
1. Introduction
Imaginez pouvoir préparer vos données pour l'analyse plus rapidement et plus efficacement sans avoir besoin d'être un expert en programmation. Avec BigQuery Data Preparation, c'est possible. Cette fonctionnalité puissante simplifie l'ingestion, la transformation et le nettoyage des données, et permet à tous les spécialistes des données de votre organisation de préparer les données.
Prêt à découvrir les secrets cachés dans vos données produit ?
Prérequis
- Connaissances de base concernant la console Google Cloud
- Connaissances de base de SQL
Points abordés
- Découvrez comment la préparation des données BigQuery peut nettoyer et transformer vos données brutes en informations commerciales exploitables, à l'aide d'un exemple réaliste du secteur de la mode et de la beauté.
- Exécuter et planifier la préparation des données nettoyées
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web (par exemple, Chrome)
2. Configuration de base et exigences
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.


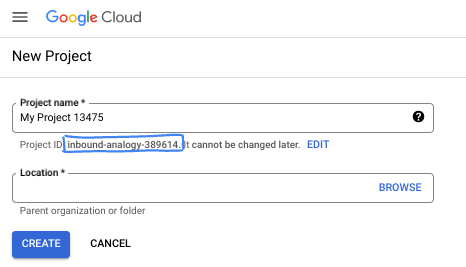
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300$.
3. Avant de commencer
Activer l'API
Pour utiliser Gemini dans BigQuery, vous devez activer l'API Gemini pour Google Cloud. Cette étape est généralement effectuée par un administrateur de service ou un propriétaire de projet disposant de l'autorisation IAM serviceusage.services.enable.
- Pour activer l'API Gemini pour Google Cloud, accédez à la page Gemini pour Google Cloud sur Google Cloud Marketplace. Accéder à Gemini pour Google Cloud
- Dans le sélecteur de projets, choisissez un projet.
- Cliquez sur Activer. La page s'actualise et affiche l'état Activé. Gemini dans BigQuery est désormais disponible dans le projet Google Cloud sélectionné pour tous les utilisateurs disposant des autorisations IAM requises.
Configurer des rôles et des autorisations pour développer des préparations de données
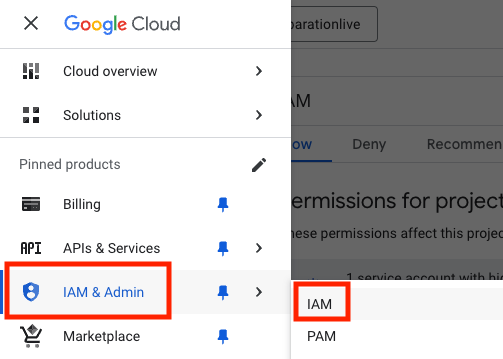
- Dans IAM et administration, sélectionnez IAM.
- Sélectionnez votre utilisateur, puis cliquez sur l'icône en forme de crayon pour modifier le principal.
Pour utiliser la préparation de données BigQuery, vous devez disposer des rôles et autorisations suivants :
- Éditeur de données BigQuery (roles/bigquery.dataEditor)
- Consommateur d'utilisation du service (roles/serviceusage.serviceUsageConsumer)
4. Rechercher la fiche "bq data preparation demo" et s'y abonner dans BigQuery Analytics Hub
Nous utiliserons l'ensemble de données bq data preparation demo pour ce tutoriel. Il s'agit d'un ensemble de données associé dans BigQuery Analytics Hub à partir duquel nous allons lire les données.
La préparation des données n'écrit jamais dans la source. Nous vous demanderons de définir une table de destination dans laquelle écrire. La table avec laquelle nous allons travailler pour cet exercice ne comporte que 1 000 lignes afin de limiter les coûts. Toutefois,la préparation des données s'exécute sur BigQuery et évoluera en conséquence.
Pour trouver l'ensemble de données associé et vous y abonner, procédez comme suit :
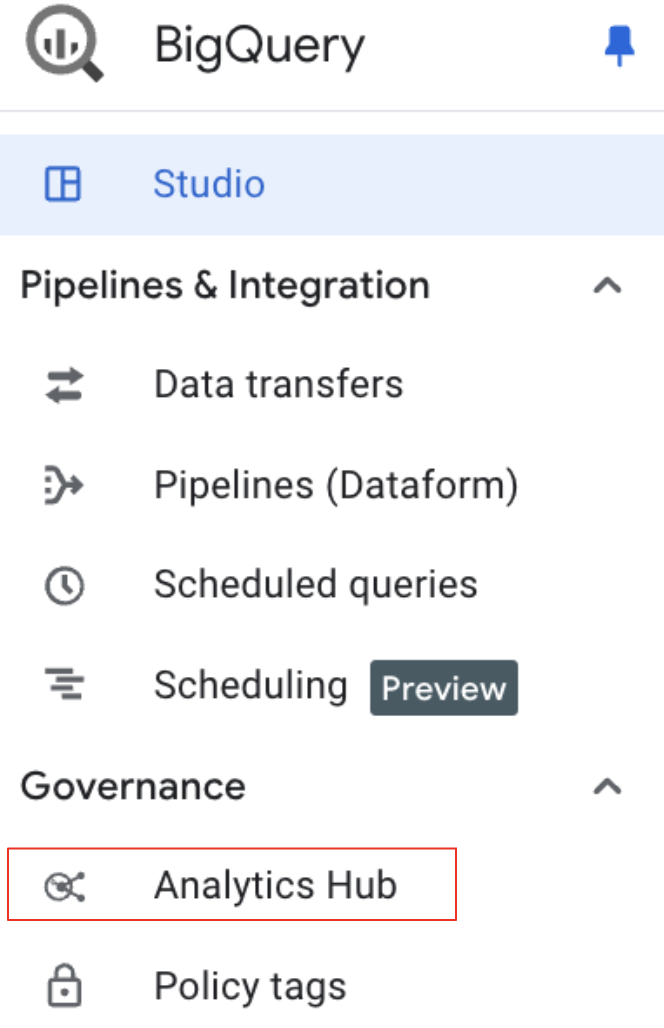
- Accédez à Analytics Hub : dans la console Google Cloud, accédez à BigQuery.
- Dans le menu de navigation BigQuery, sous "Gouvernance", sélectionnez "Analytics Hub".
- Recherchez la fiche : dans l'UI Analytics Hub, cliquez sur Rechercher des fiches."
- Saisissez
bq data preparation demodans la barre de recherche, puis appuyez sur Entrée.
