
1. Введение
Представьте, что вы можете быстрее и эффективнее подготавливать данные к анализу, не будучи экспертом в программировании. С функцией подготовки данных BigQuery это становится реальностью. Эта мощная функция упрощает ввод, преобразование и очистку данных, предоставляя подготовку данных в руки всех специалистов по работе с данными в вашей организации.
Готовы раскрыть секреты, скрытые в данных о вашей продукции?
Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовое понимание SQL
Что вы узнаете
- Как подготовка данных в BigQuery может очистить и преобразовать ваши исходные данные в полезную бизнес-аналитику, на реалистичном примере из индустрии моды и красоты.
- Как запустить и запланировать подготовку данных для очищенных данных
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
2. Основные настройки и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .

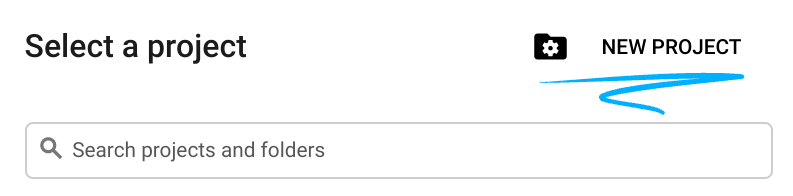
- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
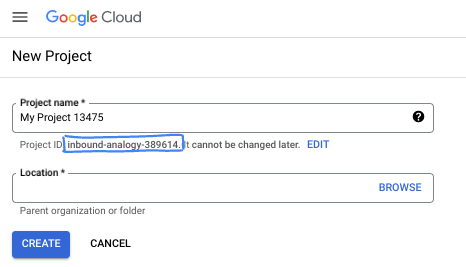
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
3. Прежде чем начать
Включить API
Для использования Gemini в BigQuery необходимо включить API Gemini для Google Cloud. Обычно этот шаг выполняет администратор сервиса или владелец проекта с разрешением IAM serviceusage.services.enable .
- Чтобы включить API Gemini для Google Cloud, перейдите на страницу Gemini для Google Cloud в Google Cloud Marketplace. Перейдите на страницу Gemini для Google Cloud.
- В окне выбора проекта выберите проект.
- Нажмите «Включить» . Страница обновится и отобразит статус «Включено» . Gemini в BigQuery теперь доступен в выбранном проекте Google Cloud всем пользователям, имеющим необходимые разрешения IAM.
Настройте роли и права доступа для разработки процессов подготовки данных.
- В разделе IAM и администрирование выберите IAM.
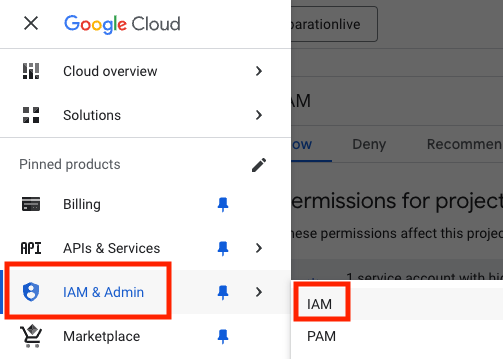
- Выберите пользователя и нажмите на значок карандаша, чтобы «Изменить данные руководителя».
Для использования функции подготовки данных BigQuery вам потребуются следующие роли и разрешения:
- Редактор данных BigQuery (roles/bigquery.dataEditor)
- Потребитель использования сервиса (roles/serviceusage.serviceUsageConsumer)
4. Поиск и подписка на демонстрационную версию «bq data preparation demo» в BigQuery Analytics Hub.
В этом уроке мы будем использовать bq data preparation demo . Это связанный набор данных в BigQuery Analytics Hub, из которого мы будем считывать данные.
Подготовка данных никогда не включает запись обратно в исходный файл, и мы попросим вас определить целевую таблицу для записи. Таблица, с которой мы будем работать в этом упражнении, содержит всего 1000 строк, чтобы минимизировать затраты, но подготовка данных выполняется на BigQuery и будет масштабироваться параллельно.
Выполните следующие шаги, чтобы найти связанный набор данных и подписаться на него:
- Для доступа к Analytics Hub : в консоли Google Cloud перейдите в раздел BigQuery.
- В меню навигации BigQuery в разделе «Управление» выберите «Центр аналитики».
- Поиск объявления: В интерфейсе центра аналитики нажмите «Поиск объявлений ».
- Введите в строку поиска
bq data preparation demoи нажмите Enter.
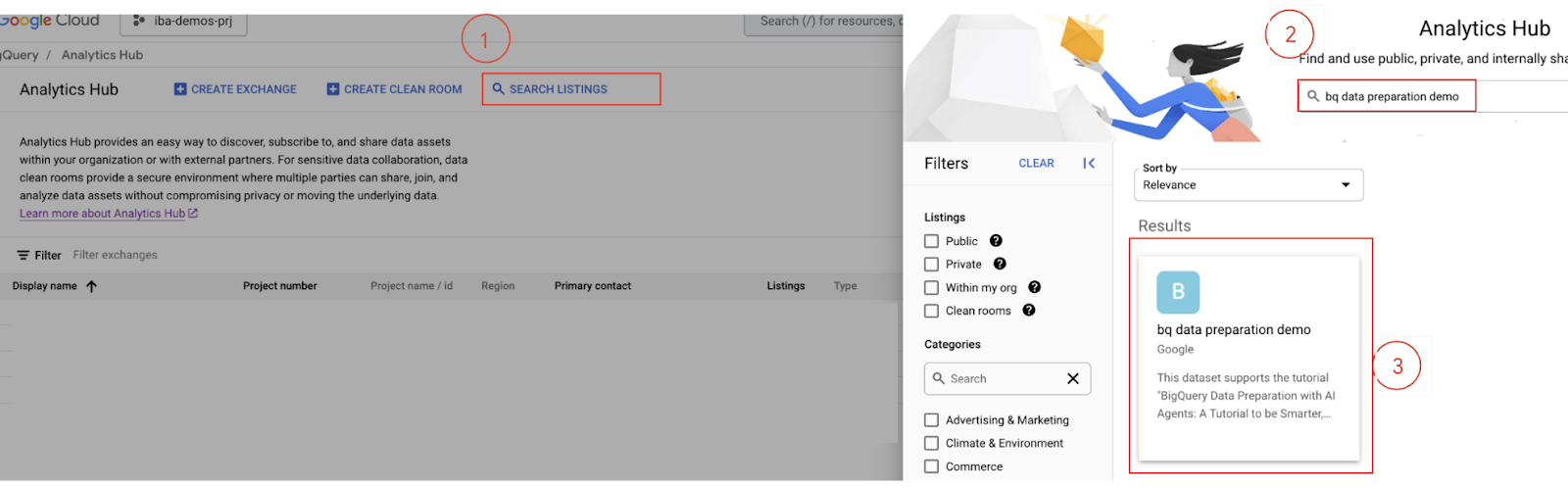
- Подпишитесь на рассылку: выберите
bq data preparation demoиз результатов поиска. - На странице с подробной информацией о товаре нажмите кнопку «Подписаться» .
