
1. מבוא
העדכון האחרון: 14 ביולי 2022
יכולת התבוננות באפליקציה
יכולת צפייה ופרופילר מתמשך
המונח 'יכולת תצפית' מתאר מאפיין של מערכת. מערכת עם ניראות מאפשרת לצוותים לבצע ניפוי באגים פעיל במערכת שלהם. בהקשר הזה, שלושת עמודי התווך של ניראות – יומנים, מדדים ועקבות – הם האינסטרומנטציה הבסיסית שמאפשרת למערכת לרכוש ניראות.
בנוסף לשלושת עמודי התווך של יכולת התצפית, פרופיל מתמשך הוא עוד רכיב מרכזי של יכולת התצפית, ובסיס המשתמשים בתחום הולך וגדל. Cloud Profiler הוא אחד מהמקורות, והוא מספק ממשק קל לשימוש כדי להתעמק במדדי הביצועים במחסניות הקריאה של האפליקציה.
ה-Codelab הזה הוא חלק 2 בסדרה, והוא עוסק בהטמעה של סוכן פרופילים רציף. בחלק הראשון מוסבר על מעקב מבוזר באמצעות OpenTelemetry ו-Cloud Trace, ותוכלו לקרוא בו על זיהוי צוואר הבקבוק של המיקרו-שירותים.
מה תפַתחו
ב-codelab הזה, תגדירו את סוכן הפרופילים הרציף בשירות השרת של 'אפליקציית שייקספיר' (שנקראת גם Shakesapp) שפועלת באשכול Google Kubernetes Engine. הארכיטקטורה של Shakesapp היא כפי שמתואר בהמשך:

- Loadgen שולח מחרוזת שאילתה ללקוח ב-HTTP
- הלקוחות מעבירים את השאילתה מ-loadgen לשרת ב-gRPC
- השרת מקבל את השאילתה מהלקוח, מאחזר את כל היצירות של שייקספיר בפורמט טקסט מ-Google Cloud Storage, מחפש את השורות שמכילות את השאילתה ומחזיר ללקוח את מספר השורה שתואמת לשאילתה
בחלק 1, גיליתם שהצוואר בקבוק נמצא איפשהו בשירות השרת, אבל לא הצלחתם לזהות את הסיבה המדויקת.
מה תלמדו
- איך מטמיעים סוכן פרופיל
- איך בודקים את צוואר הבקבוק ב-Cloud Profiler
Codelab זה מסביר איך להטמיע סוכן של כלי לניתוח ביצועים (profiler) רציף באפליקציה.
מה תצטרכו
- ידע בסיסי ב-Go
- ידע בסיסי ב-Kubernetes
2. הגדרה ודרישות
הגדרת סביבה בקצב אישי
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים אל Google Cloud Platform Console ( console.cloud.google.com) ויוצרים פרויקט חדש.
אם כבר יש לכם פרויקט, לוחצים על התפריט הנפתח לבחירת פרויקט בפינה הימנית העליונה של המסוף:
ולוחצים על הלחצן 'פרויקט חדש' בתיבת הדו-שיח שמופיעה כדי ליצור פרויקט חדש:
אם עדיין אין לכם פרויקט, תופיע תיבת דו-שיח כמו זו שבהמשך כדי ליצור את הפרויקט הראשון:
בתיבת הדו-שיח הבאה ליצירת פרויקט, אפשר להזין את הפרטים של הפרויקט החדש:
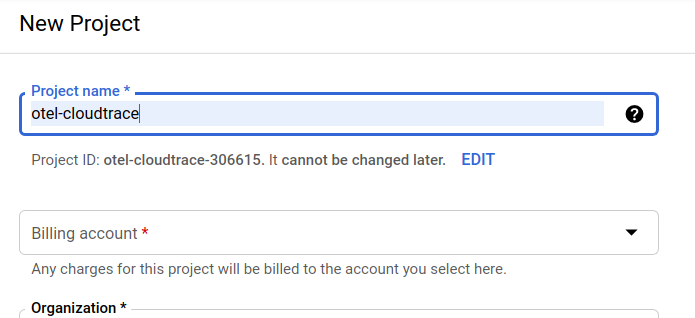
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה, הוא יופיע כ-PROJECT_ID.
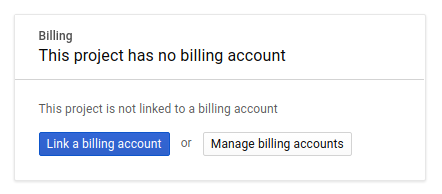
לאחר מכן, אם עדיין לא עשיתם זאת, תצטרכו להפעיל את החיוב במסוף למפתחים כדי להשתמש במשאבים של Google Cloud ולהפעיל את Cloud Trace API.
העלות של ה-Codelab הזה לא אמורה להיות גבוהה מכמה דולרים, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים (ראו את הקטע 'ניקוי נתונים' בסוף המסמך הזה). במסמכי התיעוד הרשמיים מפורטים המחירים של Google Cloud Trace, Google Kubernetes Engine ו-Google Artifact Registry.
- תמחור של חבילת התפעול של Google Cloud | חבילת התפעול
- תמחור | מסמכי Kubernetes Engine
- תמחור של Artifact Registry | תיעוד של Artifact Registry
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$, כך שסדנת ה-codelab הזו אמורה להיות בחינם לגמרי.
הגדרה של Google Cloud Shell
אפשר להפעיל את Google Cloud ואת Google Cloud Trace מרחוק מהמחשב הנייד, אבל ב-codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. כלומר, כל מה שצריך כדי לבצע את ההוראות במאמר הזה הוא דפדפן (כן, זה עובד ב-Chromebook).
כדי להפעיל את Cloud Shell ממסוף Cloud, פשוט לוחצים על 'הפעלת Cloud Shell'  (הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
(הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע, ושהפרויקט כבר הוגדר ל-PROJECT_ID.
gcloud auth list
פלט הפקודה
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
פלט הפקודה
[core] project = <PROJECT_ID>
אם מסיבה כלשהי הפרויקט לא מוגדר, פשוט מריצים את הפקודה הבאה:
gcloud config set project <PROJECT_ID>
מחפש את PROJECT_ID? כדאי לבדוק באיזה מזהה השתמשתם בשלבי ההגדרה, או לחפש אותו בלוח הבקרה של Cloud Console:
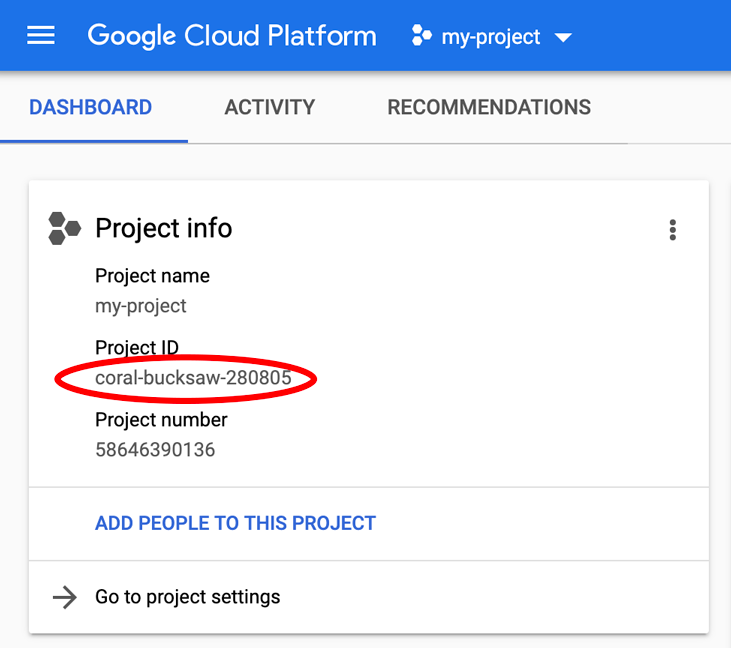
ב-Cloud Shell מוגדרים גם כמה משתני סביבה כברירת מחדל, שיכולים להיות שימושיים כשמריצים פקודות בעתיד.
echo $GOOGLE_CLOUD_PROJECT
פלט הפקודה
<PROJECT_ID>
לבסוף, מגדירים את אזור ברירת המחדל ואת הגדרת הפרויקט.
gcloud config set compute/zone us-central1-f
אפשר לבחור מתוך מגוון אזורים שונים. מידע נוסף זמין במאמר בנושא אזורים ותחומים.