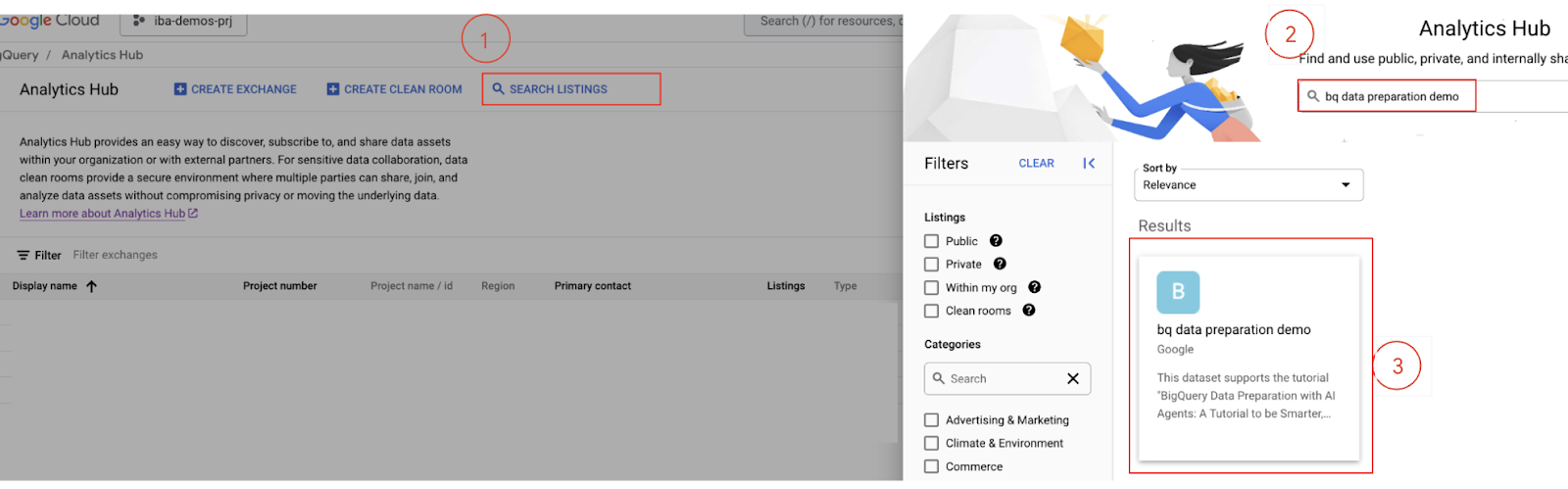
- S'abonner à la fiche : sélectionnez la fiche
bq data preparation demodans les résultats de recherche. - Sur la page d'informations sur la fiche, cliquez sur le bouton S'abonner.
- Examinez les boîtes de dialogue de confirmation et mettez à jour le projet ou l'ensemble de données si nécessaire. Les valeurs par défaut devraient être correctes.
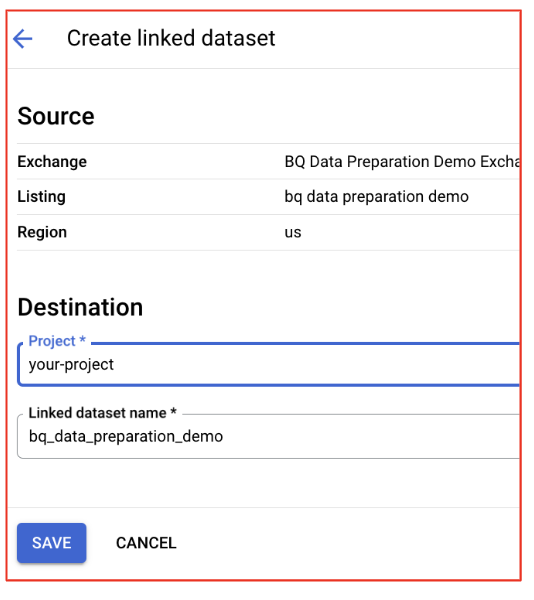
- Accédez à l'ensemble de données dans BigQuery : une fois votre abonnement souscrit, les ensembles de données de la fiche seront associés à votre projet BigQuery.
Revenez dans BigQuery Studio.
5. Explorer les données et lancer la préparation des données
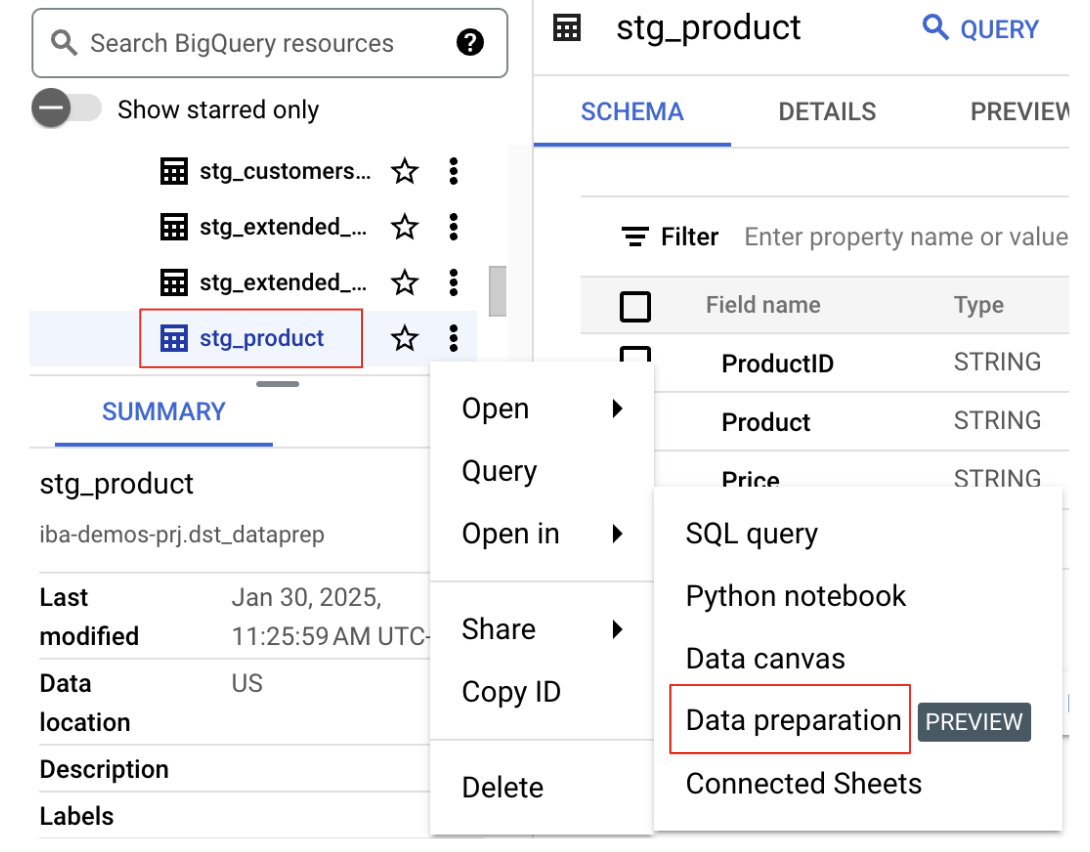
- Localisez l'ensemble de données et la table : dans le panneau "Explorateur", sélectionnez votre projet, puis recherchez l'ensemble de données inclus dans la fiche
bq data preparation demo. Sélectionnez la tablestg_product. - Ouvrir dans la préparation des données : cliquez sur les trois points verticaux à côté du nom de la table, puis sélectionnez
Open in Data Preparation.