- Просмотрите все диалоговые окна подтверждения и при необходимости обновите проект/набор данных. Настройки по умолчанию должны быть правильными.
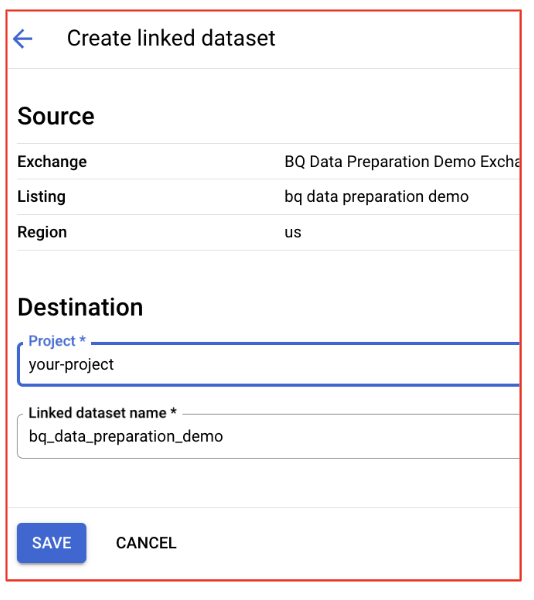
- Доступ к набору данных в BigQuery: После успешной подписки наборы данных из списка будут связаны с вашим проектом BigQuery.
Вернуться в BigQuery Studio .
5. Изучите данные и запустите подготовку данных.
- Найдите набор данных и таблицу: на панели «Проводник» выберите свой проект, а затем найдите набор данных, который был включен в
bq data preparation demo. Выберите таблицуstg_product. - Открыть в режиме подготовки данных: Щелкните три вертикальные точки рядом с названием таблицы и выберите
Open in Data Preparation.
Это откроет таблицу в интерфейсе подготовки данных, готовую к преобразованию ваших данных.
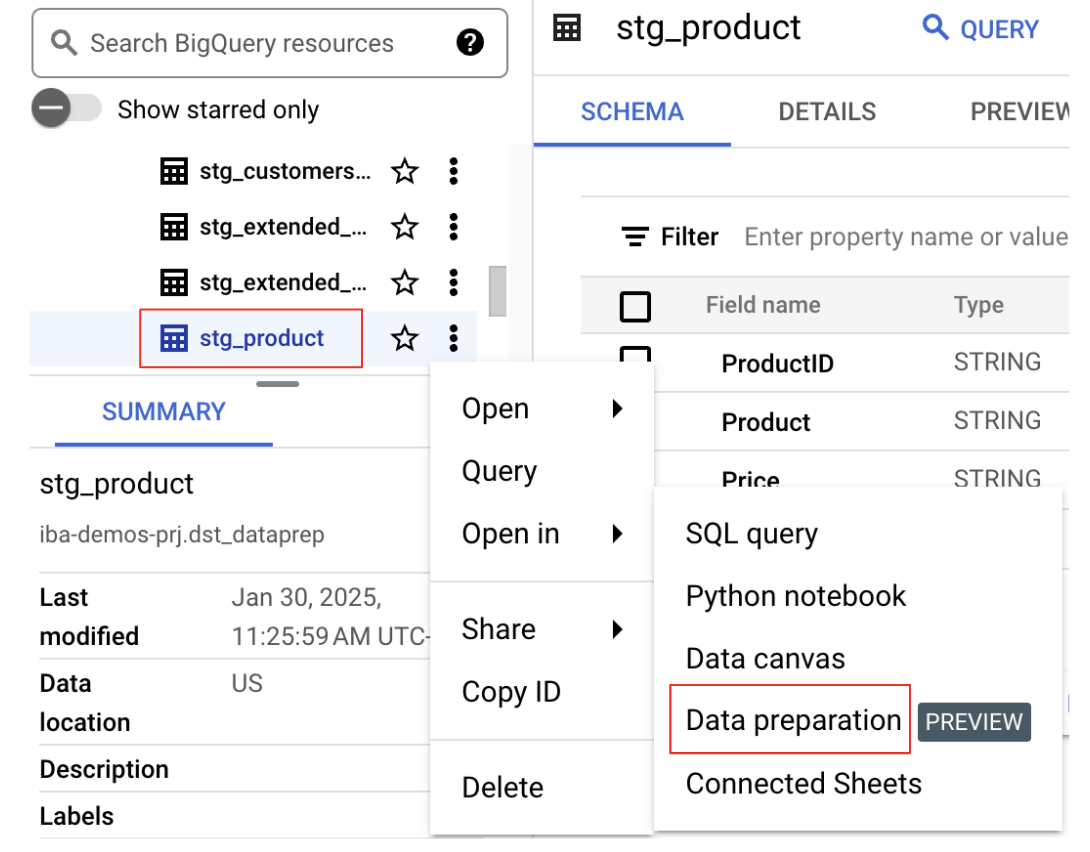
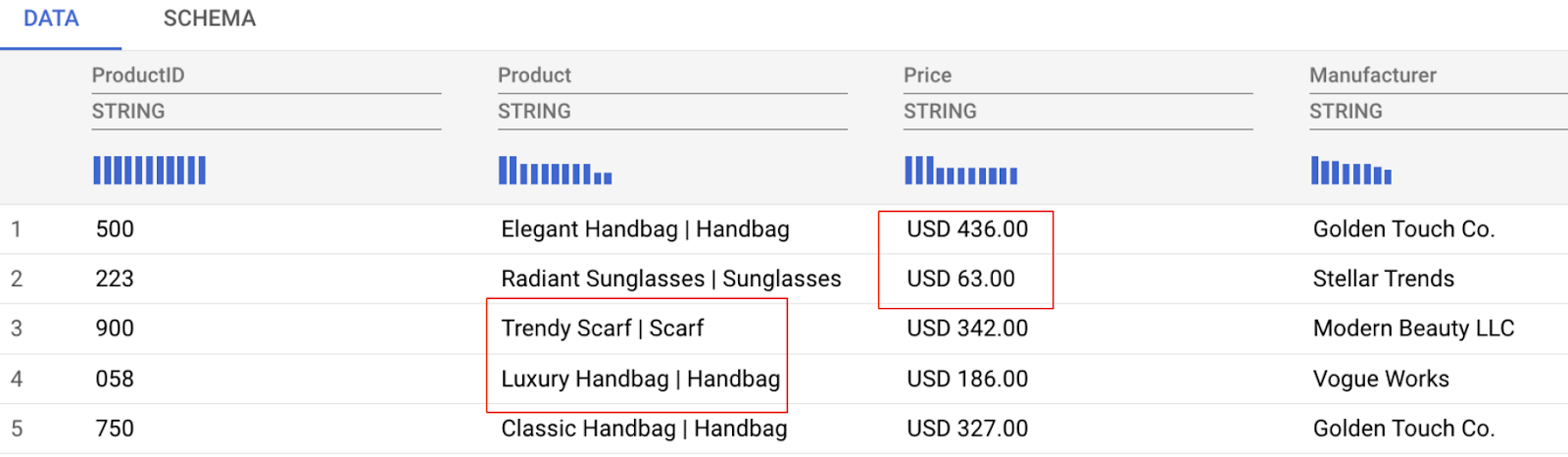
Как вы можете видеть в предварительном просмотре данных ниже, у нас есть несколько задач по работе с данными, которые мы будем решать, в том числе:
- В столбце «Цена» указаны как сумма, так и валюта, что затрудняет анализ.