מעבר להגדרת השפה
ב-codelab הזה אנחנו משתמשים ב-Go לכל קוד המקור. מריצים את הפקודה הבאה ב-Cloud Shell ומוודאים שהגרסה של Go היא 1.17 ומעלה.
go version
פלט הפקודה
go version go1.18.3 linux/amd64
הגדרה של אשכול Google Kubernetes
במעבדת התכנות הזו תריצו אשכול של מיקרו-שירותים ב-Google Kubernetes Engine (GKE). תהליך ה-codelab הוא כדלקמן:
- הורדת פרויקט הבסיס ל-Cloud Shell
- איך יוצרים מיקרו-שירותים בקונטיינרים
- העלאת קונטיינרים ל-Google Artifact Registry (GAR)
- פריסת קונטיינרים ב-GKE
- שינוי קוד המקור של שירותים לצורך מעקב אחר אינסטרומנטציה
- מעבר לשלב 2
הפעלת Kubernetes Engine
קודם כל, אנחנו מגדירים אשכול Kubernetes שבו Shakesapp פועל ב-GKE, ולכן אנחנו צריכים להפעיל את GKE. עוברים לתפריט Kubernetes Engine ולוחצים על הלחצן ENABLE (הפעלה).
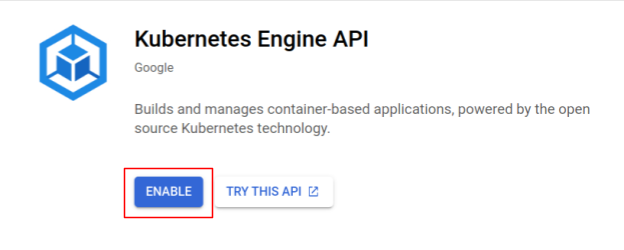
עכשיו אפשר ליצור אשכול Kubernetes.
יצירת אשכול Kubernetes
ב-Cloud Shell, מריצים את הפקודה הבאה כדי ליצור אשכול Kubernetes. עליך לוודא שערך האזור נמצא באזור שבו תשתמש ליצירת מאגר Artifact Registry. אם האזור של המאגר לא כולל את האזור, צריך לשנות את הערך של האזור us-central1-f.
gcloud container clusters create otel-trace-codelab2 \ --zone us-central1-f \ --release-channel rapid \ --preemptible \ --enable-autoscaling \ --max-nodes 8 \ --no-enable-ip-alias \ --scopes cloud-platform
פלט הפקודה
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s). Creating cluster otel-trace-codelab2 in us-central1-f... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/development-215403/zones/us-central1-f/clusters/otel-trace-codelab2]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/us-central1-f/otel-trace-codelab2?project=development-215403 kubeconfig entry generated for otel-trace-codelab2. NAME: otel-trace-codelab2 LOCATION: us-central1-f MASTER_VERSION: 1.23.6-gke.1501 MASTER_IP: 104.154.76.89 MACHINE_TYPE: e2-medium NODE_VERSION: 1.23.6-gke.1501 NUM_NODES: 3 STATUS: RUNNING
הגדרת Artifact Registry ו-skaffold
עכשיו יש לנו אשכול Kubernetes שמוכן לפריסה. לאחר מכן מתכוננים ל-Container Registry כדי לדחוף ולפרוס קונטיינרים. כדי לבצע את השלבים האלה, צריך להגדיר Artifact Registry (GAR) ו-skaffold כדי להשתמש בו.
הגדרת Artifact Registry
מנווטים לתפריט Artifact Registry ולוחצים על הלחצן ENABLE (הפעלה).

אחרי כמה רגעים, יופיע דפדפן המאגר של GAR. לוחצים על הלחצן CREATE REPOSITORY (יצירת מאגר) ומזינים את שם המאגר.
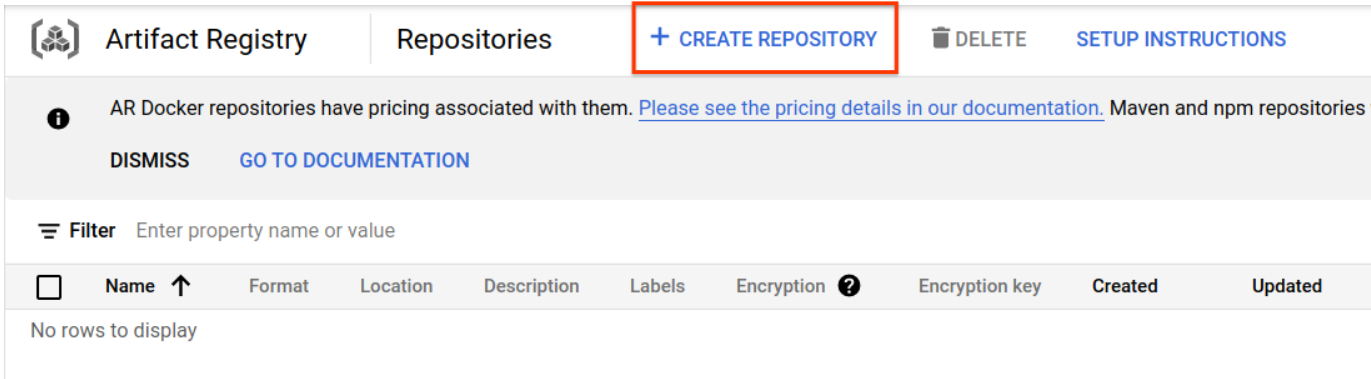
ב-codelab הזה, קראתי למאגר החדש trace-codelab. הפורמט של הארטיפקט הוא Docker וסוג המיקום הוא Region. בוחרים את האזור שקרוב לאזור שהגדרתם כברירת מחדל ב-Google Compute Engine. לדוגמה, בדוגמה שלמעלה נבחרה האפשרות us-central1-f, ולכן כאן נבחרת האפשרות us-central1 (Iowa). אחר כך לוחצים על הלחצן 'יצירה'.
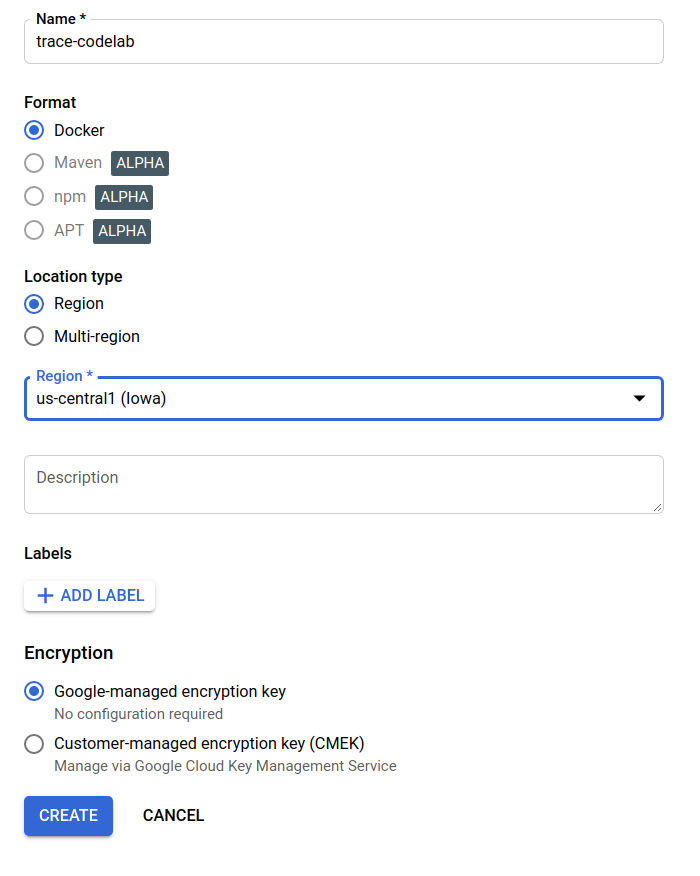
עכשיו מופיע trace-codelab בדפדפן המאגר.