La table s'ouvre dans l'interface de préparation des données, ce qui vous permet de commencer à transformer vos données.
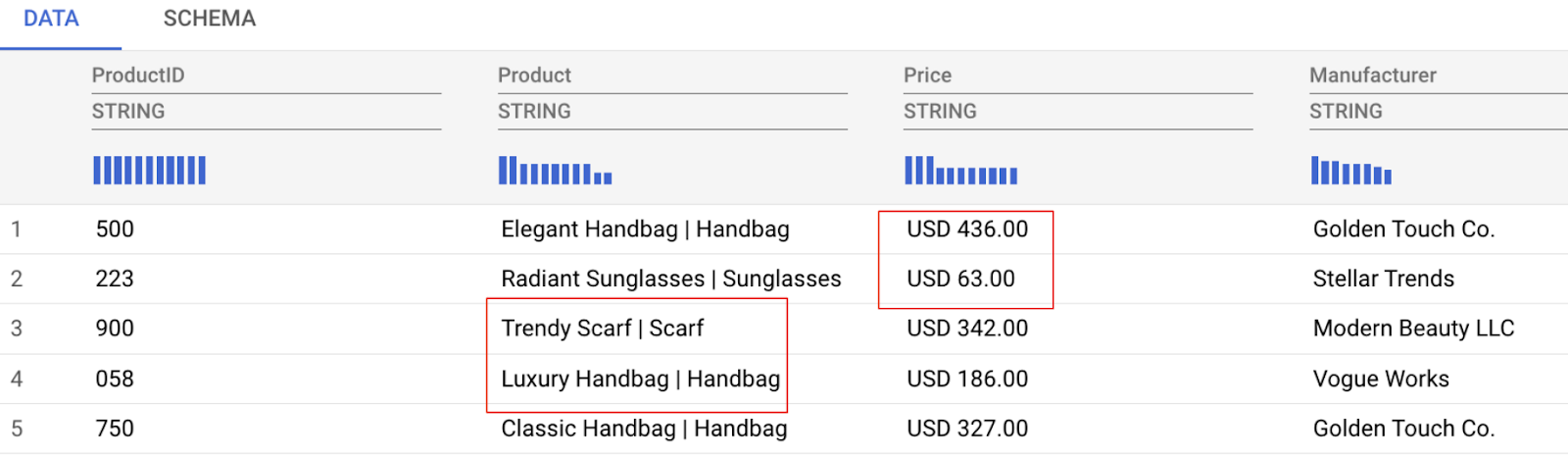
Comme vous pouvez le voir dans l'aperçu des données ci-dessous, nous allons devoir relever certains défis liés aux données, dont les suivants :
- La colonne "Prix" contient à la fois le montant et la devise, ce qui rend l'analyse difficile.
- La colonne "Produit" mélange le nom et la catégorie du produit (séparés par une barre verticale |).
Gemini analyse immédiatement vos données et suggère plusieurs transformations. Dans cet exemple, nous voyons plusieurs recommandations. Nous appliquerons celles dont nous avons besoin lors des prochaines étapes.

6. Gérer la colonne "Prix"
Commençons par la colonne Prix. Comme nous l'avons vu, il contient à la fois la devise et le montant. Notre objectif est de les séparer en deux colonnes distinctes : "Devise" et "Montant".
Gemini a identifié plusieurs recommandations pour la colonne "Prix".
- Recherchez une recommandation semblable à celle-ci :
Description : "Cette expression supprime le préfixe "USD " du champ spécifié"
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- Sélectionnez "Aperçu".
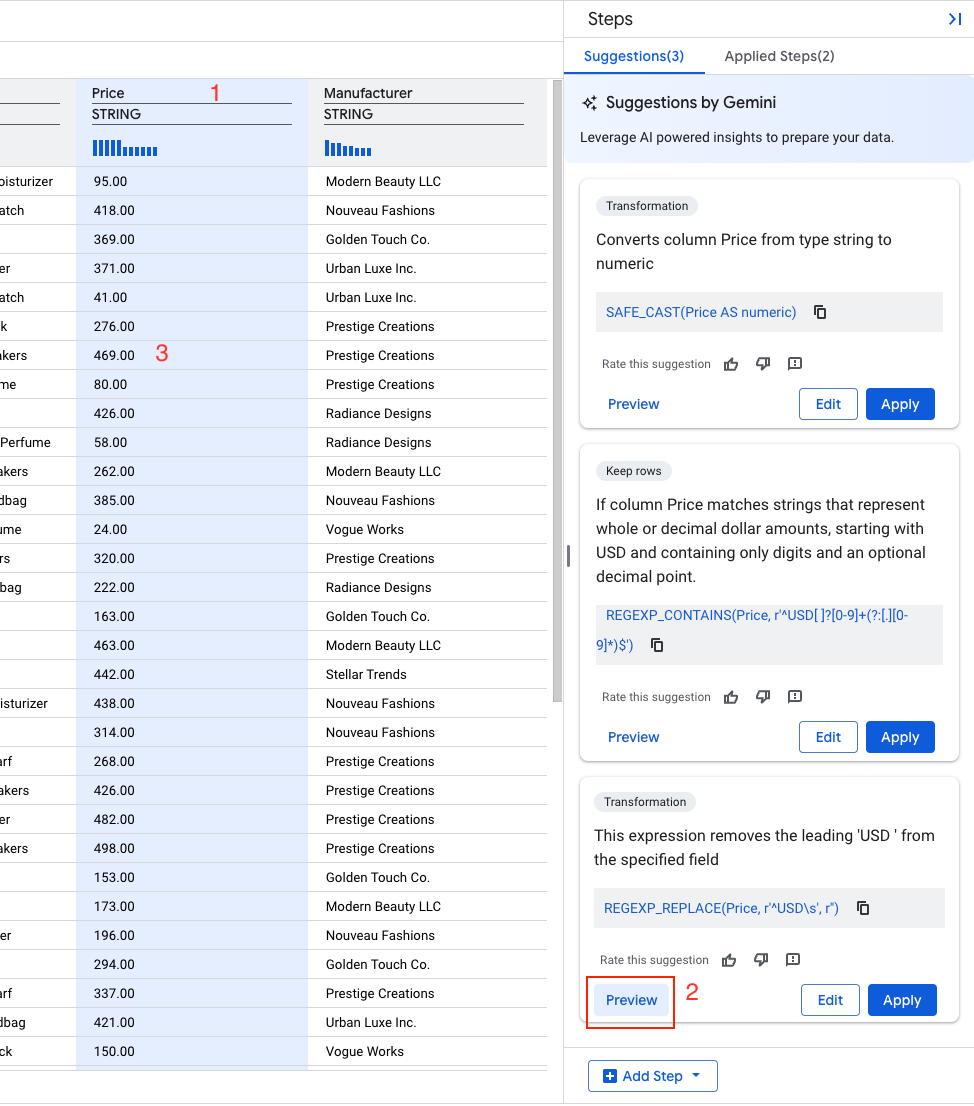
- Sélectionnez "Appliquer".