- В столбце «Товар» название товара и категория указаны вместе (разделены символом вертикальной черты |).
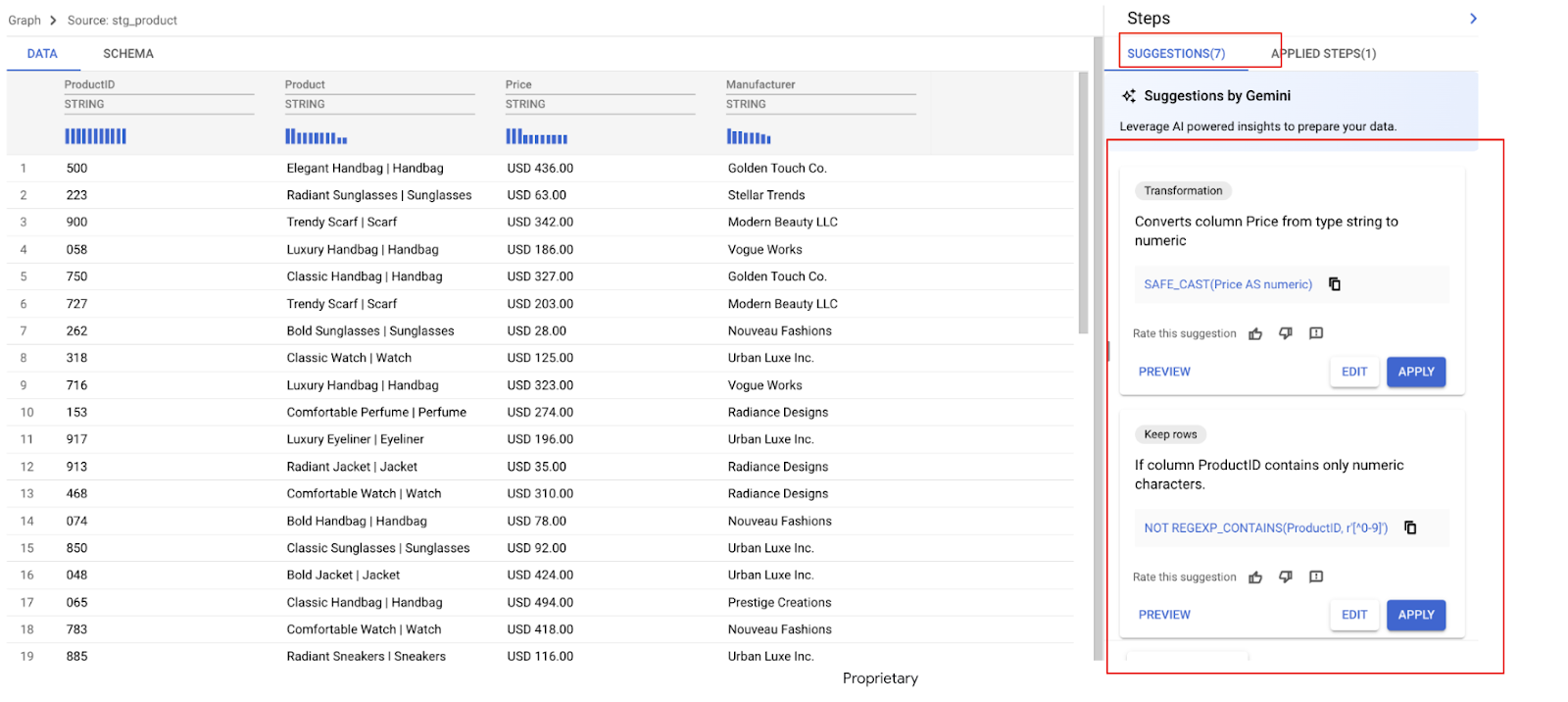
Сразу же Gemini анализирует ваши данные и предлагает несколько преобразований. В этом примере мы видим ряд рекомендаций . На следующих шагах мы применим те, которые нам необходимы.
6. Работа с ценовым столбцом
Давайте разберемся со столбцом «Цена» . Как мы уже видели, он содержит как валюту, так и сумму. Наша цель — разделить их на два отдельных столбца: «Валюта» и «Сумма» .
Компания Gemini выделила несколько рекомендаций для рубрики «Цены».