נחזור לכאן בהמשך כדי לבדוק את נתיב הרישום.
הגדרה של Skaffold
Skaffold הוא כלי שימושי כשעובדים על בניית מיקרו-שירותים שפועלים ב-Kubernetes. הוא מטפל בתהליך העבודה של בנייה, שליחה ופריסה של קונטיינרים של אפליקציות באמצעות קבוצה קטנה של פקודות. כברירת מחדל, Skaffold משתמש ב-Docker Registry כמאגר קונטיינרים, לכן צריך להגדיר את Skaffold כך שיזהה את GAR כשמעבירים אליו קונטיינרים.
פותחים שוב את Cloud Shell ומוודאים ש-skaffold מותקן. (כברירת מחדל, Cloud Shell מתקין את skaffold בסביבה). מריצים את הפקודה הבאה כדי לראות את הגרסה של skaffold.
skaffold version
פלט הפקודה
v1.38.0
עכשיו אפשר לרשום את מאגר ברירת המחדל לשימוש ב-Skaffold. כדי לקבל את נתיב המאגר, עוברים אל מרכז הבקרה של Artifact Registry ולוחצים על שם המאגר שהגדרתם בשלב הקודם.
לאחר מכן, נתיבי הניווט יופיעו בחלק העליון של הדף. לוחצים על הסמל  כדי להעתיק את נתיב הרישום ללוח.
כדי להעתיק את נתיב הרישום ללוח.
כשלוחצים על לחצן ההעתקה, מופיעה תיבת הדו-שיח בתחתית הדפדפן עם הודעה כמו:
הטקסט us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab הועתק
חוזרים אל Cloud Shell. מריצים את הפקודה skaffold config set default-repo עם הערך שהעתקתם מהמרכז לשליטה.
skaffold config set default-repo us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab
פלט הפקודה
set value default-repo to us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab for context gke_stackdriver-sandbox-3438851889_us-central1-b_stackdriver-sandbox
בנוסף, צריך להגדיר את הרישום בהגדרות של Docker. מריצים את הפקודה הבאה:
gcloud auth configure-docker us-central1-docker.pkg.dev --quiet
פלט הפקודה
{
"credHelpers": {
"gcr.io": "gcloud",
"us.gcr.io": "gcloud",
"eu.gcr.io": "gcloud",
"asia.gcr.io": "gcloud",
"staging-k8s.gcr.io": "gcloud",
"marketplace.gcr.io": "gcloud",
"us-central1-docker.pkg.dev": "gcloud"
}
}
Adding credentials for: us-central1-docker.pkg.dev
עכשיו אפשר לעבור לשלב הבא ולהגדיר מאגר תגים של Kubernetes ב-GKE.
סיכום
בשלב הזה מגדירים את סביבת ה-codelab:
- הגדרת Cloud Shell
- נוצר מאגר Artifact Registry עבור Container Registry
- הגדרת skaffold לשימוש במאגר הקונטיינרים
- נוצר אשכול Kubernetes שבו פועלים המיקרו-שירותים של ה-codelab
הבא בתור
בשלב הבא, תגדירו את סוכן הפרופילים הרציף בשירות השרת.
3. בנייה, שליחה ופריסה של המיקרו-שירותים
הורדת חומרי ה-codelab
בשלב הקודם הגדרנו את כל הדרישות המוקדמות ל-codelab הזה. עכשיו אפשר להפעיל מיקרו-שירותים שלמים על גביהם. חומרי ה-Codelab מאוחסנים ב-GitHub, לכן צריך להוריד אותם לסביבת Cloud Shell באמצעות פקודת ה-git הבאה.
cd ~ git clone https://github.com/ymotongpoo/opentelemetry-trace-codelab-go.git cd opentelemetry-trace-codelab-go
מבנה הספריות של הפרויקט הוא כדלקמן:
.
├── README.md
├── step0
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step1
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step2
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step3
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step4
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
├── step5
│ ├── manifests
│ ├── proto
│ ├── skaffold.yaml
│ └── src
└── step6
├── manifests
├── proto
├── skaffold.yaml
└── src
- מניפסטים: קובצי מניפסט של Kubernetes
- proto: הגדרת proto לתקשורת בין הלקוח לשרת
- src: ספריות לקוד המקור של כל שירות
- skaffold.yaml: קובץ תצורה של skaffold
ב-codelab הזה תעדכנו את קוד המקור שנמצא בתיקייה step4. אפשר גם לעיין בקוד המקור בתיקיות step[1-6] כדי לראות את השינויים מההתחלה. (חלק 1 כולל את שלבים 0 עד 4, וחלק 2 כולל את שלבים 5 ו-6)
הרצת פקודת skaffold
לבסוף, אפשר ליצור, להעביר ולפרוס את כל התוכן באשכול Kubernetes שיצרתם. זה נשמע כאילו התהליך כולל כמה שלבים, אבל בפועל, כלי Skaffold עושה הכול בשבילכם. ננסה את זה עם הפקודה הבאה:
cd step4 skaffold dev
מיד אחרי הפעלת הפקודה, מוצג פלט היומן של docker build ואפשר לוודא שהם נדחפים בהצלחה למאגר.
פלט הפקודה
... ---> Running in c39b3ea8692b ---> 90932a583ab6 Successfully built 90932a583ab6 Successfully tagged us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step1 The push refers to repository [us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice] cc8f5a05df4a: Preparing 5bf719419ee2: Preparing 2901929ad341: Preparing 88d9943798ba: Preparing b0fdf826a39a: Preparing 3c9c1e0b1647: Preparing f3427ce9393d: Preparing 14a1ca976738: Preparing f3427ce9393d: Waiting 14a1ca976738: Waiting 3c9c1e0b1647: Waiting b0fdf826a39a: Layer already exists 88d9943798ba: Layer already exists f3427ce9393d: Layer already exists 3c9c1e0b1647: Layer already exists 14a1ca976738: Layer already exists 2901929ad341: Pushed 5bf719419ee2: Pushed cc8f5a05df4a: Pushed step1: digest: sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe size: 2001
אחרי שכל מאגרי השירותים נדחפים, פריסות Kubernetes מתחילות באופן אוטומטי.