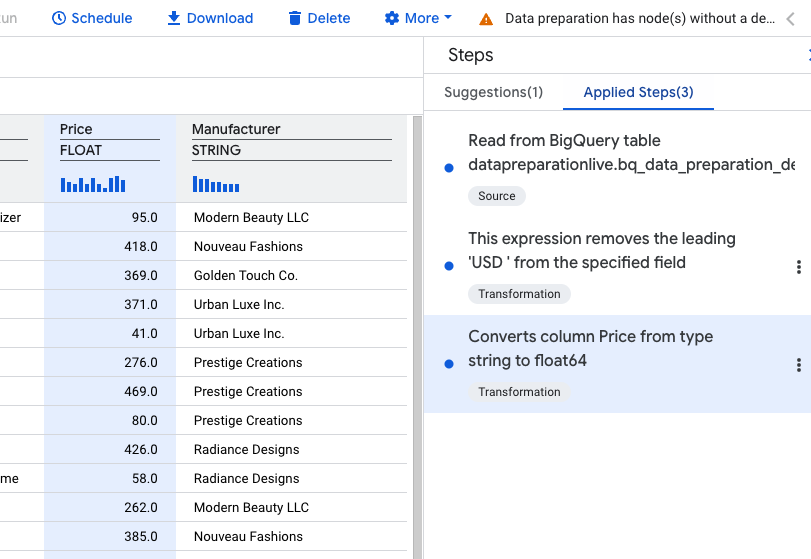
Ensuite, pour la colonne Price, convertissons le type de données de STRING en NUMERIC.
- Recherchez une recommandation semblable à celle-ci :
Description : "Convertit la colonne "Prix" du type chaîne en type float64"
SAFE_CAST(Price AS float64)
- Sélectionnez "Appliquer".
Trois étapes appliquées devraient maintenant s'afficher dans votre liste d'étapes.
7. Gérer la colonne "Produit"
La colonne "Produit" contient à la fois le nom et la catégorie du produit, séparés par une barre verticale (|).
Bien que nous puissions à nouveau utiliser le langage naturel, explorons une autre fonctionnalité puissante de Gemini.
Nettoyer le nom du produit
- Sélectionnez la partie de la catégorie d'une entrée de produit, y compris le caractère
|, puis supprimez-la.
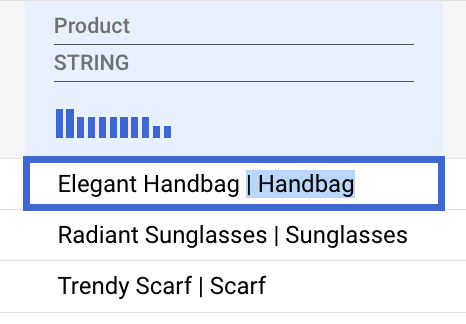
Gemini reconnaîtra intelligemment ce modèle et suggérera une transformation à appliquer à l'ensemble de la colonne.
- Sélectionnez "Modifier".

La recommandation de Gemini est parfaite : elle supprime tout ce qui se trouve après le caractère "|", isolant ainsi le nom du produit.
Mais cette fois, nous ne voulons pas écraser nos données d'origine.
- Dans le menu déroulant de la colonne cible, sélectionnez "Créer une colonne".
- Définissez le nom sur ProductName.
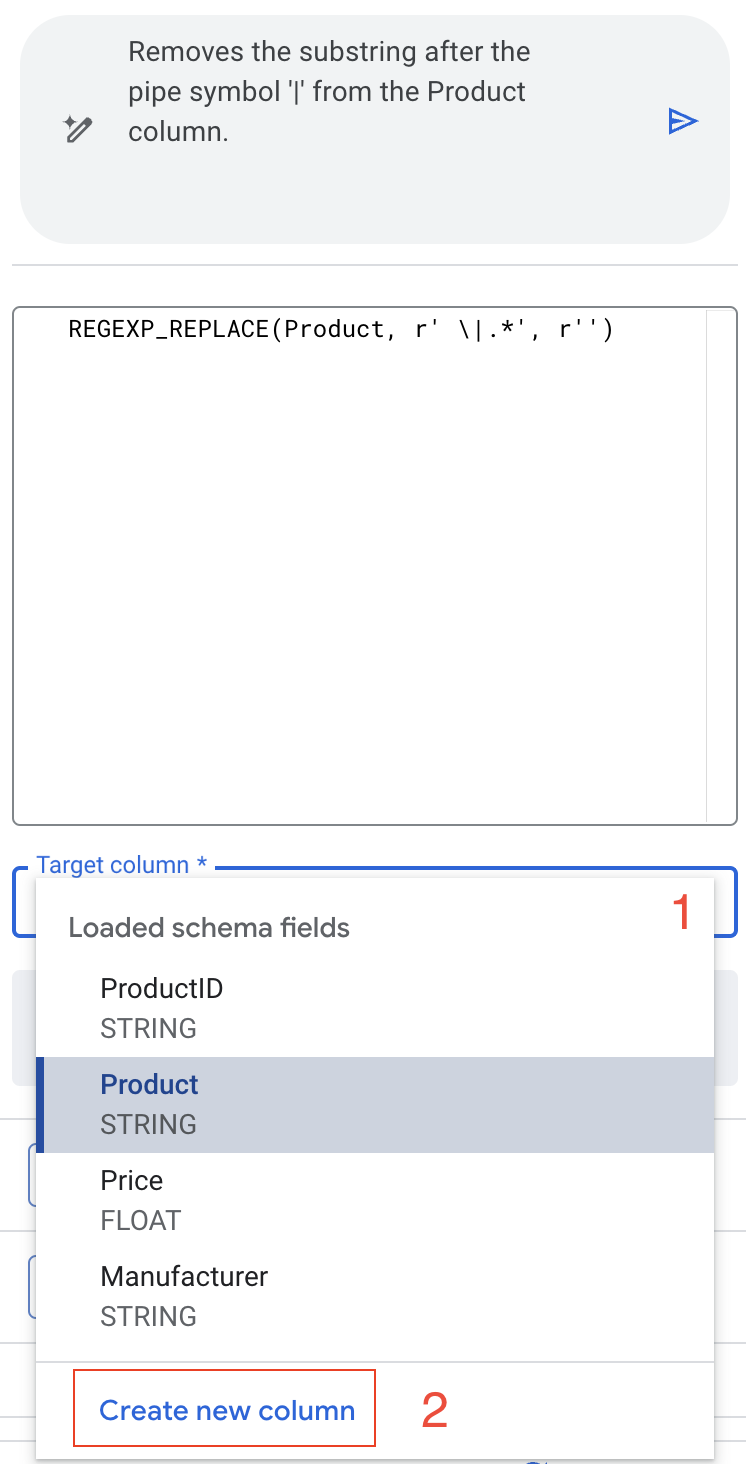
- Prévisualisez les modifications pour vous assurer que tout est correct.