- Найдите рекомендацию, содержащую примерно следующее:
Описание: "Это выражение удаляет начальный символ 'USD' из указанного поля"
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- Выберите «Предварительный просмотр»
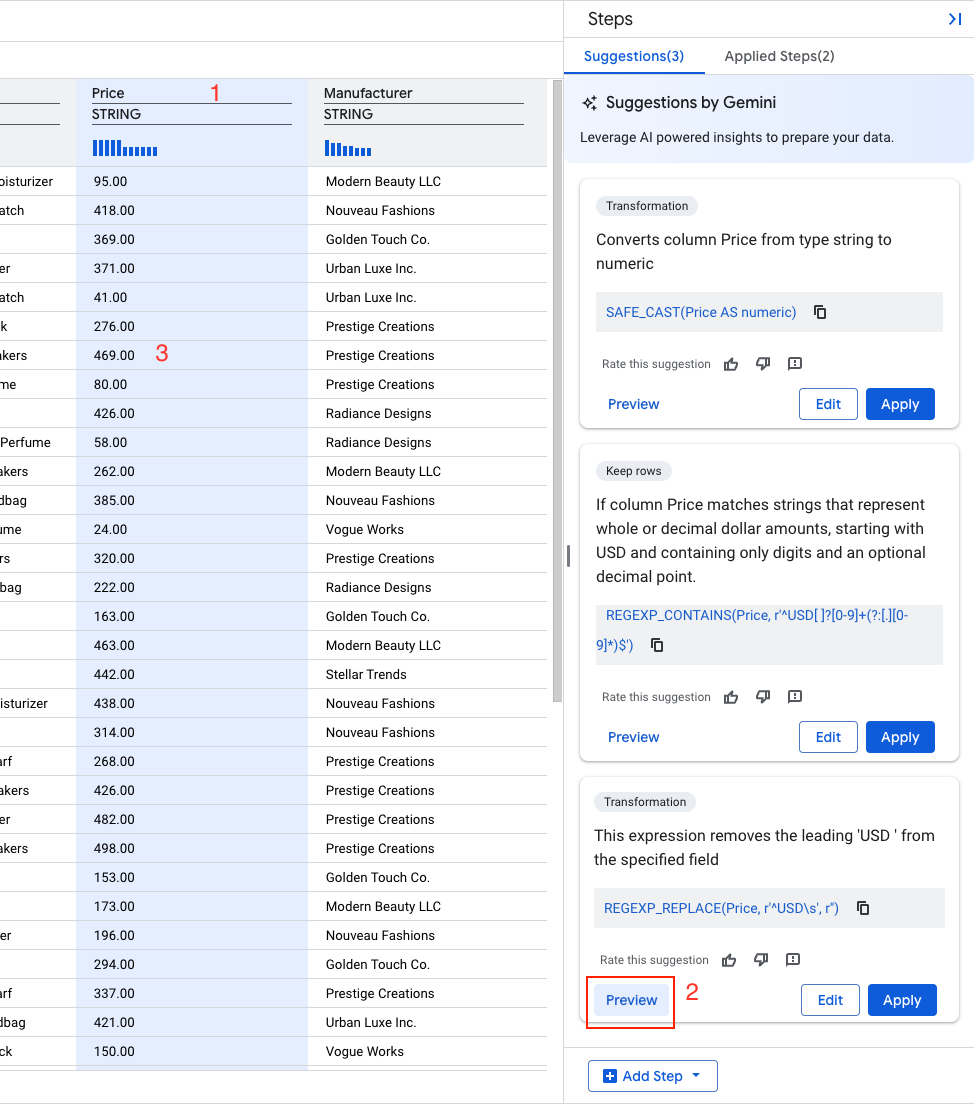
- Выберите «Применить»
Далее, для столбца «Цена» преобразуем тип данных из строкового в числовой .
- Найдите рекомендацию, содержащую примерно следующее:
Описание: "Преобразует столбец Price из строкового типа в тип float64"
SAFE_CAST(Price AS float64)
- Нажмите «Применить».
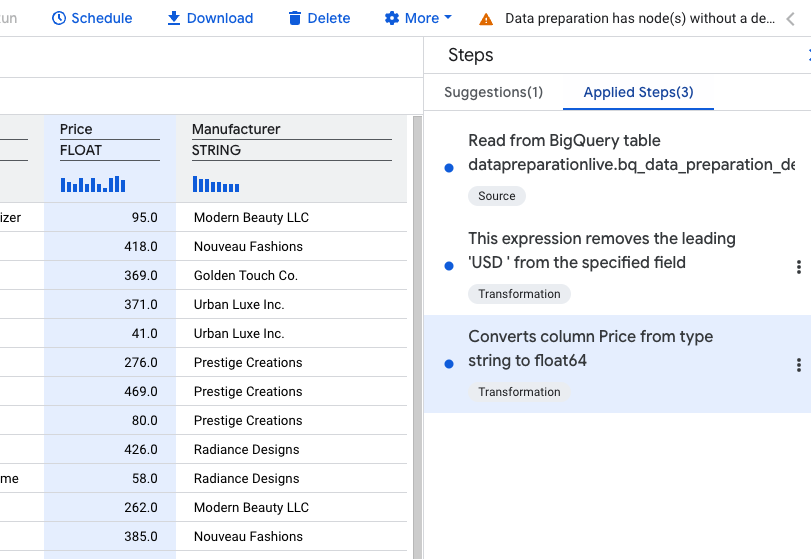
Теперь в списке выполненных шагов должны отображаться три уже примененных шага.
7. Работа со столбцом «Продукт».
В столбце «Товар» указаны как название товара, так и категория, разделённые вертикальной чертой (|).
Хотя мы могли бы снова использовать естественный язык, давайте рассмотрим еще одну мощную особенность Gemini.
Исправьте название продукта.
- Выделите часть записи о товаре, содержащую категорию, включая символ
|", и удалите её.
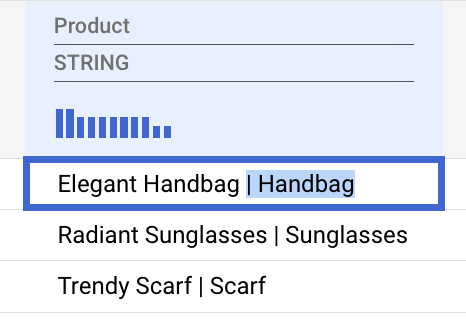
Близнецы умело распознают эту закономерность и предложат преобразование, которое следует применить ко всей колонке.
- Выберите «Редактировать».
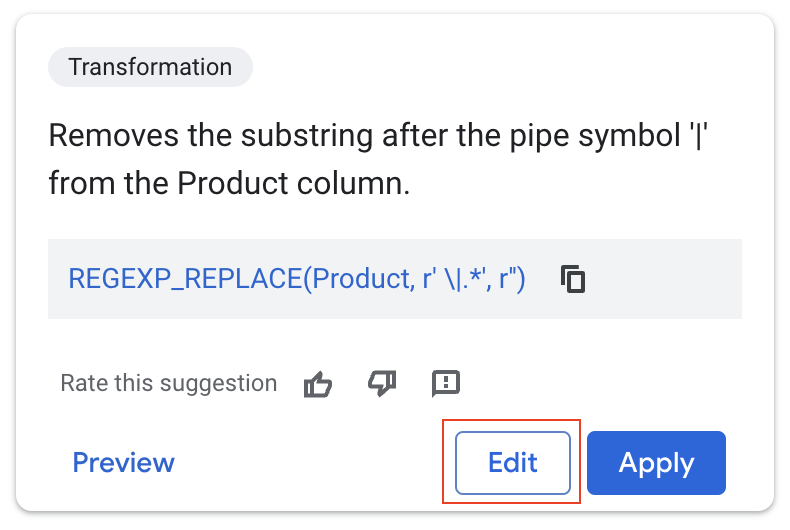
Рекомендация Gemini абсолютно верна: она удаляет все, что находится после символа '|', эффективно изолируя название продукта.
Но на этот раз мы не хотим перезаписывать исходные данные.
- В раскрывающемся списке «Целевой столбец» выберите «Создать новый столбец».
- Задайте имя ProductName .