פלט הפקודה
sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 size: 1997 Tags used in deployment: - serverservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/serverservice:step4@sha256:8acdbe3a453001f120fb22c11c4f6d64c2451347732f4f271d746c2e4d193bbe - clientservice -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/clientservice:step4@sha256:b71fce0a96cea08075dc20758ae561cf78c83ff656b04d211ffa00cedb77edf8 - loadgen -> us-central1-docker.pkg.dev/psychic-order-307806/trace-codelab/loadgen:step4@sha256:eea2e5bc8463ecf886f958a86906cab896e9e2e380a0eb143deaeaca40f7888a Starting deploy... - deployment.apps/clientservice created - service/clientservice created - deployment.apps/loadgen created - deployment.apps/serverservice created - service/serverservice created
אחרי הפריסה, יומני האפליקציה בפועל שמועברים אל stdout יופיעו בכל אחד מהקונטיינרים באופן הבא:
פלט הפקודה
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:15 {"match_count":3040}
[loadgen] 2022/07/14 06:33:15 query 'love': matched 3040
[client] 2022/07/14 06:33:16 {"match_count":3040}
[loadgen] 2022/07/14 06:33:16 query 'love': matched 3040
[client] 2022/07/14 06:33:19 {"match_count":463}
[loadgen] 2022/07/14 06:33:19 query 'tear': matched 463
[loadgen] 2022/07/14 06:33:20 query 'world': matched 728
[client] 2022/07/14 06:33:20 {"match_count":728}
[client] 2022/07/14 06:33:22 {"match_count":463}
[loadgen] 2022/07/14 06:33:22 query 'tear': matched 463
חשוב לשים לב שבשלב הזה, אתם רוצים לראות את כל ההודעות מהשרת. עכשיו אפשר להתחיל להטמיע את OpenTelemetry באפליקציה כדי לעקוב אחרי השירותים.
לפני שמתחילים להגדיר את השירות, צריך לכבות את האשכול באמצעות Ctrl-C.
פלט הפקודה
...
[client] 2022/07/14 06:34:57 {"match_count":1}
[loadgen] 2022/07/14 06:34:57 query 'what's past is prologue': matched 1
^CCleaning up...
- W0714 06:34:58.464305 28078 gcp.go:120] WARNING: the gcp auth plugin is deprecated in v1.22+, unavailable in v1.25+; use gcloud instead.
- To learn more, consult https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
- deployment.apps "clientservice" deleted
- service "clientservice" deleted
- deployment.apps "loadgen" deleted
- deployment.apps "serverservice" deleted
- service "serverservice" deleted
סיכום
בשלב הזה, הכנתם את החומר של ה-Codelab בסביבה שלכם ואישרתם ש-Skaffold פועל כמצופה.
הבא בתור
בשלב הבא תשנו את קוד המקור של שירות loadgen כדי להגדיר את פרטי המעקב.
4. הוספת מכשור לסוכן Cloud Profiler
הקונספט של פרופילים רציפים
לפני שנסביר על הרעיון של יצירת פרופילים רציפה, נסביר קודם על יצירת פרופילים. פרופיל הוא אחת הדרכים לנתח את האפליקציה באופן דינמי (ניתוח תוכנה דינמי), והוא מתבצע בדרך כלל במהלך פיתוח האפליקציה בתהליך של בדיקת עומס וכו'. זו פעילות חד-פעמית למדידת מדדי המערכת, כמו שימוש במעבד ובזיכרון, במהלך התקופה הספציפית. אחרי איסוף נתוני הפרופיל, המפתחים מנתחים אותם מחוץ לקוד.
פרופיל רציף הוא גישה מורחבת לפרופיל רגיל: הוא מריץ פרופילים של חלונות קצרים מול האפליקציה שפועלת לזמן ארוך באופן תקופתי, ואוסף הרבה נתוני פרופיל. לאחר מכן, המערכת יוצרת באופן אוטומטי את הניתוח הסטטיסטי על סמך מאפיין מסוים של האפליקציה, כמו מספר הגרסה, אזור הפריסה, זמן המדידה וכו'. פרטים נוספים על הרעיון הזה מופיעים במסמכי התיעוד שלנו.
מכיוון שהיעד הוא אפליקציה שפועלת, יש דרך לאסוף נתוני פרופיל באופן תקופתי ולשלוח אותם לקצה עורפי כלשהו שמבצע עיבוד של הנתונים הסטטיסטיים. זהו סוכן Cloud Profiler, ותטמיעו אותו בשירות השרת בקרוב.
הטמעת סוכן Cloud Profiler
לוחצים על הלחצן  בפינה השמאלית העליונה של Cloud Shell כדי לפתוח את Cloud Shell Editor. פותחים את
בפינה השמאלית העליונה של Cloud Shell כדי לפתוח את Cloud Shell Editor. פותחים את step4/src/server/main.go מהסייר בחלונית השמאלית ומחפשים את הפונקציה הראשית.
step4/src/server/main.go
func main() {
...
// step2. setup OpenTelemetry
tp, err := initTracer()
if err != nil {
log.Fatalf("failed to initialize TracerProvider: %v", err)
}
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
svc := NewServerService()
// step2: add interceptor
interceptorOpt := otelgrpc.WithTracerProvider(otel.GetTracerProvider())
srv := grpc.NewServer(
grpc.UnaryInterceptor(otelgrpc.UnaryServerInterceptor(interceptorOpt)),
grpc.StreamInterceptor(otelgrpc.StreamServerInterceptor(interceptorOpt)),
)
// step2: end adding interceptor
shakesapp.RegisterShakespeareServiceServer(srv, svc)
healthpb.RegisterHealthServer(srv, svc)
if err := srv.Serve(lis); err != nil {
log.Fatalf("error serving server: %v", err)
}
}
בפונקציה main, מוצג קוד הגדרה מסוים של OpenTelemetry ו-gRPC, שנוצר בחלק 1 של ה-codelab. עכשיו מוסיפים כאן את ה-instrumentation של סוכן Cloud Profiler. כמו שעשינו בשביל initTracer(), אפשר לכתוב פונקציה בשם initProfiler() כדי שהקוד יהיה קריא יותר.
step4/src/server/main.go
import (
...
"cloud.google.com/go/profiler" // step5. add profiler package
"cloud.google.com/go/storage"
...
)
// step5: add Profiler initializer
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.0.0",
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
נבחן את האפשרויות שצוינו בprofiler.Config{} object.
- שירות: שם השירות שאפשר לבחור ולהפעיל במרכז הבקרה של כלי הפרופיל
- ServiceVersion: שם גרסת השירות. אתם יכולים להשוות בין קבוצות נתונים של פרופילים על סמך הערך הזה.
- NoHeapProfiling: השבתת הפרופיילינג של צריכת הזיכרון
- NoAllocProfiling: השבתת הפרופיילינג של הקצאת הזיכרון
- NoGoroutineProfiling: השבתה של יצירת פרופילים של goroutine
- NoCPUProfiling: השבתה של פרופיילינג של המעבד (CPU)
ב-Codelab הזה, אנחנו מפעילים רק פרופיל CPU.
עכשיו צריך רק להפעיל את הפונקציה הזו בפונקציה main. חשוב לייבא את חבילת Cloud Profiler בבלוק הייבוא.
step4/src/server/main.go
func main() {
...
defer func() {
if err := tp.Shutdown(context.Background()); err != nil {
log.Fatalf("error shutting down TracerProvider: %v", err)
}
}()
// step2. end setup
// step5. start profiler
go initProfiler()
// step5. end
svc := NewServerService()
// step2: add interceptor
...
