॉलम के नाम पर क्लिक करें. आपको नीचे दी गई इमेज में दिखाए गए सुझावों की तरह ही कुछ सुझाव दिखेंगे.
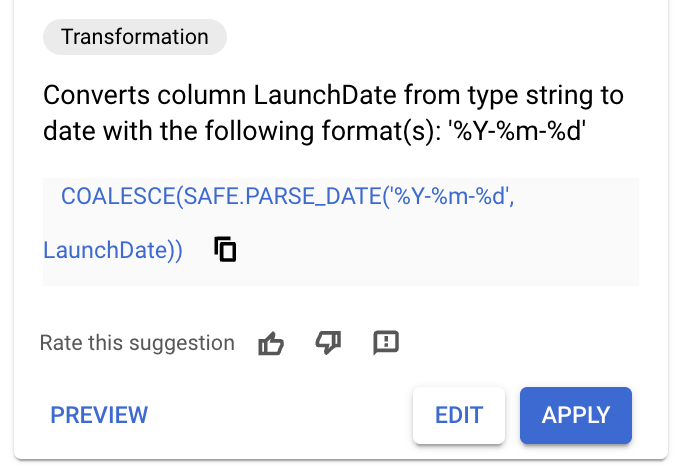
- अगर आपको नीचे दिए गए SQL के साथ कोई सुझाव दिखता है, तो लागू करें पर क्लिक करके सुझाव लागू करें और अगले चरण छोड़ दें.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- अगर आपको ऊपर दिए गए एसक्यूएल से मिलता-जुलता कोई सुझाव नहीं दिखता है, तो
Add Stepपर क्लिक करें. Transformationको चुनें.- SQL फ़ील्ड में, यह डालें:
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
Target ColumnsकोLaunchDateपर सेट करें.Applyपर क्लिक करें.
LaunchDate कॉलम में अब तारीख का एक जैसा फ़ॉर्मैट है.

9. डेस्टिनेशन टेबल जोड़ना
अब हमारा डेटासेट साफ़ हो गया है और इसे हमारे डेटा वेयरहाउस में डाइमेंशन टेबल में लोड किया जा सकता है.
ADD STEPपर क्लिक करें.Destinationको चुनें.- ज़रूरी पैरामीटर भरें: डेटासेट:
bq_data_preparation_demoटेबल:DimProduct Saveपर क्लिक करें.

अब हमने "डेटा" और "स्कीमा" टैब के साथ काम किया है. इनके अलावा, BigQuery डेटा तैयार करने की सुविधा में "ग्राफ़" व्यू भी मिलता है. इससे आपकी पाइपलाइन में, डेटा को बदलने के चरणों का क्रम विज़ुअल तरीके से दिखता है.
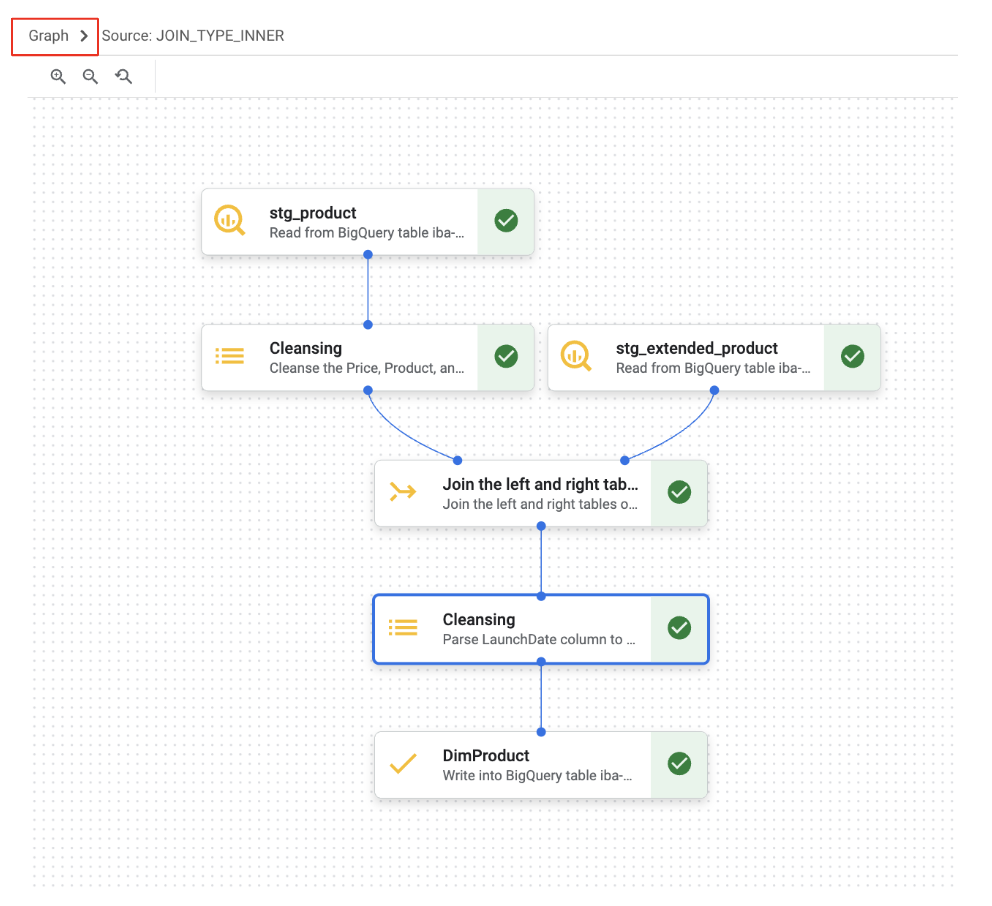
10. बोनस A: 'निर्माता' कॉलम को मैनेज करना और गड़बड़ी वाली टेबल बनाना
हमें Manufacturer कॉलम में खाली वैल्यू भी मिली हैं. हम इन रिकॉर्ड के लिए, डेटा क्वालिटी की जांच करना चाहते हैं. साथ ही, इन्हें ज़्यादा समीक्षा के लिए, गड़बड़ी वाली टेबल में ले जाना चाहते हैं.
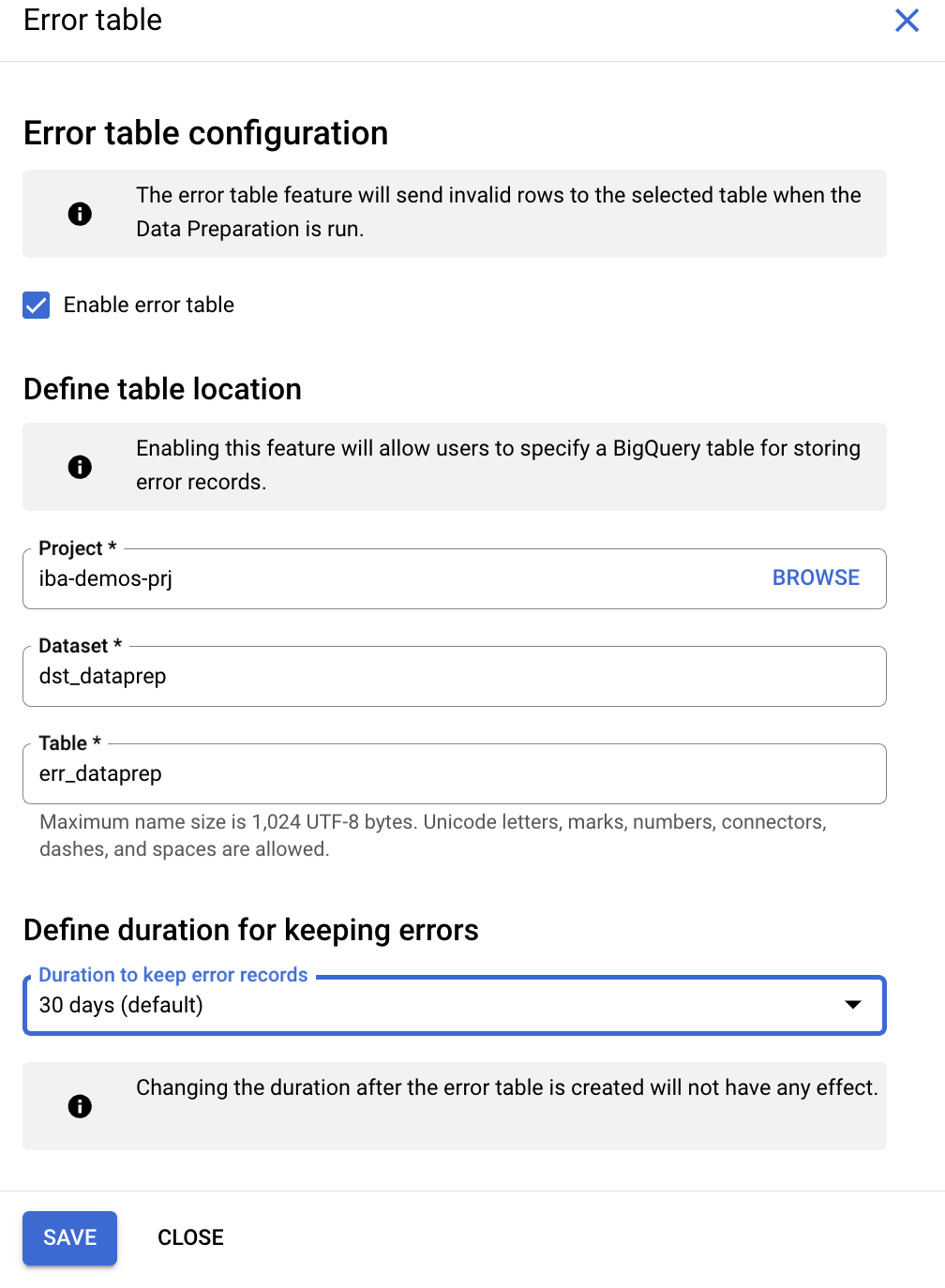
गड़बड़ी वाली टेबल बनाना
stg_product data preparationटाइटल के बगल में मौजूद,Moreबटन पर क्लिक करें.Settingसेक्शन में जाकर,Error Tableको चुनें.Enable error tableबॉक्स पर सही का निशान लगाएं और सेटिंग को इस तरह कॉन्फ़िगर करें:
- डेटासेट:
bq_data_preparation_demoचुनें - टेबल:
err_dataprepडालें Define duration for keeping errorsमें जाकर,30 days (default)को चुनें
Saveपर क्लिक करें.
'मैन्युफ़ैक्चरर' कॉलम के लिए पुष्टि करने की सुविधा सेट अप करना
- 'निर्माता' कॉलम चुनें.
- Gemini, काम के ट्रांसफ़ॉर्मेशन की पहचान कर लेगा. उस सुझाव को ढूंढें जिसमें सिर्फ़ वे पंक्तियां शामिल हैं जिनमें 'मैन्युफ़ैक्चरर' फ़ील्ड खाली नहीं है. इसमें इस तरह का एसक्यूएल होगा:
Manufacturer IS NOT NULL
2.इस सुझाव की समीक्षा करने के लिए, "बदलाव करें" बटन पर क्लिक करें.
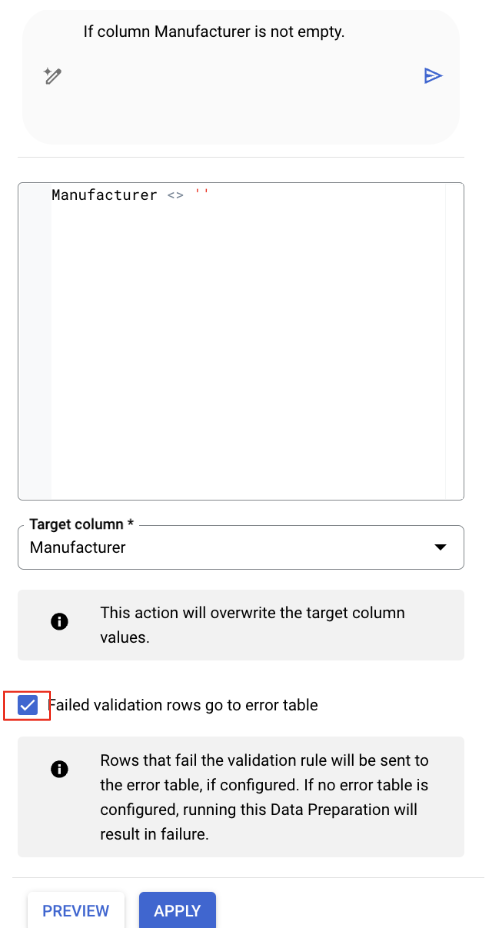
- अगर "पुष्टि नहीं की जा सकी, तो पंक्तियों को गड़बड़ी वाली टेबल में ले जाएं" विकल्प पर सही का निशान नहीं लगा है, तो उस पर सही का निशान लगाएं
Applyपर क्लिक करें.