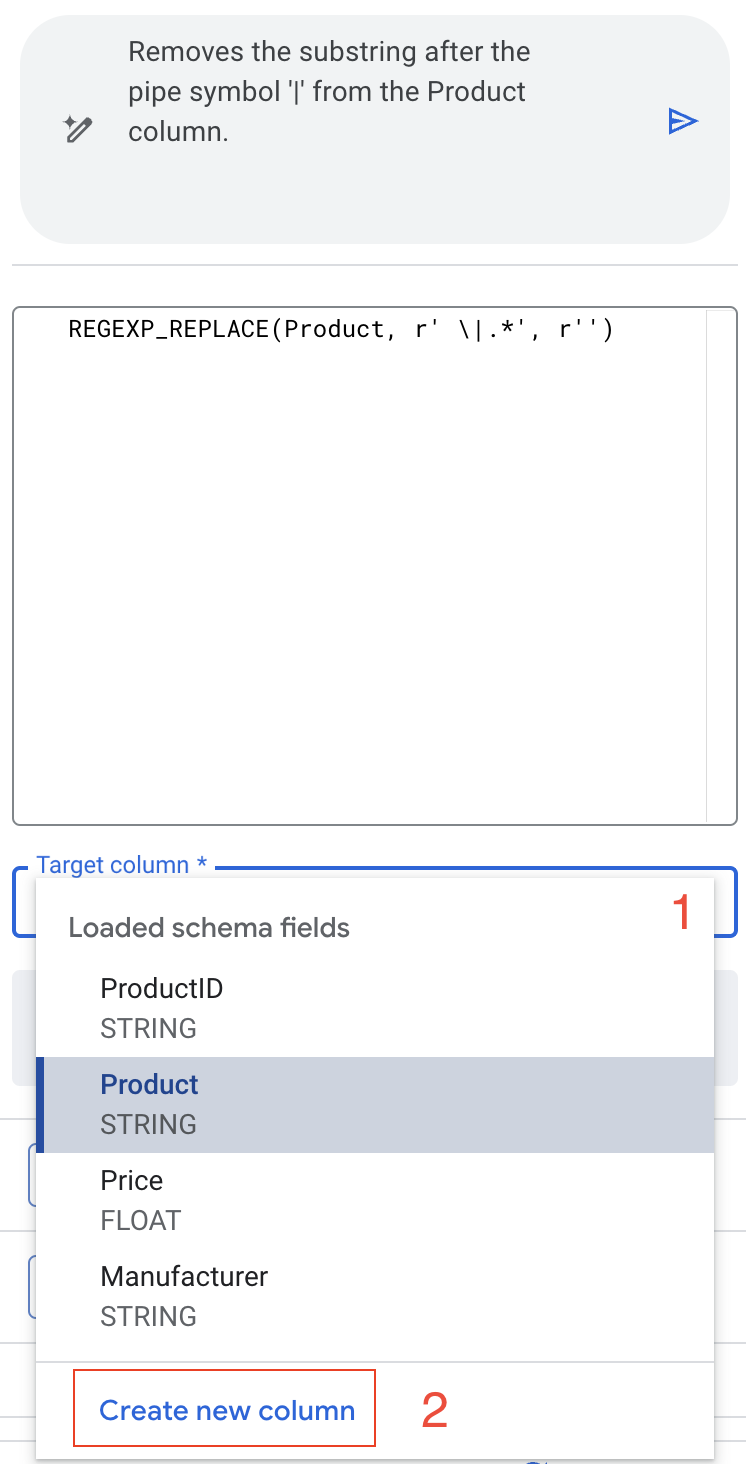
- Предварительно просмотрите изменения, чтобы убедиться, что всё выглядит хорошо.
- Примените преобразование.
Извлечь категорию товара
Используя естественный язык, мы дадим указание Gemini извлечь слово после вертикальной черты (|) в столбце «Продукт». Это извлеченное значение будет перезаписано в существующий столбец под названием «Продукт».
- Нажмите
Add Step, чтобы добавить новый шаг преобразования.
- Выберите
Transformationиз выпадающего меню. - В поле запроса на естественном языке введите «извлечь слово после вертикальной черты (|) в столбце «Продукт»», затем нажмите Enter , чтобы сгенерировать SQL-запрос.
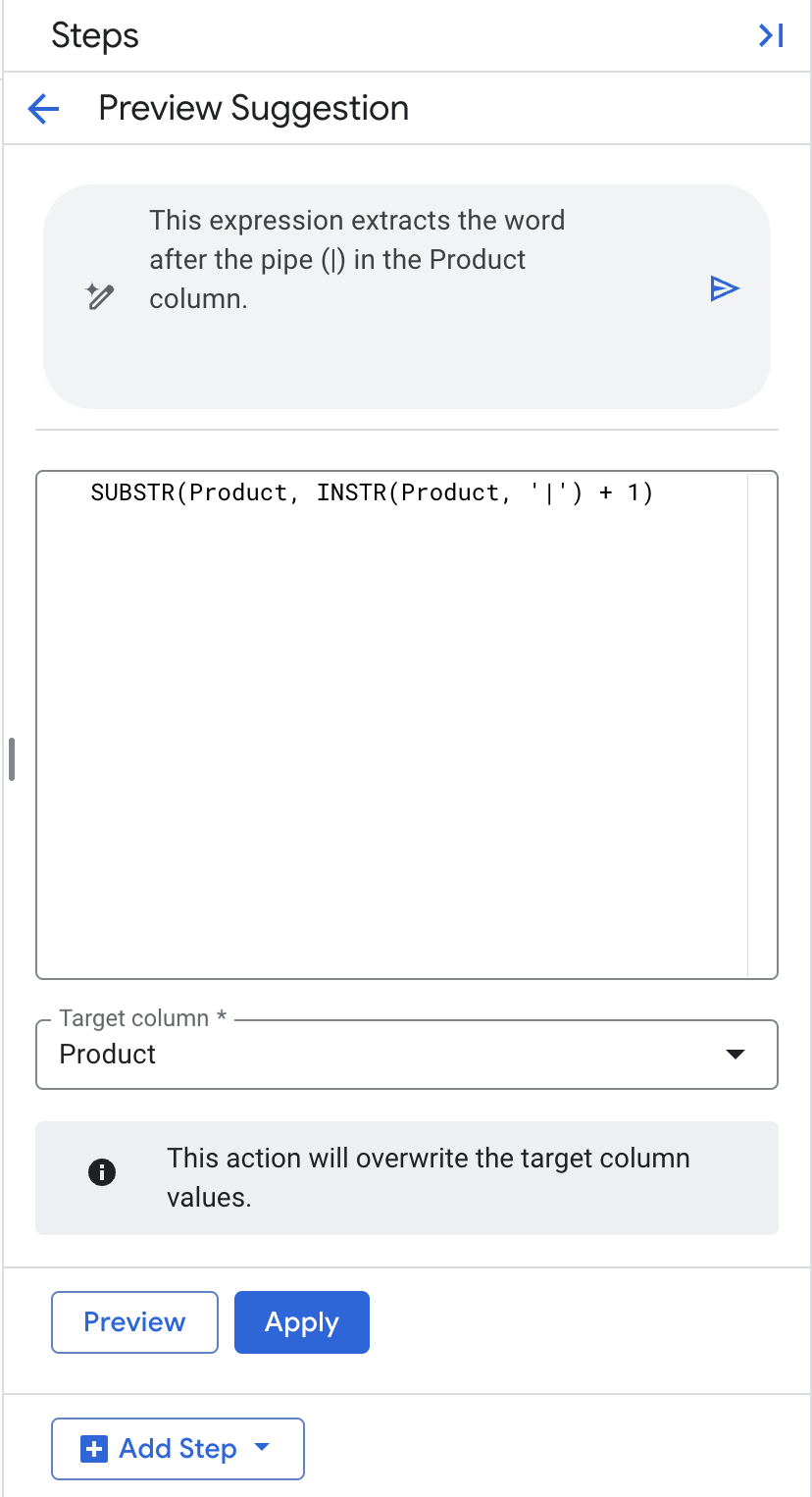
- Оставьте столбец «Цель» пустым, указав значение «Продукт».