}
שימו לב שאתם קוראים לפונקציה initProfiler() עם מילת המפתח go. הפונקציה profiler.Start() חוסמת, ולכן צריך להריץ אותה ב-goroutine אחר. עכשיו אפשר להתחיל לבנות. חשוב להריץ את הפקודה go mod tidy לפני הפריסה.
go mod tidy
עכשיו פורסים את האשכול עם שירות השרת החדש.
skaffold dev
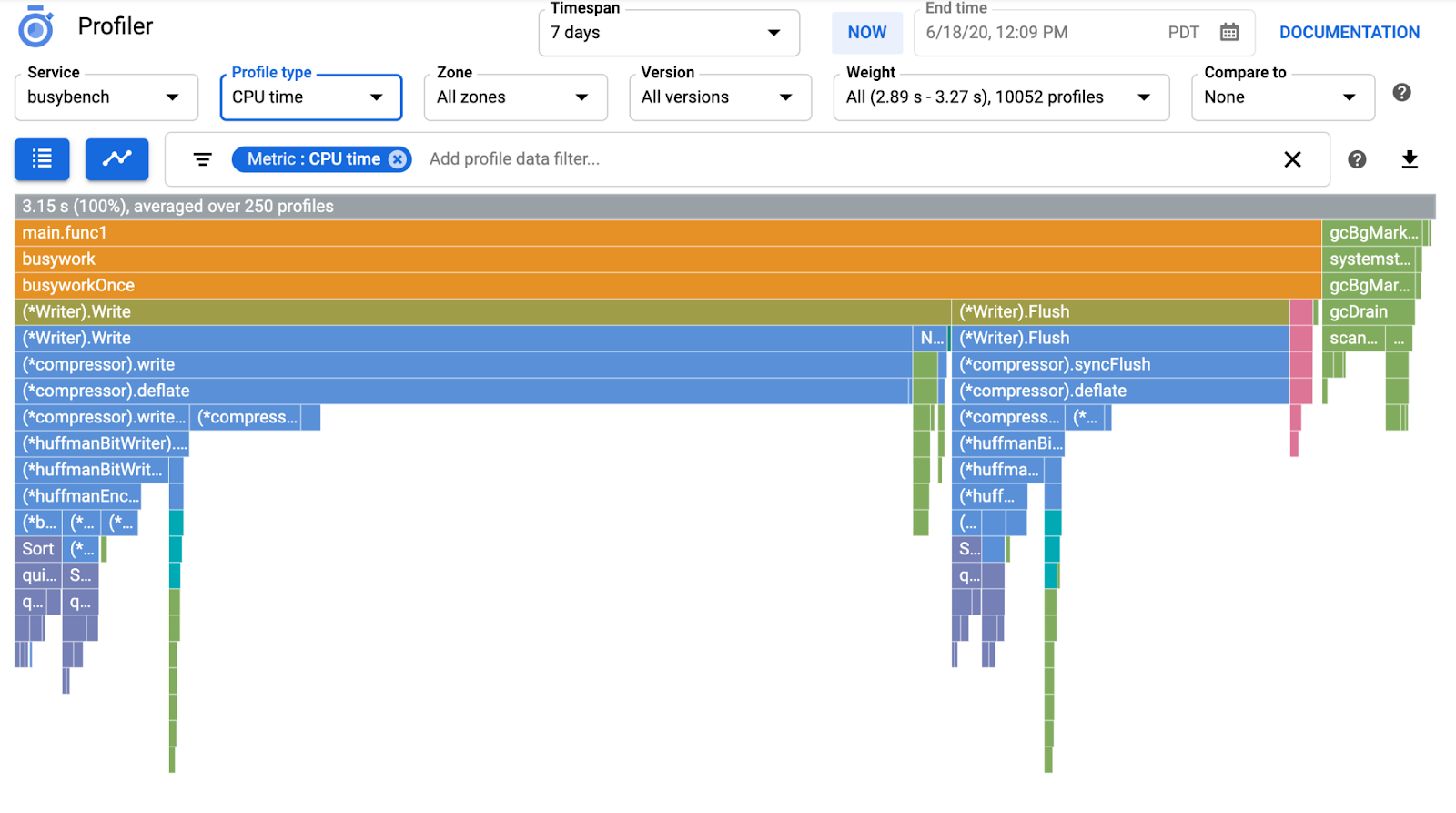
בדרך כלל לוקח כמה דקות עד שתרשים הלהבות מופיע ב-Cloud Profiler. מקלידים 'profiler' בתיבת החיפוש שלמעלה ולוחצים על סמל הכלי Profiler.

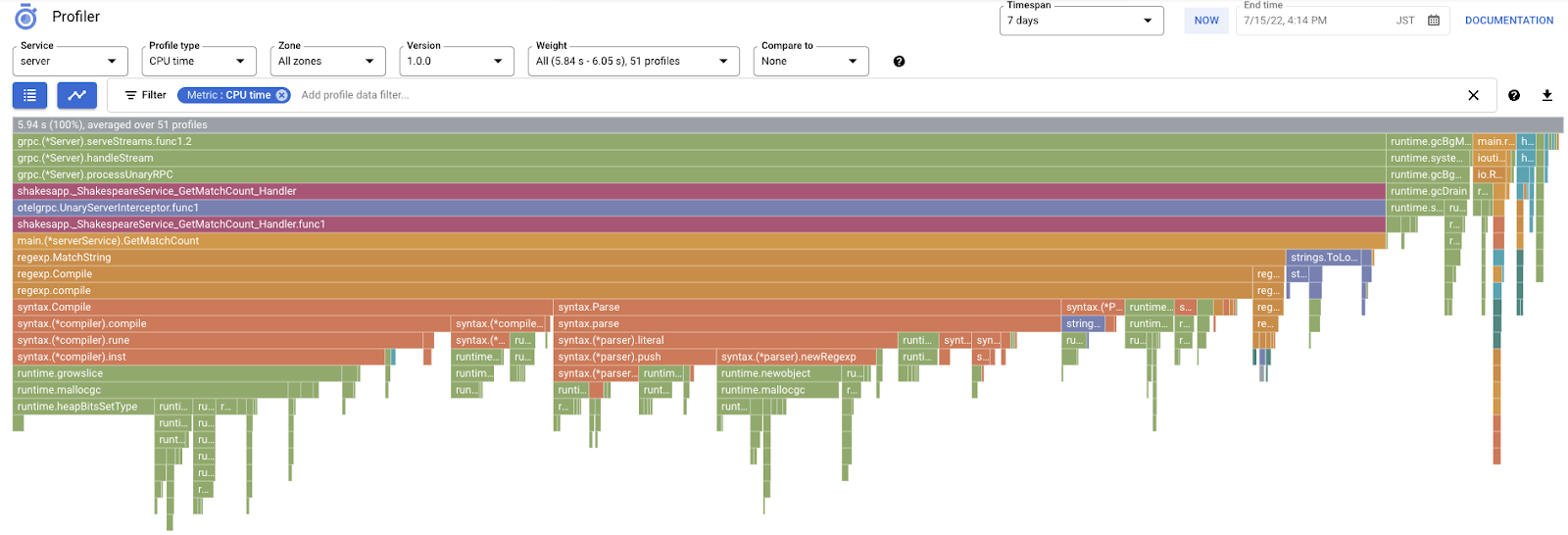
אחר כך יוצג תרשים הלהבות הבא.
סיכום
בשלב הזה, הטמעתם את סוכן Cloud Profiler בשירות השרת ואישרתם שהוא יוצר תרשים להבה.
הבא בתור
בשלב הבא, תבדקו את הגורם לצוואר הבקבוק באפליקציה באמצעות תרשים הלהבות.
5. ניתוח של תרשים להבות (flame graph) ב-Cloud Profiler
מה זה תרשים להבות (flame graph)?
תרשים להבת אש הוא אחת הדרכים להמחיש את נתוני הפרופיל. הסבר מפורט זמין במסמך שלנו, אבל הנה סיכום קצר:
- כל עמודה מייצגת קריאה למתודה או בקשה להפעלת פונקציה באפליקציה
- הכיוון האנכי הוא סטאק ביצוע, שגדל מלמעלה למטה
- הכיוון האופקי הוא השימוש במשאבים. ככל שהפס ארוך יותר, כך המצב גרוע יותר.
בהתאם לכך, נבחן את תרשים הלהבות שהתקבל.
ניתוח תרשים להבות
בקטע הקודם למדתם שכל עמודה בתרשים הלהבה מייצגת את הקריאה לפונקציה או הפעלת method, והאורך שלה מייצג את השימוש במשאבים בפונקציה או בשיטה. בתרשים הלהבות של Cloud Profiler, הסרגל ממוין בסדר יורד או לפי האורך משמאל לימין, ולכן כדאי להתחיל לבדוק את החלק השמאלי העליון של התרשים.