- Appliquez la transformation.
Extraire la catégorie de produits
En langage naturel, nous allons demander à Gemini d'extraire le mot qui suit la barre verticale (|) dans la colonne "Produit". Cette valeur extraite sera écrasée dans la colonne existante "Produit".
- Cliquez sur
Add Steppour ajouter une étape de transformation.
- Sélectionnez
Transformationdans le menu déroulant. - Dans le champ de requête en langage naturel, saisissez "extraire le mot après le symbole | dans la colonne "Produit"", puis appuyez sur Entrée pour générer le code SQL.
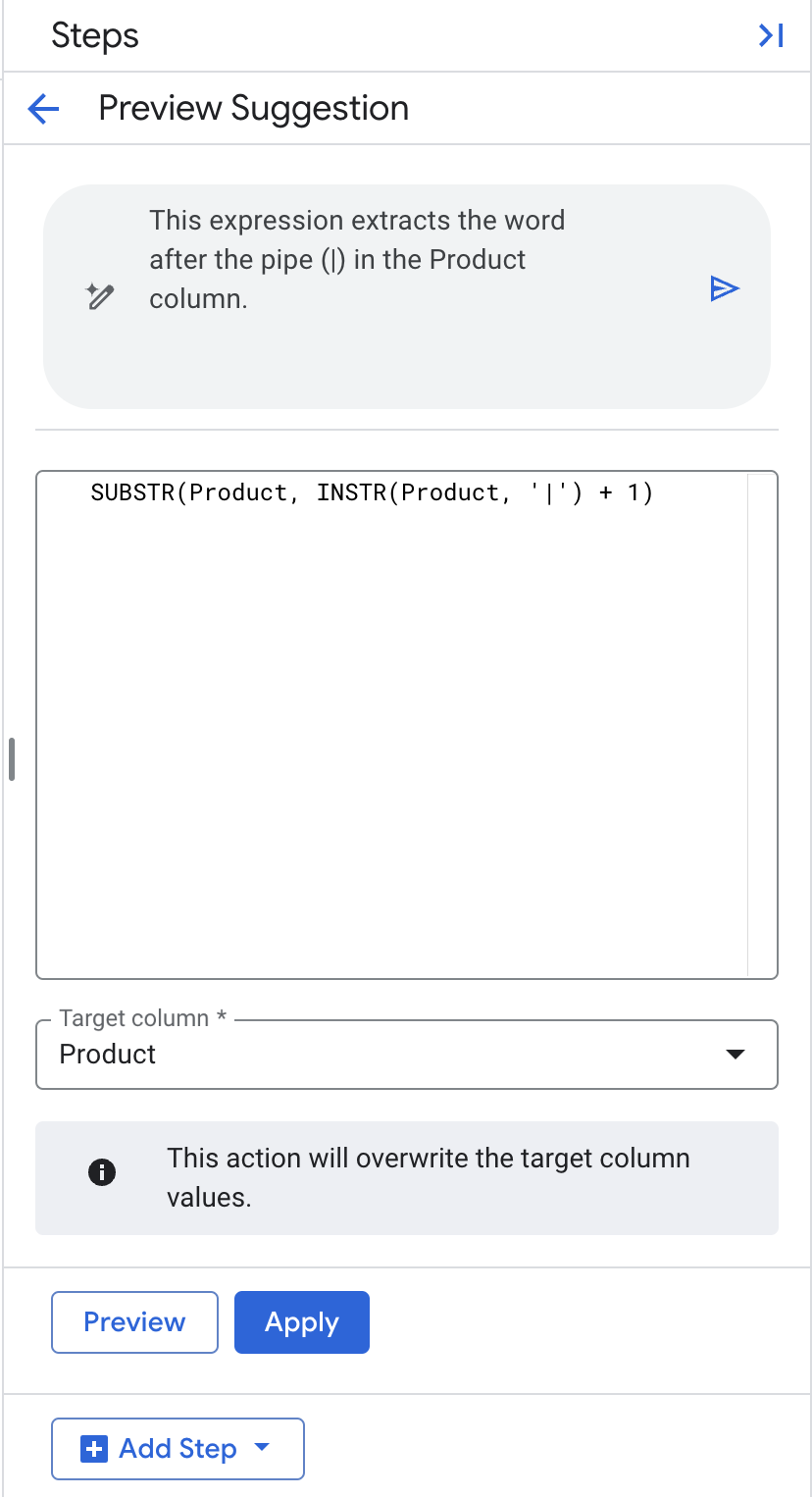
- Laissez la colonne cible définie sur "Produit".
- Cliquez sur "Appliquer".