- Нажмите «Применить».
В результате преобразования должны получиться следующие результаты.
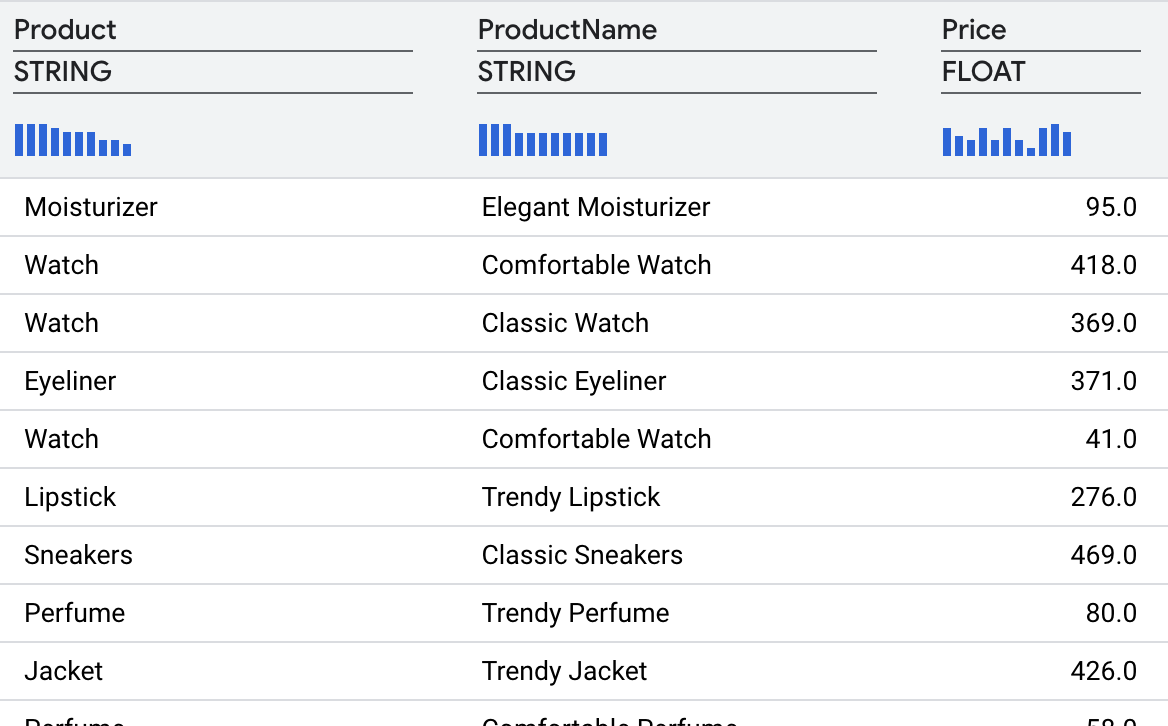
8. Объединение данных для их обогащения.
Часто возникает необходимость обогатить данные информацией из других источников. В нашем примере мы объединим данные о продукте с расширенными атрибутами продукта, stg_extended_product , из сторонней таблицы. Эта таблица содержит такие сведения, как бренд и дата выпуска.
- Нажмите «
Add Step - Выберите
Join - Перейдите к таблице
stg_extended_product.
В BigQuery Gemini автоматически определил ключ соединения productid и выполнил квалификацию левой и правой частей, поскольку имена ключей идентичны.
Примечание: Убедитесь, что в поле описания указано «Объединение по productid». Если оно содержит дополнительные ключи объединения, замените поле описания на «Объединение по productid» и выберите кнопку «Сгенерировать» в поле описания, чтобы повторно сгенерировать выражение объединения со следующим условием L.
productid
= Р.
productid . 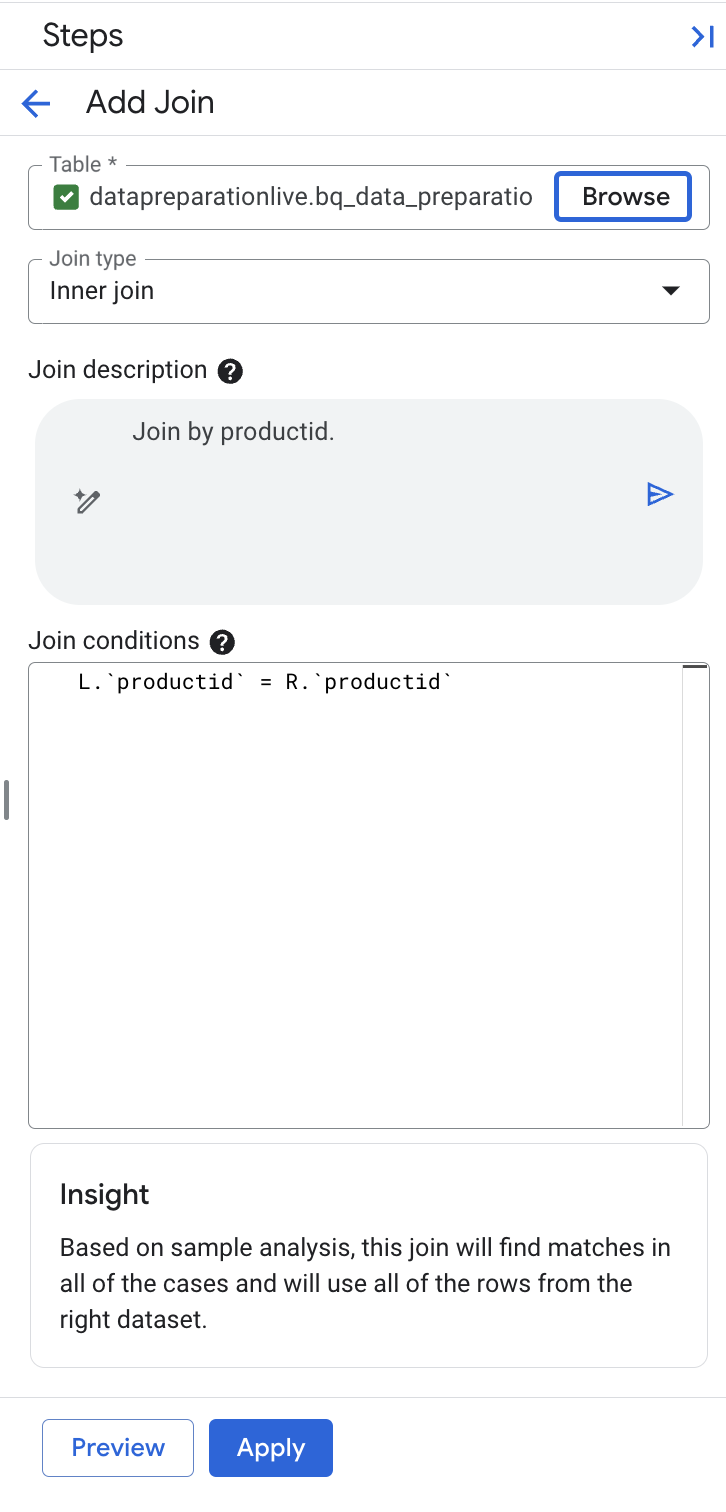
- При желании выберите «Предварительный просмотр», чтобы просмотреть результаты.