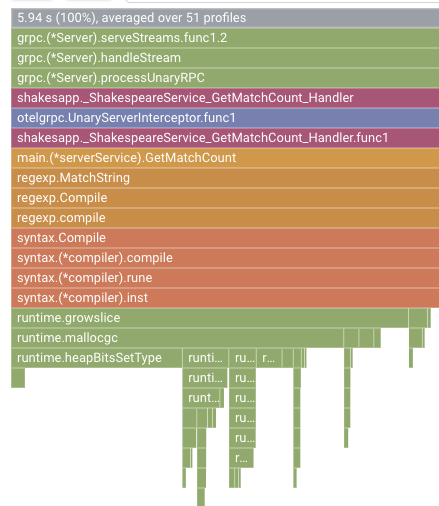
במקרה שלנו, ברור ש-grpc.(*Server).serveStreams.func1.2 צורך את רוב זמן המעבד, ובעיון ב-סטאק ביצוע מלמעלה למטה, רואים שרוב הזמן מושקע ב-main.(*serverService).GetMatchCount, שהוא ה-handler של שרת gRPC בשירות השרת.
בקטע GetMatchCount, מוצגת סדרה של פונקציות regexp: regexp.MatchString ו-regexp.Compile. הם מגיעים מחבילת התקנים הרגילה, כלומר הם נבדקו היטב מנקודות מבט רבות, כולל ביצועים. אבל התוצאה כאן מראה שהשימוש במשאב של זמן המעבד גבוה ב-regexp.MatchString וב-regexp.Compile. בהתבסס על העובדות האלה, ההנחה היא שהשימוש בפונקציה regexp.MatchString קשור לבעיות בביצועים. אז בואו נבדוק את קוד המקור שבו נעשה שימוש בפונקציה.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line, query := strings.ToLower(line), strings.ToLower(req.Query)
isMatch, err := regexp.MatchString(query, line)
if err != nil {
return resp, err
}
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
זה המקום שבו מתבצעת הקריאה ל-regexp.MatchString. אם תעיינו בקוד המקור, תראו שהפונקציה נקראת בתוך לולאת ה-for המוצבת. לכן יכול להיות שהשימוש בפונקציה הזו לא נכון. בואו נחפש את GoDoc של regexp.

לפי המסמך, הפונקציה regexp.MatchString קומפיילת את דפוס הביטוי הרגולרי בכל קריאה. לכן, הסיבה לצריכת המשאבים הגבוהה היא כנראה:
סיכום
בשלב הזה, ניתחתם את תרשים הלהבות והנחתם מה הגורם לניצול המשאבים.
הבא בתור
בשלב הבא תעדכנו את קוד המקור של שירות השרת ותאשרו את השינוי מגרסה 1.0.0.
6. עדכון קוד המקור והשוואה בין תרשימי הלהבות
עדכון קוד המקור
בשלב הקודם, הנחתם שהשימוש ב-regexp.MatchString קשור לצריכת המשאבים הגבוהה. אז בואו נפתור את הבעיה. פותחים את הקוד ומשנים קצת את החלק הזה.
step4/src/server/main.go
func (s *serverService) GetMatchCount(ctx context.Context, req *shakesapp.ShakespeareRequest) (*shakesapp.ShakespeareResponse, error) {
resp := &shakesapp.ShakespeareResponse{}
texts, err := readFiles(ctx, bucketName, bucketPrefix)
if err != nil {
return resp, fmt.Errorf("fails to read files: %s", err)
}
// step6. considered the process carefully and naively tuned up by extracting
// regexp pattern compile process out of for loop.
query := strings.ToLower(req.Query)
re := regexp.MustCompile(query)
for _, text := range texts {
for _, line := range strings.Split(text, "\n") {
line = strings.ToLower(line)
isMatch := re.MatchString(line)
// step6. done replacing regexp with strings
if isMatch {
resp.MatchCount++
}
}
}
return resp, nil
}
כפי שאפשר לראות, עכשיו תהליך ההידור של תבנית ה-regexp מופרד מה-regexp.MatchString ומועבר מחוץ ללולאת ה-for המקוננת.
לפני שמפעילים את הקוד הזה, חשוב לעדכן את מחרוזת הגרסה בפונקציה initProfiler().
step4/src/server/main.go
func initProfiler() {
cfg := profiler.Config{
Service: "server",
ServiceVersion: "1.1.0", // step6. update version
NoHeapProfiling: true,
NoAllocProfiling: true,
NoGoroutineProfiling: true,
NoCPUProfiling: false,
}
if err := profiler.Start(cfg); err != nil {
log.Fatalf("failed to launch profiler agent: %v", err)
}
}
עכשיו נראה איך זה עובד. פורסים את האשכול באמצעות פקודת skaffold.
skaffold dev
אחרי כמה זמן, טוענים מחדש את מרכז הבקרה של Cloud Profiler ובודקים איך הוא נראה.
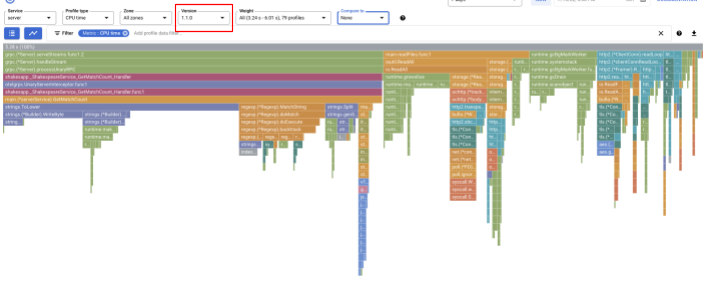
חשוב לשנות את הגרסה ל-"1.1.0" כדי לראות רק את הפרופילים מגרסה 1.1.0. כפי שאפשר לראות, האורך של העמודה של GetMatchCount קטן יותר, ויחס השימוש בזמן ה-CPU (כלומר, העמודה) קצר יותר.

אפשר לא רק להסתכל על תרשים הלהבות של גרסה אחת, אלא גם להשוות בין ההבדלים של שתי גרסאות.

משנים את הערך של התפריט הנפתח 'השוואה ל' ל'גרסה' ואת הערך של 'גרסה בהשוואה' ל'1.0.0', הגרסה המקורית.
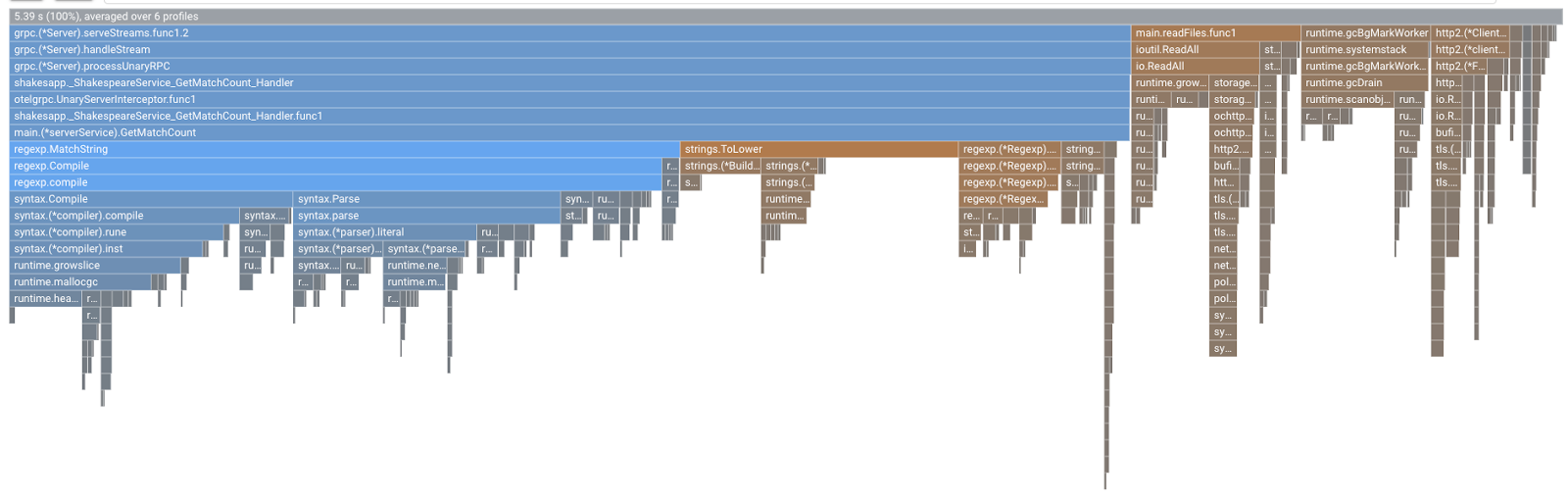
יוצג תרשים להבת כזה. הצורה של הגרף זהה לגרף 1.1.0, אבל הצבעים שונים. במצב השוואה, המשמעות של הצבע היא:
- כחול: הערך (צריכת המשאבים) שהופחת
- כתום: הערך (צריכת המשאבים) שהושג
- אפור: ניטרלי
בואו נבחן את הפונקציה מקרוב, בהתאם למקרא. כדי לראות פרטים נוספים בתוך העמודה, לוחצים על העמודה שרוצים להגדיל. לוחצים על הסרגל main.(*serverService).GetMatchCount. אם תעבירו את העכבר מעל העמודה, תוכלו לראות את פרטי ההשוואה.