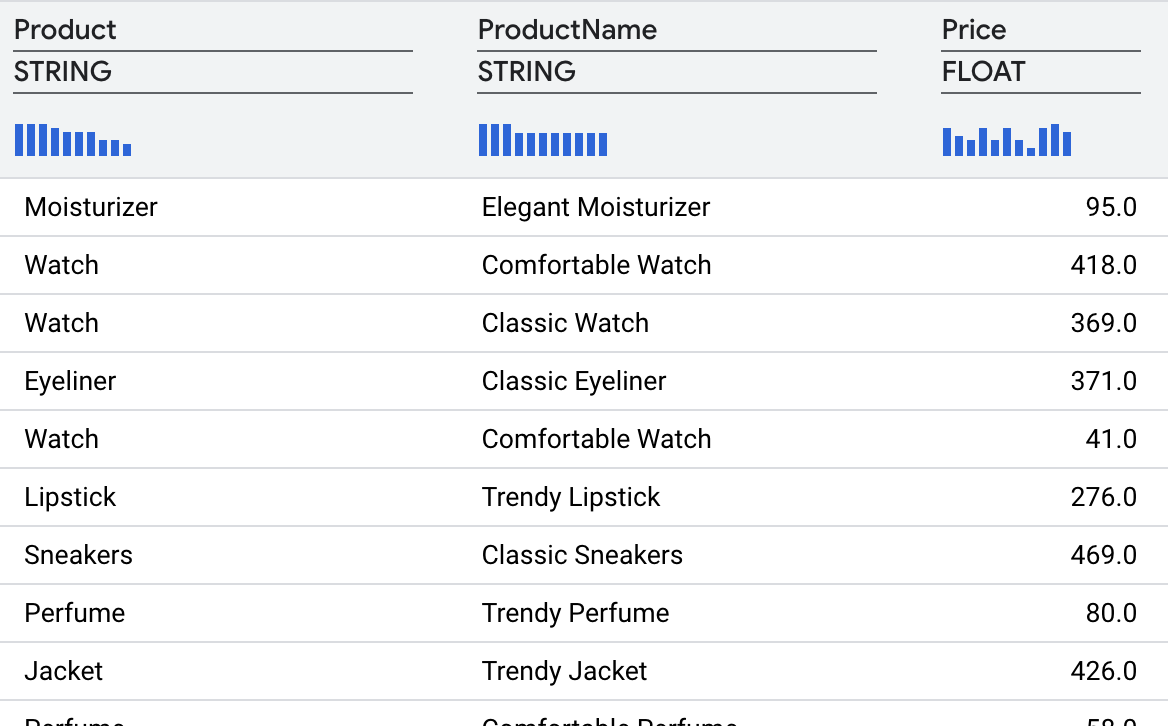
La transformation doit vous donner les résultats suivants.
8. Joindre pour enrichir les données
Vous aurez souvent besoin d'enrichir vos données avec des informations provenant d'autres sources. Dans notre exemple, nous allons joindre nos données produit aux attributs de produit étendus, stg_extended_product, à partir d'un tableau tiers. Ce tableau inclut des informations telles que la marque et la date de lancement.
- Cliquez sur
Add Step. - Sélectionner
Join - Accédez à la table
stg_extended_product.
Gemini dans BigQuery a automatiquement sélectionné la clé de jointure "productid" pour nous et a qualifié les côtés gauche et droit, car le nom de la clé est identique.
Remarque : Assurez-vous que le champ de description indique "Rejoindre par productid". S'il inclut des clés de jointure supplémentaires, remplacez le champ de description par "Joindre par productid", puis sélectionnez le bouton de génération dans le champ de description pour générer à nouveau l'expression de jointure avec la condition suivante : L.
productid
= R.
productid. 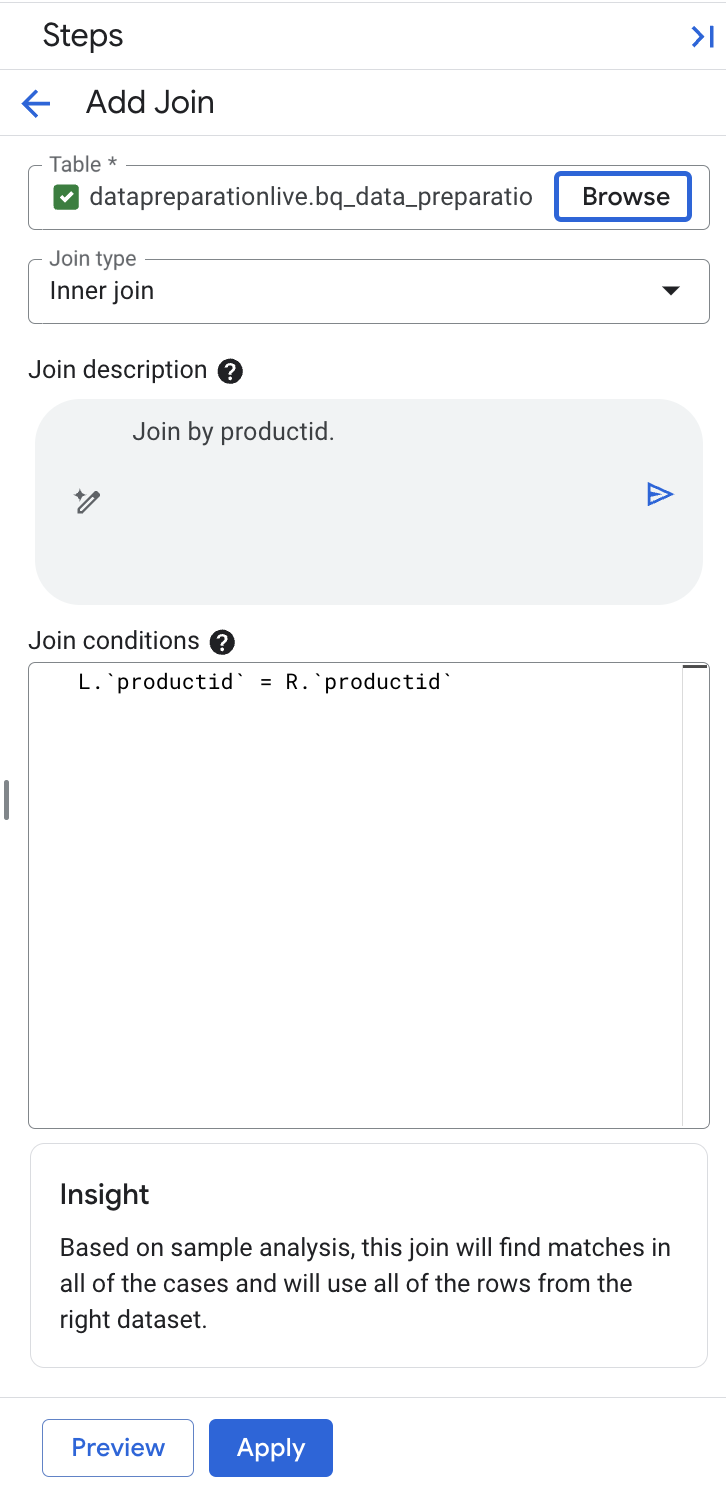
- Vous pouvez également sélectionner "Aperçu" pour prévisualiser les résultats.
- Cliquez sur
Apply.
Nettoyer les attributs étendus
La jointure a réussi, mais les données des attributs étendus nécessitent un nettoyage. La colonne LaunchDate présente des formats de date incohérents, et la colonne Brand contient des valeurs manquantes.
Commençons par la colonne LaunchDate.