- Нажмите
Apply.
Очистка расширенных атрибутов
Несмотря на успешное объединение, данные расширенных атрибутов нуждаются в некоторой очистке. В столбце LaunchDate наблюдаются несогласованные форматы дат, а в столбце Brand присутствуют пропущенные значения.
Начнём с рассмотрения столбца LaunchDate .

Перед выполнением каких-либо преобразований ознакомьтесь с рекомендациями Gemini.
- Щёлкните по названию столбца
LaunchDate. Вы увидите несколько сгенерированных рекомендаций, похожих на те, что показаны на изображении ниже.
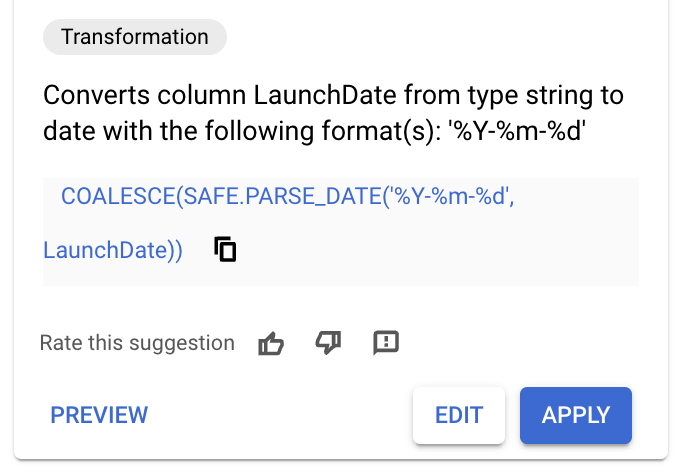
- Если вы видите рекомендацию со следующим SQL-запросом, примените её и пропустите следующие шаги.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Если вы не нашли рекомендацию, соответствующую приведенному выше SQL-запросу, нажмите
Add Step. - Выберите
Transformation. - В поле SQL введите следующее:
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Установите
Target ColumnsвLaunchDate. - Нажмите
Apply.
Теперь столбец LaunchDate имеет единый формат даты.

9. Добавление целевой таблицы
Наш набор данных теперь очищен и готов к загрузке в таблицу измерений в нашем хранилище данных.
- Нажмите
ADD STEP. - Выберите
Destination. - Укажите необходимые параметры: Набор данных:
bq_data_preparation_demoТаблица:DimProduct - Нажмите «
Save».

Мы уже поработали с вкладками «Данные» и «Схема». В дополнение к ним, BigQuery Data Preparation предоставляет представление «График», которое визуально отображает последовательность шагов преобразования в вашем конвейере.

10. Бонус A: Обработка столбца «Производитель» и создание таблицы ошибок.
Мы также обнаружили пустые значения в столбце Manufacturer . Для этих записей мы хотим провести проверку качества данных и переместить их в таблицу ошибок для дальнейшего анализа.
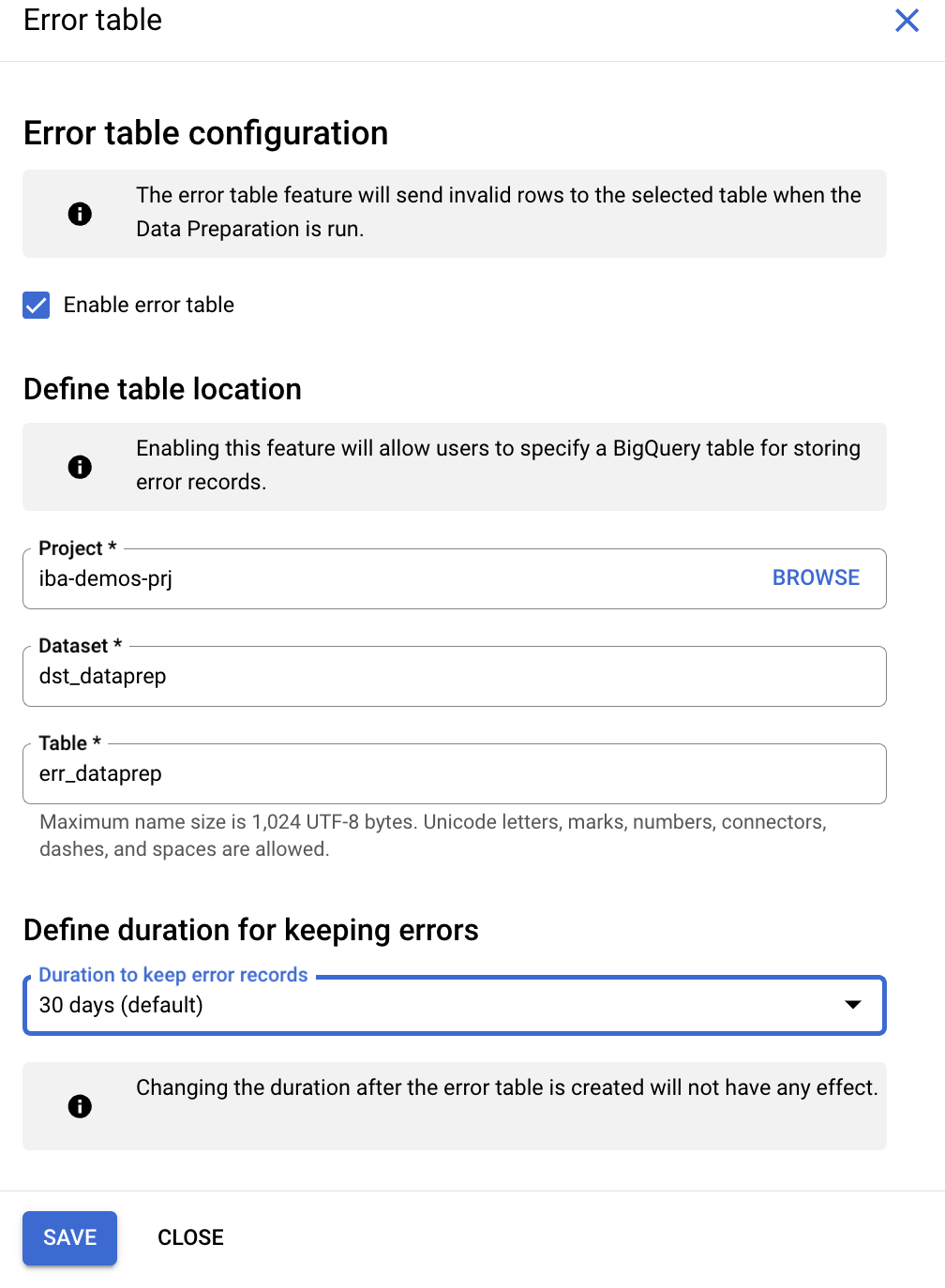
Создайте таблицу ошибок.