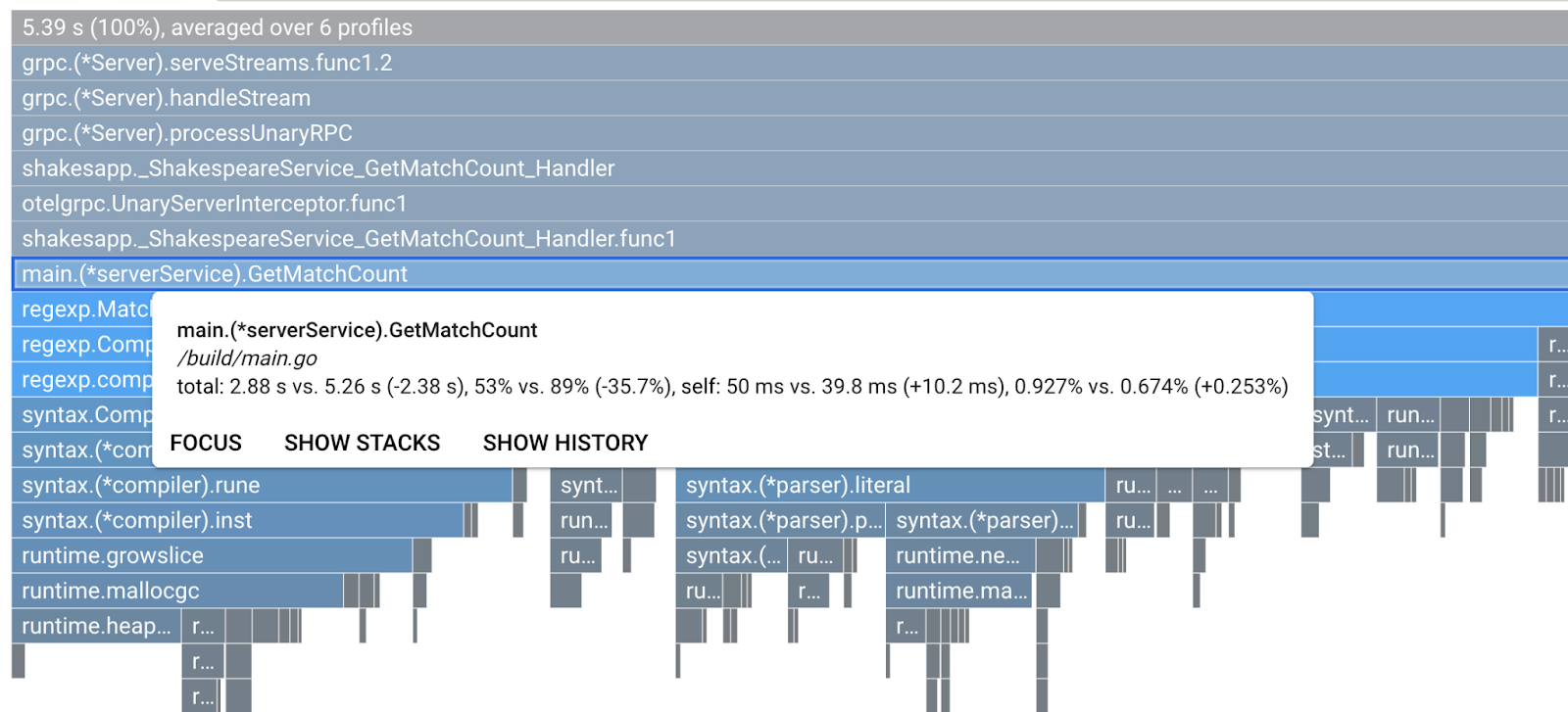
הזמן הכולל של המעבד (CPU) ירד מ-5.26 שניות ל-2.88 שניות (הזמן הכולל הוא 10 שניות = חלון הדגימה). זה שיפור משמעותי!
עכשיו אפשר לשפר את ביצועי האפליקציה על סמך הניתוח של נתוני הפרופיל.
סיכום
בשלב הזה, ערכתם את שירות השרת ואישרתם את השיפור במצב ההשוואה של Cloud Profiler.
הבא בתור
בשלב הבא תעדכנו את קוד המקור של שירות השרת ותאשרו את השינוי מגרסה 1.0.0.
7. שלב נוסף: אישור השיפור בתרשים הזרימה של Trace
ההבדל בין מעקב מבוזר לבין פרופיל רציף
בחלק 1 של ה-codelab, אישרתם שאתם יכולים לזהות את שירות צוואר הבקבוק בכל המיקרו-שירותים של נתיב בקשה, ושאתם לא יכולים לזהות את הסיבה המדויקת לצוואר הבקבוק בשירות הספציפי. בשיעור הזה, חלק 2 של Codelab, למדתם שפרופיל רציף מאפשר לכם לזהות את צוואר הבקבוק בתוך שירות יחיד ממחסניות קריאות.
בשלב הזה, נבדוק את תרשים המפל מתוך המעקב המבוזר (Cloud Trace) ונראה את ההבדל מהפרופיל הרציף.
תרשים המפל הזה הוא אחד מהעקבות עם השאילתה 'אהבה'. הזמן הכולל הוא בערך 6.7 שניות (6,700 אלפיות השנייה).