Avant de créer des transformations, consultez les recommandations de Gemini.
- Cliquez sur le nom de la colonne
LaunchDate. Vous devriez voir des recommandations générées semblables à celles de l'image ci-dessous.
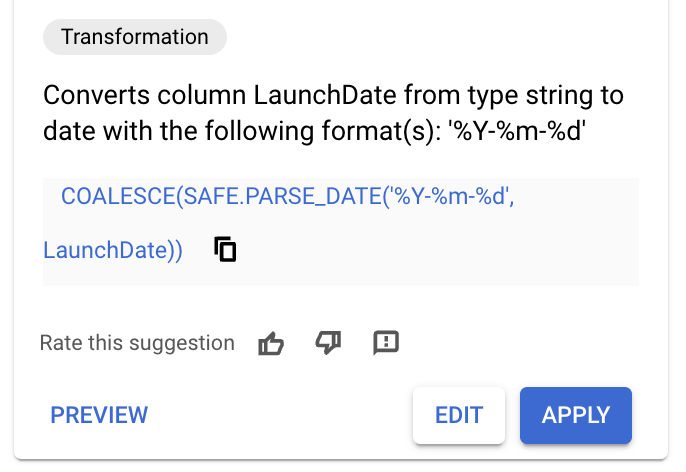
- Si vous voyez une recommandation avec la requête SQL suivante, cliquez sur Appliquer et ignorez les étapes suivantes.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Si aucune recommandation ne correspond à la requête SQL ci-dessus, cliquez sur
Add Step. - Sélectionnez
Transformation. - Dans le champ SQL, saisissez ce qui suit :
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Définissez
Target ColumnssurLaunchDate. - Cliquez sur
Apply.
La colonne "LaunchDate" (Date de lancement) présente désormais un format de date cohérent.

9. Ajouter une table de destination
Notre ensemble de données est maintenant propre et prêt à être chargé dans une table de dimension de notre entrepôt de données.
- Cliquez sur
ADD STEP. - Sélectionnez
Destination. - Renseignez les paramètres requis : Ensemble de données :
bq_data_preparation_demoTable :DimProduct - Cliquez sur
Save.

Nous avons maintenant travaillé avec les onglets "Données" et "Schéma". En plus de ces éléments, la préparation des données BigQuery fournit une vue "Graphique" qui affiche visuellement la séquence des étapes de transformation dans votre pipeline.
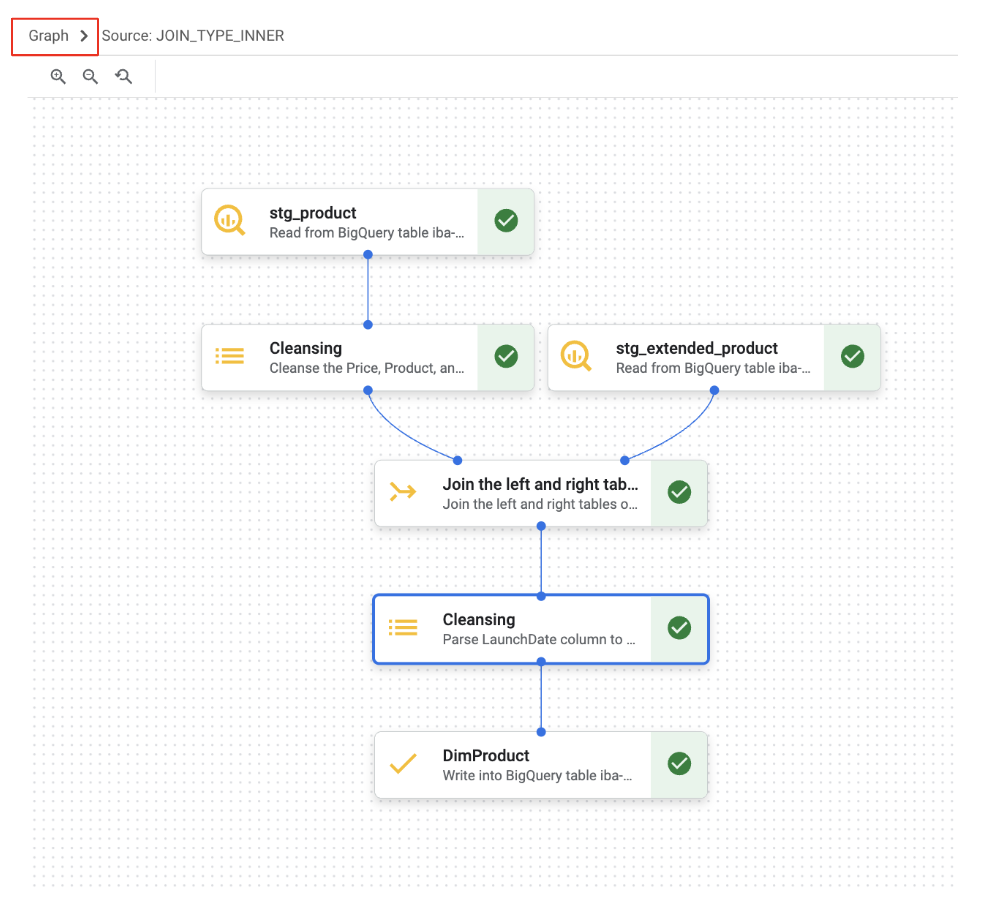
10. Bonus A : Gérer la colonne "Fabricant" et créer un tableau des erreurs
Nous avons également identifié des valeurs vides dans la colonne Manufacturer. Pour ces enregistrements, nous souhaitons implémenter un contrôle de la qualité des données et les déplacer vers une table d'erreurs pour un examen plus approfondi.