- Нажмите кнопку
Moreрядом с заголовкомstg_product data preparation. - В разделе
SettingвыберитеError Table. - Установите флажок
Enable error tableи настройте параметры следующим образом:
- Набор данных: Select
bq_data_preparation_demo - Таблица: Введите
err_dataprep - В разделе
Define duration for keeping errorsвыберите30 days (default)
- Нажмите «
Save».
Настройте проверку данных в столбце «Производитель».
- Выберите столбец «Производитель».
- Вероятно, Gemini уже определила подходящую трансформацию. Найдите рекомендацию, которая сохраняет только те строки, где поле «Производитель» не пустое. SQL-запрос будет выглядеть примерно так:
Manufacturer IS NOT NULL
2. Нажмите кнопку «Редактировать» рядом с этой рекомендацией, чтобы просмотреть её.
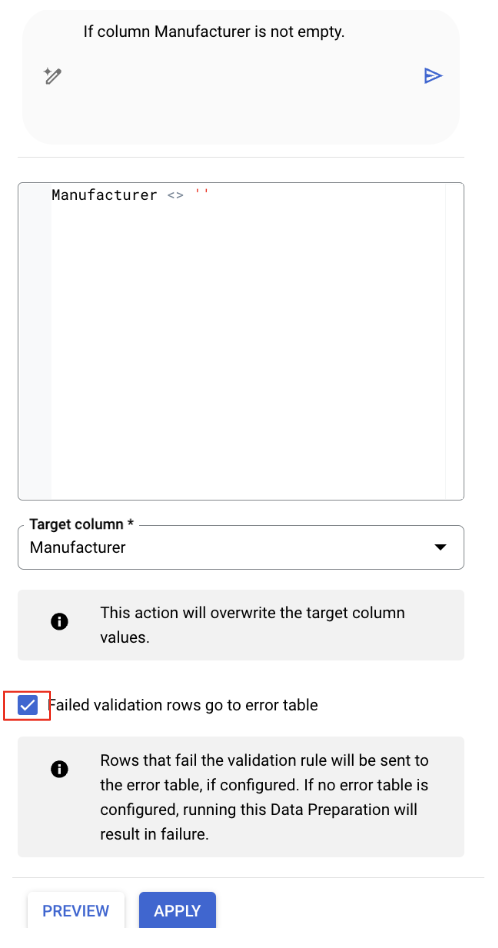
- Если флажок не установлен, установите флажок «Строки, не прошедшие проверку, переносятся в таблицу ошибок».
- Нажмите
Apply.
В любой момент вы можете просмотреть, изменить или удалить примененные преобразования, нажав кнопку «Примененные шаги».
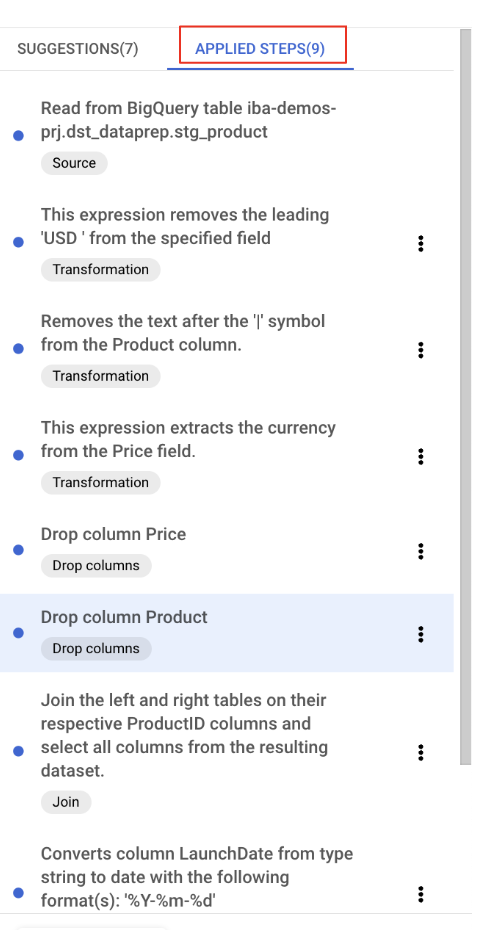
Удалите избыточный столбец ProductID_1.
Теперь можно удалить столбец ProductID_1, в котором дублируется ProductID из объединенной таблицы.
- Перейдите на вкладку
Schema. - Нажмите на три точки рядом со столбцом
ProductID_1. - Нажмите на
Drop.
Теперь мы готовы запустить задачу подготовки данных и проверить весь наш конвейер обработки данных. Как только мы будем удовлетворены результатами, мы можем запланировать автоматическое выполнение этой задачи.
- Прежде чем покинуть окно подготовки данных, сохраните ваши подготовительные действия. Рядом с заголовком
stg_product data preparationвы увидите кнопкуSave». Нажмите на эту кнопку, чтобы сохранить.
11. Очистка окружающей среды
- Удалите
stg_product data preparation - Удалите
bq data preparation demo
12. Поздравляем!
Поздравляем с завершением практического занятия!
Что мы рассмотрели
- Настройка подготовки данных
- Открытие таблиц и навигация по подготовке данных
- Разделение столбцов с числовыми данными и данными, описывающими единицы измерения.
- Стандартизация форматов дат
- Выполнение подготовки данных