"लागू किए गए चरण" बटन पर क्लिक करके, कभी भी लागू किए गए बदलावों की समीक्षा की जा सकती है, उनमें बदलाव किया जा सकता है या उन्हें मिटाया जा सकता है.
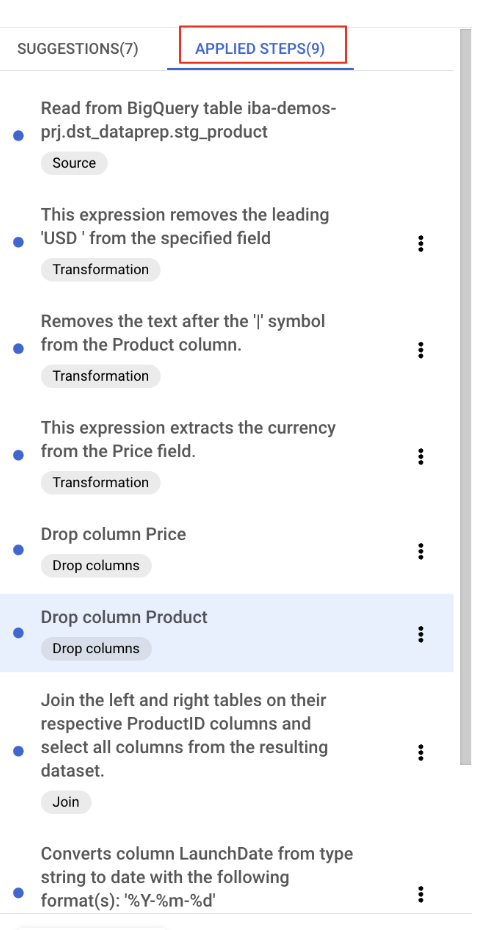
ProductID_1 कॉलम में मौजूद काम के न रहे डेटा को मिटाना
अब ProductID_1 कॉलम को मिटाया जा सकता है. यह कॉलम, हमारी जोड़ी गई टेबल के ProductID को डुप्लीकेट करता है.
Schemaटैब पर जाएंProductID_1कॉलम के बगल में मौजूद तीन बिंदुओं पर क्लिक करें.Dropपर क्लिक करें.
अब हम डेटा तैयार करने का काम शुरू करने और अपनी पूरी पाइपलाइन की पुष्टि करने के लिए तैयार हैं. जब हमें नतीजे सही लगते हैं, तब हम इस काम को अपने-आप होने के लिए शेड्यूल कर सकते हैं.
- डेटा तैयार करने वाले व्यू से बाहर निकलने से पहले, अपनी सेटिंग सेव करें. आपको
stg_product data preparationशीर्षक के बगल में,Saveबटन दिखेगा. सेव करने के लिए बटन पर क्लिक करें.
11. एनवायरमेंट को साफ़ करना
stg_product data preparationको मिटाएंbq data preparation demoडेटासेट मिटाएं
12. बधाई हो
कोडलैब पूरा करने के लिए बधाई.
हमने क्या-क्या बताया
- डेटा तैयार करने की प्रोसेस सेट अप करना
- टेबल खोलना और डेटा तैयार करने की सुविधा पर जाना
- संख्या और यूनिट डिस्क्रिप्टर डेटा वाले कॉलम को अलग-अलग करना
- तारीख के फ़ॉर्मैट को स्टैंडर्ड बनाना
- डेटा तैयार करने की प्रोसेस चल रही है