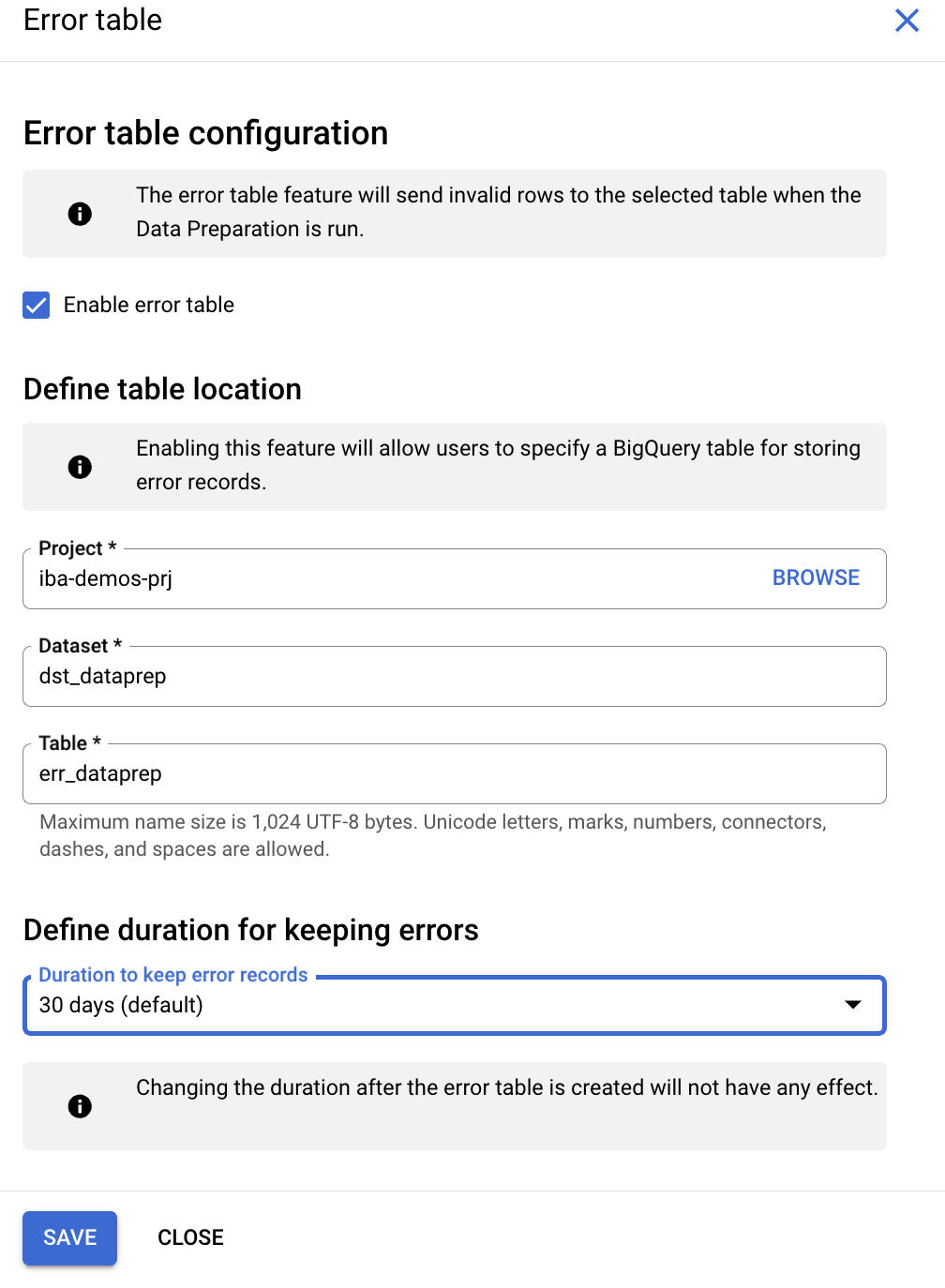
Créer un tableau d'erreurs
- Cliquez sur le bouton
Moreà côté du titrestg_product data preparation. - Dans la section
Setting, sélectionnezError Table. - Cochez la case
Enable error table, puis configurez les paramètres comme suit :
- Ensemble de données : sélectionnez
bq_data_preparation_demo. - Table : saisissez
err_dataprep. - Sous
Define duration for keeping errors, sélectionnez30 days (default).
- Cliquez sur
Save.
Configurer la validation dans la colonne "Fabricant"
- Sélectionnez la colonne "Fabricant".
- Gemini aura probablement identifié une transformation pertinente. Recherchez la recommandation qui ne conserve que les lignes où le champ "Fabricant" n'est pas vide. Le code SQL ressemblera à ceci :
Manufacturer IS NOT NULL
2.Cliquez sur le bouton "Modifier" de cette recommandation pour l'examiner.
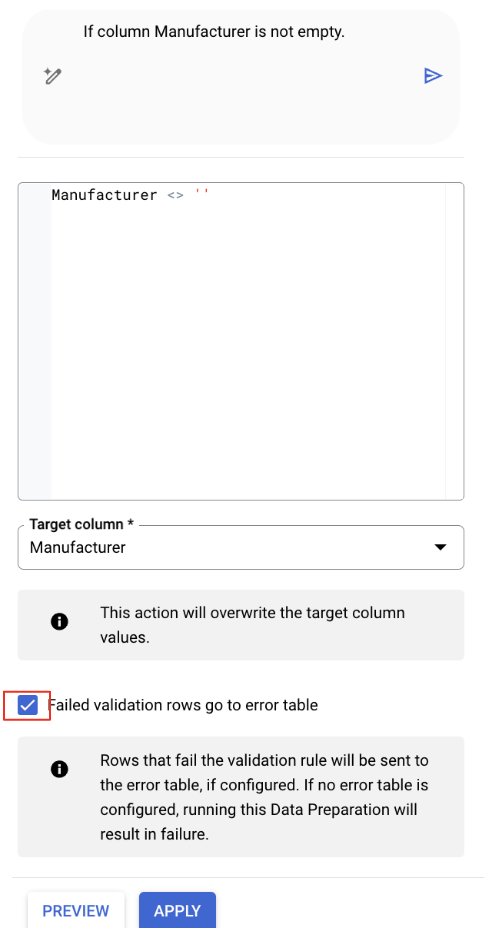
- Cochez l'option Les lignes de validation ayant échoué sont envoyées vers la table d'erreurs si elle n'est pas cochée.
- Cliquez sur
Apply.
À tout moment, vous pouvez examiner, modifier ou supprimer les transformations que vous avez appliquées en cliquant sur le bouton "Étapes appliquées".
Nettoyer la colonne ProductID_1 redondante
Vous pouvez maintenant supprimer la colonne "ProductID_1", qui duplique la colonne "ProductID" de notre tableau joint.
- Accédez à l'onglet
Schema. - Cliquez sur les trois points à côté de la colonne
ProductID_1. - Cliquez sur
Drop.
Nous sommes maintenant prêts à exécuter le job de préparation des données et à valider l'ensemble de notre pipeline. Une fois que nous sommes satisfaits des résultats, nous pouvons programmer l'exécution automatique du job.
- Avant de quitter la vue de préparation des données, enregistrez vos préparations. À côté du titre
stg_product data preparation, un boutonSavedevrait s'afficher. Cliquez sur le bouton pour enregistrer.
11. Nettoyer l'environnement
- Supprimez
stg_product data preparation. - Supprimer l'ensemble de données
bq data preparation demo
12. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Configurer la préparation des données
- Ouvrir des tableaux et parcourir la préparation des données
- Fractionner des colonnes contenant des données numériques et des données de description d'unité
- Standardiser les formats de date
- Exécuter des préparations de données