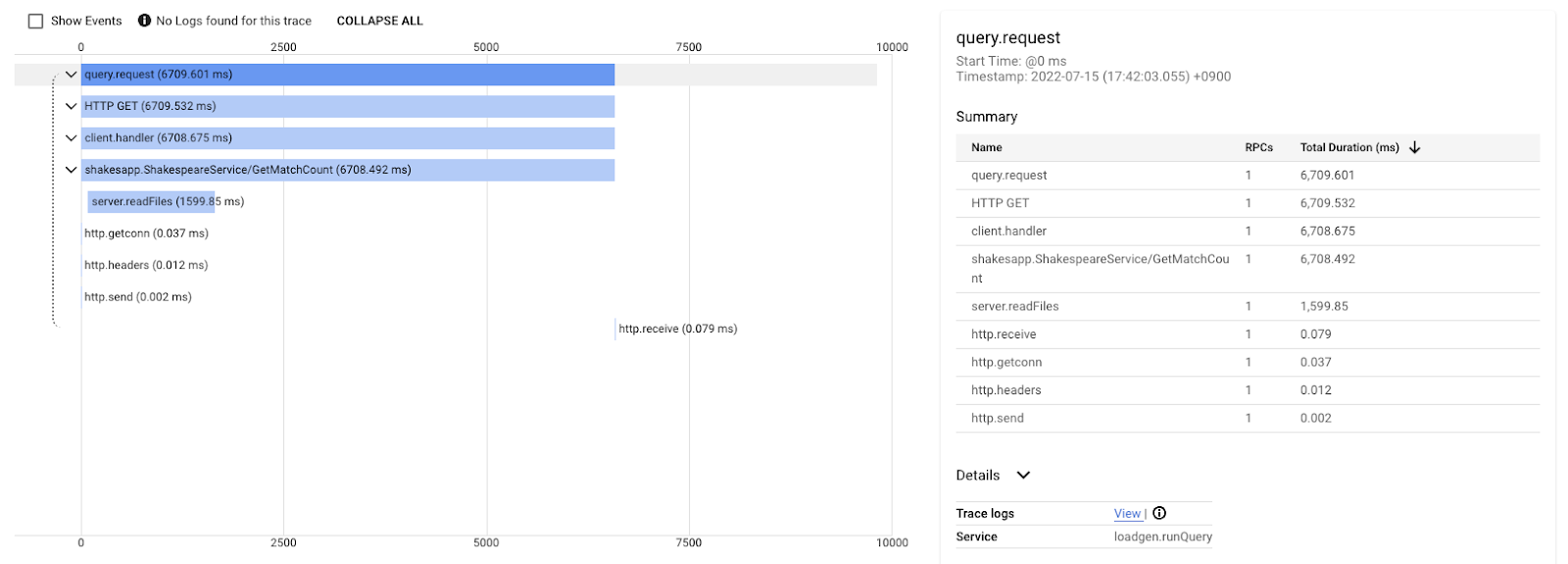
וזה אחרי השיפור לאותה שאילתה. כפי שניתן לראות, זמן האחזור הכולל הוא עכשיו 1.5 שניות (1,500 אלפיות השנייה), וזה שיפור משמעותי לעומת ההטמעה הקודמת.
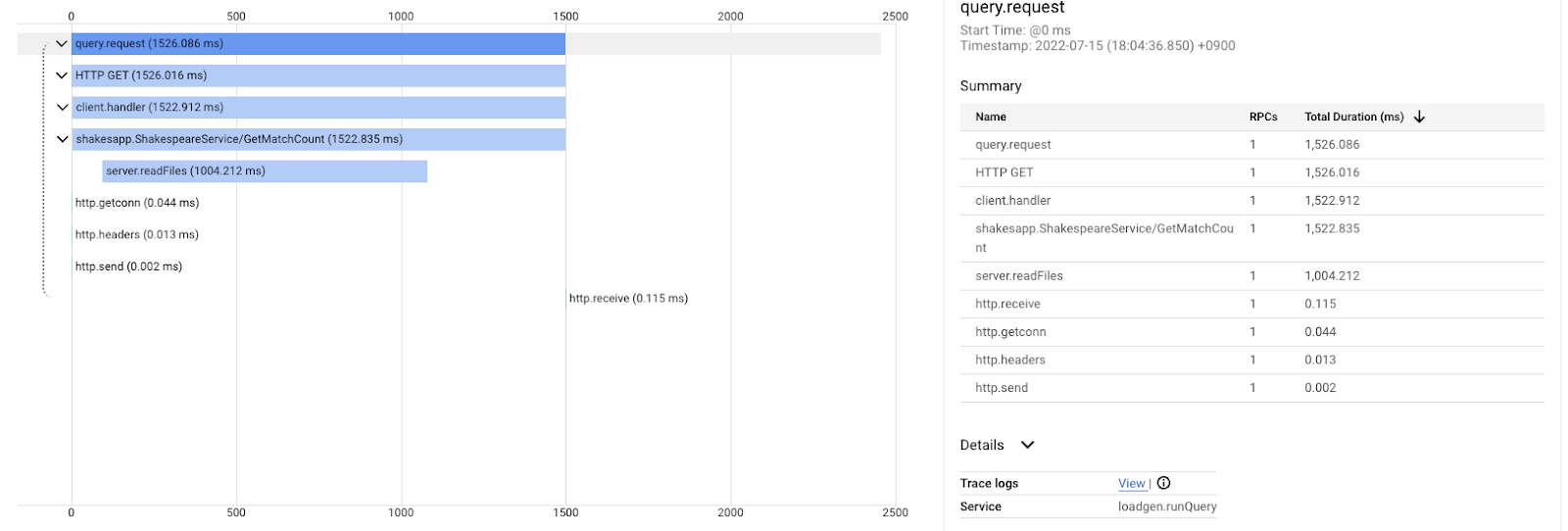
הנקודה החשובה כאן היא שבתרשים ה-Waterfall של מעקב מבוזר, מידע על סטאק ביצוע לא זמין אלא אם מבצעים אינסטרומנטציה של יחידות לוגיות למעקב בכל מקום. בנוסף, מעקב מבוזר מתמקד רק בזמן האחזור בין השירותים, בעוד שפרופיל רציף מתמקד במשאבי המחשב (CPU, זיכרון, תהליכי מערכת הפעלה) של שירות יחיד.
בנוסף, המעקב המבוזר מבוסס על אירועים, והפרופיל המתמשך הוא סטטיסטי. לכל מעקב יש גרף חביון שונה, וצריך פורמט שונה כמו חלוקה כדי לראות את מגמת השינויים בחביון.
סיכום
בשלב הזה בדקתם את ההבדל בין מעקב מבוזר לבין פרופילים רציפים.
8. מזל טוב
יצרתם בהצלחה עקבות מבוזרים באמצעות OpenTelemery ואישרתם את השהיות של הבקשות במיקרו-שירות ב-Google Cloud Trace.
כדי לתרגל עוד, אתם יכולים לנסות את הנושאים הבאים בעצמכם.
- ההטמעה הנוכחית שולחת את כל הטווחים שנוצרו על ידי בדיקת תקינות. (
grpc.health.v1.Health/Check) איך מסננים את הטווחים האלה מ-Cloud Trace? רמז כאן. - התאמת יומני אירועים לטווחים, והסבר על אופן הפעולה ב-Google Cloud Trace וב-Google Cloud Logging. רמז כאן.
- להחליף שירות מסוים בשירות בשפה אחרת ולנסות להגדיר אותו באמצעות OpenTelemetry בשפה הזו.
אם תרצה לקבל מידע על כלי הפרופיל אחרי זה, תוכל לעבור לחלק 2. במקרה כזה, אפשר לדלג על הקטע 'ניקוי' שבהמשך.
פינוי נפח
בסיום ה-Codelab, חשוב להפסיק את אשכול Kubernetes ולמחוק את הפרויקט כדי שלא תחויבו באופן לא צפוי ב-Google Kubernetes Engine, ב-Google Cloud Trace וב-Google Artifact Registry.
קודם צריך למחוק את האשכול. אם מריצים את האשכול עם skaffold dev, פשוט לוחצים על Ctrl-C. אם מריצים את האשכול עם skaffold run, מריצים את הפקודה הבאה:
skaffold delete
פלט הפקודה
Cleaning up... - deployment.apps "clientservice" deleted - service "clientservice" deleted - deployment.apps "loadgen" deleted - deployment.apps "serverservice" deleted - service "serverservice" deleted
אחרי שמוחקים את האשכול, בחלונית התפריט בוחרים באפשרות 'IAM & Admin' (ניהול הרשאות וניהול) > 'Settings' (הגדרות), ואז לוחצים על הלחצן 'SHUT DOWN' (כיבוי).
לאחר מכן מזינים את מזהה הפרויקט (ולא את שם הפרויקט) בטופס שבתיבת הדו-שיח ומאשרים את הסגירה.